덕목 기반 강화학습: 윤리적 인공지능을 위한 새로운 로드맵
본 논문은 기존 강화학습(RL) 윤리 연구가 규칙 기반(의무론)과 단일 보상(결과론) 접근에 머무는 한계를 지적하고, ‘덕목(virtue)’을 정책 수준의 지속 가능한 습관으로 정의한다. 사회 학습, 다목표·제약 최적화, 친화도 정규화, 그리고 다양한 문화·전통 윤리의 제어 신호화라는 네 가지 연구 로드맵을 제시하며, 윤리적 행동을 규칙 검증이나 스칼라 보상이 아니라 특성 요약, 변동성에 대한 내구성, 그리고 명시적 가치 트레이드오프로 평가할 …
저자: Majid Ghasemi, Mark Crowley
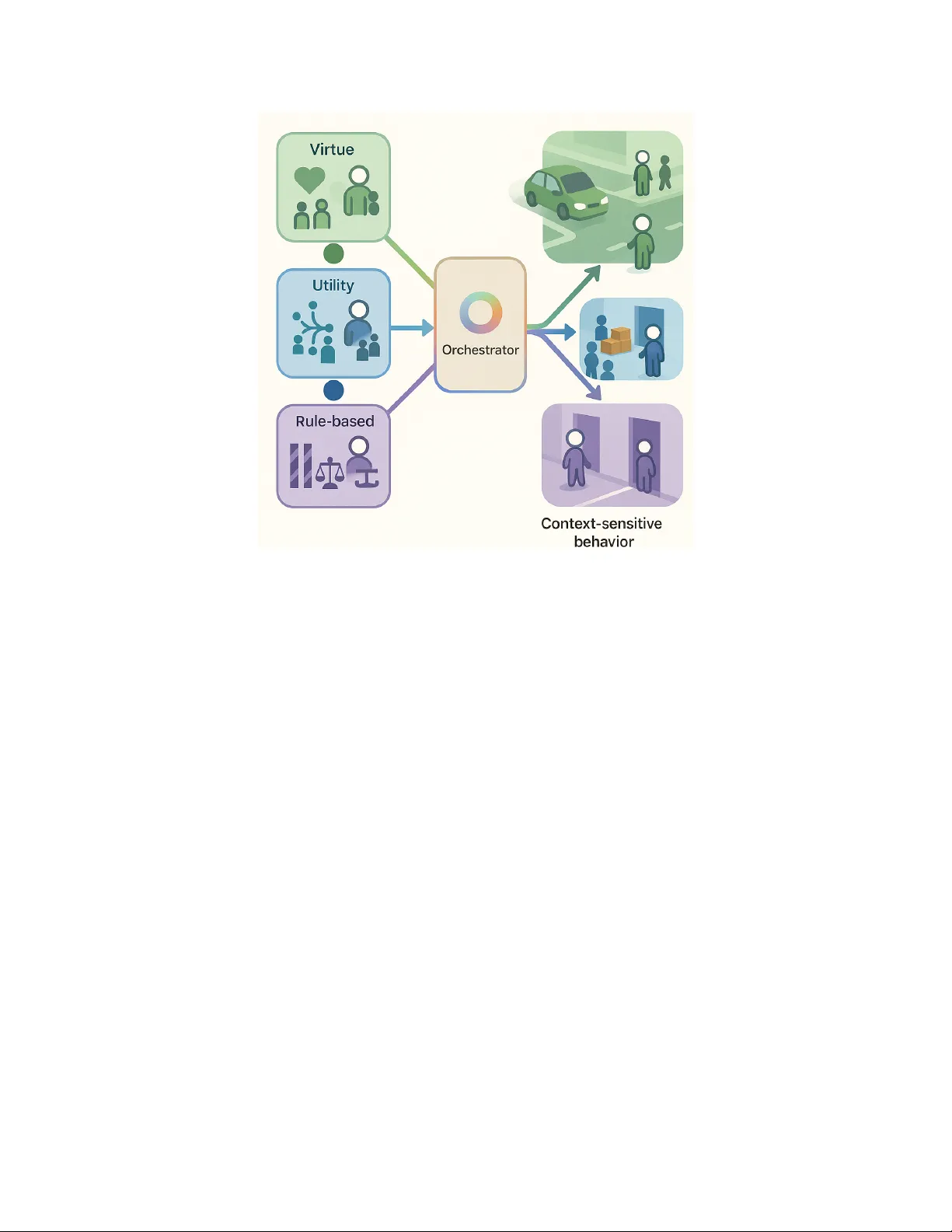
본 논문은 인공지능 시스템이 점점 더 중요한 의사결정 영역에 투입됨에 따라, 강화학습(RL) 기반 윤리 설계가 직면한 근본적인 문제들을 체계적으로 분석한다. 기존 연구는 크게 두 축으로 나뉜다. 첫 번째는 의무론적 접근으로, 규칙·제약·보호막을 사전에 정의해 에이전트가 이를 위반하지 않도록 강제한다. 이러한 방법은 명시적 규칙이 존재할 때는 효과적이지만, 환경이 불확실하거나 새로운 상황이 등장하면 규칙 해석이 모호해지고, 규칙을 따르는 것이 아니라 ‘덕목’이라는 내면화된 습관을 형성하지 못한다는 한계가 있다. 두 번째는 결과론적 접근으로, 다양한 윤리적 목표를 하나의 스칼라 보상에 압축한다. 이 경우 다중 가치(예: 안전, 공정성, 효율성)를 명시적으로 구분하지 못해 트레이드오프가 가려지고, 보상 설계가 부실하면 프록시 게이밍이나 보상 해킹이 발생한다.
덕목 윤리학을 RL에 적용하기 위해 저자는 ‘정책 수준 성향(trait)’이라는 개념을 도입한다. 성향은 특정 행동이나 상태에 대한 덕목 관련 신호 X(s,a)∈
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기