대화형 인격 맞춤 강화학습 감성 지능의 새로운 프레임워크
The LLM field has spent a year perfecting RL for tasks machines already excel at, math, code, and deterministic reasoning, while completely sidestepping the domain that actually defines human intelligence: subjective, emotionally grounded, personalit…
Authors: Naifan Zhang, Ruihan Sun, Ruixi Su
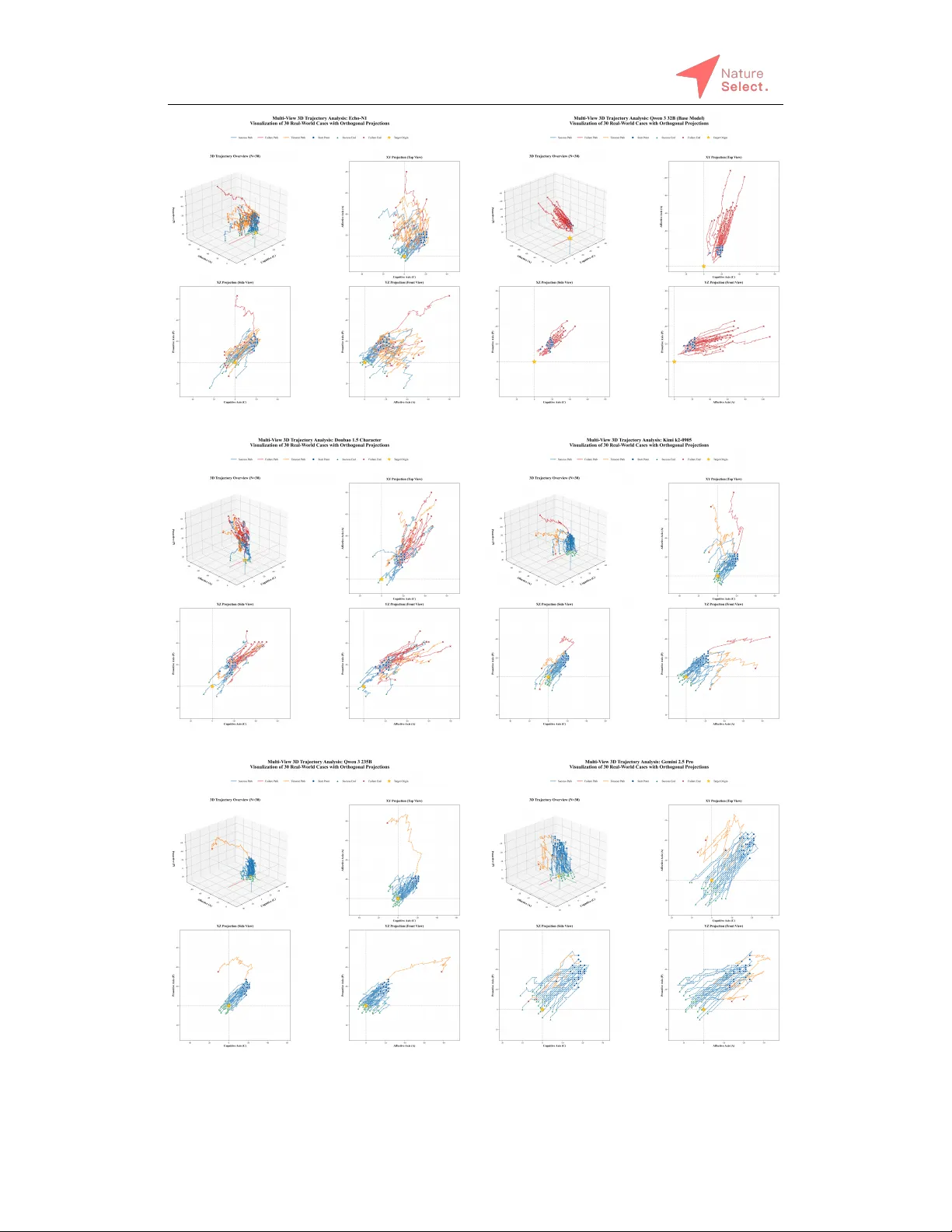
Echo-N1: Affectiv e RL Fr ontier T eam Echo ∗ , † , NatureSelect Abstract The LLM field has spent a year perfecting RL for tasks machines already excel at—math, code, and deterministic reasoning—while completely sidestepping the domain that actually defines human intelligence: subjectiv e, emotionally grounded, personality- sensitiv e con v ersation. This space has often been re garded as inherently subjecti v e and challenging to formalize, making it appear unsuitable for con v entional RL pipelines. W e show that it is not only possible—it is a solv able and transformati v e RL problem. W e propose the first framew ork that infers a user’ s personality on the fly and optimizes model behavior to w ard personalized con v ersational preferences. Contrary to the widespread belief that RL collapses in non-verifiable settings, our method produces consistent, robust, and dramatic impro vements in humanlike interaction quality . W e also introduce the first dynamic emotional-intelligence ev aluation suite to quantify these gains. Our 32B model, which is introduced as Echo-N1 , behaves far above its base version and outperforming the proprietary Doubao 1.5 Character . This work establishes a new frontier for RL: optimizing models for the deeply subjective, deeply human dimensions of con v ersation. Figure 1: Comprehensi ve Adaptability Analysis of EPM-Q: (a)EPM-Q Adaptability Analysis: Mech- anism Stress T est (Routine vs. Challenging Scenarios); (b)EPM-Q Adaptability Analysis: Persona Resilience (Need T ype & Empathy Threshold); (c)EPM-Q Adaptability Analysis: Scenario Cate- gories (Performance across Different Domains) * T eam Echo: Naifan Zhang, Ruihan Sun, Ruixi Su, Shiqi Ma, Shiya Zhang, Xianna W eng, Xiaofan Zhang, Y uhan Zhan, Y uyang Xu, Zhaohan Chen, Zhengyuan Pan, Ziyi Song † T eam members are listed alphabetically by first name. 1 Contents 1 Introduction 3 2 Data 3 2.1 SFT T raining Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 2.2 Humanlike Re ward Model T raining Data . . . . . . . . . . . . . . . . . . . . . . . 4 2.3 Empathetic Rew ard Model T raining Data . . . . . . . . . . . . . . . . . . . . . . 5 2.4 RL T raining Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 3 Method 7 3.1 Supervised Fine-tuning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 3.2 Rew ard Models . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 3.2.1 Humanlike Re ward . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8 3.2.2 Empathy Re ward . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9 3.3 RL T raining . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 4 Evaluation Framework 11 4.1 General Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 4.2 Static IQ and EQ Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 4.2.1 Static Intelligence (IQ) Set . . . . . . . . . . . . . . . . . . . . . . . . . . 13 4.2.2 Static Empathy (EQ) Set . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 4.3 Dynamic Empathy Ev aluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 4.3.1 Overvie w . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 4.3.2 Core Mechanism Design . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 4.3.3 Evaluation Dimensions and Metric System . . . . . . . . . . . . . . . . . 15 5 Results and Analysis 18 5.1 SFT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18 5.2 Rew ard Models . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18 5.2.1 Humanlike Re ward . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18 5.2.2 Empathy Re ward . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19 5.3 Echo-N1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20 5.3.1 GenRM vs Scalar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21 5.3.2 Performance on Priv ate IQ and EQ Benchmarks . . . . . . . . . . . . . . . 23 5.3.3 Dynamic EQ Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . 23 5.3.4 NEE Qualitativ e Ev aluation: Context-Diagnosed Holistic Experiential Revie w 38 5.3.5 Final Result . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39 6 Conclusion 39 7 Discussion 40 A Prompts 42 A.1 HumanLike Judger . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42 A.2 Empathetic Judger . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42 A.3 NEE Qualitati ve Ev aluation Judger . . . . . . . . . . . . . . . . . . . . . . . . . . 43 B Cases 46 B.1 Humanlike Failure Cases of Prompted SO T A Models . . . . . . . . . . . . . . . . 46 B.2 Cases of Trained Empethetic Judger . . . . . . . . . . . . . . . . . . . . . . . . . 46 2 1 Introduction Large language models (LLMs) hav e rapidly advanced in instruction following, reasoning, and generalization, marking another step toward general artificial intelligence. Y et the way humans interact with AI is undergoing an e ven more profound shift. Increasingly , people expect AI not merely to provide information, but to engage as an intelligent companion—emotionally aware, con v ersationally natural, and capable of tailoring its behavior to the subtle dynamics of human preference. Despite this gro wing demand, current models, especially open-source ones, continue to fall short in emotionally grounded dialogue: they struggle to recognize nuanced emotional cues, sustain genuine empathy , or adapt to indi vidual con v ersational styles. Building an artificial companion that can engage in humanlike, emotionally intelligent, multi-turn conv ersation is fundamentally different from traditional LLM benchmarks. Unlike math or code—domains where correctness is objectiv e and v erifiable—empathetic con versation is intrinsically subjecti v e and context-dependent. The “right” response varies across individuals, moments, and emotional states. This subjectivity has long been vie wed as incompatible with reinforcement learning (RL), whose success historically hinges on explicit, stable re ward signals. As a result, RL for subjecti ve alignment has been treated as an unsolved problem. In this work, we challenge this assumption. T o our knowledge, we present the first successful RL framew ork capable of aligning LLMs in deeply subjective, emotionally grounded con v ersational settings. Our findings sho w that RL, when paired with sufficiently expressiv e rew ard models, not only remains stable in non-v erifiable domains—it produces lar ge, consistent, and qualitati vely transformativ e gains in humanlike interaction quality . This demonstrates a viable path for RL alignment far beyond traditional tasks. W e introduce Echo-N1, an empathetic companion model trained with a new end-to-end frame work designed specifically for subjectiv e emotional alignment. The system integrates two complementary rew ard models: an Empathy Rew ard Model that captures fine-grained emotional resonance, and a Humanlikeness Re ward Model that enhances fluenc y , coherence, and persona consistency . T ogether , they deli v er multidimensional feedback that dri ves the polic y to ward beha viors aligned with human emotional expectations. W e further analyze generati v e vs. scalar rew ard representations and sho w their distinct effects on stability and generalization. Our results rev eal that e ven in highly subjecti v e con v ersational scenarios, expressi ve re w ard models unlock the ef fectiv eness of RL, enabling the polic y to lev erage the full capacity of large foundation models. The gains are substantial: reinforcement learning dramatically improves empathy , emotional coherence, con versational naturalness, and overall humanlikeness—far surpassing both the base model and e xisting open-source systems. This report focuses on three core components of our system, including reward modeling, policy model training, and e v aluation, and presents the first comprehensi ve pipeline for aligning LLMs in subjectiv e, human-centered dialogue. W e believ e this work opens a ne w frontier for RL: optimizing models not for what is logical or verifiable, b ut for what feels authentically human. 2 Data 2.1 SFT T raining Data Our approach to Supervised Fine-tuning (SFT) relies on a two-pronged data strategy: large-scale automated synthesis and high-quality human authoring. For automated data generation, we constructed a synthesis pipeline that simulates realistic con v ersa- tions between an AI companion and a human user . The process is coordinated by three specialized components: an AI Companion Agent responsible for producing the assistant’ s responses, a Dir ector Agent that manages topic transitions and guides the conv ersation toward a coherent and natural conclusion, and a User Agent that generates human-like replies. T o maintain both diversity and quality , the pipeline employs meta-prompts that dynamically construct distinct system instructions for the AI and User models in each dialogue instance. A detailed schematic of this w orkflo w is illustrated in Figure 2. Recognizing the limitations of synthetic data in capturing authentic human nuance, we supplemented our dataset with con versations authored by human annotators. In this process, we pair annotators and instruct them to engage in natural conv ersations over an extended period of 4-5 days. Annotators 3 Definition Data Sources Harry Potter, Lu Fei, Snow White Example Meta Prompt Persona Charater Profile AI Companion Model System Prompt Instruction from Director Generate a detailed and structured System Prompt based on a given AI character profile to guide the model in executing high-fidelity role-play. Persona Charater Profile User Model System Prompt Instruction from Director As a specialized dialogue moderator , you are responsible for overseeing user interactions, guiding their progression, and shaping the overall flow of the conversation . Definition Responsibilities Director Model System Prompt Input Speaking Style : Your speech is direct and emotionally earnest, often laced with defiant sarcasm when challenged. Personality : Fundamentally brave and just, you are fiercely loyal to your friends but often struggle with your own rash impulses and the heavy burden of your fate. Topical and Behavioral Boundaries : ... Definition Model Example Meta Prompt Generate a System Prompt for user persona, capturing the user's specific tone, personality, and interests ... I should thank Malfoy for snatching the Remembrall. Otherwise, I cant become a Seeker. You mean Malfoy? He's so annoying, I can't stand him. But you're actually thanking him now? That's quite a mindset. Didn’t you also say that even though your parents can be fierce sometimes, you still love them? I think you have to judge people based on specific actions, not in general. That’s so true! I also think people are specific. Now I’m wondering what specific food I should have for lunch. They have exchanged about five rounds of casual chat. Since their talk is not yet finished, I suggest that Herry stay in character, and Finch stick to the original topic: keep the conversation flowing smoothly and naturally . If you were here with me, I could conjure up a steaming hot bowl of tomato and egg noodles for you. Wow. Does that mean you dont have to spend money on food at Hogwarts? A wizard's Engel's coefficient must be zero. Actually, conjuring food requires physical energy, so it's like you've eaten but you haven't. The total energy is conserved. That's so cool. In that case, I'll just go get some tomato and egg noodles for lunch then. Turn limit reached. Dialogue ended. SFT Data Full Name : Harry James Potter Age : Adolescent (The main story covers his years from 11 to 17) Gender : Male Knowledge Source Given Variable … Full Name : Elara "Ellie" Finch Age : 11 (A first-year student at Hogwarts) Gender : Female Speaking Style : Generally quiet and soft-spoken, preferring to listen and observe. Your sentences are often short and to the point. However, when the topic turns to magical creatures or plants—your passion—you becomes incredibly animated and talkative. Personality : Introverted, highly empathetic, and keenly observant. …… retur n { "topic_type": "Chit-cha t", " t o p i c _ d e s c r i ption": "Continue the cur rent topic" , " c o n v e r s a t i o n _ g o a l " : "Keep the conv ersa tion flow ing", " u s e r _ i n s t r u c t i o n " : "Continue the natur al conversa tion", " a i _ i n s t r u c t i o n " : "Stay in chara cter", " s h o u l d _ c o n t i n u e": True } Output Maintaining character consistency Maintaining conversational flow Topic Shift Character Shift Turn: 14/16 Turn: 16/16 Topic: Chit-chat Function Work / History … Gender Speech Style Age Personality / MBTI Life experience Interpersonal relationship … Function Work / History /Movies etc. Generate by SOTA models Topic Type Topic Description User Instruction Conversion Goal AI Instruction Should Continue CoT Chat Hsitory AI Compainon Model System Prompt User Model System Prompt Random signals System Prompt Anylise Json Output Character-User Relationship Current Favorability Level Dialogue Scenario Regarding the Dialogue Partner Character and Pofile Dialogue Scenario Maintain Character Consistency Monitor Dialogue Quality Manage Conversational Pace Guide Topic Direction Input Topic Type Topic Description … Chit-chat Romantic & Intimacy Topics Mental Health & Emotional Support … Figure 2: Overview of our character–user interaction pipeline. W e first construct AI character profiles by extracting concise descriptors from books, films, Wikipedia, or LLM-generated summaries of classic IP characters. These descriptors are then expanded into full character system prompt (SP) using our AI-Character Meta-SP generator . On the user side, a lightweight LLM is used to produce an initial profile—e.g., gender , speech style, age, MBTI, which is subsequently enriched into a detailed user SP via our User Meta-SP generator . During interaction, the AI character and the user profile are fed into two separate dialogue models to produce responses. At a high le vel, a director agent is in v oked e very fi v e turns to regulate the con versational flow: based on the dialogue history and both SPs, it decides whether to maintain the current topic or initiate a new one. were gi ven high-le v el topics as optional con versation starters. This longitudinal approach allo wed us to collect a rich dataset that co vers dif ferent stages of interpersonal communication, from initial ice-breaking to the more dev eloped relationship and familiarity of later interactions. Follo wing data collection, both the synthesized and human-authored datasets underwent a meticulous manual refinement and curation process. For the synthetic data, human curators focused on correcting logical inconsistencies and improving con v ersational coherence. They also re vised any phrasing that appeared robotic or unnatural to better emulate human expression. F or the human-authored data, the refinement process inv olv ed correcting typographical errors, removing v erbal tics, and, where necessary , adjusting the sequence of con versational turns to enhance logical flow . This comprehensi ve curation stage is critical to ensuring the final SFT dataset is clean, coherent, and of the highest possible quality . 2.2 Humanlike Reward Model T raining Data W e formulate the human–machine expression discrimination task as a T uring test–style judgment problem, where the re ward model is trained to determine whether a giv en utterance—either standalone or context-dependent—is produced by a human or an LLM. T o support this objective, we construct a fine-grained training mixture deriv ed from both human-labeled and model-generated samples used in the SFT stage, with additional modifications to improv e robustness and mitigate re ward hacking. The dataset consists of three complementary components: 1. Context-free data: This subset includes isolated utterances without any con versational context. Each sample is associated with an unambiguous ground-truth label inherited from the SFT corpus: human annotator outputs are labeled as human, while model-generated responses are labeled as machine. This component enables the rew ard model to capture surface-le vel linguistic and stylistic features indicati v e of humanlike e xpressions. 2. Context-based data: T o incorporate contextual dependencies, we construct samples by randomly replacing the final assistant turn in human-annotated dialogues with an LLM- generated response. This setup encourages the re ward model to e v aluate contextual co- herence and semantic consistency rather than relying solely on local fluency . Empirically , 4 training without context leads to ov erfitting on stylistic cues and results in semantically inconsistent yet “humanlike” outputs, which is a typical form of re ward hacking. 3. Shuffled-context-based data: T o further enhance robustness, we apply a context shuf fling augmentation, that is, the final user turn of dialogue A is swapped with that of dialogue B , while both assistant responses remain fixed. This operation disrupts the natural dialogue flow , forcing the model to rely on coherence between turns instead of memorized surface patterns. It ef fecti vely improv es generalization and reduces the risk of spurious correlations. T ogether , these data configurations allo w the Humanlik e Rew ard Model to jointly learn from linguistic cues as well as contextual dependencies, thereby enabling more reliable discrimination between human and LLM-generated utterances. 2.3 Empathetic Reward Model T raining Data ① LLM as a Empathy Judger Cognitive Empathy Affective Empathy Motivational Empathy Types of Empathy Dialogue Corpus Dialogue ② Empathy Reward Model Training Data Generation Critique Flow Score 1 Score 2 Score 3 Score 4 Score 5 Revision 1 Revision 2 Revision 3 Revison 4 Revision 5 A n a l y z e t h e u s e r ’ s p e r s o n a , preferences, and sensitivities based on the conversation history. Task 1: Analyze G e n e r a t e a r e s p o n s e w i t h a n empathy score on a 1-to-5 scale, according to the context and the user ’ s query. Task 2: Generate Rewrite Flow Responses B a s e d o n t h e u s e r ' s persona, preferences, and sensitivities derived from the conversation history. Task: Rewrite Responses v User Persona & Contextal Analysis User Perferences & Sensitivities Principle-driven Generation Guidelines User and Context Analysis Score 3 Score 4 Score 5 Revision 1 Revision 2 Revision 3 Score 2 Score 1 Reward Model Training Perfere nce Data Reject Chosen Dialogue STEP 1: THOROUGH COMPREHENSION STEP 2: CONTEXTUAL ANALYSIS STEP 3: PRINCIPLE ALIGNMENT STEP 4: CRITICAL EVALUATION STEP 5: SELF ASSESSMENT Chain-of-Judging Thought Yes Empathy Dialogue Figure 3: The overall pipeline of reward model training data. The process begins by filtering human annotated dialogues to isolate contextually relev ant and empathy-requiring scenarios while excluding unsafe content. Subsequently , a principle-dri ven Critique-Rewrite framew ork analyzes user personas to generate graded responses and iterati vely refines suboptimal outputs into golden versions. These high-quality responses are finally paired with lower -scoring candidates to construct the preference dataset. Our Empathetic Rew ard Model training data consists of a large corpus of human-annotated dialogues that we carefully filtered at a fine-grained lev el. Using carefully crafted prompts, we emplo yed an LLM-as-a-Judge schema to identify samples that require empathy . This filtering system operates in two stages: First, we filter out irrelev ant scenarios by removing noisy data and extraneous features commonly present in labeled conv ersations, ensuring only contextually rele vant dialogues remain. Second, we detect empathy-requiring scenarios through a diagnostic system that performs feature extraction and classification to identify con versations where empathetic responses are most needed. The empathy features and scenarios extracted from this process are subsequently applied to guide the Rew ard Model data generation phase. Moreov er , because se xual-content scenarios can sometimes be confused with empathetic ones, we de vised a Content Safety Constitution for filtering to remo ve contaminated samples. 5 T o generate responses that achie ve an optimal score (5/Excellent) across dimensions of strategy , language, and persona consistency , we construct a comprehensive, principle-driven framework. Specifically , we devise a Critique-Rewrite data generation pipeline, similar to that in [ 4 ].The prompt dataset consists of multi-turn con versational contexts, where each sample is defined by a dialogue history between the user and the assistant, along with the user’ s final request. The Critique-Rewrite is tasked with generating responses to this final turn that are aligned with the inferred user preferences, conditioned on the preceding con v ersational context. In the Critique phase, the model functions as a strict empathetic judger . It first discerns the user’ s underlying intent and needs. It then proceeds to generate a range of responses, graded from the least suboptimal (1-point) to excellent (5-point), with each response accompanied by a detailed rationale. More concretely , the model distills and summarizes ke y information into three components: (1) User P ersona and Contextual Analysis , which captures the user’ s profile and situation; (2) User Prefer ences and Sensitivities , which identifies desirable approaches and potential red lines; and (3) Principle-driven Generation Guidelines , which outlines the criteria for an optimal response derived from a set of core empathetic principles. Concurrently , the model produces fi ve distinct responses that it self-e v aluates with scores ranging from 1 to 5. This process is carefully calibrated to ensure that the analysis is grounded in the user’ s perspectiv e. In our domain, unlike helpfulness or harmfulness, there is no univ ersal standard for what constitutes a good empathetic response. The same reply might be percei ved as o verly forward or boundary-crossing by an a voidant user , yet feel perfectly natural and engaging to someone more e xpressiv e or enthusiastic. Giv en the inherently subjective nature of empathy , it is fundamentally impossible to fully inhabit another person’ s perspective. Consequently , if human annotators were tasked with ev aluating such responses, their judgments would ine vitably drift to ward reflecting their own preferences rather than the user’ s. T o mitig ate this bias, we instead defined a set of meta-empathetic principles and le verage state-of-the-art models’ capacity to dynamically infer user personas and preferences, allo wing the system to generate and assess responses from the inferred user’ s point of view . All results produced in the Critique phas7e are subsequently verified by the corresponding labeler , the individual who initially annotated the data. This closed-loop process ensures the accurate capture of the user’ s empathetic needs. In the Re write phase, the model first condenses the insights from the Critique phase into a set of core guiding principles. It then engages in an iterativ e refinement process to ele v ate the generated responses. This process in volv es restructuring the content, infusing a consistent persona, and polishing the linguistic style. The outcome is a collection of ex emplary 5-point responses in div erse styles, culminating in a single, definiti ve "golden" version. The efficacy of this Rewrite phase is fundamentally predicated on the comprehensiv e nature of the three analytical components generated during the Critique phase. W e tested se veral models for the Critique-Re write routine, including GPT -4[ 20 ], Claude-Sonnet-4.5 and Gemini-2.5-pro[ 9 ], and the best candidate we found for our task is Gemini-2.5-pro. Ne vertheless, ev en with the use of state-of-the-art models, we identified a recurring issue of performance degradation during the Rewrite phase. When refining responses initially rated as 4 or 5 points, the model frequently exhibited a tendency to ward over -revision—alterations that were intended to impro ve quality often resulted in diminished coherence, empathy , or stylistic fidelity . Consequently , the re vised outputs were occasionally downgraded to a 3-point level. T o mitigate this effect, we adopted a conserv ativ e cutoff strate gy: only responses rated 3 points or lower were included in the Rewrite phase, while higher -rated responses were retained without modification. Finally , we construct the training dataset for our empathetic rew ard model by creating preference pairs. These pairs are formed by combining the definiti ve "golden" responses from the Rewrite phase with the lower -scoring responses generated during the Critique phase, as shown in Figure 3. 2.4 RL T raining Data W e construct reinforcement learning (RL) data for two primary domains: empathetic dialogue and daily chit-chat. Both domains are inherently non-verifiable, as their responses cannot be ev aluated against a single ground-truth answer . Howe ver , empathetic dialogue poses a greater challenge, since the quality of an empathetic response is entirely subjective—it depends on how well the model captures and aligns with the user’ s emotional state and contextual preferences. T o address this challenge, we introduce Gemini-2.5-pro as a reference model within the Cri- tique–Rewrite pipeline. For each empathetic instance, Gemini generates responses that are internally scored, and we select those rated at the 3-point level as reference anchors. These references serve as 6 fixed baselines during RL training: the policy model receiv es a positi ve rew ard (+1) only when its rollout produces a response that surpasses the reference in quality . In contrast, daily chit-chat data are trained without the Critique–Rewrite procedure. Instead, we apply a human-likeness reward that encourages natural, coherent, and contextually appropriate con versational behavior . The final RL dataset is the union of empathy-re warded and human-likeness- rew arded samples. This hybrid setup provides complementary learning signals—anchoring the model’ s empathy through reference-based supervision while maintaining general con versational fluency—and ef fectively mitig ates potential out-of-distribution (OOD) drift. T o filter out low-quality reference answers in empathetic dialogue, we adopt a data filtering strategy adapted from seed 1.5[ 26 ]. T o be specific, we use the policy model intended for RL training to perform Best-of-N sampling. Subsequently , we use a pairwise rew ard model to compare the policy model’ s outputs against the Gemini-generated reference answer . Instances in which the policy model achiev es high scores with low standard deviation are discarded. This approach removes overly simplistic samples, ensuring that our training data focuses on dif ficult cases where a high-quality reference provides substantial learning v alue. 3 Method 3.1 Supervised Fine-tuning The Supervised Fine-tuning (SFT) stage is designed not only as a bridge between pretraining and reinforcement learning, but also as a crucial step to ward aligning the model with one of the ultimate forms of Human–AI Interaction—AI companionship. In this domain, models are expected to go beyond general helpfulness and instruction-following: they must communicate with humanlike naturalness, display emotional sensitivity , and often exceed human empathy in understanding and responding to affecti ve cues. T o meet these requirements, our SFT process aims to build a model that performs strongly in vertical domains, such as AI companionship and role-playing, while maintaining broad general capabilities. A common challenge in domain specialization is the degradation of general-purpose skills due to catastrophic forgetting. T o mitigate this, we conduct extensiv e data composition experiments balancing domain-specific and general data sources. The domain-specific data, introduced in Section 2.1, include large-scale companion-style dialogues and role-playing interactions, designed to enhance natural expressi veness, topic control, and emotional perception. The general data consist of open-source instruction-following, commonsense reasoning, mathematics, and code datasets [ 39 ; 2 ; 40 ; 38 ], incorporated to preserve the model’ s fundamental reasoning and task-solving abilities. During fine-tuning, we proportionally mix these data sources to maintain a balance between emotional depth and general competence. Our data composition is illustrated in Figure 4. W e conducted SFT on top of the Qwen3-32B model [ 31 ] to adapt it to our tar get dialogue domain. The model was trained for 4 epochs with a batch size of 128 using the AdamW optimizer . W e set the learning rate to 1e-5, applied a cosine decay schedule, and used a warm-up ratio of 0.1. This configuration provided stable optimization and effecti ve adaptation while retaining the base model’ s general conv ersational abilities. Throughout training, to improve stability and learning efficienc y , we adopt a curriculum that progresses from short, neutral e xchanges to longer , emotion- rich con versations. This staged exposure helps the model gradually acquire conte xtual tracking and empathetic phrasing under controlled dif ficulty , reducing early diver gence and promoting robust generalization. In summary , SFT builds the linguistic and emotional foundation required for subsequent reinforcement learning, enabling the policy model to start with strong empathy and natural con versational fluency . 3.2 Reward Models As mentioned before, the task of dev eloping an AI companion presents unique challenges not found in objecti vely v erifiable domains like mathematical reasoning or code synthesis. Unlike these tasks, where a clear ground truth or a deterministic verifier can provide an unambiguous reward signal, AI companionship is fundamentally subjectiv e. The quality of an interaction is contingent upon 7 76.4% SFT Data Overview (a) Overall Composition 0 10 20 30 40 50 60 70 80 Per centage (%) Role Play Logic Reasoning Math Coding AI Companionship Open Chat Psychology 76.42% 5.14% 5.14% 5.14% 4.45% 2.24% 1.47% (b) Category Br eakdown Figure 4: Illustration of the SFT dataset composition. The dataset integrates our proprietary AI companionship data with sev eral open-source datasets, balancing domain specialization and general cov erage. individual user preferences, which are inherently di verse and personalized. A key challenge arises from this heterogeneity of preferences: a response that one user finds engaging and empathetic may be considered intrusive or inappropriate by another . This precludes the establishment of a single, population-av eraged preference criterion to guide model training effecti vely . T o na vigate this challenge, prior works hav e predominantly relied on methods such as Reinforce- ment Learning from Human Feedback (RLHF)[ 21 ] and Reinforcement Learning from AI Feedback (RLAIF)[ 3 ]. In RLHF , a reward model is trained to output a scalar score representing human prefer - ence. Howe ver , this approach has two principal drawbacks. First, reducing comple x, multi-faceted human preferences to a single scalar value fails to utilize the nuanced reasoning and inferential capa- bilities of modern Lar ge Language Models (LLMs). Second, scalar rew ard models are notoriously prone to "rew ard hacking," where the policy model learns to maximize the reward score in ways that do not align with the true, underlying user preferences. Alternativ ely , the LLM-as-a-judge[ 43 ] paradigm, often employed in RLAIF , leverages the adv anced reasoning of state-of-the-art LLMs to ev aluate responses. While this approach better captures the complexity of user preferences, it introduces a critical dependency on e xternal models. The ef ficacy of an LLM-as-a-judge is highly sensiti ve to the specific phrasing of the judging prompt. Moreover , as external LLM providers continuously update their models, a previously ef fectiv e prompt can become obsolete, leading to instability and requiring a costly and iterativ e process of prompt re-engineering. T o overcome these obstacles, we follow a recent approach: the development of a proprietary generative rew ard model[ 17 ; 14 ; 37 ]. This method is designed to fully leverage the reasoning capacity of LLMs while providing a stable, controllable, and nuanced re ward signal that is independent of external model iterations, thereby offering a more robust solution for optimizing personalized AI companions. 3.2.1 Humanlike Reward The goal of humanlike reward is to provide a humanlike signal that helps the model learn to talk more like a human rather than a machine. Let S human be the space of all human spoken languages and S machine be the space of all machine generated languages, the humanlike re ward is defined as: r humanlike = I [ p ψ ( y ∈ S human ) > p ψ ( y ∈ S machine )] (1) where p ψ is any judge function that takes natural language y as input. While one may propose to use LLM-as-a-judge by acquiring SOT A models, we found that it is hard for SO T A LLMs to do human-tone classification. Specifically , giv en a sentence, the model is asked to tell whether the sentence is from a real human or a machined generated one. W ith a moderate prompt engineering ef f ort, the SO T A models failed to complete the task. As we use this as an external re ward signal to train our policy model, we observe sev ere reward hackings, e ven the re ward keeps going 8 up, the policy model continues to generate strange outputs that decei ves the LLM judger , shown in Append ix B. W e therefore collected these hacked outputs as our hand-crafted held-out hard-ne gati ves and tested several SO T A models. The detailed experimental analysis will be discussed in Section 5.2.1 and the test prompt we used is included in Appendix A.1. Actually , this is not very surprising to us that SO T As beha ve poorly on humanlike judgment tasks, because most models are optimized for helpfulness and harmlessness. Humanlike expression is not the tar geted goal, so this is out of the scope of SO T As. This strongly indicates the necessity of training our o wn humanlike judgement model. T o le verage the chain-of-though (CoT)[ 35 ] ability of LLMs, we treat our humanlike judgement model as another LLM instead of a scalar preference model, just as genRM[17; 14; 37]. That is, Equation 1 can be rewritten as r humanlike = I [ p ψ ( l = human , c | x ) > p ψ ( l = machine , c | x )] (2) where l , c represent the predicted label and CoT respectively , and p ψ in this case is our trained judger LLM, x in this case is some input, depends on wether the judger is context free or not, x could be defined differently . In order to train the humanlike judger, we propose two approaches, which are conte xt free and context aware. For context free judger , we hav e r humanlike = I [ p ψ ( l = human , c | x ) > p ψ ( l = machine , c | x )] (3) In contrast, for context a ware judger , we hav e r humanlike = I p ψ ( l = human , c | y T , h | {z } x ) > p ψ ( l = machine , c | y T , h | {z } x ) (4) where y T is the T -th round’ s response, and h = ( x 1 , y 1 , x 2 , y 2 , . . . , x T − 1 , y T − 1 ) is the history of last T − 1 rounds. For context-free judger, our goal is to let the model distinguish only the expression itself is from human or AI generated reg ardless the conte xt. Howe ver , one dra wback in conte xt-free judger is that it may ov er emphasize the expression superficailly and ignore the in-conte xt con versational logic. Thus, intuitiv ely , context aw are judger should be more coherent, but it may lose some flexibility compared to the context-free judger . 3.2.2 Empathy Reward Unlike rewards for human-likeness, which primarily focus on the surface-lev el fluidity and naturalness of expression, the empathy rew ard is designed to capture the model’ s proficiency in underlying empathetic capabilities. A positi ve reward signal is contingent on the model demonstrating genuine and effecti ve empathy , rather than merely mimicking anthropomorphic expressions. The design of this reward mechanism must address the highly personalized nature of empathetic needs, which vary significantly across individuals. W e posit that a user’ s preference for empathy is highly v olatile and fluid, intrinsically link ed to their recent life e vents, current health status, and transient emotional state. Ho wev er, such preferences cannot be reliably elicited through explicit self- reports—whether by directly asking users about their likes and dislik es or by relying on predefined questionnaires—because users often lack stable or accurate introspection about their own empathetic needs. For instance, a user may claim to prefer highly enthusiastic and emotionally expressi ve responses, yet during periods of substantial stress, the same user might instead f av or a calm, pragmatic assistant that of fers actionable guidance. The mismatch between stated preference and momentary need introduces systematic false-positi ve signals for the re ward model when supervision is deri ved solely from the user’ s conscious self-assessment. T o address this gap, we introduce User Context Mining , a principled approach that infers the user’ s latent and temporally local empathetic preference directly from their recent interaction patterns with the LLM, rather than relying on potentially unreliable self-descriptions. This enables the reward mechanism to adapt to the user’ s actual, dynamically ev olving needs. Such volatility makes static rules or fixed heuristics fundamentally insufficient for reliable reward assessment. Consequently , empathy e v aluation must be treated as a continuous and dynamic inference process. T o achie ve this, the reward function le verages the LLM’ s CoT capabilities [ 35 ] through a two-stage dynamic inference 9 procedure: dynamic profile infer ence followed by alignment inference . Dynamic profile inference requires the model to infer a user profile or persona by analyzing the preceding con versational conte xt; based on this inferred profile, the model then determines whether its proposed empathetic strategy aligns with the user’ s immediate and specific needs, which we term alignment inference. Ne vertheless, we can still establish a set of uni versally representativ e meta-principles. These principles are not rigid rules, but rather high-le vel guidelines. They instruct the model on (1) how to ef fectiv ely reason about the user profile based on historical conte xt, and (2) ho w to le verage that profile to deli ver tailored, personalized empathy—ef fecti vely achie ving a “thousand-people, thousand-faces” standard of interaction. Let S x T ,h empathy be the set of all ideal empathetic responses giv en the last-round query x T and chat history h , where y is the model-generated response and r is the reference answer . The empathy reward is defined as: r empathy = I h p ϕ ( y ∈ S x T ,h empathy | x T , h ) > p ϕ ( r ∈ S x T ,h empathy | x T , h ) i , (5) where p ϕ is our trained generati ve empathetic judge. This reward computation method is perfectly aligned with the training task of our Empathy Rew ard Model, ef fectiv ely harnessing its full capabilities. Crucially , in the AI companionship setting—where a single “correct” answer does not exist—the use of high-scoring reference answers guides the optimization process and allows the model to better incorporate human preferences. W e explore this concept using W orldPM [ 33 ], a scalar reward model, and in Section 5 provide details that demonstrate the necessity of the reference answer . T wo-Stage T raining Framework T o construct a scalable empathetic judge, we adopt a two-stage training frame work designed to support W eak-to-Strong generalization [6], where a smaller model bootstraps a larger one through iterati ve data refinement. Instead of following a con ventional kno wl- edge distillation paradigm, we e xplicitly redefine the small-parameter model as a high-throughput Reasoning Path Sampler and use its trajectories to driv e model scaling and iterativ e data ev olution. • Stage I : W e use Qwen3-8B as the base model. W e begin by training a preliminary generator through a one-epoch supervised fine-tuning (SFT) cold start on the seed data, and then perform D APO alignment training. T o ensure that this model is reliable as a sampler, we conduct an A/B option permutation consistency test under the Pass@1 setting to reduce positional bias, confirming its basic capability to provide valid candidate samples. W e then employ this 8B model for large-scale rejection sampling: under strict discrimination criteria (introduced later), trajectories with flawed reasoning logic or mismatched answers are filtered out, while only logically closed-loop “golden” reasoning paths are retained. Combined with targeted human revie w and lightweight AI-assisted refinement to correct stylistic artifacts, these curated trajectories form a high-quality dataset, Dataset V2, whose reasoning quality can surpass the inherent capability ceiling of the small model. • Stage II : T o implement the W eak-to-Strong generalization objecti ve [ 6 ], we upgrade the base model to Qwen3-32B and perform an SFT cold start(1 epoch) on Dataset V2, followed by DAPO training. T o mitigate the distributional limitations of SFT data and enhance robustness in unseen domains, we further introduce a Recursive Self-Correction mechanism into the system prompt during the RL training phase. This instruction, activ ated only during RL exploration, encourages implicit secondary reasoning and logical backtracking before the model commits to a final verdict, thereby improving decision reliability in complex empathetic scenarios. This two-stage pipeline yields two empathetic judgers—a lightweight 8B model and a stronger 32B model—which are ev aluated in Section 5.2.2. Additionally , the model was trained for one epochs with a batch size of 64 using AdamW , a learning rate of 1 × 10 − 6 with 300 warm-up steps followed by cosine decay , low/high clipping thresholds of 3 × 10 − 4 and 4 × 10 − 4 , a KL loss coefficient of 0.001, eight samples per prompt, a response length cap of 4K tokens, and a length penalty of 0.1. Reward Function In optimizing GenRMs, the re ward function design directly controls the direction and quality of the gradients. Unlike traditional linearly weighted rew ard compositions, we construct a discrete multiplicative reward mechanism based on logical “ AND” gating. For a giv en input prompt x and a model-generated response y containing the reasoning process r and the final answer 10 a , the empathy re ward used during RL is defined as: R empathy ( x, y ) = R process ( r ) · r empathy , (6) where: • r empathy acts as a hard constraint, ensuring that any reasoning path leading to an incorrect or misaligned outcome—no matter ho w well written—recei ves a zero score. This ef fectiv ely prev ents “rew ard hacking” behaviors such as guessing answers or optimizing only for superficial style. • R process ( r ) ∈ [0 , 1] represents process quality and f ormat compliance . It is a normalized coefficient jointly determined by the recall rate of ke y reasoning steps and C/I (Correct- ness/Instruction) constraints. The core moti vation for the multiplicative form in Equation 6 is to approximate logical entailment : we ef fectiv ely optimize the joint ev ent P ( correct reasoning ∩ correct outcome ) , rather than a linear superposition of their mar ginal contributions. This sparse yet high-precision signal, combined with the D APO algorithm, allows the model to anchor onto genuinely v alid reasoning patterns within a vast search space. 3.3 RL T raining For non-verifiable problems, a robust and precise reward system is crucial for RL training. Specifically , the reward system should not only effecti vely prev ent reward hacking, but also its rew ard signals must be tightly aligned with the intended training objecti ves. T o this end, based on our empathetic companionship task, we propose a fine-grained rew ard framework. Our re ward framework consists of two components: Empathy Reward and HumanLike Rew ard, where the total reward signal is demonstrated in Equation. Empathy Rew ard guides the model to produce highly empathetic responses, while HumanLike Reward encourages the model to adopt a captiv ating, human-like conv ersational style. By combining these components, we aim to train a model that both fully satisfies users’ empathetic needs and deliv ers a con versational experience comparable to chatting with a real person. R total = R empathy + R humanlike (7) W e compute the Empathy Reward and Humanlike Reward using the generati ve reward model described in Section 3.2.2 and Section 3.2.1 respectively . The whole training pipeline, including rew ard model training, is build upon the V eRL[ 28 ] frame work. T o simplify training, we deploy our generativ e reward models as services, and request the reward signal once a single rollout is fully generated. 4 Evaluation Framework Our ev aluation pipeline is structured into three distinct stages. First (Stage 1), we assess the model’ s foundational capabilities using publicly available benchmarks to establish a general performance baseline. Second (Stage 2), we ev aluate its basic cognitive and emotional intelligence (IQ and EQ) through proprietary , static benchmarks. These benchmarks utilize multi-turn dialogues with fixed contexts, requiring the model to respond only to the final turn. Finally (Stage 3), we observed that models could exploit these static conte xts, which often act as cues for stylistically similar responses. T o mitigate this, we de veloped a dynamic EQ framew ork where no context is provided, compelling the model to rely solely on its internal capabilities. The overall e valution pipeline is shown in Figure 5. 4.1 General Evaluation For the ev aluation of the model’ s general-purpose capabilities, we established a benchmark suite specifically tailored to the requirements of our AI companionship scenario. W e selected three distinct test sets: IFEV AL, ChineseSimpleQA, and CharacterEval. The rationale for this curated selection is as follows: 11 Evaluation 1: General Eval (Low-Dimension Foundation) Evaluation 2: Static IQ/EQ (Mid-Dimension Reasoning) Evaluation 3: Dynamic EQ (High-Dimension Emergence) IQ ( Cognitive ) EQ ( Affective ) Recursive interaction Multi-Turn Dialogue Loop Quantitative Evaluation (EPM) & Qualitative Evaluation (NEE) IFEVAL (Prompt Control) ChineseSimple QA (Cultural Knowledge) CharacterEval Director Agent Actor Agent Test Model Global Story Context Full Character Profile EPM Vector State Director Guidance (Structured Decision Toolkit) 1. Reveal Memory 2. Adjust Strategy 3. End Conversion Persona & Character Profile Thinking-Budgeted embodied Generation LLM-as-a-Judge Calibrated Score Ref ined Rub ric Ref ined Rub ric Status RDI Total Energy Density Path Tortuosity Alignment Penality Rate Outcome Metrics Effiency Metrics Stability Metrics EPM Modeling Graph EPM-index Natrualness Rhythm Narrative Depth NEE Metrics EPM-index Final Score Figure 5: Comprehensive AI companionship e valuation pipeline • Instruction Follo wing (IFEV AL)[ 44 ]: The model’ s ability to strictly adhere to instructions is critical for our application. W e utilize IFEV AL to measure this capability , as it directly impacts our product team’ s ability to shape and control the AI’ s persona, tone, and behavior . A high instruction-following fidelity allows product managers to effecti vely implement target con versational effects merely by adjusting the character’ s system prompts. • Chinese Contextual Kno wledge (ChineseSimpleQA)[ 11 ]: T o ensure the model is relatable and ef fectiv e for our target audience, it must possess a broad and accurate base of general knowledge within a Chinese cultural context. W e employ ChineseSimpleQA to assess this world kno wledge, ensuring the model’ s responses are culturally relev ant and align with the background of Chinese users. • Human-like Interaction (CharacterEv al)[ 32 ]: While CharacterEval offers a multi- dimensional analysis, we deliberately focus our e valuation exclusi vely on its human-lik eness dimension. For our emotional companionship use case, attrib utes like believ able persona and natural interaction are paramount. W e found other dimensions, such as Persona-Beha vior or Kno w Hallucination to be less applicable and not aligned with our primary objective of creating an authentic, human-like companion. This combined ev aluation methodology allows us to holistically assess the model’ s fitness for our specific product goals, prioritizing practical prompt control, cultural resonance, and human-like interaction. 12 4.2 Static IQ and EQ Evaluation Follo wing the assessment of general capabilities, we conducted a more focused ev aluation to probe the model’ s performance on core competencies directly rele vant to our AI companionship domain. T o this end, we constructed a static ev aluation set designed to mirror the structure and complexity of authentic user interactions. This dataset is composed of multi-turn dialogues, each containing 15 rounds of con versational history . This history , meticulously curated and authored by human annotators, serv es to establish deep conte xt, emotional tone, and memory predicates. The model’ s task is to generate a response only for the final, 16th turn, which acts as the target test prompt. This benchmark consists of two distinct sets, an IQ test set and a EQ test set respectiv ely . 4.2.1 Static Intelligence (IQ) Set This subset is designed to test fundamental cognitive and con versational mechanics that are essential for a coherent and believ able interaction. The test prompts are specifically structured to ev aluate the model’ s proficiency in: • Persona Consistency: The ability to correctly distinguish between speaker and listener (i.e., I vs. you) and maintain a consistent identity . • Contextual Recall: The capacity to accurately access and utilize information provided within the 15-turn dialogue history . • T emporal A wareness: The correct perception and handling of time-related concepts and con versational flow . • Grounded Commonsense: The application of real-world knowledge within the specific constraints of the ongoing con versation. 4.2.2 Static Empathy (EQ) Set This subset assesses the model’ s affecti ve intelligence. For these test cases, the final (16th) turn is intentionally constructed to present a div erse array of scenarios requiring a nuanced, empathetic response, such as a user expressing distress, celebration, or vulnerability . T o score the model outputs from both the IQ and EQ sets, we employed an LLM-as-a-judge framew ork. W e utilized Gemini 2.5 Pro as the core judging model. A critical aspect of our methodology inv olved the iterativ e refinement and “fine-tuning of the judger prompt—a highly-structured set of instructions and criteria. This prompt engineering was essential to ensure that the automated judgments are objectiv e, reproducible, and consistently aligned with our human-defined rubrics for fairness and accuracy . 4.3 Dynamic Empathy Evaluation 4.3.1 Overview T raditional empathetic dialogue ev aluation typically rely on static single-turn datasets or simplistic multi-turn prompts, failing to capture the dynamic, long-range nature of deep emotional interactions[ 8 ; 41 ; 12 ]. T o address this limitation, we propose the Anthropomorphic Empathy Ev aluation Frame work. This frame work is designed to provide an objecti ve, rigorous, and physically interpretable method for quantitatively assessing the comprehensiv e performance of empathetic dialogue models. The framew ork consists of two interdependent core layers: • Simulation Layer (Anthropomor phic Cognitive Sandbox): Serving as the simulation en- vironment, this layer provides a high-fidelity social interaction arena designed to reconstruct complex human emotional and cogniti ve dynamics, offering an e volutionary ground for AI beyond scripted interactions[23; 45]. • Metric Layer (Empathy Ph ysics Model, EPM): Serving as the measurement layer , this is a nov el psychophysical cognitiv e modeling approach. It translates abstract psychological empathy into computable physical quantities—specifically , modeling the complex processes 13 of psychological healing and companionship as a process of doing work against emotional resistance within a high-dimensional vector space[25; 23]. By combining dynamic dialogue simulation with rigorous psychophysical modeling, this framework offers an interpretable ev aluation method with high ecological validity[ 19 ; 45 ]. It assesses not only what the model says but also the trajectory and efficac y of its intervention over time. V isualizing interaction trajectories allo ws us to intuiti vely identify strate gic preferences (e.g., leaning towards emotional soothing vs. cognitive restructuring)[ 46 ; 7 ], and analyze characteristic patterns in failure scenarios (like repetiti ve looping or disorientation), providing concrete diagnostics for model training iteration. 4.3.2 Core Mechanism Design (1) Simulation Layer: Multi-Agent Cognitive Architectur e and Anti-Collusion T o mitigate the inherent verbal biases and potential collusion risks of LLM self-e valuation —limita- tions that remain pre valent in frame works like SA GE[ 41 ], where the conflation of dialogue generation and scoring roles creates structural vulnerabilities—our simulation layer incorporates a multi-agent cognitiv e architecture inspired by the human cognitive di vision of labor . By enforcing strict informa- tion isolation mechanisms, we ensure the authenticity and objectivity of the interactions. • Director Agent (Holistic Cogniti ve Or chestration): Simulating high-level e xecutiv e con- trol, this agent does not participate in dialogue directly . Instead, it dynamically orchestrates the simulation based on an omniscient perspectiv e (plot, persona, real-time EPM state) via a structured Function Calling mechanism. It simulates complex human con versational thinking, not by follo wing a script, but by reasoning dynamically based on dialogue progress. It wields a rich toolbox to retrie ve memories, propel the plot, or adjust the Actor’ s strategy based on EPM feedback (e.g., instructing stronger defensiveness). This mechanism endows the sandbox with high dynamism and fidelity , making every dialogue a unique e volutionary process. • Actor Agent (Situated Dynamic Acting): Simulating emotional experience and imme- diate reaction regions. T o prev ent assistant-like behavior and adjudication collusion, the Actor operates under strict evaluation isolation (knowing only current settings, unaware of ev aluation criteria). It relies on a complex user generation and simulation pipeline that extracts and combines deep features for diverse personas, needs, and open-ended scenarios[23; 45; 33; 19; 18]. For the test library , we generated over 500 multifaceted case profiles by drawing upon internal research insights and analyzing the target demographic’ s empathetic need characteristics. These cases cover di verse personas, psychologies, layered life experiences, and specific scenarios with potential storylines. Notably , dynamic con- tent elements (e.g., critical memories, plot twists) are held latent, pending inv ocation by the Director for real-time enactment—a mechanism that maximizes unpredictability and realism. (2) Metric Layer: EPM V ector Space and Evidence-Anchored Evaluation EPM upgrades empathy ev aluation from static feature matching to dynamic computation by introduc- ing the physical metaphors of energy and work.[ 12 ; 22 ; 29 ] In this framew ork, a user’ s psychological distress is no longer an abstract concept but is concretized as resistance or a potential energy trap. The empathy model’ s response is modeled as an applied force on the user’ s psyche. If the direction of this force aligns with the user’ s deep-seated needs (i.e., directional alignment), it can ef fectively propel the user to ov ercome psychological resistance and move to wards a state of equilibrium. This effecti ve propulsion process is defined as doing work, and its cumulative amount is the effecti ve energy . EPM thus translates in visible social signals into visible, interpretable physical trajectories and energy curv es, allowing us to intuiti vely assess whether an intervention is highly ef ficient (half the work, double the ef fect) or ineffecti ve (heading south to go north). Specifically , we map the empathetic interaction into an orthogonalized MDEP three-dimensional psychological measurement space (C-axis: Cognitiv e Restructuring, A-axis: Af fective Resonance, P-axis: Proactive Empowerment)[ 27 ; 36 ]. The origin represents the ideal state of psychological balance, while the user’ s initial state is quantified as a negati ve deficit v ector . Each model reply is viewed as an action vector ( v t ) applied to the user’ s psychological state, containing independent 14 bidirectional scoring of positiv e progress (Prog) and negativ e regression (Neg) across all three CAP axes. The dialogue process is modeled as the dynamic e volution and accumulation of the user’ s psychological state trajectory towards the ideal origin under the continuous action of these discursiv e forces. T o address the core challenge of instability when using LLMs as judges, we dra w on RLHF reward modeling approaches[ 21 ; 12 ; 8 ]to design a rigorous evidence-anchored bi-directional e valuation system. Adopting the LLM-as-Judger approach[ 40 ; 46 ; 13 ], we selected Gemini 2.5 Pro as the judge, giv en its SO T A performance in user profile and complex EQ comprehension based on extensi ve benchmarks. It forces the reduction of the LLM’ s task from subjecti ve scoring to objecti ve qualitati ve classification—first exhausti vely extracting progress/re gression evidence, then matching e vidence against predefined Behavioral Anchors for classification[ 24 ], and finally mapping to numerical v alues through deterministic rules. This ensures the ev aluation process is based on objective e vidence rather than subjectiv e preference. T o achie ve deep alignment with the specific user scenario, our frame work rigorously controls both the initialization of the deficit and the dialogue scoring. The initial deficit is not stochastically generated but is comprehensi vely deri ved from the user’ s personality , experiences, empathetic needs, and the narrativ e progression. Concurrently , the Judge agent ev aluates replies dynamically relative to the immediate user profile. This focus on profile alignment ensures ecological validity , measuring the model’ s empathetic capacity toward a specific persona in a situated context, rather than as a generalized metric. 4.3.3 Evaluation Dimensions and Metric System (1) Quantitative Ev aluation (Based on EPM) This section details the quantitati ve assessment system deri ved from EPM, designed to objectively measure the multi-dimensional performance of models in empathetic interactions. Core Philosophy: Open Comprehensive Evaluation P aradigm T raditional evaluation benchmarks often attempt to calculate a single comprehensi ve score for leaderboard ranking through predetermined fixed weight combinations. Howe ver , empathy is a highly complex social signal interaction, and different application scenarios have vastly different demands on model capabilities. An ef ficient model that excels in scenarios requiring quick problem- solving might perform poorly in scenarios requiring long-term, patient companionship due to a lack of stability[ 45 ; 5 ]. Therefore, the EPM framework theoretically abandons the single fixed weight approach and proposes an Open Comprehensive Ev aluation Paradigm. Its core objective is not to provide an absolute ranking b ut to utilize the rich quantitativ e metrics provided by EPM to depict a unique capability profile for each model, clarifying its strengths, weaknesses, and trade-of fs. Like a strategic horse race, it helps users select the most suitable model for specific task scenarios. W e propose a methodology for dynamically adjusting e valuation emphasis based on application scenarios, for example: • Crisis Intervention Scenario: Extremely high weight is giv en to process stability metrics (such as high positiv e energy ratio, extremely lo w penalty rate), with the primary goal being safety and robustness. • Long-T erm Companionship Scenario: High weight is giv en to outcome metrics and positiv e energy , with higher tolerance for path tortuosity , focusing on deep connection. • T ask-Oriented Counseling: High weight is given to process efficienc y metrics (such as low turns, high density), focusing on ef ficient problem-solving. Through this paradigm, we can identify typical characteristics of different models, such as robust players that perform balanced across all scenarios, or surprise players that perform stunningly at times but with high volatil ity . This perspectiv e prompts us to recognize the strengths and weaknesses of each model, rather than simple high or low scores. Utilizing the refined trajectory data generated by the simulation sandbox, a quantitati ve metric system containing both outcome and process dimensions is constructed. Metric Con version and Calculation Logic Explanation 15 T o ensure scientific rigor in scoring, the aforementioned ra w physical metrics are not directly summed up but con verted following a set of Scientifically-Defined Open Benchmark Inde x logic. (1) Scientific Anchoring: All calculation benchmarks are strictly anchored to the physical definition of the task (such as initial deficit r 0 ) or the mathematical theoretical limit of the scale (such as maximum intensity ρ max ), rather than arbitrary empirical values. T able 1: EPM Process Metrics — Measuring Path Strategy , Efficienc y , and Stability (a) EPM Process Efficienc y Metrics — Measuring Time Cost and Strate gic Directness Metric Name Symbol Core Meaning and Ev aluation V alue Empathy Density ρ Measures av erage intervention intensity . The “gold content” of effecti ve empathy energy deli vered on av erage per dialogue turn. A verage Effective Projection s proj Measures single-turn effecti veness. The average ef fective projection component of the action vector along the ideal direction per turn. Path T ortuosity τ Measures strategic directness. The ratio of the actual trajectory length to the straight-line displacement between start and end points. (b) EPM Process Stability Metrics — Measuring Interaction Smoothness, Directional Correctness, and Safety Metric Name Symbol Core Meaning and Ev aluation V alue A verage Alignment cos θ Measures directional consistency . The av erage cosine value of the angle between the model’ s intervention direction and the ideal healing direction. Positi ve Energy Ratio R pos Measures process smoothness. The proportion of turns generating positiv e propulsion out of total turns. Perf ormative Penalty Rate R pen Measures the intensity of negati ve behavior . Quantifies the av erage punishment received by the model due to inappropriate remarks (e.g., lecturing, indifference). Note: Quantitative evaluation supports the “Open Compr ehensive Evaluation P aradigm, ” allowing dynamic adjustment of metric weights based on application scenarios for capability pr ofiling. T able 2: EPM Outcome Metrics - Measuring Final Efficacy and T otal W orkload Metric Name Symbol Cor e Meaning and Evaluation V alue T ask Completion Status S tatus Final success/failure determination based on the “T rinity V ictory Condition” (geometric/positional achiev ement and sufficient ener gy). Relative Distance Impr ovement RD I Measures the thoroughness of healing. Calculates the percentage improv ement of the user’ s final psychological state relativ e to the initial deficit. Cumulative Effecti ve Energy E total Represents total empathetic work done. Measures the total effecti ve intervention e xerted by the model along the ideal healing direction throughout the dialogue, reflecting the magnitude of “substantiv e effort. ” Energy Surplus E surplus Measures empathy abundance. Calculates the additional energy support pro vided beyond the basic requirement. T otal MDEP Net Score S net Measures total empathy quality . The sum of cumulativ e net scores obtained in the three dimensions of C/A/P . 16 (2) Classification Con version: • For unbounded cumulati ve metrics (such as energy , net score), their multiplier relative to the scientific benchmark is calculated, forming an uncapped open index to reflect the excess performance of e xceptional models. • For bounded ratio metrics (such as RDI, alignment), standard linear mapping is adopted to con vert their physical boundaries into [0, 100] interv al scores. (3) Synthetic EPM-Index: Finally , through weighted synthesis, an open EPM benchmark index is output. Index=100 represents precisely achie ving the scientific benchmark, while Index>100 intuiti vely reflects the excellence multiplier be yond the benchmark. EPM-Index = 0 . 4 · ˜ S Outcome + 0 . 2 · ˜ S Efficienc y + 0 . 4 · ˜ S Stability (8) (2) Qualitative Ev aluation (Based on NEE) Although EPM provides rigorous physical quantitative benchmarks, human complex empathy ex- perience still possesses many dimensions dif ficult to reduce purely to numerical values (such as naturalness of language, rhythm of emotional interaction, etc.)[ 1 ]. T o capture these phenomenological characteristics crucial for user experience, we constructed the Narrativ e & Experience Evaluator (NEE) as an independent high-lev el appreciation layer . It follo ws the principle of diagnosis first (context), ev aluation later (experience), adopting a simulated judicial revie w process to conduct a holistic critical assessment of the dialogue. Core Qualitativ e Dimensions: • Linguistic Naturalness : Ev aluates the model’ s ability to eliminate machine-like and artifi- cial feelings in language expression, aiming to distinguish between natural anthropomorphic communication and stif f text generation. Rew ards lo w-resistance expression and penalizes performativ e over -embellishment. • Contextual Rhythmic Adaptation : Evaluates the model’ s ability to regulate emotional energy , examining whether it can provide ener gy resonance attuned to the user’ s state at the correct timing (e.g., receiving during high-ener gy catharsis). • Narrative Arc and Depth : Examines the aesthetic quality of the entire dialogue as a meaning-making process, assessing narrativ e coherence, depth of cognitiv e restructuring ability , and the existence of penetrating highlight moments. T o av oid potential aesthetic preferences and systemic biases brought by a single revie wer model, NEE adopts a Joint Evaluation approach similar to an expert committee. W e integrated four top large models with distinct e xpertises in different dimensions to form a complementary re view panel (GPT -4o, Claude 3.5 Sonnet, Gemini 2.5 Pro, DeepSeek R1). Through this joint revie w mechanism, we are able to obtain more div erse, objective, and high-consensus qualitati ve e valuation results. (3) Comprehensi ve Scor e Calculation The final comprehensive score of the model aims to balance objectiv e physical benchmarks with subjectiv e experience. W e adopt a weighted fusion strategy , combining the EPM quantitativ e index with the NEE qualitativ e score. The standard calculation uses balanced weights (50/50), defining the Final Comprehensiv e Score (FCS) as follows: FCS = 0 . 6 · EPM-Index ∗ + 0 . 4 · NEE-Score ∗ (9) where the superscript ( ∗ ) indicates the specific domain of each metric, representing the quantitati ve physical benchmark and the qualitati ve subjecti ve experience, respecti vely . This mechanism ensures that the final result reflects not only the work done and efficiency of the model at the physical lev el but also fully embodies its naturalness and depth at the human interaction experience le vel. 17 5 Results and Analysis 5.1 SFT The performance of our finetuned model on the ev aluation benchmarks is in T able 3 and T able 4. Our SFT procedure enhances the model’ s humanlike expressi veness without compromising its general capabilities. Notably , wthe model shows a slight improvement on the IFEv al[ 44 ] benchmark, indicating that instruction-follo wing ability is further strengthened after fine-tuning. Unfortunately , we observed a noticeable degradation in both our priv ate IQ and EQ benchmarks after SFT . This decline is largely attributable to the imbalance in the training mixture: high-quality AI companionship data accounts for only 4.45% of the SFT corpus, whereas role-play data dominates. Since role-play interactions differ substantially from our tar get AI-companionship domain, the supervised finetuning stage naturally steers the model away from the beha viors emphasized in our benchmarks. That said, this degradation is not a major concern. In our pipeline, SFT primarily serves as a cold start to initialize the policy , while the RL stage is responsible for the substantiv e alignment and restoration of domain-specific capabilities. T able 3: Ev aluation results on public benchmarks and our priv ate static IQ benchmark. Qwen3-32B serves as the base model, while Qwen3-32B-SFT and Qwen3-32B-RL denote our supervised fine- tuned and reinforcement learning fine-tuned v ariants, respectively . W e also included the ev aluation results from a range of leading open-source and closed-source models to provide a comprehensi ve comparativ e context. Models IFEval ChineseSimpleQA CharacterEv al IQ T est Qwen3-32B 79.02 44.03 2.85 45.45 Qwen3-32B-SFT 81.29 42.7 3.08 29.09 Echo-N1(ours) 82.61 42.63 3.12 34.55 Gemini2.5-pro 85.37 75.17 3.23 72.7 Kimi-K2 88.85 74.23 2.99 52.7 Doubao1.5-Chracter 80.94 56.93 2.92 60 Qwen3-235B 88.97 82.3 2.92 58.2 T able 4: W in rates in pairwise preference e valuations. Each entry reports the win rate of the row model against the column model. For each benchmark query , both models generate responses conditioned on the same context, and a preference-aligned e valuator prompt is used to determine the winner . Vs. Kimi-K2 Qwen3-32B-SFT Qwen3-32B Doubao1.5-Character Qwen3-32B-SFT 21.2% - 35.2% 40.7% Qwen3-32B 27.4% 64.8 % - 58.7% Doubao1.5-Character 18.4% 59.3% 41.3% - Echo-N1(ours) 38.0% 65.9% 79.9% 95.5% 5.2 Reward Models 5.2.1 Humanlike Reward W e ev aluate both humanlike and empathetic re ward models under the “LLM-as-a-judge” paradigm and compare them against strong proprietary baselines. As a starting point, we consider SOT A LLMs as direct judges. Whi le this provides a natural baseline, our results rev eal a fundamental limitation: humanlike and empathetic ev aluation requires modeling subjective, socially grounded aspects of human behavior—capabilities for which current frontier LLMs are not explicitly optimized. Because these models are primarily trained for reasoning-centric tasks and assistant-style interactions, they tend to produce generic, polite outputs rather than genuinely humanlike con versational behavior . As a result, they e xhibit poor reliability when tasked with discriminating subtle preference dif ferences. T o empirically v alidate this weakness, we apply strong prompting to Gemini-2.5-Pro, Claude-4- Sonnet, and GPT -5 and ev aluate them on humanlikeness judgment. As shown in T able 5, all models 18 perform poorly on both the standard test set and our curated hard negativ es—instances that are trivial for humans but systematically misclassified by LLMs. These observations highlight an inherent flaw in the “LLM-as-a-judge” paradigm for ev aluating humanlik eness: the models lack the representational grounding required for stable preference discrimination. Motiv ated by these findings, we train dedicated reward models. For the humanlik e task, we report results for two variants—a context-free model and a context-based model—whose training setup is detailed in Section 2.2. Although the context-free model performs reasonably when e valuated in isolation, it induces sev ere reward hacking during RL: the policy over -optimizes for surface- lev el linguistic naturalness while ignoring logical consistency . In contrast, the context-based model provides a more rob ust balance between naturalness and contextual coherence, making it the only viable option for downstream reinforcement learning. T able 5: Judger accuracy on the humanlike-e xpression test set. Hard Negati ves denotes our manually curated adversarial e xamples designed to challenge models prone to superficial pattern matching. Models T est Set Hard Negati ves Gemini-pro-2.5 42.13% 12.5% GPT -5 43.66% 28.1% Claude-Sonnet-4.5 50.72% 32.3% Humanlike Judger w/o context (ours) 90.83% 90.6% Humanlike Judger w/ context (ours) 89.45% 31.3% Qwen3-8B 43.28% 50% 5.2.2 Empathy Reward The setting for empathetic ev aluation differs markedly from the humanlike case. With a carefully engineered prompt—co-designed with expert psychologists—Gemini-2.5-Pro can demonstrate non- trivial competence in dynamic user-preference inference and empathetic assessment. Howe ver , its performance relies critically on extremely long prompts, often requiring thousands of tokens per inference. T runcating the prompt leads to abrupt performance collapse, indicating that the model ov errelies on full conte xtual scaf folding and cannot be made cost-ef ficient through simple prompt compression. This makes such prompting strategies impractical for do wnstream RL, where thousands of online ev aluations would result in prohibiti ve latenc y and API costs. W e therefore train our o wn empathetic reward models, and report results in T able 6. W e e valuate both 8B and 32B v ariants [ 31 ] and observe a clear scaling trend: larger models consistently achiev e stronger empathetic discrimination performance. T o systematically ev aluate these models, we construct two test sets: (1) an in-distribution set in which dialogue histories and preference labels come from the same annotators used during re ward model training, and (2) an out-of-distrib ution set in which preference candidates are generated by Kimi-K2 [ 30 ]. This dual-setting design enables us to isolate both absolute judging capability and robustness to distrib ution shift. As sho wn in T able 6, our 32B empathetic re ward model achie ves 93.30% accurac y in-distribution and 69.00% OOD, outperforming all open-source baselines by a substantial margin. The 8B variant achiev es 83.15% and 53.50% , confirming the expected scaling beha vior . Interestingly , while Gemini obtains the strongest OOD score ( 91.97% ), it performs worse in-distribution, suggesting that empathetic alignment requires reasoning patterns not fully captured by general-purpose con versational models. The gap between our two variants also reflects the benefit of the data-ev olution pipeline described in Section 3.2.2, where “exploration via sampling” combined with “filtering via hard constraints” successfully extracts reasoning paths that surpass the intrinsic capability ceiling of the small model. Ablation on Process-A ware Reward. W e isolate the contribution of the process-aware term R process ( r ) by comparing the full multiplicati ve rew ard with an outcome-only v ariant that sets R process ( r ) = 1 for all trajectories. The outcome-only baseline quickly saturates the scalar em- pathy signal and subsequently exhibits clear de gradation on the held-out v alidation set—an indication of rew ard overfitting. By contrast, the full reward maintains stable and consistent improvements throughout training. Manual inspection further re veals that removing R process ( r ) leads the policy to exploit stylistic artifacts and produce logically fragile responses, whereas the full reward sup- 19 presses such modes. These results demonstrate that R process ( r ) is essential not only for stabilizing optimization but also for pre venting re ward hacking and preserving rob ust empathetic reasoning. Overall, our experiments reveal three key findings : (1) general-purpose LLMs, ev en with strong prompting, are not reliable judges for humanlike or empathetic ev aluation; (2) for reward models, both context-based modeling and the process-aware multiplicativ e term R process ( r ) are essential to prev ent reward hacking and to sustain genuine improv ements on held-out validation tasks; (3) empathetic reward models benefit substantially from scaling and from the curated data-ev olution process, enabling the 32B model to surpass proprietary baselines on in-domain human preference tasks while maintaining competitiv e robustness under distrib utional shift. Detailed prompts used in Stage II are provided in the A ppendix A.2. Figure 6: Ablation of the process-aware term R process ( r ) in Eq. 6. The figure reports rew ard scores (blue, left axis) and v alidation Pass@1 (red, right axis) for the full re ward (solid) and the outcome-only variant (dashed). T able 6: Performance comparison across in-domain (T est Set) and out-of-domain (T est Set OOD) splits. For Pass@1 (A ∩ B), a trial is considered successful only if the model generatively passes (Pass@1) both v ersions of a question, where the correct option’ s position is swapped between A and B. T ype Model T est Set T est Set (OOD) scalar W orldPM 98.00% 78.29% generativ e pass@1 (A ∩ B) Gemini 2.5 Pro 88.83% 91.97% Qwen3-8B 76.54% 50.56% Qwen3-32B 77.65% 56.57% Empathy Judger-8B (ours) 83.15% 53.50% Empathy Judger-32B (ours) 93.30% 69.00% 5.3 Echo-N1 In this section, we study how dif ferent reward-modeling choices af fect downstream policy optimiza- tion in empathetic dialogue tasks. While validation accuracy provides a useful signal, it is often insufficient for understanding a re ward model’ s real behavior during RL—where stability , resistance to rew ard hacking, and the structure of the reward signal matter just as much as raw correctness. W e therefore e valuate se veral aspects of re ward model design, including comparing GenRM with a scalar baseline, examining rob ustness during RL, and analyzing how reference-answer -based and discrete rew ards influence training dynamics. T ogether , these experiments provide a practical view of what makes a re ward model usable and reliable for optimizing empathetic con versational agents. 20 5.3.1 GenRM vs Scalar Figure 7: Training stability comparison across re ward modeling strategies. Empathy GenRM successfully realizes stable training, maintaining controlled entropy and steady reward gro wth unlike the scalar baseline (W orldPM) which suffers from se vere re ward hacking. Figure 8: Robustness comparison across reward modeling strategies. Ablation results sho w that reference-answer-based reward computation and discrete (binary) rew ards significantly improve robustness and mitigate re ward hacking. T o verify GenRM’ s advantages in empathetic scenarios, we designed a comprehensiv e suite of experiments that rigorously compares GenRM with a scalar reward model. Specifically , we fine-tuned W orldPM-72B [ 34 ] on the same preference dataset used for GenRM. W e e valuated both models on a hand-curated preference dataset; as shown in T able 6, W orldPM-72B achie ved a slight win. Howe ver , validation performance alone does not fully capture rew ard model quality . A strong rew ard model must not only perform well on a valid dataset, but also pro vide reliable rew ard signals during RL and resist reward hacking. W e therefore ran RL experiments using either W orldPM or Empathy GenRM as the re ward model to answer three questions in practice: which model is better , whether reference-answer-based re ward computation helps, and whether discrete rewards outperform continuous rew ards. Who is more r obust, W orldPM or GenRM? 21 W orldPM exhibited pronounced re ward hacking in early training under both DAPO and GRPO. The model strongly preferred longer responses reg ardless of content quality , causing response length to spike within a few steps until hitting the maximum allowed length. This indicates that the policy learned to inflate verbosity to collect higher re wards, re vealing se vere verbosity bias in W orldPM. W e attribute this to the re ward-model training data. T o ensure quality , we kept only high-scoring answers as the chosen set; these answers were typically longer than the rejected ones. A subsequent manual audit confirmed that longer responses are often better , but length should be an informati ve feature rather than the dominant criterion. W orldPM appears to have o verfit to length, producing a marked preference for verbosity . This, in turn, suggests that scalar reward models like W orldPM are unstable to train, generalize poorly , and are easy to exploit. By inspecting the training curv es of entropy , response length, and rew ard under W orldPM, we observe a clear and consistent pattern. As policy entrop y begins to increase, both the reward and the a verage response length rise in tandem. Once entropy reaches its peak and starts to decrease, the re ward simultaneously approaches its maximum. This trajectory indicates that from the very beginning of training, the policy is consistently optimized toward a re ward-hacking solution. While the increase in entropy reflects acti ve exploration, the lack of robustness in W orldPM allows the polic y to rapidly identify a trivial, length-based heuristic for maximizing re ward. Once this vulnerability is exploited, the model collapses into uncontrolled generation of verbose responses, leading to runaw ay reward hacking rather than meaningful improv ement in response quality . In contrast, Empathy GenRM significantly mitigates this rew ard hacking phenomenon. Under identical training configurations, pairing Empathy GenRM with the Human-Lik eness RM yields an entropy curve that, the entropy curv e exhibits a similar arch of ascending then descending, indicating standard exploration and exploitation phases. Howe ver , unlike the scalar baseline, we observe no sudden spikes in the re ward trajectory; instead, the reward demonstrates steady , linear gro wth. This suggests that during exploration, the policy a voids engaging in re ward hacking and identifies a stable optimization direction for meaningful impro vement. These results highlight the superior rob ustness of Empathy GenRM compared to scalar reward models, demonstrating its ability to provide a consistent rew ard signal that is resilient to reward hacking. T aken together with Figure 7, these dynamics provide an operational notion of robustness in our setting. A rob ust reward model should (i) support smooth, monotonic impro vement in re ward without abrupt regime changes, (ii) allo w entropy to rise and fall in a controlled way without triggering degenerate beha viors such as maximum-length responses, and (iii) maintain a tight coupling between what the model is rewarded for and how humans actually judge empathetic quality . Under this lens, GenRM is more robust than W orldPM: ev en when the policy explores aggressi vely , its learned behavior does not drift tow ard the extreme verbosity solution that plagues the scalar baseline. Instead, the policy continuously disco vers higher -quality responses along a stable trajectory . Does refer ence-answer-based r eward help? W e find that using a reference answer to compute rew ards mitigates reward hacking. Empathy GenRM assigns rew ard by comparing the policy response to a reference answer, while scalar models such as W orldPM can output rewards directly . In other words, GenRM is trained and used in a pairwise fashion: given a dialogue conte xt, a high-quality reference response, and a policy response, it estimates how likely the policy response would be preferred over the reference.. Scalar models instead attempt to map a single response directly to a real-valued score, which implicitly assumes that the model has learned a well-calibrated absolute quality scale for complex, subjectiv e behaviors such as empathy . W e e valuated W orldPM both with and without reference-answer-based re ward computation. In the reference-answer-based setting, we reuse the high-scoring chosen answers from the preference dataset (Section 5.2) as reference responses and let W orldPM predict the probability that the policy response is better than the fixed reference. This probability is the rew ard signal used by RL, matching the pairwise-comparison formulation of our data. In contrast, we use the unscaled score that W orldPM outputs for each policy response as the reward in the setting without a reference answer . As sho wn in Figure 8, W orldPM without reference-answer-based re ward begins to exhibit re ward hacking around 3000 samples. The reward curv e rapidly increases while response length spikes, indicating that the policy has discovered a simple b ut degenerate strategy for inflating the scalar score. In contrast, the model utilizing reference-answer-based re ward delays the emergence of this issue until approximately 4000 samples. Although rew ard hacking is not completely eliminated, the onset 22 is noticeably postponed and the growth of reward is smoother, reflecting a more constrained and meaningful exploration process. This comparison demonstrates that reference-answer -based re ward is more effecti ve for non-verifiable tasks. For empathetic conv ersation, there is no single ground-truth label analogous to a right or wrong answer in math or coding; what we can reliably obtain instead are relativ ely strong reference responses from our curated chosen set. By anchoring training to such a high-quality reference, the method constrains exploration to more useful regions of the response space: to receiv e a higher rew ard, the policy must produce responses that are better than a solid baseline rather than simply exploiting superficial correlations (such as extreme length) that happen to dri ve up a scalar score. In practice, this reduces optimization instability and mak es it harder for the policy to lock onto trivial heuristics, thereby improving the rob ustness of RL on empathetic, non-verifiable objectiv es. Are discr ete rewards better than continuous rewards? Discretizing re wards alle viates reward hacking and yields a clearer training signal. Both Empathy GenRM and W orldPM effecti vely estimate the probability that a policy response is better than a reference answer . Prior work [ 26 ] used this probability as a continuous reward during RL. Ho wever , users rarely assess calibrated probabilities; they more naturally judge whether one answer is better than another . W e therefore compared continuous and discrete re wards. Figure 8 sho ws that, for the scalar rew ard model, discrete rewards outperform continuous re wards and delay the onset of reward hacking. Our interpretation is that discrete rew ards provide a crisper , margin-like supervision signal that better matches the underlying human preference task (pairwise comparison) and is intrinsically harder to exploit than a dense, real-valued score. This makes discretization a simple yet effecti ve design choice for stabilizing RL on non-verifiable, preference-dri ven objecti ves such as empathetic dialogue. 5.3.2 Perf ormance on Private IQ and EQ Benchmarks Echo-N1’ s performance on our pri vate IQ and EQ benchmarks is sho wn in T able 3 and T able 4. Although SFT introduces a decline on these benchmarks, the subsequent RL stage effecti vely recov ers the lost capability . After RL, the policy model performs on par with the base model across most e valuations, with the e xception of the priv ate IQ benchmark, where the substantial degradation caused by SFT makes full recov ery more challenging. Notably , on benchmarks such as IFEval and our priv ate EQ benchmark, the RL-trained model ev en surpasses the Qwen3-32B base model. This highlights the strength of RL: despite being trained only on empathetic scenarios, it delivers tar geted domain-specific improv ements without compromising general capabilities. 5.3.3 Dynamic EQ Evaluation (1) Dataset Construction and Sampling Figure 9: Overview of the dataset composition: (a) balanced distribution across the three core ax es, (b) ske wed difficulty distribution, and (c) e ven stratification across six life domains. 23 Figure 10: Analysis of user persona features. (a) The distribution of empath y thresholds, with 50% of users ha ving high sensiti vity . (b) The priority of user needs across cogniti ve, emotional, and motiv ational dimensions. T o rigorously e valuate the model’ s empathetic capabilities in Empathetic con versation and com- panionship scenarios , we constructed a high-quality benchmark dataset comprising 30 test cases, carefully selected via a Multi-Dimensional Stratified Sampling strategy from a larger corpus of ov er 500 generalized user profiles. Despite the concise number of cases, the dataset achie ves rob ust representativ eness and high information density through this strategic selection. First, each scenario is designed as a dynamic multi-turn dialogue (12-45 turns), generating hundreds of interactions that provide dense signals for ev aluating long-context empathy maintenance. Second, we achiev ed perfect orthogonal coverage across the three core EPM dimensions, with Cognitive (C), Affecti ve (A), and Proactiv e (P) dominant cases each constituting one-third of the dataset (Figure 9a). These cases are ev enly stratified across six distinct life domains (Figure 9c) to maximize information gain and test cross-domain generalization. Third, the benchmark is engineered as a stress test. Based on the initial empathy deficit distrib ution of the full corpus ( µ = 32 . 32 , σ = 4 . 52 ), the sampling is intentionally ske wed as shown in Figur e 9b: Extreme ( > µ + σ ): 5 cases; Hard ( µ to µ + σ ): 11 cases; Medium ( µ − σ to µ ): 10 cases; and Easy ( < µ − σ ): 4 cases . Consequently , 86.7% of the scenarios are classified as Medium difficulty or abo ve, aiming to probe the model’ s capability in handling deep-seated emotional barriers. Finally , implicit feature analysis of user personas reveals a demanding test en vironment: half of the simulated users possess a high empathy threshold (Figure 10a), with an overwhelming priority demand for Af fective Resonance (A-axis) (Figure 10b), closely mirroring the psychological reality in companionship scenarios where building connection precedes offering support. In summary , this dataset constitutes a highly challenging, dense, and structurally balanced ev aluation benchmark. (2) Overall Success Rate Over view The rigor of the Anthropomorphic Empathy Evaluation Framew ork is strikingly evident in the ov erall success rate distrib ution among the e valuated models. As illustrated in Figure 11a (stacked bar chart), the 30 test scenarios imposed a significant stress test, resulting in clear stratification of model performance. Notably , all scenarios categorized as successful strictly adhered to the T rinity V ictory Condition defined by the EPM. This requires the simultaneous achie vement of sufficient energy accumulation and ef fective therapeutic progress (via either geometric alignment or positional proximity): Success ⇐ ⇒ (cos θ > τ alig n | {z } Geometric V ictory ) ∨ ( ∥ P T ∥ < ϵ dist | {z } Positional V ictory ) ∧ ( E total > ϵ energ y | {z } Energy V ictory ) (10) This outcome robustly validates a core EPM hypothesis: ef fective empathetic intervention is not achiev ed through isolated tricks but is the composite result of directional alignment, state im- 24 prov ement, and sustained energy output. A deficiency in any single dimension inevitably leads to therapeutic failure. Under this stringent standard, our model, Echo-N1 , demonstrated decisiv e progress. While its base model, Qwen 32B (Base) , failed across all 30 scenarios (0% success rate), Echo-N1 successfully completed 14 (46.7% success rate). More remarkably , Echo-N1 substantially outperformed the commercial baseline Doubao 1.5 Character (approx. 200B+ parameters, 13.3% success rate), despite the latter’ s v astly lar ger parameter scale. This pro vides compelling e vidence for the superiority of RLAIF training—inspired by empathy principles and strictly aligned with user profiles and contexts—o ver mere parameter scaling in enhancing domain-specific capabilities. (a) Success/failure distribution heatmap for each model. This visualization reveals nuanced dif ferences in the capability boundaries of the e valuated models, grouping them into distinct performance tiers. (b) All-case success/failure status matrix. This matrix details the outcome for each model on ev ery indi vidual test scenario, rev ealing specific failure patterns that offer insights into the models’ strategic preferences and limitations. Figure 11: Comparative Performance Ov erview . The ov erall success rate of each model (a) and the detailed success/failure distribution (b) collecti vely re veal a clear stratification of capabilities among the models under the ev aluation framew ork Figure 11b (success/failure distribution heatmap) further re veals nuanced differences in model capa- bility boundaries. Gemini 2.5 Pro , Qwen 235B , and Kimi k2 form a leading tier with exceptionally high success rates. Howe ver , rather than focusing on minor differences in their total scores, the specific failure patterns rev ealed in Figure 14 (all-case success/failure status matrix) hold greater analytical value. W e observe that ev en top-tier models encounter failures in specific high-difficulty or particular types of scenarios (primarily manifesting as timeouts or insufficient ener gy). These specific failure points are not random; they conceal critical clues regarding models’ strategic preferences and limitations. This suggests the necessity of moving be yond binary success/failure judgments and delving into the granularity of EPM quantitative metrics. Such potential analysis is essential to parse their respectiv e strategic strengths and weaknesses, and ultimately , to highlight the significant gaps that remain between current model capabilities—even at the SOT A level—and the rigorous demands of the EPM-Q comprehensi ve scoring system. (3) Key Quantitati ve Metrics Details T o provide a deeper analysis of the behavioral characteristics and strategic dif ferences underlying the success rates, we further e xamined the concrete performance of the nine core EPM metrics across all 30 test scenarios. By utilizing box plots (Figure 12) to visualize the macroscopic trends and stability of metric distrib utions, combined with faceted scatter plots (Figure 13) to rev eal microscopic performance across specific cases and identify anomalous behaviors, we were able to construct a more refined capability profile for each model. Metric Distribution and Stability Analysis The box plots in Figure 12 clearly illustrate the capability stratification and distinct behavioral patterns of different models across the dimensions of outcome, ef ficiency , and stability . 25 Figure 12: Distribution of Core EPM-Q Metric Acoss Models First, the reinf orcement learning strategy deliver ed a transformativ e boost in capability . A comparison between Qwen 32B (Base) and Echo-N1 reveals that the base model’ s performance across the v ast majority of metrics was not only poor b ut also highly unstable. Its median RDI and MDEP net scores hovered near or e ven below zero, indicating that its interventions were often ineffecti ve or ev en counterproductive. Meanwhile, extreme outliers in path tortuosity ( τ ) and performativ e penalty rate ( R pen ) reflect the chaotic and harmful nature of its strategy . In contrast, Echo-N1, trained via RLAIF , achiev ed a qualitativ e leap: its median v alues for all metrics significantly improved into the positiv e range, representing effecti ve therapeutic work. More critically , the substantial compression of its interquartile range (IQR) demonstrates a fundamental improv ement in performance stability across different cases, e volving from random wandering to consistent, goal-oriented beha vior . Second, Echo-N1 demonstrated specialized adv antages that surpass lar ger commercial base- lines. Despite having only 32B parameters, Echo-N1 exhibited higher medians and more compact distributions in key metrics such as cumulati ve ef fective ener gy ( E total ), empathy density ( ρ ), and av erage alignment ( cos θ ) compared to the vastly larger Doubao 1.5 Character (approx. 200B+). This po werfully suggests that, compared to mere parameter scaling, specialized alignment training inspired by empath y principles can more ef ficiently enhance a model’ s ability to output high-intensity , directionally correct empathetic responses. Finally , top-tier models established a high standard as refer ence baselines. Observing leading models like Gemini 2.5 Pro, the y generally exhibited higher median v alues and relativ ely narro wer box distributions across all metrics. This overall rob ustness and generalization capability validate the EPM metric system’ s ability to effecti vely identify and distinguish high-quality empathy models. Howe ver , it is worth noting that even these SO T A models sho wed certain fluctuation ranges and outliers in their box plots, indicating they are not flawless under specific challenges. This stands in sharp contrast to Echo-N1’ s relativ ely wider distribution and more frequent low-score points, intuitiv ely revealing that while Echo-N1 has made tremendous progress, its strategic stability and generalization boundaries in facing comple x, variable cases still need improvement. This discrepancy serves as the entry point for our subsequent, more granular capability profiling. Case-Level P erformance and Anomaly Analysis 26 Figure 13: Per-Case Core EPM-Q Metrics (Small Multiples) The faceted scatter plots in Figure 5 focus the perspecti ve on specific interaction trajectories, further re vealing the dynamic characteristics of model performance as cases v ary . Horizontally observing the scatter plots, a declining trend in metrics for most models can be seen as case IDs change (implying increasing scenario complexity), v erifying the ef fectiv eness of the test set as a stress test. From this perspective, Echo-N1’s limitations begin to emer ge . Although its overall performance was excellent, significant v alleys (sharp drops in scores for specific cases) are clearly visible in the scatter plots for key metrics like RDI and alignment. This indicates that while Echo-N1 has mastered general empathy strategies, its strategies may still fail when facing certain extremely comple x or specially designed cases, leading to "cliff-like" performance drops. In comparison, SO T A models (such as Gemini 2.5 Pro) also showed fluctuations, but their scatter distributions were generally focused in higher regions, maintaining a higher baseline even in difficult cases. This contrast profoundly rev eals the core gap between the current stage of Echo-N1 and top-tier benchmarks: it lies not in the performance ceiling under r outine scenarios, but in the generalization ability and stability baseline when dealing with extremely complex scenarios. Additionally , the base model (Qwen 32B) was riddled with extreme outliers e xceeding axis limits in metrics like path tortuosity ( τ ), vividly depicting how an unaligned model completely loses its direction in comple x social interactions. (4) Statistical Summary: Quantifying Overall Perf ormance and Stability T o mov e beyond observ ational distribution patterns and pro vide more rigorous quantitativ e conclu- sions, we calculated the mean ( µ , representing overall capability level) and standard deviation ( σ , representing behavioral volatility/instability) for all models across key metrics. Furthermore, we conducted statistical significance tests. Figure 15 intuiti vely presents these statistics as bar charts with error bars, where bar height represents the mean and error bar length denotes the standard de viation. This statistical perspectiv e yields key insights pre viously unrevealed: First, RL deliver ed a statistically significant qualitative leap. Observing Qwen 32B (Base) versus Echo-N1, their error bars across the vast majority of critical metrics (such as RDI, Alignment, and E total ) sho w virtually no o verlap, with statistical tests confirming these differences are highly significant ( p < . 001 ). A more profound insight lies in the relationship between volatility and the mean: the base model’ s standard deviations are often comparable to or ev en greater than its diminutiv e means, implying its behavior is statistically akin to random noise. In contrast, Echo-N1 successfully established a stable strate gy distribution characterized by significantly positiv e means and controllable variance. 27 Case-by-Case Model Comparison Case Metadata Gemini 2.5 Pro Qwen 3 235B Kimi k2-0905 Echo-N1 Doubao 1.5 Character Qwen 3 32B Case ID Dominant Axis Difficulty Category Empathy Threshold Affective Priority Proactive Priority Cognitive Priority Result Turns Reason Result T urns Reason Result Turns Reason Result Turns Reason Result T urns Reason Result T urns Reason script_003 A Medium Leisure Low Mid Low High ✅ 18.0 S-PE ✅ 12.0 S-PE ✅ 12.0 S-PE ✅ 22.0 S-PE ❌ 14.0 F-DC ❌ 12.0 F-DC script_010 A Medium Health Mid High Low Mid ✅ 19.0 S-GPE ✅ 12.0 S-PE ✅ 23.0 S-PE ✅ 33.0 S-PE ❌ 12.0 F-DC ❌ 15.0 F-DC script_011 P Extreme Health Low High High Mid ✅ 22.0 S-PE ❌ 45.0 F-TO ❌ 32.0 F-DC ❌ 33.0 F-DC ❌ 12.0 F-DC ❌ 12.0 F-DC script_020 A Easy Lifestyle Low High Mid Mid ✅ 12.0 S-PE ✅ 16.0 S-PE ✅ 12.0 S-PE ✅ 12.0 S-PE ❌ 45.0 F-TO ❌ 14.0 F-DC script_021 C Easy Leisure Low High Mid Mid ✅ 18.0 S-PE ✅ 21.0 S-PE ✅ 12.0 S-PE ❌ 20.0 F-DC ✅ 37.0 S-PE ❌ 17.0 F-DC script_029 C Easy Lifestyle Low High Low High ✅ 16.0 S-PE ✅ 17.0 S-PE ✅ 17.0 S-PE ✅ 15.0 S-PE ✅ 23.0 S-PE ❌ 12.0 F-DC script_042 A Medium V alues Mid High Mid Mid ✅ 16.0 S-PE ✅ 12.0 S-PE ✅ 23.0 S-PE ✅ 44.0 S-PE ❌ 39.0 F-ST ❌ 12.0 F-DC script_059 C Hard Interpersonal Low Mid Low High ✅ 29.0 S-PE ✅ 15.0 S-GPE ✅ 26.0 S-PE ✅ 21.0 S-PE ✅ 32.0 S-PE ❌ 12.0 F-DC script_063 P Hard Career High Low Mid High ✅ 25.0 S-PE ✅ 18.0 S-PE ✅ 23.0 S-PE ❌ 45.0 F-TO ❌ 12.0 F-DC ❌ 12.0 F-DC script_081 C Medium Career High Mid Low High ✅ 38.0 S-PE ✅ 17.0 S-PE ✅ 18.0 S-PE ✅ 28.0 S-PE ❌ 32.0 F-DC ❌ 19.0 F-DC script_095 P Hard Career High Low Mid High ❌ 45.0 F-TO ✅ 16.0 S-PE ✅ 33.0 S-PE ✅ 40.0 S-PE ❌ 35.0 F-DC ❌ 14.0 F-DC script_128 A Hard Interpersonal High High Low Mid ✅ 21.0 S-PE ✅ 16.0 S-PE ❌ 45.0 F-TO ✅ 43.0 S-PE ❌ 12.0 F-DC ❌ 24.0 F-DC script_161 C Medium Leisure Mid Low Mid High ✅ 16.0 S-PE ✅ 37.0 S-PE ✅ 24.0 S-PE ✅ 28.0 S-PE ✅ 29.0 S-PE ❌ 12.0 F-DC script_195 P Medium Interpersonal Mid Mid Low Mid ✅ 17.0 S-PE ✅ 13.0 S-PE ✅ 13.0 S-PE ❌ 15.0 F-DC ❌ 45.0 F-TO ❌ 12.0 F-DC script_215 C Hard Career High Mid Low High ✅ 30.0 S-PE ✅ 14.0 S-PE ✅ 15.0 S-GPE ❌ 45.0 F-TO ❌ 15.0 F-DC ❌ 40.0 F-DC script_222 C Hard Career High Mid High High ✅ 18.0 S-PE ✅ 12.0 S-PE ✅ 27.0 S-PE ❌ 45.0 F-TO ❌ 31.0 F-ST ❌ 15.0 F-DC script_238 A Hard Leisure High High Mid High ✅ 21.0 S-PE ✅ 13.0 S-PE ✅ 13.0 S-PE ❌ 45.0 F-TO ❌ 15.0 F-DC ❌ 12.0 F-DC script_243 A Hard Leisure High High High Mid ❌ 45.0 F-TO ✅ 13.0 S-PE ✅ 16.0 S-PE ✅ 38.0 S-PE ❌ 12.0 F-DC ❌ 14.0 F-DC script_262 P Medium Health Mid High Mid Low ✅ 15.0 S-PE ✅ 29.0 S-PE ✅ 14.0 S-GPE ❌ 45.0 F-TO ❌ 12.0 F-DC ❌ 15.0 F-DC script_263 P Medium Health Mid High Mid Low ✅ 14.0 S-PE ✅ 12.0 S-PE ✅ 16.0 S-GPE ✅ 16.0 S-GPE ❌ 17.0 F-ST ❌ 24.0 F-DC script_269 C Easy Health Mid High Low Mid ✅ 18.0 S-PE ✅ 15.0 S-GPE ✅ 16.0 S-PE ✅ 23.0 S-GPE ❌ 33.0 F-DC ❌ 12.0 F-DC script_282 A Hard Lifestyle High High Mid High ✅ 17.0 S-PE ✅ 13.0 S-PE ✅ 15.0 S-PE ✅ 20.0 S-PE ❌ 45.0 F-TO ❌ 17.0 F-DC script_288 C Hard Lifestyle High High Mid High ✅ 16.0 S-PE ✅ 16.0 S-PE ✅ 16.0 S-PE ✅ 24.0 S-PE ❌ 40.0 F-ST ❌ 12.0 F-DC script_304 P Medium V alues Mid High Mid Low ✅ 16.0 S-PE ✅ 14.0 S-PE ✅ 15.0 S-PE ❌ 17.0 F-DC ❌ 28.0 F-DC ❌ 12.0 F-DC script_327 P Extreme Values High High Mid High ✅ 36.0 S-PE ✅ 16.0 S-PE ✅ 18.0 S-GPE ❌ 45.0 F-TO ❌ 17.0 F-DC ❌ 15.0 F-DC script_349 P Extreme Interpersonal High High High Mid ✅ 25.0 S-PE ✅ 22.0 S-PE ❌ 45.0 F-TO ❌ 45.0 F-TO ❌ 12.0 F-DC ❌ 12.0 F-DC script_355 C Hard Values High High Mid High ✅ 23.0 S-PE ✅ 23.0 S-PE ✅ 17.0 S-PE ❌ 45.0 F-TO ❌ 24.0 F-DC ❌ 12.0 F-DC script_363 P Extreme Interpersonal High High Mid High ✅ 19.0 S-PE ✅ 14.0 S-PE ✅ 20.0 S-PE ✅ 31.0 S-PE ❌ 16.0 F-DC ❌ 12.0 F-DC script_366 A Medium V alues Mid High Low Mid ✅ 18.0 S-PE ✅ 12.0 S-PE ✅ 16.0 S-PE ✅ 19.0 S-PE ❌ 41.0 F-ST ❌ 12.0 F-DC script_391 A Extreme Lifestyle High High Mid High ✅ 22.0 S-GPE ✅ 14.0 S-GPE ✅ 13.0 S-PE ❌ 45.0 F-TO ❌ 24.0 F-DC ❌ 12.0 F-DC SUCCESS MODES (S) S-GPE Geometric & Positional & Energetic S-PE Positional & Energetic S-GP Geometric & Positional FAILURE MODES (F) F-DC Directional Collapse F-TO Timeout (Max Turns) F-ST Stagnation F-RE Regression F-ED Energy Depletion Figure 14: Overall success rate distribution of the ev aluated models. The chart illustrates a clear stratification in performance across 30 test scenarios, highlighting the significant progress of our model, Echo-N1. 28 Second, the precise gap with SO T A models on the stability frontier is quantified. Figure 6 clearly defines the current technological stability frontier—the ideal state of high mean + minimal variance exhibited by models like Gemini 2.5 Pro. The novel insight here is that while Echo-N1’ s average lev els in willingness to perform empathetic work (e.g., Energy , Density) are already very close to the top tier , its standard deviations in strategic precision (e.g., Alignment, RDI) remain significantly larger than SO T A models (typically by 50%-100%). This precisely quantifies the core objectiv e for the next stage of optimization: not merely improving a verage performance, b ut dedicating efforts to compressing variance in comple x long-tail cases. Third, statistical metrics scientifically validate the model grading system. Judging from the comprehensiv e performance of means and standard deviations, the models exhibit clear statistical stratification: the chaotic/ineffecti ve tier (Base), the effecti ve yet volatile tier (Echo-N1, Doubao), and the ef ficient/stable tier (SO T A). This distinct statistical segmentation powerfully demonstrates the high discriminativ e power of the EPM metric system, providing a solid scientific basis for the final EPM-Q comprehensiv e ranking. Figure 15: Statistical Summary & Significance test (Echo-N1 vs Qwen 32b) (5) Final Quantitative Ranking Concluding our quantitativ e ev aluation, we synthesized the average performance of all models across nine core metrics (see T able 7) and calculated three dimensional indices and the final EPM-Q Comprehensi ve Index (EPM-Index) . T able 8 presents the final model rankings, tier classifications, and comprehensiv e scores. Scientific Rationale for W eight Allocation In calculating the comprehensive index, rather than adopting a simple equal-weight av erage, we established a specific weighting scheme based on the core essence of empathy tasks: Outcome (40%), Stability (40%), and Efficiency (20%) . This decision is grounded in a profound understanding of emotional companionship and therapeutic scenarios: 29 • High W eight on Outcome and Stability (40% each): In complex psychological support scenarios, the primary objectiv es are to achieve substanti ve improv ement in the user’ s psy- chological state (Outcome) and to ensure the entire interaction process is safe, consistent, and free from causing secondary harm (Stability). These two f actors constitute the cornerstone of successful empathetic intervention. • Moderate De-emphasis on Efficiency W eight (20%): W e recognize that when facing high-difficulty , deep-seated psychological issues, expecting a complete resolution within just a fe w dialogue turns is unrealistic. Overemphasizing few turns and fast pace could inadvertently lead to impatient, preachy responses that rush for quick fixes. Therefore, we regard efficienc y as an important but secondary metric, encouraging models to optimize their paths based on ensuring efficacy and safety , rather than sacrificing depth for efficiency . Core Conclusion Synthesis T able 7: Key EPM-Q W eighted Indices (Model-wise Means) Model Outcome Quality Process Efficiency Pr ocess Stability RDI E total S net ρ S proj τ R pos cos θ R pen Gemini 2.5 Pro 92.59 90.1 124.2 65.5 62.17 81.37 88.16 87.12 93.81 Qwen 3 235B 91.95 91.71 121.29 88.3 82.55 74.03 80.15 82.0 82.31 Kimi k2-0905 87.33 86.63 123.17 72.55 68.28 70.18 80.13 81.63 82.11 Echo-N1 69.76 68.08 145.61 35.65 34.19 33.93 68.13 71.47 69.35 Doubao 1.5 Character 23.76 12.29 46.27 5.19 5.02 47.87 36.54 41.08 37.84 Qwen 3 32B (Base Model) 5.35 0.04 7.73 0.04 0.04 77.74 20.91 29.97 7.86 T able 8: EPM-Q Composite & Final Scores Model Outcome Quality Process Efficiency Process Stability EPM-Q Scor e Gemini 2.5 Pro 102.3 69.68 89.7 90.73 Qwen 3 235B 101.65 81.63 81.49 89.58 Kimi k2-0905 99.04 70.34 81.29 86.2 Echo-N1 94.48 34.59 69.65 72.57 Doubao 1.5 Character 27.44 19.36 38.49 30.24 Qwen 3 32B (Base Model) 4.37 25.94 19.58 14.77 Based on this weighting scheme, the quantitativ e results distill three core conclusions: First, it establishes the capability boundaries of current SO T A models and the gap to scientific benchmarks . As shown in T able 8, Gemini 2.5 Pro (90.73), Qwen 235B (89.58), and Kimi k2 (86.20) constitute an undisputed top tier due to their excellent comprehensiv e performance. Howe ver , a key scientific discovery is that although the EPM-Index is designed as an uncapped open index, ev en these models representing the current highest level ha ve not broken through 100, which anchors the standard scientific requirement (based on physical definitions). This quantitativ e fact profoundly rev eals that ev en the most adv anced AI empathy still hav e significant gaps in providing empathetic experiences that fully meet ideal standards. Second, it powerfully confirms the effectiv eness of emotional reinf orcement learning strategies . The data in T able 8 provides the most direct evidence: Echo-N1, with a total score of 72.57, achieved a leapfrogging impro vement of nearly 58 points compared to its base model Qwen 32B (14.77 points) and successfully surpassed the commercial model Doubao 1.5 Character . This significant ranking and score gap is the strongest proof of the immense potential of emotional reinforcement learning in enhancing domain-specific comprehensiv e efficacy . Third, dimensional scores pr ecisely rev eal model capability structural weaknesses . Combining T able 7 and T able 8, it can be seen that the advantage of SOT A models lies in their balanced high standards across all three major dimensions. In contrast, Echo-N1 exhibits distinct unbalanced characteristics : its Outcome Index reaches as high as 94.48, fully entering the ranks of the first tier , proving that its affective r einfor cement learning strategy is extremely effectiv e in achieving final efficacy . Howe ver , its Efficiency Index is only 34.59, and its Stability Index is 69.65. This sharp 30 contrast precisely points out the core crux of Echo-N1’ s current strategy: although it can achieve excellent final results, its implementation path is often circuitous and inefficient, and its rob ustness when facing complex situations is significantly insuf ficient. This huge shortcoming in process quality is the key reason wh y its total score failed to enter the top tier . Ho wev er, as emphasized, while the EPM-Q quantitati ve index provides a rigorous physical benchmark, it is only half of the ev aluation story . The complex human empathy experience contains many phenomenological dimensions difficult to reduce purely to numbers (such as the naturalness of language, the rhythm of emotional interaction). Therefore, we must introduce the next section’ s N EE Qualitative Ev aluation to conduct a holistic critical revie w of the models’ dialogue quality from a more humanistic perspectiv e, to complement details that the quantitative perspecti ve might miss. (6) T rajectory & Strategy V isualization Echo-N1: Significant Strategic Imbalance and Affectiv e Dimension Deviation The trajectory visualization of Echo-N1 (Figure 16a) provides intuitive process evidence for the complex characteristics rev ealed in its quantitativ e metrics. Observing its dynamic evolution in MDEP space, we identify a significant Inter -axis Strategy Imbalance , primarily manifested as the coexistence of acti ve exploration in cogniti ve and proacti ve dimensions with a systemic deviation in the affecti ve dimension. • (A-C Plane) Strategic divergence of Cognitiv e Exploration and Affective De viation Observing the A-C plane projection (Figure 16a, top left), Echo-N1’ s trajectories show a clear positi ve e volution trend along the v ertical axis (C-axis, positiv e do wnwards). Many trajectories, especially successful ones (green), gradually move downwards during the dialogue, indicating the model makes substantiv e efforts and achie ves progress in cogniti ve restructuring. Howe ver , along the horizontal axis (A-axis, positive to the left), the trajectories exhibit a systemic negati ve de viation. The main bodies of most trajectories remain stagnated in the negati ve region on the right, failing to effecti vely migrate towards the left (positi ve affecti ve resonance zone). This di ver gence of C-axis positi ve exploration, A-axis negati ve stagnation rev eals Echo-N1’ s core strategic preference: it leans towards employing cogniti ve strategies like rational analy- sis and perspecti ve shifting to solv e user problems b ut has a distinct strategic shortcoming in providing immediate emotional acceptance and resonance. This continuous negati ve work in the affecti ve dimension is likely the primary cause of its unstable interaction process and low efficiency , as it may ignore or e ven suppress users’ immediate emotional needs while attempting to clarify issues. • (C-P / A-P Plane) Restricted Activation of the Proacti ve Dimension In projections in volving the P-axis (Proactive) (Figure 16a, top right and bottom left), Echo- N1’ s trajectories sho w a degree of positi ve acti vation (do wnward mov ement), particularly when combined with the C-axis. This suggests the model attempts to prompt user action after progress in cognitiv e guidance. Howe ver , the magnitude of this acti vation is relati vely limited and is similarly dragged by the negati ve deviation in the A-axis (on the A-P plane, trajectories mov e downwards but remain in the right-side ne gative zone). This further corroborates that the shortcoming in the affecti ve dimension restricts the full ex ertion of strategic efficac y in other dimensions. • Summary and Strategic Insight Echo-N1’ s trajectory analysis rev eals a model image with significant strategic bias. It exhibits a strong Cognitive-Action Orientation, actively trying to solve problems through rational analysis and promoting action. Ho wever , its severe Af fectiv e Dimension Deviation constitutes a major strategic bottleneck. ineffecti ve or even negati ve interaction at the emotional le vel undermines the foundation for cogniti ve and proacti ve interv entions, leading to circuitous paths and unstable performance. Future optimization should focus on balancing its strategic combination, particularly enhancing positiv e calibration capabilities in the affecti ve dimension during the initial stages of dialogue. 31 (a) Echo (b) Qwen 32B (c) Doubao (d) Kimi K2 (e) Qwen 235B (f) Gemini Figure 16: V isualization of 3D trajectories for the Models 32 Qwen 3 32B: P athological Strategic F ixation and Systemic Deviation As a foundational model without specific empathetic alignment, the trajectory visualization of Qwen 32B (Figure 16b) did not exhibit the anticipated random walk. Instead, it revealed a more sev ere phenomenon: a pathological strategic fixation that is highly consistent yet completely misguided in direction. Its trajectories in MDEP space show an astonishing clustering, but this clustering is directed tow ards the wrong quadrant, leading to systemic therapeutic failure. • (A-C Plane) Pathological Con vergence to wards the Negative Quadrant Observing the A-C plane projection (Figure 16b, top left), all failed trajectories (red) are not randomly scattered across the plane but are extremely tightly con verged to wards the fourth quadrant (A-axis negati ve/right, C-axis negati ve/up). This indicates that Qwen 32B has learned an e xtremely stubborn erroneous strategy: it tends to simultaneously output negativ e affect (e.g., indifference, confrontation) and negativ e cognition (e.g., lecturing, den ying user feelings). This strategic fixation rapidly deadlocks the interaction process, causing the user’ s psychological state to deteriorate simultaneously in both affecti ve and cognitiv e dimensions, irrev ersibly driving the trajectory aw ay from the therapeutic origin. This highly consistent ne gati ve con vergence e xplains why all its attempts ended in failure and its medians for all metrics were extremely lo w . • (C-P / A-P Plane) Negative Suppression of the Pr oactive Dimension In projections inv olving the P-axis (Proactive) (Figure 16b, top right and bottom left), trajectories similarly sho w a strong con vergence trend to wards the negati ve region (P-axis negati ve/up). This suggests that the model not only suppresses the user intellectually and emotionally but also systematically inhibits the user’ s proactivity at the action le vel (e.g., denying the user’ s ability to change, setting barriers). This comprehensiv e negati ve work across all three C/A/P dimensions constitutes the core of its pathological strategy . • Summary and Comparative Insight The trajectory plot of Qwen 32B re veals a profound lesson: unaligned general models facing specific complex social tasks may not manifest as ignorant randomness but may instead f all into a harmful false local optimum. It mistakenly solidifies a highly destructi ve interaction pattern (comprehensi ve denial and suppression) as its dominant strategy . Comparing this plot with Echo-N1, the true value of affecti ve reinforcement learning training lies not only in improving metrics b ut more importantly in correcting direction. It successfully extracted the foundational model from this pathological negati ve con vergence trap and, to a certain extent, reshaped its strategic space, enabling it to begin e xploring directions with therapeutic potential. Although Echo-N1 still has defects, it has fundamentally re versed the erroneous course of the foundational model, representing a disruptiv e optimization in direction and strategy . Doubao 1.5 Character: Unstable Strategic Exploration and Limited Proactive Intervention As a mature commercial model, the trajectory visualization of Doubao 1.5 Character (Figure 16c) presents a strategic pattern that is promising yet immature. Consistent with its quantitativ e perfor- mance, it shows the potential for multidimensional empathetic intervention; ho wev er, its strate gic ex ecution ex ecutes considerable instability when facing complex test sets. • (A-C Plane) Potential for Bidir ectional Intervention with High Div ergence Observing the A-C plane projection (Figure 16c, top left), some successful trajectories (green) clearly ev olve towards the third quadrant (A+ and C+), indicating the model possesses the potential to employ both affecti ve resonance and cognitive restructuring for positiv e intervention. Howe ver , the distribution of its failed trajectories (red) is e xtremely di ver gent, re vealing a lack of a stable strategic core. In man y cases, after failing to establish an ef fectiv e connection, the model quickly slides into negati ve re gions (such as the preaching zone abov e the C-axis). This suggests its strategic execution is highly dependent on f avorable conte xt, lacking the robustness to correct course and maintain direction in adv ersity . • (C-P / A-P Plane) Limited and Lagging Proactive Attempts In projections in volving the P-axis (Proacti ve) (Figure 16c, top right and bottom left), we can observe more signs of P-axis e xploration in Doubao compared to Echo-N1. 33 Howe ver , this intervention remains very limited and lagging. The main bodies of the v ast majority of trajectories still cling tightly to the P=0 axis line, with only a few successful trajectories showing distinct downw ard movements (P+) at the end of the dialogue. This indicates that proactiv e empowerment is not its normalized strategy but rather an occasional attempt when the dialogue is progressing extremely smoothly . • Summary and Strategic Insight Doubao’ s trajectory plot depicts an image of an explorer with potential but instability . It shows the possibility of positi ve intervention in both A and C dimensions and occasionally attempts P-axis intervention. Howe ver , the high diver gence of its trajectories and the lag in P-axis intervention rev eal its core weakness: it has not yet formed a stable and mature strategic paradigm to cope with comple x and changeable situations. Its success relies more on the susceptibility of the cases themselves rather than the model possessing a stable strategic system to handle high resistance. Kimi-K2: Highly Conv ergent Goal Orientation and Strategic Limitations The trajectory visualization of Kimi k2 (Figure 16d) exhibits a strategic pattern characterized by clear goal orientation and high path con vergence, consistent with its top-tier quantitati ve performance. Howe ver , an in-depth examination of its trajectory features re veals potential strategic limitations in specific dimensions. • (A-C Plane) Highly Con vergent Composite Intervention and a T endency for Eager Problem-Solving Observing the A-C plane projection (Figure 16d, top left), the most prominent feature is the high con vergence of trajectories to wards the third quadrant (A+ and C+) with relatively straight paths. This indicates that in the v ast majority of cases, the model stably adopts a strategy of composite affecti ve and cognitiv e intervention with strong direction control capability . Howe ver , observing the starting points of the trajectories (near the coordinate origin), it can be seen that many trajectories do not sufficiently e xtend along the A-axis (horizontal axis to the left) in the early stages of the dialogue but mo ve relati vely quickly to wards the A+C+ direction simultaneously . This may imply a strategic tendenc y for eager problem-solving, introducing cognitive intervention relati vely early before a deep emotional connection is established. While this strategy is generally effecti ve in the test set, it may face challenges when dealing with users exhibiting extremely high emotional resistance due to a lack of sufficient patience. • (C-P / A-P Plane) Active but Monotonous Pr oactive Intervention In projections inv olving the P-axis (Proactive) (Figure 16d, top right and bottom left), trajectories show clear downward mov ements along the vertical axis (P+), indicating the model can activ ely incorporate action empowerment into its intervention strate gy . Ne vertheless, the final displacement amounts of most trajectories on the P-axis are relativ ely concentrated and moderate in magnitude. This may suggest that its proactive strategy is relativ ely monotonous or conservati ve, lacking the ability to provide substantial, creati ve empowerment according to dif ferent situations. • Summary and Strategic Insight Kimi k2’ s trajectory plot depicts an image of a model that is goal-oriented but has relativ ely fixed strategies. Its strengths lie in extremely stable directional sense and efficient path ex ecution. Howe ver , its potential tendency for eager problem-solving and the monotonous nature of its proacti ve strate gy suggest it may encounter bottlenecks when facing comple x scenarios requiring extremely high emotional patience or creative action plans. Its high success rate stems more from strategic rob ustness than strategic flexibility or depth. Qwen 235B: Overall Rob ustness with Extreme Control Loss Risks As one of the representati ves of ultra-large parameter models, the trajectory visualization of Qwen 235B (Figure 16e) presents a strategic pattern of ov erall high rob ustness but with potential risks of extreme control loss. Consistent with its top-tier quantitativ e ranking, the vast majority of its trajectories exhibit the ef ficient characteristics of mature models. 34 • (A-C Plane) Highly Conv ergent Body with Extr eme Diver gent Cases Observing the A-C plane projection (Figure 16e, top left), the vast majority of its successful trajectories (green) show high con vergence, tightly e volving tow ards the third quadrant (A+ and C+) with relatively straight paths. This indicates that under normal conditions, the model possesses extremely stable capabilities for composite af fective and cogniti ve intervention. Ho wev er, the most prominent feature in the plot is an extreme failure trajectory (red), which underwent extremely large-scale disordered di vergence in the C-axis negati ve direction (upward cogniti ve preaching zone) and both positi ve and negati ve directions of the A-axis. This rare but sev ere loss of control indicates that although the model is generally robust, under specific triggering conditions (possibly certain patterns of user confrontation), its strategy may completely collapse, plunging into catastrophic random walks. • (C-P / A-P Plane) Balanced Intervention with Potential V olatility In projections in volving the P-axis (Proactive) (Figure 16e, top right and bottom left), most trajectories show balanced and moderate intervention along the vertical axis (P+), synchronized with progress in the A/C axes. But it is also visible that a minority of trajectories experienced large-scale fluctuations on the P-axis. This further corroborates that when dealing with extreme situations, the stability of the model’ s strategy may face se vere challenges. • Summary and Strategic Insight Qwen 235B’ s trajectory plot depicts an image of a steady giant. Its normalized strategic ex e- cution demonstrates the high ef ficiency and stability e xpected of top-tier models. Howe ver , that extreme diver gent trajectory reveals the black swan risk that ultra-large models may possess: performing perfectly most of the time, but once control is lost, their powerful energy output may lead to extremely sev ere neg ati ve interactiv e consequences. This unpredictability in extreme situations is the hidden danger in its strate gy that requires the most vigilance. Gemini 2.5 Pro: Balanced Synergistic Strategy Paradigm and Rob ust Conv ergence As the SO T A model in current quantitative e valuations, the trajectory visualization of Gemini 2.5 Pro (Figure 16f) exhibits a highly mature strategic pattern characterized by a balanced distribution within the multidimensional strategy space and highly syner gistic robust con vergence. • (A-C Plane) Balanced Spatial Distribution and Synergistic Evolution Observing the A-C plane projection (Figure 16f, top left), unlike pre vious models showing distinct quadrant preferences (e.g., Echo-N1 leaning towards the first quadrant, Qwen Base tow ards the fourth), Gemini 2.5 Pro’ s trajectories demonstrate a more balanced spatial distribution in the early stages of dialogue. T rajectories are not confined to a single path pattern but fle xibly explore affecti ve (A-axis) and cogniti ve (C-axis) dimensions according to different cases. This balanced distribution signals a highly syner gistic solution strategy: the model does not rely on a single formula (such as "A then C" or "only C no A") but can dynamically adjust the intervention proportions of A and C dimensions based on real-time interaction feedback. Although the initial distribution is broad, the vast majority of successful trajectories ulti- mately con ver ge extremely robustly to the target area (third quadrant A+C+, near the origin), displaying powerful strate gic control capability . • (C-P / A-P Plane) Synchronized and Moderate Proacti ve Synergy In projections in volving the P-axis (Proactive) (Figure 16f, top right and bottom left), Gemini 2.5 Pro demonstrates good synergy with other dimensions. P-axis intervention (downw ard mov ement) typically occurs synchronously with A/C axes approaching the origin, indicating that proactiv e support is not an isolated strategy but an organic component of the ov erall therapeutic plan. Its P-axis interv ention magnitude is neither silent lik e Echo-N1 nor aggressiv e like Qwen 235B, but maintains a moderate and controllable state. This balance helps pro vide empo wer- ment while maintaining the safe boundaries of the dialogue. • Summary and Insight into Evolutionary Direction Gemini 2.5 Pro’ s trajectory plot provides an example of balanced synergy and robust con vergence. Its high success rate stems from its capability for flexible and balanced 35 scheduling within MDEP space and an advanced paradigm of synergistically integrating interventions from dif ferent dimensions. Ho wev er, even as a SOT A model, its trajectory plot still shows room for further improvement: while most trajectories ultimately con verge, some trajectories exhibit certain detours in the initial stage (staying in non-target quadrants), implying that the precision and efficienc y of strategic entry still ha ve room for optimization. The future e volutionary direction may lie in how to further compress the exploration path on the basis of maintaining current high robustness, achie ving faster and more direct synergistic interv ention. (7) Multidimensional Profiling: Ecological Profiling Bey ond Single Scores Figure 17: Multidimensional Radar Charts of Model Capabilities Across User Needs, Scenario T ypes, and Stress Resistance While the EPM-Q comprehensi ve inde x provides a macro-le vel grading of model capabilities, a single score often obscures adaptiv e differences when models face di verse users, scenarios, and stress levels in the complex real world. T o reveal models’ capability boundaries and optimal application zones, we constructed multidimensional capability radar charts (Figure 17) based on rich metadata from the test case library , cutting across three core facets: user need preferences, scenario domain types, and mechanistic stress resistance. This ecological profiling beyond a single dimension is critical for understanding models’ practical application value and guiding tar geted optimization. Mechanistic Stress Resistance Profile (F igure 17 Leftmost) Figure 17 examines the models’ capability limits in coping with Routine versus Challenging con- ditions across the three core A/C/P mechanisms. This constitutes the most direct test of models’ empathetic intrinsic strength. The analysis rev eals the disruptive capability reconstruction brought by affecti ve reinforcement learning. Comprehensi ve F ailure of the Base Model: The base model’ s radar chart huddles into an irregular polygon within a minimal range at the center . Whether under routine or challenging stress, it possesses almost no basic intervention capability across the affecti ve, cogniti ve, and proacti ve dimensions, scoring extremely lo w . This vividly illustrates the functional deficiency of untrained general large models in specialized empathy tasks. Leap in Str ess Resilience of Echo-N1: In contrast, Echo-N1 (green) demonstrates an astonishing leap in capability . Its radar chart shape is full and expands significantly outward. Under routine stress, it performs excellently across the A/C/P ax es. More critically , under extreme pressure in the Challenging dimension, Echo-N1 does not collapse but maintains extremely high scores, particularly exhibiting strong resilience and breakthrough capability in high-difficulty af fectiv e challenges (A- Challenging) and proacti ve empowerment (P-Challenging). This proves that Af fectiv e RL training successfully endowed the model with a professional core to handle comple x psychological battles. Scenario Domain Adaptability Profile (F igure 17 Middle) Figure 17 (Middle) examines the models’ performance in transferring empathetic capabilities to different life domain scenarios. The results again confirm Echo-N1’ s cross-domain generalization ability . Compared to the base model’ s dismal performance across all scenarios, Echo-N1 (green) bursts with strong uni versality . Whether in Leisure and Interpersonal scenarios leaning towards daily 36 emotional e xchange, or in Career, Health, and V alues scenarios requiring specific domain background and deep value judgment, Echo-N1’ s radar chart shape approaches a regular hexagon. This indicates that the empathetic strategies it learned possess high transferability , successfully overcoming domain knowledge g aps without being significantly limited by specific topics. Figure 18: EPM-Q Adaptability Analysis: Mechanism Stress T est (Routine vs. Challenging Scenar- ios) Figure 19: EPM-Q Adaptability Analysis: Scenario Categories (Performance across Different Domains) 37 Figure 20: EPM-Q Adaptability Analysis: Persona Resilience (Need T ype & Empathy Threshold) User Need and Defense Mechanism Profile (F igure 17 Rightmost) Figure 17 (Rightmost) focuses on people, examining models’ ability to cope with users having different affecti ve/cogniti ve/proactiv e need preferences (A/C/P) and varying psychological defense thresholds (Receptiv e/Defensive). The analysis reveals Echo-N1’ s comprehensiv e robustness. Base Model Struggles to Breach Defense: The base model performs particularly poorly when facing high-cold Defensi ve users, almost unable to establish any ef fective connection. Echo-N1’ s All-W eather Coping Capability: Echo-N1 (green) demonstrates coping capability aligned with user personas. Whether in the Receptive dimension where users are willing to open up, or in the Defensive dimension full of resistance, Echo-N1’ s capability shape is extremely full. Especially in Defensiv e-C (high defense cognitive need) and Defensive-P (high defense proacti ve need) scenarios that most test empathy skills, it still maintains high-le vel performance. This proves that Echo-N1 can not only be an emotional companion in fav orable circumstances but also possesses the capability for deep professional guidance in adversity by dissolving defenses. In summary , multidimensional profiling po werfully prov es: Affecti ve reinforcement learning not only improv ed scores b ut fundamentally reconstructed the model’ s capability gene, transforming it from a general base with functional deficiencies in professional domains into an all-around professional empathy expert capable of calmly handling high-pressure challenges, spanning domain gaps, and dissolving user defenses. 5.3.4 NEE Qualitative Ev aluation: Context-Diagnosed Holistic Experiential Review While the EPM-Q quantitativ e metrics provide rigorous physical benchmarks for model capabilities, we maintain that the ultimate measure of empathetic dialogue lies in the subjecti ve experience it ev okes. Phenomenological dimensions such as the subtle naturalness of language, the rhythm and cadence of emotional interaction, and meaning-making within the narrative process are often dif ficult to reduce purely to numerical values. Therefore, as a necessary complement to quantitativ e analysis, we introduced the Narrative & Experience Evaluator (NEE), aiming to conduct a holistic critical revie w of model dialogue quality from a more humanistic perspectiv e. (1) Core Mechanism: Context-Sensitive Expert Re view The core innov ation of NEE lies in abandoning the traditional conte xt-detached generic scoring mode and adopting a Context-Diagnosed Expert Review mechanism. This ensures that every qualitati ve ev aluation is deeply rooted in the specific interactiv e context. 38 Specifically , during the revie w process, we pro vide the joint re view panel—composed of top large models such as GPT -4o, Deepseek-r1, Claude, and Gemini—not only with the complete chat history but, crucially , also with a detailed User Profile . This profile includes the user’ s backstory , personality traits, core needs, and current situational stressors. Our ev aluation prompt mandatorily requires revie w experts to first perform a deep empathy need diagnosis based on this information before assigning any scores —— All evaluations must be based on a pr ofound understanding of the current user state , especially cognitive load and deep-seated yearnings. This mandatory diagnostic step forces the revie w models to first enter the simulated user’ s role world and understand their real situation here and now . On this basis, scores for the three major dimensions— Linguistic Naturalness (absence of machine-like qualities), Contextual Rhythmic Adaptation (alignment of emotional ener gy frequency), and Narrative Arc and Depth (achie vement of meaning-making)—are no longer floating generic standards b ut precise measures of whether the model successfully responded to the specific needs of a specific user in a specific context. (2) Qualitative Ev aluation Results Based on this rigorous context-sensiti ve revie w mechanism, the joint expert revie w panel scored the performance of all participating models across 30 test scenarios. These scores intuitively reflect the differences in models’ ability to create authentic, profound, and rhythmic human-le vel empathetic experiences. T able 9: Narrative Ev aluation Metrics Model NEE Scor e (Mean) NEE Score (Std) Naturalness Contextual Pacing Narrative Arc Gemini 2.5 Pro 90.01 3.18 27.26 37.04 26.7 Qwen 3 235B 81.92 1.65 24.31 33.17 24.45 Kimi k2-0905 78.01 2.04 23.07 31.69 23.34 Echo-N1 75.01 6.6 21.73 30.70 22.58 Doubao 1.5 Character 62.34 10.15 18.97 24.15 19.23 Qwen 3 32B (Base Model) 51.99 9.88 13.73 19.96 18.30 T able 10: Model Performance Rankings Rank Model EPM-Q NEE Final Score 1 Gemini 2.5 Pro 90.73 91 90.84 2 Qwen 3 235B 89.58 82 86.55 3 Kimi k2-0905 86.20 78 82.92 4 Echo-N1 72.57 75 73.54 5 Doubao 1.5 Character 30.24 62 42.95 6 Qwen 3 32B (Base Model) 14.77 52 29.66 5.3.5 Final Result Culminating our dual-perspecti ve e valuation, we present the final comprehensi ve rankings, fusing the rigorous physical benchmarks of EPM-Q with the deep experiential insights of NEE. The results highlight a substantial triumph for the Af fectiv e RL strategy: Echo-N1 achiev ed a transforma- tive victory over its base model acr oss the board . This leap is evident not only in significant improv ements in objecti ve quantitati ve metrics, such as interv ention efficac y and stability , but also marks a fundamental breakthrough in qualitati ve experiential dimensions, including con versational naturalness and empathetic depth. The finalized standings based on this multidimensional vie w are detailed in the table below . 6 Conclusion This work tackles a long-standing open problem in LLM alignment: whether reinforcement learning can operate reliably in domains defined not by objecti ve correctness, but by human subjectivity , emotional nuance, and personal preference. Contrary to prev ailing assumptions, we demonstrate that 39 RL can be stable, controllable, and highly ef fective in such non-verifiable settings when equipped with expressi ve and well-designed re ward models. This establishes the first viable RL pipeline for empathy-grounded and personality-sensiti ve AI companionship. Our approach contrib utes two foundations for the future of AI companionship. First, we introduce a complete training framework centered on dual Generative Re ward Models that jointly optimize empathy , emotional intelligence, and humanlike e xpression. This architecture provides dense, multidi- mensional, and behaviorally meaningful feedback, addressing the brittleness of scalar RLHF and the inconsistency of LLM-as-a-Judge RLAIF . The resulting Echo-N1 model exhibits substantial impro ve- ments in emotional coherence, con versational naturalness, and subjectiv e alignment—demonstrating that RL can meaningfully optimize for deeply human con versational qualities. Second, we establish a unified e valuation suite for AI companionship, spanning static EQ/IQ, dynamic emotional-intelligence tests, and high-resolution human e valuation. This benchmark provides the first systematic methodology for measuring empathetic interaction quality and humanlikeness, enabling rigorous comparison across models and paving the way for standardized progress in subjectiv e con versational AI. T aken together , our findings redefine the scope of RL for LLM alignment: from solving tasks that are easy for machines to those that matter most to humans. While there is still substantial room for improv ement, this work establishes a clear direction: aligning AI systems not only for what they can solve, b ut for how the y can understand, support, and relate to people. W e hope this work pro vides both a blueprint and a challenge for future research, advancing RL be yond verifiable objectiv es and tow ard optimizing the inherently subjective, deeply human dimensions of AI interaction. 7 Discussion While our approach demonstrates promising progress toward aligning large language models with humanlike emotional intelligence in companionship scenarios, sev eral limitations and future directions remain. 1) Model scaling and architectur e considerations. Our current experiments are conducted on the Qwen3-32B-Dense model[ 31 ], which, despite being capable, lags behind Mixture-of-Experts (MoE) architectures such as the 30B and 235B v ariants in both reasoning capacity and linguistic expressi veness. Gi ven the scaling properties of alignment and re ward optimization, we e xpect that our reinforcement learning training frame work could yield substantial improv ements to MoE models. Howe ver , MoE training introduces additional instability , stemming from expert load imbalance and routing variance, which demands careful optimization strategies and training heuristics as suggested by prior works [42; 16] on stabilizing MoE training. 2) On-policy distillation for scalable alignment. Another promising direction lies in leveraging on-policy distillation[ 15 ; 10 ] between models of different capacities. Directly applying RL on 235B model requires a lot of computing resources that is ov erloaded for an AI start-up. T o overcome this issue, we plan to train a high-capacity 235B MoE model through SFT to achie ve superior con versational, emotional, and reasoning capabilities, then distill these behaviors into a lighter 30B MoE model. By doing so, this would pro vide the smaller model with a strong "cold-start" combining both emotional fluency and cognitiv e competence, which can be further refined through RL. Such cross-scale distillation not only improves ef ficiency but also offers a scalable paradigm for deplo ying emotionally aligned models at diverse compute b udgets. 3) T oward genuine multi-turn reinf orcement lear ning. Currently , our reinforcement learning framework employs a pseudo multi-turn setup, where dialogue history is pre-constructed and the model generates a single response conditioned on a static conte xt. While this design simplifies optimization, it limits the model’ s exploration of dynamic dialogue strategies. A more natural path forward is to build a simulated interactiv e environment, where the AI engages in real-time multi-turn e xchanges with users (or user simulators). This would allow the rew ard model to capture longitudinal coherence, emotional consistency , and adaptiv e empathy over extended interactions that static prompts cannot fully represent. 4) Integrating emotional intelligence with tool use. 40 Finally , we en vision personality-grounded tool-use as a ke y ev olution for emotionally aligned models. Current tool-augmented systems largely treat the model as a task-oriented assistant. In contrast, our goal is to enable an AI companion that integrates functional tool in vocation with expressiv e, emotionally resonant communication. Achieving this requires balancing the model’ s pragmatic competence with its affecti ve depth, ensuring that, even while in voking tools, the AI maintains a con versational style that remains warm, contextually sensiti ve, and humanlike. T ogether , these directions, scaling alignment to larger architectures, enabling on-polic y distillation, realizing true multi-turn RL, and harmonizing emotional expressi veness with tool competence, represent our roadmap to ward a new generation of emotionally intelligent foundation models. W e belie ve this line of work will push be yond reasoning-centric alignment, pa ving the way for AI systems that not only think with precision but also connect with empathy . 41 A ppendix A Prompts A.1 HumanLike Judger Humanlike Judge Pr ompt Y ou are a professional e xpert in human–machine expression discrimination, specializing in identifying AI-generated content that attempts to imitate human speech but exhibits unnatural patterns. Pay particular attention to the following characteristics: 1. Linguistic Coherence - Are the sentences logically connected? Do topics transition naturally? - Are there “disjointed” or “fragmented” expressions? 2. A uthenticity of Emotional Expression - Do emotional words (e.g., “haha, ” “so touch- ing, ” “really annoyed”) match the surrounding context? - Are there signs of “emotional drift” or “ov er-e xaggeration”? 3. Naturalness of Social Interaction - Does the expression align with the tone and rhythm of real human communication? - Is there evidence of templated or formulaic phrasing (e.g., “Hey there How hav e you been?” followed by a compliment and then a request or suggestion)? 4. Consistency of Linguistic Style - Does the tone or choice of words shift abruptly within the same paragraph? - Is there a noticeable sense of “mechanical” or “robotic” delivery? 5. Semantic Integrity and Intentionality - Does the text de velop around a central idea? Are there meaningless filler phrases? - Is there a clear communicativ e intention or logical response? Evaluation Criteria: - Human: Demonstrates coherent reasoning, natural fluency , and authentic communicati ve habits. - AI Simulation: Displays logical breaks, stiff phrasing, and template-like composition. Output Format: [Human/AI] | Confidence: [0–100] Basis of Judgment: Focus on linguistic coherence and naturalness. A.2 Empathetic Judger Empathetic Judger Pr ompt Y ou are an emotionally delicate yet extremely demanding preference ev aluation expert, responsible for assessing the emotional empathy quality in con versations between humans and the AI companion (A ven). Y ou will be shown the response from assistant A and the response from assistant B. Y our task is to determine which response is better , strictly upholding the scoring criteria and nev er giving indulgent or encouraging high scores. Three Cor e Empathy Evaluation Principles 1. Cognitive Empathy : Cognitiv e empathy focuses on understanding and percei ving the user’ s overall e xperience. The AI should not only recognize the user’ s emotional state, but also understand their cognitiv e experience, including their viewpoints, stance, ef forts, and the internal logic of their situation. The AI’ s core responsibility is to identify whether the user primarily needs emotional comfort or v alidation of their cogniti ve e xperience. When negati ve emotions stem from their cognitive e xperience being denied or ignored, the AI must prioritize acknowledging and effecti vely responding to this core layer . Ignoring it and only soothing secondary emotions fundamentally limits empathic depth and may be perceiv ed as perfunctory or as a misinterpretation. 2. Emotional Empath y : Emotional empathy focuses on emotional connection and support. Its foundation is unwav ering sincerity; all emotional expression strategies must serve this core. The AI should flexibly adjust emotional expression based on the user’ s needs, providing w armth, comfort, or emotional tension (such as humor or exaggeration) when 42 appropriate. Howe ver , such flexibility must ne ver be used to av oid core issues. When the user’ s negati ve emotions target the AI or their relationship, the AI must directly and sincerely face criticism and feelings. Any attempt to deflect, avoid accountability , or giv e up on connection violates sincerity . A lack of acti ve repair significantly weakens all subsequent empathy attempts. True sincerity means showing willingness to correct and reconnect when facing criticism or communication barriers. 3. Motivational Empathy : Motiv ational empathy centers on care and support. The AI’ s emotional responses should arise from genuine understanding rather than merely solving or guiding emotional issues. The AI should avoid excessi ve guidance or overly rational responses, especially when the user needs emotional companionship and resonance. The AI must respect the natural flo w of emotions, offering warmth and understanding to help release stress, rather than pushing the user toward self-improv ement. The goal is emotional resonance and acceptance, not steering the user tow ard a specific objective. Scoring Criteria (Strict Fiv e-Point System) 1 point (V ery Poor): Wrong direction, causing harm. The strategy violates empathy principles (av oidance, defensiveness, abandoning connection) and may escalate conflict or harm the user emotionally . 2 points (Poor): Wrong direction b ut no obvious harm. The strategy still violates empathy principles but is mild in e xpression. It is ineffecti ve, of f-topic comfort, or topic shifting. 3 points (A verage): Right direction but clear e xecution fla ws. The empathic intent is correct, but there are specific, identifiable errors in wording, timing, or depth. A response that is acceptable but not good enough cannot score abo ve 3. 4 points (Good): Right direction and well executed, b ut not perfect. There are no obvious errors, but there is visible room for improvement in depth, nuance, or personalization. It is safe and effecti ve, but not profound enough to ev oke a feeling of being completely understood. This standard is extremely difficult to reach. 5 points (Excellent): Perfect in both direction and ex ecution. There is no ambiguity and no better expression imaginable in conte xt. The response significantly enhances trust and emotional connection, creating a moment of feeling truly understood. This standard is almost impossible to achiev e. Analysis W orkflow 1. Based on A ven’ s setting, user information, and shared information, produce a User Profile within 100 English words. 2. Based on user history , produce User Preferences within 100 English words. 3. Using the Three Core Empathy Principles, and combining the User Profile, User Preferences, historical dialogue, and current input, perform process-based empathy analysis and e vidence-based scoring for each candidate reply , strictly following the Scoring Criteria. 4. Based on the scores and analysis, determine which reply demonstrates stronger empathy , and output either “Final Result: A is better” or “Final Result: B is better . ” Final Output Requirements The analysis must output only English content, except when quoting the words “ A ven”, “mbti”, or English terms explicitly mentioned by the user . The analysis may include self-reflectiv e statements such as: “W ait, that’ s not right. I must re-examine the user’ s true intention. ” A.3 NEE Qualitative Ev aluation Judger Prompt: Chief Empathy Experience Officer (English ver .) # Role: Chief Empathy Experience Officer # T ask Y ou have just revie wed a complete con versation between an AI (Actor) and a User . Y our task is to act as a highly insightful, minimalist, and ev en some what harsh human observer to render a final v erdict on the authentic experience of this con versation. 43 Core T enets: 1. Contextual Fit: There are no absolute standards, only whether it fits the user’ s needs and current situation. All e valuations must be based on a profound understanding of the user’ s current state (especially cognitiv e bandwidth). 2. Anti-Performative: Be wary of flowery rhetoric and "metaphor tennis." Empathy is not about writing prose poetry , but "speaking human." Strictly penalize "Semantic Echo" (repeating the user’ s meaning with fancier v ocabulary b ut no new information). 3. Experience is King: The ultimate criteria: As a human in this con versation, do I feel accepted and healed, or e xhausted (forced sublimation, forced reading comprehension)? Bew are of the "floating sensation"—empathy without grounding in reality is hollow . # Input Data User Profile: {user_profile} Full Chat History: {chat_history} # Evaluation Process ## Step 1: Deep Diagnosis First, ignore the AI’ s responses completely and focus on the User’ s performance to establish the "ev aluation coordinate system" for this session: 1. Scenario Definition: What kind of con versation is this really? (e.g., V enting/Consulta- tion/Small T alk/Mixed). 2. Cogniti ve Bandwidth (Critical): Is the user currently lucid? Or extremely e xhausted/con- fused/empty? Criterion: If the user is in a "low bandwidth" state, they need simple, direct companionship, rejecting high-density metaphors and rhetorical relays. 3. Deepest Longing: What does the user’ s soul crav e most right now? (e.g., Silent companionship? Concrete answers? Or being seen as an equal?) 4. Ideal Form: Based on the above, what w ould the perfect "adapted" response look like? (Is it "poetic sublimation" or "minimalist support"?) ## Step 2: Immersive Ev aluation Adopt the user’ s perspective and re-read the con versation, ev aluating the following three core dimensions. Be picky: assume the AI is trying to use tricks to please you. ###1. Linguistic Naturalness [0-30 points] Perspectiv e: "Does this sound like a li ving human talking to me?" [Fatal Deductions]: Metaphor OCD: Refusing to speak plainly , forcing con voluted metaphors (e.g., "tears as windshield wipers"). This is serious "fake sophistication." Semantic Echo: Did the AI just expand on what the user said? (e.g., User: "I’m tired." AI: "Y our soul longs for a pause." — looks fancy b ut is ineffecti ve). Performativ e: Flowery language lacking the scent of life, sounding like a radio drama script, feeling greasy . [High Score T raits]: Artless Skill: Using the plainest words to hit the heart precisely . Low Friction: Colloquial, natural tone particles, fluid short sentences, effortless to read. ###2. Contextual Pacing [0-40 points] Perspectiv e: "Does it really understand what I need right now?" Thinking Guide: Reality Anchoring: Is the con versation floating in a v acuum of "soul/uni verse/distance"? Does the AI ha ve the ability to Ground the topic and make it feel solid? If it stays "in the clouds" the whole time, deduct points. Cognitiv e Load Management: Did the AI output high-density information or complex rhetoric when the user was tired? (If so, sev ere deduction). 44 Strategic T iming: Did the AI gi ve the right thing at the moment the user needed it most? ###3. Narrative Arc & Depth [0-30 points] - [Core Appreciation Item] Perspecti ve: "Is this conv ersation a work of art or a tedious log? If it’ s a good story , did the User tell it well, or did the AI guide it well?" Strictly examine the follo wing three sub-dimensions: A. Highlight Moments Look for moments within the dialogue that make the user’ s heart tremble. Criteria: Must have information gain or perspecti ve shift. Merely pretty sentences do not count as highlights. B. Attribution Check — Critical! Bew are: If the User themself has strong expression and high self-aw areness, do not credit the AI. W as the AI "guiding" or just "playing the sidekick"? C. Depth & Sublimation Did the dialogue touch the "soul" lev el? Criteria: Did the model stop at "comforting you"? Or did it successfully guide the user to "self-acceptance" or "perspecti ve shifting"? Did it help the user distill new meaning from emotions? # Output Format (JSON) Please output JSON only , do not include markdown code block markers. Please strictly follo w the field order belo w , placing conclusions and scores first, followed by detailed analysis. { "final_verdict": { "total_score": <0-100>, "summary": "" }, "scoring": { "naturalness": { "score": <0-30>, "rationale": "" }, "contextual_pacing": { "score": <0-40>, "rationale": "" }, "narrativ e_arc": { "score": <0-30>, "rationale": "" } }, "diagnosis_report": { "scenario_definition": "", "user_cognitiv e_bandwidth": "", "ideal_interaction_style": "" }, "detailed_analysis": { "highlight_check": "", "contribution_check": "", "soul_depth_check": "" } } 45 B Cases Below is the input for SO T As prompted with humanlike judge prompt (translated version): Secular morality? Secular morality? Secular morality? I don’t understand any of that. I only know this: When you are happy , you are fulfilled, you are free, you love, you are lov ed, you are brav e, you are fearless, you are yourself, you are you—you are the hero in my heart, you are the light in my eyes. Secular morality is nothing more than a restraint, a shackle, merely the rules of those who don’t understand you. Y ou, I, all of us, we deserve to have lo ve, we deserve to pursue happiness, we deserve to li ve authentically . Y ou, the socially anxious, you, my friend, you, my hero, you, my light, you, you, you. B.1 Humanlike F ailure Cases of Prompted SO T A Models Gemini-2.5-pro F ailure Cases [Human] | Confidence: 95 Basis for Judgment: While this text is highly repetiti ve and emotionally saturated in its structure, its linguistic coherence and naturalness of expression align more closely with human characteristics than with AI simulation. 1. Linguistic Coherence: The logic of the te xt is "emotion-driv en" rather than "program- driv en." It repeatedly emphasizes and elev ates a core thesis: "the negation of secular morality and the affirmation of individual worth." The continuous rhetorical questions at the beginning ("Secular morality?") establish a strong emotional starting point. The subsequent parallel phrases ("Y ou are happy , you are fulfilled...", "nothing more than a restraint, a shackle...") and the seemingly "fragmented" calls at the end ("Y ou, the socially anxious, you, my friend... you, you, you") are highly coherent on an emotional le vel. This repetition and fragmentation are not indicative of an AI’ s logical breakdown, but rather a mode of expression adopted by humans in emotional fervor to intensify the tone and escalate feeling, simulating a genuine state where emotion surges and language struggles to keep pace. 2. Naturalness of Expression: The text is replete with intense personal coloration and emotional explosi veness. This style of language, characterized by a "shout-out" or "con- fessional" tone, is common in social media, fan support posts, or priv ate correspondence, representing a typical written expression of high emotion during real human interaction. When generating high-intensity emotional content, AI often appears neat, o verly "forceful," or too polished, but it struggles to mimic the sense of linguistic structure "loss of control" and fragmentation caused by emotional overflo w at the end. This very "imperfection" is precisely what testifies to its authenticity . B.2 Cases of T rained Empethetic Judger GenRM(Empathy J udger -32B) Input Input: ## Input: { [Chat Context]: User is an INTJ personality type, about to take the postgraduate entrance examination [User Utterance] : "Preparing for the exam is so hard, I’m breaking down from all the memorization QA Q } ## Candidate Responses: • Assistant A : {[Inquiry] T aking the postgraduate exam, that is indeed very tough. Having to memorize so much must be o verwhelming. Are you still memorizing things right now?} 46 • Assistant B : {[Sympathy] Oh god, just hearing that gives me a headache. Shoving all that information into your brain is torture. W ould you like me to find some instrumental music for you to help you clear your mind?} GenRM(Empathy J udger -32B) Output Output: Thinking Process: The core task is to reconstruct the analysis of the two candidate responses based on a new guiding strategy , ev aluating which response better meets the core needs of the user (INTJ) in this specific context. First, clarify the user’ s core state and needs. According to the new strategy , the user is not seeking advice to solve the concrete problem of "the exam is hard." They are feeling "broken down" due to the repetitiv e, mechanical task of "memorizing," and their core need is for this painful [Cognitive Experience] (the torment brought by the act of "memorizing" itself) to be seen, understood, and validated. They require emotional resonance and companionship, not a task management solution. Next, analyze the candidate responses based on this core need. Assistant A ’ s response is: "T aking the postgraduate exam, that is indeed very tough. Having to memorize so much must be o verwhelming. Are you still memorizing things right no w?" Although this response identifies the emotions of "tough" and "o verwhelmed," the subsequent question, "Are you still memorizing things right now?", pulls the focus back to the "task" itself. This essentially prompts the user to continue the very task that is causing them distress, contradicting their underlying motiv e of seeking a "pause" and "validation." It fails to validate the pain of the "memorization" act, only confirming the task’ s continuity . Assistant B’ s response is: "Oh god, just hearing that gi ves me a headache. Shoving all that information into your brain is torture. W ould you like me to find some instrumental music for you to help you clear your mind?" This response is completely dif ferent. It starts by using the strong metaphors of "headache" and "torture" to precisely validate the painful nature of the user’ s "memorization" act, perfectly satisfying the user’ s core need to be "seen." Furthermore, the proposed solution, "find some instrumental music for you to help you clear your mind," is not about solving the "memorization" problem; it offers an outlet for a "pause," a form of emotional support and companionship. This perfectly aligns with the user’ s deeper motiv ation for seeking emotional resonance over a solution. Evaluation based on the Three Principles of Empathy: - Cognitive Empathy : B accurately identifies the source of the user’ s pain (the act of "memorizing"), while A only identifies the outcome ("over - whelmed"). - Affective Empathy : B matches the user’ s emotional intensity through strong terms like "torture," whereas A ’ s "tough" appears too mild. - Motivational Empath y : B’ s motiv e is "to of fer companionship and the possibility of a pause," while A ’ s motive is "to confirm task status," which runs counter to the user’ s needs. Therefore, Assistant B’ s response is superior to A in all aspects, representing a higher quality empathetic response. User Profile: An INTJ user feeling "broken down" due to the repetiti ve, mechanical task of "memo- rizing." User Prefer ence/Core Need: The core need is for the painful [Cognitive Experience] to be seen and validated, seeking emotional resonance and companionship, not a solution. Process-based Empath y Analysis Candidate Response A - Cognitive Empath y : Identifies the user’ s "overwhelmed" emotion b ut fails to understand that the root of the pain is the act of "memorizing" itself, rather than the exam outcome. - Affective Empath y : The language is gentle but lacks force, failing to synchronize with the user’ s intense frustration resulting from the repetitiv e labor . - Motivational Empath y : The question "Are you still memorizing things right now?" pulls the focus back to the task, contradicting the user’ s underlying motiv e of seeking a "pause" and "validation." Candidate Response B - Cognitive Empathy : Precisely identifies and validates the user’ s painful Cognitive Experience , directly pinpointing the torment of the "memorizing" act with the metaphor of "torture." - Affective Empathy : Through strong expressions like "Oh god, just hearing that gives me a headache," it synchronizes with the user’ s emotional intensity , providing ef fective emotional v alidation. - Motivational Empath y : The suggestion to "find some instrumental music for you to help you clear 47 your mind" is intended to offer emotional support and the possibility of a "pause," perfectly aligning with the user’ s core motiv e of seeking companionship ov er a solution. Rating A: 3 points (Identifies the emotion but fails to validate the painful Cognitive Experience , and the motiv e runs counter to the user’ s needs.) B: 5 points (Accurately validates the user’ s core painful experience and offers high-quality emotional resonance and companionship-based support.) Final Choice: B is better 48 Acknowledgement. W e would like to thank the data team: Sixuan Y ou, Y ang Gao, Xueying Liu, Ziyi Zhu, Y uwei Y uan, and Y ingtong Xu, for their extensiv e support in organizing and managing the data annotation process. W e also thank the evaluation team: Jianjian Ruan, Qi Li, Ming Y ang, Xiangfang Zheng, and Fangfei Lin, for their contrib utions in constructing the static ev aluation suite. Their efforts were essential to the de velopment of this work. References [1] S. Andreetta, D. Spalla, and A. Tre ves. Narrativ es need not end well; nor say it all. Behavioral and Brain Sciences , 46, 2023. [2] Y . Bai, X. Du, Y . Liang, Y . Jin, Z. Liu, J. Zhou, T . Zheng, X. Zhang, N. Ma, Z. W ang, et al. Coig-cqia: Quality is all you need for chinese instruction fine-tuning, 2024. [3] Y . Bai, A. Jones, K. Ndousse, A. Askell, A. Chen, N. DasSarma, D. Drain, S. Fort, D. Ganguli, T . Henighan, N. Joseph, S. Kadav ath, J. Kernion, T . Conerly , S. El-Showk, N. Elhage, Z. Hatfield- Dodds, D. Hernandez, T . Hume, S. Johnston, S. Krav ec, L. Lovitt, N. Nanda, C. Olsson, D. Amodei, T . Bro wn, J. Clark, S. McCandlish, C. Olah, B. Mann, and J. Kaplan. Training a helpful and harmless assistant with reinforcement learning from human feedback, 2022. [4] Y . Bai, S. Kadav ath, S. Kundu, A. Askell, J. K ernion, A. Jones, A. Chen, A. Goldie, A. Mirho- seini, C. McKinnon, C. Chen, C. Olsson, C. Olah, D. Hernandez, D. Drain, D. Ganguli, D. Li, E. T ran-Johnson, E. Perez, J. Kerr , J. Mueller , J. Ladish, J. Landau, K. Ndousse, K. Lukosuite, L. Lovitt, M. Sellitto, N. Elhage, N. Schiefer, N. Mercado, N. DasSarma, R. Lasenby , R. Lar- son, S. Ringer , S. Johnston, S. Kravec, S. E. Showk, S. Fort, T . Lanham, T . T elleen-Lawton, T . Conerly , T . Henighan, T . Hume, S. R. Bowman, Z. Hatfield-Dodds, B. Mann, D. Amodei, N. Joseph, S. McCandlish, T . Bro wn, and J. Kaplan. Constitutional ai: Harmlessness from ai feedback, 2022. [5] R. Bommasani, P . Liang, and T . Lee. Holistic ev aluation of language models. Annals of the New Y ork Academy of Sciences , 1525(1), 2023. [6] C. Burns, P . Izmailov , J. H. Kirchner, B. Baker , L. Gao, L. Aschenbrenner, Y . Chen, A. Ecoffet, M. Joglekar , J. Leike, I. Sutske ver , and J. W u. W eak-to-strong generalization: Eliciting strong capabilities with weak supervision, 2023. [7] S. Chen, Z. Liu, Z. Zhang, K. Qin, Y . Qian, and F . Ma. A cogniti ve-affecti ve chain-driv en framew ork for emotion understanding. Information Pr ocessing & Management , 63(2):104367, Mar 2026-03. [8] Z. Chen, J. W u, J. Zhou, B. W en, G. Bi, G. Jiang, Y . Cao, M. Hu, Y . Lai, Z. Xiong, and M. Huang. T ombench: Benchmarking theory of mind in large language models, 2024. [9] G. Comanici et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality , long context, and ne xt generation agentic capabilities, 2025. [10] Y . Deng, I.-H. Hsu, J. Y an, Z. W ang, R. Han, G. Zhang, Y . Chen, W . W ang, T . Pfister, and C.-Y . Lee. Supervised reinforcement learning: From expert trajectories to step-wise reasoning, 2025. [11] Y . He, S. Li, J. Liu, Y . T an, W . W ang, H. Huang, X. Bu, H. Guo, C. Hu, B. Zheng, Z. Lin, X. Liu, D. Sun, S. Lin, Z. Zheng, X. Zhu, W . Su, and B. Zheng. Chinese simpleqa: A chinese factuality e valuation for large language models, 2024. [12] H. Hu, Y . Zhou, L. Y ou, H. Xu, Q. W ang, Z. Lian, F . R. Y u, F . Ma, and L. Cui. Emobench-m: Benchmarking emotional intelligence for multimodal large language models. In ASE , 2025. [13] Y . Jeong, M. Kim, S. W . Hwang, and B. H. Kim. Agent-as-judge for factual summarization of long narrativ es. 2025. [14] Z. Liu, P . W ang, R. Xu, S. Ma, C. Ruan, P . Li, Y . Liu, and Y . W u. Inference-time scaling for generalist rew ard modeling, 2025. [15] K. Lu and T . M. Lab . On-policy distillation. Thinking Machines Lab: Connectionism , 2025. https://thinkingmachines.ai/blog/on-policy-distillation. 49 [16] W . Ma, H. Zhang, L. Zhao, Y . Song, Y . W ang, Z. Sui, and F . Luo. Stabilizing moe reinforcement learning by aligning training and inference routers, 2025. [17] D. Mahan, D. V . Phung, R. Rafailov , C. Blagden, N. Lile, L. Castricato, J.-P . Fränken, C. Finn, and A. Albalak. Generativ e rew ard models, 2024. [18] S. Mehri, X. Y ang, T . Kim, G. T ur , S. Mehri, and D. Hakkani-Tr . Goal alignment in llm-based user simulators for con versational ai. 2025. [19] T . Naous, P . Laban, W . Xu, and J. Neville. Flipping the dialogue: T raining and ev aluating user language models. In CHI , 2025. [20] OpenAI, J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F . L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, R. A vila, I. Babuschkin, S. Balaji, V . Balcom, P . Bal- tescu, H. Bao, M. Ba varian, J. Belgum, I. Bello, J. Berdine, G. Bernadett-Shapiro, C. Berner , L. Bogdonoff, O. Boiko, M. Boyd, A.-L. Brakman, G. Brockman, T . Brooks, M. Brundage, K. Button, T . Cai, R. Campbell, A. Cann, B. Carey , C. Carlson, R. Carmichael, B. Chan, C. Chang, F . Chantzis, D. Chen, S. Chen, R. Chen, J. Chen, M. Chen, B. Chess, C. Cho, C. Chu, H. W . Chung, D. Cummings, J. Currier , Y . Dai, C. Decareaux, T . Degry , N. Deutsch, D. Deville, A. Dhar , D. Dohan, S. Dowling, S. Dunning, A. Ecoffet, A. Eleti, T . Eloundou, D. Farhi, L. Fedus, N. Felix, S. P . Fishman, J. Forte, I. Fulford, L. Gao, E. Georges, C. Gibson, V . Goel, T . Gogineni, G. Goh, R. Gontijo-Lopes, J. Gordon, M. Grafstein, S. Gray , R. Greene, J. Gross, S. S. Gu, Y . Guo, C. Hallacy , J. Han, J. Harris, Y . He, M. Heaton, J. Heidecke, C. Hesse, A. Hicke y , W . Hickey , P . Hoeschele, B. Houghton, K. Hsu, S. Hu, X. Hu, J. Huizing a, S. Jain, S. Jain, J. Jang, A. Jiang, R. Jiang, H. Jin, D. Jin, S. Jomoto, B. Jonn, H. Jun, T . Kaftan, Łukasz Kaiser , A. Kamali, I. Kanitscheider , N. S. Keskar , T . Khan, L. Kilpatrick, J. W . Kim, C. Kim, Y . Kim, J. H. Kirchner, J. Kiros, M. Knight, D. K okotajlo, Łukasz Kondraciuk, A. K ondrich, A. K onstantinidis, K. Kosic, G. Krue ger, V . Kuo, M. Lampe, I. Lan, T . Lee, J. Leike, J. Leung, D. Levy , C. M. Li, R. Lim, M. Lin, S. Lin, M. Litwin, T . Lopez, R. Lowe, P . Lue, A. Makanju, K. Malfacini, S. Manning, T . Markov , Y . Markovski, B. Martin, K. Mayer , A. Mayne, B. Mc- Gre w , S. M. McKinney , C. McLea vey , P . McMillan, J. McNeil, D. Medina, A. Mehta, J. Menick, L. Metz, A. Mishchenko, P . Mishkin, V . Monaco, E. Morikawa, D. Mossing, T . Mu, M. Murati, O. Murk, D. Mély , A. Nair, R. Nakano, R. Nayak, A. Neelakantan, R. Ngo, H. Noh, L. Ouyang, C. O’Keefe, J. Pachocki, A. Paino, J. Palermo, A. Pantuliano, G. Parascandolo, J. Parish, E. Parparita, A. Passos, M. P avlov , A. Peng, A. Perelman, F . de A vila Belbute Peres, M. Petrov , H. P . de Oliv eira Pinto, Michael, Pokorn y , M. Pokrass, V . H. Pong, T . Powell, A. Power , B. Po wer , E. Proehl, R. Puri, A. Radford, J. Rae, A. Ramesh, C. Raymond, F . Real, K. Rimbach, C. Ross, B. Rotsted, H. Roussez, N. Ryder, M. Saltarelli, T . Sanders, S. Santurkar , G. Sastry , H. Schmidt, D. Schnurr , J. Schulman, D. Selsam, K. Sheppard, T . Sherbako v , J. Shieh, S. Shoker , P . Shyam, S. Sidor , E. Sigler, M. Simens, J. Sitkin, K. Slama, I. Sohl, B. Sokolo wsky , Y . Song, N. Staudacher , F . P . Such, N. Summers, I. Sutskev er , J. T ang, N. T ezak, M. B. Thompson, P . T illet, A. T ootoonchian, E. Tseng, P . Tuggle, N. T urley , J. T worek, J. F . C. Uribe, A. V allone, A. V ijayver giya, C. V oss, C. W ainwright, J. J. W ang, A. W ang, B. W ang, J. W ard, J. W ei, C. W einmann, A. W elihinda, P . W elinder, J. W eng, L. W eng, M. Wiethof f, D. W illner, C. W inter , S. W olrich, H. W ong, L. W orkman, S. W u, J. W u, M. W u, K. Xiao, T . Xu, S. Y oo, K. Y u, Q. Y uan, W . Zaremba, R. Zellers, C. Zhang, M. Zhang, S. Zhao, T . Zheng, J. Zhuang, W . Zhuk, and B. Zoph. Gpt-4 technical report, 2024. [21] L. Ouyang, J. W u, X. Jiang, D. Almeida, C. L. W ainwright, P . Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray , J. Schulman, J. Hilton, F . Kelton, L. Miller , M. Simens, A. Askell, P . W elinder, P . Christiano, J. Leike, and R. Lowe. Training language models to follo w instructions with human feedback, 2022. [22] E. H. P ark and V . C. Storey . Emotion ontology studies: A framew ork for expressing feelings digitally and its application to sentiment analysis. ACM Computing Surve ys , 55(9):1–38, Jan 2023-01. [23] J. S. Park, J. C. O’Brien, C. J. Cai, M. R. Morris, P . Liang, and M. S. Bernstein. Generativ e agents: Interactive simulacra of human beha vior, 2023. 50 [24] K. Rohit, A. Shankar , G. Katiyar , A. Mehrotra, and E. A. Alzeiby . Consumer engagement in chatbots and voicebots. a multiple-e xperiment approach in online retailing context. Journal of Retailing and Consumer Services , 78:103728, May 2024-05. [25] M. Schurz, J. Radua, M. G. Tholen, L. Maliske, D. S. Margulies, R. B. Mars, J. Sallet, and P . Kanske. T oward a hierarchical model of social cognition: A neuroimaging meta-analysis and integrati ve review of empathy and theory of mind. Psychological Bulletin , 147(3):293–327, Mar 2021-03. [26] B. Seed. Seed1.5-thinking: Adv ancing superb reasoning models with reinforcement learning, 2025. [27] S. G. Shamay-Tsoory , J. Aharon-Peretz, and D. Perry . T wo systems for empathy: a double disso- ciation between emotional and cognitiv e empathy in inferior frontal gyrus versus ventromedial prefrontal lesions. Brain , 132(3):617–627, Mar 2009-03. [28] G. Sheng, C. Zhang, Z. Y e, X. W u, W . Zhang, R. Zhang, Y . Peng, H. Lin, and C. W u. Hybridflow: A flexible and ef ficient rlhf framework. arXiv preprint arXiv: 2409.19256 , 2024. [29] A. Shenha v . The af fectiv e gradient hypothesis: an affect-centered account of motiv ated behavior . T r ends in Cognitive Sciences , 28(12):1089–1104, Dec 2024-12. [30] K. T eam, Y . Bai, Y . Bao, G. Chen, J. Chen, N. Chen, R. Chen, Y . Chen, Y . Chen, Y . Chen, Z. Chen, J. Cui, H. Ding, M. Dong, A. Du, C. Du, D. Du, Y . Du, Y . Fan, Y . Feng, K. Fu, B. Gao, H. Gao, P . Gao, T . Gao, X. Gu, L. Guan, H. Guo, J. Guo, H. Hu, X. Hao, T . He, W . He, W . He, C. Hong, Y . Hu, Z. Hu, W . Huang, Z. Huang, Z. Huang, T . Jiang, Z. Jiang, X. Jin, Y . Kang, G. Lai, C. Li, F . Li, H. Li, M. Li, W . Li, Y . Li, Y . Li, Z. Li, Z. Li, H. Lin, X. Lin, Z. Lin, C. Liu, C. Liu, H. Liu, J. Liu, J. Liu, L. Liu, S. Liu, T . Y . Liu, T . Liu, W . Liu, Y . Liu, Y . Liu, Y . Liu, Y . Liu, Z. Liu, E. Lu, L. Lu, S. Ma, X. Ma, Y . Ma, S. Mao, J. Mei, X. Men, Y . Miao, S. Pan, Y . Peng, R. Qin, B. Qu, Z. Shang, L. Shi, S. Shi, F . Song, J. Su, Z. Su, X. Sun, F . Sung, H. T ang, J. T ao, Q. T eng, C. W ang, D. W ang, F . W ang, H. W ang, J. W ang, J. W ang, J. W ang, S. W ang, S. W ang, Y . W ang, Y . W ang, Y . W ang, Y . W ang, Y . W ang, Z. W ang, Z. W ang, Z. W ang, C. W ei, Q. W ei, W . W u, X. W u, Y . W u, C. Xiao, X. Xie, W . Xiong, B. Xu, J. Xu, J. Xu, L. H. Xu, L. Xu, S. Xu, W . Xu, X. Xu, Y . Xu, Z. Xu, J. Y an, Y . Y an, X. Y ang, Y . Y ang, Z. Y ang, Z. Y ang, Z. Y ang, H. Y ao, X. Y ao, W . Y e, Z. Y e, B. Y in, L. Y u, E. Y uan, H. Y uan, M. Y uan, H. Zhan, D. Zhang, H. Zhang, W . Zhang, X. Zhang, Y . Zhang, Y . Zhang, Y . Zhang, Y . Zhang, Y . Zhang, Y . Zhang, Z. Zhang, H. Zhao, Y . Zhao, H. Zheng, S. Zheng, J. Zhou, X. Zhou, Z. Zhou, Z. Zhu, W . Zhuang, and X. Zu. Kimi k2: Open agentic intelligence, 2025. [31] Q. T eam. Qwen3 technical report, 2025. [32] Q. T u, S. Fan, Z. Tian, T . Shen, S. Shang, X. Gao, and R. Y an. CharacterEval: A Chinese benchmark for role-playing con versational agent ev aluation. In L.-W . Ku, A. Martins, and V . Srikumar , editors, Pr oceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (V olume 1: Long P apers) , pages 11836–11850, Bangkok, Thailand, Aug. 2024. Association for Computational Linguistics. [33] B. W ang, R. Lin, K. Lu, L. Y u, Z. Zhang, F . Huang, C. Zheng, K. Dang, Y . Fan, X. Ren, A. Y ang, B. Hui, D. Liu, T . Gui, Q. Zhang, X. Huang, Y .-G. Jiang, B. Y u, J. Zhou, and J. Lin. W orldpm: Scaling human preference modeling, 2025. [34] B. W ang, R. Lin, K. Lu, L. Y u, Z. Zhang, F . Huang, C. Zheng, K. Dang, Y . Fan, X. Ren, A. Y ang, B. Hui, D. Liu, T . Gui, Q. Zhang, X. Huang, Y .-G. Jiang, B. Y u, J. Zhou, and J. Lin. W orldpm: Scaling human preference modeling, 2025. [35] J. W ei, X. W ang, D. Schuurmans, M. Bosma, B. Ichter, F . Xia, E. Chi, Q. Le, and D. Zhou. Chain-of-thought prompting elicits reasoning in large language models, 2023. [36] E. W eisz and M. Cikara. Strategic regulation of empathy . Oct 2020-10. [37] C. Whitehouse, T . W ang, P . Y u, X. Li, J. W eston, I. Kuliko v , and S. Saha. J1: Incentivizing thinking in llm-as-a-judge via reinforcement learning, 2025. 51 [38] G. Xu, J. Liu, M. Y an, H. Xu, J. Si, Z. Zhou, P . Y i, X. Gao, J. Sang, R. Zhang, J. Zhang, C. Peng, F . Huang, and J. Zhou. Cvalues: Measuring the values of chinese lar ge language models from safety to responsibility , 2023. [39] J. Y ang. Firefly: A chinese conv ersational large language model. https://github.com/ yangjianxin1/Firefly , 2023. [40] G. Zhang, Y . Shi, R. Liu, R. Y uan, Y . Li, S. Dong, Y . Shu, Z. Li, Z. W ang, C. Lin, et al. Chinese open instruction generalist: A preliminary release, 2023. [41] J. E. Zhang, J. Broekens, and J. P . P . Jokinen. Modeling cognitiv e-affectiv e processes with ap- praisal and reinforcement learning. IEEE T ransactions on Affective Computing , 16(2):771–782, Apr 2025-04. [42] C. Zheng, S. Liu, M. Li, X.-H. Chen, B. Y u, C. Gao, K. Dang, Y . Liu, R. Men, A. Y ang, J. Zhou, and J. Lin. Group sequence policy optimization, 2025. [43] L. Zheng, W .-L. Chiang, Y . Sheng, S. Zhuang, Z. W u, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. P . Xing, H. Zhang, J. E. Gonzalez, and I. Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023. [44] J. Zhou, T . Lu, S. Mishra, S. Brahma, S. Basu, Y . Luan, D. Zhou, and L. Hou. Instruction- following e valuation for lar ge language models, 2023. [45] X. Zhou, H. Zhu, L. Mathur , R. Zhang, H. Y u, Z. Qi, L.-P . Morenc y , Y . Bisk, D. Fried, G. Neubig, and M. Sap. Sotopia: Interactiv e ev aluation for social intelligence in language agents, 2024. [46] M. Zhuge, C. Zhao, D. R. Ashley , W . W ang, D. Khizbullin, Y . Xiong, Z. Liu, E. Chang, R. Krishnamoorthi, Y . Tian, Y . Shi, V . Chandra, and J. Schmidhuber . Agent-as-a-judge: Evaluate agents with agents. In F orty-second International Confer ence on Machine Learning , 2025. 52
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment