딥 강화학습 정책의 적대적 탄력성·견고성 벤치마크를 위한 강화학습 기반 방법
본 논문은 딥 강화학습(DRL) 정책이 상태 전이의 적대적 교란에 얼마나 견고하고 탄력적인지를 정량적으로 평가하기 위한 두 가지 RL 기반 벤치마크 기법을 제안한다. 정책의 표현 학습에서 발생하는 취약점과 정책 자체가 전이 분포 변화에 민감한 부분을 구분하고, 이를 바탕으로 테스트 시점의 탄력성(최소 교란 횟수)과 견고성(최대 적대적 후회)을 측정한다. 실험은 CartPole 환경에서 DQN, A2C, PPO2 정책에 적용했으며, A2C가 가장…
저자: Vahid Behzadan, William Hsu
본 논문은 딥 강화학습(Deep Reinforcement Learning, DRL) 정책이 상태 전이 단계에서 발생할 수 있는 적대적 교란에 대해 얼마나 탄력적(resilient)이고 견고(robust)한지를 정량적으로 평가하는 새로운 벤치마크 방법을 제시한다. 기존 연구는 주로 관측값 자체를 변형하는 적대적 예시(adversarial example)에 초점을 맞추어 정책의 취약성을 측정했으며, 이 과정에서 정책이 학습한 상태 표현(representation)과 정책이 전이 dynamics에 대해 갖는 민감도를 구분하지 못하는 문제점이 있었다. 저자들은 이러한 한계를 극복하기 위해 두 가지 핵심 접근을 제안한다.
첫 번째는 정책 취약성을 두 축으로 분리하는 수학적 정의이다. ‘표현 취약성’은 DRL 에이전트가 상태를 어떻게 인코딩하고 특징을 추출하는 과정에서 발생하는 약점을 의미하고, ‘전이 민감성’은 학습된 정책이 실제 환경의 상태 전이 확률분포 변화에 얼마나 민감하게 반응하는지를 나타낸다. 이를 바탕으로 두 가지 평가 문제를 정의한다. (1) 테스트‑시점 탄력성(Test‑time Resilience): 주어진 정책이 최대 후회(adversarial regret)를 초래하도록 하는 최소 교란 횟수를 찾는 문제. (2) 테스트‑시점 견고성(Test‑time Robustness): 정해진 교란 예산(δ_max) 하에서 달성 가능한 최대 후회를 찾는 문제. 여기서 ‘후회’는 정상(비교) 에이전트와 교란된 에이전트가 얻은 누적 보상의 차이로 정의된다.
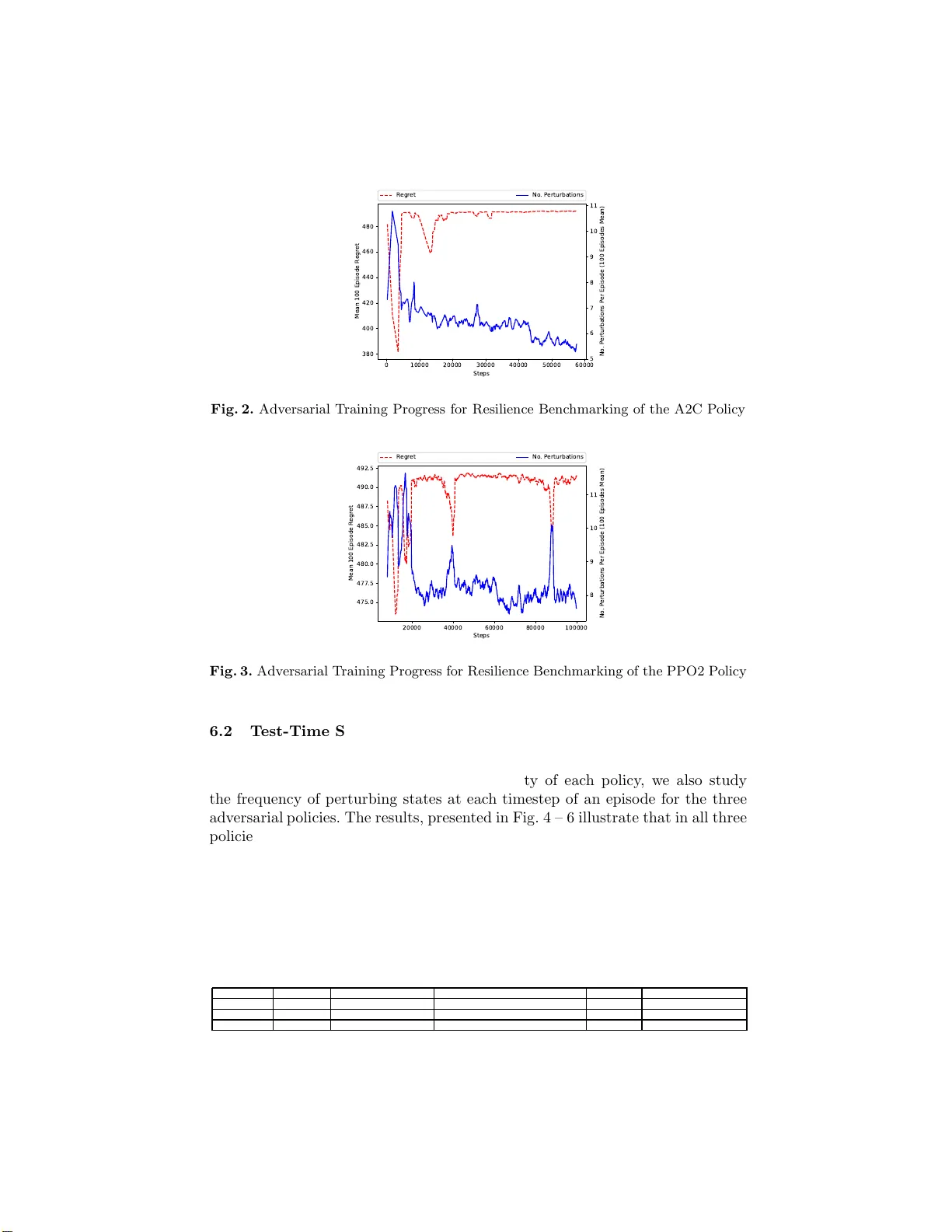
두 번째는 위 정의를 실제 측정 가능한 메트릭과 절차로 구현하는 RL‑기반 프레임워크이다. 적대적 에이전트를 별도의 강화학습 에이전트로 설정하고, 목표 정책의 상태‑행동 가치 함수(Q*)를 이용해 교란 행동을 선택한다. 탄력성 측정에서는 적대적 에이전트가 Q*값이 가장 낮은 행동을 강제로 선택하도록 하여, 교란이 발생할 때마다 일정 비용(c_adv) 을 부과한다. 알고리즘 1은 교란 여부에 따라 보상을 0 또는 –c_adv 로 설정하고, 에피소드 종료 시 남은 보상 차이를 추가한다. 훈련 과정에서 적대적 반환(R*_perturbed)과 최대 후회(R*_adv) 를 기록하고, 테스트 단계에서는 평균 교란 비용 C_adv 를 산출해 정책의 탄력성 하한을 제공한다.
견고성 측정은 탄력성 절차에 교란 예산 δ_max 를 도입해 변형한다. 알고리즘 2는 교란 횟수가 δ_max 를 초과하면 비용을 δ_max 배로 스케일링하고, 에피소드 종료 시 보상 차이를 추가한다. 이를 통해 정해진 예산 내에서 정책이 견딜 수 있는 최대 후회를 정량화한다. 두 절차 모두 ‘흰색 상자(white‑box)’ 상황을 가정해 목표 정책의 Q*를 직접 활용하거나, ‘검은색 상자(black‑box)’ 상황에서는 정책 모방 학습(imitation learning)으로 Q*를 근사한다.
실험은 OpenAI Gym의 CartPole 환경을 사용한다. 세 가지 대표적인 DRL 알고리즘—값‑반복 기반 DQN, 정책‑그라디언트 기반 PPO2, 액터‑크리틱 기반 A2C—를 각각 학습시킨 뒤, 동일한 적대적 DQN 에이전트를 이용해 제안한 두 메트릭을 측정한다. 교란 비용은 모든 상태·행동에 대해 c_adv=1 로 동일하게 설정했으며, 훈련은 적대적 후회가 200 에피소드 동안 안정화될 때까지 진행한다. 결과는 다음과 같다. A2C는 평균 7.69번의 교란으로 후회 488.16을 기록해 가장 높은 탄력성을 보였고, PPO2는 7.49번·490.47, DQN은 7.13번·491.15 순으로 뒤따랐다. 견고성 측면에서도 A2C가 가장 큰 후회를 달성했으며, 전반적으로 정책마다 교란에 대한 민감도가 차이 나는 것을 확인했다.
논문의 주요 기여는 세 가지이다. (1) 정책 취약성을 표현 학습과 전이 민감도로 명확히 구분한 이론적 프레임워크 제시, (2) 탄력성과 견고성을 정량화하는 두 가지 RL‑기반 벤치마크 절차와 메트릭 개발, (3) CartPole 환경에서 DQN, A2C, PPO2 정책에 적용해 제안 방법의 실현 가능성을 입증. 한편 한계점으로는 실험이 비교적 단순한 이산 상태·행동 환경에 국한되었으며, 교란 비용을 균일하게 설정한 점, 그리고 적대적 에이전트의 학습이 전역 최적에 도달하지 않을 가능성을 언급한다. 향후 연구에서는 연속 제어 환경, 물리적 노이즈·센서 결함 등 다양한 교란 모델, 그리고 방어 메커니즘(예: 적대적 훈련, 정규화)과의 통합 평가가 필요하다. 또한, 정책의 표현 취약성을 직접 분석하고, 이를 완화하기 위한 구조적 설계 가이드라인을 제시하는 것이 향후 과제로 제시된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기