Neural Style Transfer for Audio Spectograms
There has been fascinating work on creating artistic transformations of images by Gatys. This was revolutionary in how we can in some sense alter the 'style' of an image while generally preserving its 'content'. In our work, we present a method for c…
Authors: Prateek Verma, Julius O. Smith
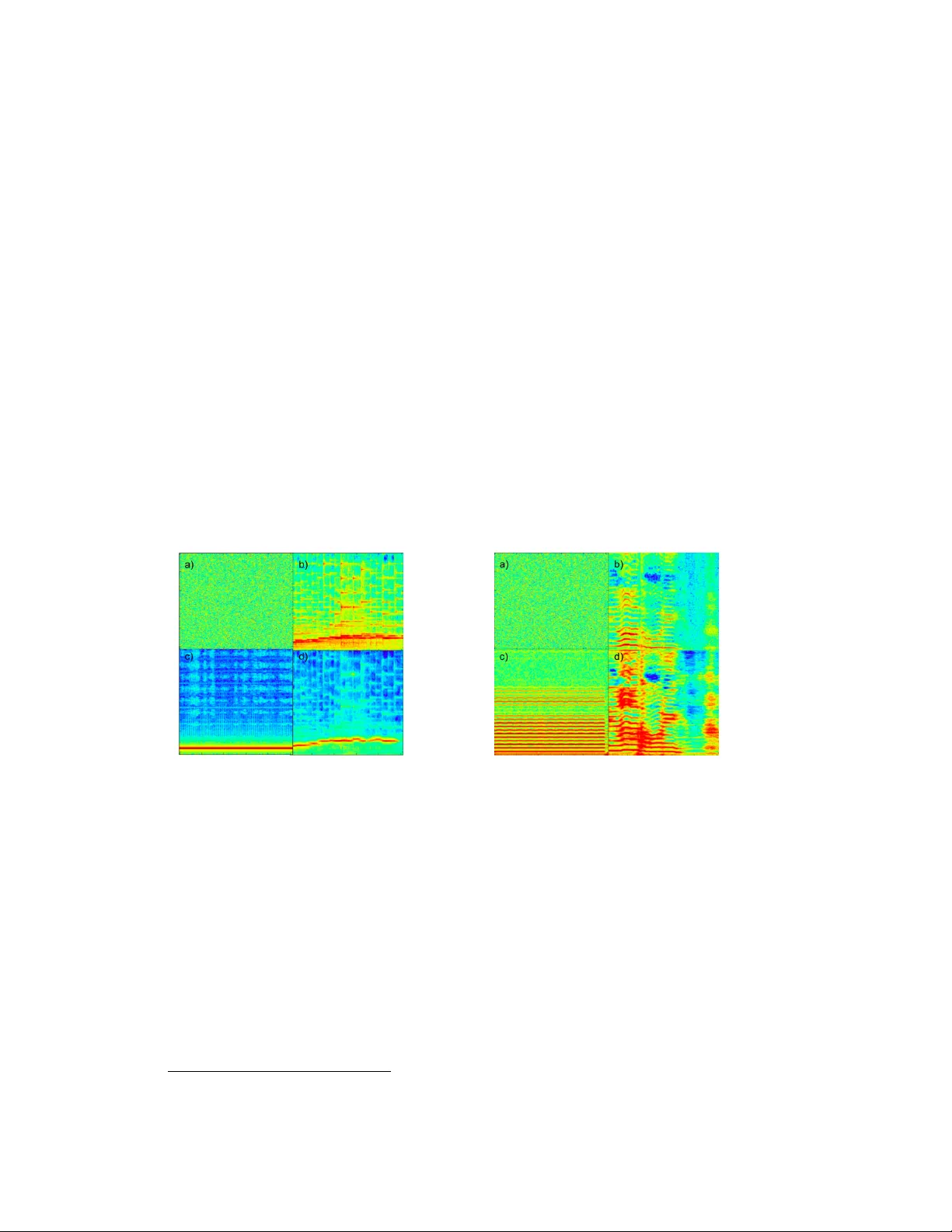
Neural Style T ransfer f or A udio Spectr ograms Prateek V erma, J ulius O. Smith Center for Computer Research in Music and Acoustics (CCRMA), Stanford Univ ersity prateekv@stanford.edu, jos@ccrma.stanford.edu Abstract There has been fascinating work on creating artistic transformations of images by Gatys et al. This was re volutionary in how we can in some sense alter the “style” of an image while generally preserving its “content”. In this work, we present a method for creating ne w sounds using a similar approach. For demonstration, we in vestigate tw o different tasks, resulting in bandwidth expansion/compression, and timbral transfer from singing voice to musical instruments. 1 Introduction W e present a new machine learning technique for generating music and audio signals. The focus of this work is to de velop ne w techniques parallel to what has been proposed for artistic style transfer for images by Gatys et al. [1]. W e present tw o cases of modifying an audio signal to generate ne w sounds. A feature of our method is that a single architecture can generate these dif ferent audio-style-transfer types using the same set of parameters which otherwise require comple x hand-tuned di verse signal processing pipelines. Finally , we propose and in v estigate generation of spectrograms from noise by satisfying an optimization criterion deri ved from features deriv ed from filter-activ ations of a con volutional neural net. The potential flexibility of this sound-generating approach is discussed. 2 Methodology There has been recent work applying architectures in computer vision for acoustic scene analysis. In particular , [3] uses standard architectures such as AlexNet, VGG-Net, and ResNet for sound understanding. The performance gains from the vision models are translated to the audio domain as well. The w ork in [2, 3] used a mel-filter-bank input representation, while we use Short-T ime Fourier T ransform (STFT) log-magnitude instead. W e desire a high-resolution audio representation from which perfect reconstruction is possible via, e.g., Griffin-Lim Reconstruction [7]. All experiments in this work use an audio spectrogram representation ha ving duration 2.57s, frame-size 30ms, frame-step 10ms, FFT -size 512, and audio sampling rate of 16kHz. The core of the success of neural style transfer for vision is to optimize the input signal, starting with random noise, to take on the features of interest deri ved from acti vations at dif ferent layers after the passing through a conv olutional net based classifier which was trained on the content of the input image. W e follow a similar approach, with some modifications for audio signals. First, we train a standard Ale xNet [5] architecture, but hav e a smaller recepti ve size of 3 × 3 instead of the lar ger receptiv e fields used in the original work. This is to retain the audio resolution, both along time and frequency , as larger recepti ve fields would yield poor localization in the audio reconstruction, which results in audible artifacts. W e also add additional loss terms in order to match the av eraged timbral and ener gy en velope. All applications here correspond to timbr e transfer of musical instruments having no e xplicit knowledge of features such as pitch, note onset time, type of instrument, and so on. The AlexNet was trained on audio spectograms to distinguish classes of musical instrument sounds ( 80 from AudioSet), with 3 × 3 con volutions and 2 × 2 pooling, having a total of 6 layers with objectiv e function minimizing the cross-entropy loss using the Adam optimizer [4]. 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA. 3 Experiments W e focus on two experiments: (1) imposing the style of a tuning fork on a harp, resulting in bandwidth compression do wn to the fundamental, and (2) transferring the style of a violin note to a singing v oice, resulting in bandwidth e xpansion. Thus, we hav e a new form of cross-synthesis imposing the style of one instrument on the content of another , with applications similar to [6]. W e e xplored various hyper-parameters and single/multiple layers from which we e xtract these features for optimization. The goal is to ha ve a single parameter setting that can perform all of these tasks, without ha ving to explicitly de velop hand-crafted rules. T raditionally there hav e been distinct signal processing based approaches to do such tasks. Subplots in Figs. 1-2 a)-d) are log-magnitude spectrograms with the y-axis 0-8kHz and x-axis 0-2.57s. Note in Fig. 2. how this approach not only changes the timbre, but also increases the bandwidth of the signal, as seen in the strength of the higher harmonics. The objectiv e equation below dri ves the reconstructed spectrogram X recon from random noise to be the spectra that minimizes the sum of weighted loss terms L c denoting the content loss (the Euclidean norm of the difference between the current activ ation filters and those of the content spectrogram), L s the style loss (which is the normalized Euclidean norm between the Gram matrix of filter acti v ations of selected conv olutional layers similar to [1] between X and X s ), and L e and L t which measure deviation in the temporal and frequency energy en v elopes respectiv ely from the style audio. W e found that matching the weighted energy contour and frequenc y energy contour (timbral en velope), namely e s and t s , av eraged over time in our loss function, helped in achie ving improved quality . The energy term in the loss function is required because the Gram matrix does not incorporate temporal dynamics of the target audio style, and w ould generally follow that of the content if not included. X recon = argmin X L total = ar gmin X αL c ( x, x c ) + β L s ( x, x s ) + γ L e ( x e , e s ) + δ L t ( x t , t s ) . Figure 1: a) sho ws the Gaussian noise from which we start the input to optimize, b) Harp sound (content) c) T uning Fork (style) and d) Neural Style transferred output with hav- ing content of harp and style of tuning fork https://youtu.be/UlwBsEigcdE Figure 2: a) sho ws the Gaussian noise from which we start the input to optimize, b) Singing sound (content) c) V iolin note (style) and d) Neural Style transferred output with having content of singing and style of violin. https://youtu.be/RpGBkfs24uc 4 Conclusion and Future W ork W e hav e proposed a novel way to synthesize audio by treating it as a style-transfer problem, starting from a random-noise input signal and iterati vely using back-propagation to optimize the sound to conform to filter-outputs from a pre-trained neural architecture. The two examples were intended to explore and illustrate the nature of the style transfer for spectrograms, and more musical examples are subjects of ongoing work. The flexibility of this approach, and the promising results to date indicate interesting future sound cross-synthesis methods. W e believe this work can be extended to many new audio synthesis/modification techniques based on new loss-term formulations for the problem of interest, and are excited to see and hear what lies ahead. 1 1 Acknowledgments: The authors would like to thank Andrew Ng’ s group and the Stanford Artificial Intelligence Laboratory for the use of their computing resources. Prateek V erma would like to thank Ziang Xie for discussion about challenges in the problem, and Alexandre Alahi for style transfer work in computer vision. 2 Refer ences 1. Gatys, Leon A., Alexander S. Ecker , and Matthias Bethge. "A neural algorithm of artistic style." arXiv preprint arXi v:1508.06576(2015). 2. Recommending music on Spotify with deep learning – Sander Dieleman benanne.github .io/2014/08/05/spotify-cnns.html 3. Hershey , Shawn, et al. "CNN architectures for lar ge-scale audio classification." Acoustics, Speech and Signal Processing (ICASSP), 2017 IEEE International Conference on. IEEE, 2017. 4. Kingma, Diederik, and Jimmy Ba. "Adam: A method for stochastic optimization." arXi v preprint arXiv:1412.6980 (2014). 5. Krizhevsk y , Alex, Ilya Sutske ver , and Geof frey E. Hinton. "Imagenet classification with deep con volutional neural networks." Adv ances in neural information processing systems. 2012. 6. V erma, Prateek, and Preeti Rao. "Real-time melodic accompaniment system for Indian music using TMS320C6713." VLSI Design (VLSID), 2012 25th International Conference on. IEEE, 2012. 7. Griffin, Daniel, and Jae Lim. "Signal estimation from modified short-time Fourier trans- form." IEEE T ransactions on Acoustics, Speech, and Signal Processing 32.2 (1984): 236- 243. 3
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment