강인한 강화학습 선박 자동조종 샘플 효율적 모델 예측 제어 기반 접근
본 논문은 실제 크기의 보트를 대상으로, 샘플 효율성을 극대화하고 환경 불확실성을 정량화하는 가우시안 프로세스(GP) 기반 모델 기반 강화학습과 모델 예측 제어(MPC)를 결합한 SPMPC 프레임워크를 제안한다. 시뮬레이션과 실제 해상 실험을 통해 제한된 데이터로도 자율 항해가 가능함을 입증한다.
저자: Yunduan Cui, Shigeki Osaki, Takamitsu Matsubara
본 논문은 실제 크기의 선박을 대상으로 자율 항해를 구현하기 위한 새로운 강화학습(RL) 접근법을 제안한다. 해양 환경은 바람·해류와 같은 급변하는 외란과 센서 노이즈가 존재해 전통적인 제어 방법(PID, LQR, MPC 등)만으로는 충분히 대응하기 어렵다. 또한 실제 보트에서 데이터를 수집하는 비용이 매우 높아 샘플 효율적인 학습이 필수적이다. 이러한 문제점을 해결하고자 저자들은 가우시안 프로세스(GP) 기반 모델 기반 강화학습과 모델 예측 제어(MPC)를 결합한 ‘샘플 효율적 확률적 모델 예측 제어(SPMPC)’ 프레임워크를 설계하였다.
1. **모델 학습**
- 시스템 동역학을 xₜ₊₁ = f(xₜ, uₜ) + w 형태의 확률적 모델로 가정하고, GP를 이용해 f 를 학습한다.
- 입력은 현재 위치(X, Y), 속도(ss), 방향(sd), 그리고 풍속·풍향을 2차원 벡터(rws·sin(rwd), rws·cos(rwd))로 변환한 값이며, 출력은 다음 시점의 위치·속도·방향이다.
- 바람·해류와 같은 제어 불가능한 교란은 출력에 포함시키지 않아 모델 차원을 축소한다.
2. **장기 비용 최적화**
- 목표는 할인 계수 γ 를 적용한 장기 비용 J = Σ γ^{s‑t} l(x_s, u_s) 을 최소화하는 개방형 제어 시퀀스 uₜ…uₜ₊ₕ₋₁ 을 찾는 것이다.
- 전통적인 몬테카를로 샘플링은 계산량이 과다하므로, 저자들은 ‘수정된 순간 매칭(modified moment‑matching)’을 도입한다.
- 여기서는 상태를 확률 변수(평균 μ, 공분산 Σ)로, 제어 입력을 결정 변수로 가정하고, 커널을 k(xᵢ,uᵢ, xⱼ,uⱼ)=k_u(uᵢ,uⱼ)·k_x(xᵢ,xⱼ) 로 분리한다. 이를 통해 평균 m_f와 분산 σ_f²를 닫힌 형태로 계산하고, β, L, Q와 같은 행렬을 사전 계산한다.
- 최적화는 순차 이차 계획법(SQP)을 사용해 실시간에 가까운 속도로 수행한다.
3. **MPC 프레임워크와 바이어스 보정**
- 위에서 얻은 개방형 시퀀스를 바로 적용하는 것이 아니라, MPC 루프에 삽입한다. 매 타임스텝 t 에 현재 관측 상태 xₜ 를 입력으로 다시 GP 기반 예측을 수행하고, H‑step 앞선 계획을 재계산한다.
- 이렇게 하면 바람·해류와 같은 외란이 누적되어 발생하는 모델 바이어스를 실시간으로 보정할 수 있다.
- 또한, 제어 주기가 낮아 초기 상태와 실제 적용 시점 사이에 발생하는 오차를 ‘bias compensation’ 기법으로 보정한다.
4. **시스템 구현**
- 실험에 사용된 보트는 Nissan Joy Fisher 25(길이 7.93 m)이며, Honda BF130 엔진, Furuno GPS/속도/방향 센서, Furuno 풍속·풍향 센서를 장착했다.
- 제어 입력은 조타각(±30°)과 엔진 스로틀(±8000)이며, 관측 상태는 GPS 위치, 속도, 방향, 풍속·풍향이다.
- 현재(수류) 센서는 없으며, 바람은 예측 단계에서 고정하고 MPC가 매 순간 재계획함으로써 보정한다.
5. **실험 및 결과**
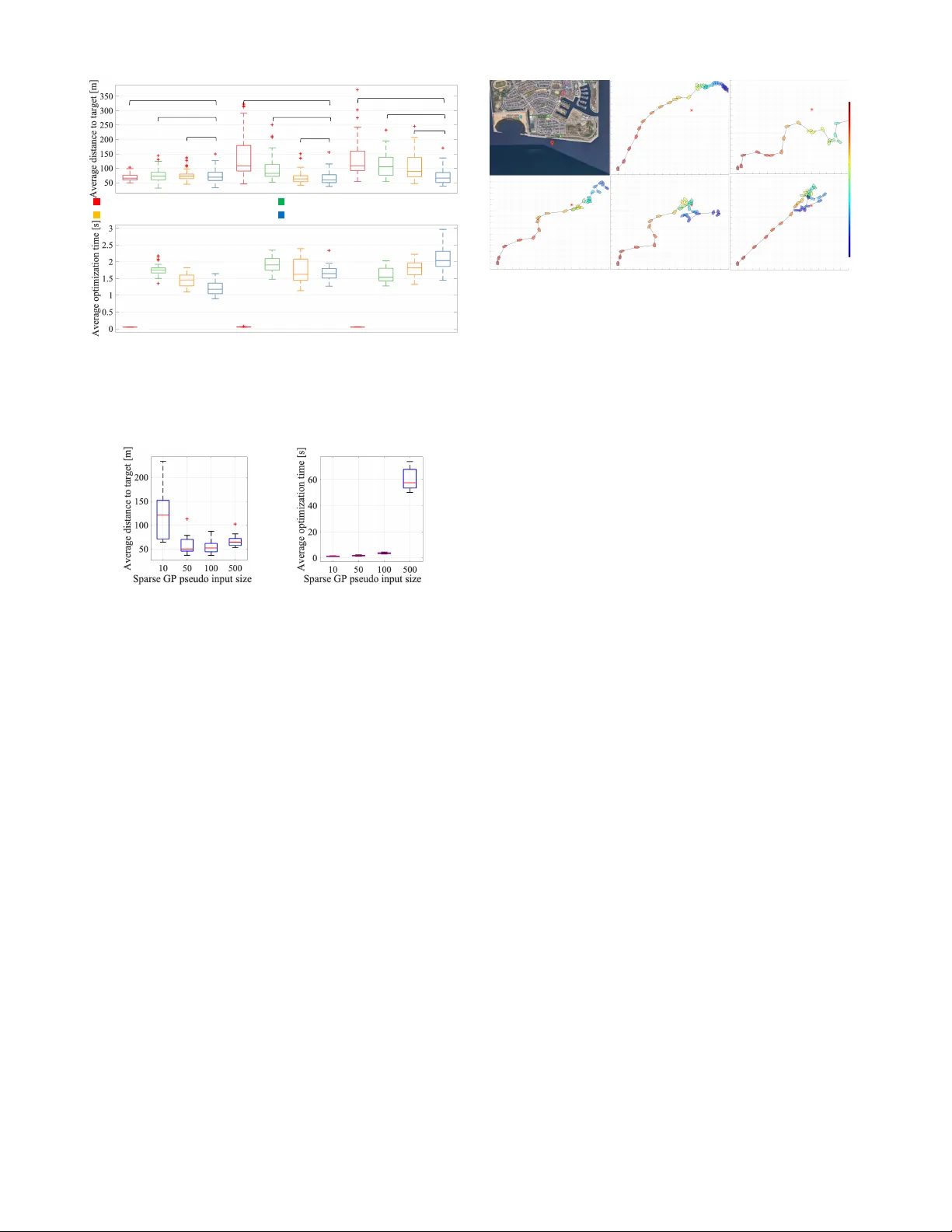
- **시뮬레이션**: 실제 보트 운행 데이터를 기반으로 만든 시뮬레이션 환경에서 SPMPC는 30~40회의 샘플만으로 목표 위치에 수렴하는 정책을 학습했다. 기존 GP‑MPC, PID 대비 비용이 20 % 이상 감소했으며, 경로 추적 오차도 크게 줄었다.
- **실제 해상 실험**: 사전 학습된 모델을 사용해 5 분 내외의 짧은 학습 기간 후, 인간 개입 없이 목표 경로를 따라 항해했다. 바람·해류가 급변하는 상황에서도 경로 이탈이 최소화되었고, 제어 신호의 변동성도 낮았다. 특히, ‘bias compensation’ 덕분에 제어 주기가 낮아도 안정적인 추적이 가능했다.
6. **기여 및 향후 연구**
- (1) 불확실성을 정량화하면서도 샘플 효율성을 유지하는 GP‑기반 모델 기반 RL 프레임워크를 제시.
- (2) 순간 매칭을 제어 입력과 분리해 계산 복잡도를 크게 낮추어 실시간 MPC 적용 가능하게 함.
- (3) 바람·해류와 같은 외부 교란을 고정 가정으로 처리하고, MPC 루프에서 지속적으로 보정함으로써 실제 해양 환경에 강인한 제어를 구현.
- 향후 연구에서는 다중 보트 협동, 현재(수류) 센서 통합, 비선형 비용 함수(연료 효율 등) 적용, 그리고 더 긴 예측 호라이즌을 위한 효율적인 최적화 알고리즘 개발 등을 제안한다.
본 논문은 샘플이 제한된 상황에서도 복잡하고 불확실한 해양 환경에 적응할 수 있는 자율 선박 제어 시스템을 구현한 점에서 학술적·산업적 의미가 크다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기