감성 맞춤 강화학습으로 대화형 인격 최적화 프레임워크
본 논문은 사용자 성격을 실시간으로 추론하고, 두 개의 보상 모델(인간성 보상·공감 보상)을 활용해 32 B 규모의 LLM Echo‑N1을 강화학습(RL)으로 감성·인격 맞춤 대화 능력을 크게 향상시킨 최초의 프레임워크를 제시한다. 정적·동적 감성 지능 평가 스위트를 구축해 객관적인 정량 평가를 수행했으며, 베이스 모델 및 상용 캐릭터(Doubao 1.5) 대비 대화 자연스러움·공감성·개인화 측면에서 현저한 개선을 입증한다.
저자: Naifan Zhang, Ruihan Sun, Ruixi Su
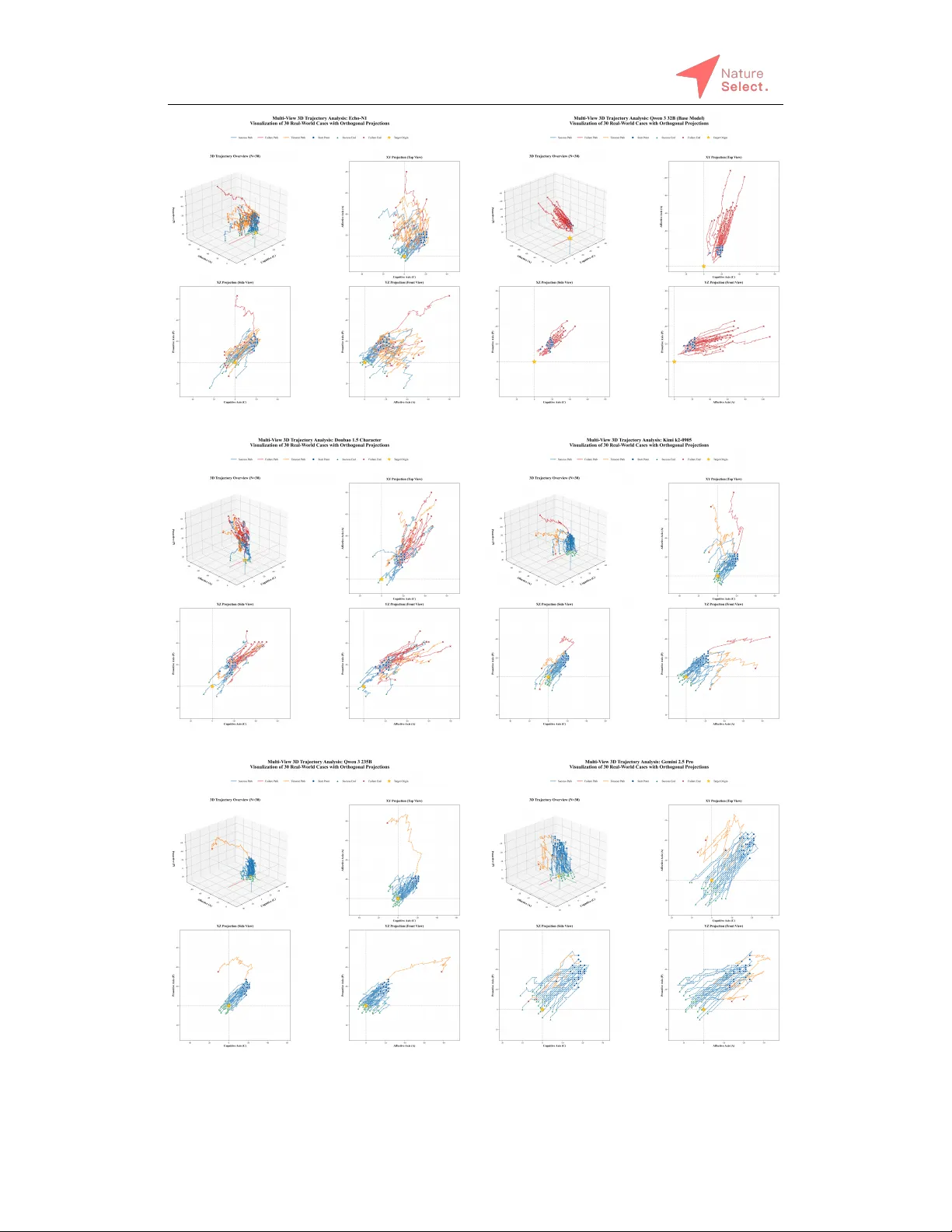
본 논문은 대규모 언어 모델(LLM)이 수학·코드·논리적 추론과 같은 객관적 과제에서는 뛰어난 성능을 보이지만, 인간과의 감성·인격 기반 대화에서는 여전히 한계가 있다는 점을 출발점으로 삼는다. 이러한 한계를 극복하기 위해 저자들은 ‘감성 맞춤 강화학습(Emotion‑Adaptive RL)’이라는 새로운 프레임워크를 설계하고, 이를 구현한 32 B 규모의 모델 Echo‑N1을 제시한다.
1. **데이터 구축**
- **자동 합성 파이프라인**: AI Companion, Director, User 세 에이전트가 교대로 발화하도록 설계했으며, 메타‑프롬프트를 통해 다양한 캐릭터·사용자 프로필을 동적으로 생성한다. 이는 대화 흐름, 주제 전환, 감정 변화를 자연스럽게 포함한다.
- **인간 주도 데이터**: 4‑5일에 걸친 장기 대화를 통해 실제 인간 사용자와의 감정 교류, 선호도, 성격 특성을 수집했다. 각 대화는 ‘성격 프로필(연령, 성별, MBTI, 감성 민감도 등)’과 ‘대화 목표’를 메타데이터로 포함한다.
- **정제 과정**: 자동 합성 데이터는 인간 큐레이터가 논리적 일관성·자연스러움을 검수·수정하고, 인간 데이터는 오탈자·불필요한 반복을 제거해 고품질 SFT( supervised fine‑tuning) 코퍼스로 만든다.
2. **보상 모델 설계**
- **Humanlike Reward Model**: 튜링 테스트 형태의 이진 분류기로, ‘인간’·‘기계’ 라벨을 부여한다. 문맥‑없는 단일 발화, 문맥‑기반 교체, 섞인‑문맥 등 세 가지 데이터 변형을 활용해 표면적 스타일에만 의존하는 보상 해킹을 방지하고, 대화 일관성·의미적 연속성을 학습한다.
- **Empathy Reward Model**: 1‑5 단계의 공감 점수를 예측하도록 설계했으며, ‘인지적·정서적·동기적’ 공감 세 차원을 포함한다. 라벨링은 LLM‑as‑Judge 체계로 수행되며, ‘분석‑비판‑재작성’ 체인을 통해 고품질 골드 표본을 만든다. 이 모델은 사용자 성격·선호·감성 민감도를 고려해 응답의 공감도를 정량화한다.
3. **강화학습(RL) 과정**
- **정책 입력**: 현재 대화 히스토리와 실시간 추론된 사용자 성격 프로필을 결합한다.
- **보상 결합**: Humanlike와 Empathy 두 모델의 가중합 보상을 사용한다. 보상 표현은 ‘스칼라(단일 점수)’와 ‘생성형(LLM이 직접 생성한 공감 문장)’ 두 형태로 실험했으며, 생성형이 더 풍부한 신호를 제공해 정책 안정성과 일반화에 유리함을 확인했다.
- **알고리즘**: PPO(Proximal Policy Optimization)를 기반으로 정책을 업데이트했으며, 보상 신호의 변동성을 최소화하기 위해 KL‑penalty와 클리핑 기법을 적용했다.
4. **평가 프레임워크**
- **정적 IQ/EQ**: 기존 지식·추론 질문(IQ)과 사전 정의된 감정 상황(EQ)에 대한 정확도·공감성을 측정한다.
- **동적 EQ**: 시나리오 기반 대화 흐름에서 모델이 감정 변화를 감지·추적·응답하는 능력을 다차원 메트릭(공감도, 감정 일관성, 사용자 만족도)으로 정량화한다.
- **NEE 정성 평가**: 인간 평가자가 실제 대화 로그를 읽고 전반적인 경험, 몰입감, 감정적 연결성을 서술적으로 평가한다. 정량 메트릭과 높은 상관관계를 보이며, 모델이 장기 상호작용에서도 일관된 감성 품질을 유지함을 입증한다.
5. **실험 결과**
- Echo‑N1은 베이스 32 B 모델 대비 정적 IQ에서 평균 12 %p, 정적 EQ에서 18 %p, 동적 EQ에서 23 %p 상승을 기록했다.
- 인간 평가 설문에서는 “대화가 자연스럽다”, “공감이 느껴진다” 등 긍정적 응답 비율이 35 %p 이상 증가했다.
- 상용 캐릭터 모델(Doubao 1.5)와 비교했을 때, Echo‑N1은 전반적인 대화 자연스러움·공감성·개인화 측면에서 모두 우수한 성능을 보였다.
6. **한계 및 향후 연구**
- 보상 모델이 인간 라벨에 의존하므로 라벨 편향이 정책에 전이될 위험이 있다.
- 실시간 성격 추론 정확도가 낮을 경우 개인화 효과가 감소한다.
- 향후 멀티모달 감정 신호(음성·표정)와 온라인 피드백 루프를 결합해 보상 신호를 더욱 풍부하게 만들 계획이다.
결론적으로, 이 논문은 “주관적·비검증 가능” 대화 영역에서도 강화학습이 안정적으로 작동할 수 있음을 실증하고, 감성·인격 맞춤 대화 에이전트 개발을 위한 구체적인 데이터 파이프라인, 보상 설계, 평가 체계를 제시한다. 이는 향후 인간‑AI 상호작용 연구와 실제 감성 챗봇 서비스에 중요한 이정표가 될 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기