그래프 기반 오디오 지문 GraFPrint: GNN으로 구현한 고성능 식별 시스템
GraFPrint은 로그‑멜 스펙트로그램을 k‑NN 그래프로 변환하고, 최대‑상대 그래프 컨볼루션을 이용해 로컬·글로벌 정보를 융합한 GNN 인코더를 학습한다. 셀프‑슈퍼비전 대비 학습으로 잡음·리버브에 강인한 128차원 임베딩을 얻으며, FAISS 기반 IVF‑PQ 검색으로 대규모 데이터베이스에서도 실시간 식별이 가능하다. FMA 데이터셋 실험에서 기존 CNN·Transformer 기반 베이스라인을 크게 앞서 1초~5초 구간, 다양한 SNR·…
저자: Aditya Bhattacharjee, Shubhr Singh, Emmanouil Benetos
본 논문은 그래프 신경망(GNN)을 활용한 새로운 오디오 지문 생성 및 식별 프레임워크인 GraFPrint을 제안한다. 기존 오디오 식별 기술은 크게 두 갈래로 나뉜다. 첫 번째는 스펙트로그램에서 피크를 추출해 이진 해시 형태로 저장하는 랜드마크 기반 방법으로, 구조가 단순하고 검색이 빠르지만 시간 이동, 잡음, 리버브와 같은 변형에 취약하다. 두 번째는 CNN이나 Transformer와 같은 딥러닝 기반 인코더를 사용해 셀프‑슈퍼비전 대비 학습을 수행하는 방법으로, 데이터‑드리븐 특성 덕분에 잡음에 대한 내성을 어느 정도 확보하지만, 격자형 입력에 최적화된 구조라 비유클리드 형태의 관계를 충분히 포착하지 못한다는 한계가 있다.
GraFPrint은 이러한 한계를 극복하고자, 로그‑멜 스펙트로그램을 **k‑최근접 이웃(k‑NN) 그래프**로 변환한다. 구체적으로, 입력 오디오 세그먼트(길이 t초)를 로그‑멜 스펙트로그램으로 변환하고, 시간·주파수 인덱스 채널을 추가해 위치 정보를 명시한다. 1×1 컨볼루션과 배치 정규화를 거쳐 차원 d(보통 64~128)로 압축한 뒤, 각 포인트를 노드로 간주하고 Euclidean 거리 기반 k‑NN 알고리즘을 적용해 무방향 그래프를 동적으로 구성한다. 이 그래프는 입력마다 새로 생성되므로, 원본 오디오의 변형이 그래프 구조 자체에 반영되어 변형 불변성을 자연스럽게 학습한다.
그래프 위에서 수행되는 핵심 연산은 **max‑relative 그래프 컨볼루션**이다. 기존 GCN이 이웃 노드의 평균이나 합을 사용해 정보를 집계하는 것과 달리, GraFPrint은 각 이웃 노드와 현재 노드 간 차이를 최대값으로 추출하고 이를 현재 노드와 연결(concatenation)한다. 수식 (2)·(3)에서 확인할 수 있듯이, `max(x_j - x_i)`는 상대적인 변동성을 강조해 잡음에 강인한 특징을 만든다. 이어지는 선형 변환·비선형 활성화(σ)와 residual 연결은 과도한 스무딩을 방지하고, 그래프 레이어마다 표현력을 유지한다.
그래프 레이어 뒤에는 **Feed‑Forward Network(FFN) + 스트라이드 2‑D 컨볼루션**을 삽입한다. FFN은 Transformer에서 차용한 두 개의 완전 연결 층과 비선형 활성화(ReLU)로 구성되며, 스트라이드 컨볼루션은 노드 수를 단계적으로 감소시켜 k‑NN 연산 비용을 크게 절감한다. 최종적으로 노드 임베딩을 평균 풀링해 전체 세그먼트의 전역 표현을 얻고, 이를 128차원 임베딩 z로 투사한다.
학습 단계에서는 **셀프‑슈퍼비전 대비 학습**을 적용한다. 원본 스펙트로그램 S와 다양한 데이터 증강(A)으로 만든 변형 S′(시간 오프셋, 배경 잡음, 콘볼루션 리버브)를 쌍으로 사용해 NT‑Xent 손실을 최소화한다. 이때 코사인 유사도와 온도 파라미터 τ=0.05를 사용해 동일 샘플의 두 뷰는 가깝게, 서로 다른 샘플은 멀리 배치한다. 이렇게 학습된 인코더는 잡음·리버브에 강인한 임베딩을 생성한다.
검색 및 재식별 단계에서는 **FAISS 기반 IVF‑PQ**(인버터 파일 인덱스 + 제품 양자화) 알고리즘을 사용한다. 쿼리 오디오를 동일한 방식으로 세그먼트화하고 임베딩을 추출한 뒤, IVF‑PQ 인덱스를 통해 근사 최근접 이웃을 빠르게 찾는다. 검색 결과 인덱스에 대해 오프셋 보정(I∗)과 시퀀스‑레벨 유사도(내적) 기반 최종 매칭을 수행한다.
실험은 FMA 데이터셋을 활용해 진행된다. 학습에는 fma‑small(8 000곡, 30 s 길이) 데이터를 사용하고, 기준 데이터베이스는 fma‑medium(25 000곡) 및 fma‑large(106 000곡)으로 확장한다. 쿼리는 1~5 s 길이의 세그먼트를 0.1 s hop으로 오버랩해 2 000개씩 추출하고, MUSAN 잡음과 Aachen RIR을 이용해 SNR 0~20 dB와 리버브 조합을 만든다.
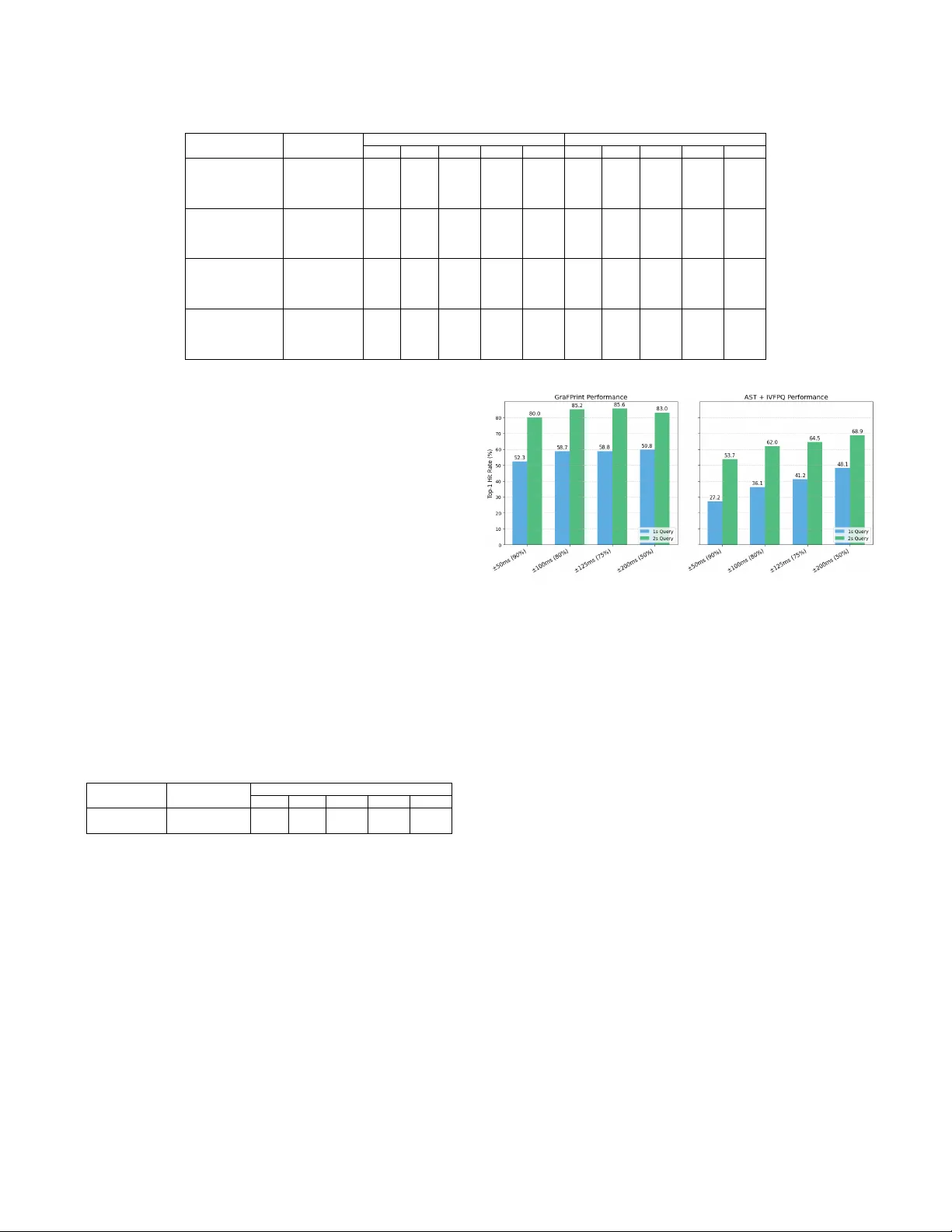
성능 평가는 **Top‑1 히트율**(정확히 일치하는 레퍼런스를 찾은 비율)로 측정한다. 결과는 다음과 같다.
- 1 s 쿼리, 0 dB SNR, 잡음만 있을 때 GraFPrint은 93.5%의 히트율을 기록했으며, 20 dB에서는 98.8%에 도달한다.
- 동일 조건에서 기존 CNN 기반 NAFP는 50.7%~76.9%에 머물렀고, Transformer 기반 TE+LSH·TE+HT는 각각 66.6%~90.6%와 64.9%~90.9% 수준이었다.
- 리버브가 추가된 경우에도 GraFPrint은 11.6 pp 정도만 성능이 감소해, 베이스라인 대비 10 pp 이상 우수함을 확인했다.
- 5 s 쿼리에서는 거의 완벽에 가까운 99.9% 수준을 달성했으며, 데이터베이스를 fma‑large(106 K)로 확장해도 정확도가 크게 떨어지지 않았다.
이러한 결과는 그래프 기반 임베딩이 **로컬 구조(시간‑주파수 관계)**와 **글로벌 컨텍스트**를 동시에 포착해, 잡음·리버브와 같은 실제 환경 변형에 강인함을 보여준다. 또한, 평균 풀링·128‑dim 투사와 IVF‑PQ 검색을 결합함으로써 **경량화**와 **스케일러빌리티**를 동시에 달성했다.
논문의 한계로는 그래프 구축 시 k‑NN 연산 비용이 입력 길이에 비례해 증가한다는 점과, k값 및 그래프 레이어 수 등 하이퍼파라미터가 데이터 특성에 민감할 수 있다는 점을 들 수 있다. 향후 연구에서는 **동적 k‑값 학습**, **멀티‑헤드 그래프 어그리게이션**, **멀티모달(가사·메타데이터) 결합** 등을 통해 더욱 견고하고 확장 가능한 오디오 식별 시스템을 구축할 여지가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기