Reinforcement Learning Ship Autopilot: Sample efficient and Model Predictive Control-based Approach
In this research we focus on developing a reinforcement learning system for a challenging task: autonomous control of a real-sized boat, with difficulties arising from large uncertainties in the challenging ocean environment and the extremely high co…
Authors: Yunduan Cui, Shigeki Osaki, Takamitsu Matsubara
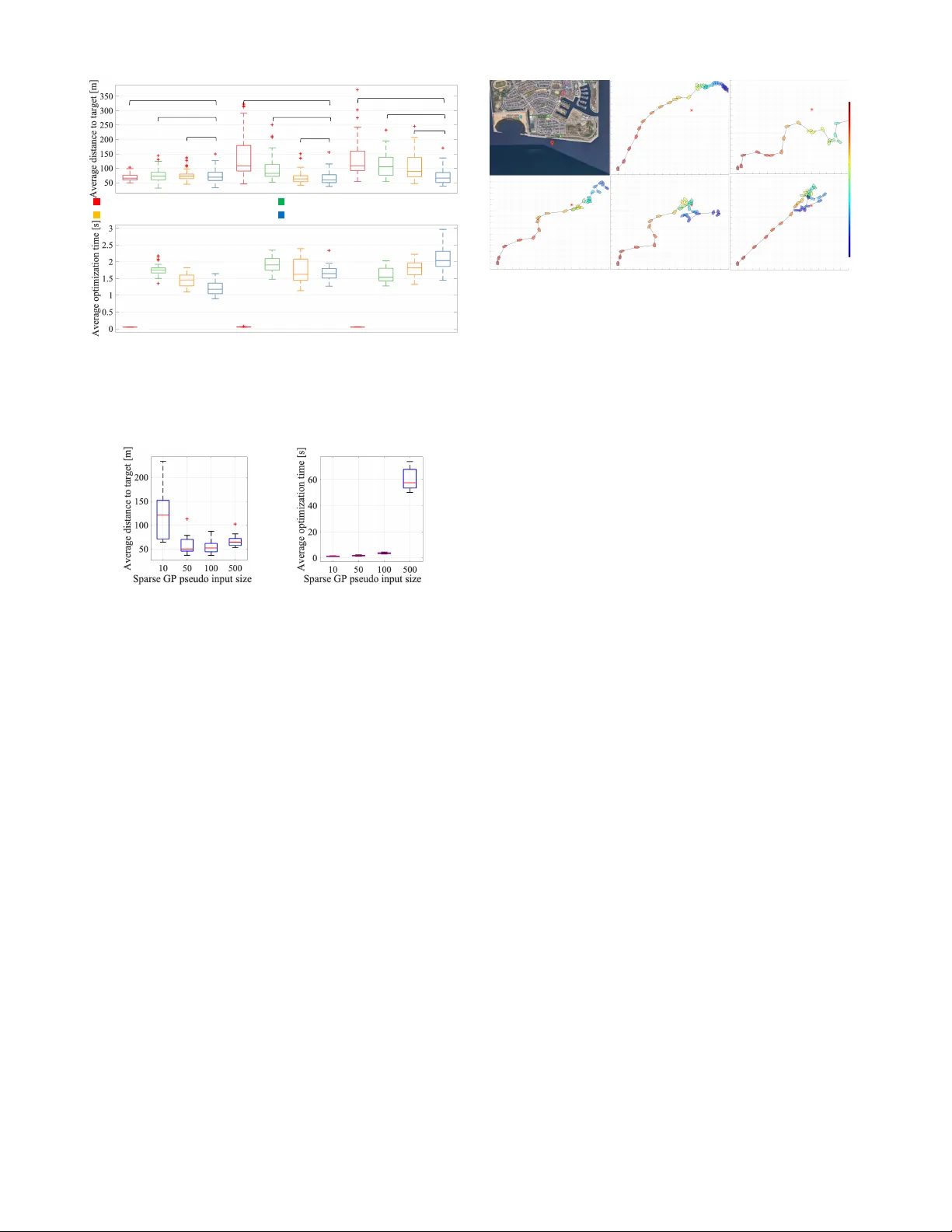
Reinf or cement Learning Boat A utopilot: A Sample-efficient and Model Pr edictive Contr ol based A ppr oach Y unduan Cui 1 , Shigeki Osaki 2 , and T akamitsu Matsubara 1 Abstract — In this resear ch we focus on de veloping a rein- for cement learning system f or a challenging task: autonomous control of a real-sized boat, with difficulties arising from large uncertainties in the challenging ocean en vironment and the extremely high cost of exploring and sampling with a real boat. T o this end, we explore a novel Gaussian pr ocesses (GP) based reinf orcement learning appr oach that combines sample-efficient model-based reinf orcement learning and model predicti ve con- trol (MPC). Our appr oach, sample-efficient probabilistic model predicti ve contr ol (SPMPC), iteratively learns a Gaussian pro- cess dynamics model and uses it to efficiently update control signals within the MPC closed control loop. A system using SPMPC is built to efficiently learn an autopilot task. After in vestigating its performance in a simulation modeled upon real boat driving data, the proposed system successfully learns to drive a r eal-sized boat equipped with a single engine and sensors measuring GPS, speed, direction, and wind in an autopilot task without human demonstration. I . I N T RO D U C T I O N Autonomous vehicles including smart cars and unmanned aircraft/watercraft form a rising field that not only brings beneficial changes to our transportation infrastructure such as relieving labor shortages, av oiding collisions, and providing assistance to humans [1], but also further enable ventures such as resource e xploration [2] and search and rescue [3]. On the other hand, it is arduous to obtain good control policies for such autonomous systems since preparing hu- man driving demonstrations encompassing a broad range of possible scenarios subject to different en vironmental settings is a prohibiti ve endeav our . Such difficulties make the use of reinforcement learning (RL) [4] an appealing prospect since RL provides a natural matter to autonomously discover optimal policies from unkno wn en vironments via trial-and- error interactions [5]. Even though RL has already been widely applied to both autonomous ground [6] and air [7] vehicles, its application to autonomous boats, or unmanned surface vehicles, remains relati vely limited [8] primarily due to: 1) Uncertainties in a dynamic ocean en vironment, e.g. frequently changing disturbances due to the unpre- dictable wind and current, signal noise, and hysteresis of onboard sensors, that strongly impact boat handling and dynamics. 2) The extremely high time cost of exploring and sam- pling with real boats. 1 Y . Cui and T . Matsubara are with the Division of Information Science, Graduate School of Science and T echnology , Nara Institute of Science and T echnology (NAIST), Japan 2 S. Osaki is with FURUNO ELECTRIC CO., L TD., Japan Fig. 1: The Nissan Joy Fisher 25 for experiment (left) with GPS/speed/direction sensor , engine (right top), and the wind sensor (right bottom). Recent works in this area mainly focused on traditional control methods including proportional inte gral deriv ati ve (PID) controllers [9], linear quadratic controller (LQR) [10], model predictiv e controllers (MPC) [11] and neural networks [12]. Howe ver these, to the best of the authors’ kno wledge, remain insuf ficient to driv e a real-sized boat in an open ocean en vironment without human assistance and demonstration. T o tackle the main difficulties of autonomous boats men- tioned above, an RL method should consider the large uncer- tainties from strong disturbance and noise while maintaining sample efficienc y . One potential solution is the combination of the model-based RL [13] and Gaussian processes (GP) [14] since model-based RL methods contrib ute to better data efficienc y than model-free ones by learning policies from a trained model instead of directly from the en vironment, GP is a po werful tool that naturally takes the model’ s uncertainties into account. A GP based actor-critic learning model was proposed in [15]. Martin et al. applied GP to temporal difference RL to underwater robot navigation in an indoor pool [16]. As one state-of-the-art model-based RL method, PILCO [17] reduces model bias by explicitly incorporating GP model uncertainty into planning and control. Assuming the tar get dynamics are fully controllable, it learns an optimal policy by a long-term planning at the initial state. Howe ver , applying PILCO to an autonomous boat is difficult due to the uncontrollable and unpredictable disturbances like the wind and current. A proper feedback control against these disturbances by re-planning is computationally demanding since a large number of parameters in a state-feedback policy are optimized, while ignoring them in the long-term planning may result in an accumulated model error and bad control performances. In this research we de velop a novel RL approach spe- cialized for autonomous boat control, specifically , automat- ically driving a real boat in an autopilot task. Our ap- proach, sample-efficient probabilistic model predicti ve con- trol (SPMPC), iterati vely learns a Gaussian process dynamics model to increase the robustness of control against sev eral unpredictable and frequently changing noises and distur- bances and ef ficiently optimizes control signals under a close-loop MPC to reduce the heavy computation cost of full-horizon planning in [17]. A system based on SPMPC is built to learn autopilot task with a real-size boat equipped with a single engine and sensors of GPS, speed, direction, and wind (Fig. 1). The results show the capability of the proposed approach in autonomous boats with both rob ustness to disturbances and sample efficienc y . Compared with prior works, the contributions of this paper are the follo wing: 1) Propose a sample-efficient, probabilistic model-based RL suitable for real boat control. 2) Build a learning control system with bias compensation for the boat autopilot task. Its capabilities are ev aluated in a simulation tuned with real boat dri ving data. 3) Conduct experimental validation of the system on a real-size boat in a real ocean en vironment. The remainder of this paper is organized as follows. Section II presents related works. Section III introduces SPMPC. Section IV details the RL system for autonomous boats. The results of simulation and real autopilot tasks are in Section V. Discussions follow in Section VI. I I . R E L A T E D W O R K S W illiams et al. [6] combined MPC with model-based RL and successfully implement it to autonomous ground vehicles. This work approximates the dynamics model by means of neural networks that are difficult to follow the fully Bayesian formalism. Thus, it would require a large number of samples for model learning and hyper -parameter selection. Cao et al. [18] proposed a GP model-based MPC controller to support state uncertainties in an unmanned quadrotor simulation control problem, utilizing a robust MPC controller which requires pre-collected training data to learn the GP model without self-exploration for data collection. Kamthe et al. [19] first extend PILCO to av oid the full- horizon planning in model-based RL by introducing MPC to moderate the real-time disturbances within a closed control loop. This work successfully sho ws its sample ef ficiency in cart-pole and double pendulum in simulation tasks without considering external disturbances. One potential limitation of [19] to wards real-world challenging control problems may be the relatively hea vy computational cost since its optimization is e xecuted with a dimensionality expanded deterministic dynamical system with Lagrange parameter and state con- straint under the Pontryagin’ s maximum principle (PMP). In this work, we focus on the RL system for real-w orld autonomous boats where state-constraints are less important in the currently focused problems, rather a simpler and more computationally ef ficient method would be desirable. Our proposed approach, SPMPC, has a certain similarity to the method in [19] with the follo wing features as adv antages for real boat autopilot: 1) By separating the uncertain state and deterministic con- trol signal in prediction (Section III-B), our approach directly optimizes the long-term cost with neither the expanded dynamics nor state constraints, therefore is more computationally efficient and suitable for real- world control problems. 2) Our approach employs bias compensation to com- pensate the bias, error between the initial states in the control plan and the actual ship before control ex ecution due to the relativ ely-low control frequency . I I I . A P P RO AC H In this section, we detail SPMPC. As a model-based RL, it stores the knowledge of the environment in a learned model (Section III-A). Its control polic y is made by combining the long-term optimization (Section III-B) and the MPC controller (Section III-C). Its RL loop follo ws: 1) Observe state and optimize control signals based on the model and polic y (long-term optimization + MPC) 2) Operate the control signal to the system, observe the next state and collect the sample 3) Update the model with all samples, return to 1) A. Model Learning In this w ork, a dynamical system is modeled by GP: x t +1 = f ( x t , u t ) + w , w ∼ N ( 0 , Σ w ) , (1) x ∈ R D is state, u ∈ R U is control signal, f is the unkno wn transition function, w is an i.i.d. system noise. Note that in this work the dimension of output state x t +1 can be smaller than input x t to handle uncontrollable states, e.g., wind, we assume the y all ha ve dimension D for the simplification of equations. Gi ven the training input tuples ˜ x t := ( x t , u t ) , and their training tar gets y t := x t +1 , for each target dimension a = 1 , ..., D , a GP model is trained based on the latent function y a t = f a ( ˜ x t ) + w a with a mean function m f a ( · ) and squared e xponential covariance kernel function: k a ( ˜ x i , ˜ x j ) = α 2 f a exp − 1 2 ( ˜ x i − ˜ x j ) T ˜ Λ − 1 a ( ˜ x i − ˜ x j ) , (2) where α 2 f a is the variance of f a , and ˜ Λ a is the diagonal matrix of training inputs’ length scales in kernel. The pa- rameters of GP model are learned by evidence maximization [14, 20]. Define ˜ X = [ ˜ x 1 , ..., ˜ x N ] as the training inputs set, Y a = [ y a 1 , ..., y a N ] as the collection of the training targets in corresponding dimension, k a, ∗ = k a ( ˜ X , ˜ x ∗ ) , k a, ∗∗ = k a ( ˜ x ∗ , ˜ x ∗ ) , K a i,j = k a ( ˜ x i , ˜ x j ) as the corresponding element in K a , and β a = ( K a + α 2 f a I ) − 1 Y a , the GP predictive distribution of a new input ˜ x ∗ follows: p ( f a ( ˜ x ∗ ) | ˜ X , Y a ) = N ( f a ( ˜ x ∗ ) | m f a ( ˜ x ∗ ) , σ 2 f a ( ˜ x ∗ )) , (3) m f a ( ˜ x ∗ ) = k T a, ∗ ( K a + α 2 f a I ) − 1 Y a = k T a, ∗ β a , (4) σ 2 f a ( ˜ x ∗ ) = k a, ∗∗ − k T a, ∗ ( K a + α 2 f a I ) − 1 k a, ∗ . (5) B. Optimization of an Open-loop Contr ol Sequence Define a one-step cost function l ( · ) , the next step is to search a multiple steps optimal open-loop control sequence u ∗ t , ..., u ∗ t + H − 1 that minimizes the expected long-term cost: [ u ∗ t , ..., u ∗ t + H − 1 ] = arg min u t ,..., u t + H − 1 t + H − 1 X s = t γ s − t l ( x s , u s ) , (6) where γ ∈ [0 , 1] is the discount factor . In general, including the model uncertainties in Eq. 6 is difficult since approximat- ing the intractable mar ginalization of model input by tradi- tional methods like Monte-Carlo sampling is computationally demanding, especially for each candidate of control sequence during optimization. As one solution, we utilize analytic mov ement matching [21, 22] that assumes a Gaussian model input and provides exact analytical expressions for the mean and v ariance. In this section, we propose a modified moment- matching to ef ficiently optimize the deterministic control sequence in Eq. 6 by separating the uncertain state and deterministic control in the prediction: [ µ t +1 , Σ t +1 ] = f ( µ t , Σ t , u t ) . (7) Based on the moment-matching [22], the proposed method starts by separating the kernel function in Eq. (2) by assum- ing the state and control signal are independent: k a ( x i , u i , x j , u j ) = k a ( u i , u j ) × k a ( x i , x j ) . (8) Define k a ( u ∗ ) = k a ( U , u ∗ ) and k a ( x ∗ ) = k a ( X , x ∗ ) , the mean and co variance related to Eqs. (4) and (5) then follows: m f a ( x ∗ , u ∗ ) = k a ( u ∗ ) × k a ( x ∗ ) T β a , (9) σ 2 f a ( x ∗ , u ∗ ) = k a ( u ∗ , u ∗ ) × k a ( x ∗ , x ∗ ) − ( k a ( u ∗ ) × k a ( x ∗ )) T ( K a + α 2 f a I ) − 1 ( k a ( x ∗ ) × k a ( u ∗ )) (10) where the element in K a is K a i,j = k a ( x i , x j ) × k a ( u i , u j ) and β a = ( K a + α 2 f a I ) − 1 Y a , X = [ x 1 , ..., x N ] and U = [ u 1 , ..., u N ] are the training inputs, Y a = [ y a 1 , ..., y a N ] is the training tar gets in corresponding dimension. Giv en the uncertain state x ∗ ∼ N ( µ , Σ ) and deterministic control signal u ∗ as inputs, the predicted mean follows: p ( f ( x ∗ , u ∗ ) | µ , Σ , u ∗ ) ≈ N ( µ ∗ , Σ ∗ ) , (11) µ a ∗ = β T a k a ( u ∗ ) Z k a ( x ∗ ) p ( x ∗ | µ , Σ ) d x ∗ = β T a l a . (12) For target dimensions a, b = 1 , ..., D , the predicted v ariance Σ aa ∗ and cov ariance Σ ab ∗ , a 6 = b follow: Σ aa ∗ = β T a Lβ a + α 2 f a − tr ( K a + σ 2 w a I ) − 1 L − µ 2 a ∗ , (13) Σ ab ∗ = β T a Qβ b − µ a ∗ µ b ∗ . (14) V ector l a and matrices L , Q has elements: l ai = k a ( u i , u ∗ ) Z k a ( x i , x ∗ ) p ( x ∗ | µ , Σ ) d x ∗ = k a ( u i , u ∗ ) α 2 f a | Σ Λ a + I | − 1 2 × exp − 1 2 ( x i − µ ) T ( Σ + Λ a ) − 1 ( x i − µ ) . (15) Boat trajectory MPC predicted trajectory Boat position Predicted position Uncertainty Current/wind disturbances Bias caused by long- term optimization Target Tim e Past Future Predic ted states with uncer tainty Observed states Target states Predic ted horiz on Predicted control sequence Previous control signals 𝑡 𝑡 + 𝐻 − 1 Fig. 2: Overall of the MPC framew ork. Left: The MPC framew ork. Right: the MPC framew ork with long-term pre- diction in autonomous boat control. L ij = k a ( u i , u ∗ ) k a ( u j , u ∗ ) k a ( x i , µ ) k a ( x j , µ ) | 2 Σ Λ − 1 a + I | 1 2 × exp ( z ij − µ ) T ( Σ + 1 2 Λ a ) − 1 Σ Λ − 1 a ( z ij − µ ) , (16) Q ij = α 2 f a α 2 f b k a ( u i , u j ) k b ( u i , u j ) | ( Λ − 1 a + Λ − 1 b ) Σ + I | − 1 2 × exp − 1 2 ( x i − x j ) T ( Λ a + Λ b ) − 1 ( x i − x j ) × exp − 1 2 ( z 0 ij − µ ) T R − 1 ( z 0 ij − µ ) (17) where Λ a is the diagonal matrix of training inputs length scales in k ernel k a ( x i , x j ) . z 0 and R are gi ven by: z 0 ij = ˜ Λ b ( Λ a + Λ b ) − 1 x i + Λ a ( Λ a + Λ b ) − 1 x j , (18) R = ( Λ − 1 a + Λ − 1 b ) − 1 + Σ t . (19) Compared with [19] that driv es a dimensionality expanded system in the moment-matching, our approach focused on simplifying the moment-matching with uncertain state and deterministic control signal to wards an efficient optimization. Giv en the cost function l ( · ) , prediction length H , initial con- trol sequence u 0 t , ..., u 0 t + H − 1 , and control constraints, any constrained nonlinear optimization method can search for the optimal control sequence to minimize the long-term cost in Eq. 6 where the future states and corresponding uncertainties in H − 1 steps are predicted by the modified moment- matching. In this work, sequential quadratic programming (SQP) [23] is used. C. Model Pr edictive Contr ol F ramework After obtaining the optimal H -step open-loop control trajectory u ∗ t , ..., u ∗ t + H − 1 by minimizing the long-term cost in Eq. 6 (Section III-B), the next step is to transfer this open-loop control sequence to an implicit feedback controller using the MPC framework [24]. As shown in the left side of Fig. 2 for each step t , given the current state x t , an optimal H -step open-loop control sequence is determined following Eq. 6 to minimize the long-term cost based on a H -step prediction using Eq. 7. The first control signal u ∗ t is then applied to the system and then get the next step state T ABLE I: The observed states and control parameters of our autonomous boat system Observed State Name Description From X The position in X axis GPS sensor Y The position in Y axis GPS sensor ss Boat speed Direction sensor sd Boat direction Direction sensor rws Relativ e wind speed wind sensor rwd Relativ e wind direction wind sensor Control Signal Name Description Range RR The steering angle [ − 30 , 30] ◦ Throttle The throttle value of engine [ − 8000 , 8000] Wind Sensor Engine Ste er GPS / Speed/Dir ecti on Sensor Communi cat ion Node MPC fr amework Boat System Obse rved State s Control Signal Autonomous System Gaussia n Processes Model Long- term Sta tes Predi cti on Cost Funct ion Fig. 3: The SPMPC System. x t +1 . An implicit closed-loop controller is then obtained by re-planning the H -step open-loop control sequence at each coming state. I V . A U T O N O M O U S B OA T C O N T RO L S Y S T E M In this section, the details of building a system specialized for real boat autopilot using the SPMPC are introduced. A. Autonomous Boat System As sho wn in Fig. 1, the proposed system was applied to a real Nissan JoyFisher 25 (length: 7.93 m, width: 2.63 m, height: 2.54 m) fitted with a single Honda BF130 engine and two sensors: a Furuno SC-30 GPS/speed/direction sensor and a Furuno WS200 wind sensor . As noted in T able I, observed states include the boat’ s current GPS position, speed, and direction from the direction sensor , and relative wind speed and direction from the wind sensor . The boat was not equipped with a current sensor . Control parameters are defined as the steering angle and engine throttle that respectiv ely control the boat’ s turning and linear velocity . There are two disturbances that strongly af fect the na vigation of our system in the real ocean: the unobservable ocean current and the observable but unpredictable wind. In this work, we b uild a SPMPC system based on our proposed approach to alle viate the effect of these disturbances. B. SPMPC System The ov erall autonomous system that applies SPMPC to autonomous boat control has three parts: training the GP model, predicting long-term states, and running the MPC framew ork. The GP model is trained follo wing Section III- A. Since the wind is an unpredictable and uncontrollable disturbance that strongly af fects the boat behaviors, the dimensions of input and output in the GP model are dif ferent. W e define the input states as x t = [ X t , Y t , ss t , sd t , r ws t × sin( r wd t ) , r ws t × cos( rw d t )] where the relative wind speed and direction are translated to a 2D v ector , the training tar gets as y t = [ X t +1 , Y t +1 , ss t +1 , sd t +1 ] . The control signal is defined as u t = [ RR t , thr ottle t ] . Additionally , the wind states in x s are fixed to their initial observ ation in x t when optimizing the control sequence in Eq. 6, i.e. we assume the wind is fix ed during the long-term prediction. The effects of disturbances from current and the assump- tion of fixed wind are alleviated by the MPC framework (Section III-C) in the SPMPC system. As shown in the right side of Fig. 2, to av oid accumulated prediction error , the SPMPC controller updates the state af fected by disturbances and re-plans a control sequence at e very step. Therefore, it iterativ ely makes the boat reaching the target ev en though the predicted trajectories (green arrow) are biased compared with the real one (yellow arro w) at each step. The complete workflo w is shown in Fig. 3. There is a software node to handle communications between the autonomous system and lower -lev el boat hardware interface. At each step t , this node first passes sensor readings to the autonomous system as the initial state following Section IV - B. The autonomous system searches a H -step control signal sequence that minimizes the long-term cost based on a H - step state prediction subject to constant wind states. The first control signal u ∗ t in the output sequence is sent to the hardware interface to control the steering and engine throttle. C. Bias Compensation for MPC In real-w orld applications, under the ef fect of the previous control signal u t − 1 which is continuously sent to the system during the process of Eq. 6, the state after obtaining u ∗ t , defined as x ∗ t , will be different to the state used for searching u t , defined as x 0 t . The bias b t = x ∗ t − x 0 t , sho wn as the purple arrows in the right side of Fig. 2, will worsen the controller’ s performance, especially when optimization is length y . There- fore, a bias compensation is required to mitigate this effect by predicting the boat’ s state after each optimization. Denoting the optimization time with t opt , we implement the bias compensation to predict position [ X bias , Y bias ] after t opt according to the boat’ s current position [ X , Y ] , speed ss and direction sd : X bias = X + ss × sin ( sd ) × t opt Y bias = Y + ss × cos ( sd ) × t opt (20) It will be used as the initial state in Eq. 6 to reduce the ef fect of the control signals during optimization. D. Learning Pr ocess Here we introduce the learning process of SPMPC system. Follo wing T able I, the GP model is initialized by N trial s × L rol lout samples with random actions as shown in lines 1-10 in Algorithm 1. At step j , the state x j is observed via the Algorithm 1: SPMPC for boat autopilot Input: N initial , N trial s , L rol lout , H , costF un Output: model 1 Function SPMPC( N initial , ..., costF un ) : 2 for i = 1 , 2 , ..., N initial do 3 ResetBoat() 4 for j = 1 , 2 , ..., L rol lout do 5 x j = ReadSensor() 6 u j = RandAct() 7 OperateActions( u j ) 8 y j = ReadSensor() 9 ˜ x j = ( x j , u j ) 10 ˜ X = { ˜ X , ˜ x j } , Y = { Y , y j } 11 model = TrainGP( ˜ X , Y ) 12 for i = 1 , 2 , ..., N trial s do 13 ResetBoat() 14 for j = 1 , 2 , ..., L rol lout do 15 x 0 = ReadSensor() 16 x ∗ = BiasComp( x 0 ) 17 u j = OptAct( x ∗ , H , model, costF un ) 18 x j = ReadSensor() 19 OperateActions( u j ) 20 [ y j ] = ReadSensor() 21 ˜ x j = ( x j , u j ) 22 ˜ X = { ˜ X , ˜ x j } , Y = { Y , y j } 23 model = TrainGP( ˜ X , Y ) 24 retur n model 25 End Function function ReadSensor(), and the random control signal u j is generated with RandAct(). After applying the control signal to the system, the tar get y j is observ ed. x j and y j are added to the GP model’ s training input/target sets. The next is the RL process (line 11 to 22), which runs N trial s rollouts to iterativ ely improve performance. At each step, the current state x 0 is first observed, and the state with bias compensation, x ∗ = [ X bias , Y bias ] follo wing Eq. 20 is predicted by BiasComp(). The control signal u j is calculated by Eq. 6 via function OptActions() where H is the MPC prediction step, costF un is the cost function for the acti vity being undertaken. The corresponding state and target are then observed and added to the training input/target sets. The GP model is updated after each rollout. V . E X P E R I M E N T S A. Simulation Experiments The SPMPC system is first in vestigated in a simulator dev eloped by FURUNO ELECTRIC CO., L TD following the state definition and the control constraints in T able I. It simu- lates feasible boat behaviors based on real driving data of the Nissan Joy Fisher 25 in the real ocean en vironment. In the simulation, we set an autopilot task in a 500 × 500 m 2 open area with arbitrary wind and ocean current. The objective is Euclide a n di stance base d cost functi on Mahal a nobis dist ance based cos t funct i on Fig. 4: Con ver gence of SPMPC with Euclidean-distance and Mahalanobis-distance based cost functions. to dri ve the boat from its initial position [0 , 0] to the target position P targ et = [400 , 250] and remain as close as possible. The states and actions are defined in T able I. In terms of en vironmental parameters, the wind and current directions follow a uniform distribution [ w d, cd ] ∼ U ( − 180 , 180) ◦ , wind speed w s ∼ U (0 , 10) m/s , and current speed cs ∼ U (0 , 1) m/s . At each step both wind and current slightly change to simulate an open oceanic environment follo wing [∆ w d, ∆ cd ] ∼ U ( − 0 . 1 , 0 . 1) ◦ , [∆ w s, ∆ cs ] ∼ U ( − 0 . 1 , 0 . 1) m/s . The control signal is operated ov er the course of 3 . 5 s, consisting of a 2 . 5 s operation time and 1 s optimization time t opt for bias compensation. Optimization stops when reaching its termination criteria, with the time taken recorded as an e v aluation criterion. 1) Cost Function Definition: T wo one-step cost functions in Eq. 6 are implemented to consider the ef fect of the predicted state’ s uncertain information in cost function. One is based on the Euclidean-distance between the predicted mean of boat position in the s -th step P s = [ X s , Y s ] and P targ et : l ( P s ) = 1 2 || P s − P targ et || 2 . (21) Another one is based on Mahalanobis-distance that considers both predicted mean and variance of boat position: l ( P s , Σ P s ) = 1 2 ( P s − P targ et ) T ˜ S ( P s − P targ et ) (22) where ˜ S = W − 1 ( I + Σ P s W − 1 ) − 1 , W is a diagonal matrix scaled by parameter 1 σ 2 c . W e set σ c = 1 in this experiment. Since the predicted v ariance in the previous step is required in Eqs. 12 and 13, both two cost functions can benefit from the uncertainty information in long-term prediction. 2) Evaluation of Learning P erformances: The first exper - iment is to in vestigate the con ver gence of SPMPC with the different type of cost function and the different number of samples av ailable. F ollowing Algorithm 1, we set the rollout length L rol lout = 50 and RL iterations N trial s = 10 . The MPC prediction horizon H = 5 , N initial = [1 , 5 , 10] , i.e. build the initial GP model with 50 , 250 , and 500 random samples, are tested. The random samples for initializing GP model are generated by randomly selecting control signal RR ∼ U ( − 30 , 30) ◦ and throttl e ∼ U ( − 8000 , 8000) at each step, under the random wind and current generated following Section V -A. Sparse GP [25] with 50 pseudo-inputs are utilized for efficient calculation. After each iteration, the GP model is tested in 10 independent rollouts. The discount factor is not such a sensitiv e parameter since the prediction horizon in SPMPC is set to be relativ ely short due to the large disturbances. In this experiment, we set γ = 0 . 95 . The learning performance was av eraged ov er 10 times ex- periments. A comparative baseline is conducted by applying two PID controllers for steering angle and throttle value of engine. The PID error is defined as the angle between boat head and the target, and the distance from boat to the target. The control frequency of PID controllers is set to 20 Hz, while SPMPC operates each action ov er 3 . 5 s, about 0 . 28 Hz. Both two PID controllers’ parameters were manually tuned to P = 1 . 0 , I = 0 . 1 , D = 0 . 1 based on its average performance on 1000 trials with the same environmental parameters above. Figure 4 shows the av erage distances to the tar get position in the last 20 steps of both SPMPC and baseline. Using the Euclidean-distance based cost function (Eq. 21), SPMPC con ver ged to better performances during RL process. As a comparison, SPMPC could not learn to improv e its perfor- mance using the Mahalanobis-distance based cost function (Eq. 22). One possible reason is the RL process needs to explore unkno wn states as similar as other RL methods. Us- ing the Mahalanobis-distance based cost function, the agent may av oid to transit to the states with large uncertainties and therefore learned a local minimum with poor control performance since the GP model initialized by a limited number of samples that could not suf ficiently explore enough states for achie ving the task. T urning to the successful learning result using the Euclidean-distance based cost function in Fig.4, when N initial = 1 , SPMPC iteratively improv ed its performance from 196 . 53 m to 72 . 20 m within 10 iterations to be close to the baseline’ s, 54 . 66 m , since the GP model initialized by few samples results in a poor exploration of RL. W ith more initial random samples, SPMPC accelerated the learning process to outperform the baseline, the av erage distance was to the target was decreased from 66 . 74 m to 29 . 4 m ( N initial = 5 ), 42 . 32 m to 27 . 79 m ( N initial = 10 ). Figure 5 gives e xamples of learning result of SPMPC and the baseline. Both the manually tuned baseline and the proposed method performed well under small disturbances. W ith larger disturbances, only the proposed method could successfully driv e the boat to the target. The PID controller could not reach and stay close to the target ev en with a higher control frequency than SPMPC due to its disability of handling disturbances. The model prediction accuracy was ev aluated by testing the model at each iteration on additional 40 rollouts with random control signals and wind, current settings ( L rol lout = Small disturbances , base line Initial ws = 2.73 m/s Initial cs = 0.16 m/s Small disturbances , SPMPC Initial ws = 2.73 m/s Initial cs = 0.16 m/s Large disturbances, SPMPC Initial ws = 7.05 m/s Initial cs = 0.75 m/s Large disturbances, baseline Initial ws = 7.05 m/s Initial cs = 0.75 m/s Target Start Target Start Target Start Target Start Step 1 Step 50 (a) Itera tion 10 Itera tion 1 Target 500 initial random samples RL explor a tion tr a jectories SPMPC, 500 init ia l samples Target (b) Fig. 5: Examples of (a) the baseline and SPMPC in simula- tion task (b) the RL exploration samples and initial samples 50 ). W ith 50 initial samples, SPMPC decreased the average prediction error (with 95% confidence interval) from 9 . 87 ± 15 . 55 m to 7 . 88 ± 11 . 21 m within 10 iterations. W ith 250 initial samples, the average error decreased from 6 . 65 ± 9 . 6 m to 6 . 35 ± 8 . 58 m . W ith 500 initial samples, the average error decreased from 6 . 29 ± 7 . 97 m to 6 . 26 ± 8 . 01 m . Although the prediction error reached a lower limit and stop decreasing with 500 initial samples due to the strong disturbances and bias described in Section IV, it is reasonable compared with the boat length in our simulation ( 7 . 9 m ). The first e xperiment empirically confirmed that using the Euclidean-distance based cost function, the proposed RL approach can con v erge over the iterations with a very limited number of samples, and achie ve better control performance than the baseline. It also indicated the importance of both initial samples and RL exploration in SPMPC. The number of initial samples af fects the model prediction accuracy and the quality of RL exploration. The RL process explores to collect samples that focus on reducing the task-specific cost function. As an example shown in Fig. 5b, the 500 initial samples gives the agent sufficient knowledge of dri ving behaviors. Then the RL process iteratively explores unkno wn states to finally achie ve the task. 3) The effect of SPMPC Settings: The second experiment is to ev aluate 1) whether the longer horizon contributes to better control results, 2) whether considering the uncertain- ties of predicted state, i.e. the boat position, velocity , and direction improv e performance in a challenging environment, 3) whether the bias compensation contributes to better con- trol performance. Four different configurations of SPMPC are compared: 1) H = 1 , variance on, bias compensation on 2) H = 5 , variance of f, bias compensation on 3) H = 5 , variance on, bias compensation of f 4) H = 5 , variance on, bias compensation on Most settings follow Section V -A.2 with Euclidean-distance based cost function. The max speeds of current are set to 0 ~ 10 m/s 0 ~ 1 m/s wind curr ent 0 ~ 10 m/s 0 ~ 2 m/s 0 ~ 10 m/s 0 ~ 3 m/s p = 0.71 p = 0.56 p < 0.001 H = 1, variance on, bias compensation on H = 5, variance off , bias compens ation off H = 5, variance on, bias compensation of f H = 5, variance on, bias compensation on p = 0.74 p = 0.16 p < 0.001 p < 0.001 p < 0.001 p = 0.002 Fig. 6: Control performance and optimization time ov er 50 tests with dif ferent settings. Fig. 7: The effect of sparse GP setting on control perfor- mance and optimization time. 1 , 2 , 3 m/s as a parameter of unobservable uncertainty . The experiment starts with N initial = 10 rollouts with random actions to train a GP model, followed by N trial s = 10 rollouts to iteratively update the GP model. The learned controller is tested with another 50 rollouts. The average distances to the target position and optimiza- tion times over L rol lout = 50 steps are sho wn in Fig. 6. Note that an average bias near 70 m is a good result since the start position is over 400 m f ar away to the target. All four settings worked well with a small current. On the other hand, configuration 4 outperformed others as the max current speed increased. The t-test result (with significance le vel α = 0.05) on different settings in Fig. 6 indicates that the long prediction horizon, uncertainty information (variance) in long-term prediction and bias compensation contribute to a significantly better and more rob ust control performance in a challenging ocean en vironment. On the other hand, searching each step control signal tak es approx. 0 . 05 s while long horizon prediction takes ov er 1 s . W ith the max current speed of 3 m/s , configuration 4 takes the longest time (approx 2 s ) per search to perform well. These results indicate the ability of SPMPC system to drive the boat to the target position with a high degree of sample efficienc y ( 1000 samples) and robustness in a challenging en vironment. 4) The effect of Sparse GP Pseudo-inputs: The last ex- Ashiya-hama 34°42’15.9” N 135°18’55.4”E (Google Maps) Test after learning Rollout 2 Target Start Rollout 5 Target Start Rollout 7 Target Start Rollout 10 Target Start Step 1 Step 30 Target Start Fig. 8: The area for real experiment, routes of the real boat during the RL process and an e xample trial after learning periment is to inv estigate the effect of the sparse GP , i.e. the trade-of f between control performance and computational efficienc y . W e take configuration 4 (fiv e step prediction, support variance, and bias compensation) with 10 , 50 , 100 and 500 sparse GP pseudo-inputs and set the max current speed to 2 m/s , N rol lout = 10 and N trial s = 10 . The learned GP model is tested with another 10 rollouts. According to Fig. 7, 50 pseudo-inputs performs slightly worse (average 121 . 03 m v .s. 64 . 46 m ) than 500 pseudo- inputs b ut is far faster (average 1 . 55 s v .s. 57 . 57 s ). This result indicate the potential of efficiently running SPMPC with sparse GP . B. Real Experiments In this section, we apply SPMPC system to a real boat autopilot task. All hardware (Sec. IV -A) was provided by FUR UNO ELECTRIC CO., L TD. States and actions in this experiment are defined in T able I. The e xperimental area is Ashiya-hama, Ashiya, Hyogo, Japan ( 34 ◦ 42 0 15 . 9 00 N 135 ◦ 18 0 55 . 4 00 E, left top of Fig. 8) with the corresponding weather conditions: cloudy , current speed 0 . 0 ∼ 0 . 2 m/s , current direction 45 ◦ , w ave height 0 . 3 ∼ 0 . 5 m , wind speed 2 m/s , wind direction 135 ◦ . This weather information is av eraged over a large area, while in reality both wind and current experienced by the boat continuously change as it trav erses through. For the autopilot task, one rollout is defined as L rol lout = 30 steps. It started from the initial position [0 , 0] with initial orientation close to 0 ◦ . The objecti ve is to reach [100 , 100] and remain as close as possible. At each step, the control signal w as operated for around 7 s, including 5 s operation time and 2 s optimization time t opt (unlike in the simulation, the real optimization time here w as strictly limited to t opt ). The GP model was initialized by N initial = 10 random rollouts. Then N trial = 10 rollouts were applied in the RL process. The SPMPC settings were H = 5 , variance on and bias compensation on, with the Euclidean-distance based cost function and Sparse GP (50 pseudo-inputs). During the RL process, the SPMPC system successfully learned to reach the target position within 20 steps and attempted to remain near that position against disturbances from the real ocean en vironment. Se veral route maps during RL process are shown in Fig. 8. One example of SPMPC with 10 rollouts learning is shown in the right bottom of Fig. 8 1 . W ith a total 600 steps samples ( 50% from random sam- pling and 50% from RL), the boat reached the target position and stay within 30 steps (about 3 . 5 minutes). These results indicate the proposed system is able to accomplish the real- sized boat autopilot task in a real ocean en vironment. W ithout any human demonstration, the RL process iterati vely learned a rob ust MPC controller resilient to strong disturbances such as wind and current, with a high de gree of sample efficienc y and reasonable calculation times. V I . D I S C U S S I O N A N D F U T U R E W O RK This work presents SPMPC, an RL approach specialized for autonomous boat which is challenging due to the strong and unpredictable disturbances in the ocean environment and the extremely high cost of getting learning samples with the real boat. SPMPC combines the model-based RL, GP model and MPC framework together to naturally handle the real-time ocean uncertainties with the efficiency of both calculation and sampling. A system based on SPMPC is successfully applied it to the autopilot task of a real-size boat in both simulation and real ocean environment with not only robustness to disturbances but also great sample efficienc y and quick calculation with a limited computational resource. For the future w ork, we will compare the proposed method with related work [19] to further inv estigate its efficiency in simulation and the real ocean. Since multiple GP models are trained for each target dimension in our present setting following [17], it may be beneficial to apply the multi- dimensional output GP [26] that reduces the computational complexity of training, multiple models since the control frequency in the proposed system is limited due to the trade- off between optimization quality and computational com- plexity . Because the current system is dev eloped in Matlab (autonomous system) and Labvie w (boat hardware interface), general computational bottlenecks could be improved by moving to C++ and CUDA for future dev elopments. W e also believ e that the performance of our system would be improv ed by the addition of a suitable current sensor . An- other topic of interest is to directly learn expert dri ving skills by building a GP model-based on human demonstrations, to potentially achieve a more human-like autonomous driving. R E F E R E N C E S [1] D. J. Fagnant and K. Kock elman, “Preparing a nation for autonomous vehicles: opportunities, barriers and policy recommendations, ” T rans- portation Research P art A: P olicy and Practice , vol. 77, pp. 167–181, 2015. [2] T . Pastore and V . Djapic, “Improving autonomy and control of au- tonomous surface vehicles in port protection and mine countermeasure scenarios, ” Journal of Field Robotics , vol. 27, no. 6, pp. 903–914, 2010. [3] T . T omic, K. Schmid, P . Lutz, A. Domel, M. Kassecker , E. Mair , I. L. Grixa, F . Ruess, M. Suppa, and D. Burschka, “T oward a fully autonomous UA V: Research platform for indoor and outdoor urban search and rescue, ” IEEE robotics & automation magazine , vol. 19, no. 3, pp. 46–56, 2012. 1 video is av ailable at https://youtu.be/jOpw2cFP0mo [4] R. S. Sutton and A. G. Barto, Reinforcement learning: An introduction . MIT press Cambridge, 1998. [5] J. Kober , J. A. Bagnell, and J. Peters, “Reinforcement learning in robotics: A surv ey , ” The International Journal of Robotics Researc h , vol. 32, no. 11, pp. 1238–1274, 2013. [6] G. W illiams, N. W agener, B. Goldfain, P . Drews, J. M. Rehg, B. Boots, and E. A. Theodorou, “Information theoretic MPC for model-based reinforcement learning, ” in International Conference on Robotics and Automation (ICRA) , pp. 1714–1721, 2017. [7] L. D. Tran, C. D. Cross, M. A. Motter , J. H. Neilan, G. Qualls, P . M. Rothhaar , A. T rujillo, and B. D. Allen, “Reinforcement learn- ing with autonomous small unmanned aerial vehicles in cluttered en vironments, ” in A viation T echnolo gy , Inte gration, and Operations Confer ence , p. 2899, 2015. [8] Z. Liu, Y . Zhang, X. Y u, and C. Y uan, “Unmanned surf ace vehicles: An overvie w of developments and challenges, ” Annual Reviews in Contr ol , v ol. 41, pp. 71–93, 2016. [9] W . Naeem, G. W . Irwin, and A. Y ang, “Colregs-based collision av oidance strategies for unmanned surface vehicles, ” Mechatr onics , vol. 22, no. 6, pp. 669–678, 2012. [10] E. Lefeber, K. Y . Pettersen, and H. Nijmeijer, “Tracking control of an underactuated ship, ” IEEE transactions on control systems technology , vol. 11, no. 1, pp. 52–61, 2003. [11] A. S. Annamalai, R. Sutton, C. Y ang, P . Culverhouse, and S. Sharma, “Robust adapti ve control of an uninhabited surface vehicle, ” Journal of Intellig ent & Robotic Systems , vol. 78, no. 2, pp. 319–338, 2015. [12] Z. Peng, D. W ang, Z. Chen, X. Hu, and W . Lan, “ Adaptive dynamic surface control for formations of autonomous surface v ehicles with un- certain dynamics, ” IEEE T ransactions on Contr ol Systems T echnolo gy , vol. 21, no. 2, pp. 513–520, 2013. [13] A. S. Polydoros and L. Nalpantidis, “Survey of model-based rein- forcement learning: Applications on robotics, ” Journal of Intelligent & Robotic Systems , v ol. 86, no. 2, pp. 153–173, 2017. [14] C. E. Rasmussen and C. K. Williams, Gaussian processes for machine learning , v ol. 1. MIT press Cambridge, 2006. [15] M. Ghav amzadeh, Y . Engel, and M. V alko, “Bayesian polic y gradient and actor-critic algorithms, ” The Journal of Machine Learning Re- sear ch , v ol. 17, no. 1, pp. 2319–2371, 2016. [16] J. Martin, J. W ang, and B. Englot, “Sparse g aussian process temporal difference learning for marine robot navigation, ” in CoRL , 2018. [17] M. P . Deisenroth, D. Fox, and C. E. Rasmussen, “Gaussian processes for data-efficient learning in robotics and control, ” IEEE T ransactions on P attern Analysis & Machine Intelligence , v ol. 37, no. 2, pp. 408– 423, 2013. [18] G. Cao, E. M.-K. Lai, and F . Alam, “Gaussian process model pre- dictiv e control of an unmanned quadrotor , ” Journal of Intelligent & Robotic Systems , vol. 88, no. 1, pp. 147–162, 2017. [19] S. Kamthe and M. Deisenroth, “Data-efficient reinforcement learning with probabilistic model predicti ve control, ” in International Confer- ence on Artificial Intelligence and Statistics , pp. 1701–1710, 2018. [20] D. J. MacKay , Information theory , infer ence and learning algorithms . Cambridge uni versity press, 2003. [21] A. Girard, C. E. Rasmussen, J. Q. Candela, and R. Murray-Smith, “Gaussian process priors with uncertain inputs application to multiple- step ahead time series forecasting, ” in Advances in neural information pr ocessing systems , pp. 545–552, 2003. [22] M. P . Deisenroth, M. F . Huber , and U. D. Hanebeck, “ Analytic moment-based Gaussian process filtering, ” in the annual international confer ence on machine learning , pp. 225–232, 2009. [23] J. Nocedal and S. J. Wright, “Sequential quadratic programming, ” Numerical optimization , pp. 529–562, 2006. [24] D. Q. Mayne, J. B. Rawlings, C. V . Rao, and P . O. Scokaert, “Constrained model predictiv e control: Stability and optimality , ” A u- tomatica , v ol. 36, no. 6, pp. 789–814, 2000. [25] E. Snelson and Z. Ghahramani, “Sparse Gaussian processes using pseudo-inputs, ” in Advances in neural information processing systems , pp. 1257–1264, 2006. [26] M. ´ Alvarez, D. Luengo, M. T itsias, and N. Lawrence, “Efficient multioutput gaussian processes through variational inducing kernels, ” in International Confer ence on Artificial Intelligence and Statistics , pp. 25–32, 2010.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment