그래픽 협조 게임에서 위험과 보안의 균형
본 논문은 네트워크 상의 에이전트들이 두 가지 선택 중 하나를 조정하며 얻는 복리(복지)를 최적화하는 그래픽 협조 게임을 모델로, 운영자가 선택할 수 있는 로컬 유틸리티 파라미터 α에 따라 두 종류의 적대적 공격(광범위 공격과 집중 공격)에 대한 최악 위험을 정량화한다. α를 무작위로 선택하면 두 위험 사이의 근본적인 트레이드오프를 크게 완화할 수 있음을 보인다.
저자: Keith Paarporn, Mahnoosh Alizadeh, Jason R. Marden
본 연구는 네트워크 기반 분산 시스템이 두 가지 관습(예: 제품, 사회 규범, 정당) 중 하나를 선택하도록 유도되는 그래픽 협조 게임을 모델링하고, 시스템 운영자가 로컬 유틸리티 파라미터 α를 조정함으로써 적대적 공격에 대한 시스템 복지를 보호할 수 있는지를 분석한다. 먼저, 그래프 G=(N,E) 위에 N개의 에이전트가 존재하고, 각 에이전트 i는 이웃 j와 2×2 보상 행렬 V를 통해 상호작용한다. 행렬은 x와 y가 협조될 때 각각 1+α_sys와 1의 보상을 주며, x가 본질적으로 더 우수한 선택임을 반영한다. 에이전트 i의 총 복지는 모든 이웃과의 보상의 합 W_i(a_i,a_{-i})이며, 시스템 전체 복지는 W(a)=∑_i W_i(a_i,a_{-i})이다. 효율성은 W(a)와 가능한 최대 복지(모두 x를 선택했을 때)와의 비율로 정의된다.
시스템 운영자는 로그선형 학습(log‑linear learning)이라는 확률적 최선응답 메커니즘을 적용한다. 매 시간 단계마다 무작위로 선택된 에이전트가 현재 이웃 행동을 관찰하고, 자신의 유틸리티 U_i에 따라 확률적으로 행동을 바꾼다. 파라미터 β가 클수록 베스트‑리플라이에 가깝게 행동하고, β→0이면 무작위 선택이 된다. 이 알고리즘은 마르코프 체인을 형성하고, β→∞일 때 정적 안정 상태(stochastically stable states, SSS)가 존재한다. 기존 연구에 따르면, α_sys가 주어질 때 로그선형 학습은 항상 전부 x가 선택된 상태를 SSS로 만든다. 그러나 적이 에이전트의 유틸리티를 변조하면 이 특성이 깨질 수 있다.
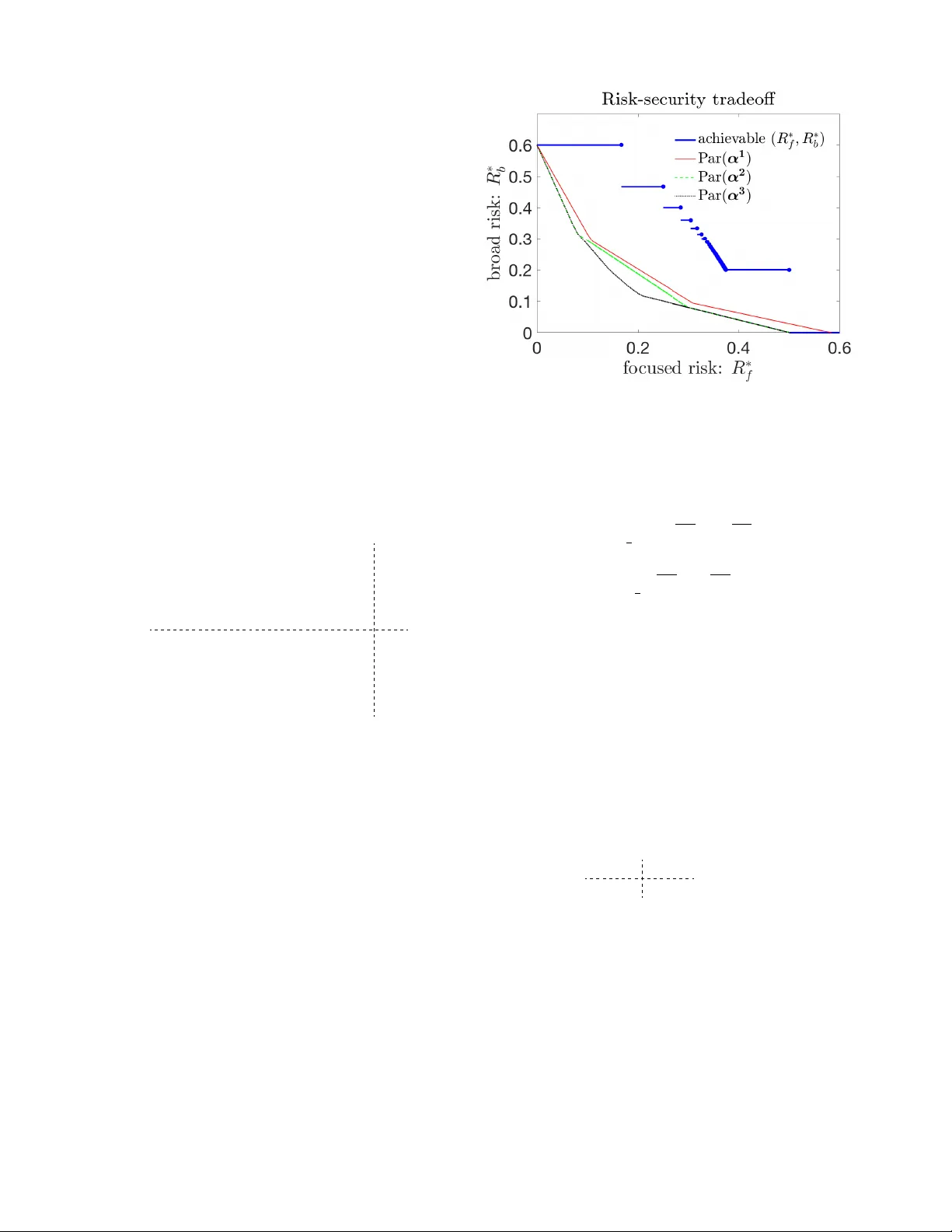
두 종류의 적대적 공격을 정의한다. (1) 광범위 공격(broad attack): 적은 각 에이전트에 임포스터 노드를 연결한다. 임포스터는 항상 x 혹은 y를 선택하도록 고정된다. 임포스터는 실제 네트워크에 포함되지 않으며, 오직 에이전트의 유틸리티에만 영향을 미친다. 임포스터 집합 S=(S_x,S_y)는 모든 노드에 대해 S_x∪S_y=N이며, S_x∩S_y=∅이다. 에이전트 i의 변형된 유틸리티는 ˜U_{α,i}=U_{α,i}+1_{i∈S_y}·1(a_i=y)+(1+α)·1_{i∈S_x}·1(a_i=x) 로 정의된다. 이때 운영자는 α>0을 선택해 전체 유틸리티를 조정한다. 위험 R_b(α,S;G)=1−J_b(α,S;G)이며, J_b는 최악 SSS에서 얻는 복지와 최적 복지의 비율이다. 최악 위험 R*_b(α) 는 모든 연결 그래프 G와 모든 가능한 S에 대해 최대값을 취한다. 정리 1에 따르면, R*_b(α)는 α가 구간 I_k=
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기