생성형 검색에서 공정한 기여도 평가를 위한 MAXSHAPLEY 알고리즘
Generative search engines based on large language models (LLMs) are replacing traditional search, fundamentally changing how information providers are compensated. To sustain this ecosystem, we need fair mechanisms to attribute and compensate content…
Authors: Sara Patel, Mingxun Zhou, Giulia Fanti
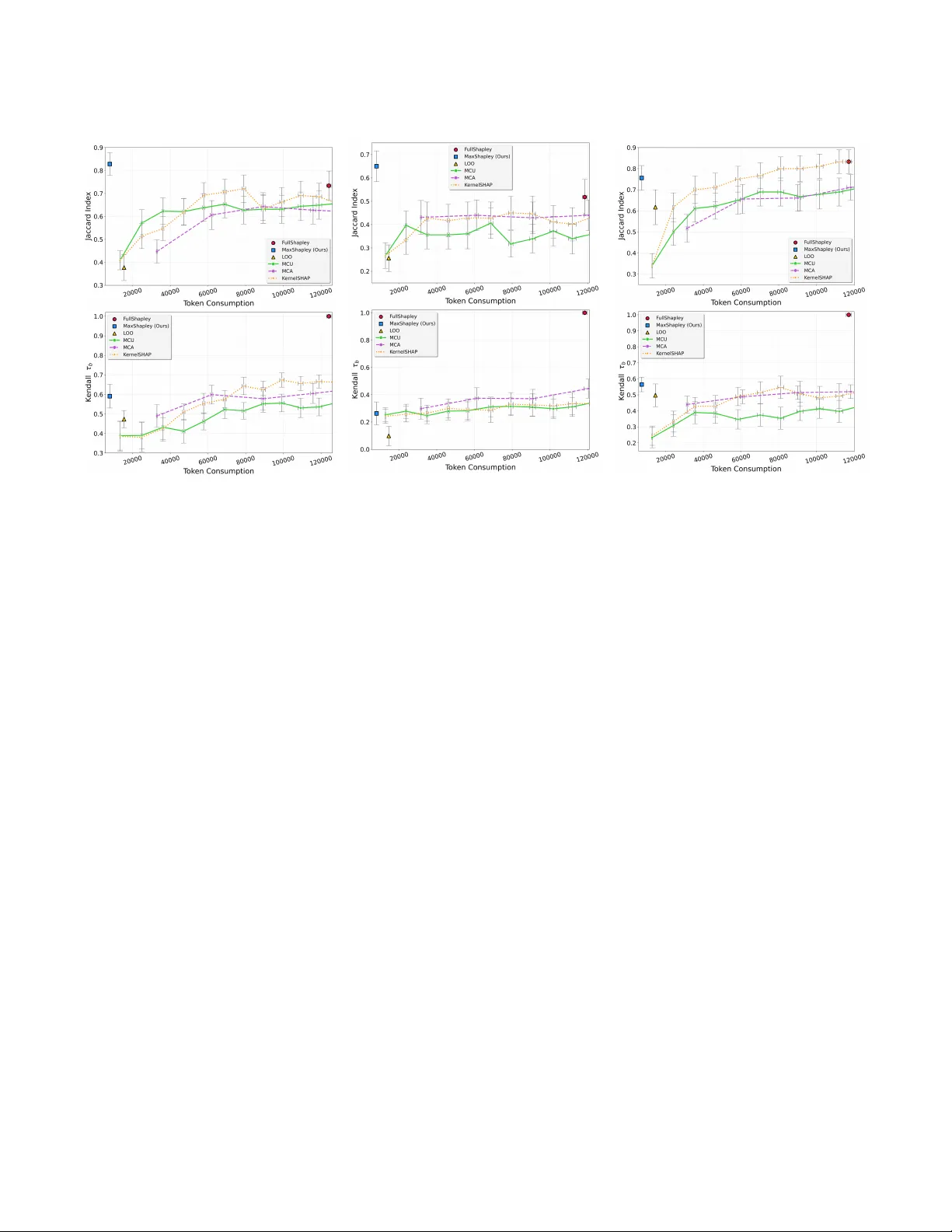
M A X S H A P L E Y : T o war ds Incentive-compatib le Generative Sear c h with F air Conte xt Attrib ution Sara Patel ∗† , Mingxun Zhou ∗§† , Giulia Fanti ∗ ∗ Carnegie Mellon Uni v ersity § HKUST Abstract Generativ e search engines based on large language models (LLMs) are replacing traditional search, fundamentally changing how infor - mation providers are compensated. T o sustain this ecosystem, we need fair mechanisms to attribute and compensate content providers based on their contributions to generated answers. W e introduce M A X S H A P L E Y , an efficient algorithm for fair attrib ution in genera- tiv e search pipelines that use retriev al-augmented generation (RA G). M A X S H A P L E Y is a special case of the celebrated Shaple y value; it leverages a decomposable max-sum utility function to compute attributions with linear computation in the number of documents, as opposed to the exponential cost of Shapley values. W e ev alu- ate M A X S H A P L E Y on three multi-hop QA datasets (HotPotQA, MuSiQUE, MS MARCO); M A X S H A P L E Y achieves comparable attribution quality to exact Shaple y computation, while consuming a fraction of its tokens—for instance, it giv es up to an 8x reduction in resource consumption ov er prior state-of-the-art methods at the same attribution accurac y . A CM Reference Format: Sara Patel ∗† , Mingxun Zhou ∗§† , Giulia Fanti ∗ . 2025. M A X S H A P L E Y : T ow ards Incentive-compatible Generative Search with F air Conte xt Attri- bution. In . A CM, Ne w Y ork, NY , USA, 15 pages. https://doi.org/10.1145/ nnnnnnn.nnnnnnn 1 Introduction Large language models (LLMs) have fundamentally changed ho w people interact with information online. As a prominent example, Generativ e search engines (also kno wn as “LLM search") reduce cognitiv e load on users by providing answers to queries without requiring users to sift through information sources or synthesize information themselves. As a result, generativ e search products (e.g. Perplexity AI [ 69 ] and Google Gemini [ 22 ]) are rapidly replacing traditional search engine products; many generati ve search products are already serving tens of millions of users daily [65]. Generativ e search pipelines typically in voke a two-step process for answering user queries: (1) First, the y retrieve rele v ant documents from a large corpus (e.g. the web, or a proprietary kno wledge base). † Equal contribution Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee pro vided that copies are not made or distrib uted for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than the author(s) must be honored. Abstracting with credit is permitted. T o copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and /or a fee. Request permissions from permissions@acm.org. Confer ence’17, W ashington, DC, USA © 2025 Copyright held by the owner/author(s). Publication rights licensed to A CM. A CM ISBN 978-x-xxxx-xxxx-x/YYYY/MM https://doi.org/10.1145/nnnnnnn.nnnnnnn (2) Giv en the retrieved documents, they generate a concise response to the query , which is sho wn directly to the user . This paradigm is an example of retrie val-augmented generation (RA G) [33, 38, 47]. Despite its promise, generative search completely changes e xisting incentive structur es for content pro viders . T oday , content providers (e.g. ne ws websites, blogs, education websites) rely in part on search engines to direct users to their sites; this traf fic is typically monetized via adv ertisements [ 92 ]. Generati ve search engines instead allow users to obtain answers directly from an AI-generated summary without visiting original sources. Traf fic to content providers appears to hav e dropped significantly since the launch of popular generative search engines [ 14 , 74 ], with Bain & Company estimating that as of early 2025, about 80% of web search users reported using AI summaries without progressing to another destination at least 40% of the time [ 81 , 82 ]—ev en though generativ e search engines have started to provide basic citations to original sources. According to recent reports [ 26 , 80 ], the fraction of worldwide web traffic produced by traditional search fell about 5% from June 2024 to June 2025, with some sources estimating an ev en larger drop (up to 25% [ 82 ]). Some media org anizations are referring to the resulting reduction in traffic as an “e xtinction-level e vent" [4]. Content providers are starting to push back; several la wsuits hav e already been filed against generative search providers for reduced traffic and lost re venue [ 29 , 62 , 68 ]. A complementary , b ut related, set of la wsuits sued AI companies for using copyrighted material dur - ing training (e.g. the Ne w Y ork T imes lawsuit against OpenAI [ 84 ] and the LibGen lawsuit against Anthropic [ 12 ]). These lawsuits are resulting in billions of dollars in liabilities and an increasing distrust from content creators [70]. Nascent industry efforts to rethink content pro viders’ relationship with LLM search include generative search engines that compensate content providers [ 1 , 32 ], and features allowing content providers to block AI cra wlers or demand payment per cra wl [ 3 ]. W e do not know the full compensation structure for these approaches, and it is unclear if and how these ef forts tailor compensation to the r elevance of content. Khosrowi et al. argue that, “Credit for ... [AI] output should be distributed between... contributors according to the nature and significance of... contributions made" [ 42 ]. Crucially , without a fair incenti ve structure, content providers may choose to withhold content from generati ve search engines, harming the whole ecosystem. Pr oblem statement and status quo. W e predict that the business model for generativ e search will need to evolv e to compensate con- tent providers for their contrib utions. Early academic ef forts to re- think the LLM ads ecosystem hav e primarily focused on sponsored search auctions for LLMs [ 11 , 13 , 21 , 25 , 28 , 34 ], which do not benefit organic content pro viders. In this paper , our goal is to define a method for attributing generati ve search results to original sources, so that content pro viders can be f airly compensated. In particular , we Conference’17, July 2017, Washington, DC, USA Sara Patel ∗† , Mingxun Zhou ∗§† , Giulia Fanti ∗ define “fairness" according to common axiomatic properties (Sec- tion 2). A key operational requirement is that our algorithm should be practical for existing generativ e search pipelines by minimizing the number and size of queries to an LLM oracle. Prior W ork. In the broader ML community , variants of the attri- bution problem hav e been used to interpret and explain the behaviors of complex machine learning models (we include a more complete description of related w ork in Section 6). Notable high-impact works include datamodels [ 37 ], TRAK [ 67 ] and Data Shapley [ 30 , 86 , 87 ] for training-time attribution to training samples, and LIME [ 73 ] and Kernel SHAP [ 53 ] for inference-time attribution between inputs and features. In contrast, our work aims to conduct inference-time attribution of outputs to RA G data sources. In the RAG domain, the most rele vant line of work is conte xt attribution , which aims to identify which piece of retrie ved conte xt information leads to the final answer generated by an LLM [ 16 – 18 , 23 , 36 , 49 , 72 , 90 ]. Howe ver , most existing context attribution methods focus fine-grained explainability , i.e., providing human- interpretable explanations of the LLM’ s output, rather than pro viding a fair and quantitative attribution to the sources of information from an economic perspectiv e. T o this end, a few recent works ha ve ex- plored the use of Shapley v alue [ 77 ] for attribution to information sources [ 60 , 88 , 90 ], where Nematov et al. [ 60 ] found that the K er- nel SHAP method [ 53 ] outperforms other Shapley-based baselines in terms of both attrib ution accuracy and computational ef ficiency . Howe ver , Shapley-based attribution typically requires repetiti ve tri- als to e valuate the contrib utions of sources—a well-known limitation of Shapley v alue [ 60 , 88 ]—making them computationally infeasible in latenc y-sensitiv e generativ e search scenarios (Figure 1, Section 4). 1.1 Our Contribution Our core technical contribution is a nov el attribution algorithm for RA G named M A X S H A P L E Y that fairly quantifies the contribution of each information provider to the final answe r based on the Shapley value concept. As in other Shaple y-based attrib ution methods [ 18 , 53 , 60 ] we treat each information pro vider as a player in a cooperati ve game and quantify each player’ s contribution by ev aluating their expected marginal contrib ution to the outcome’ s utility function , i.e., the quality of the answer . M A X S H A P L E Y of fers tw o key benefits ov er prior work: • LLM-as-a-judge utility function offers flexibility under prac- tical constraints. In prior work [ 18 , 60 ], the utility function is typically defined as the log-likelihood of the LLM generating the final answer, given a subset of information providers or partial ground truth as context. This requires access to the LLM’ s internal logits and/or assumes the a vailability of ground truth at the time of ev aluation, both of which are infeasible in practice. W e do not assume access to internal LLM state; instead, M A X S H A P L E Y uses a (possibly dif ferent) LLM-as-a-judge to e v aluate the quality of the final answer gi ven a subset of information providers as context. This requires only black-box access to the LLM and does not use ground truth, while also being customizable to dif ferent ev aluation criteria (e.g. relevance, accuracy , helpfulness, etc), making it more flexible and practical in real-world scenarios. Figure 1: Jaccard index w .r .t. ground truth relev ance scores ver - sus token consumption f or attribution algorithms on MuSiQUE with GPT4.1o. M A X S H A P L E Y achiev es 0.76 vs. FullShapley’ s 0.83, while using 6 . 2% of the token consumption. In contrast, Ker - nelSHAP reaches comparable quality to M A X S H A P L E Y (0.75) at 8 × the token consumption of M A X S H A P L E Y . • Shapley value computation with decomposable utility function offers significant efficiency gains. Prior works [ 18 , 53 , 60 ] repeat- edly sample different subsets of information providers to e valuate their marginal contributions and thus require a large computa- tional overhead. Both ContextCite [ 18 ] and Nematov et al. [ 60 ] reported that their methods require 15-30x more computation cost than the original RA G process for good attrib ution accuracy . In- stead, M A X S H A P L E Y lev erages the unique structure of generative search to propose a decomposable max-sum utility function for which the normalized mar ginal contribution of each information provider can be computed exactly with linear LLM queries in the number of information providers, without Monte-Carlo style approximations. Our empirical e valuation demonstrates that M A X S H A P L E Y can accurately and ef ficiently attribute the contributions of information providers in v arious RAG settings. In terms of the attrib ution ac- curacy , M A X S H A P L E Y achieves a high correlation (Kendall-tau correlation > 0 . 79 ) with the brute-force Shapley value through ex- haustiv e search, and shows a high alignment with human-annotated ground truth data (Jaccard Index score > 0 . 9 ). In terms of efficiency , M A X S H A P L E Y requires less than 7% of the computational costs of brute-force Shapley computation (measured by token consumption), and it reaches the same attrib ution accuracy as state-of-the-art Ker nelSHAP using 27% of the computational cost (Figure 1). W e summarize our contributions as follows: (1) W e propose M A X S H A P L E Y , a novel and ef ficient algorithm to fairly attrib ute the contributions of information providers to the final answer of a generativ e search (Section 3). (2) Through extensi ve empirical ev aluations, we show that M A X S H A P - L E Y achieves a significantly better tradeof f between attribution accuracy and ef ficiency than other baselines (Section 4). (3) W e propose potential incentiv e allocation mechanisms based on the attrib uted values provided by M A X S H A P L E Y to fairly compensate information providers (Section 5). M A X S H A P L EY : T owards Incentive-compatib le Generative Search with Fair Context Attribution Conference’17, July 2017, Washington, DC, USA Figure 2: System diagram of the attribution pr oblem in RA G pipeline. The query 𝑞 is used to retriev e a list of information sour ces 𝑆 = { 𝑠 1 , . . . , 𝑠 𝑚 } . The Search LLM takes in the query 𝑞 and the retriev ed sources 𝑆 and generates a concise answer 𝑎 to the user query . Our goal is to generate a score 𝜙 𝑖 for each inf ormation source 𝑠 𝑖 to quantify its contribution to the final answer 𝑎 . (4) W e release an open-source implementation of M A X S H A P L E Y and manually re-annotated subsets of HotPotQA, MuSiQue and TREC for future research. 1 2 Problem Setup and Pr eliminaries Pr oblem Setting. W e consider a retriev al-augmented generation (RA G) pipeline [ 33 , 38 , 47 ], which is a central building block of most LLM-based search engines. As illustrated in Figure 2, giv en a user query string 𝑞 , a RA G system first retrieves a list of 𝑚 relev ant information sources 𝑆 = { 𝑠 1 , . . . , 𝑠 𝑚 } , where we think of each 𝑠 𝑖 as a text document or snippet. Then, a text-generation model, which we refer to as the sear ch LLM Ψ , tak es the user query 𝑞 and the retriev ed sources 𝑆 as context and generates a concise answer 𝑎 to the user query . Our goal is to generate a score 𝜙 𝑖 ( 𝑞, 𝑎, 𝑠 𝑖 , 𝑆 ) for each information source 𝑠 𝑖 to quantify its contribution to the final answer 𝑎 . Note that the attribution module is gi ven access to a (possibly different) attribution LLM, which we denote with Ψ 𝐴 . The computed attribution scores 𝜙 𝑖 can be used to allocate credit (e.g. monetary compensation) to content providers. In our empirical evaluation, we use question-response datasets that include a query 𝑞 , a corpus of documents 𝑆 , a ground truth response ˜ 𝑎 and a binary annotation v ector ˜ 𝜙 , indicating which doc- uments in 𝑆 are relev ant. That is, ˜ 𝜙 𝑖 = 1 iff 𝑠 𝑖 was selected as a “relev ant" document, and 0 otherwise (more details in Section 4). Utility Function. W e will use a utility-based framew ork for the attribution problem. Whereas prior work has defined utility functions as the loss of a target model o ver a subset of training data [ 18 , 30 , 60 , 87 ], we instead build our utility function using an LLM-as-a-judge, inspired by prior w ork on LLM ev aluation [ 52 , 93 ]. W e assume there exists (and we can call) an ev aluation function Judge Ψ 𝐴 ( 𝑞, 𝑎 ; 𝑝 ) that inputs a query 𝑞 and an answer 𝑎 to the attribution LLM Ψ 𝐴 ; it is parameterized by a prompt 𝑝 . This function outputs a real-valued score in [ 0 , 1 ] representing the quality of the answer 𝑎 with respect to the query 𝑞 (1 is best). The prompt 𝑝 giv es us the flexibility to evaluate responses with respect to various scoring rules (e.g. 1 https://github .com/spaddle- boat/MaxShapley relev ance, correctness, completeness). Different baselines may hav e different J udge functions; we describe ours in Section 3. Using the Judge function, we define a utility function 𝑈 ( · ) for a subset of information sources. This function passes a subset of information sources 𝑆 ′ ⊆ 𝑆 to the search LLM Ψ , along with the query 𝑞 , to generate an answer . Then, we use the attribution LLM Ψ 𝐴 to run the LLM-as-a-judge ev aluation on the response. 𝑈 ( 𝑆 ′ ) = Judge Ψ 𝐴 ( 𝑞, Ψ ( 𝑞 , 𝑆 ′ ) ; 𝑝 ) , (1) where Ψ ( 𝑞, 𝑆 ′ ) denotes the answer generated by the search LLM Ψ based on the query 𝑞 and the information sources in 𝑆 ′ . Pr oblem Statement. Identify a score function 𝜙 and a utility func- tion 𝑈 that satisfies the following ke y properties [78]: (1) Efficiency : The total utility is fully distributed among all players, i.e., Í 𝑖 𝜙 𝑈 𝑖 = 𝑈 ( 𝑆 ) . (2) Symmetry : If two players contribute equally to all coalitions, they should recei ve the same attrib ution, i.e., if 𝑈 ( 𝑆 ′ ∪ { 𝑠 𝑖 }) = 𝑈 ( 𝑆 ′ ∪ { 𝑠 𝑗 }) for all 𝑆 ′ ⊆ 𝑆 \ { 𝑠 𝑖 , 𝑠 𝑗 } , then 𝜙 𝑈 𝑖 = 𝜙 𝑈 𝑗 . (3) Null player : If a player does not contribute to an y coalition, it should receiv e zero attribution, i.e., if 𝑈 ( 𝑆 ′ ∪ { 𝑠 𝑖 }) = 𝑈 ( 𝑆 ′ ) for all 𝑆 ′ ⊆ 𝑆 \ { 𝑠 𝑖 } , then 𝜙 𝑈 𝑖 = 0 . (4) Additivity : When the utility function 𝑈 is the sum of two inde- pendent utility functions 𝑈 1 and 𝑈 2 , the attribution for 𝑈 should be the sum of the attrib utions for 𝑈 1 and 𝑈 2 , i.e., 𝜙 𝑈 𝑖 = 𝜙 𝑈 1 𝑖 + 𝜙 𝑈 2 𝑖 . (5) Computational efficiency: W e want the algorithm to be compu- tationally efficient, i.e. requiring polynomial computation and practical runtime (this will be ev aluated empirically). 2.1 Baselines W e briefly discuss four relevant baselines that will form the basis of our ev aluation. W e include more related work in Appendix 6. Shaple y V alue. The most natural solution to our problem is the celebrated Shapley v alue from cooperativ e game theory [ 78 ]. Intu- itiv ely , Shapley v alue 𝜙 𝑈 𝑖 for source 𝑖 measures the a verage marginal utility contribution of the 𝑖 th information source to the final answer within all possible subsets of information sources. Formally: Conference’17, July 2017, Washington, DC, USA Sara Patel ∗† , Mingxun Zhou ∗§† , Giulia Fanti ∗ 𝜙 𝑈 𝑖 = 𝑆 ′ ⊆ 𝑆 \ { 𝑠 𝑖 } | 𝑆 ′ | ! ( | 𝑆 | − | 𝑆 ′ | − 1 ) ! | 𝑆 | ! ( 𝑈 ( 𝑆 ′ ∪ { 𝑠 𝑖 }) − 𝑈 ( 𝑆 ′ ) ) . When the order of the players matters (as is the case in our setting, because LLMs are kno wn to have positional bias [ 50 ], see Section 4.2), the Shapley value can also be equi valently defined as the expected mar ginal contribution of each player when the players join the coalition in a uniformly random ordering: 𝜙 𝑈 𝑖 = E 𝜋 ∼ Perm ( 𝑆 ) [ 𝑈 ( 𝑆 𝜋 ,𝑖 ∪ { 𝑠 𝑖 }) − 𝑈 ( 𝑆 𝜋 ,𝑖 ) ] , where Perm ( 𝑆 ) denotes the uniform distribution over all permuta- tions of 𝑆 , and 𝑆 𝜋 ,𝑖 denotes the ordered list of sources that appear before 𝑠 𝑖 in the permutation 𝜋 . The Shapley value satisfies properties 1-4 above; howev er, it does not satisfy Property 5 (computational ef ficiency). W orst-case, computing Shapley value has complexity 𝑂 ( 𝑚 2 𝑚 ) for 𝑚 sources (Algorithm 3 in Appendix A.2). Nonetheless, Shapley value is an important baseline; we refer to it as FullShapley in our ev aluation. Leave-One-Out Attribution. A more efficient, albeit less prin- cipled, technique in the data v aluation literature is leave-one-out (LOO) attribution [ 43 , 49 ]. The LOO attribution score for each source 𝑠 𝑖 is computed by e valuating the utility function on the full set of information sources and then on the subset with 𝑠 𝑖 remov ed, and then taking the dif ference. Formally , for an information source 𝑠 𝑖 : 𝜙 LOO 𝑖 = 𝑈 ( 𝑆 ) − 𝑈 ( 𝑆 \ { 𝑠 𝑖 }) . (2) LOO satisfies properties 2-5, b ut critically , it does not satisfy prop- erty 1 in general. Commonly , a single player may contribute to the full utility , but LOO attrib ution assigns zero attribution to all players. Monte-Carlo Shaple y Appr oximation. Due to the computational inefficienc y of computing Shaple y v alue, Monte-Carlo based approx- imations are often used in practice [ 56 , 58 ]. They estimate Shaple y values by sampling random permutations and computing the mar- ginal contribution of each source in each permutation. A permutation, in this context, refers to an ordering of the information sources 𝑆 . A simple Monte-Carlo-based approximation can be obtained by uniformly sampling a permutation 𝜎 ( 𝑆 ) of the information sources. From a single 𝜎 ( 𝑆 ) , Shapley v alues for each source 𝑠 𝑖 can be calcu- lated by starting from the utility of the empty set 𝑈 ( ∅) , traversing the permutation, adding one source at a time, and recording the marginal contribution of each 𝑠 𝑖 in the order the y appear in 𝜎 ( 𝑆 ) . This method is denoted as Monte-Carlo Uniform (MCU) . Antithetic sampling is a variance reduction technique that takes ad- vantage of negati ve correlations between permutations by consider- ing each permutation and its in verse as a correlated pair [ 58 ]. Specif- ically , for each sampled permutation 𝜎 ( 𝑆 ) , its in verse 𝜎 ( 𝑆 ) − 1 â ˘ A ˇ Tthe permutation with rev erse orderingâ ˘ A ˇ T is also ev aluated. This method is denoted as Monte-Carlo Antithetic (MCA) . Both MCU and MCA satisfy properties 1-4 in expectation, b ut we find empirically the y require a large number of samples to adequately approximate FullShapley (Section 4). K ernelSHAP . Finally , we consider Ker nelSHAP [53], a popular method for approximating Shapley values. K ernelSHAP reframes Shapley estimation as weighted linear regression over coalition sam- ples. The method solves for Shaple y v alues using LASSO regression. It does not formally satisfy properties 1-4 in general due to its linear approximation of Shapley v alue. As with MCU and MCA, we find that KernelSHAP generally requires many samples to adequately approximate FullShapley (Section 4). 3 M A X S H A P L E Y : Efficient and Fair Attrib ution in Generative Sear ch In this section, we present our main technical construction, M A X S H A P - L E Y , an efficient algorithm to fairly and efficiently attribute the contributions of information pro viders in a retriev al-augmented gen- eration (RA G) pipeline based on Shapley value. 3.1 A new utility function f or RA G attrib ution Our main technical innov ation is in the choice of a utility function for M A X S H A P L E Y . W e observe that information sources in the RA G pipeline can provide both complementary and ov erlapping information to the final answer, and attrib ution should consider both perspectiv es. • Cooperation in pro viding complementary information. Infor- mation sources provide complementary information to each other, creating comprehensiv e context for the final answer . For example, for a query about recent stock market trends, different articles from multiple sources could provide analyses of dif ferent sectors (e.g., tech, consumer , energy , etc.), and their attribution should be based on a cooperative game. • Competition in providing overlapping information. In cases where information sources provide overlapping information, at- tribution should be based on competition , where the source with better quality or higher relev ance should be gi ven more credit. F or example, for a query about recent stock mark et trends, dif ferent articles discussing the same macroeconomic data such as GDP should be considered as competing with each other . Our new utility function. Based on the above intuition, we pro- pose a new utility function that captures both the cooperativ e and competitiv e nature of information sources. More specifically , the Judge function for M A X S H A P L E Y first prompts the attribution LLM Ψ 𝐴 to decompose the rationale of the an- swer 𝑎 into 𝑛 atomic logical key points, denoted as 𝑃 = { 𝑝 1 , . . . , 𝑝 𝑛 } (prompt in Appendix A.1). This represents the cooperative perspec- tiv e of information sources, where they work together to provide comprehensiv e context for the final answer . Then, for each k ey point 𝑝 𝑗 , given that it is already an atomic piece of information, information sources should compete with each other to provide the most rele vant information to support 𝑝 𝑗 , which represents the competitive perspective of information sources. T o quantify their contribution to this particular key point, we use the Judge to compute a relev ance-quality-based score of each informa- tion source 𝑠 𝑖 to 𝑝 𝑗 , denoted as 𝑣 𝑖 , 𝑗 (prompt in Appendix A.1). Now , given all key points and scores for source-key point pairs, we can define the utility function with a sum-max structure as follo ws: for any subset of information sources 𝑆 ′ ⊆ 𝑆 and each key point 𝑝 𝑗 , we consider that the utility of 𝑆 ′ for 𝑝 𝑗 is simply the maximum rele- vance score among all information sources in 𝑆 ′ , i.e., max 𝑠 𝑖 ∈ 𝑆 ′ 𝑣 𝑖 , 𝑗 . M A X S H A P L EY : T owards Incentive-compatib le Generative Search with Fair Context Attribution Conference’17, July 2017, Washington, DC, USA Then, the total utility of 𝑆 ′ for the answer 𝑎 can be defined as the weighted sum of utilities for all key points. 𝑈 M AX S H A PL E Y ( 𝑆 ′ ) = 𝑛 𝑗 = 1 𝑤 𝑗 max 𝑠 𝑖 ∈ 𝑆 ′ 𝑣 𝑖 , 𝑗 . (3) Here, 𝑤 𝑗 is the weight of key point 𝑝 𝑗 , which can be either uni- formly set as 1 𝑛 or computed through the LLM-as-judge approach to measure the importance of 𝑝 𝑗 to the overall answer 𝑎 . In our experiments we set 𝑤 𝑗 = 1 𝑛 for all 𝑗 , but learning these weights is an interesting question for future work. Hence, for M A X S H A P L E Y , the Judge Ψ 𝐴 ( 𝑞, Ψ ( 𝑞 , 𝑆 ′ ) ; 𝑝 ) function first computes keypoints for response 𝑎 , then determines the most rele vant document for each keypoint, then computes a weighted sum (prompts in Section A.1). Note that this definition resembles the MaxSim score used in the ColBER T retriev al algorithm [ 41 , 76 ]. The MaxSim score between a text query and a document is defined as the sum of all text query tokens’ maximum embedding similarity with an y token in the doc- ument; the retrie ver returns documents with the largest MaxSim. ColBER T -style retrie val methods remain state-of-the-art retrieval methods [ 76 ], which further justifies our design choice. Howe ver , there are two main differences between our approaches: (1) comput- ing MaxSim at the le vel of tok ens does not make sense for generativ e search, where different tokens can be highly correlated with each other , but not necessarily with the final answer . W e instead use the LLM-as-a-judge approach to compute scores at the ke y-point lev el, capturing holistic semantic information. (2) ColBER T does not con- nect their method to fair attribution or Shapley v alue, as their goal is simply to retriev e relevant documents (Section 3.2). 3.2 Efficient Shapley value computation f or the new utility function A key advantage of this new utility function is that it allows us to compute the exact Shaple y value ef ficiently , av oiding the need for computationally expensi ve Monte Carlo-based approximations. Decomposition of the Shapley value computation. The first obser- vation is that the new utility definition (Equation 3) has a weighted sum-max structure, which can be decomposed into 𝑛 independent maximization games for each ke y point. W e define the utility func- tion for the 𝑗 -th ke y point as follo ws: 𝑈 𝑗 Max ( 𝑆 ′ ) = max 𝑠 𝑖 ∈ 𝑆 ′ 𝑣 𝑖 , 𝑗 . (4) Then, based on the additivity of Shaple y v alue, we know that the Shapley value for each source 𝑖 is simply a weighted sum of the Shapley v alues for the 𝑛 key points, i.e., 𝜙 𝑈 M AX S HA P LE Y 𝑖 = 𝑛 𝑗 = 1 𝑤 𝑗 𝜙 𝑈 𝑗 Max 𝑖 . (5) Shaple y value for ke y-point level maximization games. The next step is to compute the Shapley v alue for each key-point le vel maxi- mization game. Consider a utility function Max ( ·) defined on a set of players 𝑆 = { 𝑠 1 , . . . , 𝑠 𝑚 } and their associated non-negati ve values 𝑣 1 , . . . , 𝑣 𝑚 such that it simply computes the maximum v alue among the players in 𝑆 ′ , i.e., Max ( 𝑆 ′ ) = max 𝑠 𝑖 ∈ 𝑆 ′ 𝑣 𝑖 . This maximization game is a special class of utility functions for which efficient and exact Shapley v alue computation is av ailable [ 53 ]. F or completeness, we present Algorithm 1, an 𝑂 ( 𝑚 3 ) time algorithm for Shapley value computation for the maximization game, which is significantly more efficient than the 𝑂 ( 𝑚 2 𝑚 ) time brute-force algorithm. W e provide some details of the algorithm below . Algorithm 1: Exact Shapley V alue Computation for the Maximization Game Input: List of non-negati ve values 𝑣 1 , 𝑣 2 , . . . , 𝑣 𝑚 . Output: Shapley v alues 𝜙 𝑖 for each 𝑖 ∈ 𝑚 1 W e assume 𝑣 1 ≤ 𝑣 2 , · · · ≤ 𝑣 𝑚 ; if not, we can sort the list first and keep track of the rankings. 2 for 𝑖 ∈ 𝑚 do 3 𝜙 𝑖 ← 𝑣 𝑖 𝑚 ; // The marginal contribution when 𝑣 𝑖 is placed at first is just 𝑣 𝑖 , which happens with probability 1 / 𝑚 . 4 for 𝑗 ∈ { 1 , 2 , . . . , 𝑖 − 1 } do 5 𝑝 ← 0 ; // now we compute the probability that the margin being 𝑠 𝑖 − 𝑠 𝑗 given a random permutation. 6 for 𝑘 ∈ { 2 , . . . , 𝑗 + 1 } do 7 Let ev ent 𝐴 be “ 𝑠 𝑖 is placed at the 𝑘 -th position”; 8 Let ev ent 𝐵 be “ 𝑠 𝑗 is placed among the first 𝑘 − 1 positions”; 9 Let ev ent 𝐶 be “ All elements greater than 𝑠 𝑗 except 𝑠 𝑖 are placed after the 𝑘 -th position, so 𝑠 𝑗 remains the max among the first 𝑘 − 1 positions”; 10 𝑝 𝐴 = Pr [ 𝐴 ] = 1 / 𝑚 ; 11 𝑝 𝐵 = Pr [ 𝐵 | 𝐴 ] = 𝑘 − 1 𝑚 − 1 ; 12 𝑝 𝐶 = Pr [ 𝐶 | 𝐴, 𝐵 ] = Î 𝑚 − 𝑗 − 1 ℓ = 1 𝑚 − 𝑘 − 𝑙 + 1 𝑚 − 1 − 𝑙 ; 13 𝑝 ← 𝑝 + 𝑝 𝐴 𝑝 𝐵 𝑝 𝐶 ; 14 end 15 𝜙 𝑖 ← 𝜙 𝑖 + 𝑝 · ( 𝑣 𝑖 − 𝑣 𝑗 ) . 16 end 17 end 18 retur n { 𝜙 𝑖 } 𝑖 ∈ [ 𝑚 ] T o compute the Shapley v alue for the 𝑖 -th player, Algorithm 1 computes the probability of 𝑣 𝑖 being placed at the 𝑘 -th position of a uniformly random permutation, while 𝑣 𝑗 is the maximum among the first 𝑘 − 1 positions in the permutation. Thus, the marginal contribu- tion is fixed as 𝑣 𝑖 − 𝑣 𝑗 and we can compute the expected marginal contribution from all such e vents. The closed-form formula for prob- ability computation is presented in Algorithm 1. An interesting observation is that for any pair of players 𝑣 𝑖 and 𝑣 𝑗 , the probability of 𝑣 𝑖 − 𝑣 𝑗 being the marginal contribution of 𝑣 𝑖 is independent of the actual values of all players, and depends only on the relativ e ranking of 𝑣 𝑖 and 𝑣 𝑗 among all players. Thus, we can precompute the probabilities for all pairs of rankings gi ven a specific number of players 𝑚 and store them in a lookup table to further speed up the computation. Giv en the decomposition idea and the efficient Shapley value com- putation for the maximization game, we present the full construction of M A X S H A P L E Y in Algorithm 2. Conference’17, July 2017, Washington, DC, USA Sara Patel ∗† , Mingxun Zhou ∗§† , Giulia Fanti ∗ Implementation Considerations. The actual implementation of Algorithm 2 can vary depending on the use scenario, including: • One-pass or Multiple Pass. W e can either ask the LLM to gener- ate key points and scores in one pass within the same call during the answer generation process, or use multiple calls to the LLM to generate key points and scores separately . As in prior work, we used multiple calls to reduce hallucinations [31]. • Model Selection. Giv en that the capability required for the LLM to generate key points and scores is weaker than the complete answer generation process, we can choose a fine-tuned LLM model or a smaller model for different purposes to further reduce computation cost. Our algorithm is designed to be agnostic to model selection; we show ablations in Section 4.3. • Prompt and Hyperparameter Customization. The prompts used in different stages can be customized to further improv e per- formance under dif ferent use scenarios. In the generativ e search scenario, we can e ven adapti vely generate score standards based on the user’ s query and retrieved sources to further improve score fidelity . W e include the prompts for our implementation in Sec- tion A.1. T o ensure consistency across runs, we used T empera- ture=0 in our experiment. Algorithm 2: M A X S H A P L E Y ’ s Attribution Algorithm Input: A user query 𝑞 , a set of retriev ed information sources 𝑆 = { 𝑠 1 , . . . , 𝑠 𝑚 } , and the generated answer 𝑎 from the LLM. Output: Attribution score 𝜙 𝑖 for each information source 𝑠 𝑖 . 1 Giv en the query 𝑞 and the answer 𝑎 , generate 𝑛 key points 𝑃 = { 𝑝 1 , . . . , 𝑝 𝑛 } and their weights 𝑤 1 , . . . , 𝑤 𝑛 through the LLM. 2 for 𝑗 ∈ { 1 , 2 , . . . , 𝑛 } do 3 for 𝑖 ∈ { 1 , 2 , . . . , 𝑚 } do 4 Let 𝑣 𝑖 , 𝑗 be the relev ance score between 𝑠 𝑖 and 𝑝 𝑗 . 5 end 6 Compute the Shapley v alue 𝜙 Max 𝑖 , 𝑗 for each information source 𝑠 𝑖 based on the maximization game defined by the values { 𝑣 𝑖 , 𝑗 } 𝑖 ∈ [ 𝑚 ] using Algorithm 1. 7 end 8 Let 𝜙 𝑖 = Í 𝑛 𝑗 = 1 𝑤 𝑗 𝜙 Max 𝑖 , 𝑗 be the final attribution score for each information source 𝑠 𝑖 . 9 retur n { 𝜙 𝑖 } 𝑖 ∈ [ 𝑚 ] 4 Empirical Evaluation 4.1 Evaluation Setup In experiments, we aim to e valuate M A X S H A P L E Y in terms of (a) quality of attribution, and (b) ef ficiency of the algorithm. Baselines. W e compare to the baselines introduced in Section 2, including FullShapley , LOO , MCU , MCA , and KernelSHAP . W e gav e our baselines’ Judge function access to a ground truth response ˜ 𝑎 (Prompt in Section A.1). Metrics. T o compare cost fairly across LLMs, we primarily ev al- uate token consumption , i.e., the number of input tok ens gi ven to Φ 𝐴 during attribution. W e also e valuate av erage dollar (USD) cost per attribution, and end-to-end runtime in Figure 8. W e use the follo w- ing metrics to measure utility—agreement with FullShaple y and/or ground truth relev ance labels: • Jaccard@ 𝐾 between the ground truth rele v ance labels for each document (see Datasets below) and the top- 𝐾 elements of the M A X S H A P L E Y vector . Let 𝑅 be the ground truth relev ant sources for a query (as annotated in a dataset) and let 𝐾 = | 𝑅 | . Let 𝑇 = T op 𝐾 ( ˆ 𝝓 ) . Jaccard@ 𝐾 = | 𝑇 ∩ 𝑅 | | 𝑇 ∪ 𝑅 | . Jaccard@K ∈ [ 0 , 1 ] with 1.0 indicating perfect agreement between sets (higher is better). • Kendall’ s 𝜏 𝑏 [ 40 ] between the M A X S H A P L E Y and FullShapley vectors. Ordinal agreement between rankings induced by ˆ 𝝓 and 𝝓 ★ ; 𝜏 𝑏 ∈ [ − 1 , 1 ] with 0.0 indicating no ordinal correlation and 1.0 indicating perfect correlation (higher is better). Datasets. W e ev aluate on three multi-hop question answering datasets: • HotpotQA [ 91 ]: Full-wiki setting requiring retrie val and reason- ing ov er multiple W ikipedia documents. • MuSiQUE [ 85 ]: Structured two-hop questions in full-wiki setting. • MS MARCO (TREC 2019,2020) [ 10 , 19 , 20 ]: Passage ranking with graded relev ance judgments from the TREC 2019 and 2020 Deep Learning T rack. Annotation. Although these datasets are already labeled, we found that many of the labels were noisy or inconsistent with human intu- ition. T o handle this, we ran focused e v aluations on three subsampled datasets of 30 queries per original dataset. 2 Each query in our subset has six candidate information sources, and we manually labeled per- source rele vance with tw o annotators. Annotation quality metrics are provided in Appendix A.3. W e intentionally included both relev ant and irrele vant sources among the six sources, selected according to the original (noisy) dataset annotations. W e have released this dataset, which may be of independent interest. All methods are ev alu- ated on these annotated subsets across 3 independent runs; we report means and standard errors. For completeness, we also conducted some experiments on the original, lar ger datasets. Evaluation Limitations. W e treat both FullShapley and manually- annotated relev ance as ground truth for attribution quality , although neither is perfect. As discussed in Section 4.2, LLM-as-a-judge exhibits scoring inconsistencies e ven at temperature 0, affecting all Shapley methods, including FullShaple y . Additionally , manually- annotated relevance measures a related b ut distinct concept from Shapley attribution. As we do not have a single ground truth, we measure association with both of these quantities. 4.2 Main Results Our experiments highlight two main findings: (1) M A X S H A P L E Y achie ves the best tradeoff between attrib ution quality ef ficiency by a significant mar gin. Figures 3 show how differ - ent methods trade of f token consumption for quality of attrib ution, as measured by Jaccard index with the ground truth and K endall’ s 𝜏 𝑏 with FullShapley . These results all use GPT -4.1o as the search and attribution LLM. M A X S H A P L E Y consistently outperforms LOO, 2 W e selected the first 30 question-and-answer pairs from each dataset, subject to our human annotators being able to make sense of the question. M A X S H A P L EY : T owards Incentive-compatib le Generative Search with Fair Context Attribution Conference’17, July 2017, Washington, DC, USA HotPotQA MS-MARCO MuSIQUE Figure 3: Quality of attribution (Jaccard index w .r .t. ground truth (top), Kendall 𝜏 𝑏 w .r .t. FullShapley (bottom)) versus token consumption for attribution algorithms on three datasets, using GPT -4.1o. M A X S H A P L E Y achiev es the same Jaccard index as Ker nelSHAP with the latter using 8-10 × more tokens. M A X S H A P L E Y reaches a str ong ordinal correlation via K endall’ s 𝜏 𝑏 with FullShapley for HotPotQA and MuSiQUE. On MS-MARCO, M A X S H A P L E Y r eaches a moderate ordinal correlation. For similar correlations with FullShapley , KernelSHAP consumes 3-11 × more tokens than M A X S H A P L E Y . MCU, MCA, and KernelSHAP across all datasets and metrics. K er- nelSHAP requires substantially more tokens than M A X S H A P L E Y , 8-10 × , to reach the same Jaccard index w .r .t. to ground truth annota- tions across all three datasets. Both Monte Carlo methods are e ven less efficient, requiring 17 × and 20 × respectively more tok ens than M A X S H A P L E Y to reach the same Jaccard index on MuSiQUE. For rank correlation measured by K endall’ s 𝜏 𝑏 (Figure 3, bottom), M A X S H A P L E Y achiev es a strong ordinal correlation with FullShap- ley on MuSiQ UE and HotPotQA, while KernelSHAP requires 8-11 × more tokens to reach the same correlation quality . On MS MARCO, M A X S H A P L E Y achiev es a moderate correlation with KernelSHAP achieving the same with 3 × more tokens. Note that while there is no standard way to interpret the quality of a 𝜏 𝑏 correlation, we fol- low [ 89 ], using >=0.49 to indicate a strong correlation, >=0.26 for moderate correlation, and <0.26 for weak or negligible correlation. On MS-MARCO, we observe a degradation in the quality of attribution across all Shapley attrib ution methods. The Jaccard index scores for all methods are notably smaller and M A X S H A P L E Y (as well as all other approximation methods) only achieves at most a moderate ordinal correlation with FullShapley . MS-MARCO, unlike HotPotQA and MuSiQUE, is a less curated dataset, with sometimes confusing information source content (e ven for humans). As such, the Search LLM had more trouble forming coherent and correct responses to queries with a giv en set of information sources. Note that in Figure 3, M A X S H A P L E Y has a higher Jaccard in- dex with the ground truth than FullShapley on HotPotQA and MS- MARCO. W e attribute this to the fact that the attribution LLM produces token-level variations in semantically similar responses, affecting do wnstream attribution (see belo w). W e noted the same trend if we compute cost in terms of computa- tion time or monetary cost-per -query , rather than tokens-per-query . These results are included in Section B, along with results on the full, original MuSiQUE dataset. (2) Sensitivity introduced by the LLM-as-a-judge substantially affects its attrib ution quality . LLM-as-a-judge exhibits scoring in- consistencies we belie ve arise from sensiti vity to semantically equiv- alent input variations. W e identified pairs of semantically equiv alent inputs that should yield the same v alue function score b ut dif fered in tokenization (e.g., T able 1). W e conducted 10 runs comparing the Judge ’ s numeric scores for these input pairs. These experiments rev ealed tw o key findings: first, subtle token-level changes mean- ingfully affected v alue function scores; second, there was very little randomness in these results. This is mostly expected since our ex- periments are all run with temperature=0. This pattern aligns with findings from previous studies on LLM consistenc y [ 48 , 75 ], suggest- ing that while LLMs are sensitiv e to input formulation (e.g., source ordering, context length), the y maintain reasonable stability when giv en truly identical inputs. Howe ver , Judge inconsistencies still exist because of input variations originating from the LLM response generation stage. Even with identical prompts, information sources, and temperature=0, LLM-generated responses exhibit minor div er- gences that propagate to the J udge . Prior work on output stability similarly reports that temperature=0 does not ensure determinism, Conference’17, July 2017, Washington, DC, USA Sara Patel ∗† , Mingxun Zhou ∗§† , Giulia Fanti ∗ though structured or parsed outputs, like the J udge ’ s numeric scores, tend to display greater consistency than free-form te xt [8]. 4.3 Ablations W e conducted ablations on sev eral components of M A X S H A P L E Y and baselines. More details are provided in Appendix 4.3. Model Selection. For our attribution LLM, we e valuated GPT - 4.1o (OpenAI), Claude Haiku 3.5, and Claude Sonnet 4 (Anthropic), and conducted our main experiments using only the first two. Haiku 3.5 achiev ed notably higher attribution quality than GPT -4.1o with moderately increased token consumption and cost, b ut with a no- ticeable increase in execution time (see Appendix Y). W e excluded Sonnet 4 due to prompt incompatibility and higher cost (Appendix Y). Effect of Clipping . Despite setting temperature to 0, sev eral base- lines commonly receiv ed extremely low , but non-zero, attribution scores, which caused the baselines to order sources in arbitrary ways. T o mitigate this effect, we clip all attributions belo w 0.05 to remove negligible attrib utions from every baseline except M A X S H A PL E Y , which did suffer from this effect because it only selects the maximum relev ance. After clipping, we renormalize attributions to sum to 1.0. W e illustrate the effect of clipping on FullShapley in Appendix B. P ositional Bias. LLMs are known to exhibit positional bias, dis- proportionately attending to information at the beginning and end of conte xts [ 50 ]. This phenomenon poses a critical challenge for attribution methods. W e quantified this ef fect using Haiku 3.5 on the MuSiQUE dataset, which contains e xactly two rele vant sources per sample (each query is a two-hop question). W e compared two conditions: positioning the two rele v ant sources at the beginning of the context versus randomly shuf fling all sources. Fixed positioning at the beginning yields a 0.12 increase on a verage in Jaccard index with ground truth for M A X S H A P L E Y . W e mitigated this bias throughout our experiments by randomly shuffling source order before each LLM call. While this does not eliminate positional bias entirely , it ensures that no source systemati- cally benefits from fa vorable positioning. 5 Reward Allocation Mechanisms W e envision re ward allocation mechanisms ( M A X S H A P L E Y or oth- ers) could be used in various ways to compensate content pro viders. Dir ect P ayment based on F air Attribution. One straightforward application of M A X S H A P L E Y is to use the attributed values as a ratio to allocate a fixed budget to information providers based on their contributions to the final answers. This b udget can be funded by either the users (e.g. through a subscription fee) or the generative search providers (e.g. through a fraction of their o wn ads revenue). The direct payment mechanism is simple in its theoretical model and it indeed provides a fair compensation structure for information providers. Howev er, it might be challenging to implement in the LLM-based Internet search engine ecosystems, as it requires estab- lishing a payment channel between search providers and content providers; this may be feasible in domain-specific scenarios with limited content providers (e.g., academic publishers, ne ws sites). Such a payment channel requires significant b usiness ne gotiation and legal agreements among large number of parties. A suitable application scenario could be a domain-specific search engine where there are only a limited number of information providers (e.g. a corporate knowledge base, an academic publisher , etc), in which case the direct payment mechanism can be more easily implemented between the parties (e.g., [ 32 ]), while M A X S H A P L E Y serv es as a fair and transparent attrib ution mechanism to quantify the credits. Advertisement Pr oxy based on F air Attribution. Another possibil- ity is to use the generativ e search engine to forward advertisements to vie wers. That is, the generati ve search engine can detect the dis- played advertisement on the search result pages. Once the attributed values pro vided by M A X S H A P L E Y are obtained, search providers can use the attributed values either as a probability distribution or an auction bid to allocate the advertisement slots to information providers, then sho w the corresponding advertisements to the users. Hence, content providers can still earn advertisement re venue. This model is (relativ ely) more backwards compatible with today’ s web advertisement ecosystem. One potential do wnside is that advertise- ments displayed alongside LLM-generated answers may be less effecti ve than in their original form, on their own webpages. Ad Auction Mechanism based on M A X S H A P L E Y Attribution. Fi- nally , M A X S H A P L E Y could be combined with other auction-based mechanisms for advertisement allocation. Hajiaghayi et al. [ 34 ] pro- posed an auction-based mechanism for RAG, where each advertiser bids on the opportunity to influence the LLM-generated answer . In their paper, a key technique is to compute the “adjusted bids” for each adv ertiser based on their bid and also an “attribution score” that is assumed to be a vailabl e and linearly related to the click-through rate (CTR). The core of their mechanism is a probabilistic second- price auction based on the adjusted bids. M A X S H A P L E Y could be used to compute the attribution score for each advertiser based on their contribution to the LLM’ s answer . 6 Related W ork LLMs and Online Advertisement. LLMs are being increasingly used in online advertisement systems [25, 27, 51]. A gro wing body of work is exploring mechanism design and auction design for LLM- based advertisement systems [ 11 , 13 , 24 , 25 , 34 , 44 , 59 , 69 ]. Their setting, howe ver , is orthogonal to our w ork, as their focus is on the in- teraction between advertisers and the ad platform, where advertisers are typically bidding for user attention. Our setting instead focuses on the interaction between or ganic information providers (i.e. those that do not pay for inclusion in search queries) and RA G service providers (e.g. LLM-based search engines). In this setting, content providers passi vely provide information to the service provider and currently , they generally display ads from a third-party adv ertisement platform. The two settings are complementary , where fair attribution scores from M A X S H A P L E Y can be used as a passiv e “bid” for in- formation providers to participate in auction-based advertisement systems. Recent works ha ve taken the alternati ve approach of generati ve engine optimization (GEO), which optimizes web content for gen- erativ e engines [ 2 , 15 ]. This could help content providers appear in search results (possibly including citations with links to their web- sites). While GEO is likely to become essential for many content M A X S H A P L EY : T owards Incentive-compatib le Generative Search with Fair Context Attribution Conference’17, July 2017, Washington, DC, USA Response Mean Quality Score Std. Dev Based on the provided sources, I can confidently state: Connie May Fo wler was definitely a memoirist. The source ’Connie May Fowler’ explicitly states that she wrote memoirs, specifically mentioning "When Katie W akes" (which explores her family’ s generational cycle of domestic violence) and "A Million Fragile Bones" (about her life on a barrier island and the Deepwater Horizon oil spill). 0.3 0.0 Based on the provided sources, I can confidently state: Connie May Fo wler was a memoirist. The source ’Connie May Fowler’ explicitly describes her as a "memoirist" and mentions two of her memoirs: "When Katie W akes" (which explores her family’ s generational cycle of domestic violence) and "A Million Fragile Bones" (about her life on a barrier island and the Deepwater Horizon BP oil spill) . 1.0 0.0 T able 1: The LLM-as-a-judge Judge ev aluation introduces sensiti vity to token-lev el variations in semantically equiv alent responses. Response 1 (top) was generated fr om f our rele vant sources. Response 2 (bottom) included one additional irr elevant source. Despite being semantically equivalent, the LLM-as-a-judge (Attribution LLM) assigned Judge scores of 1.0 and 0.3 (scale: 0.0-1.0). The consistent scoring across 10 runs suggests that the LLMs ar e sensitive to wording, but consistent for the same wording . providers, it may not fully address our problem of interest—lost advertising re venue from lo w click-through rates—since users ap- pear not to be clicking on sources to begin with. This could be exacerbated by the fact that LLM search citations are susceptible to manipulation [61]. Early ef forts to compensate content providers fall into two cate- gories. First, there exist some LLM-search engines that purport to compensate content providers, such as Gist [ 1 ] and O’Reilly An- swers [ 32 ]. At the time of writing, we do not kno w the details of how compensation is being allocated, and how that relates to the rele- vance of the content being pro vided to the query . Another interesting model is Cloudflare’ s pay-per-crawl tool [ 3 ], currently released in priv ate beta. It allows content providers to specify if they want to outright block AI crawlers; alternativ ely , they can require payment ev ery time a crawler accesses the provider’ s content. Attribution in Machine Learning. The attrib ution problem has been extensiv ely studied in the ML community . For training-time attribution, datamodels [ 37 ] and TRAK [ 67 ] learn a predictive model for the impact of each training data point on the tar get model’ s per- formance, while Data Shaple y [ 30 , 86 , 87 ] uses Shapley value to quantify the contrib ution of each training data point to a tar get model. At inference time, LIME [ 73 ] learns a local surrogate model to at- tribute model predictions to input features, while Kernel SHAP [ 53 ] computes Shapley value under a linear model of feature contribu- tions. Influence functions [ 43 ] instead trace attribution across the inference-training pipeline and attribute a model’ s prediction to a specific subset of training data. Such methods (including TracIn and variants [ 71 ]) require access to model weights and are not applicable to our setting, which assumes only black-box API access to search and attribution LLMs. F air attribution for Internet infr astructur e. Fair attribution, par - ticularly using Shapley v alues, has been widely studied in many contexts rele vant to the Internet. For example, sev eral works hav e studied ho w to allocate resources to Internet service providers (ISPs) and content providers [ 9 , 54 , 55 , 57 , 83 ], cloud stakeholders [ 39 , 79 ], and edge computing de vices [ 35 ] according to their Shaple y v alue. These methods typically manage the computational cost of Shapley value via Monte Carlo sampling or other simplification techniques. Our approach instead uses the structure of LLM search to propose a utility function that naturally can be computed in linear time, while also achieving high correlation with ground truth signals. 7 Conclusion This paper presents M A X S H A P L E Y , a novel and ef ficient algo- rithm for attributing the contributions of information sources in RA G-based generati ve search systems. Lev eraging an LLM-as-a- judge utility function and a decomposable max-sum formulation, M A X S H A P L E Y achiev es high attribution accurac y–demonstrated by a very strong ordinal correlation with a full Shaple y computation via Kendall’ s 𝜏 𝑏 and a Jaccard index abov e 0 . 9 with human annotations– while requiring only 7% of the computational cost of exhaustiv e Shapley v alue computation. Limitations and Futur e Directions. M A X S H A P L E Y has several limitations. First, LLM-as-a-judge methods (both M A X S H A P L E Y and all other baselines in this paper) are known to exhibit bias, fa- voring LLM-generated texts [ 66 ]. This could lead to AI-generated text being rew arded over human-generated content, which is counter - productiv e. This issue could potentially be mitigated with emergent techniques for improv ed LLM e v aluations [ 45 ], but the problem is far from being solv ed. Second, we have not considered rob ustness to adversarial agents. In practice, an adversarial content provider may attempt to game any rew ard attribution scheme without produc- ing quality content (for instance, by creating AI slop). Ideally , an attribution scheme should be rob ust to such low-quality content. In addition to addressing the above limitations, sev eral future directions remain. First, attribution via LLM can incur high latenc y (on the order of minutes for FullShapley) and cost (on the order of $1 for 15 data samples on Haiku 3.5). Moreover , these methods exhibit token sensiti vity in its scoring decisions. These issues impact all our baselines, including M A X S H A P L E Y and FullShapley; they are basic limitations of using LLMs for attribution. While M A X S HA P L E Y reduces these costs relative to baselines, it is unclear what costs will be acceptable in an LLM-search ecosystem. Second, our cur- rent method does not account for multiple sources corroborating the same key point, thereby increasing confidence in the answer . Third, M A X S H A P L E Y currently employs a flat structure for ke y point de- composition, which may be insufficient for more complex scenarios that require intricate reasoning. Lastly , while a temperature at 0 ensures near-deterministic outputs, it also suppresses e xploratory behavior , meaning that when the model errs, it tends to persist in that error rather than self-correct. Exploring these richer settings is an important direction for future work. Conference’17, July 2017, Washington, DC, USA Sara Patel ∗† , Mingxun Zhou ∗§† , Giulia Fanti ∗ Acknowledgments This work was supported in part by the National Science F oundation under grant CCF-2338772, as well as by the Initiative for Cryp- tocurrencies and Contracts (IC3) and the CyLab Secure Blockchain Initiativ e, together with their respective industry sponsors. References [1] Gist: AI monetization solutions. https://gist.ai/. [Online; accessed 2025-10-17]. [2] Pranjal Aggarwal, V ishvak Murahari, T anmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, and Ameet Deshpande. Geo: Generative engine optimization. In Pr oceedings of the 30th ACM SIGKDD Confer ence on Knowledge Discovery and Data Mining , pages 5–16, 2024. [3] W ill Allen and Simon Netwon. Introducing pay per crawl: Enabling content owners to char ge AI crawlers for access. https://blog.cloudflare.com/introducing- pay- per- crawl/, 7 2025. The Cloudflare Blog, [Online; accessed 2025-10-17]. [4] Bobby Allyn. Will Google’ s AI Overvie ws kill ne ws sites as we kno w them?, 7 2025. [Online; accessed 2025-12-04]. [5] Anthropic. Claude 3.5 Haiku, 2024. [6] Anthropic. Introducing Claude 4, 2025. [7] Anthropic. Pricing, 2025. [8] Berk Atil, Sarp A ykent, Alexa Chittams, Lisheng Fu, Rebecca J. Passonneau, Evan Radcliffe, Guru Rajan Rajagopal, Adam Sloan, T omasz Tudrej, Ferhan T ure, Zhe W u, Lixinyu Xu, and Breck Baldwin. Non-determinism of "deterministic" llm settings, 2025. [9] Donald Azuatalam, Archie Chapman, and Gre gor V erbi ˇ c. A T urvey-Shapley V alue Method for Distribution Netw ork Cost Allocation. In Australasian Universities P ower Engineering Conference . IEEE, 2024. [10] Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder , Andrew McNamara, Bhaskar Mitra, T ri Nguyen, Mir Rosen- berg, Xia Song, Alina Stoica, Saurabh T iwary , and T ong W ang. MS MARCO: A Human Generated MAchine Reading COmprehension Dataset, 2018. [11] Martino Banchio, Aranyak Mehta, and Andres Perlroth. Ads in conversations. arXiv pr eprint arXiv:2403.11022 , 2024. [12] Bartz v . Anthropic PBC, No. 69058235. U.S. District Court, Central District of California, 2024. [13] Dirk Bergemann, Marek Bojko, Paul Dütting, Renato Paes Leme, Haifeng Xu, and Song Zuo. Data-driven mechanism design: Jointly eliciting preferences and information. arXiv preprint , 2024. [14] Athena Chapekis and Anna Lieb. Google users are less likely to click on links when an AI summary appears in the results. [15] Mahe Chen, Xiaoxuan W ang, Kaiwen Chen, and Nick Koudas. Generative engine optimization: How to dominate ai search. arXiv preprint , 2025. [16] Y ung-Sung Chuang, Benjamin Cohen-W ang, Zejiang Shen, Zhaofeng W u, Hu Xu, Xi Victoria Lin, James R. Glass, Shang-W en Li, and W en tau Y ih. SelfCite: Self-Supervised Alignment for Context Attrib ution in Large Language Models. In ICML , 2025. [17] Benjamin Cohen-W ang, Y ung-Sung Chuang, and Aleksander Madry . Learning to attribute with attention, 2025. arXiv 2504.13752. [18] Benjamin Cohen-W ang, Harshay Shah, Kristian Georgiev , and Aleksander Madry . Contextcite: Attributing model generation to conte xt. NeurIPS , 37:95764–95807, 2024. [19] Nick Craswell, Bhaskar Mitra, Emine Y ilmaz, and Daniel Campos. Overvie w of the trec 2020 deep learning track, 2021. [20] Nick Craswell, Bhaskar Mitra, Emine Y ilmaz, Daniel Campos, and Ellen M. V oorhees. Overview of the trec 2019 deep learning track, 2020. [21] Cristina Criddle. Perplexity in talks with top brands on ads model as it challenges google. https://www .ft.com/content/ecf299f4- e0a9- 468b- af06- 8a94e5f0b1f4, 9 2024. [Online; accessed 2025-10-16]. [22] Google DeepMind. Google gemini: A multimodal ai model. Blog post / technical announcement, 2023. [23] Qiang Ding, Lvzhou Luo, Y ixuan Cao, and Ping Luo. Attention with dependency parsing augmentation for fine-grained attribution. , 2024. [24] A vinava Dubey , Zhe Feng, Rahul Kidambi, Aranyak Mehta, and Di W ang. Auc- tions with llm summaries. In SIGKDD . ACM, 2024. [25] Paul Duetting, V ahab Mirrokni, Renato Paes Leme, Haifeng Xu, and Song Zuo. Mechanism design for large language models. In Proceedings of the ACM W eb Confer ence 2024 , pages 144–155, 2024. [26] The Economist. Ai is killing the web . can anything sa ve it? https://www .economist. com/business/2025/07/14/ai- is- killing- the- web- can- anything- sav e- it, 2025. [27] Soheil Feizi, MohammadT aghi Hajiaghayi, K eiv an Rezaei, and Suho Shin. On- line advertisements with llms: Opportunities and challenges. arXiv preprint arXiv:2311.07601 , 2023. [28] Soheil Feizi, MohammadT aghi Hajiaghayi, Kei van Rezaei, and Suho Shin. Online advertisements with llms: Opportunities and challenges. 2024. [29] Kerry Flynn. Penske Media sues Google over AI summaries taking traffic. Axios , 9 2025. [Online; accessed 2025-10-18]. [30] Amirata Ghorbani and James Zou. Data shapley: Equitable valuation of data for machine learning. In ICML , 2019. [31] Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang T an, Xuehao Zhai, Chengjin Xu, W ei Li, Y inghan Shen, Shengjie Ma, Honghao Liu, Saizhuo W ang, Kun Zhang, Y uanzhuo W ang, W en Gao, Lionel Ni, and Jian Guo. A Survey on LLM-as-a- Judge, 2025. [32] Lucky Gunasekara, Andy Hsieh, Lan Le, and Julie Baron. The New O’Reilly An- swers: The R in “RA G" Stands for “Royalties". https://www .oreilly .com/radar/the- new- oreilly- answers- the- r- in- rag- stands- for- royalties/, 6 2024. [Online; accessed 2025-10-17]. [33] Kelvin Guu, K enton Lee, Zora Tung, Panupong P asupat, and Ming-W ei Chang. Realm: Retriev al-augmented language model pre-training, 2020. [34] MohammadT aghi Hajiaghayi, Sébastien Lahaie, Kei van Rezaei, and Suho Shin. Ad auctions for llms via retrieval augmented generation. NeurIPS , 37:18445– 18480, 2024. [35] Xingqiu He, Xiong W ang, Sheng W ang, Shizhong Xu, Jing Ren, Ci He, and Y asheng Zhang. A shapley value-based incenti ve mechanism in collaborative edge computing. In GLOBECOM . IEEE, 2021. [36] Eran Hirsch, A viv Slobodkin, David W an, Elias Stengel-Eskin, Mohit Bansal, and Ido Dagan. Laquer: Localized attribution queries in content-grounded generation. arXiv pr eprint arXiv:2506.01187 , 2025. [37] Andrew Ilyas, Sung Min Park, Logan Engstrom, Guillaume Leclerc, and Alek- sander Madry . Datamodels: Understanding predictions with data and data with predictions. In ICML . PMLR, 2022. [38] Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Y u, Armand Joulin, Sebastian Riedel, and Edouard Grav e. Atlas: Few-shot learning with retrie val augmented language models, 2022. [39] W eixiang Jiang, Fangming Liu, Guoming T ang, Kui Wu, and Hai Jin. Virtual machine power accounting with shaple y value. In ICDCS , 2017. [40] M. G. Kendall. A new measure of rank correlation. Biometrika , 30(1/2):81–93, 1938. [41] Omar Khattab and Matei Zaharia. Colbert: Efficient and effecti ve passage search via contextualized late interaction ov er bert. In SIGIR , 2020. [42] Donal Khosrowi, Finola Finn, and Elinor Clark. Engaging the many-hands prob- lem of generativ e-ai outputs: A framew ork for attributing credit. AI and Ethics , 2024. [43] Pang W ei Koh and Percy Liang. Understanding black-box predictions via influence functions. In ICML , pages 1885–1894, 2017. [44] Poet Larsen and Davide Proserpio. The impact of llms on sponsored search: Evidence from google’ s bert. USC Marshall School of Business Resear ch P aper Sponsor ed by iORB , 2025. [45] Chungpa Lee, Thomas Zeng, Jongwon Jeong, Jy-yong Sohn, and Kangwook Lee. How to correctly report llm-as-a-judge ev aluations. arXiv pr eprint arXiv:2511.21140 , 2025. [46] Jeongsoo Lee, Daeyong Kw on, and Kyohoon Jin. Grade: Generating multi-hop qa and fine-grained difficulty matrix for rag e valuation, 2025. [47] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich KÃijttler, Mike Lewis, W en tau Y ih, Tim Rock- tÃd ’schel, Sebastian Riedel, and Douwe Kiela. Retriev al-augmented generation for knowledge-intensi ve nlp tasks, 2021. [48] W eiran Lin, Anna Gerchanovsky , Omer Akgul, Lujo Bauer, Matt Fredrikson, and Zifan W ang. Llm whisperer: An inconspicuous attack to bias llm responses, 2025. [49] Fengyuan Liu, Nikhil Kandpal, and Colin Raffel. Attribot: A bag of tricks for efficiently approximating lea ve-one-out conte xt attribution. In ICLR , 2025. [50] Nelson F . Liu, Ke vin Lin, John Hewitt, Ashwin Paranjape, Michele Be vilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts, 2023. [51] T ongtong Liu, Zhaohui W ang, Meiyue Qin, Zenghui Lu, Xudong Chen, Y uekui Y ang, and Peng Shu. Real-time ad retrieval via llm-generative commercial inten- tion for sponsored search advertising. arXiv preprint , 2025. [52] Y ang Liu, Dan Iter, Y ichong Xu, Shuohang W ang, Ruochen Xu, and Chenguang Zhu. G-eval: Nlg e valuation using gpt-4 with better human alignment, 2023. [53] Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. NeurIPS , 30, 2017. [54] Richard T . B. Ma, Dah ming Chiu, John C. S. Lui, V ishal Misra, and Dan Ruben- stein. Internet economics: the use of shapley value for isp settlement. In CoNEXT . A CM, 2007. [55] Richard TB Ma, Dah-ming Chiu, John CS Lui, V ishal Misra, and Dan Rubenstein. On cooperative settlement between content, transit and eyeball internet service providers. In CoNEXT , 2008. [56] T omasz P Michalak, Karthik V Aadithya, Piotr L Szczepanski, Balaraman Ravin- dran, and Nicholas R Jennings. Efficient computation of the shapley value for game-theoretic network centrality . Journal of Artificial Intelligence Research , 46:607–650, 2013. M A X S H A P L EY : T owards Incentive-compatib le Generative Search with Fair Context Attribution Conference’17, July 2017, Washington, DC, USA [57] V ishal Misra, Stratis Ioannidis, Augustin Chaintreau, and Laurent Massoulié. In- centivizing peer -assisted services: A fluid shapley value approach. SIGMETRICS , 2010. [58] Rory Mitchell, Joshua Cooper, Eibe Frank, and Geoffrey Holmes. Sampling permutations for shapley value estimation. Journal of Machine Learning Resear ch , 23(43):1–46, 2022. [59] T ommy Mordo, Moshe T ennenholtz, and Oren Kurland. Sponsored question answering. In Proceedings of the 2024 A CM SIGIR International Conference on Theory of Information Retrieval , pages 167–173, 2024. [60] Ikhtiyor Nematov , T arik Kalai, Elizaveta K uzmenko, Gabriele Fug agnoli, Dimitris Sacharidis, Katja Hose, and T omer Sagi. Source attrib ution in retrie val-augmented generation. arXiv preprint , 2025. [61] Fredrik Nestaas, Edoardo Debenedetti, and Florian Tramèr . Adv ersarial search engine optimization for large language models. arXiv preprint , 2024. [62] Jordan Novet and Jennifer Elias. Chegg sues Google for hurting traffic as it considers alternativ es. 2 2025. [Online; accessed 2025-10-18]. [63] OpenAI. Introducing GPT-4.1 in the API, 2025. [64] OpenAI. Pricing, 2025. [65] Originality .AI. Llm visibility: Ai search statistics, 2025. [66] Arjun Panickssery , Samuel Bowman, and Shi Feng. Llm evaluators recognize and fav or their own generations. Advances in Neural Information Pr ocessing Systems , 37:68772–68802, 2024. [67] Sung Min Park, Kristian Geor giev , Andrew Ilyas, Guillaume Leclerc, and Alek- sander Madry . TRAK: Attributing model behavior at scale. In ICML , 2023. [68] Sarah Perez. News publisher files class action antitrust suit against Google, citing AI’ s harms to their bottom line, 12 2023. [Online; accessed 2025-10-18]. [69] Inc. Perplexity AI. Perplexity ai: Answer engine. W ebsite / Service, 2022. [70] The Associated Press. Anthropic to pay $1.5 billion to settle authors’ copyright lawsuit, 2025. [71] Garima Pruthi, Frederick Liu, Satyen Kale, and Mukund Sundararajan. Esti- mating training data influence by tracing gradient descent. Advances in Neural Information Pr ocessing Systems , 33:19920–19930, 2020. [72] Jirui Qi, Gabriele Sarti, Raquel Fernà ˛ andez, and Arianna Bisazza. Model internals- based answer attribution for trustworthy retriev al-augmented generation. In EMNLP . A CL, 2024. [73] Marco T ulio Ribeiro, Sameer Singh, and Carlos Guestrin. “why should i trust you?” explaining the predictions of any classifier . In SIGKDD . ACM, 2016. [74] T om Ritchie. Ai overviews: Ho w are publishers adapting to the rise of clickless search?, 2025. [75] Abel Salinas and Fred Morstatter . The butterfly ef fect of altering prompts: Ho w small changes and jailbreaks affect lar ge language model performance, 2024. [76] Kesha v Santhanam, Omar Khattab, Jon Saad-Falcon, Christopher Potts, and Matei Zaharia. Colbertv2: Effecti ve and efficient retriev al via lightweight late interaction. arXiv pr eprint arXiv:2112.01488 , 2021. [77] Lloyd S Shapley . A value for n-person games. In Contributions to the theory of games , volume 2, pages 307–317. Princeton Uni versity Press, 1953. [78] Lloyd S Shapley et al. A value for n-person games . Princeton Uni versity Press Princeton, 1953. [79] W eijie Shi, Chuan W u, and Zongpeng Li. A shapley-v alue mechanism for band- width on demand between datacenters. IEEE Tr ansactions on Cloud Computing , 6(1):19–32, 2015. [80] SimilarW eb . https://www.similarweb .com/, 2025. [81] Natasha Sommerfeld. Consumer reliance on ai search results signals new era of marketing. Bain & Company . [Online; accessed 2025-10-18]. [82] Natasha Sommerfeld, Megan McCurry , and Doug Harrington. Goodbye Clicks, Hello AI: Zero-Click Search Redefines Marketing. Bain & Company , 2 2025. [Online; accessed 2025-12-04]. [83] Rade Stanojevic, Nik olaos Laoutaris, and Pablo Rodriguez. On economic heavy hitters: Shapley v alue analysis of 95th-percentile pricing. In Pr oceedings of the 10th ACM SIGCOMM confer ence on Internet measurement , pages 75–80, 2010. [84] The Ne w Y ork T imes Compan y v . Microsoft Corporation et al. No. 1:23-cv-11195, U.S. District Court, Southern District of New Y ork, 2023. [85] Harsh T riv edi, Niranjan Balasubramanian, T ushar Khot, and Ashish Sabharwal. Musique: Multihop questions via single-hop question composition, 2022. [86] Jiachen T W ang, Zhun Deng, Hiroaki Chiba-Okabe, Boaz Barak, and W eijie J Su. An economic solution to copyright challenges of generative ai. arXiv preprint arXiv:2404.13964 , 2024. [87] Jiachen T . W ang, Prateek Mittal, Dawn Song, and Ruoxi Jia. Data shapley in one training run. In ICLR , 2025. [88] Y anting W ang, W ei Zou, Runpeng Geng, and Jinyuan Jia. Tracllm: A generic framework for attrib uting long context llms, 2025. [89] Rick Wicklin. How to interpret spearman and Kendall correlation coefficients. The DO Loop Blog, SAS Institute, April 2023. [90] Y ingtai Xiao, Y uqing Zhu, Sirat Samyoun, W anrong Zhang, Jiachen T . W ang, and Jian Du. T okenshapley: T oken lev el context attrib ution with shapley v alue, 2025. [91] Zhilin Y ang, Peng Qi, Saizheng Zhang, Y oshua Bengi o, William W . Cohen, Ruslan Salakhutdinov , and Christopher D. Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering, 2018. [92] Robbin Lee Zeff and Bradle y Aronson. Advertising on the Internet . John Wile y & Sons, Inc., 1999. [93] Lianmin Zheng, W ei-Lin Chiang, Y ing Sheng, Siyuan Zhuang, Zhanghao Wu, Y onghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P . Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023. A ppendix A Experimental Setup A.1 LLM Prompts In LLM-as-a-judge, we use the Attribution LLM (Figure 2) to com- pute the Judge function, using both GPT -4.1o and Haiku 3.5. The LLM Ψ 𝐴 receiv es a query , an LLM-generated response, a subset of the information sources, and, if the ground truth is av ailable, the ground truth to the answer, then produces a score indicating ho w well that coalition answers the query . W e designed our prompts to elicit reliable quality assessments while pre venting knowledge hallucination–ensuring the model relies solely on pro vided sources rather than its parametric kno wledge. Scores range from 0.0 to 1.0, where 1.0 indicates a perfect answer addressing all parts of the ques- tion, and 0.0 indicates an incorrect or unsupported answer . The full prompt is provided in Figure 4; we pro vide ground truth only to FullShapley and approximation baselines. For M A X S H A P L E Y , in addition to the basic LLM-generated re- sponse prompt for answering the query with a set of information sources, we used an LLM to break the response down into k ey points, then to "distill" these key points (filtering out repetitive or redun- dant key points), and then ask ed the LLM to rank each information source in terms of rele v ance to each ke y point, which serves as our value function for M A X S H A P L E Y . W e include the full version of the keypoint breakdo wn prompt in Figure 5, the distillation prompt in Figure 7, and the relev ancy scoring in Figure 6. A.2 Baseline Pseudocode Here, we provide the pseudocode for the baselines that we used in the experiments. In Algorithm 3, we include the brute-force algo- rithm for computing Shapley value. While there exist more ef ficient approximations to the Shapley value, the exact computation is known to hav e exponential comple xity . Next, we pro vide pseudocode for the Monte Carlo Approximation of Shapley V alue via Sampling, in Algorithm 4. A.3 Dataset Annotation W e independently annotated a subset of 30 queries and their informa- tion sources, then discussed to reach consensus on our annotations. Our inter-rater reliability before discussion was 94% agreement for HotPotQA and MS-MARCO, and 100% agreement for MuSiQUE. Figure 9 sho ws the cumulativ e distribution functions of Jaccard in- dex scores measuring agreement between our consensus annotations and the original dataset annotations for HotPotQA and MS-MARCO. The Jaccard index quantifies the ov erlap between the sets of sources labeled as rele vant. HotPotQA and MuSiQUE hav e binary anno- tations. For MS-MARCO, which uses a 0-3 relevance scale, we considered sources with scores of 2 or 3 as relev ant. W e had high Conference’17, July 2017, Washington, DC, USA Sara Patel ∗† , Mingxun Zhou ∗§† , Giulia Fanti ∗ You are an evaluation system that compares and evaluates AI responses to a question. If you are given the correct answer along with a question (the 'ground truth'), you must COMPLETELY IGNORE your own knowledge and beliefs about what is factually correct in the real world. The goal is to determine if the response is correct and well-founded. CRITICAL RULES: The ground truth provided is the ONLY correct answer â ˘ A ˇ T treat it as absolute truth. However, if the ground truth is not provided (if it's an empty string), then judge the accuracy of the answer based on your own knowledge. Accept semantically equivalent answers, not just exact word matches. Extra information in the AI response is fine as long as it contains the ground truth meaning. Do NOT fact-check the AI response against your own knowledge. EVALUATION FOCUS: Judge the AI's final answer/conclusion and how it got to its conclusion. Correct answers built upon evidence are better than correct guesses. Reasonable inference and pulling together well-founded pieces of information is good. It's crucial to consider what the question is asking as well. It's also CRUCIAL to remember that the ground truth is not a full and complete response; it is just the correct answer with which accuracy should be checked. SCORING PHILOSOPHY: Focus on whether the AI response's final conclusion provides the correct information with a factual basis and reasonable inference. A perfect response should (1) answer the question correctly and (2) be based on confirmed information. The journey from the question to the answer should be based on information that is confirmed or evident based on confirmed information (reasonable inferences). A full and complete response considers the question and what information the question requires us to know. The AI response will acknowledge how much of the question it can answer at the beginning of its response. Penalize for: Providing factually incorrect information that contradicts the ground truth Failing to provide any relevant answer Conditional answers ("If we assume X, then Y") â ˘ A ˇ T these show an unfounded basis (an answer based on unconfirmed information) Any indication that the response is conditional or based on unconfirmed information Additional information is okay as long as the response also answers the question. Remember that the AI response doesn't know what you're looking for; it just answers the question in the best way it knows how. A response focusing on specificity or a lack of specificity is also okay (the AI response may not know how specific of an answer the ground truth is). Score: Does the AI response fully address the question and convey the same meaning as the ground truth with confirmed information? Does the AI response fully address the question and convey the same meaning as "{ground_truth}" with confirmed information? 1.0 means a perfect answer that addresses all parts of the question and is based on confirmed information and reasonable inference. 0.7 means an almost-perfect answer, addressing most of the question, missing a very small part of the answer, or using a very small amount of unconfirmed information to reach its answer (very small means less than half). 0.5 means a partial answer, addressing only half the question, containing half the answer, or using half unconfirmed information. 0.3 means a partial answer, addressing only a small part of the question, containing less than half the answer, significant unreasonable inference, or based on mostly unconfirmed information. 0.0 means incorrect, no answer, not addressing any parts of the question, all unreasonable inference, or relying on information that is entirely unconfirmed. Judge on this scale, from 0.0 to 1.0. Figure 4: Full LLM-as-a-judge pr ompt, FullShapley and approx- imation algorithms. You are a document analysis system designed to extract the facts that inform a response to a question. YOUR PURPOSE: You should identify the information behind the reasoning of the response. Use how the response answers the question to create the key points. The response is built upon pieces of information pulled together. Your job is to turn each piece of information into a key point. KEY POINT RULES: Show how the response gets from the question to its answer step-by -step. Start with the question and analyze the response. What information is needed to answer the question, and how does the response demonstrate it? Focus on facts and statements that appear in the response or are clearly implied by it. Do NOT restate the question as a key point. Do NOT describe that connections exist â ˘ A ˇ T just state the facts in the response that create the connection. Avoid meta-commentary about the reasoning process itself. Keep key points small. Do not compound them. Each key point should be a single fact or a single step in the process of answering the question in the response. Do not use outside knowledge. Work only with what is in the response (and what is directly implied by it). Figure 5: Full M A X S H A P L E Y keypoint breakdown pr ompt. You are evaluating whether a source document provides substantive informational support for a specific statement. CRITICAL: Being on the same topic is not sufficient. The source must contain specific information that directly supports the statement's claims. Semantic equivalence or clear logical entailment is allowed. Reasonable and clear interpretation is also allowed â ˘ A ˇ T for example, if the statement refers to rectangles and the source refers to squares, that counts as support since the claim logically applies. SCORING SCALE (0.0 to 1.0): 0.0 = No Support: Source lacks information to support the statement, even if on the same topic. 0.3 = Minimal Support: Source has some relevant information but is missing key details. 0.7 = Substantial Support: Source contains most of the information needed, with only minor gaps. 1.0 = Complete Support: Source explicitly contains all information required to support the statement. KEY RULE: Only score based on substantive informational support, not topical similarity. Statements about what is not mentioned should score 0.0. Figure 6: Full keypoint r elev ance scoring prompt, M A X S H A P - L E Y . agreement with annotations for HotPotQA while MS-MARCO has moderate agreemnt. For MuSiQ UE, our consensus annotations had perfect agreement (Jaccard index of 1.0) with the dataset labels across all 30 samples. B Ablations Model Selection. W e ev aluated three large language models for suitability , GPT -4.1o (OpenAI [ 63 ]), Claude Haiku 3.5, and Claude Sonnet 4 (Anthropic [ 5 , 6 ]), but conducted our main experiments us- ing only the first two. As expected, attribution quality improved with model capability: Claude Haiku 3.5 achieved notably higher qual- ity scores than GPT -4.1o at comparable token consumption levels across all Shapley algorithms (Figure 8). Ho we ver , the progression from Haiku 3.5 to Sonnet 4 de viated from this trend. While Sonnet 4 M A X S H A P L EY : T owards Incentive-compatib le Generative Search with Fair Context Attribution Conference’17, July 2017, Washington, DC, USA You are a keypoint editor. You will receive a set of keypoints ( facts or reasoning steps). Your job is to refine them so they contain only the information necessary to answer the question. YOUR OBJECTIVE Produce a minimal set of keypoints where: - each keypoint expresses exactly one reasoning step or fact, - nothing irrelevant remains, - nothing essential to answering the question is removed, - keypoints are not merged or restructured. RULES 1. Preserve all information that directly supports answering the question. Do NOT remove anything that is required for correctness. 2. Remove redundant, repetitive, overly specific, or unhelpful details. 3. Generalize details unless their specificity is required to answer the question. 4. Do not combine keypoints. Keep each reasoning step separate. 5. Exclude: - statements about missing/insufficient information, - meta-comments, procedural notes, or analysis about the process. OUTPUT FORMAT REASONING: Explain briefly what you removed or generalized, and why. REFINED KEYPOINTS: One line per refined keypoint. Leave blank if none remain except lack-of-information statements. Figure 7: K eypoint distillation prompt, M A X S H A P L E Y . Algorithm 3: Full Shapley Input: A value function 𝑉 ( ·) and a set of 𝑚 elements (e.g., information sources) 𝑆 = { 𝑠 1 , 𝑠 2 , . . . , 𝑠 𝑚 } . Output: Shapley v alues 𝜙 𝑖 for each 𝑖 ∈ { 1 , . . . , 𝑚 } . 1 Initialize 𝜙 𝑖 ← 0 for all 𝑖 ∈ { 1 , . . . , 𝑚 } . 2 for 𝑖 ∈ { 1 , . . . , 𝑚 } do 3 for 𝑗 ∈ { 0 , . . . , 𝑚 − 1 } do 4 Let T 𝑗 be all subsets of size 𝑗 from { 1 , . . . , 𝑚 } \ { 𝑖 } . 5 for each 𝑇 ∈ T 𝑗 do 6 𝑇 ′ ← 𝑇 ∪ { 𝑖 } ; // Add element 𝑖 into subset 𝑇 7 𝑣 with ← 𝑉 ( 𝑇 ′ ) 8 𝑣 without ← 𝑉 ( 𝑇 ) 9 Δ ← 𝑣 with − 𝑣 without ; // Marginal contribution of source 𝑖 10 𝜙 𝑖 ← 𝜙 𝑖 + Δ 𝑚 − 1 𝑗 · 𝑚 11 end 12 end 13 end 14 retur n { 𝜙 𝑖 } 𝑖 ∈ [ 𝑚 ] demonstrated greater tok en ef ficiency , it did not yield the anticipated improv ement in attribution quality . In vestigation rev ealed that our prompts, optimized for GPT -4.1o and Haiku 3.5, pro ved o verly restrictiv e for Sonnet 4. Specifically , instructions designed to prev ent knowledge hallucination (e.g., di- recting the model not to fill knowledge gaps when sources cannot Algorithm 4: Monte-Carlo Approximation of Shapley V al- ues via Sampling Input: A value function 𝑉 ( · ) , number of information sources 𝑚 , and sample size 𝑛 . Output: Approximated Shapley v alues 𝜙 𝑖 for each 𝑖 ∈ { 1 , . . . , 𝑚 } . 1 Initialize 𝜙 𝑖 ← 0 for all 𝑖 ∈ { 1 , . . . , 𝑚 } . 2 Let 𝑣 ∅ ← 𝑉 ( ∅ ) ; // Value of the empty coalition 3 for 𝑟 = 1 to 𝑛 do 4 Sample a random permutation 𝜋 of { 1 , . . . , 𝑚 } from the uniform distribution. 5 Initialize 𝑇 ← ∅ , 𝑣 prev ← 𝑣 ∅ 6 for 𝑖 in 𝜋 do 7 Let 𝑇 ′ ← 𝑇 ∪ { 𝑖 } 8 𝑣 new ← 𝑉 ( 𝑇 ′ ) 9 Δ ← 𝑣 new − 𝑣 prev ; // Marginal contributions 10 Update 𝑇 ← 𝑇 ′ , 𝑣 prev ← 𝑣 new 11 end 12 end 13 retur n { 𝜙 𝑖 } 𝑖 ∈ [ 𝑚 ] answer the query) were interpreted too strictly by Sonnet 4, caus- ing it to refuse answering even when sources contained sufficient information. This suggests that prompt engineering requires model- specific calibration. More critically , Sonnet 4’ s higher cost–an order of magnitude greater than both GPT -4.1o and Haiku 3.5 (Figure 8)–combined with the extensiv e prompt re-engineering required, led us to exclude it from our main e xperiments. Between GPT -4.1o and Haiku 3.5, the tw o models used in our main experiments, cost dif ferences were modest (Figure 8). Howe ver , GPT -4.1o proved an order of magnitude faster per sample (Figure 8). While API latency af fects these measurements, the consistency of this dif ference suggests genuine ef ficiency advantages for time- sensitiv e applications. Clipping. When comparing all attribution scores to ground truth relev ance labels via Jaccard index, clipping has a minimal effect, with the largest dif ference being a 0.05 increase for FullShapley on HotPotQA with GPT -4.1o. Ho wever , clipping substantially improv es Kendall 𝜏 𝑏 ordinal correlation scores. Extremely small non-zero attri- bution scores (e.g., <0.001) introduce noise into ordinal correlation calculations by being treated as distinct ranked values rather than ties. Clipping eliminates this noise by setting near-zero attrib utions to exactly zero, resulting in clearer ordinal relationships. The most significant improvement w as with MuSiQUE with Haiku 3.5, where the ordinal correlation between M A X S H A P L E Y and FullShapley increased by 0.113 with clipping applied. Caching . W e used caching in our baseline implementations to im- prov e efficienc y . For both FullShapley and the approximation base- lines, we cached tested coalitions of sources and reused their LLM- as-a-judge scores upon cache hits to reduce costly LLM API calls. Conference’17, July 2017, Washington, DC, USA Sara Patel ∗† , Mingxun Zhou ∗§† , Giulia Fanti ∗ MuSiQUE HotPotQA MS-MARCO Figure 8: J accard index versus token consumption (top), computation time (center), and USD cost per query (bottom) acr oss LLM models and tw o Shapley algorithms. Haiku 3.5 generally outperforms GPT -4.1o in quality but incurs higher token consumption, computation costs, and computation time–effects that are more pronounced for FullShapley than for M A X S H A P L E Y . Sonnet 4’s increased capabilities, costs, and computation time do not translate into quality impro vements. Costs wer e calculated from input and output token consumption using OpenAI and Anthr opic’ s API documentation [7, 64]. In FullShapley , caching was applied to sorted coalitions of sources– unlike the unsorted caching used in the approximation algorithms– which reduced redundant e valuations and required fe wer coalition tests ov erall. This design choice improv ed cost and time efficiency: in an experiment with MuSiQUE, Haiku 3.5, and 10 data samples, unsorted caching resulted in a 3 × increase in token consumption, runtime, and therefore cost. Experiments on Lar ge Datasets. W e conducted M A X S H A P L E Y on the full MuSiQUE and HotPotQA dev datasets, and the MS- MARCO passages dataset with TREC 2019/2020 annotated datasets with GPT -4.1o, restricting our analysis to answerable queries (i.e., queries for which the pro vided information sources contain sufficient information to generate an answer). Figure 10 shows the cumulativ e distribution of Jaccard inde x scores across all 2,417 data samples for MuSiQUE, 7,405 data samples for HotPotQA, and a combined 96 data samples for MS-MARCO. W e observe a similar pattern to the agreement with our manually-annotated dataset, with more noise in the HotPotQA and MS-MARCO full datasets (this is expected, as we noted the original datasets often had noisy annotations, hence why we manually re-annotated a subset). W e observe a slightly noisier Jaccard inde x on the full MuSiQUE dataset, relativ e to our man- ually annotated subset. Although our manual annotations aligned completely with the original dataset labels, our annotated subset consisted primarily of 2-hop reasoning questions. When we e valu- ated the full MuSiQUE dataset, it also included 3-hop, 4-hop, and 5-hop questions, for which we observed a degradation in the a verage Jaccard index. This trend is consistent with prior observ ations that LLMs may exhibit reduced performance as the required reasoning depth increases [ 46 ], although our experiment does not isolate the specific source of this degradation. Nonetheless, the av erage Jaccard index for the full MuSiQUE de velopment set remains ≥ 0 . 70 . M A X S H A P L EY : T owards Incentive-compatib le Generative Search with Fair Context Attribution Conference’17, July 2017, Washington, DC, USA HotPotQA MS-MARCO Figure 9: Cumulative distribution functions of Jaccard index scores measuring the overlap between rele vant information source sets identified by our consensus annotations and those specified in the original dataset annotations. Jaccard indices were computed f or all 30 samples in our annotation subset for each dataset (HotPotQA, MS-MARCO). HotPotQA exhibits high agreement, with mor e than half the samples achieving per - fect agreement. MS-MARCO shows about 30% are in perfect agreement. MuSiQUE HotPotQA MS-MARCO Figure 10: Cumulativ e distrib ution function of Jaccard in- dex scores between rele vant information sources identified by M A X S H A P L E Y and ground truth annotations from the full MuSiQUE answerable dataset (2,417 samples), HotPotQA dev dataset (7,405 samples), and MS-MARCO passages dataset with TREC 2019/2020 rele vancy annotations (96 samples) with GPT - 4.1o. The annotated data set results (on 30 data samples) are also depicted for comparison. Impact of K e ypoint Decomposition. In our current implementa- tion of keypoint decomposition, our prompt has a “keypoint dis- tillation" component, which filters out repetiti ve or redundant key- points. T o test the robustness of M A X S H A P L E Y with different ke y- point decomposition methodologies, we test M A X S H A P L E Y on our manually-annotated datasets with GPT -4.1o using the prompt from Figure 5 without the distillation component from Figure 7. The av erage Jaccard index changes by 0.02-0.13 across datasets. On MuSiQUE (Figure 11), our results improve due to no distilla- tion (0.13 increase). Howe ver , MS-MARCO and HotPotQA, which are more representativ e of “messy" real-world web queries, suffer slightly (0.02-0.05 reduction) without distillation. This suggests that distillation is (slightly) helping the performance of M A X S H A P - L E Y . The rob ustness of M A X S H A P L E Y in the face of different ke y- point decomposition methodologies—including against adversarial manipulation—remains a direction for future research. MuSiQUE HotPotQA MS-MARCO Figure 11: Cumulativ e distrib ution function of Jaccard in- dex scores between rele vant information sources identified by M A X S H A P L E Y and ground truth annotations between keypoint composition that are “distilled" and “not distilled" with GPT - 4.1o. The average Jaccard index of MuSiQUE increases from 0.76 (distilled) to 0.89 (not distilled), HotPotQA declines from 0.83 to 0.81, and MS-MARCO declines from 0.78 to 0.73.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment