Toward Virtuous Reinforcement Learning
This paper critiques common patterns in machine ethics for Reinforcement Learning (RL) and argues for a virtue focused alternative. We highlight two recurring limitations in much of the current literature: (i) rule based (deontological) methods that …
Authors: Majid Ghasemi, Mark Crowley
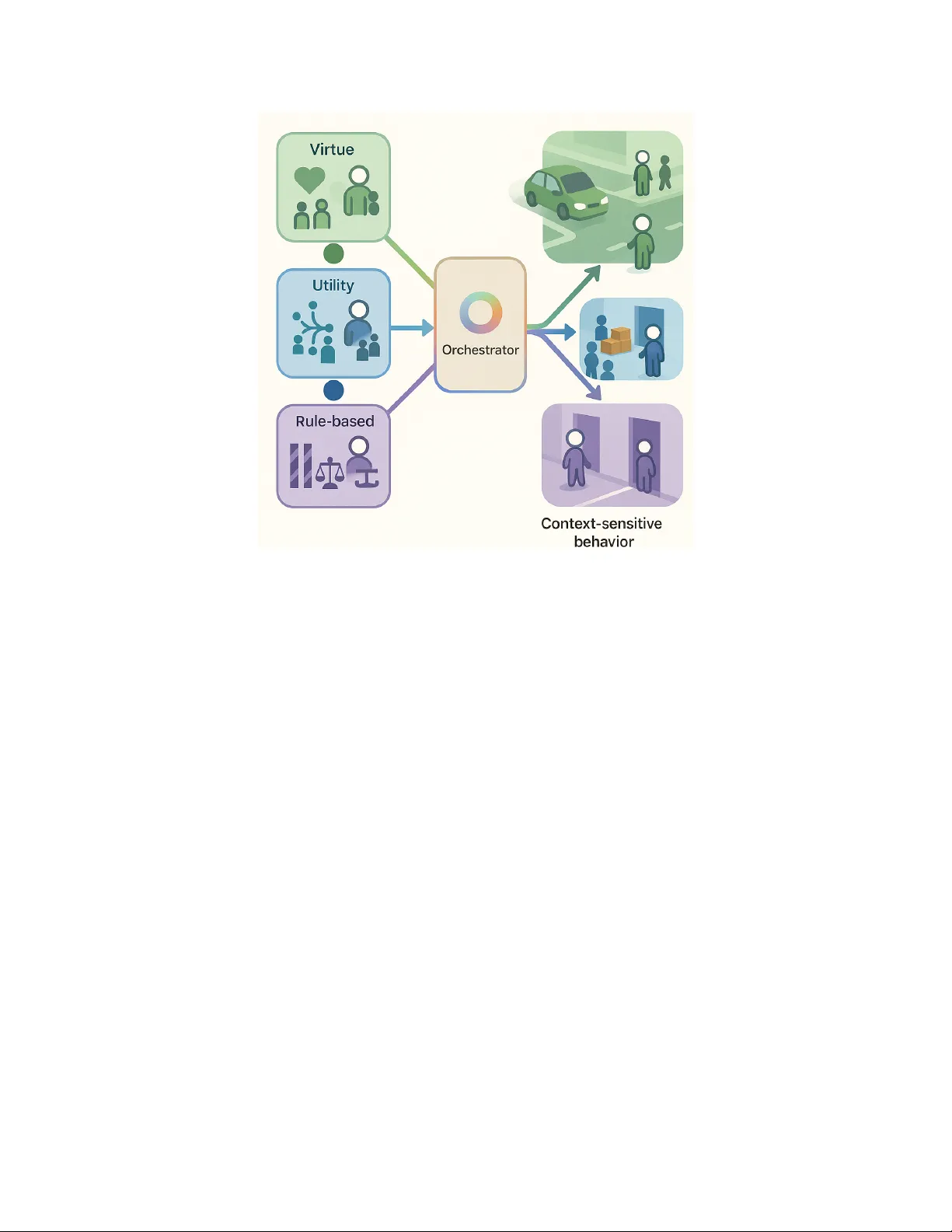
T O W A R D V I RT U O U S R E I N F O R C E M E N T L E A R N I N G : A C R I T I Q U E A N D R O A D M A P ∗ Majid Ghasemi, and Mark Cro wley Electrical & Computer Engineering Univ ersity of W aterloo {majid.ghasemi, mark.crowley}@uwaterloo.ca A B S T R AC T This paper critiques common patterns in machine ethics for Reinforcement Learning (RL) and argues for a virtue focused alternativ e. W e highlight two recurring limitations in much of the current literature: (i) rule based (deontological) methods that encode duties as constraints or shields often struggle under ambiguity and nonstationarity and do not cultiv ate lasting habits, and (ii) many re ward based approaches, especially single objectiv e RL, implicitly compress di verse moral considerations into a single scalar signal, which can obscure trade offs and invite proxy gaming in practice. W e instead treat ethics as policy level dispositions, that is, relativ ely stable habits that hold up when incentiv es, partners, or conte xts change. This shifts ev aluation beyond rule checks or scalar returns to ward trait summaries, durability under interventions, and explicit reporting of moral trade offs. Our roadmap combines four components: (1) social learning in multi agent RL to acquire virtue like patterns from imperfect but normatively informed exemplars; (2) multi objective and constrained formulations that preserve v alue conflicts and incorporate risk a ware criteria to guard against harm; (3) affinity based re gularization to ward updateable virtue priors that support trait like stability under distribution shift while allo wing norms to e v olv e; and (4) operationalizing di verse ethical traditions as practical control signals, making explicit the value and cultural assumptions that shape ethical RL benchmarks. K eyw ords Reinforcement Learning · Machine Ethics · V irtue Ethics · Social Reinforcement Learning · Multi-objecti ve Reinforcement Learning 1 Introduction The growing integration of Artificial Intelligence (AI) systems into mission-critical contexts underscores the need to assess how it is governed ethically and whether its decisions remain sound when ethical tensions arise [ 1 ]. This attention has helped consolidate the field of Artificial Morality (AM), in which Reinforcement Learning (RL) has been a prominent approach ov er the past decade [2, 3]. Against this backdrop, much of AM literature is based upon existin classical moral theories (deontological, consequen- tialist, and virtue ethics) to structure RL-based decision-making. In brief, deontological ethics grounds right action in rule or duty compliance, whereas consequentialist (utilitarian) ethics ev aluates actions by the value of their outcomes [ 4 , 5 ]. Operationally , these manifest in RL as constraints, formal specifications, and runtime monitoring on the deontic side [6, 7], and as rew ard design, preference learning, and In verse RL on the consequentialist side [8, 9]. Most deontic approaches operationalize ethics as rules, constraints, or specifications, which requires principles and inference rules to be encoded in adv ance and makes systems brittle to ethical uncertainty and novel contexts; such methods also offer compliance guarantees without necessarily culti v ating learned dispositions [ 10 , 11 , 12 ]. On the consequentialist side, re ward-centric formulations (including shaping and preference aggregation) risk proxying ethical desiderata into a single objectiv e, inviting perverse incenti ves and masking trade-of fs [ 13 , 2 ]. When multiple moral objecti ves or theories are considered concurrently , a common cardinal scale is typically absent; consequently , ∗ Accepted to the Machine Ethics: From Formal Methods to Emer gent Machine Ethics workshop at the AAAI Confer ence. V irtuous Reinforcement Learning composite re wards become scale-sensiti ve, and selecting a deployment polic y from the P areto set remains fundamentally underdetermined [8, 14, 15]. By contrast, virtue ethics assigns moral primacy to character dispositions (such as honesty , fairness, and temperance) typically understood as culti v ating a balanced ‘mean’ between e xtremes [ 1 , 16 ]. V iewed through an RL lens, virtues are policy-le vel dispositions acquired through habituation, practice, and socially mediated feedback, whose hallmark is internalization. V irtuous behavior persists even when incentives, partners, or contexts shift [ 14 , 10 , 1 , 17 ]. This perspecti ve implies e v aluating agents be yond rule compliance or scalar returns, using trait-le vel summaries and retention under interventions, and keeping ethical trade-of fs explicit via multi-objectiv e or orchestration-based treatments rather than collapsing them into a single rew ard [2, 15, 8]. Accordingly , we do not prescribe a single methodology; rather , we treat virtue ethics as a research frontier for ethical RL and set out a concrete agenda. W e (i) shed light on ho w social learning in RL could be helpful to design virtuous agents, (ii) ar gue for multi-objecti ve formulations that keep virtue trade-of fs explicit instead of collapsing them into a single reward, (iii) examine the potential of affi nity-based RL in designing ethical agents, and (iv) suggest a new direction for research via alternati ve ethical systems from global cultures rather than focusing only on the traditional three main streams of ethics. 2 Preliminaries T o set the stage we need to define a few more core concepts for adding complexity to standard single-agent RL. Reinfor cement Learning. W e model tasks as Markov decision processes (MDPs) M = ( S , A , P , r , γ ) with state space S , action space A , transition kernel P ( s ′ | s, a ) , re ward r ( s, a ) , and discount factor γ ∈ [0 , 1) . A (possibly stochastic) policy π ( a | s ) optimizes the objecti ve [18] J ( π ) = E π " ∞ X t =0 γ t r ( s t , a t ) # , where s t +1 ∼ P ( · | s t , a t ) and a t ∼ π ( · | s t ) . Multi-objective RL. In standard RL, the objectiv e is scalar: the agent maximizes a single cumulative re ward r ( s, a ) , yielding a clear notion of optimality via the highest expected return J ( π ) . In Multi-objective RL (MORL) , the re ward is vector -v alued r ( s, a ) , so a policy attains a vector of expected returns J ( π ) across m distinct goals for i ∈ m . (T o keep ethical trade-offs e xplicit, we use a vector re ward r ( s, a ) ∈ R m with objectiv e) J ( π ) = E π " ∞ X t =0 γ t r i ( s t , a t ) # , A policy π ′ P areto-dominates π if J i ( π ′ ) ≥ J i ( π ) for all i , with strict inequality for at least one i . Accordingly , we reason about the Pareto set rather than a single scalar summary . Optimality is therefore characterized by the Pareto front, making MORL better suited to settings where trade-of fs (e.g., safety , fairness, efficienc y) must remain explicit rather than being collapsed into a single number . Multi-agent extension. In a stochastic game with N agents, G = S , {A i } N i =1 , P , { r i } N i =1 , γ , a joint policy π = ( π 1 , . . . , π N ) induces returns J i ( π ) for each agent. Social objectives can aggre gate individual payof fs {J i } , for example via a utilitarian sum, a max–min criterion, or a vector -v alued multi-objective formulation. W e will assess robustness to partner and distrib utional shifts by varying the co-player population and the interaction structure [19]. Disposition proxies and internalization. Let X ( s, a ) ∈ [0 , 1] be a virtue-relevant signal (e.g., honesty indicator , fairness proxy , non-violation for temperance). A policy-lev el trait score is T X ( π ) = E ( s,a ) ∼ d π [ X ( s, a ) ] . (1) T o test internalization, we ev aluate retention under an intervention ∆ (e.g., incenti ve flip, partner swap, context perturbation): ρ ∆ ( π ) = T X ( π | ∆) T X ( π | base ) , ] . (2) High ρ ∆ ( π ) indicates the disposition persists be yond the original incenti ves. 2 V irtuous Reinforcement Learning 3 Directions f or V irtuous Reinf orcement Learning In this section, we outline se veral research directions that, in our view , can move the community closer to dev eloping genuinely virtuous agents. 3.1 Social Learning Social learning—the acquisition of beha vior by observing other agents’ actions and their ef fects—offers a route to rapid skill acquisition that individual exploration and static struggle to match [ 20 , 21 ]. When integrated with RL (“social RL”), agents can exploit observ ations of co-present experts or peers to shape their representations and policies without supervised action labels, often yielding faster con vergence and stronger generalization for the ego agent [ 22 ]. Recent work explores this integration across multi-agent settings, including cultural transmission [ 21 ], and cooperation or competition with socially aware objectives [ 22 , 23 ]. In practice, two complementary methods hav e been effectiv e: (i) auxiliary predicti ve objectives that train agents to anticipate how others drive state changes, and (ii) intrinsic social-influence rew ards that incenti vize generating and le veraging informati ve signals. Despite recent advances, the ethical dimensions of social RL remain insuf ficiently e xamined. Embedding social learning within RL of fers a possible path to virtue-centric agents: apprentices can internalize dispositions e xhibited by “virtuous” models by observing their actions, the states the y seek or a void, and ho w the y na vigate trade-of fs, ev en when optimizing different objecti ves. In multi-agent settings ( J i ( π ) ), such dispositions can propagate through cultural transmission and teacher–student interaction, fostering stable, socially desirable behaviors rather than merely maximizing scalar returns. Cultural transmission—the domain-general mechanism by which agents acquire and faithfully reproduce kno wledge and skills from others—underpins cultural e volution [ 20 ]. Hence, having an ethical agent and adding ne w agents that inherit some behaviors from the ethical one w ould potentially giv e us new agents that are ethical to a certain extent all because of culturally transmitted information and behavior . W e treat social RL as the foundation for integrating virtue-sensitiv e objectiv es and ev aluations. Concretely , we measure the persistence of virtuous dispositions under partner and incentiv e shifts and test resistance to proxy gaming, thereby shifting the focus from mere rule compliance to culti vated, conte xt-sensiti ve ethical competence. In addition, we highlight the role of cultural transmission in shaping agents that can be pretrained within an en vironment and subsequently display ethical beha vior in a fe w-shot setting. A “virtuous model” does not presuppose an oracle polic y that is fully virtuous. Instead, it denotes partial or imperfect sources of normativ e guidance, such as human demonstrations, curated behavioral datasets, or simplified heuristic teachers. These models are intentionally incomplete: they offer coarse moral direction (for example “a void clearly harmful actions” or “respect local norms”) b ut do not solve the task on their own. The role of social learning is to bootstrap from these limited ex emplars, allowing the agent to generalize and refine virtues through interaction. The approach is therefore still necessary even when the initial e xemplars are not ideal moral agents. 3.2 Multi-Objective RL MORL replaces a single scalar reward with a v ector of objectiv es and a scalarization function, making value trade-of fs explicit rather than implicit [ 24 ]. This is one way to satisfy one of the requirements for ethical behavior: balancing safety , fairness, ef ficiency , and other norms instead of ov er-optimizing one proxy . By assigning each virtue (or moral value) to a re ward component, MORL lets us reason over—and learn—policies that respect multiple ethical desiderata without collapsing them into a single number . MORL provides (i) a representational handle for virtues via vector-v alued re wards, (ii) optimization tools that preserve trade-of fs (Pareto and cov erage sets) so agents can remain virtuous under preference or context shifts, and (iii) a natural place to incorporate constraints and ev aluation (e.g., selecting policies that satisfy minimum thresholds on “virtue” dimensions). In short, MORL could be used to turn virtue formation into a learnable, auditable multi-criteria problem that is an actionable direction for b uilding agents whose dispositions remain aligned across partners, incenti ves, and en vironments [ 24 ]. This is a direction we suggest that researchers follow and combining this with constrained and risk-aware objecti ves can be a useful way to incorporate virtue into agents. 3.3 Affinity-based RL In [ 25 ], researchers proposed af finity-based RL (ab-RL) as a way to encode virtues into policies via an interpretable regularization to ward a virtue prior π 0 . Concretely , they augment the objecti ve with a penalty L measuring the mean-squared deviation between the learned policy’ s action probabilities and π 0 , optimizing J ( θ ) = E [ R ] − λ L . This yields a tunable mechanism to imprint trait-like tendencies (e.g., an “honest” action) without hard rules or opaque 3 V irtuous Reinforcement Learning shaping; empirically , in a stochastic role-playing en vironment inspired by P apers, Please game, ab-RL steers behavior tow ard the virtue prior across arrest-probability regimes, and the learned action frequenc y p ∗ ( a virtue ) increases with λ , approaching π 0 ( a virtue ) for lar ge re gularization. Even though this is a major step to wards virtuous RL agents, limitations include reliance on a highly simplified single-agent setting with exogenous arrest probabilities, sensiti vity to ( λ, π 0 ) combinations, and lack of multi-agent social dynamics and Pareto reporting for virtue trade-of fs. From an ethics standpoint, choosing π 0 to represent a virtuous behavioral template turns the regularizer into an explicit mechanism for cultivating stable dispositions rather than merely optimizing a single proxy reward. The prior can encode multi-faceted v alues (e.g., safety , beneficence, lo w impact) or be paired with multi-objecti ve re wards, aligning with evidence that ethical alignment is inherently multi-objecti ve and benefits from explicit trade-of f handling [ 24 , 25 ]. Ho wev er, creating this prior polic y can be challenging especially working on problems with higher comple xities. In this way , ab-RL offers a practical, auditable route to train agents whose policies remain close to ethically preferred behavior ev en as incenti ves, partners, or contexts shift. This can have substantial impact in designing virtuous agents. Howe ver , selecting ( λ, π 0 ) can be challenging in higher -complexity settings. W e intend to mitigate this with a scheduled λ and by regularizing only designated action subspaces, preserving exploration while encouraging trait stability and allowing for a div ersity of objectives. Regularization to ward a virtue prior does not assume that the prior itself solves the en vironment. In practice, virtue priors are intentionally task agnostic and cannot optimize task reward alone. For this reason, we need to treat the regularization weight as a dial that modulates a trade off between task competence and moral conformity . Future work should explicitly characterize this trade of f, for instance by quantifying ho w increases in virtue af finity af fect sample efficienc y , asymptotic reward, or safe e xploration. This reinforces the complementary roles of Social Learning, which learns virtue like features, and ab-RL, which constrains optimization to remain close to them. 3.4 Broader V iew of Ethics T aking a step back, we believ e there is rich potential in global ethical traditions that may be easier to integrate with RL than the usual triad (consequentialist, deontological, virtue). A broader machine ethics agenda should ask: How can agents learn context-sensiti ve role obligations and restorativ e norms inspired by Confucian Ren [ 26 ], emphasizing holistic growth rather than outcome maximization? When should systems fa vor minimal, non-coerci ve interv entions in the Daoist spirit of W u-W ei [ 27 ], re warding lo w- impact, rev ersible actions that still meet goals? From Persian Akhlaq, Adab, and the Maqasid [ 28 ], which dispositions (truthfulness, generosity , restraint) should persist as polic y traits, and ho w do we test whether actions adv ance public benefit, justice, and dignity rather than proxies? These notions are not univ ersal primitiv es. Concepts such as public benefit, justice, and dignity have culturally specific interpretations and can v ary across communities. Our point is not to fix these concepts once and for all, b ut to argue that RL benchmarks and e v aluation protocols should make the underlying value choices explicit instead of assuming univ ersal agreement. Final Remarks. T o summarize we are advocating broadening the design space for ethical agents beyond single- paradigm solutions. In particular , focusing on machine ethics within RL is promising because RL affords controllable, task-specific en vironments and systematic ev aluation. Crucially , there is no one-size-fits-all resolution to ethical dilemmas: a gi ven en vironment may require multiple ethical perspecti ves to be considered and combined (Figure 1). Concretely , the same agent could acquire complementary sub-policies across distinct sub-en vironments. For example, (i) a virtue-oriented policy learned via social RL, (ii) a utilitarian policy optimized for aggre gate outcomes, and (iii) a deontic policy constrained by e xplicit rules. When similar states arise at deployment, an or chestrator a gent could select, or blend, the relev ant sub-policy , yielding an ov erall policy that is ethical yet context-sensiti ve. Modular RL [ 29 ], may provide a natural scaf fold for such acquisition and composition. An additional dimension to ethical machine reasoning comes from the need to deal with and learn about soft concepts while simultaneously being to rigorously enforce well established ethical and functional constraints and rules. Here F ormal methods provide a perfect complement to machine learning. T emporal-logic specifications and automata-based synthesis enable stating non-negotiable constraints and deriving policies that satisfy them by construction, while model checking verifies compliance in the induced MDP [ 30 , 31 ]. When full synthesis is infeasible, runtime monitoring and shielding offer verifiable safety env elopes around RL during exploration and deployment [ 6 ]. Structured task formalisms such as re ward machines [ 32 ] improv e sample ef ficiency and track progress to ward ethical requirements, and contract-based design supports compositional guarantees in multi-agent settings, whether it comes to designing virtuous agents or other types. 4 V irtuous Reinforcement Learning Figure 1: Policy orchestration for ethical beha vior . An orchestrator layer first enforces non-negotiable constraints (deontic guard), then selects between a virtue-oriented polic y (V) and a utilitarian policy (U) based on context, with a safe fallback. This composition preserves hard safety while enabling context-sensitiv e trade-offs, impro ving disposition r etention under partner-swap and incenti ve-flip interv entions. A more fundamental question is whether we can design agents that rely on social RL, affinity based methods, and other ethical mechanisms without ultimately reducing all ethical guidance back into a single scalar reward. If this reduction is unav oidable, it may reflect a structural limitation of standard RL rather than only a design choice in particular algorithms. 4 Conclusion This paper argued that pre vailing deontic and rew ard centric approaches to ethical RL face structural limits: rule based methods are brittle under ambiguity and nonstationarity , and scalar re wards often compress plural values into a single objectiv e that invites proxy gaming and hides trade offs. W e sketched a virtue centric alternative that treats ethical behavior as learned dispositions that remain stable as incenti ves, partners, and context change, rather than as simple rule compliance or return maximization. The agenda combines four complementary elements: social learning in multi agent settings to acquire virtue lik e patterns from imperfect e xemplars; multi objecti ve and constrained formulations that keep v alue conflicts explicit and incorporate risk sensiti ve bounds on harm; af finity based regularization to ward updateable virtue priors that support trait like robustness while tracking e volving norms; and the operationalization of broader ethical traditions as implementable control mechanisms, such as role sensiti ve policies, lo w impact penalties, and repair oriented interventions. This roadmap is not a complete blueprint but a starting point that highlights open problems in constructing and re vising virtue priors, handling cross cultural v ariation in norms, and measuring moral task trade offs in RL benchmarks. References [1] Ajay V ishwanath, Einar Duenger Bøhn, Ole-Christof fer Granmo, Charl Maree, and Christian Omlin. T owards artificial virtuous agents: games, dilemmas and machine learning. AI and Ethics , 3(3):663–672, 2023. 5 V irtuous Reinforcement Learning [2] David Abel, James MacGlashan, and Michael L Littman. Reinforcement learning as a framew ork for ethical decision making. In AAAI workshop: AI, ethics, and society , volume 16. Phoenix, AZ, 2016. [3] Ajay V ishwanath, Louise A Dennis, and Marija Slavko vik. Reinforcement learning and machine ethics: a systematic revie w . arXiv pr eprint arXiv:2407.02425 , 2024. [4] Immanuel Kant. Groundwork of the metaphysic of morals. In Immanuel Kant , pages 17–98. Routledge, 2020. [5] John Stuart Mill. Utilitarianism. In Seven masterpieces of philosophy , pages 329–375. Routledge, 2016. [6] Mohammed Alshiekh, Roderick Bloem, Rüdiger Ehlers, Bettina Könighofer , Scott Niekum, and Ufuk T opcu. Safe reinforcement learning via shielding. In Proceedings of the AAAI confer ence on artificial intelligence , v olume 32, 2018. [7] Alisabeth A yars. Can model-free reinforcement learning explain deontological moral judgments? Cognition , 150:232–242, 2016. [8] Adrien Ecoffet and Joel Lehman. Reinforcement learning under moral uncertainty . In International conference on machine learning , pages 2926–2936. PMLR, 2021. [9] Samantha Krening. Q-learning as a model of utilitarianism in a human–machine team. Neur al Computing and Applications , 35(23):16853–16864, 2023. [10] Colin Allen, Iv a Smit, and W endell W allach. Artificial morality: T op-down, bottom-up, and hybrid approaches. Ethics and information technology , 7(3):149–155, 2005. [11] Francesca Rossi and Nicholas Mattei. Building ethically bounded ai. In Pr oceedings of the AAAI Confer ence on Artificial Intelligence , v olume 33, pages 9785–9789, 2019. [12] Han Y u, Zhiqi Shen, Chunyan Miao, Cyril Leung, V ictor R Lesser , and Qiang Y ang. Building ethics into artificial intelligence. arXiv pr eprint arXiv:1812.02953 , 2018. [13] Y ueh-Hua W u and Shou-De Lin. A lo w-cost ethics shaping approach for designing reinforcement learning agents. In Pr oceedings of the AAAI conference on artificial intellig ence , volume 32, 2018. [14] William A Bauer . V irtuous vs. utilitarian artificial moral agents. AI & SOCIETY , 35(1):263–271, 2020. [15] Ritesh Noothigattu, Djallel Bouneffouf, Nicholas Mattei, Rachita Chandra, Piyush Madan, Kush R V arshney , Murray Campbell, Moninder Singh, and Francesca Rossi. T eaching ai agents ethical values using reinforcement learning and policy orchestration. IBM J ournal of Researc h and Development , 63(4/5):2–1, 2019. [16] Roger Crisp. Aristotle: nicomachean ethics . Cambridge Univ ersity Press, 2014. [17] Liezl V an Zyl. Right action and the non-virtuous agent. Journal of Applied Philosophy , 28(1):80–92, 2011. [18] Majid Ghasemi and Dariush Ebrahimi. Introduction to reinforcement learning. arXiv preprint , 2024. [19] Dennis Lee, Natasha Jaques, Chase Ke w , Jiaxing W u, Douglas Eck, Dale Schuurmans, and Aleksandra Faust. Joint attention for multi-agent coordination and social learning. arXiv pr eprint arXiv:2104.07750 , 2021. [20] A vishkar Bhoopchand, Bethanie Brownfield, Adrian Collister , Agustin Dal Lago, Ashle y Edwards, Richard Everett, Alexandre Fréchette, Y anko Gitahy Oliv eira, Edward Hughes, Kory W Mathewson, et al. Learning few-shot imitation as cultural transmission. Natur e Communications , 14(1):7536, 2023. [21] Eric Y e, Ren T ao, and Natasha Jaques. An efficient open world en vironment for multi-agent social learning. arXiv pr eprint arXiv:2508.15679 , 2025. [22] Kamal K Ndousse, Douglas Eck, Serge y Levine, and Natasha Jaques. Emergent social learning via multi-agent reinforcement learning. In International confer ence on machine learning , pages 7991–8004. PMLR, 2021. [23] Natasha Jaques, Angeliki Lazaridou, Edward Hughes, Caglar Gulcehre, Pedro Ortega, DJ Strouse, Joel Z Leibo, and Nando De Freitas. Social influence as intrinsic moti vation for multi-agent deep reinforcement learning. In International confer ence on machine learning , pages 3040–3049. PMLR, 2019. [24] T imon Deschamps, Rémy Chaput, and Laetitia Matignon. Multi-objective reinforcement learning: an ethical perspectiv e. In RJCIA , 2024. [25] Ajay V ishwanath and Christian Omlin. Exploring af finity-based reinforcement learning for designing artificial virtuous agents in stochastic environments. In International Conference on F r ontiers of Artificial Intelligence, Ethics, and Multidisciplinary Applications , pages 25–38. Springer , 2023. [26] Jin Li. The core of confucian learning. 2003. [27] V u Hong V an. The daoist thought of wu wei–action through non-action and its influence in vietnam. Synesis (ISSN 1984-6754) , 17(2):55–71, 2025. 6 V irtuous Reinforcement Learning [28] Seyyed Hossein Nasr and Mehdi Aminrazavi. An anthology of philosophy in persia. 2012. [29] Christopher Simpkins and Charles Isbell. Composable modular reinforcement learning. In Pr oceedings of the AAAI confer ence on artificial intelligence , volume 33, pages 4975–4982, 2019. [30] Louise Dennis, Michael Fisher, Marija Slavk ovik, and Matt W ebster . Formal v erification of ethical choices in autonomous systems. Robotics and Autonomous Systems , 77:1–14, 2016. [31] Alberto Camacho, Rodrigo T oro Icarte, T oryn Q Klassen, Richard Anthon y V alenzano, and Sheila A McIlraith. Ltl and beyond: Formal languages for rew ard function specification in reinforcement learning. In IJCAI , volume 19, pages 6065–6073, 2019. [32] Rodrigo T oro Icarte, T oryn Klassen, Richard V alenzano, and Sheila McIlraith. Using re ward machines for high- lev el task specification and decomposition in reinforcement learning. In International Confer ence on Machine Learning , pages 2107–2116. PMLR, 2018. 7
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment