RL-Based Method for Benchmarking the Adversarial Resilience and Robustness of Deep Reinforcement Learning Policies
This paper investigates the resilience and robustness of Deep Reinforcement Learning (DRL) policies to adversarial perturbations in the state space. We first present an approach for the disentanglement of vulnerabilities caused by representation lear…
Authors: Vahid Behzadan, William Hsu
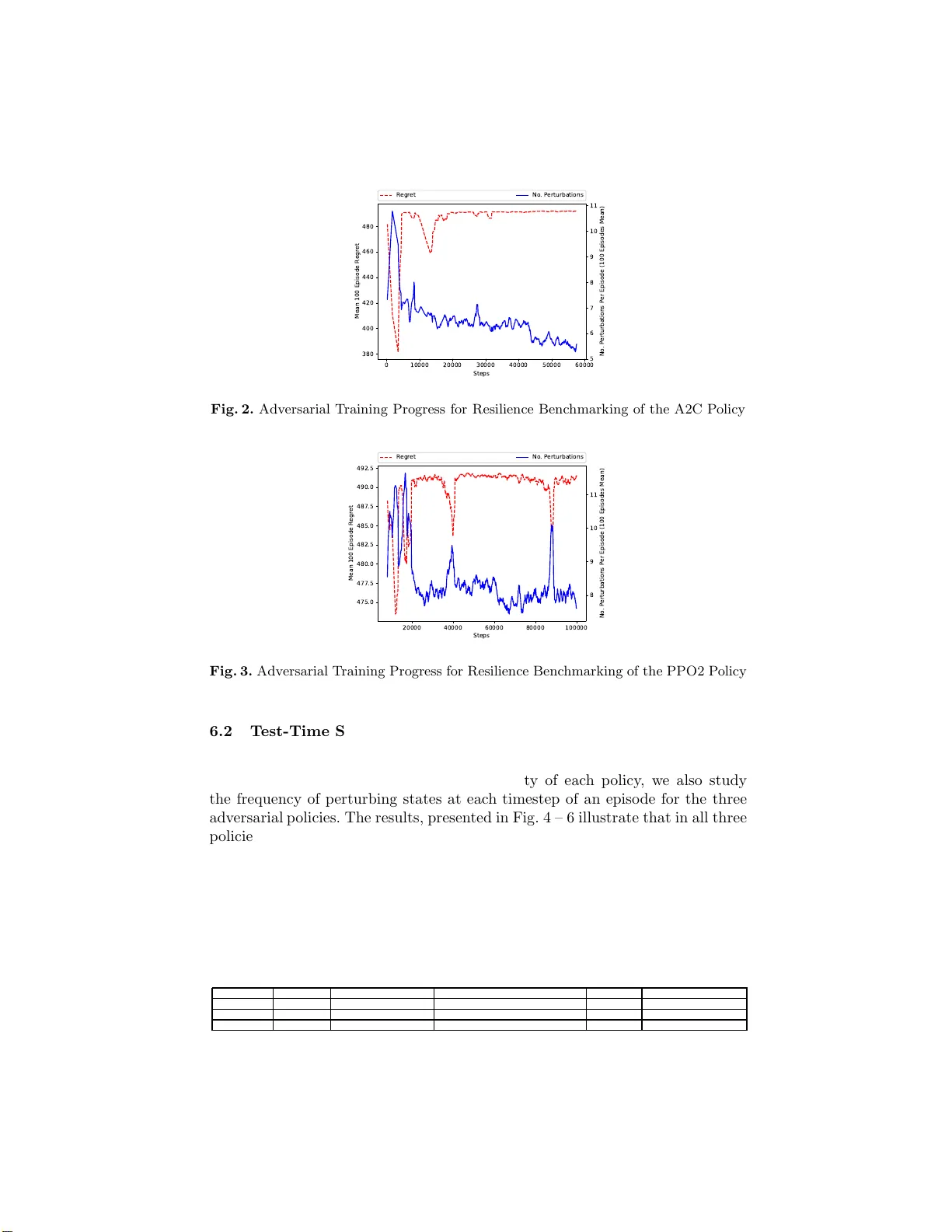
RL-Based Metho d for Benc hmarking the Adv ersarial Resilience and Robustness of Deep Reinforcemen t Learning P olicies V ahid Behzadan 1 and William Hsu 1 { behz adan, bhsu } @ ksu.edu Kansas State Universit y Abstract. This pap er inv estigates the resilience and robustness of Deep Reinforcemen t Learning (DRL) p ol icies to adversarial p erturbations in the state space. Accordingly , we first presen t an approach for the disen- tanglemen t o f vulnerabilities caused by representation learning of DRL agen ts f rom those that stem from the sensitivit y of the DRL p olicies to distributional shifts in state transitions. Building on this approac h, w e propose tw o RL-based tec hn iques for quan titative b enc hmark ing of adversa rial resil ience and robu stness in DRL p olicies a gainst perturba- tions of state transitions. W e demonstrate the feasibilit y of our prop osals through exp erimen tal ev aluatio n of resilience and robu stn ess i n DQN, A2C, and PPO2 p olicie s trained in the Cartp ole environmen t. Keywords: Deep Reinforcemen t Learning · Adversaria l Attack · Policy Generalization · Resilience · rob u stness · b enc hmarkin g . 1 In tro duction Since the rep orts b y Behzadan & Munir [1] and Huang et al. [5], the primary emphasis of the s tate of the art in DRL security [2] has been on the vulnera bilit y of p olicies to state-space p e rturbations. In particular , the ma nipulation of the po licy via adversarial exa mples [4] has rema ined the main fo cus of cur ren t liter- ature on this issue. How ever, this bias towards a dv ersar ial example attac ks g ives rise to a critical shortcoming: the analys es of such attacks fail to disen tang le the vulnerability caused b y the learned representation and that which is due to the sensitivity of the DRL dyna mics to distributional shifts in state transitions . Also, the p erformance of de fense s pr oposed for a dv ersar ial example attacks ar e inherently limited to the considered attack mechanisms. As the most s uccessful techn ique for mit ig ation o f adversarial examples, adversarial training is known to enha nce the r obustness of ma c hine lear ning mo dels to the type of attack used for gener ating the training adversarial ex a mples, while lea ving the model vul- nerable to o ther types of attacks[8]. F urthermore, the curr en t literature fails to provide s olutions and appr oac hes which ca n be used in practice to ev aluate and improv e the robustness and r esilience of DRL p olicies to attac ks that exploit the sensitivity to state transitio ns. Also, there remains a need for qua n titative 2 V ahid Behzadan and William Hsu { behzadan , bhsu } @ksu.edu approaches to measure and b enc hmar k the resilience and r obustness of DRL po licies in a r eusable and generaliza ble manner. In re s ponse to these sho rtcomings, this pa p er aims to addr ess the pr oblem of quantifying and b enc hmark ing the robustness and resilience o f a DRL a gen t to adversarial p erturbations of state transitions at test-time, in a manner that is indep enden t of the a ttac k t yp e. This improv es the gener alization of current techn iques tha t ana lyze the mo del a gainst sp ecific a dv ersar ial ex a mple attacks. Accordingly , the main co n tributions of this pap er are as follows: 1. W e present formulations of the resilience and ro bustness problems that e n- able the disen tang le men t of limitation in representation learning from sensi- tivit y of p olicies to state transitio n dynamics. 2. W e prop ose t wo RL-based techniques and corresp onding metrics for the mea- surement and b enchm a r king of resilience and ro bustness of DRL p olicies to per turbations of state transitions, 3. W e demons trate the feasibility of our prop osal through exp e rimen tal ev alu- ation of their p erformance on DQN, A2C, and PP O2 a gen ts trained in the Cartp ole environment . The rema inder of this pap er is organized as follo ws: Section 2 defines and formulates the pro blems of adv ers a rial resilience and robustness in DRL. Our prop osed metho ds for b enc hmark ing the test-time resilie nce and r obustness o f DRL po licies are presented in Sections 3 and 4. Section 5 provides the details of exp erimen tal setup for ev a luating the p erformance of our prop osals, with the corres p onding results pr esen ted in Sectio n 6. The pap er concludes in Section 7 with a summar y of findings a nd remar ks on future directio ns of r esearch . 2 Problem F orm ulation W e consider the the generic problem of RL in the settings of a Mar k ov Decision Pro cess (MDP), describ ed by the tuple M D P := < S , A , R , P > , where S is the set o f reachable states in the process , A is the set of av ailable actions, R is the mapping of transitions to the immediate re ward, and P repr esen ts the transition probabilities (i.e., state dynamics), whic h ar e initially unknown to RL agents. A t any g iv en time-step t , the MDP is at a state s t ∈ S . The RL agent’s ch o ice of action at time t , a t ∈ A causes a transition from s t to a state s t +1 according to the transition pro ba bilit y P ( s t +1 | s t , a t ). The a gen t receives a reward r t +1 = R ( s t , a t , s t +1 ) for choos ing the a c tion a t at state s t . In tera ctions of the age nt with MDP ar e deter mined b y the p olicy π . When such in teractio ns are deterministic, the p olicy π : S → A is a mapping betw een the states and their cor responding actions. A sto c hastic p o licy π ( s ) represents the probability distribution of implementing an y actio n a ∈ A at state s . The goal of RL is to lea rn a p olicy that ma x imizes the exp ected discounted return E [ R t ], where R t = P ∞ k =0 γ k r t + k ; with r t denoting the instantaneous r ew ard received at time t , and γ is a discount factor γ ∈ [0 , 1]. T o fa cilitate the formal statemen t of a dv ersar ial resilience and r obustness, we first in tro duce the following definitions: Benc h m ark in g Resilience and Robustness in DRL 3 – A dversarial R e gr et at time T is the difference betw een r eturn obta ine d by the nomina l (unp erturb ed) agent at time T and the return obtained by the p erturb ed agent at time T . F ormally : ˆ R adv ( T ) = R nominal ( T ) − R pertur bed ( T ). The time T may represent either the termina l timestep o f an episo de, or the time-horizon of interest in the analys is. – A dversarial Budget is defined by the one or more of the following pa- rameters: the maximum num b er of features that can b e p erturb ed in the observ ations ( O max ∈ [0 , ∞ ] ), the max im um n umber of o bserv a tio ns that can b e p erturbed ( N max ∈ [0 , ∞ ] ), and the probability of p erturbing each observ ation ( P ( pertu rb ) ∈ [0 , 1] ). Building on these tw o concepts, we define the problems of adversarial r e- silience and robustness as follows: 1. T est-Time R esil ienc e: The minimu m num b er of s ta te p erturbations re- quired to incur the maximum reduction to the total retur n at time T (de- noted by ˆ R adv ( T )) for an agent driven by a p olicy π ( s ) in an environment with transition dynamics P . 2. T est-Time R obustness: The maximum adversarial regret ˆ R adv ( T ) = ǫ max achiev able via a maximum o f δ max state p erturbations for an agent driven by a po licy π ( s ) in an environmen t with tra nsition dynamics P . The following sections provide the details o f our prop osed so lutio ns to each of the aforementioned problem settings . 3 Benc hmarking of T est-Tim e Resilience This problem can b e mo deled as that o f finding an optimal adversaria l p olicy π adv ( s ) that minimizes the cost incurre d to the a dversar y C adv in or der to im- po se the ma xim um adversarial reg ret ˆ R adv ( T ), the worst-case v alue of which is the highes t cum ulative reward achiev ed by the target p olicy R max . Our prop osed approach is throug h the formulation of this pro blem in the s e tt ing s of reinforce- men t learning. T he state spac e in the corr esponding MDP is the set of s ta tes in the targe t MDP , augmented with the action of the target in that sta te, i.e., S ′ = {∀ s ∈ S : ( s, π ( s )) } . F or the purp ose of mea suring a low er- bound for the resilience, we consider the worst-case white-box adversary , which is able to im- po se targeted state p erturbations with 10 0% success ra te, to induce any action within the p ermissible action- set of the ta rget A which has the lowest Q -v alue at any state s according to the targ et’s optimal state- a ction v alue function Q ∗ . In this ca se, the s et o f p ermissible adversaria l actions at any s tate s is given by: A adv ( s ) = { No Action } ∪ A \ π ∗ ( s ) (1) Where A is the a c tio n set of the tar geted ag en t, a nd π : S → A is the p olicy of the targ eted age nt. In the prop osed approach, the a dv ersa r ial reward v alue is determined via the pr ocedure deta iled in Algorithm 1: 4 V ahid Behzadan and William Hsu { behzadan , bhsu } @ksu.edu Algorithm 1 Reward Assignment of RL Agent for Measur ing Adversarial Re- silience Require: T arget p olicy π ∗ , P erturbation cost function c adv ( ., . ), Maxim um ac hiev able score R max , Optimal state-action val ue function Q ∗ ( ., . ), Current adversarial p oli cy π adv , Current sta te s t , Current co unt of adversa rial actions Adv C ount , Current score R t Set T oPerturb ← π adv ( s t ) if T oPerturb is F alse then a t ← π ∗ ( s t ) Rew ar d ← 0 else a ′ t ← arg min a Q ∗ ( s t , a ) Rew ar d ← − c adv ( s t , a ′ t ) end if if either s t or s ′ t is terminal then Rew ar d + = ( R max − R t ) end if where c ( s t , a ′ t ) is the co s t of imp osing the sta te per turbation which induces the adversarial a ction a ′ t at s tate s t . It is noteworth y that if the v alue o f c ( s t , a ′ t ) is in v aria n t with resp ect to a ′ t , the a dv ersar ial action set reduces to: A adv ( s ) = { No Action , Induc e arg min a Q ( s, a ) } (2) T o obtain the test-time res ilience of p olicy π ∗ to state p erturbations, w e prop ose the following pro cedure: 1. If the state-action v alue function of the target Q ∗ is not av ailable (i.e., black- box testing), a ppro ximate Q ∗ via policy imitation [6]. 2. T rain the adversaria l ag e n t against the ta rget following π in its training envi- ronment, repo rt the optimal adversarial r eturn R ∗ pertur bed and the maxim um adversarial regr et R ∗ adv ( T ). 3. Apply the adversarial p olicy a gainst the tar g et in N episo des, recor d tota l cost C adv for each episo de, 4. Report the average of C adv ov er N episo des as the mean test-time resilience of π in the g iv en environment. This pro cedure introduces 3 metrics for the quantification of test-time resilience : the optima l adversarial return R ∗ pertur bed achiev ed in the training pro c ess of the adversarial p olicy , the maxim um adversarial regre t R ∗ adv ( T ) achieved during training, a nd the mean per- episode o f the total cost C adv . These metrics pr o vide the means to b enc hmar k and compa r e the test-time resilience of differen t po licies trained to optimize the agent’s p erformance in a given environmen t. F or the purpose of measuring r esilience, we consider co n vergence to b e rea c hed if the average a dv ersar ial re g ret ov er 200 episo des remains constant. This defini- tion r elaxes the instabilities that may arise due to the co nfiguration and architec- ture of the DRL tra ining pro cess. It is noteworthy tha t depending on the training Benc h m ark in g Resilience and Robustness in DRL 5 algorithm and design par ameters, this pro cedure is not guaranteed to conv erge to the global optimal. How ever, b y rep orting the num b er o f iterations and config- uration of random num b er g enerators with a co ns tan t seed, the rep orted results present a repro ducible lo ose low er b ound on the adversarial resilience of the tar - get. Also , the tra ined a dv ersar ial p olicy can b e used to test other p olicies for compariso n o f suc h low er -bounds under the same adversarial strategy . 4 Benc hmarking of T est-Tim e Robustness F or this problem, we prop ose a mo dified v er sion of the pro cedure developed for benchmarking the test-time resilience. Accordingly , the re ward function is adjusted to account for the lack of a target ǫ , a s well as the addition of an adversarial budget cons tr ain t δ max . The re ward measurement of this pr ocess is outlined in Algorithm 2: Algorithm 2 Reward Assignment of RL Agent for Measuring Adversarial Ro- bustness Require: Maximum p erturbation budget δ max , Perturbation cost function c adv ( ., . ), Maxim um achiev able score R max , Optimal state-action v alue function Q ∗ ( ., . ), Cur- rent adversarial p oli cy π adv , Current state s , Current count of adversa rial actions Adv C ount , Current score R t Set Adversaria lAction ← π adv ( s ) if AdversarialAction is NoAction then Rew ar d ← 0 else if A dvC ount ≥ δ max then Rew ar d ← − c a dv ( s, Adve rsar ialAction ) × δ max Adv C ount + = 1 else Rew ar d ← − c a dv ( s, Adve rsar ialAction ) Adv C ount + = 1 end if if s is terminal then Rew ar d + = 1 . 0 ∗ ( R max − R t ) Adv C ount ← 0 end if The pro posed procedur e for measuring the test-time r obustness o f a g iv en DRL policy to adversarial state p erturbations is as follows: 1. If the state-action v alue function of the target Q ∗ is not av ailable (i.e., black- box testing settings), approximate Q ∗ from the p olicy us ing imitation learn- ing (e.g., [6 ]), 2. T rain the adversarial agent against the target p olicy π ∗ in its training envi- ronment, rep ort the maxim um adversarial regret R ∗ adv ( T ) fo r time T a c hieved at adversarial optimalit y , 6 V ahid Behzadan and William Hsu { behzadan , bhsu } @ksu.edu 3. Apply the adversarial p olicy a gainst the ta rget for N episo des, record the adversarial regr et a t the end o f each episo de R adv ( T ), 4. Report the average of R adv ( T ) ov er N episo des as the mean per -episode test-time robustness of π ∗ in the g iv en e n vironment. 5 Exp erimen t Setup En vironme n t and T a rget Policies: T o demons tr ate the p erformance of the prop osed pro cedures for benchmarking the test-time ro bus tness and re s ilience in DRL p olicies, we present the analysis of the aforementioned measurements for p olicies tr ained in the Car tP ole environment in Op enAI Gym [3]. The con- sidered p olicies are chosen to repre s en t the c o mmonly-adopted state of the art metho d from ea ch class of DRL algorithms. F rom v a lue-iteration a pproaches, we consider DQN with prioritized replay . F r om p o licy g r adien t appr oac hes, we consider PPO2. As for acto r-critic metho ds, we inv estig ate the A2C metho d. T able 5 presents the specifica tions of the CartPole en viro nmen t, and T ables 5 – 5 pr o vide the parameter settings of each target po licy . T able 1. Sp eci fications of the CartP ole Environment Observ ation Space Cart Posi tion [-4.8, +4.8] Cart V elocity [-inf, +inf] P ole Angle [-24 deg, +24 deg] P ole V elo cit y at Tip [-inf, +inf] Action Space 0 : Push cart to the left 1 : Push cart to the right Rewa rd +1 for every step tak en T ermination P ole Angle is more than 12 degrees Cart Posi tion is more than 2.4 Episode length is greater than 500 T able 2. P arameters of DQN Policy No. Timesteps 10 5 γ 0 . 99 Learning Rate 10 − 3 Replay Buffer S ize 50000 First Learning Step 1000 T arget Netw ork Up date F req. 500 Prioritized Replay T rue Exploration P arameter-Space Noise Exploration F raction 0.1 Final Exploration Prob. 0.02 Max. T otal Reward 500 Benc h m ark in g Resilience and Robustness in DRL 7 T able 3. Parameters of A2C P olicy No. Timesteps 5 × 10 5 γ 0 . 99 Learning Rate 7 × 10 − 4 Entrop y Coefficient 0.0 V alue F u nction Co efficien t 0.25 Max. T otal Reward 500 T able 4. Parameters of A2C P olicy No. En vironments 8 No. Timesteps 10 6 No. Runs p er Environment p er Up date 2048 No. Minibatc hes p er up date 32 Bias-V ariance T rade-O ff F actor 0.95 No. Surrogate Epo c hs 10 γ 0 . 99 Learning Rate 3 × 10 − 4 Entrop y Coefficient 0.0 V alue F unction Co efficie nt 0.5 Max. T otal Reward 500 Adv ersarial Agent: In these ex periments, the a dv ersar ial ag en t is a DQN agent with the hyperpara meters pr o vided in T able 5. W e consider a homogeneous per turbation cost function for all state per turbations, that is ∀ s, a ′ : c adv ( s, a ′ ) = c adv . F or bo th the resilience and robustnes s measurements, we set c adv = 1 (i.e., each p erturbation incurs a cos t o f 1 to the adversary). The training pro cess is terminated when the adversarial r egret is maximized and the 100-episo de av er age of the n umber of a dv ersar ial p erturbations is qua si-stable for 200 episo des. T able 5. P arameters of DQN Policy Max. Timesteps 10 5 γ 0 . 99 Learning Rate 10 − 3 Replay Buffer S ize 50000 First Learning Step 1000 T arget Netw ork Up date F req. 500 Exp erience Selection Prioritized Rep lay Exploration P arameter-Space Noise Exploration F raction 0.1 Final Exploration Prob. 0.02 8 V ahid Behzadan and William Hsu { behzadan , bhsu } @ksu.edu 6 Results 6.1 Resil ience Benc hmarks W e consider the white-b o x settings in the training of adversaria l agents for r e- silience measurement. F or the DQN target, the optimal state-action v alue func- tion Q ∗ of the target is directly utilized. As for the A2C and PPO 2 tar gets, the state-action v a lue function is ca lculated from the internally-av aila ble state v alue estimations V ∗ ( s ) according to the following transformatio n: Q ∗ ( s t , a ) = r ( s t , a ) + γ V ∗ ( s t +1 ) (3) where s t +1 is the state resulting from a tra nsition out of state s t by implemen ting action a . T raining Results: The training progr ess plots o f a dversar ial DQN p olicy on the three tar g et p olicies a re presented in Fig.1 – 3. It ca n b e s een that a ll three po licies conv erge to the sa me o ptima. Ho wev er , for the a dv ersar y targeting the DQN p olicies, the conv ergence is a c hieved at a higher n umber of training steps. It is noteworthy that for all three policies , the mean-pe r -100 episo des of the minim um num b e r of perturba tions at con vergence is almost similar (as rep orted in T able 6 .2) , with A2C having the largest v alue of 7 . 69 pertur ba tions, PPO2 at 7 . 49 pe rturbations, and DQN having the lo west v a lue of 7 . 13. Also, the test-time per formance of these t r ained p olicies indicate similar results, with DQN requiring 6 . 95 per turbations to incur an adversaria l regr et of 491 . 15 , P PO2 requiring 7 . 72 per turbations for an adversarial r egret of 4 90 . 47, and A2C r equiring 8 . 7 1 p ertur- bations for an adversarial regret of 488 . 16. Acco rdingly , we can interpret these results as follows: the DQN p olicy ha s the low est adversarial resilience amo ng the three, follow ed b y the PPO 2 policy . Within the context o f this compariso n, the A2C p olicy is found to b e the most r e s ilien t to state-spac e p erturbation attacks. 0 2 0 0 0 0 4 0 0 0 0 6 0 0 0 0 8 0 0 0 0 1 0 0 0 0 0 1 2 0 0 0 0 1 4 0 0 0 0 1 6 0 0 0 0 S te p s 3 8 0 4 0 0 4 2 0 4 4 0 4 6 0 4 8 0 M e a n 1 0 0 Ep iso d e R e g r e t Re g r e t No . Pe r tu rb a tio n s 1 0 2 0 3 0 4 0 5 0 No . Pe r tu r b a ti on s Pe r E p i so d e (1 0 0 E p i so d e s M e a n ) Fig. 1. A dv ersarial T raining Progress for Resilience Benchmarking of the DQN Policy Benc h m ark in g Resilience and Robustness in DRL 9 0 1 0 0 0 0 2 0 0 0 0 3 0 0 0 0 4 0 0 0 0 5 0 0 0 0 6 0 0 0 0 S te p s 3 8 0 4 0 0 4 2 0 4 4 0 4 6 0 4 8 0 M e a n 1 0 0 Ep i sod e Re g r e t Re g r e t No . Pe r tu rb a tio n s 5 6 7 8 9 1 0 1 1 No . Pe r tu rb a tio n s Pe r E p iso d e ( 1 0 0 E p iso d e s M e a n ) Fig. 2. Adversaria l T raining Progress for Resilience Benchmarking of the A2C P olicy 2 0 0 0 0 4 0 0 0 0 6 0 0 0 0 8 0 0 0 0 1 0 0 0 0 0 S te p s 4 7 5 .0 4 7 7 .5 4 8 0 .0 4 8 2 .5 4 8 5 .0 4 8 7 .5 4 9 0 .0 4 9 2 .5 M e a n 1 0 0 Ep isod e Re g r e t Re g r e t No . Pe r tu rb a tio n s 8 9 1 0 1 1 No . Pe r turb a tio n s Pe r E p iso d e ( 1 0 0 E p i so d e s M e a n ) Fig. 3. A dv ersarial T raining Progress for Resilience Benc hmark in g of the PPO2 P olicy 6.2 T est-Time S tep-P erturbation Dis tribution: T o in vestigate the sta te-transition vulnerability of ea c h p olicy , we also study the frequency of p erturbing states at each timestep of an episo de fo r the thr ee adversarial po lic ies. The results, presented in Fig. 4 – 6 illus trate that in a ll three po licies, the initial timesteps hav e been the sub ject of most pertur ba tions. This result is noteworth y , a s it contradicts with the as sumption of Lin et a l.[7 ] that the most effectiv e adversarial p erturbations are those that are moun ted tow ar ds the terminal sta te of the environment. T able 6. Comparison of T est- Time and T raining-Time Resilience Measurements for DQN, A2C, and PPO2 Polic ies T arget Policy M ax. Regret Av g. Regret (T rai ning) Avg. No. Perturbat ions ( T raining) Avg. Re gr et Avg. No. Perturbations DQN 492 491.24 7.13 491.15 6.95 A2C 492 491.44 7.69 488.16 8.71 PPO2 492 491.72 7.49 490.47 7.72 10 V ahid Behzadan and William Hsu { behzadan , bhsu } @ksu.edu 0 1 2 3 4 5 6 7 8 9 1 0 T ime ste p in Ep iso d e 0 2 0 4 0 6 0 8 0 1 0 0 No . Pe r turb a ti on s Fig. 4. Perturbation Count Per Episo dic TimeStep in 100 R u ns T argeting DQN Policy 0 1 2 3 4 5 6 7 8 9 1 0 1 1 1 2 1 3 1 4 1 5 1 6 1 7 1 8 1 9 2 0 T ime ste p in Ep iso d e 0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0 No. Pe rtu rb a tio n s Fig. 5. Perturbation Coun t Per Episodic TimeStep in 100 Runs T argeting A2C Policy 6.3 Robustness Benchmarks T o de mo nstrate the p e rformance of o ur propo sed technique for benchmarking the robustness o f DRL p olicies, w e provide the training-time res ults for t wo cases of δ max = 10 and δ max = 5 for DQN, A2C, and PP O2 Policies. As illustr ated in Fig.7 – 9, all three a dv ersar ial p olicies conv er ge with s imilar minimum p ertur- bation c oun ts a s those obtained in resilience analys is. This is exp ected, as the resilience a nalysis established that the minimum num ber of a ctions required for maximum r egret is 7 . 5, w hich is less than the av ailable budget of δ max = 10 As for the ca se of δ max = 5, Fig.10 – 12 demonstrate significant differences betw een the three p olicies. In Fig.1 0 , it c a n b e see n that at 5 a c tio ns, the conv erge nc e o ccurs with an adversar ial regret of 462 . 5, while for A2C, the b est 5-action in- dication of c o n vergence o ccurs at an adversarial r egret of 224. As for PPO2, this v alue is at 268 . 2 . These results indicate a similar ranking o f the robustness in these p olicies, with DQN being the least-robust to maxim um of 5 p ertur- bations, and the A2C prev ailing as the most robust p olicy to maximum of 5 per turbations. Benc h m ark in g Resilience and Robustness in DRL 11 0 1 2 3 4 5 6 7 8 9 1 0 1 1 1 2 1 3 1 4 1 5 1 6 1 7 1 8 1 9 2 0 T ime ste p in Ep iso d e 0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0 No . Pe r turb a ti on s Fig. 6. P erturb atio n Count P er Episo dic TimeStep in 100 Runs T argeting PPO Policy 6.4 Case 1: δ max = 10: 0 2 5 0 0 0 5 0 0 0 0 7 5 0 0 0 1 0 0 0 0 0 1 2 5 0 0 0 1 5 0 0 0 0 1 7 5 0 0 0 S t e p s 3 2 5 3 5 0 3 7 5 4 0 0 4 2 5 4 5 0 4 7 5 Me a n 1 0 0 E p isod e R e g r e t R e g r e t No. Pe rt u r b a tion s 5 .0 7 .5 1 0 .0 1 2 .5 1 5 .0 1 7 .5 2 0 .0 2 2 .5 No. Pe rt u r b a tion s Pe r E p isod e (1 0 0 Ep isod e s M e an ) Fig. 7. Adversarial T raining Progress for Robustness Benchmarking - D QN, δ max = 10 0 2 0 0 0 0 4 0 0 0 0 6 0 0 0 0 8 0 0 0 0 1 0 0 0 0 0 S t e p s 1 0 0 1 5 0 2 0 0 2 5 0 3 0 0 3 5 0 4 0 0 4 5 0 5 0 0 M e a n 1 0 0 Ep i so d e R e g re t R e g r e t No. Pe rt u r b a tion s 5 1 0 1 5 2 0 2 5 No. Pe r turb a t i ons Pe r Ep i so d e (1 0 0 E p isod e s M e a n) Fig. 8. Adversarial T raining Progres s for R ob u stness Benchmarking - A2C, δ max = 10 12 V ahid Behzadan and William Hsu { behzadan , bhsu } @ksu.edu 0 2 0 0 0 0 4 0 0 0 0 6 0 0 0 0 8 0 0 0 0 1 0 0 0 0 0 1 2 0 0 0 0 1 4 0 0 0 0 1 6 0 0 0 0 S t e p s 2 7 5 3 0 0 3 2 5 3 5 0 3 7 5 4 0 0 4 2 5 4 5 0 4 7 5 Me a n 1 0 0 E p isod e R e g r e t R e g r e t No. Pe rt u r b a tion s 8 1 0 1 2 1 4 1 6 1 8 2 0 2 2 No. Pe rt u r b a tion s Pe r E p isod e (1 0 0 Ep isod e s M e an ) Fig. 9. A dv ersarial T raining Prog ress for Robustness Benchmarking - PPO2, δ max = 10 6.5 Case 2: δ max = 5: 0 2 5 0 0 0 5 0 0 0 0 7 5 0 0 0 1 0 0 0 0 0 1 2 5 0 0 0 1 5 0 0 0 0 1 7 5 0 0 0 S t e p s 1 0 0 1 5 0 2 0 0 2 5 0 3 0 0 3 5 0 4 0 0 4 5 0 5 0 0 Me a n 1 0 0 E p isod e R e g r e t R e g r e t No. Pe rt u r b a tion s 4 5 6 7 8 9 1 0 1 1 No. Pe rt u r b a tion s Pe r E p isod e (1 0 0 Ep isod e s M e an ) Fig. 10. Adversarial T raining Progress for Rob u stness Benc hmarking - DQN, δ max = 5 0 5 0 0 0 0 1 0 0 0 0 0 1 5 0 0 0 0 2 0 0 0 0 0 2 5 0 0 0 0 S t e p s 5 0 1 0 0 1 5 0 2 0 0 2 5 0 3 0 0 3 5 0 4 0 0 M e a n 1 0 0 Ep i so d e R e g re t R e g r e t No. Pe rt u r b a tion s 4 6 8 1 0 1 2 1 4 No. Pe r turb a t i ons Pe r Ep i so d e (1 0 0 E p isod e s M e a n) Fig. 11. Adversaria l T raining Progress for R ob u stness Benchmarking - A2C, δ max = 5 Benc h m ark in g Resilience and Robustness in DRL 13 1 0 0 0 0 2 0 0 0 0 3 0 0 0 0 4 0 0 0 0 S t e p s 2 0 0 2 2 0 2 4 0 2 6 0 2 8 0 Me a n 1 0 0 E p isod e R e g r e t R e g r e t No. Pe rt u r b a tion s 5 6 7 8 9 1 0 No. Pe rt u r b a tion s Pe r E p isod e (1 0 0 Ep isod e s M e an ) Fig. 12. Adversarial T raining Progress for Robustness Benchmarking - PPO2, δ max = 5 7 Conclusion W e presented tw o RL-based techniques for b enc hmark ing the r esilience and ro- bustness of DRL policies to adv er sarial p erturbations of state transition dynam- ics. E xperimental ev aluation of o ur prop osals demons trate the fea sibilit y of these techn iques for quantitativ e analysis o f p olicies with rega rds to their sensitivity to state transition dynamics. A promising ven ue of further explor ation is to study and extend the prop osed metho dologies for ev aluation of generalizatio n in DRL po licies. References 1. Behzadan, V., Munir, A.: V ulnerabilit y of deep reinforcement learning to policy in- duction attacks. In : International Conference on Mac hine Learning and Data Mining in Pattern Recognition. pp. 262–275 . Springer (2017) 2. Behzadan, V., Munir, A.: The faults in our pi stars: Security issues and op en chal- lenges in deep reinforcement learning. arXiv preprint arX iv :1 810.10369 ( 20 18) 3. Brockman, G., Cheung, V ., Pettersson, L ., Schneider, J., Sch ulman, J., T ang, J., Zarem ba, W.: Op enai gy m. arXiv p reprin t arXiv:1606.015 40 (2016) 4. Good fe llow, I.J., S hlens, J., Szegedy , C.: Explaining and harnessing adversarial ex- amples (2014). arXiv preprint arXiv:1412. 6572 (2014) 5. Huang, S., Papernot, N., Goo dfello w, I., Duan, Y., Abb eel, P .: A dv ersarial attacks on neural netw ork p olici es. arXiv preprint arXiv :1702.02284 (2017) 6. Hussein, A., Gab er, M.M., Ely an, E., Ja yne, C. : Imitation learning: A survey of learning metho ds. A CM Computing S urv eys (CSUR) 50 (2), 21 (2017) 7. Lin, Y.C., H ong, Z.W., Liao, Y .H., Shih, M.L., Liu, M.Y., Sun, M.: T actics of adver- sarial attac k on deep reinforcement lea rning agents. arX iv preprint arXiv:17 03.06748 (2017) 8. T ram ` er, F., K urakin, A., P ap ernot, N., Go odfello w, I., Boneh, D., McDaniel, P .: En- sem ble adversarial training: A ttacks and defenses. arXiv preprint arXiv:1705.072 04 (2017)
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment