콘코드 빠르고 정확한 CPU 성능 모델링
콘코드는 마이크로아키텍처 설계 공간을 빠르게 탐색할 수 있도록, 각 하드웨어 구성 요소별 분석 모델과 얕은 신경망을 결합한 새로운 성능 예측 방법을 제안한다. 5 order‑of‑magnitude 속도 향상과 평균 2 % 수준의 CPI 예측 오차를 달성한다.
저자: Arash Nasr-Esfahany, Mohammad Alizadeh, Victor Lee
이 논문은 마이크로아키텍처 설계 단계에서 필수적인 성능 예측을, 기존 사이클‑레벨 시뮬레이터와 최신 머신러닝 기반 모델의 장단점을 보완하는 새로운 방법론 ‘콘코드(Concorde)’를 통해 해결한다. 먼저, 저자들은 사이클‑레벨 시뮬레이터(gem5)가 제공하는 높은 정확도에도 불구하고, 수십억 명령을 포함한 대규모 워크로드에 대해 수시간에서 수일이 소요되는 비효율성을 강조한다. 반면, 최근 LSTM·Transformer 기반 시퀀스 모델은 명령 길이에 비례하는 O(L) 복잡도로 인해 10배 정도의 속도 향상만을 제공한다는 한계가 있다. 이러한 배경에서 콘코드는 두 단계로 구성된 ‘컴포지셔널 분석‑ML 융합’ 구조를 제안한다.
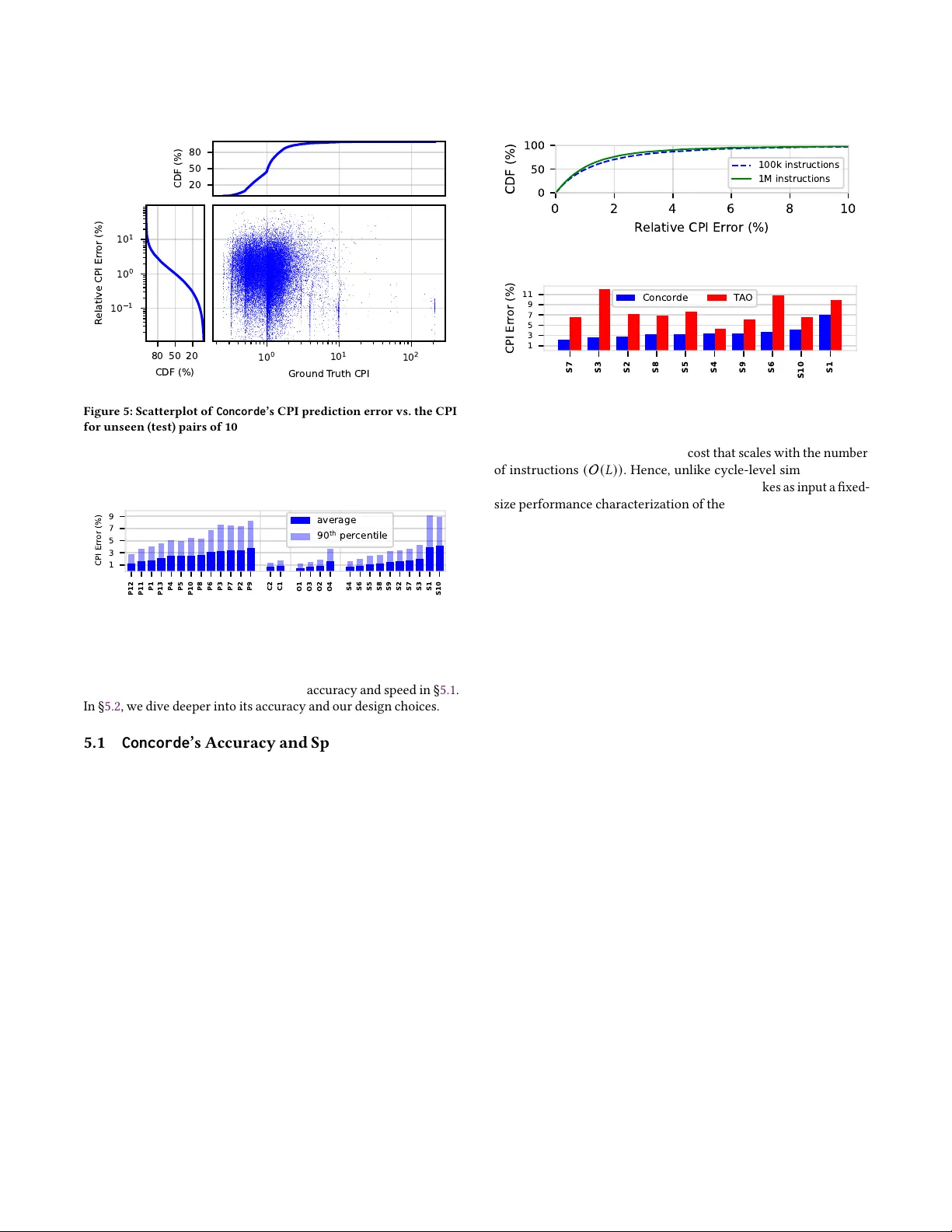
첫 번째 단계인 분석 단계에서는 프로그램을 200~400명령 단위의 윈도우로 분할하고, 각 윈도우에 대해 개별 마이크로아키텍처 자원(프론트엔드 버퍼, ROB, 로드 큐, 캐시, 디코드 폭 등)의 이론적 최대 처리량을 간단한 수식 모델로 계산한다. 이때 다른 자원은 무한 용량이라고 가정해, 각 자원의 병목만을 독립적으로 평가한다. 이렇게 얻어진 처리량 시계열은 CDF 형태의 퍼포먼스 분포로 변환되며, 고정된 퍼센타일 값(예: 10th, 25th, 50th, 75th, 90th)으로 요약된다. 이러한 피처는 프로그램 길이에 무관하게 일정한 차원을 유지한다.
두 번째 단계는 얕은 다층 퍼셉트론(MLP)이다. 분석 단계에서 추출된 분포 피처와 마이크로아키텍처 파라미터 집합을 입력으로 받아, 실제 사이클‑레벨 시뮬레이터가 제공하는 CPI와의 비선형 관계를 학습한다. 중요한 점은 분석 단계에서 모든 파라미터 조합에 대해 피처를 미리 계산해 두면, 추론 시에는 해당 파라미터에 대응하는 피처만 조회하고 MLP를 한 번 실행하면 된다는 것이다. 따라서 추론 복잡도는 O(1)이며, 1 M 명령 구간에 대해 1 ms 이하, 전체 1 B 명령 프로그램에 대해서도 수초 내에 예측이 가능하다.
실험에서는 1백만 개의 무작위 프로그램 구간과 20개의 마이크로아키텍처 파라미터(프론트엔드, 백엔드, 메모리)를 조합한 2.2 × 10²³ 가능한 설계 공간을 대상으로 학습 및 평가를 수행했다. 콘코드는 평균 CPI 예측 오차가 2 % 수준이며, 10 %를 초과하는 경우는 2.5 %에 불과했다. 또한, ARM N1 기반 실제 코어에 대해 기존 최첨단 시퀀스 모델(TAO)보다 2배 가량 정확도가 높았다(3.5 % vs 7.8 %). 속도 측면에서는 분석 단계의 일회성 비용을 제외하고, 5~7 order‑of‑magnitude 빠른 추론을 달성했다.
추가적으로, 저자들은 Shapley 값 개념을 적용해 각 마이크로아키텍처 구성 요소가 전체 CPI에 기여하는 비율을 정량화하는 ‘미세‑입력 성능 기여 분석’을 수행했다. 이 분석은 150 M CPI 평가를 1시간 내에 완료했으며, 기존 파라미터 절삭 방식보다 공정하고 상세한 인사이트를 제공한다.
결론적으로, 콘코드는 간단한 분석 모델과 얕은 ML 모델의 조합을 통해, 설계 공간 탐색, 민감도 분석, 그리고 성능 기여 분석 등 다양한 실무 시나리오에서 기존 방법이 감당하기 어려운 규모와 정확도를 동시에 만족한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기