On-Demand Video Dispatch Networks: A Scalable End-to-End Learning Approach
We design a dispatch system to improve the peak service quality of video on demand (VOD). Our system predicts the hot videos during the peak hours of the next day based on the historical requests, and dispatches to the content delivery networks (CDNs…
Authors: Damao Yang, Sihan Peng, He Huang
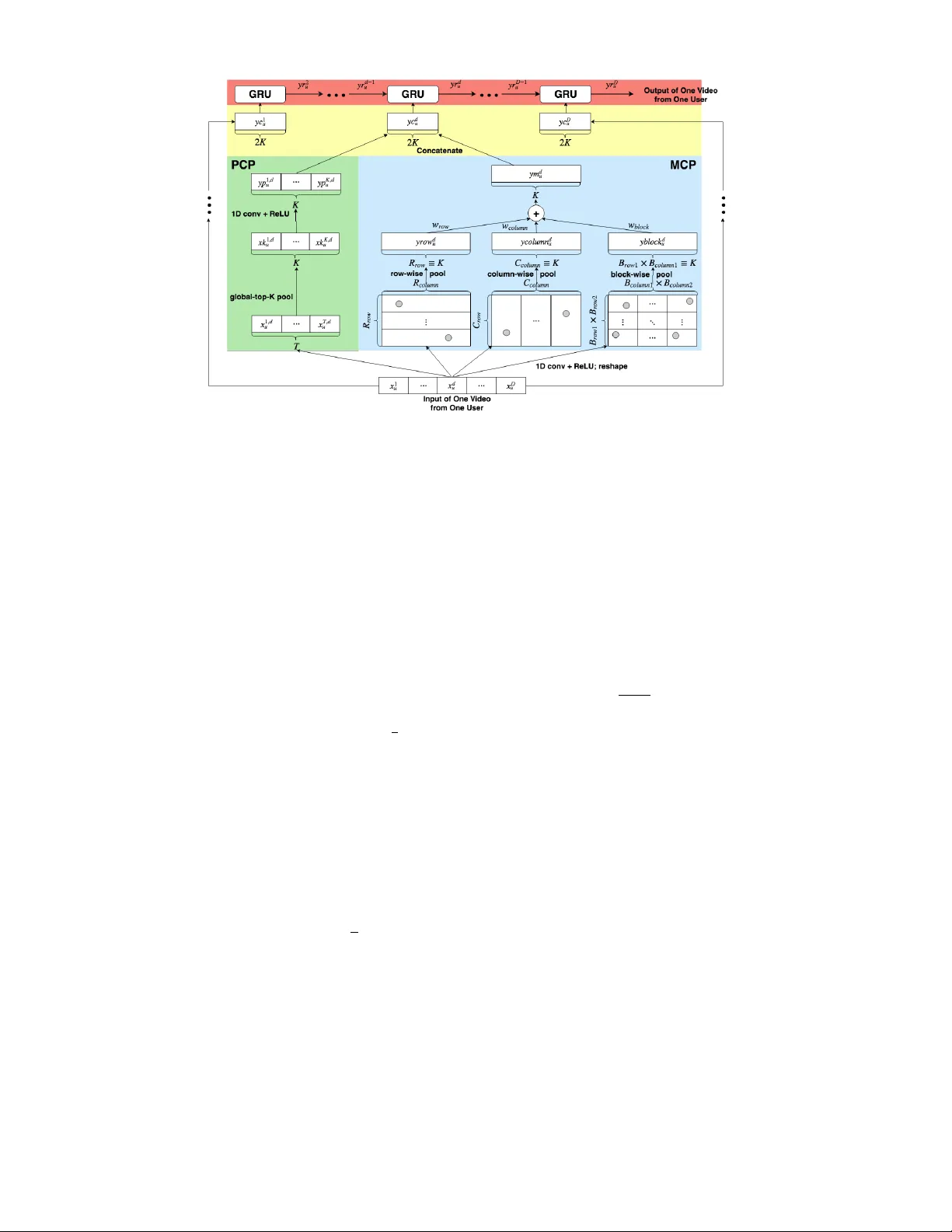
On-Demand V ideo Dispatch Networks: A Scalable End-to-End Learning Approach Damao Y ang Bilibili Inc. yangdamao@bilibili.com adrian.y .dm@gmail.com Sihan Peng NYU Shanghai sp4059@nyu.edu He Huang Purdue Univ ersity hhuang1206@gmail.com Hongliang Xue Cornell Univ ersity xuehongliang518@gmail.com Abstract W e design a dispatch system to improve the peak service quality of video on demand ( V OD ). Our system predicts the hot videos during the peak hours of the next day based on the historical requests, and dispatches to the content delivery networks ( CDN s) at the previous off-peak time. In order to scale to billions of videos, we build the system with two neural networks, one for video clustering and the other for dispatch policy developing. The clustering network employs autoencoder layers and reduces the video number to a fixed value. The policy network employs fully connected layers and ranks the clustered videos with dispatch probabilities. The tw o networks are coupled with weight-sharing temporal layers, which analyze the video request sequences with conv olutional and recurrent modules. Therefore, the clustering and dispatch tasks are trained in an end-to-end mechanism. The real-world results show that our approach achiev es an average prediction accuracy of 17%, compared with 3% from the present baseline method, for the same amount of dispatches. I . I N T RO D U C T I O N A N D R E L AT E D W O R K A typical architecture of Internet V OD is depicted in Figure 1(a). Giv en the knowledge of the relation between users and videos as well as of the relation between users and CDNs, one key issue as Figure 1(b) is to dispatch videos to CDNs. Improper dispatches cause poor video service qualities. It is noticed that fi ve main challenges occur with the emerging popularity of V OD: (1) large video amount (currently 50 million) compared with limited storage capacity (800,000 videos per CDN on av erage) and dispatch bandwidth (30,000 videos per day on average); (2) ev er-increasing uploaded videos (60,000 videos per day on av erage) ev ery day; (3) notable dif ferences between peak (1,667,000 qps) and off-peak (235,000 qps) requests and video preferences; (4) erratic variants of user requests; (5) implicit and intrinsic request relations among users due to different populations, economies and cultures. Bearing the above challenges in mind, we aim at a scalable video dispatch system working at off-peak time to enhance the peak service qualities on the next day . Fig. 1. V ideo Dispatch System and Problems Our present baseline method triggered the dispatch of video v to CDN i , when the requests of v from the users served by i exceed a threshold h for a period p . This implies that one successful service corresponds to h CDN misses. Besides, dispatch at peak time occupies network bandwidth and resources, which affects the peak service quality . W e apply two ratios as e valuation metric: r whole as the number of requested videos after dispatched within a whole day ov er the total dispatch number, and r peak as the number of peak requested dispatched from sev eral hours ago till recently over the total dispatch number . While r whole can be optimized by fine tuning h and p , r peak stays low , meaning that the baseline method performs poor for peak service quality . This is due to difficulty (3) and (4), and the baseline method fails to explore the relation between peak and of f-peak requests, only to exploit a very short memory of requests without knowing the longer changing pattern. A. T ime Series F orecasting Recurrent neural networks ( RNN s) memorize state transition efficiently thanks to their recursive structures with hidden state storage. RNN has been applied to predict noisy and non-stationary time series, where the series are unsupervised learned before sent to RNN in case that RNN prefers short-term dependencies than long-term dependencies caused by vanishing gradients. Long short-term memories ( LSTM s) and gated recurrent units ( GRU s) are proposed with learnable gates to control information flowing in order to alleviate this problem. Both LSTM and GR U hav e achiev ed the state-of-the-art performances in sequential applications. A common point in the above sequential models is that every single point in the series weighs equally importantly , and therefore they are vulnerable to noise and prone to overfitting to specific series patterns. Con volutional neural networks ( CNN s), which are typically implemented with globally shared nonlinear filters followed by pooling operations, strengthen and extract local features. CNN has formed the crux of computer vision applications. CNN is usually followed with max pool to subtract the most representativ e features for each local region. T ime series analysis with CNN (Borovykh et al. 2017) also emerges in recent years. In this paper , we put a top-k pool ahead of CNN to extract the peak-time pattern, place three max pools behind CNN to extract the inter-day pattern, and concatenate CNN with RNN (Jozefowicz et al. 2016) to learn the dynamics with low complexity and in av oidance of overfitting compared with pure RNN. In W av enet, causal CNN without pools (reference ?) were proposed to generate predicted 1D signals, forcing the filters always to calculate on the previous points. It is noticeable that in the above researches, all the input and output elements value equally . Howe ver , the peak-time-oriented dispatch problem focuses more on the peak elements than the of f-peak ones. Besides, the predicted peak requests are not necessarily precise in an e xact time, since the peak time sustains in a period. This motiv ates us to design our algorithm to differentiate peak and off-peak request patterns. B. Ranking Pr oblems At first glance, video dispatch can be solved the same way as a variation of 0/1 knapsack problem. Metaheuristic techniques are guaranteed neither an optimal solution, nor polynomial prediction time complexity . Neural network methods, such as Hopfield Net [Hopfield and T ank, 1985], and recently proposed Pointer Net [V inyals et al., 2015], though hav e been successfully verified in similar combinatorial optimization applications, suffer from either scalability or low-dimension restrictions. Alternativ ely , the dispatch problem is to pick top-k videos by the probabilities of the future requests from the users served by certain CDN serv ers. This process simulates a ranking problem. Learning to rank ( L2R ) has produced a much better performance than traditional methods. The L2R algorithms are categorized [Liu, 2009] as pointwise [Li et al., 2008], and other techniques. The pointwise ranking focuses on total and absolute orders. This works for the dispatch problem because the strategies cannot be made until the total video requests hav e been seen, while the pairwise ranking aims at partial orders and the listwise ranking costs too high complexity for large scale data set. C. Clustering and Manifold Learning In the ranking or time series forecasting problems, the set of ranked items or series are predetermined. The V OD provider , howe ver , is facing ne w videos all the time, which is nontrivial in dispatch problems. Clustering methods categorize data with distance-based metric without human labelling so that ne w videos as well as present ones are represented with a nearest centroid. T o cope with “curse of dimensionalit”, manifold learning projects features into a low dimensional subspace, unco vering the intrinsic distrib ution of the input data in visible and “compact” w ay . Autoencoder [Hinton and Salakhutdinov , 2006], as a nonlin- ear dimensionality reduction method, was proposed to pretrain deep neural networks. It and variations [Kingma and W elling, 2013], [Makhzani et al., 2015] hav e been applied as preprocessing for clustering [Baldi, 2012], [Xie et al., 2016]. Distributed clustering algorithms [T asoulis and Vrahatis, 2004] were proposed for large data set. Unfortunately , they do not maintain consistent clustering indices at training and predicting iterations. W e propose a supervised-like clustering modification to solve this problem. 2 D. End-to-end Learning Recently it has been a fashion to train multi-task neural networks in an end-to-end learning mechanism for better performances rather than to optimize them independently . Within the ideal end-to-end learning trait, all learnable parameters are differentiable with respect to the ultimate task‘s losses (in supervised learning) or re wards (in reinforcement learning). One strategy is to carefully design the structure of these networks so that they are connected by shared components. For example, Faster Rcnn [Ren et al., 2015] combined region proposal with objection recognition by a shared CNN part as feature extractors, and led to globally optimized object detection results; value iteration networks [T amar et al., 2016] introduced a fully differentiable CNN planning module to approximate the value iteration algorithm, simultaneously approximating the Markov decision process and optimizing the control. E. Our Contributions 1) An end-to-end learning mechanism which fulfills video clustering and dispatch tasks. 2) A nov el structure for time series forecasting which utilizes both peak-time and whole-day temporal features. 3) A supervised-like clustering method fit for the mini-batch gradient descent ( MBGD ) training and the distrib uted en vi- ronment, and therefore scalable for big data. 4) State-of-the-art performances under the real-world VOD system. F . Notations The symbols in this paper are defined as follows: D denotes the constant as the number of consecutive days when training or predicting a batch of data. T denotes the constant as the number of time intervals within a day . K denotes the constant as the number of peak time intervals within a day . U denotes the set of the users. I denotes the set of CDNs, and I u the set of the CDNs that serve user u . V denotes the set of the videos, and V i the set of the videos dispatched to CDN i R denotes the set of the requested videos within a day , R u the set of the requested videos from the user u within a day , R d the set of the requested videos on day d , and R u d the set of the requested videos by the user u on day d . P R denotes the set of the requested videos at peak time, and similarly with P R u , P R d , and P R u d . C denotes the mapping from the video to its cluster , and C ( r ) denotes the cluster of the video r . C P denotes the probabilities of the clustered videos dispatched to the CDNs, and C P C ( r ) ,i the probability of the cluster of the requested video r dispatched to IDC i . C P T denotes the upper bound of the sum of clustered dispatch probabilities to the CDNs. | A | denotes the cardinality of the set A . < ( f ) denotes the cardinality of the range of the mapping f . A 1 × A 2 denotes the Cartesian product of two sets A 1 and A 2 . ⊗ represents con volution operator . top ( K | S ) represents extracting the K largest elements out of S according to the ordered set given by S . sor t ( V ) represents sorting V in descending order . maxpool ( M , r , c ) represents to extract the max element of each submatrix M 0 r × c of the matrix M , and reshape the output to 1D. ReLU ( x ) , sig moid ( x ) , and tanh ( x ) are the nonlinear activ ation functions, referring to rectifier, sigmoid, and hyperbolic tangent functions. || v || 2 denotes the L2-norm of v . 3 I I . P RO B L E M F O R M U L AT I O N min C,C P X u ∈ U X r ∈ P R D +1 u | r | Y i ∈ I u 1 − C P C ( r ) ,i R 1 ... R D s. t. X r ∈ S u ∈ U D S d =1 R d u C P C ( r ) ,i ≤ C P T i , ∀ i ∈ I 0 . 0 ≤ C P C ( r ) ,i ≤ 1 . 0 , ∀ r ∈ [ u ∈ U D [ d =1 R d u , ∀ i ∈ I C ( r ) ∈ C, ∀ r ∈ [ u ∈ U D [ d =1 R d u , ∀ i ∈ I I I I . T H E S T RU C T U R E O F D I S P A T C H N E U R A L N E T W O R K S W e set up two neural networks, clustering network and policy network, as depicted in Figure 2. The clustering network is composed of temporal layers and clustering layers. The policy network comprises accumulation layers, temporal layers and policy layers. The two networks are coupled with the temporal layers, which have identical structures and shared weights. The outputs of the clustering network and the primiti ve inputs constitute the inputs of the policy network. The outputs of the policy network are the probabilities of the videos dispatched to users rather than to CDNs. The probabilities of the videos dispatched to CDNs will be calculated in a following “post-processing” procedure. Fig. 2. Structure of the T wo Coupled Networks A. Primitive Inputs The primitive inputs for one video are its request sequences. Each sequence represents the requests from a user on T intervals of D days. Therefore, the primitiv e inputs have a user dimension and a time dimension with intraday and interday parts. The inputs of video v is denoted as follows, where x t,d u ≥ 0 denotes the requested number of v from the user u on interval t on day d . X ( v ) = x 1 , 1 1 ... x T , 1 1 ... ( x 1 ,D 1 ... x T ,D 1 . . . x 1 , 1 | U | ... x T , 1 | U | ... ( x 1 ,D | U | ... x T ,D | U | ( v ) W e define X t,d u = x 1 ,d u ... x T ,d u for con venience. The primitive inputs exclude the information other than video requests, such as video metadata, weekends and holidays. There are three reasons: (1) the mapping from video content to user request is not bijection due to redundant uploads; (2) labelling the videos with tags may be subjective and ambiguous; (3) the video requests are highly nonstationary processes, and modeling with other observations is vulnerable to ov erfitting. 4 B. T emporal Layers The temporal layers process the time dimension of the inputs. There are two components, CNN module for the intraday part and RNN module for the interday part, as depicted in Figure 3. The temporal layers are designed to predict the future requests with daily peak-time features and whole-day trajectories. The CNN module has two parallel groups of conv olutional filters with pools, which we call peak con volutional part ( PCP ) and mean con volutional part ( MCP ) respectiv ely . PCP and MCP take X d u as a batch. In PCP , the inputs are processed with a global top-K pool sorted by the total requests at each time. Then 1D conv olutions are calculated. X K d u = top K ar gsor t X x ∈ V X d u !! Y P d u = ReLU ( W peak ⊗ X K d u + b peak ) W peak and b peak are learnable parameters. In MCP , the inputs are passed via 1D con volution filters. Y M C d u = ReLU ( W mean ⊗ X d u + b mean ) W mean and b mean are learnable parameters. Then Y M C d u is reshaped to three matrices Row d u , C ol umn d u , B lock d u : R row × R column , C row × C column , and ( B row 1 × B row 2 ) × ( B column 1 × B column 2 ) , where T = R row × R column = C row × C column = ( B row 1 × B row 2 ) × ( B column 1 × B column 2 ) , and K = R row = C column = ( B row 1 × B column 1 ) The rows are closely related to hours, and the columns to minutes. These matrices are processed with 2D max pools and weightedly summed: Y R d u = maxpool ( Row d u , 1 , R column ) Y C d u = maxpool ( C olumn d u , C row , 1) Y B d u = maxpool ( B l ock d u , B row 2 , B column 2 ) Y M d u = w row Y R d u + w column Y C d u + w block Y B d u w row , w column , and w block are learnable parameters. The outputs of the CNN module, C d u , are the concatenation of Y P d u and Y M d u . The RNN module adopts GR U, and takes C d u as the d th input for user u . The d th output R d u is computed as : z d u = sigmoid ( W z C d u + U z R d − 1 u + b z ) r d u = sigmoid ( W r C d u + U r R d − 1 u + b r ) R d u = (1 − z d u ) R d − 1 u + z d u tanh ( W h C d u + U h ( r d u R d − 1 u ) + b h ) W z , U z , b z , W r , U r , b r , W h , U h , and b h are learnable parameters. The outputs of the temporal layers from user u are R D u . W e denote the outputs for video v from all users as T ( v ) = R D 1 ... R D | U | ( v ) . 5 Fig. 3. T emporal layers C. Clustering Layers The clustering layers process the user dimension of the inputs. There are four components, normalization module, autoencoder module, clustering module and loss module. The normalization module scales the inputs T ( v ) according to L2-norm, as N T ( v ) . The autoencoder module adopts a feedforward structure, which encodes N T ( v ) to E ( v ) on the 2D plane E nc 2 = ( − 1 . 0 , 1 . 0) × ( − 1 . 0 , 1 . 0) , and then decodes back to D ( v ) . In the clustering module, we divide E nc 2 into |< ( C ) | hierarchical blocks B 2 . W e construct B 2 as Figure 4 and follows: 1) Let r intv = ( − 1 . 0 , 1 . 0) , and N D H the number of di visions per right-side hierarchy . Let RI ntv 1 = φ . 2) Divide rintv uniformly into N D H open sub-intervals S ub 1 . Let α = 0 . 0 , 1 . 0 N D H ∈ S ub 1 . Insert S ub 1 \ { α } into RI ntv 1 . 3) Let r intv = α . Repeat 2 until | RI ntv 1 | ≥ 1 2 |< ( C ) | 1 / 2 . 4) Let I ntv 1 = { α, ( − α R , − α L ) | α ∈ RI ntv 1 } 5) Let B 2 = I ntv 1 × I ntv 1 . Comparison with K-means results in Figure 4 shows that our supervised-like clustering method maintains the consistency of cluster indices in MBGD training and distributed en vironment, so that the video cluster can be determined without knowledge of the other ones. The loss module adds the loss from the enc-dec module and the loss from the clustering module weighted by a hyperparameter ω . loss c = 1 2 X v ∈ V N T ( v ) − D ( v ) 2 2 + ω min b ∈ B 2 E ( v ) − O b 2 2 O b denotes the coordinate of the center of b . W e apply unsupervised learning to explore the user dimension because there are few labeled tags or accurate prior knowledge. Besides, we separate the temporal layers from the autoencoder module for two reasons: (1) fully-connected structure is not an optimal choice for time series analysis; (2) the decoders with RNN and CNN suffer from lack of a finite-sized dictionary . 6 Fig. 4. Example of Hierarchical Clustering Blocks D. Accumulation Layers The accumulation layers group the primitiv e inputs by their clusters. X A c = X v ∈ V T { C ( v ) = c } X ( v ) Then follows normalization, and gets N X A ( c ) After the temporal layers, the outputs are T ( c ) . E. P olicy Layers The policy layers estimate the probabilities for each video cluster to be dispatched to all users on day ( D + 1) . There are two components, full connection module and loss module. The full connection module transforms T ( c ) to U P ( c ) on (0 . 0 , 0 . 1) | U | with learnable parameters. The loss module compares U P ( c ) with the real request data on day D+1 . R ( c ) = X A D +1 1 P u ∈ U X A D +1 u ... X A D +1 | U | P u ∈ U X A D +1 u ( c ) loss p = 1 2 X c ∈< ( C ) U P ( c ) − R ( c ) 2 2 I V . I M P L E M E N T AT I O N A N D R E S U LT S A. Data Set W e prepare the data set with the real-world video requests from each user accumulated ev ery fiv e minutes. Historical requests are for training, and 15 consecutiv e days of requests until present are for predicting. There are 177 users, and the dimension of the feature space of one video has 12 minutes × 24 hours × 15 days × 177 users = 764,640. W e analyze the video requests from two aspects. Firstly , we consider each video request sequence from one user as an independent stochastic process and observe the nonstationarities. W e sample 5,000 sequences, calculate the difference of the means within a one-day sliding window . After taking the first-order difference of the sequences, the difference of means decreases, as in T able 1. That means nonstationarities are reduced. Next we run the Kwiatkowski-Phillips-Schmidt-Shin ( KPSS ) test to the sampled sequences with one-day lag (288). They also show the nonstationarities. Secondly , we analyze the peak request frequencies. The total request number is 82,700,000 for two hours, with 8,930,000 videos, so the av erage request frequency per video is 9. W e sort the videos in descending order of request frequencies, and show the request distribution after excluding current videoss. Figure 5 shows a typical long-tail shape. 7 Difference of Means Original 0.00616 After first-order differences 0.00158 KPSS T est KPSS statistic -5.38 P-value 0.000003 1% -3.43 Critical values 5% 2.86 10% 2.57 T ABLE I N O NS TA T I O NA R I TY A NA L Y S IS F O R V I DE O R EQ U E ST S Fig. 5. Peak-time V ideo Request Distribution B. En vironment W e run on multi-machines with 48-core CPU (Intel Xeon 2.20GHz) and 128G memory , based on T ensorFlow 1.3 and coordinated with Apache Zookeeper 3.4. C. T rainers and Pr edictors T raining the clustering network requires a clustering trainer, and training the policy network requires a clustering predictor and a policy trainer . Predicting inv olves clustering and policy predictors. The trainers comprises all of the modules in the respective networks. The clustering predictor is composed of the all layers but the decoder and loss modules in the clustering network, and the policy predictor is composed of all layers but the loss module in the policy network. D. Asynchr onous T raining Mechanism Three models are generated through training the temporal, clustering, and policy layers. The clustering model is updated in the clustering network. The temporal and policy models are updated in the policy network. W e train the two networks asynchronously as in Figure 6. W e start the policy trainer first with randomized clustering indices. Then start the clustering predictor and trainer with the identical temporal model trained for sev eral iterations in the policy trainer . The clustering trainer fetches the temporal model from the policy trainer ev ery 200 iterations. The clustering predictor fetches the clustering model from the clustering trainer at each iteration. The video dispatch scenario differs from the regular L2R in that the items are assumed as independent in the latter case, while the popular videos often enjoy continual requests. Therefore, the dataset for the policy network needs shuf fling to break the chronological order so as to remov e autocorrelation between the neighboring samples. This procedure is inspired by experience replay [Lin, 1992], [Mnih et al., 2013] in reinforcement learning. 8 All of the learnable parameters are initialized with Xavier initialization [Glorot and Bengio, 2010]. The MBGD optimizer is utilized, and the learning rates are layer-wisely tuned with decay settings. Fig. 6. Asynchronous T raining Mechanism E. Pr ediction Mechanism with P ost-pr ocessing 1) Run the clustering predictor for C ( V ) . 2) Run the policy predictor for U P |< ( C ) | , | U | . 3) Calculate C P C,I = U P |< ( C ) | , | U | U C | U | , | I | . 4) For ∀ i ∈ I , sort V in the descending order of C P C ( V ) ,i . The videos in the same cluster are sorted in the descending order of uploaded time. Dispatch the first 10,000 videos to i . F . T raining P erformances Firstly , Figure 7 shows how the normalization module helps the clustering trainer to con ver ge, where the normalization module is remov ed for A and B. Loss curve A represents training with a data set of 20 batches, and unchanged temporal models. The loss jumps beyond the initial value immediately after 3 iterations, and then descends slowly . Loss curve B represents training with a data set of only one batch, and periodically (every 500 iteration) changed temporal model. The loss shoots up every time the temporal model is updated to newly randomized values. Loss curve C represents training with a data set of 20 batches, and changed temporal model as in B. It descends 30% at the first 500 iterations, and continues till the 10,000 iterations. Fig. 7. Clustering T rainer Loss Percentages Secondly , Figure 8 shows how shuffled data set helps the policy trainer to con ver ge. The data set in A is ordered by ascending date, and divided into two groups in the middle. The policy trainer fetches the two groups of data alternately , training each group for 200 iterations. The data set in B is finely shuffled. Loss A decreases more rapidly than loss B in the beginning, but shoots up after moving to the other half of data, causing it difficult to con verge. Thirdly , Figure 9 shows the training results based on the section of “asynchronous training mechanism”. They conv erge without being interfered by each other . 9 Fig. 8. Polic y Trainer Loss Percentages Fig. 9. Asynchronous T raining Losses of Both Trainers G. Assessment for V ideo Clustering Firstly , T able 2 compares the inner productions between 10,000 video requests in the same clusters (e xcluding the inner productions of the video requests to themselves) with those in different clusters. The mean from the same clusters is much larger than that from the different, and the coef ficient of v ariation ( CV ) is smaller . This implies that the video requests from the same cluster are much more similar than from the different. Same Different Mean 14.0 0.117 CV 1.41 4.59 T ABLE II I N NE R P R O DU C T I VI T I ES F RO M S A M E / D I FF ER E N T C L U ST E R Secondly , Figure 10 compares the video request densities in different clusters, including non-sparsities ( NS ), L1-norms and L2-norms (whose means are multiplied by 20). NS is defined as the ratio of the number of non-zeros to the length. The means of the three are positively related, and the CVs are close. This implies that the videos with similar request densities are more likely to be in the same cluster . Thirdly , we count the number of videos ( NV ) in each cluster , and calculate the average distances ( AD ) from the encoder outputs to the cluster centroids.T able 3 applies Pearson correlation coefficient to measure the correlation of NV with AD and the area of the cluster . This implies that a larger cluster area for larger values of the encoder outputs is space efficient with sufficient accuracies. H. Pr ediction and Contr olled Experiment Results W e dispatch respectively 10,000 videos out of 50 million to 50 CDNs at daily off-peak time for the next peak-time requests. Our video dispatch prediction takes 4 hours and 100 machines to compute. W e denote our proposed algorithm as A. 10 Fig. 10. V ideo Request Densities NV and area 0.6194 NV and AD -0.4956 T ABLE III C O RR E L A T I O N C O E FFIC I E N T W e pre viously dispatched videos based on the threshold of their request frequencies during a period of time, denoted as B. Since B dispatches videos at peak time, extra costs are not ignorable. The prediction accuracy is represented as the ratio of the peak-time request number (rev enues) to the peak-time dispatch number (costs). For comparison, six other methods are listed. Firstly , we compute dispatch policies via classification without video clustering . This restricts us to b uild one request model for one user in order to lo wer the input dimensions. The outputs are either “to dispatch” or “not to dispatch”, while the ground truth is the average requests over the peak time on the next day . Method C applies logistic regression and Method D applies Gradient Boosting Decision Tree. Secondly , we remov e the end-to-end learning mechanism, and let the clustering and policy tasks run independently . This restricts us from using temporal layers in the clustering network. Method E substitutes the clustering network with principal component analysis to reduce the input dimension to 4, followed by K-means clustering. Method F removes the temporal layers from the clustering network. Thirdly , method G substitutes our supervised-like blocks with K-means clustering . Fourthly , method H remov es the CNN module from the temporal layers. The input sequences in C, D, E, F and H are sampled per hour . The prediction data set in E and G is limited to the latest 10,000 videos, and the dispatch number is 100. The prediction results are shown in Figure 11, which summarize A and B for 90 days, and C to H for 30 days. The results include the means and standard deviations of the prediction accuracies, but exclude recalls because the CDN storage capacities are much smaller than the total size of the requested videos. The overall performances of the end-to-end learning methods, namely A, G ,H, D and C are better than the others. Although K-means in G and E provides more accurate clustering results, it suffers from scaling issues and limits the dispatch candidates. The CNN module in method A filters the sequences, meanwhile retaining the important information, which especially ha ve advantages ov er the fully connected structure as in F , and also in D and C. Besides, the CNN module with learned parameters performs better than trivial downsampling method in H. The RNN module in A, G and H provides better sequence forecasting accuracies mainly because RNN is able to explore complex nonlinear state transitions. Lastly , our pre vious method B suffers from the dilemma of request frequencies and request amounts as in Figure 5. Although a higher threshold in B implies higher dispatch accuracies, the number of dispatchable videos decrease. V . C O N C L U S I O N In this paper , we propose a video dispatch algorithm for V OD to enhance peak-time service quality . W e cluster the videos with one network by their request patterns before dispatching them from the large candidate set. W e develop dispatch policies for the clustered videos with the other network inspired by pointwise L2R algorithms. The two networks are coupled with shared temporal-feature-extracting layers, which comprise CNN and RNN modules. After training them asynchronously , the average prediction accuracy on real-world video requests is 5 times as high as that of our previous methods. 11 Fig. 11. Prediction Results Future work will be dev oted to risk controls to guarantee robustness regardless of rapidly changing situations. R E F E R E N C E S [Baldi, 2012] Baldi, P . (2012). Autoencoders, unsupervised learning, and deep architectures. In Pr oceedings of ICML workshop on unsupervised and transfer learning , pages 37–49. [Glorot and Bengio, 2010] Glorot, X. and Bengio, Y . (2010). Understanding the difficulty of training deep feedforward neural networks. In Pr oceedings of the thirteenth international conference on artificial intelligence and statistics , pages 249–256. [Hinton and Salakhutdinov , 2006] Hinton, G. E. and Salakhutdinov , R. R. (2006). Reducing the dimensionality of data with neural networks. science , 313(5786):504–507. [Hopfield and T ank, 1985] Hopfield, J. J. and T ank, D. W . (1985). “neural” computation of decisions in optimization problems. Biological Cybernetics , 52(3):141–152. [Kingma and W elling, 2013] Kingma, D. P . and W elling, M. (2013). Auto-encoding variational bayes. arXiv preprint . [Li et al., 2008] Li, P ., W u, Q., and Burges, C. J. (2008). Mcrank: Learning to rank using multiple classification and gradient boosting. In Advances in neural information processing systems , pages 897–904. [Lin, 1992] Lin, L.-J. (1992). Self-improving reactiv e agents based on reinforcement learning, planning and teaching. Machine learning , 8(3-4):293–321. [Liu, 2009] Liu, T .-Y . (2009). Learning to rank for information retriev al. F oundations and T r ends R in Information Retrieval , 3(3):225–331. [Makhzani et al., 2015] Makhzani, A., Shlens, J., Jaitly , N., and Goodfellow , I. J. (2015). Adversarial autoencoders. CoRR , abs/1511.05644. [Mnih et al., 2013] Mnih, V ., Kavukcuoglu, K., Silver , D., Graves, A., Antonoglou, I., W ierstra, D., and Riedmiller, M. (2013). Playing atari with deep reinforcement learning. arXiv preprint . [Ren et al., 2015] Ren, S., He, K., Girshick, R., and Sun, J. (2015). Faster r-cnn: T owards real-time object detection with region proposal networks. In Advances in neural information processing systems , pages 91–99. [T amar et al., 2016] T amar, A., W u, Y ., Thomas, G., Levine, S., and Abbeel, P . (2016). V alue iteration networks. In Advances in Neural Information Pr ocessing Systems , pages 2154–2162. [T asoulis and Vrahatis, 2004] T asoulis, D. K. and Vrahatis, M. N. (2004). Unsupervised distributed clustering. In P arallel and distributed computing and networks , pages 347–351. [V inyals et al., 2015] Vin yals, O., Fortunato, M., and Jaitly , N. (2015). Pointer networks. In Cortes, C., Lawrence, N. D., Lee, D. D., Sugiyama, M., and Garnett, R., editors, Advances in Neural Information Pr ocessing Systems 28 , pages 2692–2700. Curran Associates, Inc. [Xie et al., 2016] Xie, J., Girshick, R., and Farhadi, A. (2016). Unsupervised deep embedding for clustering analysis. In International confer ence on machine learning , pages 478–487. 12
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment