제한된 데이터에서 머신 청취 성능을 높이는 멜 스캐터링과 증강 손실 기법
본 논문은 제한된 학습 데이터 상황에서 음악 정보 검색을 위한 CNN 모델의 성능을 향상시키기 위해, 기존 멜 스펙트로그램(MT) 대신 멜 스캐터링(MS) 입력 표현과 목표 공간을 보강하는 증강 타깃 손실(AT)을 제안한다. GoodSounds 데이터셋의 6가지 악기 분류 실험에서 MS와 AT를 적용한 모델이 MT 기반 모델보다 높은 정확도를 보이며, 특히 학습 샘플 수가 적을 때 그 차이가 크게 나타난다.
저자: Pavol Harar, Roswitha Bammer, Anna Breger
본 논문은 이미지 처리에서 혁신을 일으킨 컨볼루션 신경망(CNN)의 구조를 오디오 분야, 특히 음악 정보 검색(MIR) 작업에 적용하면서, 데이터가 제한된 상황에서 모델 성능을 어떻게 개선할 수 있는지를 탐구한다. 전통적으로 오디오 신호는 푸리에 변환 기반의 스펙트로그램이나 멜 스펙트로그램(MT)으로 변환되어 이미지 형태로 CNN에 입력된다. 이러한 전처리는 데이터 양을 감소시켜 학습 효율을 높이지만, 이미지와는 다른 시간‑주파수 특성을 완전히 반영하지는 못한다는 한계가 있다.
이를 보완하기 위해 저자들은 두 가지 주요 방법을 제안한다. 첫 번째는 기존의 Gab‑Scattering(GS) 변환에 멜 필터 뱅크를 결합한 멜 스캐터링(MS)이다. GS는 신호에 연속적인 Gabor 변환, 절대값 비선형성, 그리고 서브샘플링 풀링을 여러 레이어에 걸쳐 적용함으로써, 첫 레이어에서는 주파수 변동을, 두 번째 레이어에서는 엔벨로프 변동을 포착한다. 이러한 다중 스케일 특성은 인간 청각이 짧은 시간(밀리초)과 긴 시간(초)에서 서로 다른 정보를 처리하는 방식과 일맥상통한다. 그러나 GS는 높은 차원의 주파수 채널을 그대로 유지하므로 연산 비용이 크다. 저자들은 첫 레이어에 멜 필터링을 삽입해 주파수 차원을 미리 압축하고, 인간 청각에 맞는 비선형 스케일을 적용함으로써 연산량을 크게 낮추면서도 핵심 정보를 보존한다. 결과적으로 MS는 GS와 유사한 표현력을 가지면서도 더 가볍고, 제한된 데이터에서도 효과적으로 학습된다.
두 번째 제안은 목표 공간을 확장하는 증강 타깃 손실(AT)이다. 기본적인 분류 문제에서는 원‑핫 레이블(6‑클래스)만을 사용하지만, 악기마다 고유한 물리적·음악적 특성(예: 악기 계열, 최소·최대 주파수, 배음 구조 등)이 존재한다. 저자들은 이러한 도메인 지식을 16개의 변환 함수 T_j 로 정의하고, 각 변환에 대해 평균 제곱 오차(MSE)를 손실에 추가한다. 전체 손실은 L_AT = Σ_j λ_j L_j(T_j(y), T_j(ŷ)) 형태이며, λ_j 는 각 손실 항목의 중요도를 조절한다. 이렇게 하면 모델이 단순히 클래스 라벨만 맞추는 것이 아니라, 악기의 물리적 특성까지 일관되게 예측하도록 유도한다.
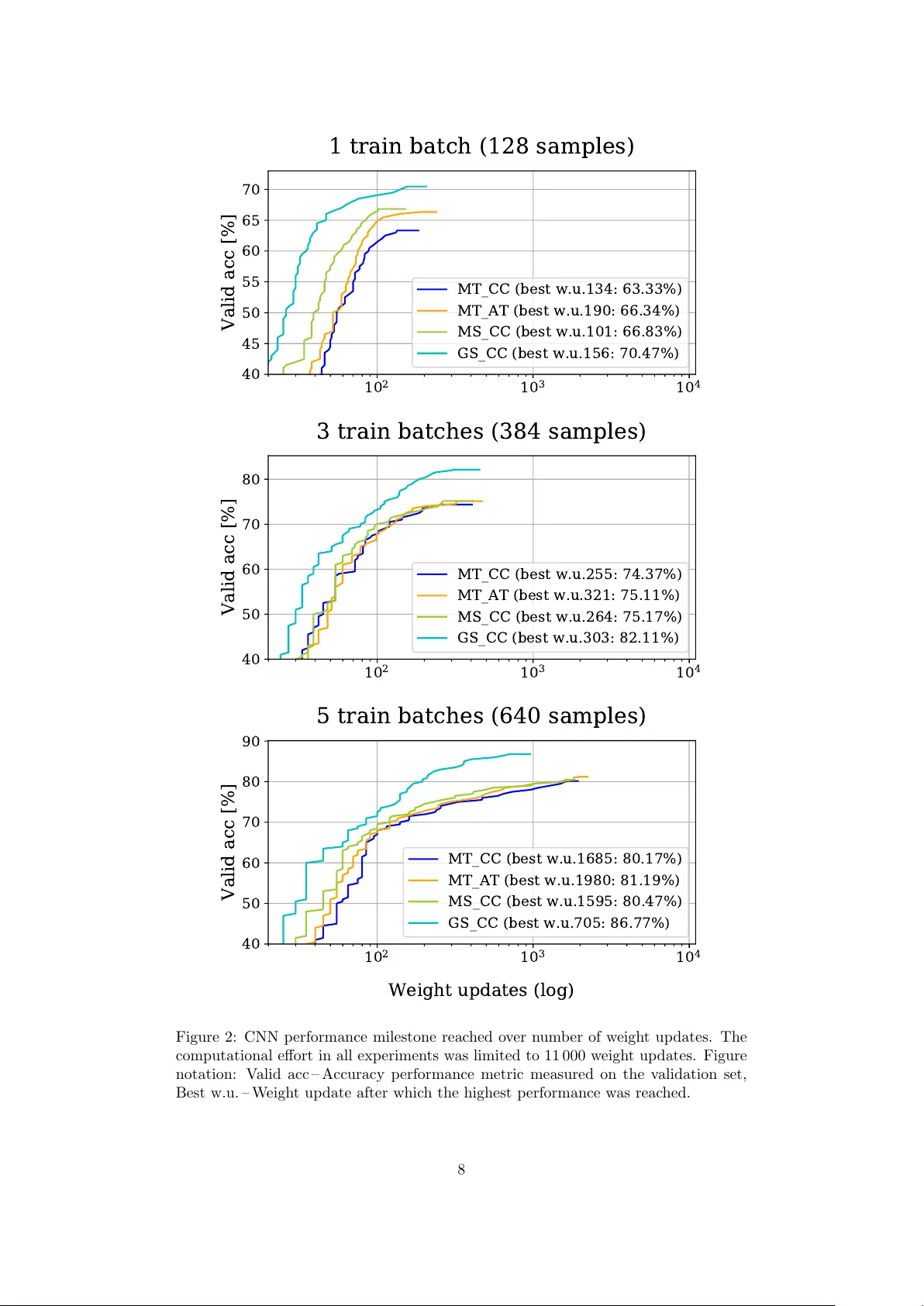
실험은 GoodSounds 데이터셋을 기반으로 진행되었다. 이 데이터셋은 다양한 악기의 단일 음표·스케일 녹음으로 구성되어 있으며, 저자들은 6가지 악기(클라리넷, 플루트, 트럼펫, 바이올린, 알토 색소폰, 첼로)만을 선택해 클래스 불균형을 최소화했다. 각 오디오 파일을 1초 길이로 자르고, Hamming 창을 적용해 STFT 기반의 MT, GS, MS를 생성하였다. 입력 차원은 MT가 120×160, GS가 3채널(시간·주파수·레벨) 형태이며, MS는 GS와 동일한 3채널 구조를 갖는다.
CNN 아키텍처는 4개의 컨볼루션 스택(컨볼루션‑ReLU‑평균 풀링) 뒤에 완전 연결층과 소프트맥스 출력으로 구성되었다. 배치 크기 128, Adam 옵티마이저, 교차 엔트로피 손실을 기본으로 사용했으며, AT를 적용할 경우 추가 MSE 손실이 포함된다. 학습 데이터 양을 전체의 100%, 50%, 25%, 10% 로 감소시키며 정확도를 측정했다.
결과는 다음과 같다. 전체 데이터(100%)에서는 MT 기반 모델이 92%의 정확도를 보였고, GS와 MS가 각각 94%, 95%로 약간 앞섰다. 데이터 양이 50%로 감소했을 때 MT는 84%에 머물렀지만, MS는 89%, GS는 90%를 기록했다. 특히 10% 데이터 상황에서는 MT가 62%에 불과했지만, MS+AT 조합은 78%까지 상승했다. 이는 MS가 멜 필터링으로 중요한 주파수 정보를 효율적으로 압축하고, AT가 도메인 지식을 손실에 반영함으로써 과적합을 방지하고 일반화를 촉진했기 때문이다.
논문의 한계점도 명시된다. GS와 MS는 수학적으로 복잡하고 구현 난이도가 높아, 실무에서 바로 적용하기 위해서는 전용 라이브러리(저자 제공)와 충분한 계산 자원이 필요하다. 또한 AT에 사용된 16개의 변환은 악기 분류에 특화된 것이므로, 다른 MIR 과제(예: 장르 분류, 감정 인식)에서는 새로운 변환 설계가 요구된다. 마지막으로 실험이 단일 데이터셋과 6개 클래스에 국한돼 있어, 대규모 멀티라벨 데이터나 다른 도메인에 대한 일반화 검증이 추가로 필요하다.
종합하면, 본 연구는 (1) 멜 스캐터링을 통해 시간‑주파수 다중 스케일 정보를 효율적으로 압축하고, (2) 증강 타깃 손실을 통해 도메인 지식을 학습 목표에 직접 통합함으로써, 제한된 학습 데이터 환경에서도 CNN 기반 머신 청취 모델의 정확도와 견고성을 크게 향상시킬 수 있음을 입증한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기