Convergence of Learning Dynamics in Stackelberg Games
This paper investigates the convergence of learning dynamics in Stackelberg games. In the class of games we consider, there is a hierarchical game being played between a leader and a follower with continuous action spaces. We establish a number of co…
Authors: Tanner Fiez, Benjamin Chasnov, Lillian J. Ratliff
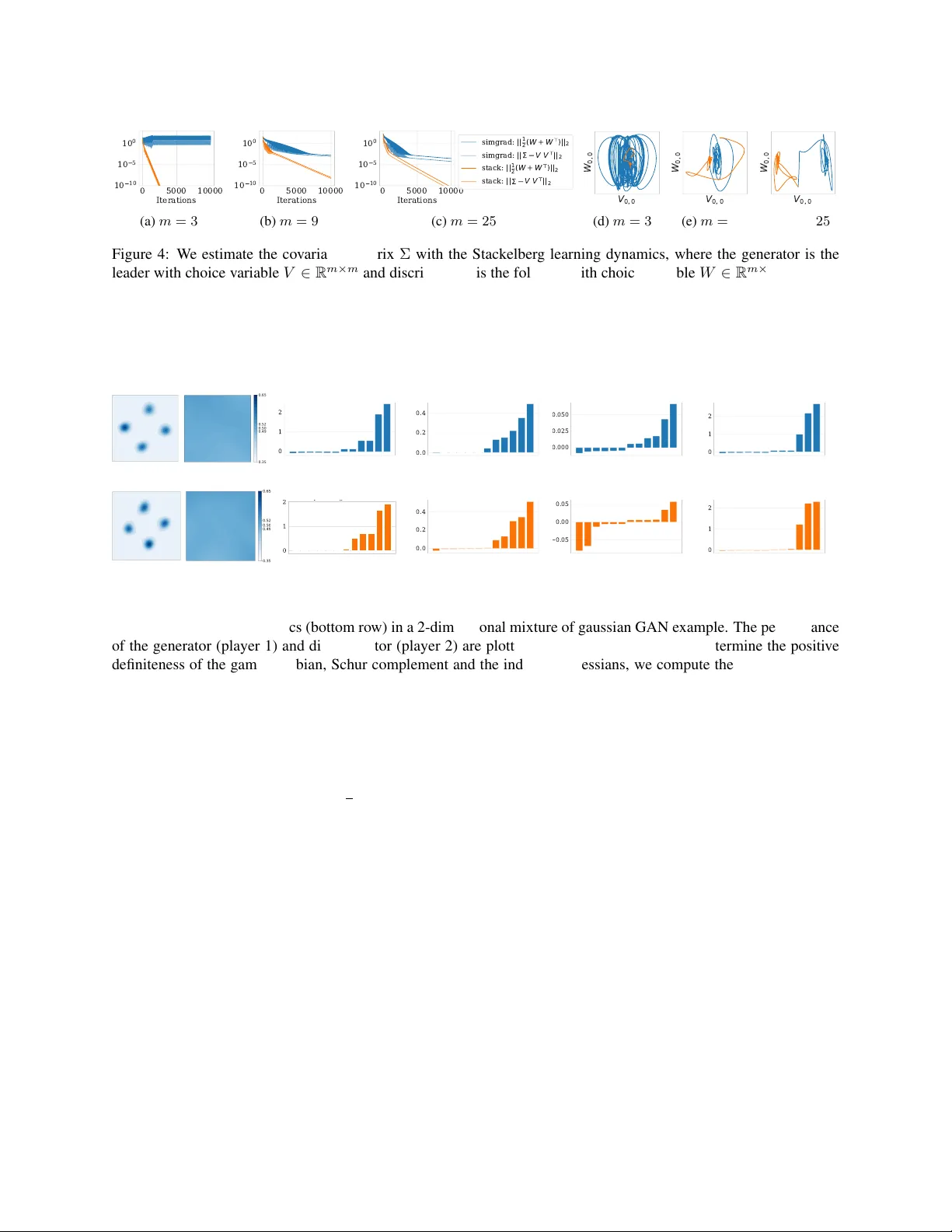
Con ver gence of Learning Dynamics in Stack elberg Games T anner Fiez FI E Z T @ U W . E D U Department of Electrical and Computer Engineering University of W ashington Benjamin Chasnov B C H A S N OV @ U W . E D U Department of Electrical and Computer Engineering University of W ashington Lillian J. Ratliff R A T L I FFL @ U W . E D U Department of Electrical and Computer Engineering University of W ashington Abstract This paper in vestigates the con vergence of learning dynamics in Stack elberg games. In the class of games we consider , there is a hierarchical game being played between a leader and a follower with continuous action spaces. W e establish a number of connections between the Nash and Stackelber g equilibrium concepts and characterize conditions under which attracting critical points of simultaneous gradient descent are Stackel- berg equilibria in zero-sum games. Moreo ver , we sho w that the only stable critical points of the Stack elberg gradient dynamics are Stackelberg equilibria in zero-sum games. Using this insight, we dev elop a gradient- based update for the leader while the follo wer employs a best response strategy for which each stable critical point is guaranteed to be a Stackelberg equilibrium in zero-sum games. As a result, the learning rule prov- ably conv erges to a Stackelberg equilibria gi ven an initialization in the region of attraction of a stable critical point. W e then consider a follower employing a gradient-play update rule instead of a best response strate gy and propose a two-timescale algorithm with similar asymptotic con ver gence guarantees. For this algorithm, we also provide finite-time high probability bounds for local con vergence to a neighborhood of a stable Stackelber g equilibrium in general-sum games. Finally , we present extensiv e numerical results that vali- date our theory , provide insights into the optimization landscape of generati ve adversarial networks, and demonstrate that the learning dynamics we propose can effecti vely train generati ve adv ersarial networks. 1. Introduction T ools from game theory no w play a prominent role in machine learning. The emerging coupling between the fields can be credited to the formulation of learning problems as interactions between competing algorithms and the desire to characterize the limiting behaviors of such strategic interactions. Indeed, game theory provides a systematic framew ork to model the strategic interactions found in modern machine learning problems. A significant portion of the game theory literature concerns games of simultaneous play and equilibrium analysis. In simultaneous play games, each player rev eals the strategy they ha ve selected concurrently . The solution concept often adopted in non-cooperativ e simultaneous play games is the Nash equilibrium. In a Nash equilibrium, the strategy of each player is a best response to the joint strategy of the competitors so that no player can benefit from unilaterally de viating from this strategy . The study of equilibrium giv es rise to the question of when and why the observed play in a game can be expected to correspond to an equilibrium. A common explanation is that an equilibrium emerges as the long run outcome of a process in which players repeatedly play a game and compete for optimality ov er time [ 22 ]. Consequently , an important topic in the study of learning in games is the con vergence behavior of learning algorithms reflecting the underlying game dynamics. Adopting this viewpoint and analyzing so-called ‘natural’ dynamics [ 7 ] often provides deep insights into the structure of a game. Moreover , a firm understanding of the structure of a game can inform how to design learning algorithms strictly for 1 F I E Z , C H A S N OV , R A T L I FF computing equilibria. Seeking equilibria via computationally efficient learning algorithms is an equally important perspecti ve on equilibrium analysis [ 22 ]. The classic objectiv es of learning in games are now being widely embraced in the machine learning community . While not encompassing, the prev ailing research areas epitomizing this phenomenon are ad- versarial training and multi-agent learning. A considerable amount of this work has focused on generativ e adversarial networks (GANs) [ 23 ]. Finding Nash equilibria in GANs is challenging owing to the complex optimization landscape that arises when each player in the game is parameterized by a neural network. Consequently , significant effort has been spent lately on de veloping principled learning dynamics for this application [ 3 , 25 , 37 , 39 , 40 , 42 ]. In general, this line of work has analyzed learning dynamics designed to mitigate rotational dynamics and con ver ge faster to stable fixed points or to avoid spurious stable points of the dynamics and reach equilibria almost surely . In our work, we draw connections to this literature and belie ve that the problem we study gi ves an under-e xplored perspecti ve that may provide valuable insights moving forw ard. Characterizing the outcomes of competiti ve interactions and seeking equilibria in multi-agent learning gained prominence much earlier than adversarial training. Howe ver , following initial works on this topic [ 24 , 27 , 35 ], scrutiny was gi ven to the solution concepts being considered and the field cooled [ 56 ]. Owing to the arising applications with interacting agents, problems of this form are being studied extensi vely again. There has been a shift toward analyzing gradient-based learning rules, in part due to their scalability and success in single-agent reinforcement learning, and rigorous con vergence analysis [ 3 , 21 , 33 , 38 , 60 ]. The progress analyzing learning dynamics and seeking equilibria in games is promising, but the work has been narro wly focused on simultaneous play games and the Nash equilibrium solution concept. There are many problems exhibiting a hierarchical order of play between agents in a diverse set of fields such as human-robot collaboration and interacting autonomous systems in artificial intelligence [ 20 , 36 , 45 , 54 ], mechanism design and control [ 19 , 51 , 52 ], and organizational structures in economics [ 2 , 13 ]. In game theory , this type of game is known as a Stackelber g game and the solution concept studied is called a Stackelber g equilibrium. In the simplest formulation of a Stackelberg game, there is a leader and a follower that interact in a hierarchical structure. The sequential order of play is such that the leader is endowed with the power to select an action with the knowledge that the follo wer will then play a best-response. Specifically , the leader uses this kno wledge to its adv antage when selecting a strategy . In this paper, we study the conv ergence of learning dynamics in Stackelber g games. Our moti vation stems from the emergence of problems in which there is a distinct order of play between interacting learning agents and the lack of e xisting theoretical con ver gence guarantees in this domain. The dynamics analyzed in this work reflect the underlying game structure and characterize the e xpected outcomes of hierarchical game play . The rigorous study of the learning dynamics in Stackelber g games we provide also has implications for simultaneous play games rele vant to adversarial training. Contributions. W e formulate and study a nov el set of gradient-based learning rules in continuous, general- sum games that emulate the natural structure of a Stackelberg game. Building on work characterizing a local Nash equilibrium in continuous games [ 50 ], we define the differ ential Stac kelber g equilibrium solu- tion concept (Definition 4 ), which is a local notion of a Stackelber g equilibrium amenable to computation. An analogous local minimax equilibrium concept was dev eloped concurrently with this work, but strictly for zero-sum games [ 28 ]. Importantly , the equilibrium notion we present generalizes the local minimax equilibrium concept to general-sum games. In our work, we draw several connections between Nash and Stackelber g equilibria for the class of zero-sum games, which can be summarized as follo ws: • W e show in Proposition 2 that stable Nash equilibria are differential Stackelberg equilibria in zero- sum games. Concurrent with our work, Jin et al. [ 28 ] equiv alently show that local Nash equilibria 2 are local minimax equilibria. This result indicates learning dynamics seeking Nash equilibria are simultaneously seeking Stackelber g equilibria. • W e re veal that there exist stable attractors of simultaneous gradient play that are Stackelber g equilibria and not Nash equilibria. Moreover , in Propositions 3 and 4 we giv e necessary and sufficient condi- tions under which the simultaneous gradient play dynamics can a void Nash equilibria and con ver ge to Stackelberg equilibria. T o demonstrate the relev ancy to deep learning applications, Propositions 5 and 6 specialize the general necessary and suf ficient conditions from Propositions 3 and 4 to GANs satisfying the realizable assumption [ 43 ], which presumes the generator is able to create the underly- ing data distribution. This set of results has implications for the optimization landscape in GANs as we explore in our numerical e xperiments. Our primary contributions concern the con vergence behavior of the gradient-based learning rules we formu- late that mirror the Stackelber g game structure. These contributions can be summarized as follo ws: • W e demonstrate in Proposition 1 that the only stable critical points of the Stackelberg gradient dynam- ics are Stackelber g equilibria in zero-sum games. This is in contrast to the simultaneous gradient play dynamics, which can be attracted to non-Nash critical points in zero-sum games. This insight allows us to define a gradient-based learning rule for the leader while the follower plays a best response for which each attracting critical point is a Stackelberg equilibria in zero-sum games. As a result, the learning rule prov ably con verges to an equilibria given an initialization in the region of attraction of a stable critical point. A formal exposition of this set of dynamics and results is pro vided in Section 3.1 . • Lev eraging the Stackelber g game structure, for general-sum games, we formulate a gradient-based learning rule in which the leader and follower hav e an unbiased estimator of their gradient so that updates are stochastic. • In Section 3.2 , we consider a formulation in which the follower uses a gradient-play update rule instead of an e xact best response strate gy and propose a tw o-timescale algorithm to learn Stackelber g equilib- ria. W e show almost sure asymptotic con vergence to Stackelber g equilibria in zero-sum games and to stable attractors in general-sum g ames; a finite-time high probability bound for local con ver gence to a neighborhood of a stable Stackelber g equilibrium in general-sum games is also gi ven. • W e present this paper with a single leader and a single follower , b ut this is only for ease of presentation. The extension to N followers that play in a staggered hierarchical structure or simultaneously is in Appendix F ; equi v alent results hold with some additional assumptions. Finally , we present se veral numerical experiments in Section 4 , which we no w detail: • W e present a location g ame on a torus and a Stackelberg duopoly game. The examples are general-sum games with equilibrium that can be solv ed for directly , allo wing us to numerically v alidate our theory . The games demonstrate the advantage the leader gains from the hierarchical order of play compared to the simultaneous play versions of the games. • W e ev aluate the Stack elberg learning dynamics as a GAN training algorithm. In doing so, we find that the leader update remov es rotational dynamics and prev ents the type of cycling behavior that plagues simultaneous gradient play . Moreov er , we discov er that the simultaneous gradient dynamics can em- pirically con verge to non-Nash attractors that are Stackelberg equilibria in GANs. The generator and the discriminator exhibit desirable performance at such points, indicating that Stackelber g equilibria can be as desirable as Nash equilibria. Lastly , the Stackelberg learning dynamics often con verge to non-Nash attractors and reach a satisfying solution quickly using learning rates that can cause the simultaneous gradient descent dynamics to cycle. Related W ork. The perspective we explore on analyzing games in which there is an order of play or hi- erarchical decision making structure has been generally ignored in the modern learning literature. Howe ver , 3 F I E Z , C H A S N OV , R A T L I FF this vie wpoint has long been researched in the control literature on games [ 4 , 5 , 29 , 47 , 48 ]. Similarly , work on bile vel optimization [ 16 , 17 , 59 ] adopts this perspecti ve. The select fe w recent works in the machine learning literature on learning in games considering a hierar - chical decision-making structure e xclusively focus on zero-sum games [ 18 , 28 , 34 , 42 , 46 ], unlike our work, which e xtends to general-sum games. A notew orthy paper in the line of w ork in the zero-sum setting adopt- ing a min-max perspecti ve was the introduction of unrolled GANs [ 42 ]. The authors consider a timescale separation between the generator and discriminator , gi ving the generator the adv antage as the slo wer player . This work used the Schur complement structure presented in Danskin [ 16 , 17 ] to define a minimax solution of a zero-sum g ame abstraction of an adversarial training objecti ve. Essentially the discriminator is allo wed to perform a finite roll-out in an inner loop of the algorithm with multiple updates; this process is referred to as ‘unrolling’. It is (informally) suggested that, using the results of Danskin [ 16 , 17 ], as the roll-out horizon approaches infinity , the discriminator approaches a critical point of the cost function along the discriminators axis gi ven a fix ed generator parameter configuration. The unrolling procedure has the same ef fect as a deterministic timescale separation between players. Formal con ver gence guarantees to minimax equilibria in zero-sum games characterizing the limiting beha v- ior of simultaneous individual gradient descent with timescale separation were recently obtained [ 28 , 34 ]. While related, simultaneous indi vidual gradient play with time-scale separation is a distinct set of dynamics that departs from the dynamics we propose that reflect the Stackelber g game structure. It is also w orth pointing out that the multi-agent learning papers of F oerster et al. [ 21 ] and Letcher et al. [ 33 ] do in some sense seek to gi ve a player an adv antage, but nev ertheless focus on the Nash equilibrium concept in any analysis that is pro vided. Organization. In Section 2 , we formalize the problem we study and provide background material on Stackelber g games. W e then draw connections between learning in Stackelber g games and existing w ork in zero-sum and general sum-games rele vant to GANs and multi-agent learning, respecti vely . In Section 3 , we gi ve a rigorous con ver gence analysis of learning in Stackelber g games. Numerical e xamples are provided in Section 4 and we conclude in Section 5 . 2. Preliminaries W e lev erage the rich theory of continuous games and dynamical systems in order to analyze algorithms im- plemented by agents interacting in a hierarchical game. In particular , each agent has an objectiv e they want to selfishly optimize that depends on not only their o wn actions but also on the actions of their competitor . Ho we ver , there is an order of play in the sense that one player is the leader and the other player is the fol- lo wer 1 . The leader optimizes its objecti ve with the kno wledge that the follo wer will respond by selecting a best response. W e refer to algorithms for learning in this setting as hierar chical learning algorithms. W e specifically consider a class of learning algorithms in which the agents act myopically with respect to their gi ven objectiv e and role in the underlying hierarchical game by follo wing the gradient of their objecti ve with respect to their choice v ariable. T o substantiate this abstraction, consider a game between two agents where one agent is deemed the leader and the other the follower . The leader has cost f 1 : X → R and the follower has cost f 2 : X → R , where X = X 1 × X 2 with the action space of the leader being X 1 and the action space of the follo wer being X 2 . The designation of ‘leader’ and ‘follower’ indicates the order of play between the two agents, meaning the leader plays first and the follo wer second. The leader and the follower need not be cooperati ve. Such a game is kno wn as a Stackelber g game . 1. While we present the work for a single leader and a single follower , the theory extends to the multi-follower case (we discuss this in Appendix F ) and to the case where the single leader abstracts multiple cooperating agents. 4 2.1 Stackelberg Games Let us adopt the typical game theoretic notation in which the player index set is I and x − i = ( x j ) j ∈I / { i } denotes the joint action profile of all agents excluding agent i . In the Stackelberg case, I = { 1 , 2 } where player i = 1 is the leader and player i = 2 is the follower . W e assume throughout that each f i is suf ficiently smooth, meaning f i ∈ C q ( X , R ) for some q ≥ 2 and for each i ∈ I . The leader aims to solve the optimization problem gi ven by min x 1 ∈ X 1 n f 1 ( x 1 , x 2 ) x 2 ∈ arg min y ∈ X 2 f 2 ( x 1 , y ) o and the follo wer aims to solve the optimization problem min x 2 ∈ X 2 f 2 ( x 1 , x 2 ) . As noted abo ve, the learning algorithms we study are such that the agents follo w myopic update rules which take steps in the direction of steepest descent with respect to the above two optimizations problems, the former for the leader and the latter for the follo wer . Before formalizing these updates, let us first discuss the equilibrium concept studied for simultaneous play games and contrast it with that which is studied in the hierarchical play counterpart. The typical equilibrium notion in continuous games is the pure strategy Nash equilibrium in simultaneous play games and the Stackelber g equilibrium in hierarchical play games. Each notion of equilibria can be characterized as the intersection points of the reaction curves of the players [ 4 ]. Definition 1 (Nash Equilibrium) . The joint strate gy x ∗ ∈ X is a Nash equilibrium if for each i ∈ I , f i ( x ∗ ) ≤ f i ( x i , x ∗ − i ) , ∀ x i ∈ X i . The strate gy is a local Nash equilibrium on W ⊂ X if for each i ∈ I , f i ( x ∗ ) ≤ f i ( x i , x ∗ − i ) , ∀ x i ∈ W i ⊂ X i . Definition 2 (Stackelberg Equilibrium) . In a two-player game with player 1 as the leader , a strate gy x ∗ 1 ∈ X 1 is called a Stack elberg equilibrium str ate gy for the leader if sup x 2 ∈R ( x ∗ 1 ) f 1 ( x ∗ 1 , x 2 ) ≤ sup x 2 ∈R ( x 1 ) f 1 ( x 1 , x 2 ) , ∀ x 1 ∈ X 1 , wher e R ( x 1 ) = { y ∈ X 2 | f 2 ( x 1 , y ) ≤ f 2 ( x 1 , x 2 ) , ∀ x 2 ∈ X 2 } is the rational r eaction set of x 2 . This definition naturally extends to the n -follower setting when R ( x 1 ) is replaced with the set of Nash equilibria NE ( x 1 ) , gi ven that player 1 is playing x 1 so that the follo wer’ s reaction set is a Nash equilibrium. W e denote D i f i as the deri vati ve of f i with respect to x i , D ij f i as the partial deriv ativ e of D i f i with respect to x j , and D ( · ) as the total deriv ati ve 2 . Denote by ω ( x ) = ( D 1 f 1 ( x ) , D 2 f 2 ( x )) the vector of indi- vidual gradients for simultaneous play and ω S ( x ) = ( D f 1 ( x ) , D 2 f 2 ( x )) as the equiv alent for hierarchical play where D f 1 is the total deri v ati ve of f 1 with respect to x 1 and x 2 is implicitly a function of x 2 , which captures the fact that the leader operates under the assumption that the follower will play a best response to its choice of x 1 . It is possible to characterize a local Nash equilibrium using suf ficient conditions for Definition 1 . Definition 3 (Dif ferential Nash Equilibrium [ 50 ]) . The joint strate gy x ∗ ∈ X is a differ ential Nash equilib- rium if ω ( x ∗ ) = 0 and D 2 i f i ( x ∗ ) > 0 for each i ∈ I . 2. For example, gi ven a function f ( x, r ( x )) , Df = D 1 f + D 2 f ∂ r /∂ x . 5 F I E Z , C H A S N OV , R A T L I FF Analogous suf ficient conditions can be stated to characterize a local Stackelberg equilibrium strategy for the leader using first and second order conditions on the leader’ s optimization problem. Indeed, if D f 1 ( x ∗ 1 , r ( x ∗ 1 )) = 0 and D 2 f 1 ( x ∗ 1 , r ( x ∗ 1 )) is positive definite, then x ∗ 1 is a local Stackelberg equilibrium strategy for the leader . W e use these suf ficient conditions to define the following refinement of the Stackel- berg equilibrium concept. Definition 4 (Dif ferential Stackelberg Equilibrium) . The pair ( x ∗ 1 , x ∗ 2 ) ∈ X with x ∗ 2 = r ( x ∗ 1 ) , wher e r is implicitly defined by D 2 f 2 ( x ∗ 1 , x ∗ 2 ) = 0 , is a differ ential Stack elber g equilibrium for the game ( f 1 , f 2 ) with player 1 as the leader if D f 1 ( x ∗ 1 , r ( x ∗ 1 )) = 0 , and D 2 f 1 ( x ∗ 1 , r ( x ∗ 1 )) is positive definite.. Remark 1. Befor e moving on, let us make a few remarks about similar , and in some cases analogous, equilibrium definitions. F or zer o-sum games, the differ ential Stack elber g equilibrium notion is the same as a local min-max equilibrium for a sufficiently smooth cost function f . This is a well-known concept in optimization (see, e.g., [ 4 , 16 , 17 ], among others), and it has r ecently been intr oduced in the learning literatur e [ 28 ]. The benefit of the Stackelber g perspective is that it generalizes fr om zer o-sum games to gener al-sum games, while the min-max equilibrium notion does not. A number of adversarial learning formulations ar e in fact general-sum, often as a r esult of r e gularization and well-performing heuristics that augment the cost functions of the gener ator or the discriminator . W e utilize these local characterizations in terms of first and second order conditions to formulate the myopic hierarchical learning algorithms we study . Follo wing the preceding discussion, consider the learning rule for each player to be gi ven by x i,k +1 = x i,k − γ i,k ( ω S ,i ( x k ) + w i,k +1 ) , (1) recalling that ω S = ( D f 1 ( x ) , D 2 f 2 ( x )) and the notation ω S ,i indicates the entry of ω S corresponding to the i –th player . Moreov er , { γ i,k } the sequence of learning rates and { w i,k } is the noise process for player i , both of which satisfy the usual assumptions from theory of stochastic approximation provided in detail in Section 3 . W e note that the component of the update ω S ,i ( x k ) + w i,k +1 captures the case in which each agent does not hav e oracle access to ω S ,i , but instead has an unbiased estimator for it. The giv en update formalizes the class of learning algorithms we study in this paper . Leader -Follower Timescale Separation. W e require a timescale separation between the leader and the follo wer: the leader is assumed to be learning at a slower rate than the follower so that γ 1 ,k = o ( γ 2 ,k ) . The reason for this timescale separation is that the leader’ s update is formulated using the reaction curve of the follo wer . In the gradient-based learning setting considered, the reaction curve can be characterized by the set of critical points of f 2 ( x 1 ,k , · ) that hav e a local positiv e definite structure in the direction of x 2 , which is { x 2 | D 2 f 2 ( x 1 ,k , x 2 ) = 0 , D 2 2 f 2 ( x 1 ,k , x 2 ) > 0 } . This set can be characterized in terms of an im plicit map r , defined by the leader’ s belief that the follo wer is playing a best response to its choice at each iteration, which would imply D 2 f 2 ( x 1 ,k , x 2 ,k ) = 0 . Moreov er , under sufficient regularity conditions, the implicit mapping theorem [ 32 ] giv es rise to the implicit map r : U → X 2 : x 1 7→ x 2 on a neighborhood U ⊂ X 1 of x 1 ,k . Formalized in Section 3 , we note that when r is defined uniformly in x 1 on the domain for which con ver gence is being assessed, the update in ( 1 ) is well-defined in the sense that the component of the deri vati ve D f 1 corresponding to the implicit dependence of the follo wer’ s action on x 1 via r is well-defined and locally consistent. In particular, for a giv en point x = ( x 1 , x 2 ) such that D 2 f 2 ( x 1 , x 2 ) = 0 with D 2 2 f 2 ( x ) an isomorphism, the implicit function theorem implies there e xists an open set U ⊂ X 1 such that there e xists a unique continuously dif ferentiable function r : U → X 2 such that r ( x 1 ) = x 2 and D 2 f 2 ( x 1 , r ( x 1 )) = 0 for all x 1 ∈ U . Moreover , D r ( x 1 ) = − ( D 2 2 f 2 ( x 1 , r ( x 1 ))) − 1 D 21 f 2 ( x 1 , r ( x 1 )) 6 on U . Thus, in the limit of the two-timescale setting, the leader sees the follower as ha ving equilibriated (meaning D 2 f 2 ≡ 0 ) so that D f 1 ( x 1 , x 2 ) = D 1 f 1 ( x 1 , x 2 ) + D 2 f 1 ( x 1 , x 2 ) D r ( x 1 ) (2) = D 1 f 1 ( x 1 , x 2 ) − D 2 f 1 ( x 1 , x 2 )( D 2 2 f 2 ( x 1 , x 2 )) − 1 D 21 f 2 ( x 1 , x 2 ) . The map r is an implicit representation of the follower’ s reaction curve. Overview of Analysis T echniques. The following describes the general approach to studying the hierar- chical learning dynamics in ( 1 ). The purpose of this ov erview is to provide the reader with the high-level architecture of the analysis approach. The analysis techniques we employ combine tools from dynamical systems theory with the theory of stochastic approximation. In particular , we lev erage the limiting continuous time dynamical systems deriv ed from ( 1 ) to characterize concentration bounds for iterates or samples generated by ( 1 ). W e note that the hierarchical learning update in ( 1 ) with timescale separation γ 1 ,k = o ( γ 2 ,k ) has a limiting dynamical system that takes the form of a singularly perturbed dynamical system giv en by ˙ x 1 ( t ) = − τ Df 1 ( x 1 ( t ) , x 2 ( t )) ˙ x 2 ( t ) = − D 2 f 2 ( x 1 ( t ) , x 2 ( t )) (3) which, in the limit as τ → 0 , approximates ( 1 ). The limiting dynamical system has known con vergence properties (asymptotic con ver gence in a region of attraction for a locally asymptotically stable attractor). Such con vergence properties can be translated in some sense to the discrete time system by comparing pseudo-trajectories —in this case, linear interpolations between sample points of the update process—generated by sample points of ( 1 ) and the limiting system flo w for initializations containing the set of sample points of ( 1 ). Indeed, the limiting dynamical system is then used to generate flows initialized from the sample points generated by ( 1 ). Creating pseudo-trajectories, we then bound the probability that the pseudo-trajectories deviate by some small amount from the limiting dynamical system flow ov er each continuous time interv al between the sample points. A concentration bound can be constructed by taking a union bound ov er each time interv al after a finite time; follo wing this we can guarantee the sample path has entered the re gion of attraction, on which we can produce a L yapuno v function for the continuous time dynamical system. The analysis in this paper is based on the high-level ideas outlined in this section. 2.2 Connections and Implications Before presenting con vergence analysis of the update in ( 1 ), we draw some connections to application domains—including adversarial learning, where zero-sum game abstractions hav e been touted for finding robust parameter configurations for neural networks, and opponent shaping in multi-agent learning—and equilibrium concepts commonly used in these domains. Let us first remind the reader of some common definitions from dynamical systems theory . Gi ven a suf ficiently smooth function f ∈ C q ( X , R ) , a critical point x ∗ of f is said to be stable if for all t 0 ≥ 0 and ε > 0 , there exists δ ( t 0 , ε ) such that x 0 ∈ B δ ( x ∗ ) = ⇒ x ( t ) ∈ B ε ( x ∗ ) , ∀ t ≥ t 0 Further , x ∗ is said to be asymptotically stable if x ∗ is additionally attracti ve—that is, for all t 0 ≥ 0 , there exists δ ( t 0 ) such that x 0 ∈ B δ ( x ∗ ) = ⇒ lim t →∞ k x ( t ) − x ∗ k = 0 . 7 F I E Z , C H A S N OV , R A T L I FF A critical point is said to be non-de generate if the determinant of the Jacobian of the dynamics at the critical point is non-zero. For a non-degenerate critical point, the Hartman-Grobman theorem [ 55 ] enables us to check the eigen values of the Jacobian to determine asymptotic stability . In particular , at a non-degenerate critical point, if the eigen values of the Jacobian are in the open left-half complex plane, then the critical point is asymptotically stable. The dynamical systems we study in this paper are of the form ˙ x = − F ( x ) for some vector field F determined by the gradient based update rules employed by the agents. Hence, to determine if a critical point is stable, we simply need to check that the spectrum of the Jacobian of F is in the open right-half complex plane. For the dynamics ˙ x = − ω ( x ) , let J ( x ) denote the Jacobian of the vector field ω ( x ) . Similarly , for the dynamics ˙ x = − ω S ( x ) , let J S ( x ) denote the Jacobian of the v ector field ω S ( x ) . Then, we say a dif ferential Nash equilibrium of a continuous game with corresponding individual gradient vector field ω is stable if sp ec( J ( x )) ⊂ C ◦ + where sp ec( · ) denotes the spectrum of its argument and C ◦ + denotes the open right-half complex plane. Similarly , we say differential Stack elberg equilibrium is stable if spec( J S ( x )) ⊂ C ◦ + . 2.2.1 Implications for Zer o-Sum Settings Zero-sum games are a very special class since there is a strong connection between Nash equilibria and Stackelber g equilibria. Let us first show that for zero-sum games, attracting critical points of ˙ x = − ω S ( x ) are dif ferential Stackelber g equilibria. Proposition 1. Attracting critical points of ˙ x = − ω S ( x ) in continuous zer o-sum games ar e differ ential Stack elberg equilibria. That is, given a zer o-sum game ( f , − f ) defined by a sufficiently smooth function f ∈ C q ( X , R ) with q ≥ 2 , any stable critical point x ∗ of the dynamics ˙ x = − ω S ( x ) is a differ ential Stack elberg equilibrium. Proof . Consider an arbitrary sufficiently smooth zero-sum game ( f , − f ) on continuous strategy spaces. The Jacobian of the Stackelber g limiting dynamics ˙ x = − ω S ( x ) at a stable critical point is x ∗ J S ( x ∗ ) = D 1 ( D f )( x ∗ ) 0 − D 21 f ( x ∗ ) − D 2 2 f ( x ∗ ) > 0 . (4) The structure of the Jacobian J S ( x ∗ ) follows from the f act that D 2 ( D f )( x ∗ ) = D 12 f ( x ∗ ) − D 12 f ( x ∗ )( D 2 2 f ( x ∗ )) − 1 D 2 2 f ( x ∗ ) = 0 . The eigen values of a lo wer triangular block matrix are the union of the eigen values in each of the block diag- onal components. This implies that if J S ( x ∗ ) > 0 , then necessarily D 1 ( D f )( x ∗ ) > 0 and − D 2 2 f ( x ∗ ) > 0 . Consequently , any stable critical point of the Stackelberg limiting dynamics must be a differential Stackel- berg equilibrium by definition. The result of Proposition 1 implies that with appropriately chosen stepsizes the only attracting critical points of the update rule in ( 1 ) will be Stackelberg equilibria and thus, unlike simultaneous play individual gra- dient descent (known as gradient-play in the game theory literature), will not con verge to spurious locally asymptotically stable attractors of the dynamics that are not rele v ant to the underlying game. In a recent work on GANs [ 42 ], hierarchical learning of a similar nature proposed in this paper is studied in the context of zero-sum games. In the author’ s formulation, the generator is deemed the leader and the discriminator as the follo wer . The idea is to allow the discriminator to take k individual gradient steps to update its parameters, while the parameters of the generator are held fix ed. The ef fect of ‘unrolling’ the dis- criminator update for k steps is that a surrogate objecti ve of f ( x 1 , r 2 ( x 1 )) arises for the generator , meaning that the timescale-separation between the discriminator and the follower induces an update reminiscent of that gi ven for the leader in ( 2 ). In particular, when k → ∞ the follower con verges to a local optimum as a 8 function of the generator’ s parameters so that D 2 f ( x 1 , x 2 ) → 0 . As a result, the critical points coincide with the Stack elberg dynamics we study , indicating that unrolled GANs are con ver ging only to Stack elberg equi- libria. Empirically , GANs learned with such timescale separation procedures seem to outperform gradient descent with uniform stepsizes [ 42 ], providing e vidence Stackelberg equilibria can be suf ficient in GANs. This begs a further question of if attractors of the dynamics ˙ x = − ω ( x ) are Stackelberg equilibria. W e begin to answer this inquiry by sho wing that stable differential Nash are dif ferential Stackelberg equilibria. Proposition 2. Stable dif fer ential Nash equilibria in continuous zer o-sum games ar e differ ential Stack elber g equilibria. That is, given a zer o-sum game ( f , − f ) defined by a sufficiently smooth function f ∈ C q ( X , R ) with q ≥ 2 , a stable differ ential Nash equilibrium x ∗ is a differ ential Stack elberg equilibrium. Proof . Consider an arbitrary sufficiently smooth zero-sum game ( f , − f ) on continuous strategy spaces. Suppose x ∗ is a stable differential Nash equilibrium so that by definition D 2 1 f ( x ∗ ) > 0 , − D 2 2 f ( x ∗ ) > 0 , and J ( x ∗ ) = D 2 1 f ( x ∗ ) D 12 f ( x ∗ ) − D 21 f ( x ∗ ) − D 2 2 f ( x ∗ ) > 0 . Then, the Schur complement of J ( x ∗ ) is also positiv e definite: D 2 1 f ( x ∗ ) − D 21 f ( x ∗ ) > ( D 2 2 f ( x ∗ )) − 1 D 21 f ( x ∗ ) > 0 Hence, x ∗ is a dif ferential Stackelber g equilibrium since the Schur complement of J is e xactly the deri vati ve D 2 f at critical points and − D 2 2 f ( x ∗ ) > 0 since x is a differential Nash equilibrium. Remark 2. In the zer o-sum setting, the fact that Nash equilibria ar e a subset of Stackelber g equilibria (or minimax equilibria) for finite games is well-known [ 4 ]. W e show the r esult for the notion of differ ential Stack elberg equilibria for continuous action space games that we intr oduce. Similar to our work and con- curr ently , Jin et al. [ 28 ] also show that local Nash equilibria ar e local minmax solutions for continuous zer o-sum games. It is inter esting to point out that for a subclass of zer o-sum continuous games with a con vex-concave structur e for the leader’ s cost the set of (differ ential) Nash and (differ ential) Stackelber g equilibria coincide. Indeed, D 2 1 f ( x ) > 0 at critical points for con vex-concave games, so that if x is a differ ential Stack elberg equilibrium, it is also a Nash equilibrium. This result indicates that recent works seeking Nash equilibria in GANs are seeking Stack elberg equilib- ria concurrently . Giv en that it is well-known simultaneous gradient play can con verge to attracting critical points that do not satisfy the conditions of a Nash equilibria, it remains to determine when such spurious non- Nash attractors of the dynamics ˙ x = − ω ( x ) will be an attractor of the Stack elberg dynamics ˙ x = − ω S ( x ) . Let us start with a motiv ating question: when ar e non-Nash attractors of ˙ x = − ω ( x ) dif ferential Stac k- elber g equilibria? It was shown by Jin et al. [ 28 ] that not all attractors of ˙ x = − ω ( x ) are local min-max or local max-min equilibria since one can construct a function such that D 2 1 f ( x ) and − D 2 2 f ( x ) are both not positiv e definite but J ( x ) has positiv e eigen values. It appears to be much harder to characterize when a non-Nash attractor of ˙ x = − ω ( x ) is a differential Stackelberg equilibrium since being a differential Stack- elberg equilibrium requires the follower’ s individual Hessian to be positiv e definite. Indeed, it reduces to a fundamental problem in linear algebra in which the relationship between the eigen values of the sum of two matrices is largely unknown without assumptions on the structure of the matrices [ 30 ]. For the class of zero- sum games, in what follo ws we provide some necessary and suf ficient conditions for non-Nash attractors at which the follo wer’ s Hessian is positiv e definite to be a dif ferential Stackelberg equilibria. Before doing so, we present an illustrati ve example in which se veral attracting critical points of the simultaneous gradient play dynamics are not differential Nash equilibria b ut are differential Stackelberg equilibria—meaning points x ∈ X at which − D 2 2 f ( x ) > 0 , sp ec( J ( x )) ⊂ C ◦ + , and D 2 1 f ( x ) − D 21 f ( x ) > ( D 2 2 f ( x )) − 1 D 21 f ( x ) > 0 . 9 F I E Z , C H A S N OV , R A T L I FF 15 10 5 0 5 10 15 x 1 ( p l a y e r 1 ' s a c t i o n ) 15.0 12.5 10.0 7.5 5.0 2.5 0.0 2.5 5.0 x 2 ( p l a y e r 2 ' s a c t i o n ) x 0 simgrad - s t a c k DSE/Non-Nash DSE & DNE Figure 1: Simultaneous gradient play is attracted to non-Nash differential Stackelberg equilibria: The game is given by the pair of cost functions ( f , − f ) where f is defined in ( 5 ) with a = 0 . 15 and b = 0 . 25 . There are two non-Nash attractors of simultaneous gradient play which are also differential Stack elberg equilibria. Example 1 (Non-Nash Attractors are Stackelber g.) . Consider the zer o-sum game defined by f ( x ) = − e − 0 . 01( x 2 1 + x 2 2 ) (( ax 2 1 + x 2 ) 2 + ( bx 2 2 + x 1 ) 2 ) . (5) Let player 1 be the leader who aims to minimize f with r espect to x 1 taking into consideration that player 2 (follower) aims to minimize − f with r espect to x 2 . In F ig. 1 , we show the trajectories for various initial- izations for this game with ( a, b ) = (0 . 15 , 0 . 25) ; it can be seen that for se veral initializations, simultaneous gradient play leads to non-Nash attr actors which ar e differ ential Stackelber g equilibria. W e no w proceed to provide necessary and suf ficient conditions for the phenenom demonstrated in Ex- ample 1 . Attracting critical points x ∗ of the dynamics ˙ x = − ω ( x ) that are not Nash equilibria are such that either D 2 1 f ( x ∗ ) or − D 2 2 f ( x ∗ ) are not positiv e definite. W ithout loss of generality , considering player 1 to be the leader, an attractor of the Stackelber g dynamics ˙ x = − ω S ( x ) requires both − D 2 2 f ( x ∗ ) and D 2 1 f ( x ∗ ) − D 21 f ( x ∗ ) > ( D 2 2 f ( x ∗ )) − 1 D 21 f ( x ∗ ) to be positive definite. Hence, if − D 2 2 f ( x ∗ ) is not positive definite at a non-Nash attractor of ˙ x = − ω ( x ) , then x ∗ will also not be an attractor of ˙ x = − ω S ( x ) . W e focus on non-Nash attractors with − D 2 2 f ( x ∗ ) > 0 and seek to determine when the Schur complement is positi ve definite, so that x ∗ is an attractor of ˙ x = ω S ( x ) . In the follo wing two propositions, we need some addition notion that is common across the two results. Let x 1 ∈ R m and x 2 ∈ R n . For a non-Nash attracting critical point x ∗ , let sp ec( D 2 1 f ( x ∗ )) = { µ j , j ∈ { 1 , . . . , m }} where µ 1 ≤ · · · ≤ µ r < 0 ≤ µ r +1 ≤ · · · ≤ µ m , and let sp ec( − D 2 2 f ( x ∗ )) = { λ i , i ∈ { 1 , . . . , n }} where λ 1 ≥ · · · ≥ λ n > 0 , and define p = dim(k er( D 2 1 f ( x ∗ ))) . Proposition 3 (Necessary conditions) . Consider a non-Nash attracting critical point x ∗ of the gradient dynamics ˙ x = − ω ( x ) such that − D 2 2 f ( x ∗ ) > 0 . Given κ > 0 such that k D 21 f ( x ∗ ) k ≤ κ , if D 2 1 f ( x ∗ ) − D 21 f ( x ∗ ) > ( D 2 2 f ( x ∗ )) − 1 D 21 f ( x ∗ ) > 0 , then r ≤ n and κ 2 λ i + µ i > 0 for all i ∈ { 1 , . . . , r − p } . Proposition 4 (Suf ficient conditions) . Let x ∗ be a non-Nash attracting critical point of the individual gradi- ent dynamics ˙ x = − ω ( x ) such that D 2 1 f ( x ∗ ) and − D 2 2 f ( x ∗ ) ar e Hermitian, and − D 2 2 f ( x ∗ ) > 0 . Suppose that ther e exists a diagonal matrix (not necessarily positive) Σ ∈ C m × n with non-zer o entries such that D 12 f ( x ∗ ) = W 1 Σ W ∗ 2 wher e W 1 ar e the orthonormal eigen vectors of D 2 1 f ( x ∗ ) and W 2 ar e orthonormal 10 eigen vectors of − D 2 2 f ( x ∗ ) . Given κ > 0 suc h that k D 21 f ( x ∗ ) k ≤ κ , if r ≤ n and κ 2 λ i + µ i > 0 for each i ∈ { 1 , . . . , r − p } , then x ∗ is a differ ential Stack elberg equilibrium and an attr actor of ˙ x = − ω S ( x ) . The proofs of the above results follow from some results linear algebra and are both in Appendix A.1 . Essentially , this says that if D 2 1 f ( x ∗ ) = W 1 M W ∗ 1 with W 1 W ∗ 1 = I n × n and M diagonal, and − D 2 2 f ( x ∗ ) = W 2 Λ W ∗ 2 with W 2 W ∗ 2 = I m × m and Λ diagonal, then D 12 f ( x ∗ ) can be written as W 1 Σ W ∗ 2 for some diagonal matrix Σ ∈ R n × m (not necessarily positive). Note that since Σ does not necessarily hav e positi ve values, W 1 Σ W ∗ 2 is not the singular v alue decomposition of D 12 f ( x ∗ ) . In turn, this means that the each eigen vector of D 2 1 f ( x ∗ ) get mapped onto a single eigen vector of − D 2 2 f ( x ∗ ) through the transformation D 12 f ( x ∗ ) which describes ho w player 1’ s v ariation D 1 f ( x ) changes as a function of player 2’ s choice. With this structure for D 12 f ( x ∗ ) , we can sho w that D 2 1 f ( x ∗ ) − D 21 f ( x ∗ ) > ( D 2 2 f ( x ∗ )) − 1 D 21 f ( x ∗ ) > 0 . If we remov e the assumption that Σ has non-zero entries, then the remaining assumptions are still sufficient to guarantee that D 2 1 f ( x ∗ ) − D 21 f ( x ∗ ) > ( D 2 2 f ( x ∗ )) − 1 D 21 f ( x ∗ ) ≥ 0 . This means that x ∗ does not satisfy the conditions for a differential Stackelberg, ho wever , the point does satisfy necessary conditions for a local Stack elberg equilibrium and the point is a mar ginally stable attractor of the dynamics. While the results depend on conditions that are difficult to check a priori without knowledge of x ∗ , certain classes of games for which these conditions hold ev erywhere and not just at the equilibrium can be constructed. For instance, alternativ e conditions can be giv en: if the function f which defines the zero-sum game is such that it is conca ve in x 2 and there exists a K such that D 12 f ( x ) = K D 2 2 f ( x ) where sup x k D 12 f ( x ) k ≤ κ < ∞ 3 and K = W 1 Σ W ∗ 2 with Σ again a (not necessarily positive) diagonal matrix, then the results of Proposition 4 hold. From a control point of vie w , one can think about the leader’ s update as having a feedback term with the follower’ s input. On the other hand, the results are useful for the synthesis of games, such as in rew ard shaping or incenti ve design, where the goal is to drive agents to particular desirable behavior . W e remark that the fact that the eigen v alues of J ( x ∗ ) are in the open-right-half complex plane is not used in proving this result. W e believ e that further in vestigation could lead to a less restricti ve suf- ficient condition. Empirically , by randomly generating the different block matrices, it is quite dif ficult to find examples such that J ( x ∗ ) has positiv e eigen v alues, − D 2 2 f ( x ∗ ) > 0 , and the Schur complement D 2 1 f ( x ∗ ) − D 21 f ( x ∗ ) > ( D 2 2 f ( x ∗ )) − 1 D 21 f ( x ∗ ) is not positi ve definite. In fact, for games on scalar action spaces, it turns out that non-Nash attracting critical points of the simultaneous gradient play dynamics at which − D 2 2 f ( x ∗ ) > 0 must be differential Stackelberg equilibria and attractors of the Stackelberg limiting dynamics. Corollary 1. Consider a zer o-sum game ( f , − f ) defined by a sufficiently smooth cost function f : R 2 → R such that the action space is X = R × R and player 1 is deemed the leader and player 2 the follower . Then, any non-Nash attracting critical point of ˙ x = − ω ( x ) at which − D 2 2 f ( x ) > 0 is a differ ential Stack elberg equilibrium and an attractor of ˙ x = − ω S ( x ) . Proof . Consider a sufficiently smooth zero-sum game ( f , − f ) on continuous strategy spaces defined by the cost function f : R 2 → R . Suppose x ∗ is an attracting critical point of the dynamics ˙ x = − ω ( x ) at which − D 2 2 f ( x ∗ ) > 0 and D 2 1 f ( x ∗ ) < 0 so that it is not a Nash equilibria. The Jacobian of the dynamics at a stable critical point is J ( x ∗ ) = D 2 1 f ( x ∗ ) D 12 f ( x ∗ ) − D 21 f ( x ∗ ) − D 2 2 f ( x ∗ ) > 0 . 3. Functions such that deriv ative of f is Lipschitz will satisfy this condition. 11 F I E Z , C H A S N OV , R A T L I FF The fact that the real components of the eigenv alues of the Jacobian are positi ve implies that D 12 f ( x ∗ ) D 21 f ( x ∗ ) > D 2 1 f ( x ∗ ) D 2 2 f ( x ∗ ) and D 2 1 f ( x ∗ ) > D 2 2 f ( x ∗ ) since the determinant and the trace of the Jacobian must be positi ve. Using this information, it directly follows that the Schur complement of J ( x ∗ ) is positiv e definite: D 2 1 f ( x ∗ ) − D 12 f ( x ∗ )( D 2 2 f ( x ∗ )) − 1 D 21 f ( x ∗ ) > 0 . As a result, x ∗ is a dif ferential Stackelber g equilibrium and an attractor of ˙ x = − ω S ( x ) since the Schur complement of J ( x ∗ ) is the deriv ativ e D 2 f ( x ∗ ) and − D 2 2 f ( x ) > 0 was gi ven. W e suspect that using the notion of quadratic numerical range [ 58 ], which is a super set of the spectrum of a block operator matrix, along with the fact that the Jacobian of the simultaneous gradient play dynamics has its spectrum in the open right-half complex plane, may lead to an extension of the result to arbitrary dimensions. The results of Propositions 3 and 4 , Corollary 1 , and Example 1 imply that some of the non-Nash at- tractors of ˙ x = − ω ( x ) are in fact Stackelberg equilibria. This is a meaningful insight since recent works hav e proposed schemes to av oid non-Nash attractors of the dynamics as they ha ve been classified or vie wed as lacking game-theoretic meaning [ 37 ]. Moreo ver , some recent empirical results show that a number of successful approaches to training GANs are not con ver ging to Nash equilibria, but rather to non-Nash at- tractors of the dynamics [ 8 ]. It would be interesting to characterize whether or not the attractors satisfy the conditions we propose, and if such conditions could provide insights into how to improv e GAN training. It also further suggests that the Stackelber g equilibria may be a suitable solution concept for GANs. One of the common assumptions in some of the recent GANs literature is that the discriminator net- work is zero in a neighborhood of an equilibrium parameter configuration (see, e.g., [ 41 , 43 , 44 ]). This assumption limits the theory to the ‘realizable’ case; the work by [ 43 ] provides relaxed assumptions for the non-realizable case. In both cases, the Jacobian for the dynamics ˙ x = − ω ( x ) is such that D 2 1 f ( x ∗ ) = 0 . Proposition 5. Consider a GAN satisfying the r ealizable assumption—that is, the discriminator network is zer o in a neighborhood of any equilibrium. Then, an attracting critical point for the simultaneous gradient dynamics ˙ x = − ω ( x ) at which − D 2 2 f is positive semi-definite satisfies necessary conditions for a local Stack elberg equilibrium, and it will be a mar ginally stable point of the Stac kelber g dynamics ˙ x = − ω S ( x ) . Proof . Consider an attracting critical point x of ˙ x = − ω ( x ) such that − D 2 2 f ( x ∗ ) ≥ 0 . Note that the realizable assumption implies that the Jacobian of ω is J ( x ∗ ) = 0 D 12 f ( x ∗ ) − D 21 f ( x ∗ ) − D 2 2 f ( x ∗ ) (see, e.g., [ 43 ]). Hence, since − D 2 2 f ( x ∗ ) ≥ 0 , − D > 21 f ( x ∗ )( D 2 2 f ) − 1 ( x ∗ ) D 21 f ( x ∗ ) ≥ 0 . Since x ∗ is an attractor , D 1 f ( x ∗ ) = 0 and D 2 f ( x ∗ ) = 0 so that D f ( x ∗ ) = D 1 f ( x ∗ ) + D 2 f ( x ∗ )( D 2 2 f ) − 1 ( x ∗ ) D 21 f ( x ∗ ) = 0 Consequently , the necessary conditions for a local Stackelber g equilibrium are satisfied. Moreov er , since both − D 2 2 f ( x ∗ ) ≥ 0 and the Schur complement − D > 21 f ( x ∗ )( D 2 2 ) − 1 f ( x ∗ ) D 21 f ( x ∗ ) ≥ 0 , the Jacobian of ω S is positi ve semi-definite so that the point x ∗ is marginally stable. No w , simply satisfying the necessary conditions is not enough to guarantee that attractors of the simul- taneous play gradient dynamics will be a local Stackelberg equilibrium. W e can state suf ficient conditions by examining Proposition 4 . 12 Proposition 6. Consider a GAN satisfying the r ealizable assumption—that is, the discriminator network is zer o in a neighborhood of any equilibrium—and an attractor for the simultaneous gradient dynamics ˙ x = − ω ( x ) at whic h − D 2 2 f is positive definite. Suppose that ther e e xists a diagonal matrix Σ with non-zer o entries suc h that D 12 f ( x ∗ ) = Σ W wher e W ar e the orthonormal eig en vectors of − D 2 2 f ( x ∗ ) . Then, x ∗ is a differ ential Stack elberg equilibrium and an attr actor of ˙ x = − ω S ( x ) . The proof follows directly from Proposition 4 and Proposition 5 . It is not directly clear how restrictiv e these suf ficient conditions are for GANs. W e leave this for future inquiry . 2.2.2 Connections to Opponent Shaping Beyond the work in zero-sum games and applications to GANs, there has also been recent work, which we will refer to as ‘opponent shaping’, where one or more players takes into account its opponents’ response to their action [ 21 , 33 , 60 ]. The initial work of Foerster et al. [ 21 ] bears the most resemblance to the learning algorithms studied in this paper . The update rule (LOLA) considered there (in the deterministic setting with constant stepsizes) takes the follo wing form: x + 1 = x 1 − γ 1 ( D 1 f 1 ( x ) − γ 2 D 2 f 1 ( x ) D 21 f 2 ( x )) x + 2 = x 2 − γ 2 D 2 f 2 ( x ) The attractors of these dynamics are not necessarily Nash equilibria nor are they Stackelberg equilibria as can be seen by looking at the critical points of the dynamics. Indeed, the LOLA dynamics lead only to Nash or non-Nash stable attractors of the limiting dynamics. The effect of the additional ‘look-ahead’ term is simply that it changes the vector field and region of attraction for stable critical points. In the zero-sum case, ho wev er , the critical points of the abo ve are the same as those of simultaneous play indi vidual gradient updates, yet the Jacobian is not the same and it is still possible to con verge to a non-Nash attractor . W ith a few modifications, the abov e update rule can be massaged into a form which more closely resem- bles the hierarchical learning rules we study in this paper . In particular , if instead of γ 2 , player 2 employed a Ne wton stepsize of ( D 2 2 f 2 ) − 1 , then the update would look like x + 1 = x 1 − γ 1 ( D 1 f 1 ( x ) − D 2 f 1 ( x )( D 2 2 f 2 ( x )) − 1 D 21 f 2 ( x )) x + 2 = x 2 − γ 2 D 2 f 2 ( x ) which resembles a deterministic version of ( 1 ). The critical points of this update coincide with the critical points of a Stackelberg game ( f 1 , f 2 ) . With appropriately chosen stepsizes and with an initialization in a region on which the implicit map, which defines the − ( D 2 2 f 2 ( x )) − 1 D 21 f 2 ( x ) component of the update, is well-defined uniformly in x 1 , the above dynamics will con ver ge to Stackelberg equilibria. In this paper , we provide an in-depth con ver gence analysis and for the stochastic setting 4 of the abov e update. 2.2.3 Comparing Nash and Stackelberg Equilibrium Cost W e hav e alluded to the idea that the ability to act first giv es the leader a distinct adv antage ov er the follo wer in a hierarchical game. W e now formalize this statement with a kno wn result that compares the cost of the leader at Nash and Stackelber g equilibrium. Proposition 7. ([ 4 , Pr oposition 4.4]). Consider an arbitrary sufficiently smooth two-player general-sum game ( f 1 , f 2 ) on continuous strate gy spaces. Let f N 1 denote the infimum of all Nash equilibrium costs for player 1 and f S 1 denote an arbitrary Stac kelber g equilibrium cost for player 1. Then, if R ( x 1 ) is a singleton for every x 1 ∈ X 1 , f S 1 ≤ f N 1 . 4. In [ 21 ], the authors do not provide con ver gence analysis; the y do in their extension, yet only for constant and uniform stepsizes and for a learning rule that is different than the one studied in this paper as all players are conjecturing about the behavior of their opponents. This distinguishes the present work from their setting. 13 F I E Z , C H A S N OV , R A T L I FF This result says that the leader ne ver f av ors the simultaneous play game ov er the hierarchical play game in two-player general-sum games with unique follower responses. On the other hand, the follo wer may or may not prefer the simultaneous play game ov er the hierarchical play game. The fact that under certain conditions the leader can obtain lower cost under a Stackelberg equilibrium compared to any of the Nash equilibrium may provide further explanation for the success of the methods in [ 42 ]. Commonly , the discriminator can o verpo wer the generator when training a GAN [ 42 ] and giving the generator an advantage may mitigate this problem. In the context of multi-agent learning, the advantage of the leader in hierarchical games leads to the question of ho w the roles of each player in a g ame are decided. While we do not focus on this question, it is worth noting that when each player mutually benefits from the leadership of a player the solution is called concurrent and when each player prefers to be the leader the solution is called non-concurrent. W e believ e that exploring classes of games in which each solution concept arises is an interesting direction of future work. 3. Con vergence Analysis Follo wing the preceding discussion, consider the learning rule for each player to be giv en by x i,k +1 = x i,k − γ i,k ( ω S ,i ( x k ) + w i,k +1 ) , (6) where recall that ω S = ( D f 1 ( x ) , D 2 f 2 ( x )) . Moreover , for each i ∈ I , { γ i,k } is the sequence of learning rates and { w i,k } is the noise process for player i . As before, suppose player 1 is the leader and conjectures that player 2 updates its action x 2 in each round via r ( x 1 ) . This setting captures the scenario in which players do not have oracle access to their gradients, b ut do hav e an unbiased estimator . As an example, players could be performing policy gradient reinforcement learning or alternativ e gradient-based learning schemes. Let dim( X i ) = d i for each i ∈ I and d = d 1 + d 2 . Assumption 1. The following hold: A1a. The maps D f 1 : R d → R d 1 , D 2 f 2 : R d → R d 2 ar e L 1 , L 2 Lipschitz, and k Df 1 k ≤ M 1 < ∞ . A1b . F or each i ∈ I , the learning rates satisfy P k γ i,k = ∞ , P k γ 2 i,k < ∞ . A1c. The noise pr ocesses { w i,k } ar e zer o mean, martingale differ ence sequences. That is, given the filtr ation F k = σ ( x s , w 1 ,s , w 2 ,s , s ≤ k ) , { w i,k } i ∈I ar e conditionally independent, E [ w i,k +1 | F k ] = 0 a.s., and E [ k w i,k +1 k| F k ] ≤ c i (1 + k x k k ) a.s. for some constants c i ≥ 0 , i ∈ I . Before diving into the con ver gence analysis, we need some machinery from dynamical systems theory . Consider the dynamics from ( 6 ) written as a continuous time combined system ˙ ξ t = F ( ξ t ) where ξ t ( z ) = ξ ( t, z ) is a continuous map and ξ = { ξ t } t ∈ R is the flo w of F . A set A is said to be in variant under the flo w ξ if for all t ∈ R , ξ t ( A ) ⊂ A , in which case ξ | A denotes the semi-flow . A point x is an equilibrium if ξ t ( x ) = x for all t and, of course, when ξ is induced by F , equilibria coincide with critical points of F . Let X be a topological metric space with metric ρ , an example being X = R d endo wed with the Euclidean distance. Definition 5. A nonempty in variant set A ⊂ X for ξ is said to be internally chain transitive if for any a, b ∈ A and δ > 0 , T > 0 , ther e exists a finite sequence { x 1 = a, x 2 , . . . , x k − 1 , x k = b ; t 1 , . . . , t k − 1 } with x i ∈ A and t i ≥ T , 1 ≤ i ≤ k − 1 , such that ρ ( ξ t i ( x i ) , x i +1 ) < δ , ∀ 1 ≤ i ≤ k − 1 . 3.1 Learning Stackelber g Solutions f or the Leader Suppose that the leader (player 1) operates under the assumption that the follower (player 2) is playing a local optimum in each round. That is, gi ven x 1 ,k , x 2 ,k +1 ∈ arg min x 2 f 2 ( x 1 ,k , x 2 ) for which D 2 f 2 ( x 1 ,k , x 2 ) = 0 is a first-order local optimality condition. If, for a gi ven ( x 1 , x 2 ) ∈ X 1 × X 2 , D 2 2 f 2 ( x 1 , x 2 ) is in vertible and 14 D 2 f 2 ( x 1 , x 2 ) = 0 , then the implicit function theorem implies that there exists neighborhoods U ⊂ X 1 and V ⊂ X 2 and a smooth map r : U → V such that r ( x 1 ) = x 2 . Assumption 2. F or every x 1 , ˙ x 2 = − D 2 f 2 ( x 1 , x 2 ) has a globally asymptotically stable equilibrium r ( x 1 ) uniformly in x 1 and r : R d 1 → R d 2 is L r –Lipschitz. Consider the leader’ s learning rule x 1 ,k +1 = x 1 ,k − γ 1 ,k ( D f 1 ( x 1 ,k , x 2 ,k ) + w 1 ,k +1 ) (7) where x 2 ,k is defined via the map r 2 defined implicitly in a neighborhood of ( x 1 ,k , x 2 ,k ) . Proposition 8. Suppose that for each x ∈ X , D 2 2 f 2 is non-de gener ate and Assumption 1 holds for i = 1 . Then, x 1 ,k con ver ges almost surely to an (possibly sample path dependent) equilibrium point x ∗ 1 which is a local Stack elberg solution for the leader . Mor eover , if Assumption 1 holds for i = 2 and Assumption 2 holds, then x 2 ,k → x ∗ 2 = r ( x ∗ 1 ) so that ( x ∗ 1 , x ∗ 2 ) is a differ ential Stack elber g equilibrium. Proof . This proof follo ws primarily from using known stochastic approximation results. The update rule in ( 7 ) is a stochastic approximation of ˙ x 1 = − D f 1 ( x 1 , x 2 ) and consequently is expected to track this ODE asymptotically . The main idea behind the analysis is to construct a continuous interpolated trajectory ¯ x ( t ) for t ≥ 0 and sho w it asymptotically almost surely approaches the solution set to the ODE. Under Assump- tions 1 – 3 , results from [ 11 , § 2.1] imply that the sequence generated from ( 7 ) con verges almost surely to a compact internally chain transiti ve set of ˙ x 1 = − D f 1 ( x 1 , x 2 ) . Furthermore, it can be observed that the only internally chain transitive in v ariant sets of the dynamics are differential Stackelberg equilibria since at any stable attractor of the dynamics D 2 f 1 ( x 1 , r ( x 1 )) > 0 and from assumption D 2 2 f 2 ( x 1 , r ( x 1 )) > 0 . Finally , from [ 11 , § 2.2], we can conclude that the update from ( 7 ) almost surely con verges to a possibly sample path dependent equilibrium point since the only internally chain transiti ve in variant sets for ˙ x 1 = − D f 1 ( x 1 , x 2 ) are equilibria. The final claim that x 2 ,k → r ( x ∗ 1 ) is guaranteed since r is Lipschitz and x 1 ,k → x ∗ 1 . The abov e result can be stated with a relaxed version of Assumption 2 . Corollary 2. Given a dif fer ential Stackelber g equilibrium x ∗ = ( x ∗ 1 , x ∗ 2 ) , let B q ( x ∗ ) = B q 1 ( x ∗ 1 ) × B q 2 ( x ∗ 2 ) for some q 1 , q 2 > 0 on which D 2 2 f 2 is non-de generate. Suppose that Assumption 1 holds for i = 1 and that x 1 , 0 ∈ B q 1 ( x ∗ 1 ) . Then, x 1 ,k con ver ges almost sur ely to x ∗ 1 . Mor eover , if Assumption 1 holds for i = 2 , r ( x 1 ) is a locally asymptotically stable equilibrium uniformly in x 1 on the ball B q 2 ( x ∗ 2 ) , and x 2 , 0 ∈ B q 2 ( x ∗ 2 ) , then x 2 ,k → x ∗ 2 = r ( x ∗ 1 ) . The proof follo ws the same arguments as the proof of Proposition 8 . 3.2 Learning Stackelber g Equilibria: T wo-T imescale Analysis No w , let us consider the case where the leader again operates under the assumption that the follo wer is playing (locally) optimally at each round so that the belief is D 2 f 2 ( x 1 ,k , x 2 ,k ) = 0 , but the follower is actually performing the update x 2 ,k +1 = x 2 ,k + g 2 ( x 1 ,k , x 2 ,k ) where g 2 ≡ − γ 2 ,k E [ D 2 f 2 ] . The learning dynamics in this setting are then x 1 ,k +1 = x 1 ,k − γ 1 ,k ( D f 1 ( x k ) + w 1 ,k +1 ) (8) x 2 ,k +1 = x 2 ,k − γ 2 ,k ( D 2 f 2 ( x k ) + w 2 ,k +1 ) (9) where D f 1 ( x ) = D 1 f 1 ( x ) + D 2 f 1 ( x ) D r ( x 1 ) . Suppose that γ 1 ,k → 0 faster than γ 2 ,k so that in the limit τ → 0 , the above approximates the singularly perturbed system defined by ˙ x 1 ( t ) = − τ Df 1 ( x 1 ( t ) , x 2 ( t )) ˙ x 2 ( t ) = − D 2 f 2 ( x 1 ( t ) , x 2 ( t )) (10) 15 F I E Z , C H A S N OV , R A T L I FF The learning rates can be seen as stepsizes in a discretization scheme for solving the above dynamics. The condition that γ 1 ,k = o ( γ 2 ,k ) induces a timescale separation in which x 2 e volv es on a faster timescale than x 1 . That is, the fast transient player is the follower and the slow component is the leader since lim k →∞ γ 1 ,k /γ 2 ,k = 0 implies that from the perspective of the follo wer , x 1 appears quasi-static and from the perspectiv e of the leader , x 2 appears to have equilibriated, meaning D 2 f 2 ( x 1 , x 2 ) = 0 giv en x 1 . From this point of vie w , the learning dynamics ( 8 )–( 9 ) approximate the dynamics in the preceding section. More- ov er, stable attractors of the dynamics are such that the leader is at a local optima for f 1 , not just along its coordinate axis but in both coordinates ( x 1 , x 2 ) constrained to the manifold r ( x 1 ) ; this is to make a distinction between differential Nash equilibria in agents are at local optima aligned with their individual coordinate axes. 3.2.1 Asymptotic Almost Sure Con vergence The follo wing two results are fairly classical results in stochastic approximation. They are le veraged here to making conclusions about con vergence to Stack elberg equilibria in hierarchical learning settings. While we do not need the following assumption for all the results in this section, it is required for asymptotic con vergence of the tw o-timescale process in ( 8 )–( 9 ). Assumption 3. The dynamics ˙ x 1 = − D f 1 ( x 1 , r ( x 1 )) have a globally asymptotically stable equilibrium. Under Assumption 1 – 3 , and the assumption that γ 1 ,k = o ( γ 2 ,k ) , classical results imply that the dy- namics ( 8 )–( 9 ) con verge almost surely to a compact internally chain transitive set T of ( 10 ); see, e.g., [ 11 , § 6.1-2], [ 10 , § 3.3]. Furthermore, it is straightforw ard to see that stable differential Nash equilibria are inter - nally chain transiti ve sets since the y are stable attractors of the dynamics ˙ ξ t = F ( ξ t ) from ( 10 ). Remark 3. Ther e ar e two important points to remark on at this junctur e. F irst, the flow of the dynamics ( 10 ) is not necessarily a gradient flow , meaning that the dynamics may admit non-equilibrium attractors such as periodic orbits. The dynamics corr espond to a gradient vector field if and only if D 2 ( D f 1 ) ≡ D 12 f 2 , meaning when the dynamics admit a potential function. Equilibria may also not be isolated unless the J acobian of ω S , say J S , is non-de generate at the points. Second, except in the case of zer o-sum settings in which ( f 1 , f 2 ) = ( f , − f ) , non-Stack elberg locally asymptotically stable equilibria are attractors. That is, con ver gence does not imply that the players have settled on a Stack elber g equilibrium, and this can occur even if the dynamics admit a potential. Let t k = P k − 1 l =0 γ 1 ,l be the (continuous) time accumulated after k samples of the slow component x 1 . Define ξ 1 ,s ( t ) to be the flow of ˙ x 1 = − D f 1 ( x 1 ( t ) , r ( x 1 ( t ))) starting at time s from intialization x s . Proposition 9. Suppose that Assumptions 1 and 2 hold. Then, conditioning on the event { sup k P i k x i,k k 2 < ∞} , for any inte ger K > 0 , lim k →∞ sup 0 ≤ h ≤ K k x 1 ,k + h − ξ 1 ,t k ( t k + h ) k 2 = 0 almost sur ely . Proof . The proof follows standard arguments in stochastic approximation. W e simply provide a sketch here to giv e some intuition. First, we show that conditioned on the ev ent { sup k P i k x 1 ,k k 2 < ∞} , ( x 1 ,k , x 2 ,k ) → { ( x 1 , r ( x 1 )) | x 1 ∈ R d 1 } almost surely . Let ζ k = γ 1 ,k γ 2 ,k ( D f 1 ( x k ) + w 1 ,k +1 ) . Hence the leader’ s sample path is generated by x 1 ,k +1 = x 1 ,k − γ 2 ,k ζ k which tracks ˙ x 1 = 0 since ζ k = o (1) so that it is asymptotically negligible. In particular, ( x 1 ,k , x 2 ,k ) tracks ( ˙ x 1 = 0 , ˙ x 2 = − D 2 f 2 ( x 1 , x 2 )) . That is, on intervals [ ˆ t j , ˆ t j +1 ] where ˆ t j = P j − 1 l =0 γ 2 ,l , the norm dif ference between interpolated trajectories of the sample paths and the trajectories of ( ˙ x 1 = 0 , ˙ x 2 = − D 2 f 2 ( x 1 , x 2 )) vanishes a.s. as k → ∞ . Since the leader is tracking ˙ x 1 = 0 , the follower can be vie wed as tracking ˙ x 2 ( t ) = − D 2 f 2 ( x 1 , x 2 ( t )) . Then applying Lemma 4 provided in Appendix A , lim k → 0 k x 2 ,k − r ( x 1 ,k ) k → 0 almost surely . No w , by Assumption 1 , D f 1 is Lipschitz and bounded (in fact, independent of A1a. , since D f 1 ∈ C q , q ≥ 2 , it is locally Lipschtiz and, on the ev ent { sup k P i k x i,k k 2 < ∞} , it is bounded). In turn, it induces a 16 continuous globally inte grable vector field, and therefore satisfies the assumptions of Bena ¨ ım [ 6 , Prop. 4.1]. Moreov er, under Assumptions A1b . and A1c. , the assumptions of Bena ¨ ım [ 6 , Prop. 4.2] are satisfied, which gi ves the desired result. Corollary 3. Under Assumption 3 and the assumptions of Pr oposition 9 , ( x 1 ,k , x 2 ,k ) → ( x ∗ 1 , r ( x ∗ 1 )) almost sur ely conditioned on the event { sup k P i k x i,k k 2 < ∞} . That is, the learning dynamics ( 8 ) – ( 9 ) con ver ge to stable attractor s of ( 10 ) , the set of which includes the stable differ ential Stac kelber g equilibria. Proof . Continuing with the conclusion of the proof of Proposition 9 , on intervals [ t k , t k +1 ] the norm dif ference between interpolates of the sample path and the trajectories of ˙ x 1 = − D f 1 ( x 1 , r ( x 1 )) vanish asymptotically; applying Lemma 4 (Appendix A ) gi ves the result. Le veraging the results in Section 2.2.1 , the con ver gence guarantees are stronger since in zero-sum settings all attractors are Stackelber g; this contrasts with the Nash equilibrium concept. Corollary 4. Consider a zer o-sum setting ( f , − f ) . Under the assumptions of Pr oposition 9 and Assump- tion 3 , conditioning on the event { sup k P i k x i,k k 2 < ∞} , the learning dynamics ( 8 ) – ( 9 ) con verg e to a differ ential Stack elberg equilibria almost sur ely . The proof of this corollary follo ws the abov e analysis and in vokes Proposition 1 . As with Corollary 2 , we can relax Assumption 2 and 3 to local asymptomatic stability assumptions and obtain similarity con ver gence guarantees. Corollary 5. Given a differ ential Stackelber g equilibrium x ∗ = ( x ∗ 1 , x ∗ 2 ) wher e x ∗ 2 = r ( x ∗ 1 ) , let B q ( x ∗ ) = B q 1 ( x ∗ 1 ) × B q 2 ( x ∗ 2 ) for some q 1 , q 2 > 0 on whic h D 2 2 f 2 is non-de gener ate. Suppose that Assumption 1 holds for each player , r ( x 1 ) is a locally asymptotically stable attractor uniformly in x 1 on the ball B q 2 ( x ∗ 2 ) for the dynamics ˙ x 2 = − D 2 f 2 ( x ) , and ther e exists a locally asymptotically stable attractor on B q 1 ( x 1 ) for the dynamics ˙ x 1 = − D f 1 ( x 1 , r ( x 1 )) . Then, given an initialization x 1 , 0 ∈ B q 1 ( x ∗ 1 ) and x 2 , 0 ∈ B q 2 ( x ∗ 2 ) , it follows that ( x 1 ,k , x 2 ,k ) → ( x ∗ 1 , x ∗ 2 ) almost sur ely . 3.2.2 Finite-Time High-Pr obability Guarantees While asymptotic guarantees of the proceeding section are useful, high-probability finite-time guarantees can be lev eraged more directly in analysis and synthesis, e.g., of mechanisms to coordinate otherwise au- tonomous agents. In this section, we aim to provide concentration bounds for the purpose of deriving con vergence rate and error bounds in support of this objectiv e. The results in this section follo w the very recent w ork by Borkar and P attathil [ 12 ]. W e highlight k ey dif ferences and, in particular , where the analysis may lead to insights rele vant for learning in hierarchical decision problems between non-cooperative agents. Consider a locally asymptotically stable dif ferential Stackelber g equilibrium x ∗ = ( x ∗ 1 , r ( x ∗ 1 )) ∈ X and let B q 0 ( x ∗ ) be an q 0 > 0 radius ball around x ∗ contained in the region of attraction. Stability implies that the Jacobian J S ( x ∗ 1 , r ( x ∗ 1 )) is positiv e definite and by the con verse L yapunov theorem [ 55 , Chap. 5] there exists local L yapunov functions for the dynamics ˙ x 1 ( t ) = − τ D f 1 ( x 1 ( t ) , r ( x 1 ( t ))) and for the dynamics ˙ x 2 ( t ) = − D 2 f 2 ( x 1 , x 2 ( t )) , for each fixed x 1 . In particular , there exists a local L yapunov function V ∈ C 1 ( R d 1 ) with lim k x 1 k↑∞ V ( x 1 ) = ∞ , and h∇ V ( x 1 ) , D f 1 ( x 1 , r ( x 1 )) i < 0 for x 1 6 = x ∗ 1 . For q > 0 , let V q = { x ∈ dom ( V ) : V ( x ) ≤ q } . Then, there is also q > q 0 > 0 and 0 > 0 such that for < 0 , { x 1 ∈ R d 1 | k x 1 − x ∗ 1 k ≤ } ⊆ V q 0 ⊂ N 0 ( V q 0 ) ⊆ V q ⊂ dom ( V ) where N 0 ( V q 0 ) = { x ∈ R d 1 | ∃ x 0 ∈ V q 0 s.t. k x 0 − x k ≤ 0 } . An analogously defined ˜ V exists for the dynamics ˙ x 2 for each fixed x 1 . For no w , fix n 0 suf ficiently large; we specify the values of n 0 for which the theory holds before the statement of Theorem 1 . Define the event E n = { ¯ x 2 ( t ) ∈ V q ∀ t ∈ [ ˜ t n 0 , ˜ t n ] } where ¯ x 2 ( t ) = x 2 ,k + 17 F I E Z , C H A S N OV , R A T L I FF t − ˜ t k γ 2 ,k ( x 2 ,k +1 − x 2 ,k ) are linear interpolates—i.e., asymptotic pseudo-tr ajectories —defined for t ∈ ( ˜ t k , ˜ t k +1 ) with ˜ t k +1 = ˜ t k + γ 2 ,k and ˜ t 0 = 0 . The basic idea of the proof is to lev erage Alekseev’ s formula (Thm. 3 , Appendix A ) to bound the dif ference between the asymptotic pseudo-trajectories and the flo w of the corresponding limiting dif ferential equation on each continuous time interv al between each of the successiv e iterates k and k + 1 by sequences of constants that decay asymptotically . Then, a union bound is used over all time interv als after defined for n ≥ n 0 in order to construct a concentration bound. This is done first for the follower , sho wing that x 2 ,k tracks the leader’ s ’conjecture’ or belief r ( x 1 ,k ) about the follower’ s reaction, and then for the leader . Follo wing Borkar and Pattathil [ 12 ], we can express the linear interpolates for any n ≥ n 0 as ¯ x 2 ( ˜ t n +1 ) = ¯ x 2 ( ˜ t n 0 ) − P n k = n 0 γ 2 ,k ( D 2 f 2 ( x k ) + w 2 ,k +1 ) where γ 2 ,k D 2 f 2 ( x k ) = R ˜ t k +1 ˜ t k D 2 f 2 ( x 1 ,k , ¯ x 2 ( ˜ t k )) ds and simi- larly for the w 2 ,k +1 term. Adding and subtracting R ˜ t n +1 ˜ t n 0 D 2 f 2 ( x 1 ( s ) , ¯ x 2 ( s )) ds , Aleksee v’ s formula can be applied to get ¯ x 2 ( t ) = x 2 ( t ) + Φ 2 ( t, s, x 1 ( ˜ t n 0 ) , ¯ x 2 ( ˜ t n 0 ))( ¯ x 2 ( ˜ t n 0 ) − x 2 ( ˜ t n 0 )) + R t ˜ t n 0 Φ 2 ( t, s, x 1 ( s ) , ¯ x 2 ( s )) ζ 2 ( s ) ds where x 1 ( t ) ≡ x 1 is constant (since ˙ x 1 = 0 ), x 2 ( t ) = r ( x 1 ) , and ζ 2 ( s ) = − D 2 f 2 ( x 1 ( ˜ t k ) , ¯ x 2 ( ˜ t k )) + D 2 f 2 ( x 1 ( s ) , ¯ x 2 ( s )) + w 2 ,k +1 . In addition, for t ≥ s , Φ 2 ( · ) satisfies linear system ˙ Φ 2 ( t, s, x 0 ) = J 2 ( x 1 ( t ) , x 2 ( t ))Φ 2 ( t, s, x 0 ) , with Φ 2 ( t, s, x 0 ) = I and x 0 = ( x 1 , 0 , x 2 , 0 ) and where J 2 the Jacobian of − D 2 f 2 ( x 1 , · ) . W e provide more detail on this deri v ation in Appendix B . Gi ven that x ∗ = ( x ∗ 1 , r ( x ∗ 1 )) is a stable differential Stackelber g equilibrium, J 2 ( x ∗ ) is positiv e definite. Hence, as in [ 57 , Lem. 5.3], we can find M , κ 2 > 0 such that for t ≥ s , x 2 , 0 ∈ V q , k Φ 2 ( t, s, x 1 , 0 , x 2 , 0 ) k ≤ M e − κ 2 ( t − s ) ; this result follo ws from standard results on stability of linear systems (see, e.g., Callier and Desoer [ 14 , § 7.2, Thm. 33]) along with a bound on R t s D 2 2 f 2 ( x 1 , x 2 ( τ , s, ˜ x 0 )) − D 2 2 f 2 ( x ∗ ) dτ for ˜ x 0 ∈ V q (see, e.g., Thoppe and Borkar [ 57 , Lem 5.2]). No w , an interesting point worth making is that this analysis leads to a very nice result for the leader- follo wer setting. In particular , through the use of the auxiliary variable z , we can show that the follower’ s sample path ‘tracks’ the leader’ s conjectured sample path. Indeed, consider z k = r ( x 1 ,k ) , that is, where D 2 f 2 ( x 1 ,k , x 2 ,k ) = 0 . Then, using a T aylor expansion of the implicitly defined conjecture r , we get z k +1 = z k + D r ( x 1 ,k )( x 1 ,k +1 − x 1 ,k ) + δ k +1 where k δ k +1 k ≤ L r k x 1 ,k +1 − x 1 ,k k 2 is the error from the remainder terms. Plugging in x 1 ,k +1 , z k +1 = z k + γ 2 ,k ( − D 2 f 2 ( x 1 ,k , z k ) + τ k D r 2 ( x 1 ,k )( w 1 ,k +1 − D f 1 ( x 1 ,k , x 2 ,k )) + γ − 1 2 ,k δ k +1 ) . The terms after − D 2 f 2 are o (1) , and hence asymptotically ne gligible, so that this z sequence tracks dynam- ics as x 2 ,k . W e show that with high probability , they asymptotically contract, leading to the conclusion that the follo wer’ s dynamics track the leader’ s conjecture. T ow ards this end, we first bound the normed difference between x 2 ,k and z k . Define constants H n 0 = ( k ¯ x 2 ( ˜ t n 0 − x 2 ( ˜ t n 0 ) k + k ¯ z ( ˜ t n 0 ) − x 2 ( ˜ t n 0 ) k ) , and S 2 ,n = P n − 1 k = n 0 R ˜ t k +1 ˜ t k Φ 2 ( ˜ t n , s, x 1 ( ˜ t k ) , ¯ x 2 ( ˜ t k )) ds ) w 2 ,k +1 , and let τ k = γ 1 ,k /γ 2 ,k . 18 Lemma 1. F or any n ≥ n 0 , ther e exists K > 0 suc h that conditioned on E n , k x 2 ,n − z n k ≤ K k S 2 ,n k + e − κ 2 ( ˜ t n − ˜ t n 0 ) H n 0 + sup n 0 ≤ k ≤ n − 1 γ 2 ,k + sup n 0 ≤ k ≤ n − 1 γ 2 ,k k w 2 ,k +1 k 2 + sup n 0 ≤ k ≤ n − 1 τ k + sup n 0 ≤ k ≤ n − 1 τ k k w 1 ,k +1 k 2 . Using this bound, we can provide an asymptotic guarantee that x 2 ,k tracks r ( x 1 ,k ) and a high-probability guarantee that x 2 ,k gets locked in to a ball around r ( x ∗ 1 ) . Fix ε ∈ [0 , 1) and let N be such that γ 2 ,n ≤ ε/ (8 K ) , τ n ≤ ε/ (8 K ) for all n ≥ N . Let n 0 ≥ N and with K as in Lemma 1 , let T be such that e − κ 2 ( ˜ t n − ˜ t n 0 ) H n 0 ≤ ε/ (8 K ) for all n ≥ n 0 + T . Theorem 1. Suppose that Assumptions 1 , 2 , and 3 hold and let γ 1 ,k = o ( γ 2 ,k ) . Given a stable differ ential Stack elberg equilibrium x ∗ = ( x ∗ 1 , r ( x ∗ 1 )) , the follower’ s sample path generated by ( 9 ) with asymptotically trac k the leader’ s conjecture z k = r ( x 1 ,k ) and, given ε ∈ [0 , 1) , will get ‘lock ed in’ to a ε –neighborhood with high pr obability conditioned on r eaching B q 0 ( x ∗ ) by iteration n 0 . That is, letting ¯ n = n 0 + T + 1 , for some C 1 , C 2 , C 3 , C 4 > 0 , P( k x 2 ,n − z n k ≤ ε, ∀ n ≥ ¯ n | x 2 ,n 0 , z n 0 ∈ B q 0 ) ≥ 1 − P ∞ n = n 0 C 1 e − C 2 √ ε/γ 2 ,n − P ∞ n = n 0 C 2 e − C 2 √ ε/τ n − P ∞ n = n 0 C 3 e − C 4 ε 2 /β n . (11) with β n = max n 0 ≤ k ≤ n − 1 e − κ 2 ( P n − 1 i = k +1 γ 2 ,i ) γ 2 ,k . The key technique in proving the abov e theorem (which is done in detail in Borkar and Pattathil [ 12 ] using results from Thoppe and Borkar [ 57 ]), is taking a union bound of the errors ov er all the continuous time interv als defined for n ≥ n 0 . The above theorem can be restated to giv e a guarantee on getting locked-in to an ε -neighborhood of a stable dif ferenital Stackelber g equilibria x ∗ if the learning processes are initialized in B q 0 ( x ∗ ) . Corollary 6. F ix ε ∈ [0 , 1) and suppose that γ 2 ,n ≤ ε/ (8 K ) for all n ≥ 0 . W ith K as in Lemma 1 , let T be such that e − κ 2 ( ˜ t n − ˜ t 0 ) H 0 ≤ ε/ (8 K ) for all n ≥ T . Under the assumptions of Theor em 1 , x 2 ,k will will get ‘locked in’ to a ε –neighborhood with high pr obability conditioned on x 0 ∈ B q 0 ( x ∗ ) wher e the high-pr obability bound is given in ( 11 ) with n 0 = 0 . Gi ven that the follower’ s action x 2 ,k tracks r ( x 1 ,k ) , we can also show that x 1 ,k gets locked into an ε – neighborhood of x ∗ 1 after a finite time with high probability . First, a similar bound as in Lemma 1 can be constructed for x 1 ,k . Define the e vent ˆ E n = { ¯ x 1 ( t ) ∈ V q ∀ t ∈ [ ˆ t n 0 , ˆ t n ] } where for each t , ¯ x 1 ( t ) = x 1 ,k + t − ˆ t k γ 1 ,k ( x 1 ,k +1 − x 1 ,k ) is a linear interpolates between the samples { x 1 ,k } , ˆ t k +1 = ˆ t k + γ 1 ,k , and ˆ t 0 = 0 . Then as abov e, Aleksee v’ s formula can again be applied to get ¯ x 1 ( t ) = x 1 ( t, ˆ t n 0 , y ( ˆ t n 0 )) + Φ 1 ( t, ˆ t n 0 , ¯ x 1 ( ˆ t n 0 ))( ¯ x 1 ( ˆ t n 0 ) − x 1 ( ˆ t n 0 )) + R t ˆ t n 0 Φ 1 ( t, s, ¯ x 1 ( s )) ζ 1 ( s ) ds where x 1 ( t ) ≡ x ∗ 1 , ζ 1 ( s ) = D f 1 ( x 1 ,k , r ( x 1 ,k )) − D f 1 ( ¯ x 1 ( s ) , r ( ¯ x 1 ( s ))) + D f 1 ( x k ) − D f 1 ( x 1 ,k , r ( x 1 ,k )) + w 1 ,k +1 , and Φ 1 is the solution to a linear system with dynamics J 1 ( x ∗ 1 , r ( x ∗ 1 )) , the Jacobian of − D f 1 ( · , r ( · )) , and with initial data Φ 1 ( s, s, x 1 , 0 ) = I . This linear system, as above, has bound k Φ 1 ( t, s, x 1 , 0 ) k ≤ M 1 e κ 1 ( t − 1) for some M 1 , κ 1 > 0 . Define S 1 ,n = P n − 1 k = n 0 R ˆ t k +1 ˆ t k Φ 1 ( ˆ t n , s, ¯ x 1 ( ˆ t k )) ds · w 1 ,k +1 . 19 F I E Z , C H A S N OV , R A T L I FF Lemma 2. F or any n ≥ n 0 , ther e exists ¯ K > 0 such that conditioned on ˜ E n , k ¯ x 1 ( ˆ t n ) − x 1 ( ˆ t n ) k ≤ ¯ K k S 1 ,n k + sup n 0 ≤ k ≤ n − 1 k S 2 ,k k + sup n 0 ≤ k ≤ n − 1 γ 2 ,k + sup n 0 ≤ k ≤ n − 1 τ k + sup n 0 ≤ k ≤ n − 1 γ 2 ,k k w 2 ,k +1 k 2 + sup n 0 ≤ k ≤ n − 1 τ k k w 1 ,k +1 k 2 + sup n 0 ≤ k ≤ n − 1 τ k H n 0 + e κ 1 ( ˆ t n − ˆ t n 0 ) k ¯ x 1 ( ˆ t n 0 ) − x 1 ( ˆ t n 0 ) k . Using this lemma, we can get the desired guarantees on x 1 ,k . Indeed, as above, fix ε ∈ (0 , 1] and let N be such that γ 2 ,n ≤ ε/ (8 K ) , τ n ≤ ε/ (8 K ) , ∀ n ≥ N . Then, for any n 0 ≥ N and K as in Lemma 1 , let T be such that e − κ 2 ( ˜ t n − ˜ t n 0 ) H n 0 ≤ ε/ (8 K ) , ∀ n ≥ n 0 + T . Moreov er , with ¯ K as in Lemma 2 , let e − κ 1 ( ˆ t n − ˆ t n 0 ) ( k ¯ x 1 ( ˆ t n 0 ) − x 1 ( ˆ t n 0 ) k ≤ ε/ (8 ¯ K ) , ∀ n ≥ n 0 + T . Theorem 2. Suppose that Assumptions 1 – 3 hold and that γ 1 ,k = o ( γ 2 ,k ) . Given a stable differ ential Stack- elber g equilibrium x ∗ and ε ∈ [0 , 1) , x k will g et ‘loc ked in’ to a ε -neighborhood of x ∗ with high pr obability conditioned r eaching B q 0 ( x ∗ ) by iteration n 0 . That is, letting ¯ n = n 0 + T + 1 , for some constants ˜ C j > 0 , j ∈ { 1 , . . . , 6 } , P( k x 1 ,n − x 1 ( ˆ t n ) k ≤ ε, ∀ n ≥ ¯ n | x n 0 , x n 0 ∈ B q 0 ) ≥ 1 + P ∞ n = n 0 ˜ C 1 e − ˜ C 2 √ ε/ √ γ 2 ,n − P ∞ n = n 0 ˜ C 1 e − ˜ C 2 √ ε/ √ τ n − P ∞ n = n 0 ˜ C 3 e − ˜ C 4 ε 2 /β n − P ∞ n = n 0 ˜ C 5 e − ˜ C 6 ε 2 /η n (12) with η n = max n 0 ≤ k ≤ n − 1 e − κ 1 ( P n − 1 i = k +1 γ 1 ,i ) γ 1 ,k . An analogous corollary to Corollary 6 can be stated for x 1 ,k with n 0 = 0 . 4. Numerical Examples In this section, we present and extensi ve set of numerical examples to v alidate our theory and demonstrate that the learning dynamics in this paper can ef fecti vely train GANs 5 . 4.1 Stackelberg Duopoly In Cournot’ s duopoly model a single good is produced by two firms so that the industry is a duopoly . The cost for firm i = 1 , 2 for producing q i units of the good is gi ven by c i q i where c i > 0 is the unit cost. The total output of the firms is Q = q 1 + q 2 . The market price is P = A − Q when A ≥ Q and P = 0 when A < Q . W e can assume that A > c i for i = 1 , 2 . The profit of each firm is π i = P q i − c i q i = ( A − q i − q − i − c i ) q i . Moreov er, the unique Nash equilibrium in the game is q ∗ i = 1 3 ( A + c − i − 2 c i ) so that the market price is P ∗ = 1 3 ( A + c i + c − i ) and each firm obtains a profit of π ∗ i = 1 9 ( A − 2 c i + c − i ) 2 . In the Stackelberg duopoly model with two firms, there is a leader and a follower . The leader mov es and then the follower produces a best response to the action of the leader . Knowing this, the leader seeks to maximize profit taking advantage of the power to move before the follo wer . The unique Stackelber g equilibrium in the game is q ∗ 1 = 1 2 ( A + c 2 − 2 c 1 ) , q ∗ 2 = 1 4 ( A + 2 c 1 − 3 c 2 ) . In equilibrium the market price is P ∗ = 1 4 ( A + 2 c 1 + c 2 ) , the profit of the leader is π ∗ 1 = 1 8 ( A − 2 c 1 + c 2 ) 2 , and the profit of the follower is π ∗ 2 = 1 16 ( A + 2 c 1 − 3 c 2 ) 2 . The key point we want to highlight is that in this game, firm 1’ s (leader) profit is always higher in the hierarchical play game than the simultaneous play game. W e also use it as a simple validation example for our theory . For this problem, we simulate the Nash gradient dynamics and our two-timescale algorithm for 5. Code is av ailable at github.com/fiezt/Stackelberg-Code . 20 0 50 100 Iterations 30 40 Production q S q S 1 q S 2 q N q N 1 q N 2 (a) 0 50 100 Iterations 600 800 1000 1200 1400 Profit S S 1 S 2 N N 1 N 2 (b) Figure 2: (a) F irms’ Pr oduction. Sample learning paths for each firm showing the production ev olution and con ver- gence to the Nash equilibrium under the Nash dynamics (i.e., simultaneous gradient-based learning using players’ individual gradients with respect to their own choice variable) and conv ergence to the Stackelberg equilibrium under the Stackelberg dynamics. (b) F irms’ Pr ofit. Evolution of each firm’ s profit under the learning dynamics for both Nash and Stackelberg. Similar con vergence characteristics can be observed in (a) and (b). Of note is the improved profit obtained by the leader in the Stackelber g equilibrium compared to the Nash equilibrium. learning Stackelberg equilibria to illustrate the distinctions between the Cournot and Stackelber g duopoly models. In this simulation, we select a decaying step-size of γ i,k = 1 /k for each player in the Nash gradient dynamics. The decaying step-size is chosen to be γ 1 ,k = 1 /k for the leader and γ 2 ,k = 1 /k 2 / 3 for the follo wer in the Stackelberg two-timescale algorithm so that the leader mov es on a slower timescale than the follo wer as required. The noise at each update step is drawn as w i,k ∼ N (0 , 10) for each firm. The parameters of the example are selected to be A = 100 , c 1 = 5 , c 2 = 2 . In Figure 2 we show the results of the simulation. Figure 2a sho ws the production path of each firm and Figure 2b shows the profit path of each firm. Under the Nash gradient dynamics, the firms con verge to the unique Nash equilibrium of q ∗ N = (30 . 67 , 33 . 67) that giv es profit of π ∗ N = (944 . 4 , 1114 . 7) . The Stacklber g procedure conv erges to the unique Stackelberg equilibrium of q ∗ S = (46 , 26) that gives profit of π ∗ S = (1048 . 2 , 659 . 9) . Hence as expected the two-timescale procedure conv erges to the Stackelber g equilibrium and gi ves the leader higher profit than under the Nash equilibrium. 4.2 Location Game on T orus In this section, we examine a two-player game in which each player is selecting a position on a torus. Precisely , each player has a choice variable θ i that can be chosen in the interv al [ − π , π ] . The cost for each player is defined as f i ( θ i , θ − i ) = − α i cos( θ i − φ i ) + cos( θ i − θ − i ) , where each φ i and α i are constants. The cost function is such that each player must trade-of f being close to φ i and far from θ − i . For the simulation of this game, we select the parameters α = (1 . 0 , 1 . 3) and φ = ( π / 8 , π / 8) . There are multiple Nash and Stackelber g equilibria under these parameters. Each equilibrium is a stable equilibrium in this example. The Nash equilbria are θ ∗ N = ( − 0 . 78 , 1 . 18) and θ ∗ N = (1 . 57 , − 0 . 4) , and the costs are each f ( θ ∗ N ) = ( − 0 . 77 , − 1 . 3) and f ( θ ∗ N ) = ( − 0 . 77 , − 1 . 3) . The Stackelberg equilbria are θ ∗ S = ( − 0 . 53 , 1 . 25) and θ ∗ S = (1 . 31 , − 0 . 46) , and the costs are each f ( θ ∗ S ) = ( − 0 . 81 , − 1 . 05) . Hence, the ability to play before the follo wer gi ves the leader a smaller cost at any equilibrium. The equilibrium the dynamics will con verge to depends on the initialization as we demonstrate. For this simulation, we select a decaying step-size of γ i,k = 1 /k 1 / 2 for each player in the Nash gradient dynamics. The decaying step-size is chosen to be γ 1 ,k = 1 /k for the leader and γ 2 ,k = 1 /k 1 / 2 for the follower in the Stackelberg two-timescale dynamics. The noise at each update step is drawn as w i,k ∼ N (0 , 0 . 01) for each player . In Figure 3 we sho w the results of our simulation. The Nash and Stackelberg dynamics conv erge to an equilibrium as expected. In Figures 3a and 3b , we visualize multiple sample learning paths for the Nash and Stackelber g dynamics, respectiv ely . 21 F I E Z , C H A S N OV , R A T L I FF (a) (b) 0 20 40 Iterations 0 1 2 3 i S S 1 S 2 N N 1 N 2 (c) 0 20 40 Iterations 2 1 0 1 2 Cost f S f S 1 f S 2 f N f N 1 f N 2 (d) Figure 3: (a-b) Sample learning paths for each player showing the positions and con ver gence to local Nash equilibria under the Nash dynamics and conv ergence to local Stackelberg equilibria under the Stackelberg dynamics. The value of player 1’ s choice variable θ 1 is sho wn on the horizontal axis and the value of player 2’ s choice variable θ 2 is sho wn on the vertical axis. Note that the square depicts the unfolded torus where horizontal edges are equiv alent, vertical edges are equiv alent, and the corners are all equiv alent. The black lines show D 1 f 1 in (a) and D f 1 in (b) where the white lines sho w D 2 f 2 in both (a) and (b). (c-d) Position and cost paths for each player for a sampled initial condition under the Nash and Stackelber g dynamics. The black lines depict D 1 f 1 for Nash and D f 1 for Stackelber g and demonstrate ho w the order of play warps the first-order conditions for the leader and consequently produces equilibria which move away from the Nash equilibria. In Figure 3c we giv e a detailed look at the con vergence to an equilibrium for a sample path. Finally , in Figure 3d , we present the e volution of the cost while learning and demonstrate the benefit of being the leader and the disadv antage of being the follo wer . 4.3 Generative Adversarial Netw orks W e now present a set of illustrativ e experiments showing the role of Stackelber g equilibria in the opti- mization landscape of GANs and the empirical benefits of training GANs using the Stackelberg learning dynamics compared to the simultaneous gradient descent dynamics. W e find that the leader update em- pirically cancels out rotational dynamics and prev ents cycling behavior . Moreov er, we discov er that the simultaneous gradient dynamics can empirically con ver ge to non-Nash stable attractors that are Stackelber g equilibria in GANs. The generator and the discriminator exhibit desirable performance at such points, indi- cating that Stackelberg equilibria can be as desirable as Nash equilibria. W e also find that the Stackelberg learning dynamics often con ver ge to non-Nash stable attractors and reach a satisfying solution quickly using learning rates that can cause the simultaneous gradient descent dynamics to cycle. W e provide details on our implementation of the Stackelberg leader update and the techniques to compute relev ant eigen values of games in Appendix E . More details for specific hyperparameters can be found in Appendix D . Example 1: Learning a Covariance Matrix. W e consider a data generating process of x ∼ N (0 , Σ) , where the covariance Σ is unknown and the objectiv e is to learn it using a W asserstein GAN. The discrim- inator is configured to be the set of quadratic functions defined as D W ( x ) = x > W x and the generator is a linear function of random input noise z ∼ N (0 , I ) defined by G V ( z ) = V z . The matrices W ∈ R m × m and V ∈ R m × m are the parameters of the discriminator and the generator , respecti vely . The W asserstein GAN cost for the problem is f ( V , W ) = P m i =1 P m j =1 W ij (Σ ij − P m k =1 V ik V j k ) . W e consider the generator to be the leader minimizing f ( V , W ) . The discriminator is the follower and it minimizes a regularized cost function defined by − f ( V , W ) + η 2 T r( W > W ) , where η ≥ 0 is a tunable regularization parameter . The game is formally defined by the costs ( f 1 , f 2 ) = ( f ( V , W ) , − f ( V , W ) + η 2 T r( W > W )) , where player 1 is the leader and player 2 is the follower . In equilibrium, the generator picks V ∗ such that V ∗ ( V ∗ ) > = Σ and the discriminator selects W ∗ = 0 . 22 0 5000 10000 Iterations 1 0 1 0 1 0 5 1 0 0 (a) m = 3 0 5000 10000 Iterations 1 0 1 0 1 0 5 1 0 0 (b) m = 9 0 5000 10000 Iterations 1 0 1 0 1 0 5 1 0 0 s i m g r a d : | | 1 2 ( W + W ) | | 2 s i m g r a d : | | V V | | 2 s t a c k : | | 1 2 ( W + W ) | | 2 s t a c k : | | V V | | 2 (c) m = 25 V 0 , 0 W 0 , 0 (d) m = 3 V 0 , 0 W 0 , 0 (e) m = 9 V 0 , 0 W 0 , 0 (f) m = 25 Figure 4: W e estimate the cov ariance matrix Σ with the Stackelberg learning dynamics, where the generator is the leader with choice variable V ∈ R m × m and discriminator is the follower with choice variable W ∈ R m × m . Stackel- berg learning can more effecti vely estimate the co variance matrix when compared with simultaneous gradient descent. W e demonstrate the conv ergence for dimensions 3, 9, 25 in (a)–(c), with learning rates γ 1 ,k = 0 . 015(1 − 10 − 5 ) k , γ 2 ,k = 0 . 015(1 − 10 − 7 ) k and regularization η = m/ 5 . The trajectories of the first element of W and V are plotted ov er time in (d)–(f). Observe the cycling beha vior of simultaneous gradient descent. (a) Gen. (b) Dis. 0 1 2 J R e a l E i g e n v a l u e s (c) J 0.0 0.2 0.4 Schur Complement Eigenvalues (d) S 1 0.000 0.025 0.050 D 2 1 f E i g e n v a l u e s (e) D 2 1 f 1 0 1 2 D 2 2 f E i g e n v a l u e s (f) D 2 2 f 2 (g) Gen. (h) Dis. (i) J 0.0 0.2 0.4 Schur Complement Eigenvalues (j) S 1 0.05 0.00 0.05 D 2 1 f E i g e n v a l u e s (k) D 2 1 f 1 0 1 2 D 2 2 f E i g e n v a l u e s (l) D 2 2 f 2 Figure 5: Con ver gence to non-Nash Stackelberg equilibria for both simultaneous gradient descent (top row) and Stackelber g learning dynamics (bottom row) in a 2-dimensional mixture of gaussian GAN e xample. The performance of the generator (player 1) and discriminator (player 2) are plotted in (a)–(b) and (g)–(h). T o determine the positive definiteness of the game Jacobian, Schur complement and the individual Hessians, we compute the six smallest real eigen values and six largest real eigen values for each in (c)-(f) and (i)-(l). W e observe that for both updates, the leader’ s Hessian is non-positiv e while the Schur complement is positive. W e compare the deterministic gradient update for Stack elberg learning dynamics and simultaneous gra- dient descent, and analyze the distance from equilibrium as a function of time. W e plot k Σ − V V > k 2 for the generator’ s performance and k 1 2 ( W + W > ) k 2 for the discriminator’ s performance in Fig. 4 for v arying dimensions m with learning rate where γ 1 ,k = o ( γ 2 ,k ) and fixed regularization terms η = m/ 5 . W e ob- serve that Stackelberg learning conv erges to an equilibrium in fewer iterations than simultaneous gradient descent. For zero-sum games, our theory provides reasoning for this behavior since at any critical point the eigen values of the g ame Jacobian are purely real. This is in contrast to the game Jacobian for the simultane- ous gradient descent, which can admit imaginary eigenv alue components that are know to cause rotational forces in the dynamics. This e xample pro vides empirical evidence that the Stackelber g dynamics cancel out rotations in general-sum games. Example 2: Mixture of Gaussian (Diamond). W e also train a GAN to learn a mixture of Gaussian distributions, where the generator is the leader and the discriminator is the follower . The generator network has two hidden layers and the discriminator has one hidden layer; each hidden layer has 32 neurons. W e train using a batch size of 256 , a latent dimension of 16 , and the default ADAM optimizer configuration in PyT orch version 1. Since the updates are stochastic, we decay the learning rates to satisfy our timescale separation assumption and regularize the implicit map of the follo wer using the parameter η = 1 . W e deri ve the regularized leader update in Appendix C . 23 F I E Z , C H A S N OV , R A T L I FF (a) Real (b) 8k (c) 20k (d) 40k (e) 60k (f) 8k (g) 20k (h) 40k (i) 60k 0 10 20 J R e a l E i g e n v a l u e s (j) J 0 20 40 60 Schur Complement Eigenvalues (k) S 1 0 10 20 D 2 1 f E i g e n v a l u e s (l) D 2 1 f 1 (m) D 2 2 f 2 0 1 2 J R e a l E i g e n v a l u e s (n) J 0 1 2 Schur Complement Eigenvalues (o) S 1 0.2 0.0 0.2 0.4 D 2 1 f E i g e n v a l u e s (p) D 2 1 f 1 0 1 2 3 D 2 2 f E i g e n v a l u e s (q) D 2 2 f 2 Figure 6: Con vergence to Nash for simultaneous gradient descent in Fig. (b)–(e) and con vergence to non-Nash Stack- elberg for Stackelber g learning in Fig. (f)–(i) for the mixture of gaussian e xample. W e plot the smallest six and largest six eigen values of the game Jacobian, Schur complement and individual hessians in (j)–(m) for simultaneous gradient descent and in (n)–(q) for Stackelberg learning at iteration 60k. The eigen v alues in this example seem to indicate that simultaneous gradient descent con ver ged to a Nash equilibrium and that the Stackelberg learning dynamics con verged to a non-Nash Stackelber g equilibria. The underlying data distribution for this problem consists of Gaussian distributions with means given by µ = [1 . 5 sin( ω ) , 1 . 5 cos( ω )] for ω ∈ { k π/ 2 } 3 k =0 and each with cov ariance σ 2 I where σ 2 = 0 . 15 . Each sample of real data given to the discriminator is selected uniformly at random from the set of Gaussian distributions. W e train each learning rule using learning rates that begin at 0 . 0001 . Moreover , in this example, the acti vation follo wing the hidden layers in each network is the tanh function. W e train this experiment using the saturating GAN objective [ 23 ]. In Fig. 5a – 5b and Fig. 5g – 5h we sho w a sample of the generator and the discriminator for simultaneous gradient descent and the Stackelber g dynamics after 40,000 training batches. Each learning rule conv erges so that the generator can create a distri- bution that is close to the ground truth and the discriminator is nearly at the optimal probability throughout the input space. In Fig. 5c – 5f and Fig. 5i – 5l , we show eigenv alues from the game that allo w us to get a deeper vie w of the con vergence behavior . W e observe that the simultaneous gradient dynamics appear be in a neighborhood of a non-Nash equilibrium since the indi vidual Hessian for the leader is indefinite, the indi- vidual Hessian for the follo wer is positiv e definite, and the Schur complement is positi ve definite. Moreover , the eigen values of the leader indi vidual Hessian are nearly zero, which would reflect the realizable assump- tion from Section 2. The Stack elberg learning dynamics con verge to a point with similar eigen values, which would be a non-Nash Stackelber g equilibrium. This example demonstrates that standard GAN training can con verge to non-Nash attractors that are Stackelberg equilibria and the Stackelber g equilibria can produce good generator and discriminator performance. This indicates that it may not be necessary to look only for Nash equilibria and instead it may be easier to find Stackelberg equilibria and the performance could be as desirable. Example 3: Mixure of Gaussian (Circle). The underlying data distribution for this problem consists of Gaussian distributions with means given by µ = [sin( ω ) , cos( ω )] for ω ∈ { k π/ 4 } 7 k =0 and each with cov ariance σ 2 I where σ 2 = 0 . 3 , sampled in the similar manner as the previous example. W e train each learning rule using learning rates that begin at 0 . 0004 . Moreover , in this example, the activ ation following the hidden layers in each network is the ReLU function. 24 (a) (b) (c) (d) Figure 7: W e demonstrate Stackelberg learning on the MNIST dataset for digits for 0s and 1s in (a)-(b) and for all digits in (c)-(d). W e train the GAN with the non-saturating objective [ 23 ]. W e show the the performance in Fig. 6 along the learning path for the simultaneous gradient descent dynamics and the Stackelberg learning dynamics. The simultaneous gradient descent dynamics c ycle and perform poorly until the learning rates ha ve decayed enough to stabilize the training process. The Stackelberg learning dynamics con ver ge quickly to a solution that nearly matches the ground truth distribution. In a similar fashion as in the cov ariance example, the leader update is able to cancel out rotations and conv erge to a desirable solution with a learning rate that destabilizes the training process for standard training techniques. W e sho w the eigenv alues after training and see that for this configuration the simultaneous gradient dynamics conv erge to a Nash equilibrium and the Stackelber g learning dynamics conv erge again to a non-Nash Stackelberg equilibrium. This pro vides further e vidence that Stack elberg equilibria may be easier to reach and can pro vide suitable generator performance. Example 4: MNIST dataset. T o demonstrate that the Stackelber g learning dynamics can scale to high dimensional problems, we train a GAN on the MNIST dataset using the DCGAN architecture adapted to handle 28 × 28 images. W e train on an MNIST dataset consisting of only the digits 0 and 1 from the training images and on an MNIST dataset containing the entire set of training images. W e train using a batch size of 256 , a latent dimension of 100 , and the ADAM optimizer with the default parameters for the DCGAN network. W e regularize the implicit map of the follo wer as detailed in Appendix C using the parameter η = 5000 . If we view the regularization as a linear function of the number of parameters in the discriminator , then this selection of regularization is nearly equal to that from the mixture of Gaussian experiments. W e sho w the results in Fig. 7 after 2900 batches. For each dataset we show a sample of 16 digits to get a clear view of the generator performance and a sample of 256 digits to get a broader view of the generator output. The Stackelberg dynamics are able to con verge to a solution that generates realistic handwritten digits. The primary purpose of this example is to show that the learning dynamics including second order information and an in verse is not an insurmountable problem for training lar ge scale networks with millions of parameters. W e belie ve the tools we develop for our implementation can be helpful to researchers working on GANs since a number of theoretical works on this topic require second order information to strengthen the con vergence guarantees. 5. Conclusion W e study the con ver gence of learning dynamics in Stackelber g games. This class of games broadly pertains to an y application in which there is an order of play between the players in the game. Howe ver , the problem has not been extensi vely analyzed in the way the learning dynamics of simultaneous play games ha ve been. Consequently , we are able to giv e novel con vergence results and dra w connections to existing work focused on learning Nash equilibria. 25 F I E Z , C H A S N OV , R A T L I FF References [1] V . M. Alekseev . An estimate for the perturbations of the solutions of ordinary differential equations. V estnik Moskov . Univ . Ser . I. Mat. Meh. , 2:28–36, 1961. [2] Simon P Anderson and Maxim Engers. Stackelber g versus cournot oligopoly equilibrium. Interna- tional J ournal of Industrial Or ganization , 10(1):127–135, 1992. [3] David Balduzzi, Sebastien Racaniere, James Martens, Jakob Foerster , Karl T uyls, and Thore Graepel. The mechanics of n-player differentiable games. In International Conference on Machine Learning , pages 354–363, 2018. [4] T amer Basar and Geert Jan Olsder . Dynamic Noncooper ative Game Theory . Society for Industrial and Applied Mathematics, 2nd edition, 1998. [5] T amer Basar and Hasan Selbuz. Closed-loop stackelber g strategies with applications in the optimal control of multile vel systems. IEEE T ransactions on Automatic Contr ol , 24(2):166–179, 1979. [6] Michel Bena ¨ ım. Dynamics of stochastic approximation algorithms. In Seminair e de Pr obabilites XXXIII , pages 1–68, 1999. [7] Michel Benaım and Morris W Hirsch. Mixed equilibria and dynamical systems arising from fictitious play in perturbed games. Games and Economic Behavior , 29(1-2):36–72, 1999. [8] H Berard, G Gidel, A Almahairi, P V incent, and S Lacoste-Julien. A closer look at the optimization landscapes of generati ve adv ersarial networks. arXiv preprint , 2019. [9] T Berger , J Giribet, F M Per ´ ıa, and C Trunk. On a Class of Non-Hermitian Matrices with Positi ve Definite Schur Complements. arXiv pr eprint arxiv:1807.08591 , 2018. [10] Shalabh Bhatnagar , HL Prasad, and LA Prashanth. Stochastic recur sive algorithms for optimization: simultaneous perturbation methods , volume 434. Springer , 2012. [11] V iv ek S. Borkar . Stochastic Appr oximation: A Dynamical Systems V iewpoint . Cambridge University Press, 2008. [12] V iv ek S Borkar and Sarath Pattathil. Concentration bounds for two time scale stochastic approxi- mation. In Allerton Confer ence on Communication, Contr ol, and Computing , pages 504–511. IEEE, 2018. [13] T imothy F Bresnahan. Duopoly models with consistent conjectures. The American Economic Revie w , 71(5):934–945, 1981. [14] F . Callier and C. Desoer . Linear Systems Theory . Springer , 1991. [15] E. J. Collins and D. S. Leslie. Con ver gent multiple-timescales reinforcement learning algorithms in normal form games. The Annals of Applied Pr obability , 13(4), 2003. [16] John M. Danskin. The theory of max-min, with applications. SIAM Journal on Applied Mathematics , 14(4):641–664, 1966. [17] John M. Danskin. The Theory of Max-Min and its Application to W eapons Allocation Pr oblems . Springer , 1967. 26 [18] Constantinos Daskalakis and Ioannis Panageas. The limit points of (optimistic) gradient descent in min-max optimization. arXiv pr eprint arxiv:1807.03907 , 2018. [19] Christos Dimitrakakis, David C Parkes, Goran Radanovic, and Paul T ylkin. Multi-view decision pro- cesses: the helper-ai problem. In Advances in Neural Information Pr ocessing Systems , pages 5443– 5452, 2017. [20] Jaime F Fisac, Eli Bronstein, Elis Stefansson, Dorsa Sadigh, S Shankar Sastry , and Anca D Dragan. Hi- erarchical game-theoretic planning for autonomous vehicles. arXiv pr eprint arXiv:1810.05766 , 2018. [21] Jakob Foerster , Richard Y Chen, Maruan Al-Shediv at, Shimon Whiteson, Pieter Abbeel, and Igor Mordatch. Learning with opponent-learning awareness. In International Conference on Autonomous Agents and MultiAgent Systems , pages 122–130, 2018. [22] Drew Fudenberg, Fudenberg Drew , David K Levine, and David K Levine. The theory of learning in games , volume 2. MIT press, 1998. [23] Ian Goodfellow , Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David W arde-Farle y , Sherjil Ozair , Aaron Courville, and Y oshua Bengio. Generati ve adv ersarial nets. In Advances in Neural Information Pr ocessing Systems , pages 2672–2680, 2014. [24] Amy Greenw ald, K eith Hall, and Roberto Serrano. Correlated q-learning. In International Confer ence on Machine Learning , pages 242–249, 2003. [25] Martin Heusel, Hubert Ramsauer , Thomas Unterthiner , Bernhard Nessler , and Sepp Hochreiter . Gans trained by a two time-scale update rule conv erge to a local nash equilibrium. In Advances in Neural Information Pr ocessing Systems , pages 6626–6637, 2017. [26] Roger Horn and Charles Johnson. T opics in Matrix Analysis . Cambridge University Press, 2011. [27] Junling Hu and Michael P W ellman. Nash q-learning for general-sum stochastic games. Journal of Machine Learning Resear ch , 4:1039–1069, 2003. [28] Chi Jin, Praneeth Netrapalli, and Michael I Jordan. Minmax optimization: Stable limit points of gradient descent ascent are locally optimal. arXiv pr eprint arXiv:1902.00618 , 2019. [29] Marc Jungers, Emmanuel T r ´ elat, and Hisham Abou-Kandil. Min-max and min-min stack elberg strate- gies with closed-loop information structure. J ournal of dynamical and contr ol systems , 17(3):387, 2011. [30] Allen Knutson and T erence T ao. Honeycombs and sums of hermitian matrices. Notices of the American Mathematical Society , 2001. [31] Harold J. Kushner and G. George Y in. Stochastic appr oximation and recur sive algorithms and appli- cations , volume 35. Springer Science & Business Media, 2003. [32] John Lee. Intr oduction to smooth manifolds . Springer , 2012. [33] Alistair Letcher , Jakob Foerster , David Balduzzi, Tim Rockt ¨ aschel, and Shimon Whiteson. Stable opponent shaping in differentiable games. In International Confer ence on Learning Repr esentations , 2019. [34] T ianyi Lin, Chi Jin, and Michael I Jordan. On gradient descent ascent for noncon vex-conca ve minimax problems. arXiv pr eprint arXiv:1906.00331 , 2019. 27 F I E Z , C H A S N OV , R A T L I FF [35] Michael L Littman. Markov games as a framework for multi-agent reinforcement learning. In Inter- national Confer ence on Machine Learning , pages 157–163, 1994. [36] Chang Liu, Jessica B Hamrick, Jaime F Fisac, Anca D Dragan, J Karl Hedrick, S Shankar Sastry , and Thomas L Griffiths. Goal inference improves objecti ve and perceiv ed performance in human-robot collaboration. In International Confer ence on Autonomous Agents and Multiag ent Systems , pages 940–948, 2016. [37] E. Mazumdar , M. Jordan, and S. S. Sastry . On finding local nash equilibria (and only local nash equilibria) in zero-sum games. , 2019. [38] Eric Mazumdar and Lillian J Ratliff. On the con vergence of gradient-based learning in continuous games. arXiv pr eprint arXiv:1804.05464 , 2018. [39] Panayotis Mertikopoulos, Bruno Lecouat, Houssam Zenati, Chuan-Sheng Foo, V ijay Chandrasekhar, and Georgios Piliouras. Optimistic mirror descent in saddle-point problems: Going the extra (- gradient) mile. , 2018. [40] Lars Mescheder , Sebastian No wozin, and Andreas Geiger . The numerics of gans. In Advances in Neural Information Pr ocessing Systems , pages 1825–1835, 2017. [41] Lars Mescheder, Andreas Geiger , and Sebastian No wozin. Which training methods for gans do actually con verge? arXiv preprint , 2018. [42] Luke Metz, Ben Poole, David Pfau, and Jascha Sohl-Dickstein. Unrolled generativ e adversarial net- works. In International Conference on Learning Repr esentations , 2017. [43] V aishna vh Nagarajan and J Zico Kolter . Gradient descent gan optimization is locally stable. In Ad- vances in Neural Information Pr ocessing Systems , pages 5585–5595, 2017. [44] W eili Nie and Ankit B. Patel. T o wards a better understanding and regularization of gan training dy- namics. arXiv pr eprint arxiv:1806.09235 , 2019. [45] Stefanos Nikolaidis, Swaprav a Nath, Ariel D Procaccia, and Siddhartha Sriniv asa. Game-theoretic modeling of human adaptation in human-robot collaboration. In International Confer ence on Human- Robot Interaction , pages 323–331, 2017. [46] Maher Nouiehed, Maziar Sanjabi, Jason D Lee, and Meisam Razaviyayn. Solving a class of non- con vex min-max games using iterati ve first order methods. arXiv preprint , 2019. [47] G Papa vassilopoulos and J Cruz. Nonclassical control problems and stackelberg games. IEEE T rans- actions on Automatic Contr ol , 24(2):155–166, 1979. [48] George P Papav assilopoulos and JB Cruz. Suf ficient conditions for stackelber g and nash strategies with memory . Journal of Optimization Theory and Applications , 31(2):233–260, 1980. [49] Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised representation learning with deep con volutional generati ve adversarial networks. arXiv pr eprint arXiv:1511.06434 , 2015. [50] L. J. Ratliff, S. A. Burden, and S. S. Sastry . On the Characterization of Local Nash Equilibria in Continuous Games. IEEE T ransactions on A utomatic Contr ol , 61(8):2301–2307, 2016. [51] Lillian J Ratliff and T anner Fiez. Adaptiv e incentiv e design. arXiv pr eprint arXiv:1806.05749 , 2018. 28 [52] Lillian J Ratliff, Roy Dong, Shreyas Sekar, and T anner Fiez. A perspectiv e on incentive design: Challenges and opportunities. Annual Revie w of Contr ol, Robotics, and Autonomous Systems , 2018. [53] J. B. Rosen. Existence and uniqueness of equilibrium points for concav e n-person games. Economet- rica , 33(3):520–534, 1965. [54] Dorsa Sadigh, Shankar Sastry , Sanjit A Seshia, and Anca D Dragan. Planning for autonomous cars that le verage ef fects on human actions. In Robotics: Science and Systems , volume 2, 2016. [55] S. S. Sastry . Nonlinear Systems Theory . Springer , 1999. [56] Y oa v Shoham, Rob Powers, and Trond Grenager . If multi-agent learning is the answer , what is the question? Artificial Intelligence , 171(7):365–377, 2007. [57] Gugan Thoppe and V iv ek Borkar . A concentration bound for stochastic approximation via alekseevs formula. Stochastic Systems , 9(1):1–26, 2019. [58] C. T retter . Spectral Theory of Block Operator Matrices and Applications . Imperial College Press, 2008. [59] Alexander J Zasla vski. Necessary optimality conditions for bile vel minimization problems. Nonlinear Analysis: Theory , Methods & Applications , 75(3):1655–1678, 2012. [60] Chongjie Zhang and V ictor Lesser . Multi-agent learning with policy prediction. In AAAI Conference on Artificial Intelligence , 2010. 29 F I E Z , C H A S N OV , R A T L I FF A ppendix A. Mathematical Preliminaries In this appendix, we sho w some preliminary results on linear algebra and recall some definitions and results from dynamical systems theory that are needed to state and prov e the results in the main paper . A.1 Proofs of Pr opositions 3 and 4 The results in this subsection follow from the theory of block operator matrices and indefinite linear alge- bra [ 58 ]. The follo wing lemma is a very well-kno wn result in linear algebra and can be found in nearly any adv anced linear algebra text such as [ 26 ]. Lemma 3. Let W ∈ C n × n be Hermitian with k positive eigen values (counted with multiplicities) and let U ∈ C m × n . Then λ j ( U W U ∗ ) ≤ k U k 2 λ j ( W ) for j = 1 , . . . , min { k , m, rank( U W U ∗ ) } . Let us define | M | = ( M M > ) 1 / 2 for a matrix M . Recall also that for Propositions 3 and 4 , we have defined sp ec( D 2 1 f ( x ∗ )) = { µ j , j ∈ { 1 , . . . , m }} where µ 1 ≤ · · · ≤ µ r < 0 ≤ µ r +1 ≤ · · · ≤ µ m , and sp ec( − D 2 2 f ( x ∗ )) = { λ i , i ∈ { 1 , . . . , n }} where λ 1 ≥ · · · ≥ λ n > 0 , giv en an attractor x ∗ . W e can no w use the above Lemma to prov e Proposition 3 . The proof follo ws the main arguments in the proof of Lemma 3.2 in the work by Berger et al. [ 9 ] with some minor changes due to the nature of our problem. Proof . [Proof of Proposition 3 ] Let x ∗ be a stable attractor of ˙ x = − ω S ( x ) such that − D 2 2 f ( x ∗ ) > 0 . For the sake of presentation, define A = D 2 1 f ( x ∗ ) , B = D 12 f ( x ∗ ) , and C = D 2 2 f ( x ∗ ) . Recall that x 1 ∈ R n and x 2 ∈ R m . Suppose that A − B C − 1 B > > 0 . Claim: r ≤ n is necessary . W e argue by contradiction. Suppose not—i.e., assume that r > n . Note that if m < n , then this is not possible. In this case, we automatically satisfy that r ≤ n . Otherwise, r ≥ m > n . Let S 1 = ker( B ( − C − 1 + | C − 1 | ) B > ) and consider the subspace S 2 of C m spanned by the all the eigen vectors of A corresponding to non-positi ve eigen v alues. Note that dim S 1 = m − rank( B ( − C − 1 + | C − 1 | ) B > ) ≥ m − rank( − C − 1 + | C − 1 | ) = m − n By assumption, we hav e that dim S 2 = r so that, since r > n , dim S 1 + dim S 2 ≥ ( m − n ) + r = m + ( r − n ) > m. Thus, S 1 ∩ S 2 6 = { 0 } . Now , S 1 = k er( B ( − C − 1 + | C − 1 | ) B > ) . Hence, for any non-trivial vector v ∈ S 1 ∩ S 2 , ( B C − 1 B > − B | C − 1 | B > ) v = 0 so that we ha ve h ( A − B C − 1 B > ) v , v i = h Av , v i − h B | C − 1 | B > v , v i ≤ 0 . (13) Note that the inequality in ( 13 ) holds because the vector v is in the non-positiv e eigenspace of A and the second term is clearly non-positiv e. Thus, A − B C − 1 B > cannot be positive definite, which giv es a contradiction so that r ≤ n . Claim: κ 2 λ i + µ i > 0 is necessary . Let the maps λ i ( · ) denote the eigen values of its argument arranged in non-increasing order . Then, by the W eyl theorem for Hermitian matrices [ 26 ], we hav e that 0 < λ m ( A − B C − 1 B > ) ≤ λ i ( A ) + λ m − i +1 ( − B C − 1 B > ) , i ∈ { 1 , . . . , m } . 30 W e can now combine this inequality with Lemma 3 . Indeed, we ha ve that 0 < λ i ( A ) + k B k 2 λ m − i +1 ( − C − 1 ) < µ m − i +1 + κ 2 λ m − i +1 , ∀ i ∈ { m − r + p + 1 , . . . , m } which gi ves the desired result. Since we hav e shown both the necessary conditions, this concludes the proof. No w , let us prove Proposition 4 which gi ves sufficient conditions for when a stable non-Nash attractor x ∗ of ˙ x = − ω ( x ) is a differential Stackelberg equilibrium. Then, combining this with Proposition 1 , we have a suf ficient condition under which stable non-Nash attractors are in fact stable attractors of ˙ x = − ω S ( x ) . Proof . [Proof of Proposition 4 ] Let x ∗ be a stable non-Nash attractor of ˙ x = − ω ( x ) such that D 2 1 f ( x ∗ ) and D 2 2 f ( x ∗ ) > 0 are Hermitian. Since D 2 i f ( x ∗ ) , i = 1 , 2 are both Hermitian, let D 2 1 f ( x ∗ ) = W 1 M W ∗ 1 with W 1 W ∗ 1 = I n × n and M = diag ( µ 1 , . . . , µ m ) , and − D 2 2 f ( x ∗ ) = W 2 Λ W ∗ 2 with W 2 W ∗ 2 = I m × m and Λ = diag( λ 1 , . . . , λ n ) . By assumption, there exists a diagonal matrix Σ ∈ R m × n such that D 12 f ( x ∗ ) = W 1 Σ W ∗ 2 where W 1 are the orthonormal eigen vectors of D 2 1 f ( x ∗ ) and W 2 are orthonormal eigen vectors of − D 2 2 f ( x ∗ ) . Then, D 2 1 f ( x ∗ ) − D 21 f ( x ∗ ) > ( D 2 2 f ( x ∗ )) − 1 D 21 f ( x ∗ ) = W 1 M W ∗ 1 + W 1 Σ W ∗ 2 ( W 2 Λ W ∗ 2 ) − 1 W 2 Σ ∗ W ∗ 1 = W 1 ( M + ΣΛ − 1 Σ ∗ ) W ∗ 1 Hence, to understand the eigenstructure of the Schur complement, we simply need to compare the all neg- ati ve eigen values of D 2 1 f ( x ∗ ) in increasing order with the most positi ve eigen values of − D 2 2 f ( x ∗ ) in de- creasing order . Indeed, by assumption, r ≤ n and κ 2 λ i + µ i > 0 for each i ∈ { 1 , . . . , r − p } . Thus, D 2 1 f ( x ∗ ) − D 21 f ( x ∗ ) > ( D 2 2 f ( x ∗ )) − 1 D 21 f ( x ∗ ) > 0 since it is a symmetric matrix. Combining this with the fact that − D 2 2 f ( x ∗ ) > 0 , x ∗ is a differential Stack- elberg equilibrium. Hence, by Proposition 1 it is an attractor of ˙ x = − ω S ( x ) . A.2 Dynamical Systems Theory Primer Definition 6. Given T > 0 , δ > 0 , if there exists an incr easing sequence of times t j with t 0 = 0 and t j +1 − t j ≥ T for each j and solutions ξ j ( t ) , t ∈ [ t j , t j +1 ] of ˙ ξ = F ( ξ ) with initialization ξ (0) = ξ 0 such that sup t ∈ [ t j ,t j +1 ] k ξ j ( t ) − z ( t ) k < δ for some bounded, measurable z ( · ) , the we call z a ( T , δ ) –perturbation. Lemma 4 (Hirsch Lemma) . Given ε > 0 , T > 0 , there exists ¯ δ > 0 such that for all δ ∈ (0 , ¯ δ ) , every ( T , δ ) –perturbation of ˙ ξ = F ( ξ ) con verg es to an ε –neighborhood of the global attr actor set for ˙ ξ = F ( ξ ) . A key tool used in the finite-time two-timescale analysis is the nonlinear v ariation of constants formula of Aleksee v [ 1 ], [ 12 ]. Theorem 3. Consider a differ ential equation ˙ u ( t ) = f ( t, u ( t )) , t ≥ 0 , and its perturbation ˙ p ( t ) = f ( t, p ( t )) + g ( t, p ( t )) , t ≥ 0 31 F I E Z , C H A S N OV , R A T L I FF wher e f , g : R × R d → R d , f ∈ C 1 , and g ∈ C . Let u ( t, t 0 , p 0 ) and p ( t, t 0 , p 0 ) denote the solutions of the above nonlinear systems for t ≥ t 0 satisfying u ( t 0 , t 0 , p 0 ) = p ( t 0 , t 0 , p 0 ) = p 0 , r espectively . Then, p ( t, t 0 , p 0 ) = u ( t, t 0 , p 0 ) + Z t t 0 Φ( t, s, p ( s, t 0 , p 0 )) g ( s, p ( s, t 0 , p 0 )) ds, t ≥ t 0 wher e Φ( t, s, u 0 ) , for u 0 ∈ R d , is the fundamental matrix of the linear system ˙ v ( t ) = ∂ f ∂ u ( t, u ( t, s, u 0 )) v ( t ) , t ≥ s (14) with Φ( s, s, u 0 ) = I d , the d –dimensional identity matrix. T ypical two-timescale analysis has historically leveraged the discrete Bellman-Grownwall lemma [ 11 , Chap. 6]. Recent application of Aleksee v’ s formula has lead to tighter bounds, and is thus becoming com- monplace in such analysis. A ppendix B. Extended Analysis The results in Section 3.2.2 le verage classical results from stochastic approximation [ 6 , 10 , 11 , 31 ] including recent advances in that same domain [ 12 , 57 ]. Here we provide more detail on the deriv ation of the bounds presented in Section 3.2.2 in order to pro vide insight into what the constants are in the concentration bounds in Theorems 1 and 2 . Moreover , the presentation here is somewhat distilled and the aim is to help the reader through the analysis in Borkar and Pattathil [ 12 ] and Thoppe and Borkar [ 57 ] as it pertains to the setting we consider . W e refer the reader to each of these papers and references therein for even more detail. As in the main body of the paper , consider a locally asymptotically stable differential Stackelber g equilibrium x ∗ = ( x ∗ 1 , r ( x ∗ 1 )) ∈ X and let B q 0 ( x ∗ ) be an q 0 > 0 radius ball around x ∗ contained in the region of attraction. Stability implies that the Jacobian J S ( x ∗ 1 , r ( x ∗ 1 )) is positi ve definite and by the con verse L yapunov theorem [ 55 , Chap. 5] there exists local L yapunov functions for the dynamics ˙ x 1 ( t ) = − τ Df 1 ( x 1 ( t ) , r ( x 1 ( t ))) and for the dynamics ˙ x 2 ( t ) = − D 2 f 2 ( x 1 , x 2 ( t )) , for each fixed x 1 . In particular , there exists a local L yapunov function V ∈ C 1 ( R d 1 ) with lim k x 1 k↑∞ V ( x 1 ) = ∞ , and h∇ V ( x 1 ) , D f 1 ( x 1 , r ( x 1 )) i < 0 for x 1 6 = x ∗ 1 . For q > 0 , let V q = { x ∈ dom ( V ) : V ( x ) ≤ q } . Then, there is also q > q 0 > 0 and 0 > 0 such that for < 0 , { x 1 ∈ R d 1 | k x 1 − x ∗ 1 k ≤ } ⊆ V q 0 ⊂ N 0 ( V q 0 ) ⊆ V q ⊂ dom ( V ) where N 0 ( V q 0 ) = { x ∈ R d 1 | ∃ x 0 ∈ V q 0 s.t. k x 0 − x k ≤ 0 } . An analogously defined ˜ V exists for the dynamics ˙ x 2 for each fixed x 1 . For no w , fix n 0 suf ficiently large; we specify the values of n 0 for which the theory holds before the statement of Theorem 1 . Define the ev ent E n = { ¯ x 2 ( t ) ∈ V q ∀ t ∈ [ ˜ t n 0 , ˜ t n ] } where ¯ x 2 ( t ) = x 2 ,k + t − ˜ t k γ 2 ,k ( x 2 ,k +1 − x 2 ,k ) are linear interpolates—i.e., asymptotic pseudo-trajectories —defined for t ∈ ( ˜ t k , ˜ t k +1 ) with ˜ t k +1 = ˜ t k + γ 2 ,k and ˜ t 0 = 0 . W e can express the asymptotic pseudo-trajectories for any n ≥ n 0 as ¯ x 2 ( ˜ t n +1 ) = ¯ x 2 ( ˜ t n 0 ) − P n k = n 0 γ 2 ,k ( D 2 f 2 ( x k ) + w 2 ,k +1 ) . 32 Note that P n k = n 0 γ 2 ,k D 2 f 2 ( x k ) = P n k = n 0 R ˜ t k +1 ˜ t k D 2 f 2 ( x 1 ,k , ¯ x 2 ( ˜ t k )) ds and similarly for the w 2 ,k +1 term, due to the fact that ˜ t k +1 − ˜ t k = γ 2 ,k by construction. Hence, for s ∈ [ ˜ t k , ˜ t k +1 ) , the abov e can be rewritten as ¯ x 2 ( t ) = ¯ x 2 ( ˜ t n 0 ) + R t ˜ t n 0 − D 2 f 2 ( x 1 ( s ) , ¯ x 2 ( s )) + ζ 21 ( s ) + ζ 22 ( s ) ds where ζ 21 ( s ) = − D 2 f 2 ( x 1 ( ˜ t k ) , ¯ x 2 ( ˜ t k )) − D 2 f 2 ( x 1 ( s ) , ¯ x 2 ( s )) and ζ 22 ( s ) = − w 2 ,k +1 . In the main body of the paper ζ 2 ( s ) = ζ 21 ( s ) + ζ 22 ( s ) . Then, by the nonlinear v ariation of constants formula (Aleksee v’ s formula), we hav e ¯ x 2 ( t ) = x 2 ( t )+Φ 2 ( t, s, x 1 ( ˜ t n 0 ) , ¯ x 2 ( ˜ t n 0 ))( ¯ x 2 ( ˜ t n 0 ) − x 2 ( ˜ t n 0 ))+ R t ˜ t n 0 Φ 2 ( t, s, x 1 ( s ) , ¯ x 2 ( s ))( ζ 21 ( s )+ ζ 22 ( s )) ds where x 1 ( t ) ≡ x 1 is constant (since ˙ x 1 = 0 ) and x 2 ( t ) = r ( x 1 ) . Moreover , for t ≥ s , Φ 2 ( · ) satisfies linear system ˙ Φ 2 ( t, s, x 0 ) = J 2 ( x 1 ( t ) , x 2 ( t ))Φ 2 ( t, s, x 0 ) , with initial data Φ 2 ( t, s, x 0 ) = I and x 0 = ( x 1 , 0 , x 2 , 0 ) and where J 2 the Jacobian of − D 2 f 2 ( x 1 , · ) . Gi ven that x ∗ = ( x ∗ 1 , r ( x ∗ 1 )) is a stable differential Stackelber g equilibrium, J 2 ( x ∗ ) is positiv e definite. Hence, as in [ 57 , Lem. 5.3], we can find M , κ 2 > 0 such that for t ≥ s , x 2 , 0 ∈ V r , k Φ 2 ( t, s, x 1 , 0 , x 2 , 0 ) k ≤ M e − κ 2 ( t − s ) . This result follo ws from standard results on stability of linear systems (see, e.g., Callier and Desoer [ 14 , § 7.2, Thm. 33]) along with a bound on R t s k D 2 2 f 2 ( x 1 , x 2 ( τ , s, ˜ x 0 )) − D 2 2 f 2 ( x ∗ ) k dτ for ˜ x 0 ∈ V q (see, e.g., Thoppe and Borkar [ 57 , Lem 5.2]). Analogously we can define linear interpolates or asymptotic pseudo-trajectories for x 1 ,k . Indeed, ¯ x 1 ( t ) = x 1 ,k + t − ˆ t k γ 1 ,k ( x 1 ,k +1 − x 1 ,k ) are the linear interpolated points between the samples { x 1 ,k } where ˆ t k +1 = ˆ t k + γ 1 ,k , and ˆ t 0 = 0 . Then, as abov e, Alekseev’ s formula can again be applied to get ¯ x 1 ( t ) = x 1 ( t, ˆ t n 0 , y ( ˆ t n 0 )) + Φ 1 ( t, ˆ t n 0 , ¯ x 1 ( ˆ t n 0 ))( ¯ x 1 ( ˆ t n 0 ) − x 1 ( ˆ t n 0 )) + R t ˆ t n 0 Φ 1 ( t, s, ¯ x 1 ( s ))( ζ 11 ( s ) + ζ 12 ( s ) + ζ 13 ( s )) ds where x 1 ( t ) ≡ x ∗ 1 (again, since ˙ x 1 = 0 ) and the follo wing hold: ζ 11 ( s ) = D f 1 ( x 1 ,k , r 2 ( x 1 ,k )) − D f 1 ( ¯ x 1 ( s ) , r 2 ( ¯ x 1 ( s ))) ζ 12 ( s ) = D f 1 ( x k ) − D f 1 ( x 1 ,k , r ( x 1 ,k )) ζ 13 ( s ) = w 1 ,k +1 Moreov er, Φ 1 is the solution to a linear system with dynamics J 1 ( x ∗ 1 , r ( x ∗ 1 )) , the Jacobian of − Df 1 ( · , r ( · )) , and with initial data Φ 1 ( s, s, x 1 , 0 ) = I . This linear system, as abov e, has bound k Φ 1 ( t, s, x 1 , 0 ) k ≤ M 1 e κ 1 ( t − 1) for some M 1 , κ 1 > 0 . 33 F I E Z , C H A S N OV , R A T L I FF No w , in addition to the linear iterpolates for x 1 ,k and x 2 ,k , we define an auxiliary sequence represent- ing the leader’ s conjecture about the follower with the goal of bounding the normed difference between follo wer’ s response and this auxiliary sequence. Indeed, using a T aylor expansion of the implicitly defined map r , we get z k +1 = z k + D r ( x 1 ,k )( x 1 ,k +1 − x 1 ,k ) + δ k +1 (15) where δ k +1 are the remainder terms which satisfy k δ k +1 k ≤ L r k x 1 ,k +1 − x 1 ,k k 2 by assumption. Plugging in x 1 ,k +1 , z k +1 = z k + γ 2 ,k − D 2 f 2 ( x 1 ,k , z k ) + τ k D r ( x 1 ,k )( w 1 ,k +1 − D f 1 ( x 1 ,k , x 2 ,k ) + γ − 1 2 ,k δ k +1 ) . The terms after − D 2 f 2 are o (1) , and hence asymptotically negligible, so that this z sequence tracks dy- namics as x 2 ,k . Using similar techniques as above, we can express linear interpolates of the leader’ s belief regarding the follo wer’ s reaction as ¯ z ( t ) = ¯ z ( ˜ t n 0 ) + R t ˜ t n 0 − D 2 f 2 ( x 1 ( s ) , ¯ z ( s )) + P 4 j =1 ζ 3 j ( s ) ds where the ζ 3 j ’ s are defined as follo ws: ζ 31 ( s ) = − D 2 f 2 ( x 1 ( ˜ t k ) , ¯ z ( ˜ t k )) + D 2 f 2 ( x 1 ( s ) , ¯ z ( s )) ζ 32 ( s ) = τ k D r ( x 1 ,k ) w 1 ,k +1 ζ 33 ( s ) = − τ k D f 1 ( x 1 ,k , x 2 ,k ) D r ( x 1 ,k ) ζ 34 ( s ) = 1 γ 2 ,k δ k +1 with τ k = γ 1 ,k /γ 2 ,k . Once again, Alekseev’ s formula can be applied where x 2 ( t ) = r ( x 1 ) and Φ 2 is the same as in the application of Aleksee v’ s to x 2 ,k . Indeed, this giv es us ¯ z ( ˜ t n ) = x 2 ( ˜ t n ) + Φ 2 ( ˜ t n , ˜ t n 0 , x 1 ( ˜ t n 0 ) , ¯ z ( ˜ t n 0 ))( ¯ z ( ˜ t n 0 ) − x 2 ( ˜ t n 0 )) + P n − 1 k = n 0 R ˜ t k +1 ˜ t k Φ 2 ( ˜ t n , s, x 1 ( s ) , ¯ z ( s ))( − D 2 f 2 ( x 1 ( ˜ t k ) , ¯ z ( ˜ t k )) + D 2 f 2 ( x 1 ( s ) , ¯ z ( s ))) ds (a) + P n − 1 k = n 0 R ˜ t k +1 ˜ t k Φ 2 ( ˜ t n , s, x 1 ( s ) , ¯ z ( s )) τ k D r ( x 1 ,k ) w 1 ,k +1 ds (b) − P n − 1 k = n 0 R ˜ t k +1 ˜ t k Φ 2 ( ˜ t n , s, x 1 ( s ) , ¯ z ( s )) τ k D f 1 ( x 1 ,k , x 2 ,k ) D r ( x 1 ,k ) ds (c) + P n − 1 k = n 0 R ˜ t k +1 ˜ t k Φ 2 ( ˜ t n , s, x 1 ( s ) , ¯ z ( s )) 1 γ 2 ,k δ k +1 ds (d) Applying the linear system stability results, we get that k Φ 2 ( ˜ t n , ˜ t n 0 , x 1 ( ˜ t n 0 ) , ¯ z ( ˜ t n 0 ))( ¯ z ( ˜ t n 0 ) − x 2 ( ˜ t n 0 )) k ≤ e − κ 2 ( ˜ t n − ˜ t n 0 ) k ¯ z ( ˜ t n 0 ) − x 2 ( ˜ t n 0 ) k . (16) Each of the terms (a)–(d) can be bound as in Lemma III.1–5 in [ 12 ]. The bounds are fairly straightforward using ( 16 ). No w that we ha ve each of these asymptotic pseudo-trajectories, we can sho w that with high probability , x 2 ,k and z k asymptotically contract to one another , leading to the conclusion that the follower’ s dynamics track the leader’ s belief about the follower’ s reaction. Moreover , we can bound the dif ference between each x i,k , using ¯ x i ( t i,k ) = x i,k , and the continuous flow x i ( t ) on each interval [ t i,k , t i,k +1 ) for each i = 1 , 2 and where t 1 ,k = ˆ t k and t 2 ,k = ˜ t k . These normed-difference bounds can then be le veraged to obtain concentration bounds by taking a union bound across all continuous time intervals defined after suf ficiently large n 0 and conditioned on the events E n = { ¯ x 2 ( t ) ∈ V q ∀ t ∈ [ ˜ t n 0 , ˜ t n ] } and ˆ E n = { ¯ x 1 ( t ) ∈ V q ∀ t ∈ [ ˆ t n 0 , ˆ t n ] } . 34 T ow ards this end, define H n 0 = ( k ¯ x 2 ( ˜ t n 0 − x 2 ( ˜ t n 0 ) k + k ¯ z ( ˜ t n 0 ) − x 2 ( ˜ t n 0 ) k ) , S 1 ,n = P n − 1 k = n 0 R ˆ t k +1 ˆ t k Φ 1 ( ˆ t n , s, ¯ x 1 ( ˆ t k )) ds w 1 ,k +1 , and S 2 ,n = P n − 1 k = n 0 R ˜ t k +1 ˜ t k Φ 2 ( ˜ t n , s, x 1 ( ˜ t k ) , ¯ x 2 ( ˜ t k )) ds w 2 ,k +1 . Applying Lemma 5.8 [ 57 ], conditioned on E n , we get there exists some constant K > 0 such that k ¯ x 2 ( ˜ t n ) − x 2 ( ˜ t n ) k ≤ k Φ 2 ( ˜ t n , ˜ t n 0 , x 1 , ¯ x 2 ( ˜ t n 0 ))( ¯ x 2 ( ˜ t n 0 ) − x 2 ( ˜ t n 0 )) k + K k S 2 ,n k + sup n 0 ≤ k ≤ n − 1 γ 2 ,k + sup n 0 ≤ k ≤ n − 1 γ 2 ,k k w 2 ,k +1 k 2 Using the bound on the linear system Φ 2 ( · ) , this exactly leads to the bound k ¯ x 2 ( ˜ t n ) − x 2 ( ˜ t n ) k ≤ K e − κ 2 ( ˜ t n − ˜ t n 0 ) k ¯ x 2 ( ˜ t n 0 ) − x 2 ( ˜ t n 0 ) k + k S 2 ,n k + sup n 0 ≤ k ≤ n − 1 γ 2 ,k + sup n 0 ≤ k ≤ n − 1 γ 2 ,k k w 2 ,k +1 k 2 Thus, lev eraging Lemma III.1–5 [ 57 ], we obtain the result of Lemma 1 in the main body of the paper , and stated here for easy access. Lemma 5 (Lemma 1 of main body) . F or any n ≥ n 0 , ther e exists K > 0 suc h that conditioned on E n , k x 2 ,n − z n k ≤ K k S 2 ,n k + e − κ 2 ( ˜ t n − ˜ t n 0 ) H n 0 + sup n 0 ≤ k ≤ n − 1 γ 2 ,k + sup n 0 ≤ k ≤ n − 1 γ 2 ,k k w 2 ,k +1 k 2 + sup n 0 ≤ k ≤ n − 1 τ k + sup n 0 ≤ k ≤ n − 1 τ k k w 1 ,k +1 k 2 . Lastly , in a similar fashion we can obtain a bound for the leader’ s sample path x 1 ,k . Lemma 6 (Lemma 2 of main body) . F or any n ≥ n 0 , ther e exists ¯ K > 0 such that conditioned on ˜ E n , k ¯ x 1 ( ˆ t n ) − x 1 ( ˆ t n ) k ≤ ¯ K k S 1 ,n k + sup n 0 ≤ k ≤ n − 1 k S 2 ,k k + sup n 0 ≤ k ≤ n − 1 γ 2 ,k + sup n 0 ≤ k ≤ n − 1 τ k + sup n 0 ≤ k ≤ n − 1 γ 2 ,k k w 2 ,k +1 k 2 + sup n 0 ≤ k ≤ n − 1 τ k k w 1 ,k +1 k 2 + e κ 1 ( ˆ t n − ˆ t n 0 ) k ¯ x 1 ( ˆ t n 0 ) − x 1 ( ˆ t n 0 ) k + sup n 0 ≤ k ≤ n − 1 τ k H n 0 . T o obtain concentration bounds, the results are exactly as in Section IV [ 12 ] which follo ws the analysis in [ 57 ]. Fix ε ∈ [0 , 1) and let N be such that γ 2 ,n ≤ ε/ (8 K ) , τ n ≤ ε/ (8 K ) for all n ≥ N . Let n 0 ≥ N and with K as in Lemma 1 , let T be such that e − κ 2 ( ˜ t n − ˜ t n 0 ) H n 0 ≤ ε/ (8 K ) for all n ≥ n 0 + T . Using Lemma 5 and Lemma 3.1 [ 57 ], P( k x 2 ,n − z n k ≤ ε, ∀ n ≥ ¯ n | x 2 ,n 0 , z n 0 ∈ B q 0 ) ≥ 1 − P( S ∞ n = n 0 A 1 ,n ∪ S ∞ n = n 0 A 2 ,n ∪ S ∞ n = n 0 A 3 ,n | x 2 ,n 0 , z n 0 ∈ B q 0 ) where A 1 ,n = E n , k S 2 ,n k > ε 8 K , A 2 ,n = E n , γ 2 ,k k w 2 ,n +1 k 2 > ε 8 K , 35 F I E Z , C H A S N OV , R A T L I FF and A 3 ,n = E n , τ n k w 1 ,n +1 k 2 > ε 8 K . T aking a union bound giv es P( k x 2 ,n − z n k ≤ ε, ∀ n ≥ ¯ n | x 2 ,n 0 , z n 0 ∈ B q 0 ) ≥ 1 − P ∞ n = n 0 P( A 1 ,n | x 2 ,n 0 , z n 0 ∈ B q 0 ) + P ∞ n = n 0 P( A 2 ,n | x 2 ,n 0 , z n 0 ∈ B q 0 ) + P ∞ n = n 0 P( A 3 ,n ) | x 2 ,n 0 , z n 0 ∈ B q 0 ) . Theorem 6.2 [ 57 ], gi ves bounds P ∞ n = n 0 P( A 2 ,n | x 2 ,n 0 , z n 0 ∈ B q 0 ) ≤ K 1 P ∞ n = n 0 exp − K 2 √ ε √ γ 2 ,k , (17) P ∞ n = n 0 P( A 3 ,n ) | x 2 ,n 0 , z n 0 ∈ B q 0 ) ≤ K 1 P ∞ n = n 0 exp − K 2 √ ε √ τ k , (18) and, by Theorem 6.3 [ 57 ] P ∞ n = n 0 P( A 1 ,n | x 2 ,n 0 , z n 0 ∈ B q 0 ) ≤ K 2 P ∞ n = n 0 exp − K 3 ε 2 β n (19) with β n = max n 0 ≤ k ≤ n − 1 e − κ 2 ( P n − 1 i = k +1 γ 2 ,i ) γ 2 ,k for some K 1 , K 2 , K 3 > 0 . This gi ves the result of Theorem 1 in the main body with C 1 = K 1 , C 2 = K 2 , C 3 = K 2 , C 4 = K 3 . An exactly analogous analysis holds for obtaining the concentration bound in Theorem 2 . A ppendix C. Regularizing the F ollower’ s Implicit Map The deriv ati ve of the implicit function used in the leader’ s update requires the follo wer’ s Hessian to be an isomorphism. In practice, this may not alw ays be true along the learning path. Consider the modified update x k +1 , 1 = x k, 1 − γ 1 ( D 1 f 1 ( x k ) − D 21 f 2 ( x k ) > ( D 2 2 f 2 ( x k ) + η I ) − 1 D 2 f 1 ( x k )) x k +1 , 2 = x k, 2 − γ 2 D 2 f 2 ( x k ) , in which we regularize the in verse of D 2 2 f 2 term. This update can be deri ved from the follo wing perspecti ve. Suppose player 1 views player 2 as optimizing a linearized version of its cost with a regularization term which captures the leader’ s lack of confidence in the local linearization holding globally: arg min y ( y − x 2 ,k ) > D 2 f 2 ( x k ) + η 2 k y − x 2 ,k k 2 . The first-order optimality conditions for this problem are 0 = D 2 f 2 ( x k ) + ( y − x k, 2 ) > D 2 2 f 2 ( x k ) + η ( y − x k, 2 ) = D 2 f 2 ( x k ) − η I + D 2 2 f 2 ( x k ) x k, 2 + ( D 2 2 f 2 ( x k ) + η I ) y. Hence, if the leader views the follower as updating along the gradient direction determined by these first order conditions, then the follo wer’ s response map is gi ven by x k +1 , 2 = x k, 2 − D 2 2 f 2 ( x k ) + η I − 1 D 2 f 2 ( x k ) . 36 Ignoring higher order terms in the deriv ative of the response map, the approximate Stackelberg update is gi ven by x k +1 , 1 = x k, 1 − γ 1 ( D 1 f 1 ( x k ) − D 21 f 2 ( x k ) > D 2 2 f 2 ( x k ) + η I − 1 D 2 f 1 ( x k )) x k +1 , 2 = x k, 2 − γ 2 D 2 f 2 ( x k ) . In our GAN experiments, we use the re gularized update since it is quite common for the discriminator’ s Hessian to be ill-conditioned if not de generate. Similarly , the Schur complement we present the eigen values for in the experiments includes the re gularized individual Hessian for the follo wer . Proposition 10 (Regularized Stackelberg: Sufficient Conditions) . A point x ∗ such that the first or der con- ditions D 1 f 1 ( x ) − D 21 f 2 ( x ) > ( D 2 2 f 2 ( x ) + η I ) − 1 D 2 f 1 ( x ) = 0 and D 2 f 2 ( x ) = 0 hold, and such that D 1 ( D 1 f 1 ( x ) − D 21 f 2 ( x ) > ( D 2 2 f 2 ( x ) + η I ) − 1 D 2 f 1 ( x )) > 0 and D 2 2 f 2 ( x ) > 0 is a dif fer ential Stackelber g equilibrium with r espect to the re gularized dynamics. Proposition 11 (Re gularized Stack elberg: Necessary Conditions) . A dif fer ential Stac kelber g equilibrium x ∗ of the re gularized dynamics satisfies D 1 f 1 ( x ) − D 21 f 2 ( x ) > ( D 2 2 f 2 ( x ) + η I ) − 1 D 2 f 1 ( x ) = 0 and D 2 f 2 ( x ) = 0 hold, and D 1 ( D 1 f 1 ( x ) − D 21 f 2 ( x ) > ( D 2 2 f 2 ( x ) + η I ) − 1 D 2 f 1 ( x )) ≥ 0 and D 2 2 f 2 ( x ) ≥ 0 . This result can be seen by examining first and second order sufficient conditions for the leader’ s opti- mization problem gi ven the re gularized conjecture about the follo wer’ s update, i.e. arg min x 1 f 1 ( x 1 , x 2 ) | x 2 ∈ arg min y f 2 ( x 1 , y ) + η 2 k y k 2 , and for the problem follo wer is actually solving with its update arg min x 2 f 2 ( x 1 , x 2 ) . A ppendix D . Experiment Details This section includes complete details on the training process and hyper -parameters selected in the mixture of Gaussian and MNIST experiments. D.1 Mixture of Gaussians The underlying data distribution for the diamond experiment consists of Gaussian distributions with means gi ven by µ = [1 . 5 sin( ω ) , 1 . 5 cos( ω )] for ω ∈ { k π / 2 } 3 k =0 and each with cov ariance σ 2 I where σ 2 = 0 . 15 . Each sample of real data given to the discriminator is selected uniformly at random from the set of Gaussian distributions. The underlying data distribution for the circle experiment consists of Gaussian distributions with means giv en by µ = [sin( ω ) , cos( ω )] for ω ∈ { k π/ 4 } 7 k =0 and each with covariance σ 2 I where σ 2 = 0 . 3 . Each sample of real data giv en to the discriminator is selected uniformly at random from the set of Gaussian distributions. W e train the generator using latent vectors z ∈ R 16 sampled from a standard normal distribution in each training batch. The discriminator is trained using input vectors x ∈ R 2 sampled from the underlying distribution in each training batch. The batch size for each player in the game is 256. The network for the generator contains two hidden layers, each of which contain 32 neurons. The discriminator network consists of a single hidden layer with 32 neurons and it has a sigmoid activ ation follo wing the output layer . W e let the activ ation function follo wing the hidden layers be the T anh function and the ReLU function in the diamond and circle experiments, respectively . The initial learning rates for each player and for each learning rule is 0 . 0001 and 0 . 0004 in the diamond and circle experiments, respectiv ely . The objectiv e for the game in the diamond experiment is the saturating GAN objectiv e and in the circle experiment it is the 37 F I E Z , C H A S N OV , R A T L I FF non-saturating GAN objectiv e. W e update the parameters for each player and in each experiment using the AD AM optimizer with the def ault parameters of β 1 = 0 . 9 , β 2 = 0 . 999 , and = 10 − 8 . The learning rate for each player is decayed exponentially such that γ i,k = γ i ν k i . W e let ν 1 = ν 2 = 1 − 10 − 7 for simultaneous gradient descent and ν 1 = 1 − 10 − 5 and ν 1 = 1 − 10 − 7 for the Stackelberg update. W e regularize the implicit map of the follo wer as detailed in Appendix C using the parameter η = 1 . D.2 MNIST T o underlying data distribution for the MNIST experiments consists of digits 0 and 1 from the MNIST training dataset or each digit from the MNIST training dataset. W e scale each image to the range [ − 1 , 1] . Each sample of real data giv en to the discriminator is selected sequentially from a shuffled version of the dataset. The batch size for each player is 256. W e train the generator using latent z ∈ R 100 sampled from a standard normal distribution in each training batch. The discriminator is trained using input vectorized images x ∈ R 28 × 28 sampled from the underlying distribution in each training batch. W e use the DCGAN architecture [ 49 ] for our generator and discriminator . Since DCGAN was built for 64 × 64 images, we adapt it to handle 28 × 28 images in the final layer . W e follow the parameter choices from the DCGAN paper [ 49 ]. This means we initialize the weights using a zero-centered centered Normal distribution with standard deviation 0 . 02 , optimize using ADAM with parameters β 1 = 0 . 5 , β 2 = 0 . 999 , and = 10 − 8 , and set the initial learning rates to be 0 . 0002 . The learning rate for each player is decayed exponentially such that γ i,k = γ i ν k i and ν 1 = 1 − 10 − 5 and ν 1 = 1 − 10 − 7 . W e regularize the implicit map of the follower as detailed in Appendix C using the parameter η = 5000 . If we view the regularization as a linear function of the number of parameters in the discriminator , then this selection of regularization is nearly equal to that from the mixture of Gaussian experiments. A ppendix E. Computing the Stackelber g Update and Schur Complement The learning rule for the leader in volves computing an in verse-Hessian-vector product for the D 2 2 f 2 ( x ) in verse term and Jacobian-vector product for the D 12 f 2 ( x ) term. These operations can be done effi- ciently in Python by utilizing Jacobian-vector products in auto-dif ferentiation libraries combined with the sparse.LinearOperator class in scipy . These objects can also be used to compute their eigen val- ues, inv erses, or the Schur complement of the game dynamics using the scipy.sparse.linalg pack- age. W e found that the conjugate gradient method cg can compute the regularized in verse-Hessian-v ector products for the leader update accurately with 5 iterations and a warm start. The operators required for the leader update can be obtained by the follo wing. Consider the Jacobian of the simultaneous gradient descent learning dynamics ˙ x = − ω ( x ) at a critical point for the general sum game ( f 1 , f 2 ) : J ( x ) = D 2 1 f 1 ( x ) D 12 f 1 ( x ) D 21 f 2 ( x ) D 2 2 f 2 ( x ) . Its block components consist of four operators D ij f i ( x ) : X j → X i , i, j ∈ { 1 , 2 } that can be computed using forward-mode or re verse-mode Jacobian-vector products. Instantiating these operators as a linear operator in scipy allows us to compute the eigen values of the two player’ s individual Hessians. Proper- ties such as the real eigen values of a Hermitian matrix or complex eigen values of a square matrix can be computed using eigsh or eigs respectiv ely . Selecting to compute the smallest or largest k eigen values— sorted by either magnitude, real or imaginary v alues—allo ws one to e xamine the positi ve-definiteness of the operators. Operators can be combined to compute other operators relatively ef ficiently for large scale problems without requiring to compute their full matrix representation. For an example, take the Schur complement of the Jacobian above at fix ed network parameters x ∈ X 1 × X 2 , D 2 1 ( x ) − D 12 f 1 ( x )( D 2 2 f 2 ) − 1 ( x ) D 21 f 2 ( x ) . 38 W e create an operator S 1 ( x ) : X 1 → X 1 that maps a vector v to p − q by performing the following four operations: u = D 21 f 2 ( x ) v , w = ( D 2 2 f 2 ) − 1 ( x ) u , q = D 12 f 1 ( x ) w , and p = D 2 1 ( x ) v . Each of the operations can be computed using a single backward pass through the network except for computing w , since the in verse-Hessian requires an iterative method which can be computationally expensiv e. It solves the linear equation D 2 2 f 2 ( x ) w = u and there are various av ailable methods: we tested (bi)conjugate gradient methods, residual-based methods, or least-squares methods, and each of them provide varying amounts of error when compared with the exact solution. Particularly , when the Hessian is poorly conditioned, some methods may fail to conv erge. More in vestigation is required to determine which method is best suited for specific uses. For e xample, a fixed iteration method with warm start might be appropriate for computing the leader update online, while a residual-based method might be better for computing the the eigen values of the Schur complement. Specifically , for our mixture of gaussians and MNIST GANs, we found that computing the leader update using the conjugate gradient method with maximum of 5 iterations and warm-start works well. W e compared using the true Hessian for smaller scale problems and found the estimate to be within numerical precision. A ppendix F . N –F ollower Setting In this section, we show that the results extend to the setting where there is a single leader , but N non- cooperati ve follo wers. F .1 N + 1 Staggered Lear ners, All with Non-Unif orm Learning Rates Note that if there is a layered hierarchy in which each, for example, the first follower is a leader for the second follo wer , the second follo wer a leader for the third follower and so on, then the results in Section 3 apply under additional assumptions on the learning rates. For instance, consider a three player setting where γ 1 ,k = o ( γ 2 ,k ) and γ 2 ,k = o ( γ 3 ,k ) so that player 1 is the slo west player (hence, the ‘leader’), player 2 the second slowest, and player 3 the fastest, the ‘leader’. Then similar asymptotic analysis can be applied with the follo wing assumptions. Consider ˙ x i = 0 , i < 3 ˙ x 3 = F 3 ( x ) (20) where we will explicitly define F 3 shortly . Let x
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment