VERITAS: Leveraging Vision Priors and Expert Fusion to Improve Multimodal Data
The quality of supervised fine-tuning (SFT) data is crucial for the performance of large multimodal models (LMMs), yet current data enhancement methods often suffer from factual errors and hallucinations due to inadequate visual perception. To addres…
Authors: ** 정보 제공되지 않음 (논문에 저자 명시가 없음) **
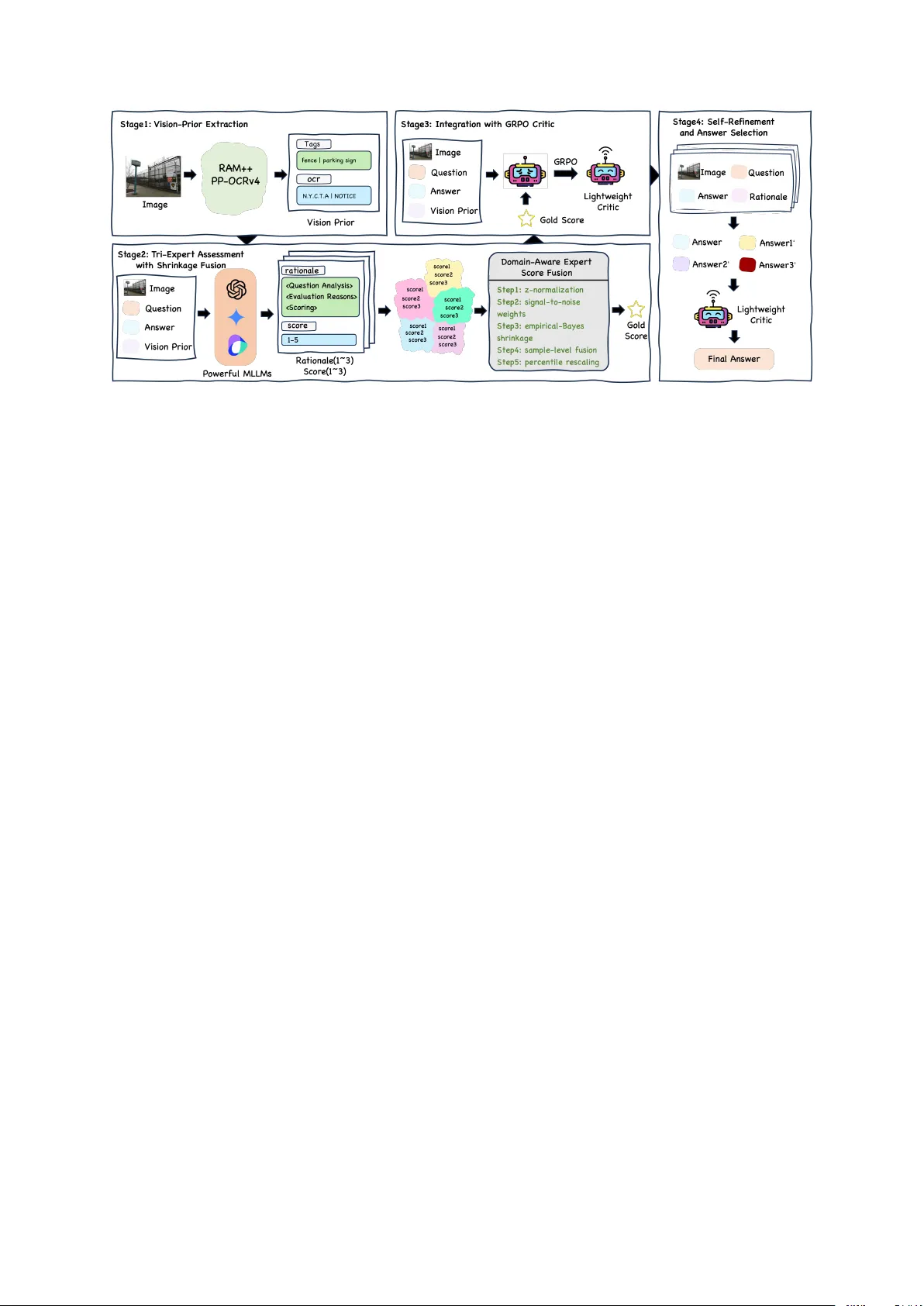
VERIT AS: Lev eraging V ision Priors and Expert Fusion to Impr ov e Multimodal Data Tingqiao Xu 1 * , Ziru Zeng 1 * , Jiayu Chen 2 1 Shanghai Jiao T ong Uni versity 2 Fudan Uni versity phenomenonkj@sjtu.edu.cn Abstract The quality of supervised fine-tuning (SFT) data is crucial for the performance of large multimodal models (LMMs), yet current data enhancement methods often suffer from fac- tual errors and hallucinations due to inadequate visual perception. T o address this challenge, we propose VERIT AS, a pipeline that system- atically integrates vision priors and multiple state-of-the-art LMMs with statistical methods to enhance SFT data quality . VERIT AS le ver - ages visual recognition models (RAM++) and OCR systems (PP-OCRv4) to extract structured vision priors, which are combined with images, questions, and answers. Three LMMs (GPT - 4o, Gemini-2.5-Pro, Doubao-1.5-pro) ev aluate the original answers, providing critique ratio- nales and scores that are statistically fused into a high-confidence consensus score serving as ground truth. Using t his consensus, we train a lightweight critic model via Group Relativ e Policy Optimization (GRPO), enhancing rea- soning capabilities efficiently . Each LMM then refines the original answers based on the cri- tiques, generating ne w candidate answers; we select the highest-scoring one as the final re- fined answer . Experiments across six multi- modal benchmarks demonstrate that models fine-tuned with data processed by VERIT AS consistently outperform those using raw data, particularly in text-rich and fine-grained rea- soning tasks. Our critic model exhibits en- hanced capability comparable to state-of-the- art LMMs while being significantly more ef- ficient. W e release our pipeline, datasets, and model checkpoints to advance research in mul- timodal data optimization. 1 Introduction Large multimodal models (LMMs)( Chen et al. , 2024b ; OpenAI , 2024 , 2023 ; W ang et al. , 2024a ; T eam et al. , 2024 ) hav e recently pushed the frontier * Equal contribution. Figure 1: Performance comparison of different models on various benchmarks. of visual–language understanding, yet their ulti- mate performance is still gated by the quality of the supervised-fine-tuning (SFT) data they learn from( Marion et al. , 2023 ; Albalak et al. , 2024 ). While recent work( Luo et al. , 2024 ; Liu et al. , 2024b ) enlarges instruction di versity or directly lets a single strong LMM (e.g., GPT -4o( OpenAI , 2024 )) synthesize answers ( Fang et al. , 2024 ; Guo et al. , 2024 ; Gu et al. , 2024 ), the generated re- sponses frequently contain factual mistakes, visual hallucinations, or stylistic inconsistencies( Bai et al. , 2024 ; Liu et al. , 2024a ; W ang et al. , 2024b ). Feed- ing such noisy data back to SFT not only wastes computation b ut also hard-limits the attainable ac- curacy of do wnstream models. T wo observ ations motiv ate this study . First, spe- cialized vision experts such as object detectors and OCR systems remain more reliable than any cur- rent LMM on fine-grained perception( Zhang et al. , 2024a ; Fu et al. , 2024b ), thus providing trustwor - thy vision priors. Second, no single LMM can serve as an oracle judge: their preferences are bi- ased, and self-e v aluation amplifies their o wn errors. Therefore, high-quality multimodal data requires (i) external vision priors to ground the scene, (ii) multiple strong but div erse LMM critics to offset indi vidual bias, and (iii) a principled way to fuse these heterogeneous signals at lo w cost. W e introduce VERIT AS , a pipeline for V ision-Priors E v aluation and R efinement through I ntegration of T ri-Expert A ssessment with S hrinkage, that systematically upgrades multi- modal SFT data through four tightly coupled components: (1) V ision-Prior Extraction employs RAM++ ( Huang et al. , 2023 ) and PP-OCRv4 ( PaddleOCR , 2024 ) to con vert images into structured tags and texts that are provided to all subsequent modules, ef fecti vely anchoring the critique on observable evidence. (2) T ri-Expert Assessment queries three state-of-the-art LMMs (GPT -4o, Gemini-2.5-Pro( Kavukcuoglu , 2025 ), Doubao-1.5-pro( T eam , 2025 )) for chain-of-thought critiques and numeric scores. A domain-aware James-Stein–style shrinkage then statistically fuses the three noisy scores into a high-confidence gold score ˆ S , reducing v ariance without sacrificing un- biasedness. (3) Integration with GRPO in volv es training a 7B-parameter multimodal critic using Group Relativ e Policy Optimization (GRPO)( Shao et al. , 2024 ), enabling reasoning-based e v aluation of answers in multimodal SFT data for more accurate assessments. By le veraging group-wise adv antages, the lightweight critic reproduces GPT -4o–le vel ranking fidelity while significantly reducing inference costs. (4) Self-Refinement generates three revised answers conditioned on the vision priors, the expert rationales, and ˆ S . The GRPO Critic selects the best among the original and revised candidates, yielding a final, confidence-graded dataset entry . Extensi ve experiments verify the effecti veness of VERIT AS. When the same 7B model is SFT - trained on our refined data, it outperforms the coun- terpart trained on raw data by +7.4 av erage accu- racy o ver six public benchmarks. The GRPO critic achie ves a Kendall τ of 0.71 with human judg- ments, only 0.05 behind GPT -4o, yet is two orders of magnitude cheaper to run. Our contributions are threefold: • W e propose the first vision-prior+multi-expert scoring framework with domain-aware statisti- cal fusion, theoretically reducing expected risk compared with single-expert or simple a veraging baselines. • W e adapt GRPO to train a lightweight multi- modal critic whose ranking consistency riv als GPT -4o at a fraction of the cost, and demonstrate its usefulness for automated answer selection. • W e release the VERIT AS pipeline, the 96K confidence-annotated multimodal dataset, and all model checkpoints to facilitate future research on robust data curation and e valuation. 2 Related W ork Advancements in Multimodal Evaluation and Critique Ev aluating multimodal models poses significant challenges due to the intricate interplay between visual and textual modalities. Traditional text-based metrics fail to capture the complexity of visual information ( Zheng et al. , 2023 ). The emer- gence of the “LLM-as-a-judge” paradigm, where large language models (LLMs) serv e as ev aluators, has brought transformati ve changes. Recent inno- v ations include methods like EvalPlanner ( Saha et al. , 2025 ), which decomposes the e valuation pro- cess into planning and reasoning stages, employing a self-training loop with supervised fine-tuning and Direct Preference Optimization (DPO) to enhance the e valuator’ s capabilities. Another approach, Self- Generated Critiques ( Y u et al. , 2024 ), lev erages a model’ s own critiques to bolster reward model- ing, providing fine-grained feedback that reduces re ward hacking risks and enhances interpretabil- ity . Similarly , Generative V erifiers ( Zhang et al. , 2024b ) reframe re ward modeling as ne xt-token pre- diction, utilizing the generati ve strengths of lan- guage models to assess input quality without direct scalar scoring. In the multimodal context, models like R1- Re ward ( Zhang et al. , 2025 ) employ reinforcement learning to train multimodal reward models, achiev- ing significant improv ements on benchmarks lik e VL Re wardBench and MM Re ward Bench. How- e ver , these methods often rely on single-model e val- uations, which can introduce biases and accumulate errors, particularly due to the limitations of LMMs in fine-grained visual perception ( Shumailov et al. , 2023 ; Zhang et al. , 2024a ). There is a need for approaches that integrate vision priors from spe- cialized models with assessments from multiple expert LMM critics, employing statistical fusion methods to enhance the reliability of ev aluations while reducing computational costs. Multimodal Data Refinement and Self- Impro vement Mechanisms Enhancing the Figure 2: Overvie w of the proposed pipeline VERIT AS containing four stages: (1) V ision-Prior Extraction, (2) Stage2: T ri-Expert Assessment with Shrinkage Fusion, (3) Integration with GRPO Critic, (4) Self-Refinement and Answer Selection. quality of multimodal training data is essential for adv ancing model performance. Prior efforts like CritiqueMM ( Ke et al. , 2024 ) and VILA ( Fang et al. , 2024 ) utilize iterative self-critique processes, where LMMs refine data using their own feedback. Ho wev er , the inherent limitations of LMMs in visual understanding can lead to error propagation and persistent issues like hallucinations ( Zhang et al. , 2024a ; Shumailov et al. , 2023 ). W e address these problems by integrating vision priors, multi-expert feedback, and a refinement mechanism to enhance multimodal data quality without error accumulation. In summary , a significant research gap exists in systematically integrating domain-specific vision experts with LMMs to enhance multimodal data critique and refinement. Moreover , existing critic models often rely on single-model e valuations with- out harnessing the benefits of multi-expert feedback and statistical confidence fusion. Addressing these issues could overcome current model limitations and improv e the quality of supervised fine-tuning data. 3 Method In this section, we propose VERIT AS , a lean vision-prior + multi-e xpert pipeline for automatic data critique and refinement. The workflow has four concise steps: (1) V ision-Prior Extraction . RAM++ and PP-OCRv4 turn each image into ob- ject tags and OCR text, providing grounded e vi- dence. (2) T ri-Expert Assessment with Shrink- age Fusion . Three strong MLLMs (GPT -4o, Gemini-2.5-Pro, Doubao-1.5-pro) critique each an- swer with the priors; a domain-aware James–Stein shrinkage merges their scores into a single high- confidence label ˆ S . (3) Integration with GRPO Critic . W e distil the costly ensemble into a 7B critic via Group Relativ e Policy Optimisation, re- taining GPT -4o-level ranking at a fraction of the cost. (4) Self-Refinement and Answer Selection . The experts rewrite the answer; the GRPO critic selects the best candidate, yielding a confidence- graded, denoised dataset. This compact design grounds vision, mitigates single-model bias, and scales high-quality multi- modal SFT data. 3.1 Data Collection T o v alidate model generalization capabilities on heterogeneous data, we systematically collected 7 benchmark datasets covering 6 core visual- language tasks: Fine-grained image caption le ver - ages Image T extualization ( Pi et al. , 2024 ) and T extCaps ( Sidorov et al. , 2020 ); LLaV AR ( Zhang et al. , 2023 ) enhances te xt-rich image understand- ing; Domain-specific reasoning employs QA pairs from AI2D(GPT4V) ( Li et al. , 2024 ); Complex reasoning synthesizes instances from ShareGPT4V ( Chen et al. , 2024a ); Multi-turn dialogue and rea- soning modeling utilizes LR V -Normal ( Li et al. , 2024 ) for long-term context tracking; Hallucination mitigation integrates samples in LR V -Instruction ( Liu et al. , 2023 ). The final dataset comprises 96K samples, com- prehensi ve statistics are provided in T able 1 . Dataset Samples Image T extualization 14,825 T extCaps 11,014 LLaV AR 19,774 AI2D (GPT4V) 4,864 ShareGPT4V 15,001 LR V -Normal 10,477 LR V -Instruction 20,000 T otal 95,955 T able 1: Data Collection Statistics. In total, 95,955 samples were gathered. 3.2 VERIT AS: A F our -Stage Pipeline f or Data Critique and Refinement T o mov e beyond a single-critic setting, VERI- T AS decomposes data curation into four succes- si ve stages, each adding an orthogonal source of reliability . Figure 2 giv es an ov erview . Stage 1: V ision-Prior Extraction W e first ground ev ery sample with explicit perceptual ev- idence. T wo off-the-shelf specialist models are in v oked on the input image I : T ags = RAM ++ ( I ) , (1) OCR = PP - OCRv4( I ) . (2) The resulting object labels and text strings are se- rialised as a string prior V = { T ags , OCR } and appended to all subsequent prompts using a natural- language wrapper . Stage 2: T ri-Expert Assessment with Shrinkage Fusion Multi-Expert Critique. Three state-of-the-art MLLMs (GPT -4o, Gemini-2.5-Pro, and Doubao- 1.5-pro) independently assess answer quality , with each model m producing: ( s m , r m ) = M ( m ) critic ( I , q , a 0 , V | E c ) (3) where s m ∈ [0 , 5] is a scalar score and r m is a structured rationale follo wing our e valuation rubric E c . Each expert recei ves the same vision priors extracted in Stage 1, ensuring grounded assess- ments.(The complete prompt template is shown in Appendix ?? ) Domain-A war e Score Fusion. Three MLLMs produce raw scores s m ( n ) ∈ [0 , 5] . W e transform them into a single confidence ˆ S ( n ) through the follo wing steps. (1) z-normalise each critic inside its domain; (2) compute a domain-wise signal-to- noise ratio (SNR) and use it as a weight; (3) shrink that weight tow ard a corpus prior via an empirical- Bayes factor α d = N d / ( N d + λ ) ; (4) form the weighted a verage of the normalised scores; (5) map the result back to the 0–5 rubric by a rob ust 5 %–95 % percentile stretch. The specific process is pre- sented in Algorithm 1 Stage 3: Integration with GRPO Critic W e dis- til fused judgement ˆ S into a 7B parameter critic using Gr oup Relative P olicy Optimisation (GRPO). GRPO eliminates an extra v alue–function by com- paring the candidate answer with a gr oup baseline drawn from the same old polic y , thereby producing a lo w-variance, self-normalising adv antage. T raining objective. For ev ery image–question pair q , we sample a group of G drafts { o i } G i =1 from the policy π θ old . The ne w policy π θ is updated by maximising J GRPO ( θ ) = E q , { o i } 1 G G X i =1 1 | o i | | o i | X t =1 " min π i,t θ π i,t θ old ˆ A i,t , clip π i,t θ π i,t θ old , 1 − ϵ, 1 + ϵ ˆ A i,t − β D KL π θ ∥ π ref # , (4) where ˆ A i,t is the group–relati ve adv antage Rewar d design. Each rollout receiv es two addi- ti ve re wards R i = R acc + R fmt : • Accuracy rew ard ( R acc ) compares the scalar score extracted from o i with the Stage-2 “gold” ˆ S R acc = max 0 , 1 − | int ( o i ) − ˆ S | 5 . (5) • Format reward ( R fmt ) encourages the critic style we need do wnstream: N =# ∈ o i + # ∈ o i + # ∈ o i (6) R fmt = 0 . 5 × N 3 (7) The indicator function # s k ∈ o i equals 1 if s k appears in o i , and 0 otherwise (A full deri vation and risk analysis are deferred to Appendix B .) Stage 4: Self-Refinement and Answer Selec- tion The rationales { r m } and score ˆ S serve as Algorithm 1: Domain-A ware Expert Score Fusion input : Scores s m ( n ) , m = 1 .. 3 ; domain labels d ( n ) ; constants ϵ = 10 − 3 , λ = 100 output : Fused confidence ˆ S ( n ) ∈ [0 , 5] 1 Step 0: domain statistics for m ← 1 to 3 do 2 for d ∈ D do 3 µ m,d ← mean ( s m ( n ) | d ( n ) = d ) 4 σ m,d ← std ( s m ( n ) | d ( n ) = d ) 5 Step 1: z-normalisation for each samples n do 6 for m ← 1 to 3 do 7 z m ( n ) ← s m ( n ) − µ m,d ( n ) σ m,d ( n ) + ϵ 8 Step 2: signal-to-noise weights for m ← 1 to 3 do 9 for d ∈ D do 10 Consensus d ← mean k ( s k | d ) 11 r m ( n ) ← s m ( n ) − Consensus d 12 Sig m,d ← std ( s m | d ) 13 Noise m,d ← std ( r m | d ) 14 Raw weight m,d ← Sig m,d Noise m,d + ϵ 15 Step 3: empirical-Bayes shrinkage f or m ← 1 to 3 do 16 w m ← mean d ( Raw weight m,d ) 17 for d ∈ D do 18 α d ← N d N d + λ 19 for m ← 1 to 3 do 20 ˆ w m,d ← α d · Raw weight m,d + (1 − α d ) · w m 21 Normalize: ˆ w m,d ← ˆ w m,d P 3 k =1 ˆ w k,d 22 Step 4: sample-level fusion f oreach samples n do 23 ˆ z ( n ) ← P 3 m =1 ˆ w m,d ( n ) · z m ( n ) 24 Step 5: percentile r escaling ( q low , q high ) ← 5% / 95% quantiles of { ˆ z ( n ) } 25 for each samples n do 26 ˆ S ( n ) ← 5 · clip ˆ z ( n ) − q low q high − q low , 0 , 1 27 retur n ˆ S ( n ) fine-grained feedback for re writing(The complete prompt template is sho wn in Appendix ?? ): a ′ m = M ( m ) rewrite ( I , q , a 0 , r m , ˆ S | E r ) . (8) W e form a candidate pool C = { a 0 , a ′ 1 , a ′ 2 , a ′ 3 } and ask the GRPO critic to rescore each candidate: ˜ s = M GRPO ( I , q , a, V ) , a ∈ C . (9) The highest-ranked answer ˆ a = arg max a ∈C ˜ s is retained together with its confidence ˆ S and a merged rationale ¯ r . The refined dataset D refine = { ( I , q , ˆ a, ˆ S , ¯ r ) } achie ves substantial quality gains without shrinking in size, overcoming the sev ere recall loss of rigid threshold filtering. This four-stage design grounds each judgement in observable evidence, balances multiple expert opinions through principled statistics, amortises cost via a compact critic, and finally deliv ers high- confidence, hallucination-free multimodal supervi- sion. A complete example of the entire process is provided in Appendix ?? 4 Experimental Setup This section describes all data resources, model configurations, and e valuation protocols used in our study . 4.1 T raining Corpora VERIT AS Instruction Corpus. T able 1 lists se ven public multimodal instruction sources that form our base corpus. For each source we keep the original R A W answer and the R E FI N E answer produced by the VERIT AS pipeline, resulting in two parallel sets( D raw and D refine ) of identical size (95,955 samples each). 4.2 Critic-Evaluation Sets In-domain 1K. T o assess in-domain rank- ing fidelity , we randomly sample 1,000 im- age–question–answer triplets from the same sev en sources while ensuring no overlap with the train- ing split. Three human annotators independently assign an integer quality score from 0 (worst) to 5 (best); majority vote is taken as the reference label. Out-of-domain CLEVR-500. W e further probe generalisation with 500 images from the CLEVR( Johnson et al. , 2017 ) test split. All origi- nal answers are correct ( good ). W e automatically inject (i) minor attribute swaps ( medium ) and (ii) se vere object-count or colour mistakes ( bad ) so that the final distrib ution is 160 / 170 / 170. Three human annotators assign ground-truth scores in the same manner as abov e. Full injection rules are provided in Appendix C . 4.3 Down-Stream Benchmarks W e adopt six widely-used public benchmarks that cov er perception, reasoning, and hallucination: • MME ( Fu et al. , 2024a ): 14 binary diagnostics for basic perception. • OCR-VQA ( Mishra et al. , 2019 ): text-in-image understanding. • MM-V et ( Y u et al. , 2023 ): open-ended ev alua- tion across 16 capabilities. • MathV ista ( Lu et al. , 2023 ): visual-symbolic mathematical reasoning. • MMT -bench ( Y ing et al. , 2024 ): 32 meta-tasks including autonomous dri ving. • POPE ( Li et al. , 2023 ): hallucination detection. All e valuations are conducted using the Vlme valkit ( Duan et al. , 2024 ) toolkit. 4.4 Model and T raining Details Model Architectur e. Every model in this study is based on Qwen2-VL-7B. W e load the Q W E N 2 - V L - I N S T R U C T checkpoints as initialisation and keep the vision encoder frozen throughout. Instruction Fine-tuning. Models trained on the Raw and Refine splits of the VERIT AS Instruc- tion Corpus are each fine-tuned for one epoch with learning rate 5e-6, batch size 64, and cosine de- cay . The identical hyper-parameter configuration is applied to e very ablation v ariant to ensure a fair comparison. Lightweight GRPO critic. F or the lightweight critic, we finetune another Qwen2-VL-7B using GRPO. Before commencing GRPO training, we first performed a "cold start" training using 6,000 data samples. Each update samples G =128 can- didate rationales, and the total training lasts one epoch ov er the 95,955 fused score items. W e set β =0 . 01 for the KL term and clip ratio ϵ =0 . 2 . 4.5 Baselines and Ablations T o isolate the contribution of ev ery component, we instantiate se ven SFT v ariants: (a) Raw : trained on D raw . (b) VERIT AS : full pipeline, trained on D refine . (c) 1-Expert +VP : one LMM critic + vision pri- ors, no fusion. (d) 1-Expert : one LMM critic, no vision priors. (e) Filter -Only : remov e samples with ˆ S < τ (keep ≈ 50 K), no re writing. (f) VERIT AS(w/o fusion) : replace shrinkage fu- sion with the av erage v alue. (g) VERIT AS(open-source) : replace the closed- source ex- pert trio with open-source models. For the critic task we compare tw o systems: • Lightweight GRPO critic : our distilled critic. • Lightweight SFT critic : supervised fine-tuning on GPT -4o scores and rationales only . 5 Results and Discussion W e first present the impact of the proposed pipeline on downstream task accuracy (§ 5.1 ), then isolate the ef fect of each design choice through ablations (§ 5.2 ). The quality and ef ficiency of the lightweight GRPO critic are analysed in § 5.3 , while § 5.4 ex- amines why the domain–aware fusion is superior to nai ve scoring. 5.1 Overall Down-stream P erf ormance T able 2 summarises the accuracy of se ven SFT v ariants on six public benchmarks. Large gains on perception-centric tasks. VER- IT AS deliv ers the strongest improvements on the two perception-hea vy suites, OCR-VQA (+14.35) and MME (+14.2). Because these tasks require precise localisation of characters, symbols and fine details, the explicitly injected vision priors (ob- ject tags + OCR strings) provide grounded evi- dence that the model can directly reference during supervision. The ef fect is already visible in the “1-Expert” ablation, and becomes maximal when multi-expert fusion and re write are enabled. Cross-modal understanding . On MM-V et the full pipeline surpasses the baseline by +6.36 points, markedly higher than an y single ablation. The test set combines 16 question styles (e.g., attribute com- parison, positional reasoning). W e conjecture that (i) denoising remov es contradictory rationales, and (ii) shrinkage fusion supplies a better-calibrated score gradient for learning nuanced cross-modal associations. Hallucination behaviour . On POPE the hallu- cination rate of VERIT AS (87.91 is better) is sta- tistically on par with the baseline (87.97). The negligible -0.06 difference indicates that re writ- ing does not introduce new hallucinations, while the vision priors pre vent the critic from falsely re- warding unsupported statements. Compared with Model MME OCR-VQA MM-V et MathV ista MMT -bench POPE Baseline 1680.9 57.780 50.780 57.3 0.625 87.97 Filter-Only 1669.3 71.908 52.569 58.6 0.633 87.41 1-Expert 1692.4 70.573 50.844 57.0 0.631 85.46 1-Expert(w/o prior) 1681.5 60.424 50.814 57.2 0.629 84.75 VERIT AS(w/o fusion) 1694.2 70.922 55.400 57.6 0.633 86.31 VERIT AS(open-source) 1686.1 64.323 50.240 56.6 0.625 85.28 VERIT AS (Full) 1695.1 72.133 57.142 59.1 0.645 87.91 T able 2: Overall performance comparison of models trained under different configurations on v arious benchmarks. The best performance for each benchmark and model size is highlighted in bold. the "1-Expert(w/o prior)" ablation (–3.2) and the "1-Expert" ablation (–2.5), vision priors and multi- expert verification clearly reduce hallucination risk. 5.2 Ablation Studies Impact of V ision Priors Comparing 1 - E X P E RT with 1 - E X P E RT ( W / O P R I O R ) isolates the effect of importing object tags and OCR strings from exter - nal detectors. The prior raises OCR-VQA by +10.1 points and MME by +10.9, while leaving general reasoning tasks largely unchanged. Such gains con- firm that the critic benefits from explicit lo w-le vel e vidence when judging fine-grained answers; with- out it, the single-expert critic often fails to spot subtle transcription or attribute errors that state- of-the-art LMMs occasionally make. The modest improv ement on POPE (+0.7) suggests that the prior also mitigates hallucinations stemming from non-existent te xt or objects. An illustrativ e exam- ple demonstrating ho w the vision prior aids the answer critique is presented in Figure 3 . Multi-Expert Scoring and Diversity Driven Rewriting T o quantify the contribution of multi- expert scoring, we contrast V E R I T A S ( F U L L ) with the single-expe rt variant 1 - E X P E RT . Adding two further experts increases the number of (score,rationale) pairs from one to three; conse- quently , the rewriter produces three alternati ve an- swers, and the GRPO critic selects the best among four candidates in total. As reported in T able 2 , this additional div er- sity yields consistent improv ements on four of the six benchmarks: MM-V et (+6.30), MME (+2.70), OCR-VQA (+1.37), and MathV ista (+1.8). Be- cause MM-V et comprises 16 heterogeneous ques- tion types (attribute comparison, positional reason- ing, etc.), the large margin indicates that critics with dif ferent inductiv e biases expose complementary error patterns that a single e xpert fails to unco ver . The GRPO critic can therefore select higher-quality Figure 3: A Comparativ e Analysis of Critique Before and After the Inte gration of V ision Prior in GPT -4o. The sections marked in red denote inaccuracies in the answer and also reflect the critique model’ s identification of these errors, while the sections highlighted in green represent accurate critique. re writes from a richer hypothesis space, translating into measurable do wnstream gains. GRPO Critic: Selecting among Rewrites vs. Discarding Data A hard-filter baseline ( F I LT E R - O N LY ) removes lo w-scored items, which improves OCR-VQA performance but eliminates 46 % of the training set, thereby limiting the di versity and richness of the training data and lo wering MME by 11.6 points. Our alternative k eeps coverage: for ev- ery filtered sample we generate three expert-guided re writes, then let the GRPO critic rescore the origi- nal plus the re writes and keep the top candidate. Empirically , GRPO selection outperforms hard filtering on all tasks: relativ e to F I L T E R - O N L Y , the full VERIT AS pipeline gains +25.8 on MME and +4.6 on MM-V et while remaining parity on hallu- cination (POPE). Thus, choosing the best among multiple re writes yields a markedly better qual- ity–quantity trade-of f than simply discarding noisy samples. Impact of Shrinkage Fusion Compared to mean-and-round averaging in VERIT AS(w/o fu- sion), the domain-aware shrinkage fusion in VERI- T AS(Full) yields consistent impro vements on ke y suites, notably around +1.2 on OCR-VQA and +1.7 on MM-V et, while also lowering hallucinations as reflected on POPE. W e attribute these gains to better cross-domain calibration via per-domain z- normalization and SNR-based weighting, variance reduction from James–Stein–style shrinkage (espe- cially in lo w-data domains), and the preservation of continuous supervision tar gets that a void quan- tization noise. T ogether , these factors provide a smoother and more faithful training signal for the GRPO critic and lead to more reliable candidate selection during refinement. Scalability and P ortability with Open-Source Expert T rios Replacing the closed-source ex- pert trio with open-source models—Qwen-2.5- VL-72B, InternVL-3-78B, and Ovis2-34B—while keeping the same VERIT AS pipeline (3-Expert, open-source) still delivers clear gains over the baseline, notably on te xt-rich perception and fine- grained recognition suites such as OCR-VQA and MME, demonstrating the method’ s portabil- ity . Howe ver , this open-source v ariant trails VER- IT AS(Full) on reasoning-hea vy and hallucination- sensiti ve benchmarks, indicating that the ultimate performance ceiling remains constrained by the strength of the open-source e xpert models(shown in T able 3 ), stronger critics enable the pipeline to realize its full potential. 5.3 Critic Quality and Efficiency T able 3 in vestigate ho w well each critic reproduces human judgements and ho w robust that beha viour remains under a domain shift. In-domain Evaluation. On the 1K de v set dra wn from the same sev en public data sources, the naive Qwen2 baseline is essentially uncorrelated with human raters ( r =0 . 12 ). Both distillation methods greatly narrow the gap to GPT -4o: the SFT critic reaches r =0 . 689 , while GRPO pushes the figure to 0 . 724 and K endall’ s τ to 0 . 711 , i.e. 89 % of GPT - 4o’ s fidelity—already competiti ve for practical data curation. Out-of-Domain Robustness. The performance gap becomes more pronounced in the out-of- domain CLEVR dataset. The Lightweight GRPO Critic maintains a reasonable correlation (Pearson r = 0 . 628 , Kendall’ s τ = 0 . 601 ), demonstrating robust generalization to unseen data distrib utions. In contrast, the Lightweight SFT Critic experi- ences a significant drop in correlation (Pearson r = 0 . 312 , K endall’ s τ = 0 . 278 ), indicating o ver - fitting to the in-domain data and poor transferabil- ity . W e attribute this to the relative objecti ve of GRPO, which forces the policy to model fine- grained ranking differences rather than absolute score regression, making it less sensiti ve to distri- butional shifts in ra w score ranges. 5.4 Effectiveness of Domain-A ware Fusion Distributional calibration. Figure 4 illustrates the score distributions assigned by the individual critics—GPT -4o, Doubao-1.5-Pro, and Gemini-2.5- Pro—compared to the distribution after applying domain-aw are fusion. The indi vidual critics exhibit v arying scoring tendencies and our fusion method recalibrates these discrepancies, resulting in a more balanced and unimodal distribution that better re- flects the true quality of the data. This demonstrates that domain-aware fusion ef fecti vely combines the strengths of indi vidual critics while mitigating their biases, leading to more reliable and consistent scor - ing across the dataset. Adaptation of critic weights across domains. Figure 5 shows the changes in critic weights be- fore (raw weights) and after fusion (fused weights) across the se ven data sources. The raw weights in- dicate the initial influence of each critic, while the fused weights demonstrate ho w the domain-aware fusion adjusts these weights based on the reliability of each critic in dif ferent domains. Notably , in data source 5, the weight for Gemini-2.5-Pro increases significantly while Doubao-1.5-Pro’ s weight de- creases, reflecting Gemini’ s stronger performance and reliability in that specific domain. This adap- ti ve weighting enhances the overall scoring accu- racy by lev eraging each critic’ s strengths where they are most effecti ve, leading to improv ed data quality for do wnstream tasks. 6 Conclusion In this paper , we introduced VERIT AS , a compre- hensi ve pipeline designed to enhance the quality of multimodal supervised fine-tuning data through the integration of vision priors, multi-e xpert assess- Model In-Domain Out-Domain Pearson-r K endall’ s T au Pearson-r K endall’ s T au Qwen2-VL-7B-Instruct 0.122 0.078 0.165 0.080 InternVL-3-78B 0.421 0.410 0.427 0.422 GPT -4o 0.816 0.761 0.822 0.773 Lightweight SFT critic (ours) 0.689 0.676 0.312 0.278 Lightweight GRPO critic (ours) 0.724 0.711 0.628 0.601 T able 3: Correlation between critic scores and human scores (higher is better). GRPO critic outperforms the SFT critic and approaches GPT -4o while being two orders of magnitude cheaper . ments with domain-aw are statistical fusion, GRPO- based critic training, and self-refinement mecha- nisms. Our extensi ve experiments demonstrate that VERIT AS effecti vely denoises and refines training data, leading to significant impro vements in downstream tasks, particularly in perception- centric benchmarks like OCR-VQA and MME. The lightweight GRPO critic achie ves near-GPT -4o ranking fidelity while operating at a fraction of the computational cost, ensuring both efficienc y and robustness. By systematically addressing issues such as factual errors and hallucinations in the data, VERIT AS not only ele v ates the performance ceil- ing of subsequent large multimodal models but also maintains data di versity and richness. W e believ e that the release of the VERIT AS pipeline, along with the refined dataset and model checkpoints, will facilitate future research in rob ust data curation and contribute to the de velopment of more reliable and accurate multimodal language models. Limitations The limitations of our work are summarized as follo ws: (1) The critique prompts and re write prompts that we hav e designed are relati vely long. While this in- creases computational ov erhead, these comprehen- si ve prompts provide richer conte xtual information, facilitating the model’ s more accurate understand- ing and generation of critique and rewritten content. These prompts can capture more nuanced semantic and syntactic information, thereby improving the quality of critiques and rewrites. Future w ork could consider how to optimize prompt design to main- tain or enhance performance without significantly increasing computational costs. (2) VERIT AS leverages state-of-the-art LMMs (GPT -4o, Gemini-2.5-Pro, Doubao-1.5-pro) for cri- tiques and refinements. Access to such powerful models may be restricted due to licensing, API limitations, or resource constraints. This depen- dency could pose challenges for broader adoption or replication of our results in dif ferent settings where these models are not readily accessible. References Alon Albalak, Y anai Elazar , Sang Michael Xie, Shayne Longpre, Nathan Lambert, Xinyi W ang, Niklas Muennighoff, Bairu Hou, Liangming Pan, Hae won Jeong, et al. 2024. A survey on data selection for language models. arXiv pr eprint arXiv:2402.16827 . Zechen Bai, Pichao W ang, Tianjun Xiao, T ong He, Zongbo Han, Zheng Zhang, and Mike Zheng Shou. 2024. Hallucination of multimodal large language models: A survey . arXiv preprint . Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Con- ghui He, Jiaqi W ang, Feng Zhao, and Dahua Lin. 2024a. Sharegpt4v: Improving large multi-modal models with better captions. In Eur opean Confer- ence on Computer V ision , pages 370–387. Springer . Zhe Chen, Jiannan W u, W enhai W ang, W eijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Le wei Lu, et al. 2024b. Internvl: Scal- ing up vision foundation models and aligning for generic visual-linguistic tasks. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition , pages 24185–24198. Haodong Duan, Junming Y ang, Y uxuan Qiao, Xinyu Fang, Lin Chen, Y uan Liu, Xiaoyi Dong, Y uhang Zang, P an Zhang, Jiaqi W ang, et al. 2024. Vlmev alkit: An open-source toolkit for ev aluating large multi-modality models. In Pr oceedings of the 32nd A CM International Conference on Multimedia , pages 11198–11201. Y unhao Fang, Ligeng Zhu, Y ao Lu, Y an W ang, Pa vlo Molchanov , Jan Kautz, Jang Hyun Cho, Marco Pav one, Song Han, and Hongxu Y in. 2024. V ila 2 : V ila augmented vila. arXiv preprint arXiv:2407.17453 . Chaoyou Fu, Y uhan Dai, Y ongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan W ang, Chenyu Zhou, Y unhang Shen, Mengdan Zhang, et al. 2024a. V ideo-mme: The first-ev er comprehensi ve ev aluation benchmark of multi-modal llms in video analysis. arXiv pr eprint arXiv:2405.21075 . Xingyu Fu, Y ushi Hu, Bangzheng Li, Y u Feng, Haoyu W ang, Xudong Lin, Dan Roth, Noah A Smith, W ei- Chiu Ma, and Ranjay Krishna. 2024b. Blink: Multi- modal large language models can see but not percei ve. In Eur opean Confer ence on Computer V ision , pages 148–166. Springer . Shuhao Gu, Jialing Zhang, Siyuan Zhou, Ke vin Y u, Zhaohu Xing, Liangdong W ang, Zhou Cao, Jin- tao Jia, Zhuoyi Zhang, Y ixuan W ang, et al. 2024. Infinity-mm: Scaling multimodal performance with large-scale and high-quality instruction data. arXiv pr eprint arXiv:2410.18558 . Jarvis Guo, T uney Zheng, Y uelin Bai, Bo Li, Y ubo W ang, King Zhu, Y izhi Li, Graham Neubig, W enhu Chen, and Xiang Y ue. 2024. Mammoth-vl: Eliciting multimodal reasoning with instruction tuning at scale. arXiv pr eprint arXiv:2412.05237 . Xinyu Huang, Y i-Jie Huang, Y oucai Zhang, W eiwei T ian, Rui Feng, Y uejie Zhang, Y anchun Xie, Y aqian Li, and Lei Zhang. 2023. Open-set image tagging with multi-grained text supervision. arXiv e-prints , pages arXiv–2310. Justin Johnson, Bharath Hariharan, Laurens V an Der Maaten, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. 2017. Cle vr: A diagnostic dataset for compositional language and elementary visual reasoning. In Pr oceedings of the IEEE confer ence on computer vision and pattern reco gnition , pages 2901–2910. K oray Kavukcuoglu. 2025. Gemini 2.5: Our most intel- ligent ai model . Pei K e, Bosi W en, Andre w Feng, Xiao Liu, Xuanyu Lei, Jiale Cheng, Shengyuan W ang, Aohan Zeng, Y uxiao Dong, Hongning W ang, et al. 2024. Critiquellm: T owards an informativ e critique generation model for ev aluation of large language model generation. In Pr oceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pages 13034–13054. Bo Li, Y uanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Y anwei Li, Ziwei Liu, et al. 2024. Llav a- onevision: Easy visual task transfer . arXiv pr eprint arXiv:2408.03326 . Y ifan Li, Y ifan Du, Kun Zhou, Jinpeng W ang, W ayne Xin Zhao, and Ji-Rong W en. 2023. Ev al- uating object hallucination in lar ge vision-language models. arXiv pr eprint arXiv:2305.10355 . Fuxiao Liu, Ke vin Lin, Linjie Li, Jianfeng W ang, Y aser Y acoob, and Lijuan W ang. 2023. Aligning large multi-modal model with robust instruction tuning. arXiv pr eprint arXiv:2306.14565 . Hanchao Liu, W enyuan Xue, Y ifei Chen, Dapeng Chen, Xiutian Zhao, Ke W ang, Liping Hou, Rongjun Li, and W ei Peng. 2024a. A survey on hallucination in large vision-language models. arXiv pr eprint arXiv:2402.00253 . Ziyu Liu, T ao Chu, Y uhang Zang, Xilin W ei, Xiaoyi Dong, Pan Zhang, Zijian Liang, Y uanjun Xiong, Y u Qiao, Dahua Lin, et al. 2024b. Mmdu: A multi-turn multi-image dialog understanding bench- mark and instruction-tuning dataset for lvlms. arXiv pr eprint arXiv:2406.11833 . Pan Lu, Hritik Bansal, T ony Xia, Jiacheng Liu, Chun- yuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai- W ei Chang, Michel Galley , and Jianfeng Gao. 2023. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. arXiv pr eprint arXiv:2310.02255 . Run Luo, Haonan Zhang, Longze Chen, Ting-En Lin, Xiong Liu, Y uchuan W u, Min Y ang, Minzheng W ang, Pengpeng Zeng, Lianli Gao, et al. 2024. Mmevol: Empo wering multimodal large language models with ev ol-instruct. arXiv preprint . Max Marion, Ahmet Üstün, Luiza Pozzobon, Alex W ang, Marzieh Fadaee, and Sara Hooker . 2023. When less is more: In vestigating data pruning for pretraining llms at scale. arXiv preprint arXiv:2309.04564 . Anand Mishra, Shashank Shekhar , Ajeet Kumar Singh, and Anirban Chakraborty . 2019. Ocr-vqa: V isual question answering by reading text in images. In ICD AR . OpenAI. 2023. Gpt-4v . OpenAI. 2024. Hello gpt-4o . PaddleOCR. 2024. Pp-ocrv4 . Renjie Pi, Jianshu Zhang, Jipeng Zhang, Rui Pan, Zhekai Chen, and T ong Zhang. 2024. Image textual- ization: An automatic frame work for creating accu- rate and detailed image descriptions. arXiv preprint arXiv:2406.07502 . Swarnadeep Saha, Xian Li, Marjan Ghazvininejad, Ja- son W eston, and Tianlu W ang. 2025. Learning to plan & reason for e valuation with thinking-llm-as-a- judge. arXiv pr eprint arXiv:2501.18099 . Zhihong Shao, Peiyi W ang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Hao wei Zhang, Mingchuan Zhang, YK Li, Y W u, et al. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv pr eprint arXiv:2402.03300 . Ilia Shumailov , Zakhar Shumaylov , Y iren Zhao, Y arin Gal, Nicolas Papernot, and Ross Anderson. 2023. The curse of recursion: Training on gen- erated data makes models forget. arXiv pr eprint arXiv:2305.17493 . Oleksii Sidorov , Ronghang Hu, Marcus Rohrbach, and Amanpreet Singh. 2020. T extcaps: a dataset for im- age captioning with reading comprehension. In Com- puter V ision–ECCV 2020: 16th European Confer- ence, Glasgow , UK, August 23–28, 2020, Proceed- ings, P art II 16 , pages 742–758. Springer . ByteDance Seed T eam. 2025. Doubao-1.5-pro . Gemini T eam, Petko Georgie v , V ing Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett T anzer , Damien V incent, Zhufeng Pan, Shibo W ang, et al. 2024. Gemini 1.5: Unlocking multimodal under- standing across millions of tokens of conte xt. arXiv pr eprint arXiv:2403.05530 . Peng W ang, Shuai Bai, Sinan T an, Shijie W ang, Zhi- hao Fan, Jinze Bai, K eqin Chen, Xuejing Liu, Jialin W ang, W enbin Ge, et al. 2024a. Qwen2-vl: Enhanc- ing vision-language model’ s perception of the world at any resolution. arXiv preprint . Y uxia W ang, Minghan W ang, Muhammad Arslan Man- zoor , Fei Liu, Georgi Georgie v , Rocktim Das, and Preslav Nakov . 2024b. Factuality of lar ge language models: A surve y . In Pr oceedings of the 2024 Con- fer ence on Empirical Methods in Natural Language Pr ocessing , pages 19519–19529. Kaining Y ing, Fanqing Meng, Jin W ang, Zhiqian Li, Han Lin, Y ue Y ang, Hao Zhang, W enbo Zhang, Y uqi Lin, Shuo Liu, et al. 2024. Mmt-bench: A compre- hensiv e multimodal benchmark for e v aluating large vision-language models tow ards multitask agi. arXiv pr eprint arXiv:2404.16006 . W eihao Y u, Zhengyuan Y ang, Linjie Li, Jianfeng W ang, Ke vin Lin, Zicheng Liu, Xinchao W ang, and Lijuan W ang. 2023. Mm-vet: Ev aluating large multimodal models for integrated capabilities. arXiv pr eprint arXiv:2308.02490 . Y ue Y u, Zhengxing Chen, Aston Zhang, Liang T an, Chenguang Zhu, Richard Y uanzhe Pang, Y undi Qian, Xuewei W ang, Suchin Gururangan, Chao Zhang, et al. 2024. Self-generated critiques boost reward modeling for language models. arXiv pr eprint arXiv:2411.16646 . Jiarui Zhang, Jinyi Hu, Mahyar Khayatkhoei, Filip Ilie vski, and Maosong Sun. 2024a. Exploring percep- tual limitation of multimodal large language models. arXiv pr eprint arXiv:2402.07384 . Lunjun Zhang, Arian Hosseini, Hritik Bansal, Mehran Kazemi, A viral Kumar , and Rishabh Agarwal. 2024b. Generativ e verifiers: Reward modeling as next-tok en prediction. arXiv pr eprint arXiv:2408.15240 . Y anzhe Zhang, Ruiyi Zhang, Jiuxiang Gu, Y ufan Zhou, Nedim Lipka, Diyi Y ang, and T ong Sun. 2023. Llav ar: Enhanced visual instruction tuning for text-rich image understanding. arXiv pr eprint arXiv:2306.17107 . Y i-Fan Zhang, Xingyu Lu, Xiao Hu, Chaoyou Fu, Bin W en, T ianke Zhang, Changyi Liu, Kaiyu Jiang, Kaibing Chen, Kaiyu T ang, et al. 2025. R1-rew ard: Training multimodal reward model through stable reinforcement learning. arXiv pr eprint arXiv:2505.02835 . Lianmin Zheng, W ei-Lin Chiang, Y ing Sheng, Siyuan Zhuang, Zhanghao W u, Y onghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Pr ocessing Systems , 36:46595–46623. A Additional Figures B Derivation and Analysis of Multi-Expert Fusion Method B.1 Notation and Problem Setup In this appendix, we pro vide a detailed deri vation and theoretical justification for the multi-expert fusion method presented in Algorithm 1 of the main paper . For each data source (domain) d ∈ D , consider the follo wing: - Let s d ( n ) = ( s 1 ,d ( n ) , s 2 ,d ( n ) , s 3 ,d ( n )) ⊤ be the vector of raw scores assigned by the three expert critics for sample n in domain d . - Let y d ( n ) be the latent true score (e.g., a human- annotated score) for sample n in domain d , as- sumed to hav e finite v ariance σ 2 y . Our goal is to construct an estimator ˆ y d ( n ) of the true score y d ( n ) by linearly combining the experts’ scores: ˆ y d ( n ) = w ⊤ d z d ( n ) , (10) Figure 4: Score distributions from individual critics and after fusion. The fusion results in a more balanced distribution. where w d = ( w 1 ,d , w 2 ,d , w 3 ,d ) ⊤ are the weights for domain d , and z d ( n ) are the normalized scores, as defined belo w . W e aim to find weights w d that minimize the expected squared error (risk): R = E h ( ˆ y d ( n ) − y d ( n )) 2 i . (11) B.2 Domain-Wise Z-Normalization T o ensure comparability across dif ferent experts and domains, we perform z-score normalization of the raw scores within each domain: z m,d ( n ) = s m,d ( n ) − µ m,d σ m,d , (12) where µ m,d and σ m,d are the mean and standard de viation of expert m ’ s scores in domain d , respec- ti vely . By this normalization, the standardized scores z m,d ( n ) satisfy: E [ z m,d ] = 0 , V ar [ z m,d ] = 1 . (13) Any linear combination of these normalized scores will hav e expectation 0 if the weights sum to zero. Ho wev er , since we aim to produce a mean- ingful aggregate score, we instead constrain the weights to sum to one: 3 X m =1 w m,d = 1 . (14) Although this introduces bias in the estimator, we correct for it later through the percentile rescal- ing step. B.3 Signal-to-Noise Ratio (SNR) Based Raw W eights Assuming that each expert’ s score is an unbiased estimator of the true score corrupted by noise, we model: s m,d ( n ) = y d ( n ) + η m,d ( n ) , (15) where η m,d ( n ) ∼ N (0 , σ 2 m,d ) represents the noise in expert m ’ s score within domain d . The expected risk (mean squared error) of our estimator is then: R = E h ( ˆ y d ( n ) − y d ( n )) 2 i = 3 X m =1 w 2 m,d σ 2 m,d , (16) since the normalized scores z m,d ( n ) are centered with unit v ariance. T o minimize R , we set the weights proportional to the in verse of the v ariances: w m,d ∝ 1 σ 2 m,d . (17) In practice, we estimate σ 2 m,d using the variance of the residuals (noise) within domain d : σ 2 m,d ≈ V ar ( s m,d ( n ) − ¯ s d ( n )) , (18) Figure 5: Critic weights before (ra w) and after fusion across se ven data sources. The fused weights adaptiv ely adjust each critic’ s influence per domain. where ¯ s d ( n ) is the mean score for sample n across all experts in domain d . Thus, the raw weights are computed based on the signal-to-noise ratio (SNR): raw_ w m,d = σ m,d noise m,d + ϵ , (19) where noise m,d is the standard deviation of the residuals r m,d ( n ) = s m,d ( n ) − ¯ s d ( n ) , and ϵ is a small constant to pre vent di vision by zero. B.4 James–Stein Shrinkage Estimator The raw weights computed above may still hav e high v ariance, especially in domains with a small number of samples ( N d small). T o address this, we apply James–Stein shrinkage, which shrinks the domain-specific weights toward the global mean weights, balancing bias and v ariance. W e compute the global mean weights: ¯ w = 1 |D | X d ∈D w d , (20) and then apply shrinkage: ˆ w d = α d w d + (1 − α d ) ¯ w , (21) where the shrinkage factor is: α d = N d N d + λ , (22) with λ being a hyperparameter set to λ = 100 in our implementation. This results in the adjusted weights ˆ w d , which are a con ve x combination of the domain-specific weights w d and the global mean weights ¯ w . The choice of α d ensures that in domains with large N d , we trust the domain-specific weights more, while in domains with small N d , we rely more on the global weights. Risk Reduction Proof Substituting the shrink- age weights into the risk R , we find that the ex- pected risk under the shrinkage estimator is less than or equal to that under the raw weights: ∆ R d = R ( ˆ w d ) − R ( w d ) = − (1 − α d ) 2 |D | 3 X m =1 ( w m,d − ¯ w m ) 2 ≤ 0 , (23) since (1 − α d ) 2 ≥ 0 and the squared dif ferences are non-negati ve. Equality holds only when w d = ¯ w . Thus, the James–Stein shrinkage estimator does not increase the risk and typically reduces it. B.5 Percentile Re-Pr ojection (Rescaling to T arget Range) After fusing the normalized scores using the ad- justed weights, we obtain the estimated scores: ˆ z ( n ) = 3 X m =1 ˆ w m,d z m,d ( n ) . (24) Ho wev er , the distribution of ˆ z ( n ) may not be standard normal due to the weighting and shrink- age. T o map the fused scores back to the original scoring range [0, 5], we apply a percentile-based linear rescaling. W e compute the lower and upper quantiles (e.g., 5% and 95%) of the fused scores ˆ z ( n ) across all samples, denoted as q low and q high , respecti vely . The final estimated scores are then: ˆ S ( n ) = 5 × clip ˆ z ( n ) − q low q high − q low , 0 , 1 , (25) where clip ( x, 0 , 1) constrains x to the interval [0, 1]. This rescaling ensures that the fused scores ˆ S ( n ) lie within the desired range [0, 5], maintains the ordering (monotonicity), and reduces the impact of outliers by capping the extreme v alues. C A utomated Error Injection in CLEVR Dataset to Create Answer Quality Tiers T o ev aluate our e valuator’ s performance across v arying answer qualities in an out-of-domain (OOD) setting, we modified the CLEVR dataset by introducing errors to create three tiers of answer quality: • High-quality answers (Tier H): Original cor - rect answers were kept unchanged. • Medium-quality answers (Tier M): Minor errors were introduced to make answers par- tially correct or slightly ambiguous. Examples include: – Adjusting numerical answers by ± 1 or ± 2 (e.g., changing "4." to "5."). – Replacing colors with similar ones (e.g., changing "Green." to "Blue." or "Cyan."). – Switching size attributes (e.g., changing "Large." to "Small."). – Changing definite answers like "Y es." to uncertain responses like "Maybe." or "Cannot tell.". – Re versing material attributes (e.g., changing "Rubber ." to "Metal."). – Modifying shapes to similar ones (e.g., changing "Cube." to "Sphere."). • Low-quality answers (T ier L): Clear errors were introduced by replacing correct answers with incorrect v alues from different categories. Examples include: – Swapping numerical answers with colors or shapes (e.g., answering "Red." instead of "3."). – Changing "Y es." to "No." or providing contradictory statements. – Providing unrelated attributes (e.g., an- swering "Metal." when the question asks for a color). – Introducing nonexistent attributes (e.g., answering "Triangle." or "Plastic.", which are not present in CLEVR). – Adding irrele vant explanations to incor - rect answers. This automated error injection approach allo wed us to generate a test set with div erse answer qual- ities, facilitating a comprehensiv e ev aluation of our model’ s ability to handle varying le vels of cor - rectness in an OOD context while using LaT eX- compatible formatting for documentation.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment