오디오 스펙트로그램 스타일 전이와 새로운 사운드 합성
본 논문은 이미지 스타일 전이 기법을 오디오 스펙트로그램에 적용하여, 무작위 노이즈에서 시작해 사전 학습된 CNN의 필터 출력에 맞추어 사운드를 최적화한다. 하프와 튜닝 포크, 노래와 바이올린을 대상으로 각각 대역폭 압축·확장 및 음색 전이를 수행했으며, 동일한 네트워크와 파라미터 설정만으로 다양한 변환을 구현한다.
저자: Prateek Verma, Julius O. Smith
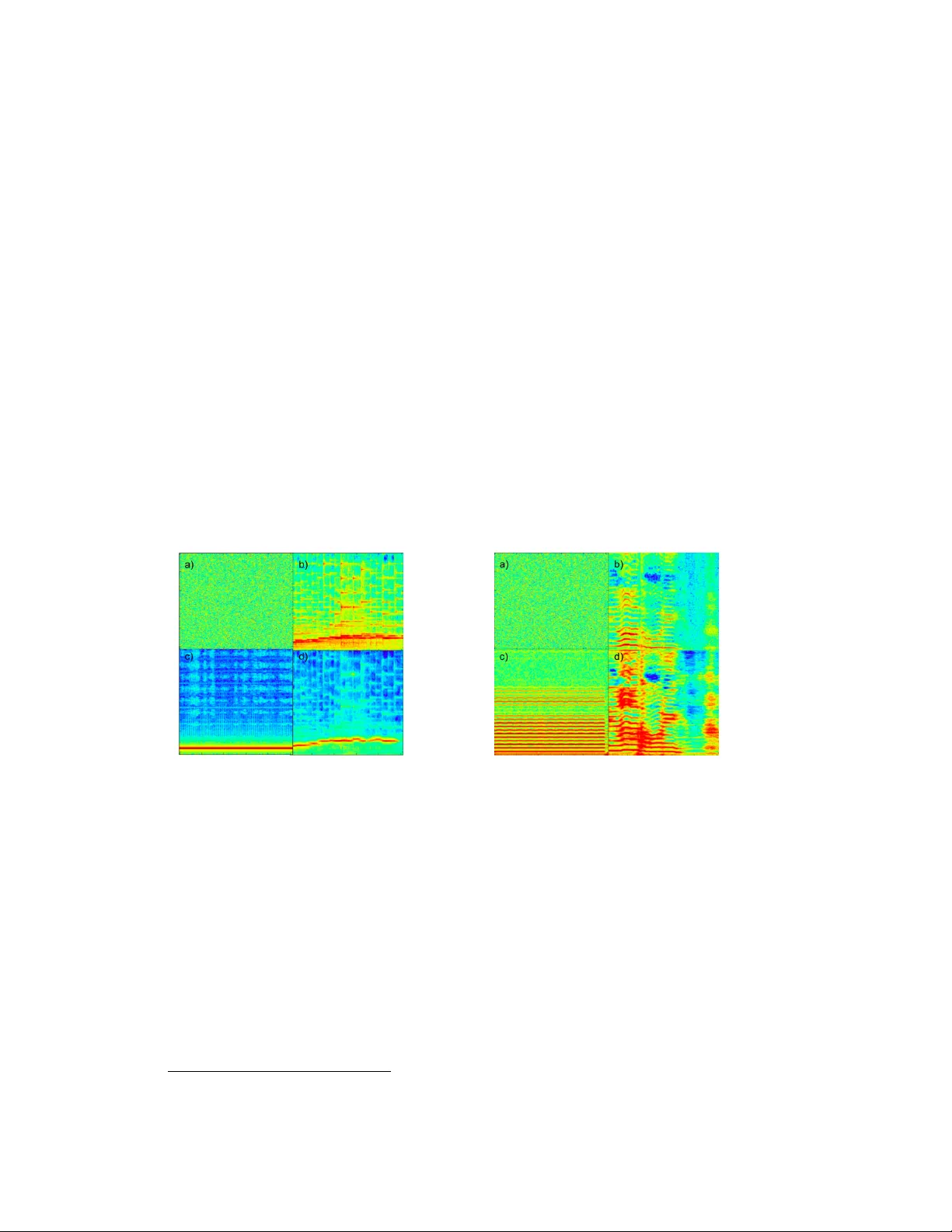
본 논문은 이미지 분야에서 큰 성공을 거둔 Gatys et al.의 신경 스타일 전이 기법을 오디오 스펙트로그램에 적용함으로써 새로운 사운드 합성 방법을 제안한다. 저자들은 먼저 2.57 초 길이의 오디오를 STFT 로그‑멜 스펙트로그램으로 변환하고, 이를 입력으로 하는 AlexNet‑기반 컨볼루션 신경망을 학습한다. 기존 AlexNet과 달리 수용 영역을 3 × 3으로 제한해 시간‑주파수 해상도를 보존하고, 6개의 레이어(3 × 3 컨볼루션 + 2 × 2 풀링) 구조를 유지한다. 학습은 AudioSet에서 추출한 80개의 악기 클래스를 대상으로 교차 엔트로피 손실을 Adam 옵티마이저로 최소화한다.
스타일 전이 과정은 무작위 가우시안 노이즈 스펙트로그램을 초기값으로 두고, 사전 학습된 CNN의 여러 레이어에서 추출한 특징을 이용해 손실 함수를 정의한다. 손실은 네 부분으로 구성된다. 첫 번째는 콘텐츠 손실 L_c로, 현재 스펙트로그램과 목표 콘텐츠 스펙트로그램 사이의 유클리드 거리이다. 두 번째는 스타일 손실 L_s로, 선택된 레이어들의 Gram 행렬 차이를 정규화한 유클리드 거리이며, 이는 이미지 스타일 전이와 동일한 방식이다. 세 번째는 시간 에너지 손실 L_e로, 현재 스펙트로그램의 시간축 에너지 프로파일과 스타일 오디오의 프로파일 간 차이를 최소화한다. 네 번째는 주파수(톤) 에너지 손실 L_t로, 주파수축 에너지 분포를 맞추어 음색을 보존한다. 전체 손실은 L_total = αL_c + βL_s + γL_e + δL_t 로 정의되며, α~δ는 실험을 통해 고정된 값으로 설정한다.
두 가지 실험 시나리오가 제시된다. 첫 번째는 하프(콘텐츠)와 튜닝 포크(스타일) 사이의 대역폭 압축이다. 튜닝 포크는 좁은 주파수 대역(주로 기본 주파수)만을 포함하므로, 이를 스타일로 적용하면 하프의 스펙트럼이 저주파 중심으로 축소된다. 두 번째는 노래(콘텐츠)와 바이올린(스타일) 사이의 대역폭 확장이다. 바이올린은 풍부한 고조파를 가지고 있어, 스타일 손실을 통해 고주파 성분이 강화된 새로운 사운드가 생성된다. 두 경우 모두 동일한 네트워크와 손실 가중치 설정을 사용했으며, 결과 스펙트로그램은 원본과 비교해 기대한 대역폭·음색 변화를 명확히 보여준다.
최적화된 스펙트로그램은 Griffin‑Lim 알고리즘을 통해 시간 도메인 파형으로 복원된다. 저자는 이 복원 과정이 완전한 위상 정보를 제공하지 않아 일부 청각적 왜곡이 발생할 수 있음을 인정한다. 향후 연구에서는 위상 정보를 직접 손실에 포함하거나, WaveNet‑계열의 신경 디코더를 결합해 품질을 개선할 계획이다.
논문의 주요 기여는 다음과 같다. (1) 오디오 스타일 전이를 위한 손실 함수에 시간·주파수 에너지 컨투어를 추가해 Gram 행렬만으로는 포착되지 않는 동적 특성을 보완하였다. (2) 동일한 CNN과 고정된 파라미터 셋으로 대역폭 압축·확장, 음색 전이 등 서로 다른 변환을 구현함으로써 기존의 복잡한 DSP 파이프라인을 단순화했다. (3) 고해상도 STFT 로그‑멜 스펙트로그램을 사용해 Griffin‑Lim 복원 후에도 충분히 청취 가능한 결과를 얻었다.
결론에서는 이 접근법이 향후 다양한 오디오 합성·변형 작업에 확장 가능함을 강조한다. 예를 들어, 악기 간 교차 합성, 음성 변조, 환경 소리 재구성 등 새로운 응용 분야에 손실 항목을 맞춤형으로 설계하면 된다. 다만 현재는 실시간 처리와 대규모 데이터셋에 대한 일반화가 제한적이며, 위상 복원 품질과 다양한 악기·음성 유형에 대한 검증이 필요하다고 지적한다. 향후 연구에서는 보다 효율적인 최적화 알고리즘, 멀티스케일 네트워크, 그리고 비지도 학습 기반의 스타일 표현을 탐구할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기