Language model integration based on memory control for sequence to sequence speech recognition
In this paper, we explore several new schemes to train a seq2seq model to integrate a pre-trained LM. Our proposed fusion methods focus on the memory cell state and the hidden state in the seq2seq decoder long short-term memory (LSTM), and the memory…
Authors: Jaejin Cho, Shinji Watanabe, Takaaki Hori
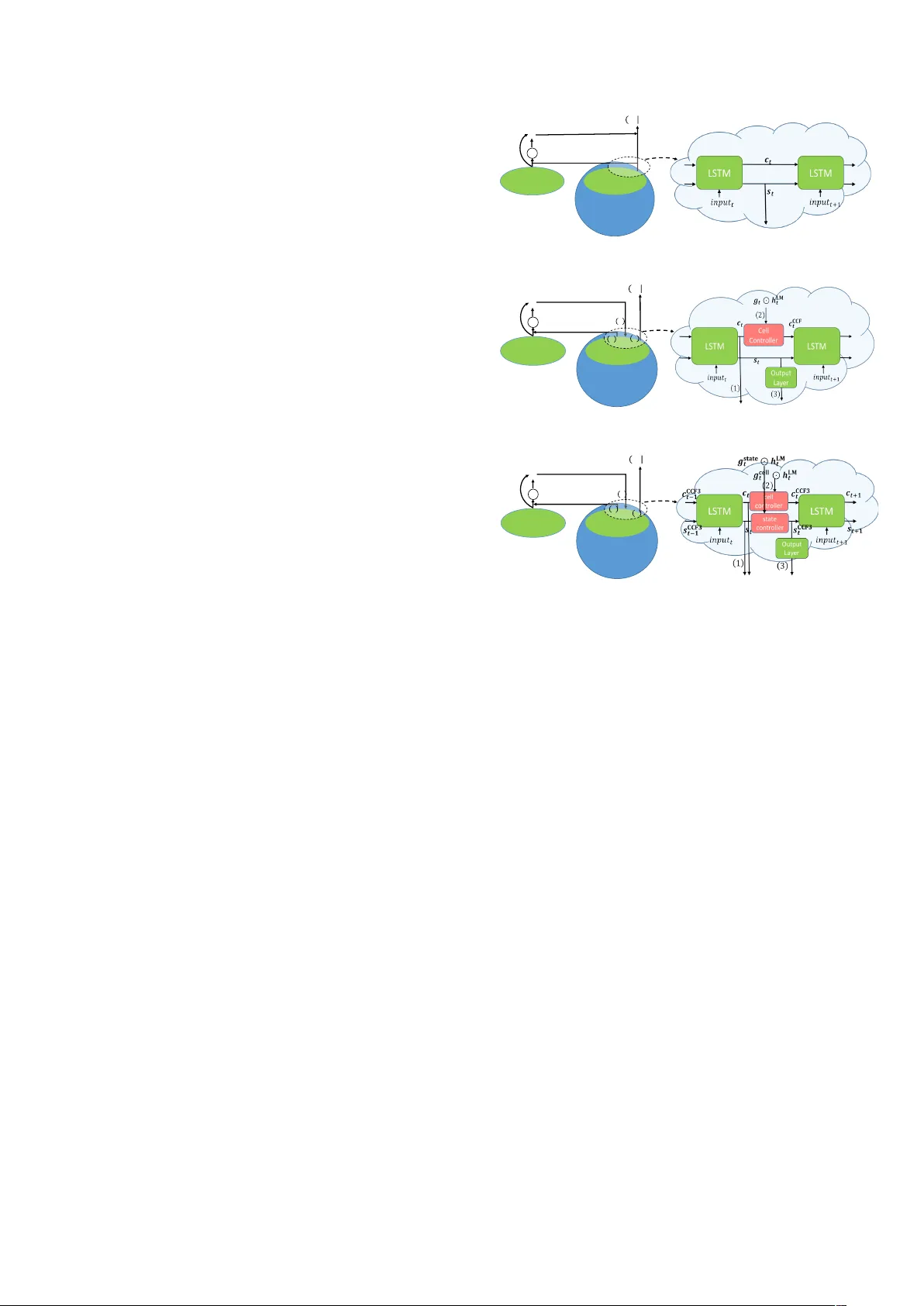
Important Notice: Please r ead this note bef or e r eading/citing this paper . LANGU A GE MODEL INTEGRA TION B ASED ON MEMOR Y CONTR OL FOR SEQUENCE TO SEQUENCE SPEECH RECOGNITION J aejin Cho 1 ∗ , Shinji W atanabe 1 ∗ , T akaaki Hori 2 ∗ , Murali Karthic k Baskar 3 ∗ , Hir ofumi Inaguma 4 ∗ , J esus V illalba 1 ∗ , Najim Dehak 1 ∗ 1 Johns Hopkins Uni versity , 2 Mitsubishi Electric Research Laboratories (MERL), 3 Brno Uni versity of T echnology , 4 K yoto Uni v ersity youjojo8478@gmail.com ABSTRA CT In this paper , we explore sev eral ne w schemes to train a seq2seq model to integrate a pre-trained LM. Our proposed fusion methods focus on the memory cell state and the hidden state in the seq2seq decoder long short-term memory (LSTM), and the memory cell state is updated by the LM unlike the prior studies. This means the mem- ory retained by the main seq2seq would be adjusted by the external LM. These fusion methods hav e several variants depending on the architecture of this memory cell update and the use of memory cell and hidden states which directly affects the final label inference. W e performed the experiments to sho w the ef fectiv eness of the proposed methods in a mono-lingual ASR setup on the Librispeech corpus and in a transfer learning setup from a multilingual ASR (MLASR) base model to a low-resourced language. In Librispeech, our best model improv ed WER by 3.7%, 2.4% for test clean, test other relatively to the shallow fusion baseline, with multi-lev el decoding. In transfer learning from an MLASR base model to the IARP A Babel Swahili model, the best scheme improved the transferred model on ev al set by 9.9%, 9.8% in CER, WER relatively to the 2-stage transfer base- line. Index T erms : Automatic speech recognition (ASR), sequence to sequence, language model, shallow fusion, deep fusion, cold fusion 1. INTRODUCTION As deep learning prospers in most research fields, systems based on it keep improving, and become the state-of-the-art in most of the sce- narios. The sequence to sequence (seq2seq) model is one of the kind that heavily depends on deep learning techniques, and it is used in many sequence mapping problems such as automatic speech recog- nition (ASR) [ 1 , 2 , 3 , 4 ] and machine translation [ 5 , 6 , 7 ]. In [ 4 ], a seq2seq model with attention mechanism is introduced in ASR. Though the performance lagged behind highly-optimized conv en- tional systems, e.g. CLDNN HMM system [ 8 ], it enabled to map a sequence of feature vectors to a sequence of characters, with a sin- gle neural network, in an end-to-end manner . In [ 9 ], the authors apply a multi-task learning scheme to train an attentional seq2seq model with connectionist temporal classification (CTC) objecti ve function [ 1 , 10 ] as auxiliary loss. Adding the CTC loss to train the model reduces the burden of the attention model to learn monotonic attention. * The affiliations of the authors may differ from their current affilia- tions. In the seq2seq ASR setup, the language model (LM) takes an im- portant role as it is already shown in hybrid ASR systems [ 11 , 12 ]. Howe v er , compared to the con ventional ASR, there hav e been only a few studies on ways to integrate an LM into seq2seq ASR [ 13 , 14 , 15 ]. In this direction, the authors in [ 5 ] introduce two methods inte- grating an LM into a decoder of the end-to-end neural machine trans- lation (NMT) system. First method was shallow fusion where the model decodes based on a simple weighted sum of NMT model and recurrent neural network LM [ 16 ] (RNNLM) scores. The next one was called deep fusion where the y combine a mono-lingual RNNLM with a NMT model by learning parameters that connect hidden states of a separately trained NMT model and RNNLM. While the parame- ters connecting the hidden states are trained, parameters in NMT and RNNLM are frozen. Recently in ASR research, a scheme called cold fusion was introduced, which trains a seq2seq model from scratch in assistance with a pre-trained RNNLM [ 17 ]. In contrast to the previ- ous methods, the parameters of the seq2seq model are not frozen dur- ing training although pre-trained RNNLM parameters are still kept frozen. The results showed the model trained this way outperforms deep fusion in decoding as well as reducing the amount of data in do- main adaptation. Later, more experiments were done comparing all three methods [ 18 ]. In the paper, they observ e that cold fusion works best among all three methods in the second pass re-scoring with a large and production-scale LM. The previous research has shown the potential of training a seq2seq model utilizing a pre-trained LM. Howe v er , it seems only ef fecti ve to limited scenarios such as domain adaptation and second-pass re-scoring. Thus, studies on better ways of integrating both models need to be e xplored. In this paper, we explored several new fusion schemes to train a seq2seq model jointly with a pre-trained LM. Among them, we found one method that works consistently better than other fusion methods over more general scenarios. The proposed methods focus on updating the memory cell state as well as the hidden state of the seq2seq decoder long short-term memory (LSTM) [ 19 ], giv en the LM logit or hidden state. This means that the memory retained by the main seq2seq model will be adjusted by the external LM for bet- ter prediction. The fusion methods have several variants according to the architecture of this memory cell update and the use of memory cell and hidden states, which directly af fects the final label inference. Note that we used LSTM networks for RNNs throughout whole ex- planations and experiments. The proposed methods, howe ver , can be applied to different variant RNNs such as gated recurrent unit (GR U) [ 20 ] only with minimal modification. The organization of this paper is as follows. First, we describe previous fusion methods as a background in Section 2 . Then, in Sec- tion 3 , we explain our proposed methods in detail. Experiments with previous and proposed methods are presented in Section 4 . Lastly , we conclude the paper in Section 5 . 2. BA CKGROUND: SHALLO W FUSION, DEEP FUSION, AND COLD FUSION IN ASR 2.1. Shallow fusion In this paper, we denotes as shallow fusion a decoding method based on the following con ve x score combination of a seq2seq model and LM during beam search, ˆ y = argmax y (log p ( y | x ) + γ log p ( y )) (1) where x is an input acoustic frame sequence while ˆ y is the predicted label sequence selected among all possible y . The predicted label sequence can be a sequence of characters, sub-words, or words, and this paper deals with character-le vel sequences. log p ( y | x ) is calcu- lated from the seq2seq model and log p ( y ) is calculated from the RNNLM. Both models are separately trained but their scores are combined in a decoding phase. γ is a scaling factor between 0 and 1 that needs to be tuned manually . 2.2. Deep fusion In deep fusion , the seq2seq model and RNNLM are combined with learnable parameters. T wo models are first trained separately as in shallow fusion , and then both are frozen while the connecting linear transformation parameters, i.e. v , b , W , and b below , are trained. g t = σ ( v T s LM t + b ) (2a) s DF t = [ s t ; g t s LM t ] (2b) ˆ p ( y t | y
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment