메모리 제어 기반 언어 모델 통합으로 향상된 시퀀스투시퀀스 음성 인식
** 본 논문은 사전 학습된 언어 모델(RNNLM)을 시퀀스‑투‑시퀀스(Seq2Seq) 디코더 LSTM의 메모리 셀과 은닉 상태에 직접 결합하는 새로운 융합 기법을 제안한다. 제안된 셀‑컨트롤 융합 1·2·3 중 특히 셀‑컨트롤 융합 3(affine) 방식이 Librispeech 960시간 데이터와 저자원 Swahili 전이 학습에서 기존 shallow, deep, cold fusion보다 월등히 낮은 WER와 CER를 달성하였다. *…
저자: Jaejin Cho, Shinji Watanabe, Takaaki Hori
**
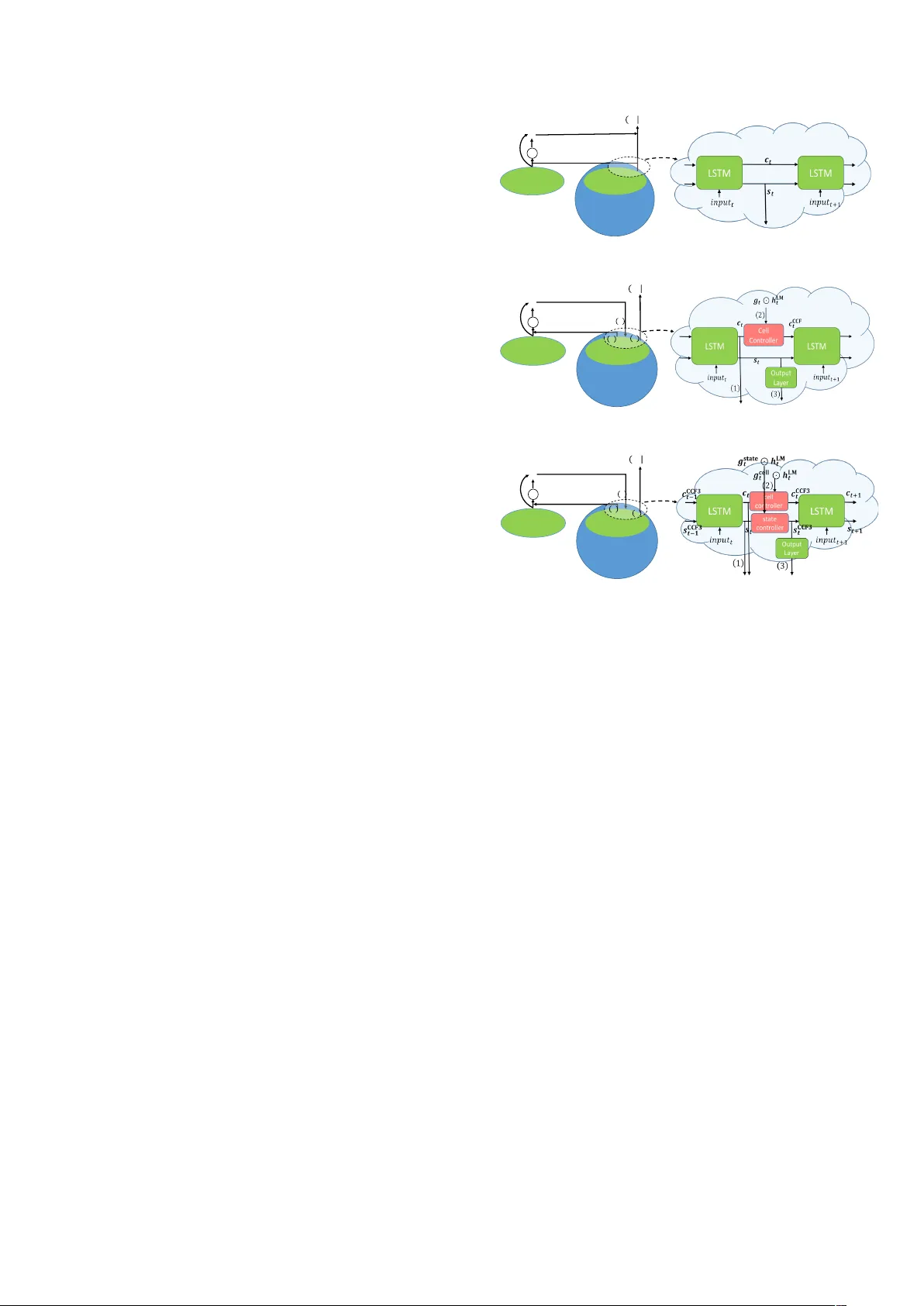
본 논문은 사전 학습된 언어 모델(RNNLM)을 시퀀스‑투‑시퀀스(Seq2Seq) 음성 인식 시스템에 보다 효과적으로 통합하기 위한 새로운 융합 기법을 제안한다. 서론에서는 Seq2Seq 기반 ASR이 기존 HMM‑DNN 시스템에 비해 학습이 복잡하고, 특히 언어 모델(LM)의 활용이 제한적이라는 점을 지적한다. 기존 연구로는 shallow fusion(디코딩 시 점수 가중합), deep fusion(은닉 상태 연결 후 파라미터 학습), cold fusion(학습 단계에서 LM을 고정하고 게이트를 통해 은닉 상태에 결합) 등이 있었지만, 이들 모두 LM 정보를 LSTM 내부 메모리 셀에 직접 반영하지 못한다는 한계가 있다.
이에 저자들은 LM의 로짓(l_LM) 혹은 은닉 표현을 변환한 후, LSTM 디코더의 메모리 셀(c_t)과 은닉 상태(s_t) 모두에 게이트(g_cell, g_state)를 적용해 직접 업데이트하는 셀‑컨트롤 융합 방식을 설계한다. 구체적인 수식은 다음과 같다.
- **셀‑컨트롤 융합 1**: h_LM = tanh(W₁ l_LM + b₁), g = σ(W₂
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기