스프레드시트 오류 방지를 위한 구조화 개발 방법론 평가
본 논문은 Jackson 구조와 들여쓰기 기법을 기반으로 한 구조화된 스프레드시트 개발 방법론을 제시하고, 실제 실험을 통해 오류 감소와 가독성 향상 효과를 검증한다.
저자: Kamalasen Rajalingham, David Chadwick, Brian Knight
논문은 스프레드시트 모델의 오류를 체계적으로 감소시키기 위해 구조화된 개발 방법론을 제안하고, 이를 실험적으로 평가한다. 서론에서는 기존의 자유형 스프레드시트가 사용자 실수에 취약하고, 유지보수가 어려운 문제점을 지적하며, 소프트웨어 공학에서 사용되는 Jackson 구조를 차용한 새로운 접근법의 필요성을 강조한다.
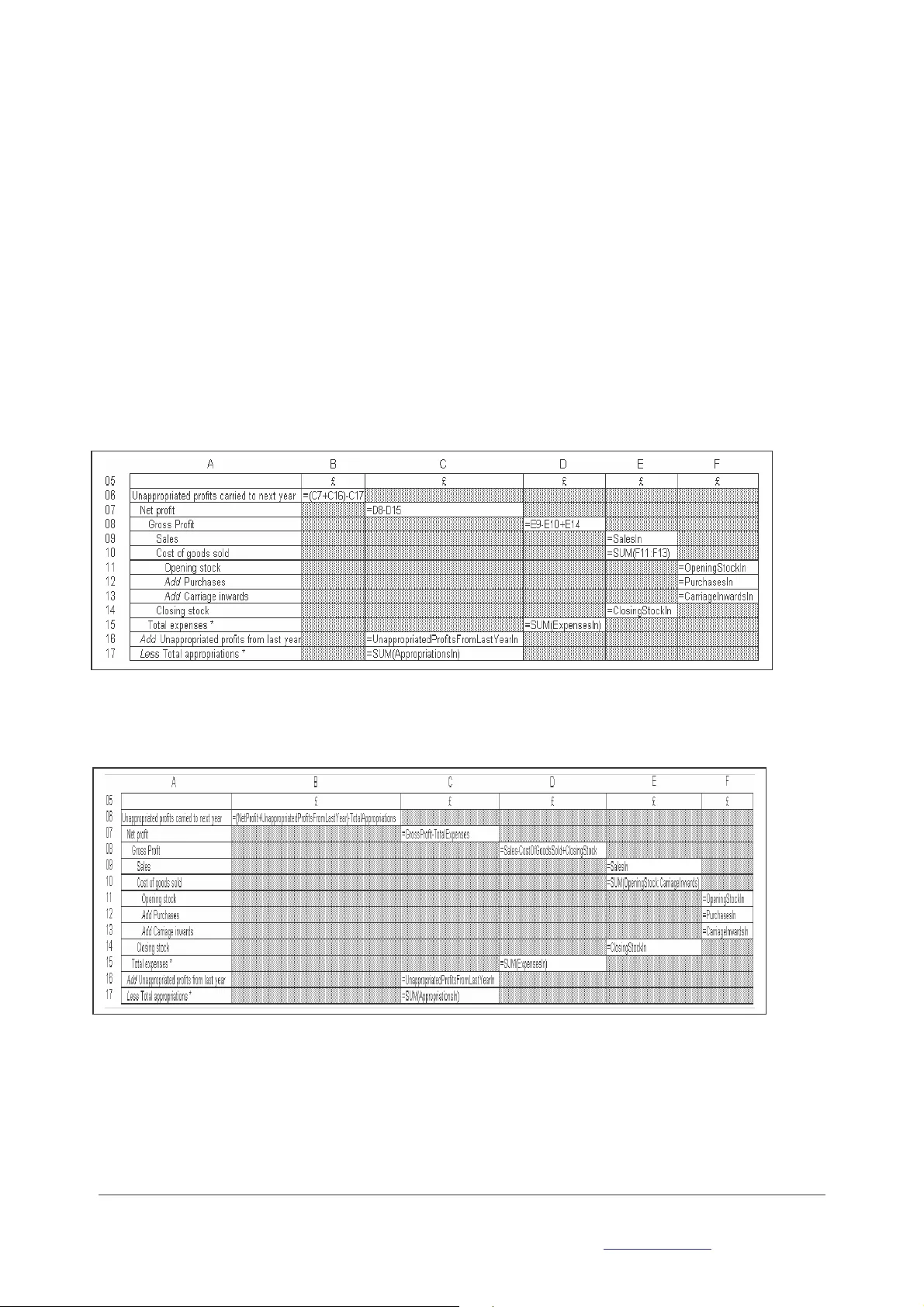
방법론 파트에서는 7단계 알고리즘을 상세히 설명한다. 첫 단계인 ‘출력 및 설계 사양’에서는 최종 사용자가 필요로 하는 보고서 형태를 별도 워크시트에 정의한다. 두 번째 단계 ‘작업 섹션 개념 설계’에서는 모델의 최상위 함수(루트 요소)를 식별하고, 이를 트리 구조의 최상위 노드로 배치한다. 세 번째 단계 ‘논리 설계’에서는 그래프 형태의 종속 관계를 트리 형태로 변환하는 두 가지 규칙을 제시한다. Rule 1은 다중 종속 요소를 복제하여 트리 구조를 만들고, Rule 2는 복제된 요소가 자체 선행 요소를 가질 경우 이를 별도 모듈로 분리한다. 이는 데이터베이스 정규화와 유사한 효과를 제공한다.
네 번째 단계 ‘작업 섹션 구조 구현’에서는 트리 구조를 시트에 매핑하기 위해 들여쓰기와 가상 열 개념을 도입한다. 각 레벨마다 고정된 가상 열을 할당함으로써 함수와 레이블이 시각적으로 정렬되고, 선행 관계가 한눈에 파악된다. 다섯 번째 단계 ‘입력 섹션 구현’에서는 모든 입력 데이터를 별도 시트에 집합(range) 형태로 정의하고, 이름을 부여한다. 이는 입력 셀 간의 의존성을 차단하고, 사용자가 데이터를 수정할 때 작업 섹션에 자동 반영되도록 한다.
여섯 번째 단계 ‘함수·관계 구현’에서는 작업 섹션에 실제 수식을 입력한다. 여기서는 하향식(bottom‑up) 접근을 취해, 가장 하위 함수부터 차례로 구현한다. 수식에 사용되는 셀 주소 대신 범위 이름을 활용해 가독성을 높이며, 필요 시 라벨을 자연어 형태로 변환하는 방안을 제시한다. 마지막 단계 ‘출력 완성’에서는 설계 단계에서 정의한 출력 시트를 채워 최종 보고서를 완성한다.
실험 부분에서는 거래·손익계정 모델을 사례로 들어, 네 명의 개발자가 전통적 방식과 제안된 구조화 방식으로 각각 모델을 구축하도록 했다. 결과는 구조화 방식이 레이아웃·구조 일관성을 보장하고, 오류 발생률을 약 70% 감소시켰으며, 검토·감사 시간이 평균 40% 단축되었다는 점을 보여준다.
논의에서는 방법론의 장점(오류 감소, 유지보수 용이, 감사 효율성)과 한계(복잡한 그래프 변환 시 중복 증가, 사용자 학습 비용, 라벨 기반 수식 변환을 위한 추가 도구 필요)를 균형 있게 다룬다. 또한 향후 연구 방향으로 자동 트리 변환 도구, 라벨 기반 수식 자동 생성, 대규모 기업 환경 적용 사례 등을 제시한다.
결론적으로, 이 논문은 스프레드시트 개발에 구조화 원칙을 적용함으로써 품질을 크게 향상시킬 수 있음을 실증적으로 입증하고, 실무 적용을 위한 구체적인 가이드라인과 향후 연구 과제를 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기