비전 프라이어와 전문가 융합으로 멀티모달 데이터 품질을 높이다
VERITAS는 이미지에서 추출한 객체·텍스트 프라이어와 GPT‑4o·Gemini‑2.5·Doubao‑1.5 등 세 개의 최첨단 멀티모달 모델이 제공하는 비판 점수를 제임스‑스틴식 가중 평균으로 융합한다. 융합된 고신뢰 점수를 지도로 사용해 7B 규모의 경량 비판 모델을 GRPO로 학습하고, 이를 통해 원본 답변을 재작성·선별한다. 실험 결과, VERITAS로 정제한 SFT 데이터로 학습한 모델이 여섯 개 벤치마크에서 평균 +7.4 % 향상되었…
저자: ** 정보 제공되지 않음 (논문에 저자 명시가 없음) **
**1. 연구 배경 및 동기**
대규모 멀티모달 모델(LMM)은 이미지와 텍스트를 동시에 이해·생성하는 능력으로 다양한 응용 분야에서 주목받고 있다. 그러나 이러한 모델의 최종 성능은 감독‑미세조정(SFT) 단계에서 사용되는 데이터의 품질에 크게 좌우된다. 기존 연구들은 질문‑답변 쌍을 대규모 LLM이나 LMM이 자동 생성하도록 했지만, 시각적 인식 능력이 부족한 모델이 만든 답변에는 사실 오류·시각적 환각·스타일 불일치가 빈번히 발생한다. 이런 노이즈가 그대로 SFT에 투입되면 연산 자원을 낭비할 뿐 아니라 모델이 도달할 수 있는 정확도 상한을 낮춘다.
**2. 핵심 아이디어**
VERITAS는 두 가지 핵심 가정을 기반으로 설계되었다. 첫째, 최신 객체 탐지기와 OCR 시스템은 인간 수준에 근접한 세밀한 시각 인식을 제공하므로, 이를 “비전 프라이어”로 활용하면 LMM이 직접 관찰하기 어려운 시각 정보를 외부에서 보강할 수 있다. 둘째, 단일 LMM을 평가자로 삼는 것은 편향과 오류를 증폭시킬 위험이 크다. 따라서 서로 다른 아키텍처·학습 목표를 가진 다수의 LMM을 독립적으로 평가하게 하고, 통계적 융합을 통해 보다 신뢰할 수 있는 “합의 점수”를 도출한다.
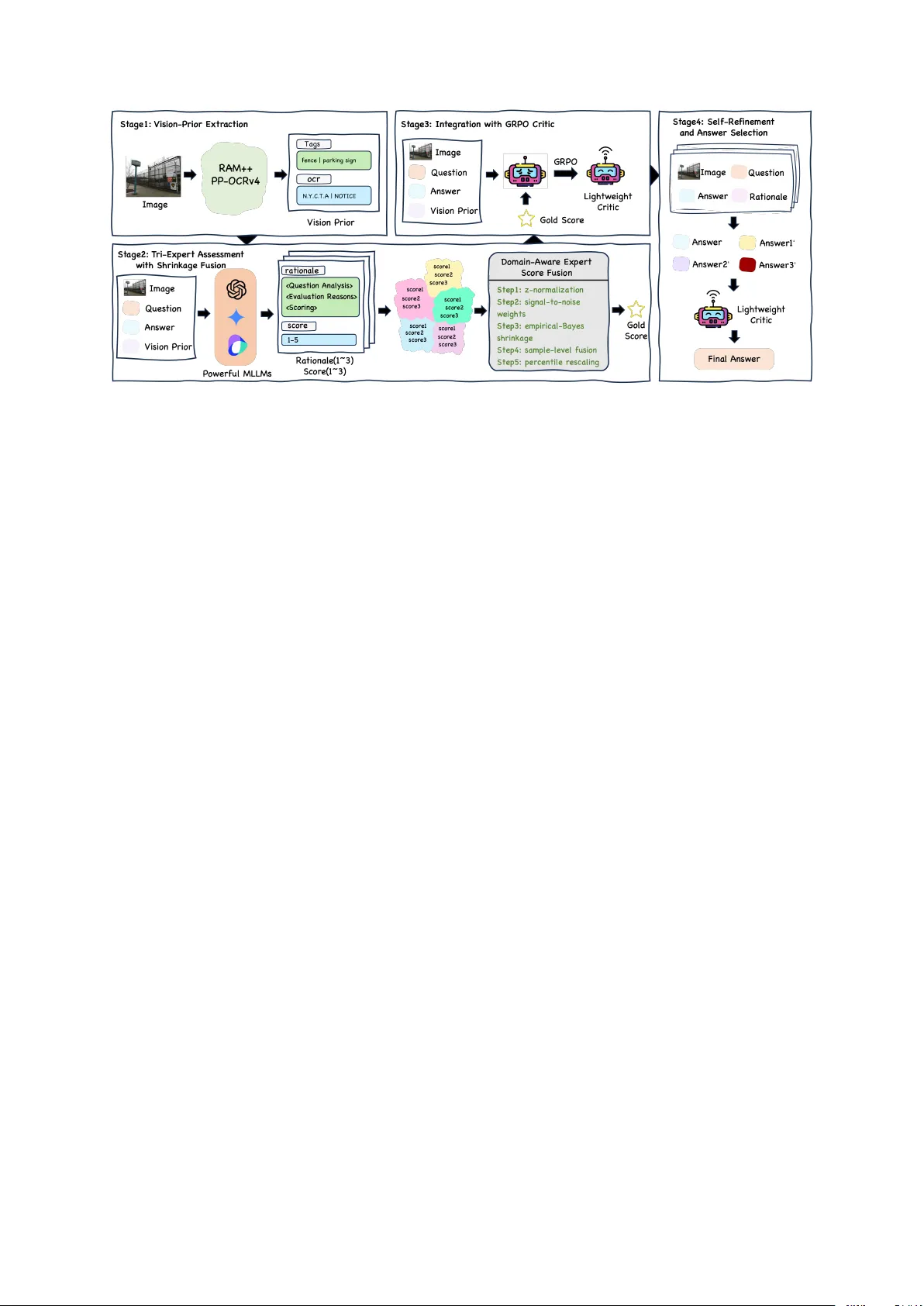
**3. 파이프라인 구성**
VERITAS는 네 단계로 이루어진 파이프라인이다.
- **Stage 1 비전‑프라이어 추출**: 입력 이미지 I에 대해 RAM++(객체 탐지)와 PP‑OCRv4(텍스트 인식)를 적용해 태그와 OCR 문자열을 얻는다. 이들을 “V = {tags, OCR}” 형태의 문자열로 직렬화하고, 이후 모든 프롬프트에 자연어 래퍼로 삽입한다.
- **Stage 2 Tri‑Expert Assessment with Shrinkage Fusion**: GPT‑4o, Gemini‑2.5‑Pro, Doubao‑1.5‑pro가 각각 (I, q, a₀, V) 를 입력받아 점수 sₘ∈
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기