Improving Machine Hearing on Limited Data Sets
Convolutional neural network (CNN) architectures have originated and revolutionized machine learning for images. In order to take advantage of CNNs in predictive modeling with audio data, standard FFT-based signal processing methods are often applied…
Authors: Pavol Harar, Roswitha Bammer, Anna Breger
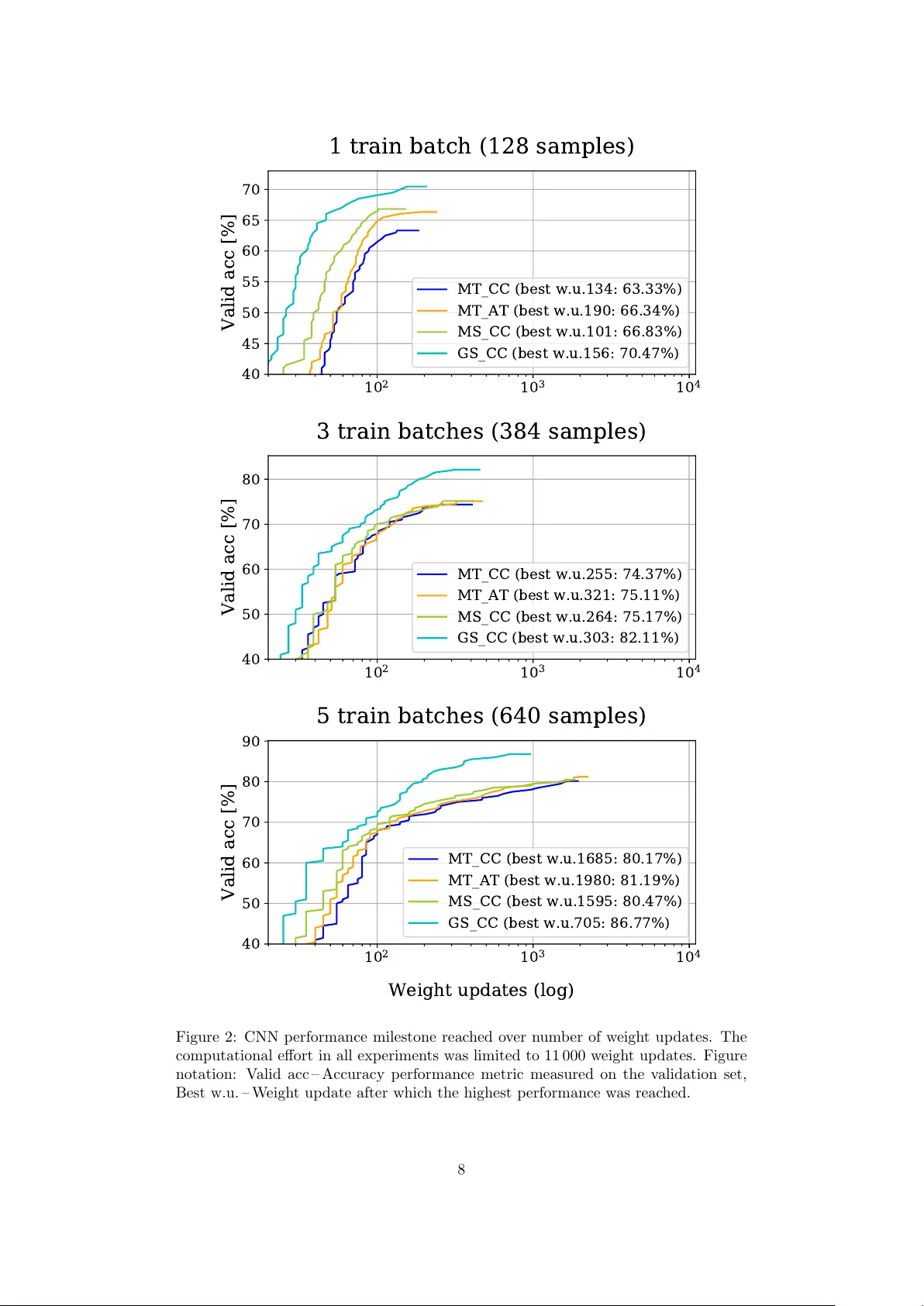
Impro ving Mac hine Hearing on Limited Data Sets P av ol Harar 1,2 , Roswitha Bammer 1 , Anna Breger 1 , Monik a D¨ orfler 1 , and Zdenek Smek al 2 1 F acult y of Mathematics, NuHA G, Univ ersity of Vienna, Vienna, Austria, pav ol.harar@univie.ac.at 2 Department of T elecommunications, Brno Universit y of T ec hnology , Brno, Czech Republic Abstract Con volutional neural netw ork (CNN) architectures hav e originated and rev- olutionized mac hine learning for images. In order to tak e adv antage of CNNs in predictive mo deling with audio data, standard FFT-based signal pro cessing metho ds are often applied to conv ert the raw audio w av eforms in to an image-like represen tations (e.g. sp ectrograms). Even though con ven tional images and sp ec- trograms differ in their feature prop erties, this kind of pre-pro cessing reduces the amoun t of training data necessary for successful training. In this contribution w e in vestigate how input and target representations interpla y with the amount of a v ailable training data in a music information retriev al setting. W e compare the standard mel-sp ectrogram inputs with a newly prop osed representation, called Mel scattering. F urthermore, w e in vestigate the impact of additional target data represen tations by using an augmented target loss function which incorporates un used av ailable information. W e observe that all prop osed metho ds outp er- form the standard mel-transform representation when using a limited data set and discuss their strengths and limitations. The source co de for repro ducibilit y of our exp erimen ts as well as intermediate results and mo del chec kp oints are a v ailable in an online rep ository . 1 In tro duction Con v olutional neural netw orks (CNNs) [11], a class of deep neural netw orks (DNNs) arc hitectures, originated in image pro cessing and hav e rev olutionized computer vision. The idea of CNNs is the in tro duction of lo calit y and weigh t-sharing in the first lay ers of a DNN, i.e. using con v olutional la y ers. This leads to the extraction of lo cal patterns, which are searched for o v er the entire image using the same filter kernels. By in termediate p o oling op erators, the extension of the local search increases across the lay ers and additionally introduces stabilit y to local deformations, [13]. Using the principles of CNNs in computer vision to solv e problems in machine hearing, including music information retriev al (MIR), has equally led to surprising successes in v arious applications. Ho w ev er, the data pro cessing pip eline needs to b e altered: the actual signal of in terest, the raw audio signal, is not directly used as input to the netw ork. Usually , it is first pre-pro cessed in to an image, allo wing for ∗ This work was supp orted b y the Uni:do cs F ellowship Programme for Doctoral Candidates in Vienna, by the Vienna Science and T echnology F und (WWTF) pro jects SALSA (MA14-018) and CHARMED (VRG12-009), by the International Mobility of Researchers (CZ.02.2.69/0.0/0.0/16 027/0008371), and by the pro ject LO1401. Infrastructure of the SIX Center was used for com- putation. 1 a time-frequency interpretation. Typical represen tations include the sp ectrogram or mo difications thereof. This step leads to a reduction of data needed for training [16]. In this pap er w e improv e the p erformance of CNNs, which are trained with the standard mel-sp ectrogram (MT) 1 input representation and limited amount of training data. T o do so, we prop ose an alternativ e input representation called Mel sc atter- ing (MS), which uses the main concept of Gab or sc attering (GS), introduced in [2], in com bination with a mel-filter bank. Moreov er, we improv e the learning results by transforming the target space within an augmente d tar get loss function (A T), intro- duced in [3]. The pap er is organized as follows: In Section 2 we introduce the learning setup and the data used in the n umerical exp erimen ts. In Section 3 we presen t the MT, and pro ceed to the definitions of GS and MS. A T is explained in Section 4. In Section 5 w e compare the results of the prop osed representations by ev aluating the classification results of an instrumen tal sounds data set, serving as a toy data set for exp erimen ts with different amount of training data. 2 Learning from Data Let D ⊂ X be a data set in an input space X , together with some information ab out the data, often called ”annotation”, which is giv en in the target space and denoted b y T ⊂ Y . Learning the relationship b et ween D and their annotations in Y can then b e understo od as lo oking for a function ψ : X 7→ Y , which describ es with sufficien t accuracy the desired mapping. The accuracy is usually measured b y a loss function, which is optimized in each iteration step of the training pro cess to up date the weigh ts. Once the learning pro cess is finished, e.g. via a stopping criterion, this results in a parameter v ector θ determining a particular mo del within the previous determined architecture. F urther, given a h yp othesis space parametrized by θ , and a set of annotated data Z m = D × T = { ( x 1 , y 1 ) , . . . , ( x m , y m ) } , w e learn a mo del ψ θ . Let the estimated targets b e denoted by ˆ y i = ψ θ ( x i ) and define the empirical loss function E Z m as E Z m ( ψ θ ) = 1 m m X i =1 L ( y i , ˆ y i ) . Common, imp ortan t examples of loss functions include the quadratic loss L ( y i , ˆ y i ) = ( ˆ y i − y i ) 2 , and the categorical cross-entrop y loss (CE). The latter is the concatenation of the softmax function on the output vector ˆ y = ( ψ θ ( x 1 ) , . . . , ψ θ ( x m )) and the cross- en trop y loss; in other words, in the case of categorical cross-entrop y , we ha v e L ( y i , ˆ y i ) = − y i log e ˆ y i P m j =1 e ˆ y j . 2.1 Data Set used for Exp erimen ts F or the classification exp erimen ts presen ted in Section 5, the Go odSounds data set [17] is used. It contains monophonic recordings of single notes or scales pla yed b y different instrumen ts. F rom eac h file, we hav e remov ed the silence with SoX v14.4.2 library 2 . The output rate was set to 44 . 1 kHz with 16 bit precision. W e ha ve split eac h file into segmen ts of the same duration (1 s = 44 100 samples) and applied a T ukey window in order to smo oth the onset and offset of the segment, thus prev en ting the undesired artifacts after applying the short-time F ourier transform (STFT). Since the classes w ere not equally represen ted in the data set, w e needed to introduce an equalization 1 W e abbreviate with MT, i.e. ”mel-transform”, in order not to collide with further abbreviations. 2 https://launc hpad.net/ubuntu/+source/so x/14.4.1-5 2 strategy . T o av oid extensive equalization techniques, we ha v e used only classes which spanned at least 10% of the whole data set, namely clarinet, flute, trump et, violin, alto saxophone and cello. More precisely , during the pro cess of cutting the audio samples into 1 s segments, we introduce increased ov erlap for instrument recordings with few er samples, thus utilizing a v ariable stride. This resulted in o v ersampling in underrepresen ted classes by o verlapping the segmen ts. 3 Time-F requency Represen tations of Audio Classical audio pre-pro cessing to ols suc h as the mel-sp ectrogram rely on some lo cal- ized, FFT-based analysis. The idea of the resulting time-frequency representation is to separate the v ariability in the signal with resp ect to time and frequency , re- sp ectiv ely . Ho wev er, for audio signals which are relev an t to human p erception, suc h as music or sp eech, significant v ariabilit y happ ens on very different time-levels: the frequency conten t itself can b e determined within a few milliseconds. V ariations in the amplitude of certain signal comp onen ts, e.g. formants or harmonics, hav e a m uch slo w e r frequency and should b e measured on the scale of up to few seconds. Longer- term musical developmen ts, which allo w, for example, to determine m usical style or genre, happ en on time-scales of more than several seconds. The basic idea of Gab or Scattering, as introduced in [2], see Section 3.2, is to capture the relev an t v ariability at different time-scales and separate them in v arious lay ers of the representation. W e first recall (mel-)sp ectrograms and turn to the definition of the scattering transforms in Section 3.2. 3.1 Sp ectrograms and Mel-Sp ectrograms Standard time-frequency represen tations used in audio-processing are based on STFT. Since w e are interested in obtaining several lay ers of time-frequency representations, w e define STFT as fr ame-c o efficients with resp ect to time-frequency-shifted v ersions of a basic window. T o this end, we in tro duce the following op erators in some Hilb ert space H . • The translation (time shift) op erator for a function f ∈ H and t ∈ R is defined as T x f ( t ) := f ( t − x ) for all x ∈ R . • The mo dulation (frequency shift) op erator for a function f ∈ H and t ∈ R is defined as M ω f ( t ) := e 2 π itω f ( t ) for all ω ∈ R . No w the STFT V g f of a function f ∈ H with resp ect to a windo w function g ∈ H can b e easily seen to b e V g f ( x, ω ) = h f , M ω T x g i with the corresp onding sp ectrogram | V g f ( x, ω ) | 2 . The set of functions G ( g , α, β ) = { M β j T αk g : ( αk , β j ) ∈ Λ } is a the Gab or system and is called Gab or frame [6], if there exist p ositiv e frame b ounds A, B > 0 such that for all f ∈ H A k f k 2 ≤ X k X j |h f , M β j T αk g i| 2 ≤ B k f k 2 . (1) Subsampling V g f on a separable lattice Λ = α Z × β Z we obtain the frame-co efficien ts of f w.r.t G ( g, α , β ). Choosing Λ thus corresp onds to picking a particular hop size in time and a finite num b er of frequency channels. The mel-sp ectrogram M S g ( f ) is defined as the result of w eighted a veraging | V g f ( α k, β j ) | 2 : M S g ( f )( α k, ν ) = X j | V g f ( α k, β j ) | 2 · Υ ν ( j ) , where Υ ν are the mel-filters for ν = 1 , ..., K with K filters. 3 3.2 Gab or Scattering and Mel Scattering W e next introduce a new feature extractor called Gab or scattering, inspired by Mal- lat’s scattering transform [12] and first introduced in [2]. In this contribution, we further extend the idea of Gab or-based scattering by adding a mel-filtering step in the first lay er. The resulting transform is called Mel scattering. Since the num b er of frequency c hannels is significantly reduced by applying the filter bank, the com- putation of MS is considerably faster. GS is a feature extractor for audio signals, obtained by an iterativ e application of Gab or transforms (GT), a non-linearity in the form of a mo dulus function and p ooling b y sub-sampling in each lay er. Since most of the energy and information of an input signal is known to be captured in the first t w o lay ers, cp. [1], w e only introduce and use the output of those first lay ers, while in principle scattering transforms allow for arbitrarily man y lay ers. In [2], it was sho wn that the output of sp ecific la yers of GS lead to in v ariances w.r.t. certain signal prop erties. Coarsely speaking, the output of the first la yer is in v ariant w.r.t. env elop e c hanges and mainly captures the frequency conten t of the signal, while the second lay er is in- v arian t w.r.t. frequency and con tains information ab out the en velope. F or more details on GS and a mathematical description of its inv ariances see [2]. In the follo wing, since we deal with discrete, finite signals f , we let H = C L , where L is the signal length, and f ` ∈ C L ` for ` = 1 , 2. The lattice parameters of the GT, i.e. Λ ` = α ` Z × β ` Z , can b e chosen differently for eac h lay er. The first lay er, which is basically a GT, corresp onds to f 1 [ β 1 j ]( k ) = |h f , M β 1 j T α 1 k g 1 i| , (2) and the second lay er can be written as f 2 [ β 1 j, β 2 h ]( m ) = |h f 1 [ β 1 j ] , M β 2 h T α 2 m g 2 i| . (3) Note that the input function of the second lay er is f 1 , where the next GT is applied separately to eac h frequency c hannel β 1 j . T o obtain the output of one lay er, one needs to apply an output generating atom φ ` , cp. [2]: f ` [ β 1 s, ..., β ` j ] ∗ φ ` ( k ) = |h f ` − 1 , M β ` j T α ` k g 1 i| ∗ φ ` , (4) for ` ∈ N in general and in our case ` = 1 , 2 . The output of the feature extractor is the collection of these coefficients (4) in one v ector, which is used as input to a mac hine learning task. Based on the GS we wan t to introduce an additional mel-filtering step. The idea is to reduce the redundancy in sp ectrogram b y frequency-av eraging. The expression in (2) is then replaced b y f 1 [ ν ]( k ) = X j |h f 0 , M β 1 j T α 1 k g 1 i| · Υ ν ( j ) , (5) where Υ ν corresp onds to the mel-filters, as introduced in Section 3.1. The other steps of the scattering pro cedure remain the same as for GS, i.e. p erforming another GT to obtain lay er 2 and afterwards applying an output generating atom in order to obtain the MS co efficien ts. The output of GS and MS can b e visually explained by Figure 1. The naming Output A displays either the output of Equation (2) in case of GS or Equation (5) in the MS case. The Output B sho ws the sp ectrogram after applying the output generating atom and Output C illustrates the output of the second lay er. 4 4 Augmen ted T arget Loss F unction In the previous sections w e in tro duced different input data representations for subse- quen t classification via deep learning. In the following w e wan t to inv estigate p ossible enhancemen t with alternative output/target data representations. T o do so, we use an augmented target loss function, a general framework is in tro duced in [3]. It allows to in tegrate known characteristics of the target space via informed transformations on the output and target data. W e now recall a general formulation of A T from [3] and des cribe subsequen tly in detail, how it can b e applied on the studied audio data. Our training data is giv en by the MT of the sounds as inputs together with instru- men t classes as targets, in tro duced in Section 2.1. The inputs to the netw ork are thus arra ys { x i } m i =1 ⊂ R 120 × 160 and ha ve asso ciated target v alues { y i } m i =1 ⊂ { 0 , 1 } 6 , corre- sp onding to the 6 instrument classes. As describ ed in Section 2, in each optimization step for the parameters of the neural netw ork, the netw ork’s output { ˆ y i } m i =1 ⊂ R 6 is compared with the targets { y i } m i =1 via an underlying loss function L . Ho wev er, training data often naturally contains additional imp ortan t target information that is not used in the original representation. W e aim to incorp orate such information tai- lored to the particular learning problem, enhancing the information conten t from the original target representation. F ollowing the definition in [3], the augmented target loss function is given by L AT y i , ˆ y i = n X j =1 λ j L j T j ( y i ) , T j ( ˆ y i ) . (6) Here, for all j = 1 , . . . , n , we let λ j > 0 b e an adjustable weigh t of L j , which is some standard loss function and T j : { 0 , 1 } 6 → R d j is a transformation which encodes the additional information on the target space. Here, T 1 corresp onds to the identit y on R 6 , i.e. no transformation is applied in the first comp onen t, where L 1 is the categorical cross-entrop y loss [20]. F or j = 2 , . . . , n , w e choose the dimension d j = 1 and L j to b e the mean squared error. The incorp oration of additional information on the Go odSounds data set is describ ed in detail in the following section. 4.1 Design of T ransformations W e heuristically choose d = 16 transformations T 2 , . . . , T 17 that use target character- istics (features) arising directly from the particular target class, with T j : { 0 , 1 } 6 → R , for j = 2 , . . . , 17. Amongst others the features are chosen from the enhanced sc heme of taxonomy [18] and from the table of frequencies, harmonics and under tones [21]. W e c ho ose transformations that pro vide information that is naturally con tained in the underlying instrumen t classes. The additional terms in the loss function (6) shall en- able to penalize common classification errors. In this exp erimen t, the transformations are given by the inner pro duct of the output/target and the feature vector. E.g. we directly know to which instrument family an instrument b elongs and distinguish b e- t w ee n woo dwind, brass and b ow ed instrumen ts, and moreo v er b et ween chordophone and aerophone instruments. Let’s assume a target vector y i ( j ) = δ ij , corresponds, resp ectiv ely , to the instruments clarinet, flute, trump et, violin, saxophone and cello, and the output of the netw ork is ˆ y i = ( a 1 , a 2 , a 3 , a 4 , a 5 , a 6 ) ∈ R 6 . The feature v ector v 1 = (1 , 1 , 0 , 0 , 1 , 0) then captures the information ”target instrument is from family w o odwind”. The transformation ma y be defined b y T 1 ( y i ) = h y i , v 1 i in order to incor- p orate this information. Additionally , by c ho osing λ j , we can weigh t the amoun t of p enalization for wrong assignments in ( T 1 ( y i ) − T 1 ( ˆ y i )) 2 . Amongst others we also use minim um and maximum frequencies of the instrument as features. E.g. the feature 5 corresp onding to minim um frequency v 2 = ( b 1 , b 2 , b 3 , b 4 , b 5 , b 6 ) ∈ R 6 . Again the trans- formation is given by T 2 ( y i ) = h y i , v 2 i . Choosing the right p enalt y for this feature could prohibit that instrumen ts belonging to the same instrumen t family are classified wrong, e.g. a cello that would b e classified as a violin. One can think ab out A T as a metho d to more precisely define the measure of distance b et w een the predicted and target classes. 5 Numerical Exp erimen ts In the numerical exp erimen ts, we compare the p erformances of CNNs trained using the CC loss and time-frequency represen tations men tioned in Section 3. As a baseline, w e use the results of MT. F urthermore w e compare the baseline with the results of MT with A T loss as in tro duced in Section 4. The o verall task is a m ulti-class classification of musical instruments based on the audio signals in tro duced in Section 2.1. 5.1 Computation of Signal Represen tations The raw audio signals were transformed in to MT, MS and GS time-frequency rep- resen tations, using the Gab or-scattering v0.0.4 library [7]. The library contains our Python implementation of all previously men tioned signal representations, with the aim to pro vide the communit y with an easy access to all of the transformations. The library’s core algorithms are based on Scipy v1.2.1 [5, 9, 15] implementation of STFT and mel-filter banks from Librosa v0.6.2 library [14]. All the representations are derived from GT. In order to hav e a go od resolution in time and frequency for our classification task, w e hav e chosen the parameters heuristically . The final shap es of the representations are shown in T able 1. The three dimensional output of GS contains the GT and outputs of lay er 1 and 2 of the GS cf. [2], the same applies to MS. The visualizations of the time-frequency transformations of an arbitrary training sample are shown in Figure 1. 5.2 Deep Conv olutional Neural Net work W e implemented our exp erimen t in Python 3.6. A CNN was created and trained from scratch on Nvidia GTX 1080 Ti GPU in Keras 2.2.4 framework [4] using the describ ed training set split in to batc hes of size 128. W e used an architecture consisting of four con volutional stacks. Eac h of them consists of a conv olutional lay er, rectified- linear unit activ ation function and av erage p o oling. These stacks were follo w ed by a fully connected lay er with softmax activ ation function. Eac h netw ork had to be adjusted slightly , b ecause the input shap es c hanged according to the time-frequency represen tation used (GS has 3 channels, MT has less frequency channels etc.). W e ha v e tried to make the results as comparable as p ossible, therefore the netw orks differ only in the num b er of channels of the input lay er, the rest of the net work is only affected by the num b er of frequency channels, which thanks to p ooling did not cause significan t difference in the nu mber of trainable parameters. All netw orks hav e comparable num b er of trainable parameters within the range from 81 042 to 83 882. The weigh ts were optimized using Adam optimizer [10]. Reproducible op en source co de can b e found in the rep ository [8]. 5.3 T raining and Results All the samples were split into training, v alidation and testing sets in suc h a wa y that v alidation and testing sets hav e exactly the same num b er of samples from each class, while this holds for training set only approximately . Segments from audio files that were used in v alidation or testing were not used in training to preven t leaking of 6 1 0 0 1 0 1 1 0 2 GS output A (GT) MS output A (MT) 1 0 0 1 0 1 1 0 2 GS output B MS output B 0 0.25 0.5 0.75 1.0 Time [s] 1 0 0 1 0 1 1 0 2 GS output C 0 0.25 0.5 0.75 1.0 Time [s] MS output C Frequency channels (log) Figure 1: Visualization of time-frequency transformations. information. Detailed information ab out the used data, stride settings for each class , obtained num b er of segments and their split can b e found in the repository [8]. In total we hav e trained 36 different mo dels (MT, MS, GS with CC and MT with A T trained on 9 training set sizes), with the following hyper-parameters: num b er of con v olutional k ernels in the first 3 conv olutional lay ers is 64 each, learning rate is 0.001, λ of A T is 10 and λ of L 2 w eigh t regularization is 0.001. As a baseline we hav e used MT with a standard CC loss function as implemented in the Keras framework and describ ed in detail in Section 2. The computational effort was limited to 11 000 w eigh t up dates. Time necessary for one weigh t up date of each mo del is sho wn in T able 1. T able 2 sho ws the highest achiev ed accuracies of the CNN mo dels trained with MT for different training set sizes along with the improv ements of this baseline by prop osed metho ds. Accuracy is computed as a fraction of correct predictions to all predictions. In Figure 2 we compare the num b er of weigh t updates necessary to surpass a certain accuracy threshold for all prop osed metho ds. Occlusion maps [19] for a random MS sample are visualized p er 3 frequency bins in Figure 3. 7 1 0 2 1 0 3 1 0 4 40 45 50 55 60 65 70 Valid acc [%] 1 train batch (128 samples) MT_CC (best w.u.134: 63.33%) MT_AT (best w.u.190: 66.34%) MS_CC (best w.u.101: 66.83%) GS_CC (best w.u.156: 70.47%) 1 0 2 1 0 3 1 0 4 40 50 60 70 80 Valid acc [%] 3 train batches (384 samples) MT_CC (best w.u.255: 74.37%) MT_AT (best w.u.321: 75.11%) MS_CC (best w.u.264: 75.17%) GS_CC (best w.u.303: 82.11%) 1 0 2 1 0 3 1 0 4 Weight updates (log) 40 50 60 70 80 90 Valid acc [%] 5 train batches (640 samples) MT_CC (best w.u.1685: 80.17%) MT_AT (best w.u.1980: 81.19%) MS_CC (best w.u.1595: 80.47%) GS_CC (best w.u.705: 86.77%) Figure 2: CNN p erformance milestone reac hed ov er num b er of weigh t up dates. The computational effort in all exp erimen ts w as limited to 11 000 weigh t up dates. Figure notation: V alid acc – Accuracy p erformance metric measured on the v alidation set, Best w.u. – W eight up date after whic h the highest p erformance was reached. 8 T able 1: Shap es and execution time TF shap e CC A T GS 3 × 480 × 160 950 ms - MT 1 × 120 × 160 250 ms 320 ms MS 3 × 120 × 160 450 ms - T able notation: TF – Time-frequency representation. CC/A T – The execution time of one weigh t up date during training with CC/A T loss function. T able 2: Improv ements of the MT Baseline Highest v alidation set accuracies NB MT MT A T MS GS 1 63.33 % +3.01 % +3.50 % +7.15 % 3 74.37 % +0.74 % +0.80 % +7.74 % 5 80.17 % +1.02 % +0.31 % +6.60 % 7 82.93 % -1.12 % -0.09 % +5.63 % 9 85.40 % +0.95 % -0.43 % +5.28 % 11 86.53 % +0.33 % +1.26 % +5.57 % 55 96.06 % -0.27 % -0.27 % +2.52 % 110 96.31 % -0.04 % +0.06 % +2.53 % 550 96.00 % +0.74 % +0.48 % +3.12 % Corresp onding testing set accuracies NB MT MT A T MS GS 1 64.28 % +2.73 % +3.36 % +6.93 % 3 75.61 % +0.58 % +0.32 % +7.26 % 5 80.69 % +0.79 % +0.07 % +6.93 % 7 83.48 % -1.13 % +0.37 % +6.30 % 9 86.30 % +0.54 % -0.43 % +5.23 % 11 87.41 % -0.43 % +1.30 % +4.85 % 55 96.27 % -0.20 % -0.31 % +2.26 % 110 96.80 % -0.55 % -0.12 % +2.21 % 550 96.72 % +0.27 % +0.07 % +2.29 % T able notation: NB – Number of training batc hes with 128 samples eac h. MT, MS and GS – mel-sp ectrogram, Mel scattering and Gabor scattering as input representa- tions with CC. MT here servers as a baseline for comparison with other metho ds. MT A T – mel-spectrogram as input representation with A T. T esting set accuracies w ere ev aluated after the ep och where the v alidation accuracy was the highest. 9 Output A Input Output B 0 0.25 0.5 0.75 1.0 Time [s] Output C O c c ( 3 × 1 6 0 ) max: 43.1% max: -31.8% max: 37.6% max: -27.5% 0 0.25 0.5 0.75 1.0 Time [s] max: 0.916% max: -0.394% I n p u t O c c + Frequency channels 0 0.25 0.5 0.75 1.0 Time [s] Figure 3: Visualization of o cclusion maps and frequency channel imp ortance based on the b est p erforming mo del trained on 1 batch of MS. Signal shown is randomly selected alto sax sample. Figure notation: Input – input represen tation for CNN. Occ – occlusion map created by sliding o cclusion window. Input Occ + – Elemen twise m ultiplication of input with positive semidefinite occ (negativ e elemen ts w ere c hanged to zeros b efore m ultiplication). Blue and red colors – P ositive and negative influence of particular frequency channel bin on the mo del p erformance. 10 6 Discussion and Conclusions Our previous w ork on Gab or scattering show ed that signal v ariabilit y w.r.t. differen t time scales is separated b y this transform, cf. [2], which is a b eneficial prop ert y for learning. The common choice of a time-frequency representation of audio signals in predictiv e mo deling is mel-sp ectrogram; hence, as a natural step, we introduced MS in this pap er, a new feature extractor which combines the prop erties of GS with mel- filter av eraging. W e also inv estigated the impact of additional information ab out the target space through A T on the p erformance of the trained CNN. F rom the results on Go odSounds dataset shown in T able 2, we see that all prop osed metho ds outp erform the baseline (mel-sp ectrogram with categorical cross-entrop y loss) on the first three most limited training sets, i.e. the data sets with the least amoun t of data. All prop osed metho ds also show a trend to ac hiev e b etter results earlier in the training, as visible in Figure 2. This trend seems to diminish with big- ger training set sizes. Impro vemen ts on the last, biggest training set can b e justified b y the fact that this exp erimen t was interrupted b efore it had the time to conv erge, therefore highligh ting earlier successes of the prop osed metho ds. F rom the newly prop osed metho ds, A T is the least exp ensiv e in terms of training time, but on the other hand yields the smallest improv ement in this exp erimen tal setup. Neverthe- less, it has another adv antage: it steers the training to w ards learning the p enalized c haracteristics, e,g. to learn the characteristic of an instrument b eing or not b eing a w o od instrument if the information ab out this grouping is provided through A T. W e b eliev e that the p ositiv e effect of A T in this setup b ecomes obsolete with higher n um b er of training batches b ecause after training ab o v e a certain accuracy threshold, the netw ork already predicts the correct groups of classes and therefore can not gain from A T anymore. MS p erformed b etter than b oth MT and MT A T for slightly higher cost of com- putation and also achiev ed the same p erformances earlier. GS outp erformed all of the tested metho ds and show ed an improv ement ov er all training set sizes, ho w ev er this might also suggest that GT (without mel-filtering) w ould b e a b etter input data represen tation for this task in the first place . As in GS, MS comprises exclusively the information of its MT origin. The separation of the embedded information in to three distinct channels migh t b e the reason for its success. The evidence is visible in Fig- ure 2, whic h shows MS reaching higher accuracies after less weigh t up dates than MT, suggesting that the net work did not ha ve to learn similar separation during training. Also, the visualization in Figure 3 supp orts this by showing a p ositiv e influence of Outputs A and B on the mo del’s p erformance. It remains to b e said, that improv ements which can b e gained by using A T, MS or GS highly dep end on the task b eing solved, on the choice of transformations based on the amoun t of additional av ailable information for A T and on the correctly chosen parameters of the time-frequency representations. F rom what was stated ab o ve, we can conclude that A T pro vides a more precise measure of distance b et ween outputs and targets. That’s wh y it can help in scenarios where the training set is not large enough to allo w the learning of all characteristics, but can be penalized b y A T. W e suggest to use/exp erimen t with the prop osed metho ds for other data sets if there is not a sufficien t amoun t of data a v ailable or/and there exist reasonable transformations in the target space relev ant to the task b eing solved. All prop osed metho ds might b e found useful also in scenarios with limited resources for training. In order to obtain reliable statistical results on the v arious methods, it would b e necessary to run all exp erimen ts several h undred times with different seeds. F or the current contribu tion, such a pro cedure was not included due to the restriction of computational resources and is thus left for future w ork. 11 References [1] J. And ´ en and S. Mallat. Deep scattering spectrum. IEEE T r ansactions on Signal Pr o c essing , 62(16):4114–4128, 2014. [2] R. Bammer, M. D¨ orfler, and P . Harar. Gab or frames and deep scattering net- w orks in audio pro cessing. arXiv pr eprint arXiv:1706.08818 , 2017. [3] A. Breger, J. I. Orlando, P . Harar, M. D¨ orfler, S. Klimscha, C. Grechenig, B. S. Gerendas, U. Schmidt-Erfurth, and M. Ehler. On orthogonal pro jections for di- mension reduction and applications in augmented target loss functions for learn- ing problems. arXiv pr eprint arXiv:1901.07598 , 2019. [4] F. Chollet et al. Keras. https://keras.io , 2015. [5] D. Griffin and J. Lim. Signal estimation from mo dified short-time fourier trans- form. IEEE T r ansactions on A c oustics, Sp e e ch, and Signal Pr o c essing , 32(2):236– 243, 1984. [6] K. Gr¨ oc henig. F oundations of time-fr e quency analysis . Applied and numerical harmonic analysis. Birkh¨ auser, Boston, Basel, Berlin, 2001. [7] P . Harar. gab or-scattering. https://gitlab.com/paloha/gabor- scattering , 2019. [8] P . Harar. gs-ms-mt. https://gitlab.com/hararticles/gs- ms- mt , 2019. [9] E. Jones, T. Oliphan t, P . P eterson, et al. SciPy: Op en source scientific to ols for Python, 2001–. [Online; accessed 2019-02-01]. [10] D. Kingma and J. Ba. Adam: A metho d for sto c hastic optimization. arXiv pr eprint arXiv:1412.6980 , 2014. [11] Y. LeCun, P . Haffner, L. Bottou, and Y. Bengio. Ob ject recognition with gradien t-based learning. In Shap e, c ontour and gr ouping in c omputer vision , pages 319–345. Springer, 1999. [12] S. Mallat. Group inv arian t scattering. Communic ations on Pur e and Applie d Mathematics , 65(10):1331–1398, 2012. [13] S. Mallat. Understanding deep con v olutional netw orks. Philosophic al T r ansac- tions of the R oyal So ciety A: Mathematic al, Physic al and Engine ering Scienc es , 374(2065):20150203, 2016. [14] B. McF ee, M. McVicar, S. Balk e, C. Thom, V. Lostanlen, C. Raffel, ..., and A. Holov at y . librosa/librosa: 0.6.2, Aug. 2018. [15] A. V. Opp enheim. Discr ete-time signal pr o c essing . Pearson Education India, 1999. [16] J. P ons Puig, O. Nieto, M. Prockup, E. M. Sc hmidt, A. F. Ehmann, and X. Serra. End-to-end learning for music audio tagging at scale. In Pr o c e e dings of the 19th International So ciety for Music Information R etrieval Confer enc e, ISMIR 2018; 2018 Sep 23-27; Paris, F r anc e. p. 637-44. International So ciet y for Music Infor- mation Retriev al (ISMIR), 2018. [17] O. Romani Picas, H. P arra Ro driguez, D. Dabiri, H. T okuda, W. Hariy a, K. Oishi, and X. Serra. A real-time system for measuring sound go o dness in instrumen tal sounds. In Audio Engine ering So ciety Convention 1 38 . Audio En- gineering So ciet y , 2015. 12 [18] E. M. V on Horn b ostel and C. Sac hs. Classification of musical instruments: T rans- lated from the original german by anthon y baines and klaus p. wac hsmann. The Galpin So ciety Journal , pages 3–29, 1961. [19] M. D. Zeiler and R. F ergus. Visualizing and understanding con volutional net- w orks. In Eur op e an c onfer enc e on c omputer vision , pages 818–833. Springer, 2014. [20] Z. Zhang and M. Sabuncu. Generalized cross entrop y loss for training deep neural netw orks with noisy lab els. In A dvanc es in neur al information pr o c essing systems , pages 8778–8788, 2018. [21] ZyT rax. F requency ranges. zytrax.com/tech/audio/audio.h tml, 2018. 13
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment