계층적 게임 학습의 수렴: 스택엘버그 역학과 GAN 적용
** 본 논문은 연속적 행동공간을 갖는 스택엘버그 게임에서 학습 알고리즘의 수렴성을 분석한다. 리더는 그래디언트 업데이트를, 팔로워는 최적응답 혹은 그래디언트 플레이를 수행하도록 설계한 두 가지 동적 모델을 제안하고, 특히 제로섬 게임에서 모든 안정적인 임계점이 스택엘버그 균형임을 증명한다. 또한 일반합 게임에 대해 두 시간척도 알고리즘을 제시하고, 지역 수렴에 대한 고확률 유한시간 경계를 제공한다. 실험은 GAN 훈련에 적용해 회전 동역학…
저자: Tanner Fiez, Benjamin Chasnov, Lillian J. Ratliff
**
본 연구는 계층적 의사결정 구조를 갖는 연속 게임, 즉 스택엘버그 게임에서 학습 알고리즘의 수렴성을 체계적으로 분석한다. 먼저, 리더와 팔로워 각각의 비용 함수 \(f_1, f_2\)가 충분히 매끄럽다고 가정하고, 행동 공간을 \(X=X_1\times X_2\)라 정의한다. 스택엘버그 게임의 핵심은 리더가 먼저 행동을 선택하고, 팔로워가 그에 대한 최적응답을 수행한다는 점이다. 이를 수학적으로는 팔로워의 반응 집합 \(R(x_1)=\{y\in X_2\mid f_2(x_1,y)\le f_2(x_1,x_2),\forall x_2\in X_2\}\) 로 표현한다.
논문은 두 가지 학습 메커니즘을 제안한다.
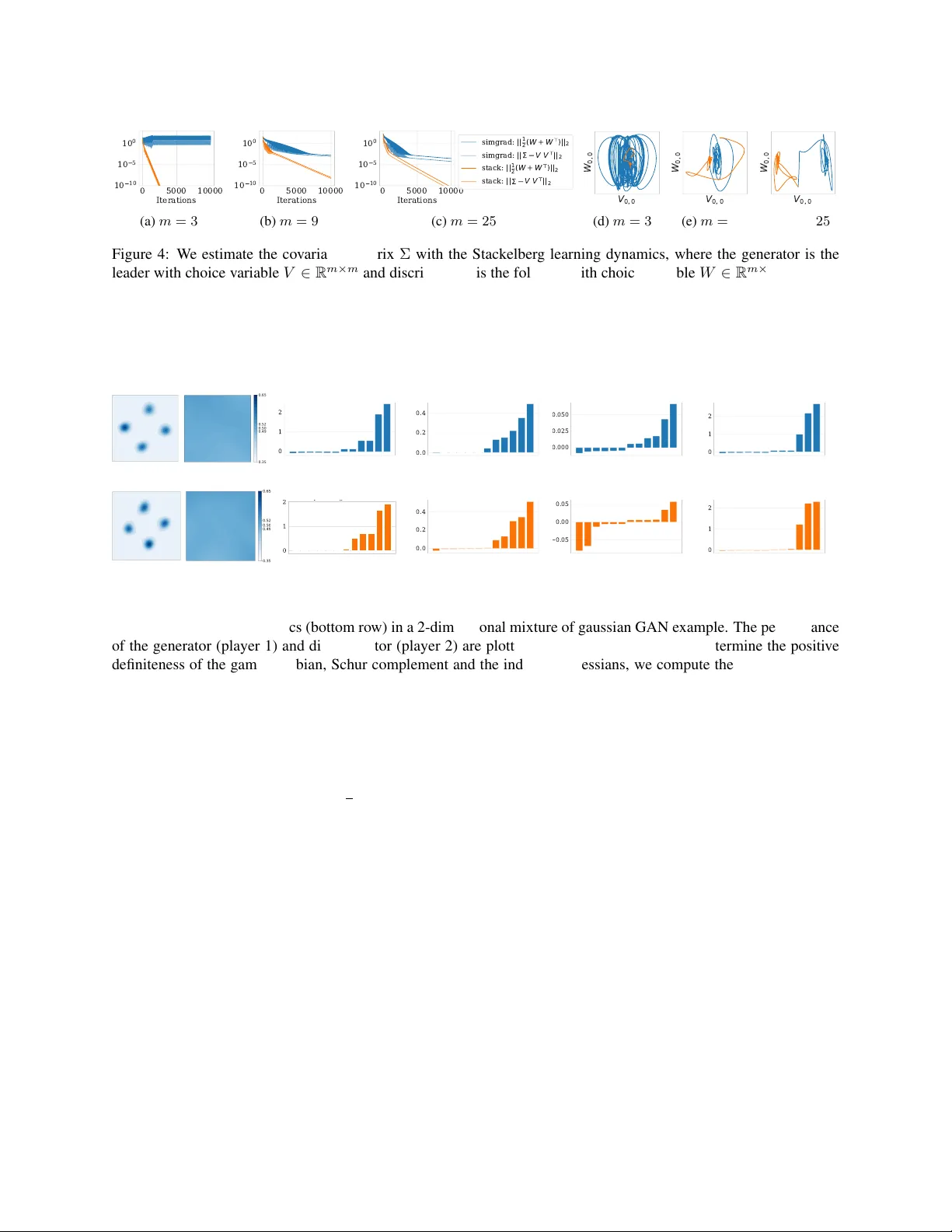
1. **Best‑Response 기반 메커니즘** – 팔로워가 정확히 최적응답을 계산하고, 리더는 팔로워의 반응을 내재화한 전미분 \(D f_1\)를 사용해 그래디언트 하강을 수행한다. 이 경우 전체 시스템의 동역학을 \(\omega_S(x)=(D f_1(x), D_2 f_2(x))\) 로 기술한다. 정리 1에서는 제로섬 게임에서 \(\omega_S\)의 모든 로컬 안정점이 스택엘버그 균형임을 증명한다. 이는 동시 그래디언트 플레이가 비내시(비Nash) 임계점에 수렴할 위험이 있는 반면, 계층적 구조를 이용하면 그런 위험을 회피한다는 중요한 결과다.
2. **Two‑Timescale Gradient 메커니즘** – 실제 딥러닝 환경에서는 팔로워가 정확한 최적응답을 구하기 어렵다. 따라서 팔로워가 자신의 비용에 대해 그래디언트 플레이를 수행하도록 하고, 리더는 더 느린 학습률로 업데이트한다. 이때 리더와 팔로워의 학습률 비율을 충분히 크게 잡으면(리더가 느리게, 팔로워가 빠르게) 두 시간척도 시스템이 거의 확실하게(Almost Sure) 스택엘버그 균형으로 수렴한다. 정리 5·정리 6은 제로섬 게임에서는 전역 수렴을, 일반합 게임에서는 지역 수렴을 고확률 경계와 함께 제공한다.
또한, 논문은 Nash 균형과 스택엘버그 균형 사이의 관계를 심도 있게 탐구한다. 제로섬 게임에서 안정적인 Nash 균형이 차별적 스택엘버그 균형과 동등함을 정리 2에서 보이며, 이는 기존 연구(Jin et al.)와 일맥상통한다. 동시에, 정리 3·정리 4는 동시 그래디언트 플레이가 Nash이 아닌 스택엘버그 균형으로 수렴할 수 있는 충분·필요 조건을 제시한다. 특히 GAN의 실현가능 가정(Generator가 데이터 분포를 완벽히 표현 가능) 하에서는 이러한 조건이 자연스럽게 만족되며, 이는 GAN 훈련에서 비내시 스택엘버그 균형이 실제로 관찰될 수 있음을 시사한다.
실험 부분에서는 세 가지 도메인을 다룬다. 첫째, 토러스 위 위치 게임은 연속적인 상태공간에서 리더가 팔로워보다 유리한 위치를 선점하는 현상을 보여준다. 둘째, 스택엘버그 듀오폴리 게임은 전통적인 동시형 듀오폴리와 비교해 리더가 얻는 이익이 크게 증가함을 확인한다. 셋째, GAN 훈련에 제안된 스택엘버그 학습 규칙을 적용한다. 여기서 리더는 생성기, 팔로워는 판별기로 설정하고, 판별기가 최적응답(또는 빠른 그래디언트 플레이)을 수행한다. 실험 결과, 동시 그래디언트(전통적인 GAN)에서는 흔히 관찰되는 회전(oscillation)과 발산 현상이 크게 감소하고, 학습률을 크게 잡아도 빠르게 수렴한다. 또한, 비내시 스택엘버그 균형에서도 생성된 이미지 품질이 경쟁적인 내시 균형과 비슷하거나 더 우수함을 보인다.
마지막으로, 논문은 기존 연구와의 차별점을 강조한다. 대부분의 기존 학습‑게임 연구는 동시 플레이와 Nash 균형에 초점을 맞추었으며, 계층적 구조를 다루는 경우는 제로섬 게임에 국한되었다. 본 연구는 일반합 게임까지 확장하고, 두 시간척도 알고리즘을 통해 실용적인 딥러닝 시스템에 적용 가능한 이론적 프레임워크를 제공한다. 또한, 스택엘버그 균형이 비내시이더라도 실제 응용(예: GAN)에서 충분히 유용할 수 있음을 실험적으로 입증한다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기