피크 타임을 앞서 잡는 온디맨드 영상 디스패치용 엔드‑투‑엔드 학습 네트워크
본 논문은 영상 수요가 급증하는 피크 시간대에 대비해, 오프‑피크에 CDN에 미리 인기 영상을 배치하는 시스템을 제안한다. 비디오를 자동 인코더 기반 클러스터링으로 압축하고, 공유된 시계열 레이어(CNN + GRU)로 요청 패턴을 학습한 뒤, 클러스터별 디스패치 확률을 예측한다. 엔드‑투‑엔드 학습으로 전체 파이프라인을 최적화했으며, 실제 Bilibili 데이터에서 기존 기준 대비 피크 예측 정확도를 3 %에서 17 %로 크게 향상시켰다.
저자: Damao Yang, Sihan Peng, He Huang
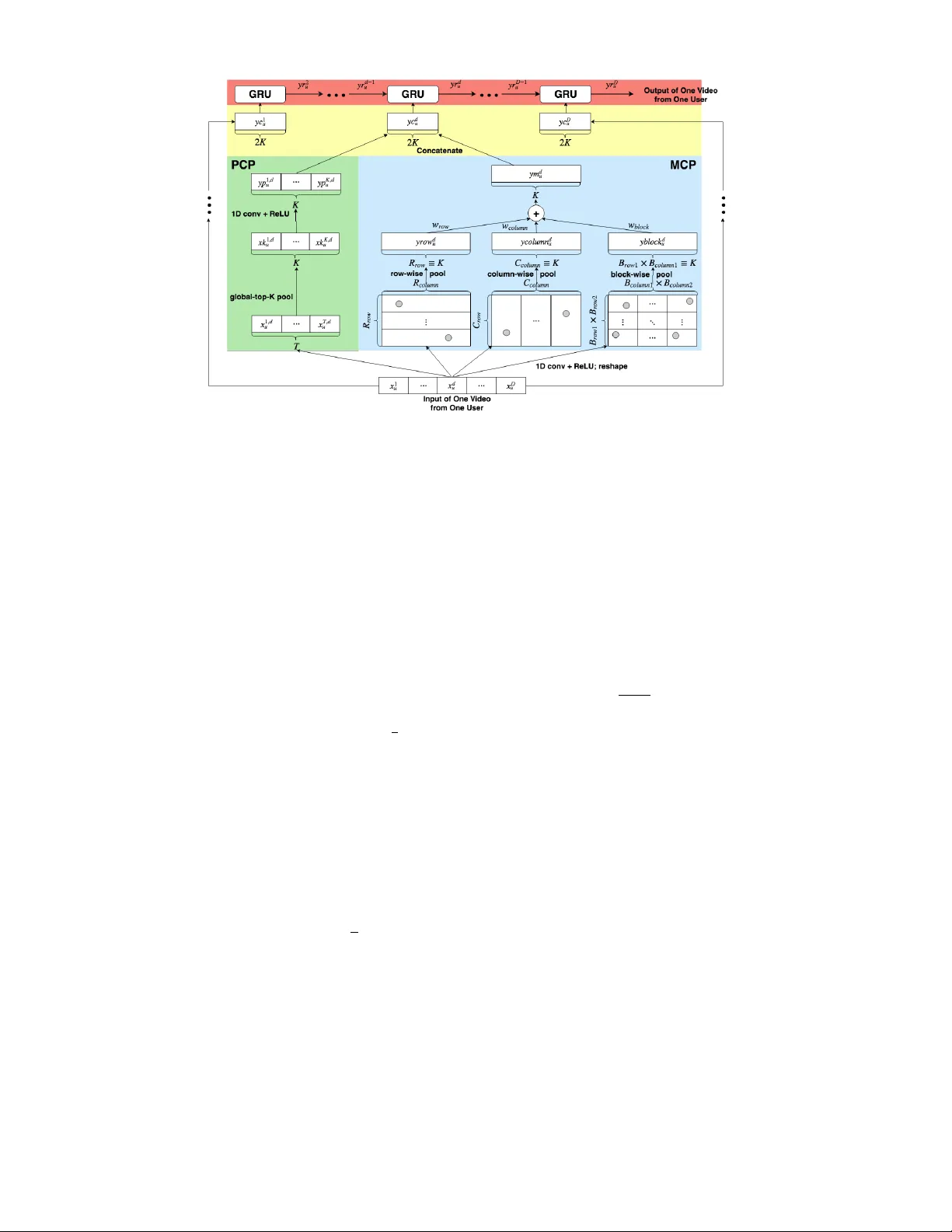
본 논문은 비디오 온디맨드(VOD) 서비스에서 피크 시간대의 트래픽 급증을 완화하기 위해, 오프‑피크에 미리 인기 영상을 CDN에 배치하는 디스패치 시스템을 설계하고 평가한다. 현재 Bilibili와 같은 대형 플랫폼은 영상 수가 수천만 개에 달하고, 각 CDN은 약 80만 개 영상만 저장할 수 있으며, 일일 전송량도 제한적이다. 이러한 상황에서 기존의 디스패치 정책은 “최근 일정 기간 동안 요청 횟수가 임계값을 초과하면 즉시 디스패치”하는 단순 규칙에 의존한다. 이 방식은 (1) 피크와 오프‑피크 사이의 요청 패턴 차이를 반영하지 못하고, (2) 짧은 메모리만 활용해 장기적인 수요 변동을 포착하지 못한다는 한계가 있다. 결과적으로 피크 시간대의 서비스 품질(r_peak)은 낮은 수준에 머물렀다.
이를 해결하기 위해 저자들은 두 개의 신경망을 결합한 엔드‑투‑엔드 학습 프레임워크를 제안한다. 첫 번째 네트워크는 “클러스터링 네트워크”로, 대규모 영상 집합을 고정된 수의 클러스터로 압축한다. 입력은 각 영상에 대해 사용자별·시간대별·일별 요청 시퀀스로 구성된 5분 간격 데이터이며, 차원은 12 분 × 24 시간 × 15 일 × 177 사용자≈764 640이다.
클러스터링 네트워크는 크게 세 부분으로 나뉜다.
1) **시계열 레이어**: CNN과 GRU를 결합한다. CNN은 두 개의 병렬 경로를 갖는다. ‘Peak Convolutional Part(PCP)’는 전체 요청량을 기준으로 top‑K 풀링을 수행한 뒤 1D 컨볼루션을 적용해 피크 구간의 특성을 강조한다. ‘Mean Convolutional Part(MCP)’는 전체 평균을 그대로 1D 컨볼루션에 통과시켜 비피크 구간을 포착한다. 두 경로의 출력은 2D 형태로 재구성되어 행·열·블록 별 2D 맥스 풀링을 거쳐 가중합된 특징 벡터 C_d,u를 만든다. 이후 GRU가 일별 순서를 입력받아 장기 의존성을 학습하고, 최종적으로 사용자 u에 대한 시계열 특징 R_D,u를 산출한다.
2) **자동 인코더(AE) 기반 클러스터링 레이어**: 정규화된 시계열 특징 N_T(v)를 L2 정규화 후, 완전 연결 AE를 통해 2차원 잠재공간 E(v)로 압축한다. 압축된 좌표는 사전에 정의된 계층적 블록 B_2(히에라키컬 클러스터) 안에 매핑된다. 블록은 균등 구간 분할을 반복해 || 개수의 클러스터를 생성한다. 이 방식은 미니배치 학습 및 분산 환경에서도 클러스터 인덱스가 일관되게 유지되도록 설계되었다.
3) **손실 함수**: 재구성 오차(‖N_T(v)‑D(v)‖²)와 클러스터 중심과의 거리 오차(‖E(v)‑O_b‖²)를 가중합한 형태이며, ω 파라미터로 두 항목의 비중을 조절한다.
두 번째 네트워크는 “정책 네트워크”이며, 클러스터링 결과를 입력으로 받아 각 클러스터‑CDN(또는 클러스터‑사용자) 쌍에 대한 디스패치 확률을 예측한다. 정책 네트워크 역시 동일한 시계열 레이어를 공유함으로써, 클러스터링 단계와 정책 단계가 동일한 시계열 특징에 기반하도록 만든다. 구체적으로, 클러스터 c에 대한 누적 입력 X_Ac를 정규화하고 시계열 레이어를 통과시켜 T(c)를 얻는다. 완전 연결층을 거쳐 0‑1 사이의 확률 벡터 U_P(c) (|U| 차원)를 출력하고, 실제 D+1일의 요청량 R(c)와의 L2 손실을 최소화한다.
전체 학습은 클러스터링 손실과 정책 손실을 동시에 역전파하는 방식으로 진행된다. 이렇게 함으로써 클러스터링 단계가 정책 목표(피크 시점 정확도)를 직접 고려하도록 만들었다는 점이 핵심이다.
**실험 설정**
- 데이터: Bilibili 실제 로그, 177명의 사용자, 15일(5분 간격) 기록, 총 5천만 개 영상 중 8.9 백만 개가 피크 2시간 동안 요청됨.
- 전처리: 비정상성을 감소시키기 위해 1차 차분 후 KPSS 테스트 수행, 비정상성 존재 확인.
- 평가 지표: 전체 디스패치 수 대비 피크 요청을 맞춘 비율(r_peak)과 전체 요청 대비 디스패치 성공률(r_whole).
**결과**
동일한 디스패치 양(예: 하루 30 천 영상) 기준으로, 기존 임계값 기반 방법은 r_peak≈3 %에 그쳤으나, 제안 모델은 r_peak≈17 %를 달성했다. 이는 피크와 오프‑피크 간의 비선형 관계를 효과적으로 학습하고, 클러스터 단위로 확장 가능한 정책을 제공함을 의미한다. 또한, 클러스터링 단계에서 영상 수를 고정된 클러스터 수(수천 개)로 압축함으로써, 실제 운영 환경에서의 계산·메모리 비용을 크게 절감할 수 있었다.
**기여 정리**
1. 클러스터링과 디스패치 정책을 하나의 엔드‑투‑엔드 프레임워크로 결합, 공동 최적화.
2. 피크와 전체 일일 패턴을 동시에 포착하는 CNN + GRU 기반 시계열 레이어 설계.
3. 자동 인코더와 계층적 블록을 이용한 대규모 영상 집합의 일관된 클러스터링 방법 제안.
4. 실제 대규모 VOD 서비스에서 피크 서비스 품질을 현저히 개선한 실증 결과 제공.
이 논문은 대규모 스트리밍 서비스가 직면한 “무한히 늘어나는 콘텐츠와 제한된 캐시·전송 자원”이라는 딜레마를 딥러닝 기반의 데이터‑주도 접근으로 해결한 사례로, 향후 CDN 캐시 관리, 사전 예측 기반 컨텐츠 배포 등에 널리 적용될 가능성이 높다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기