음악 복제 탐지를 위한 MiRA 도구와 유사도 지표 평가
본 논문은 AI 생성 음악에서 훈련 데이터 복제 여부를 객관적으로 판단하기 위해, 오디오 기반 음악 유사도 지표 다섯 가지를 활용한 모델‑독립 평가 도구 MiRA를 제안한다. 합성 데이터를 이용한 강제 복제 실험을 통해 각 지표의 복제 감지 민감도를 검증했으며, CoverID, KL divergence, CLAP, DEfNet이 10% 이상 복제 비율을 10% 이상 정확도로 탐지함을 보였다.
저자: Roser Batlle-Roca, Wei-Hsiang Liao, Xavier Serra
본 논문은 인공지능(AI) 기반 음악 생성 모델이 훈련 데이터에서 직접적인 오디오 조각을 복제하거나 표절하는 현상을 객관적으로 탐지하고 정량화하기 위한 평가 프레임워크와 도구를 제시한다. 연구 동기는 최근 생성 AI가 음악 산업에 미치는 윤리·법적·경제적 파급 효과가 커짐에 따라, 특히 저작권이 보호되는 음악 콘텐츠가 무단 복제될 위험성을 사전에 식별하고 방지할 필요성이 대두된 데 있다. 기존 연구에서는 주로 심볼릭(악보) 수준에서의 원본성 측정이나, 이미지·텍스트 분야에서의 메모리 현상 탐지를 다루었지만, 원시 오디오 형태의 음악에 대한 복제 감지 도구는 부족했다.
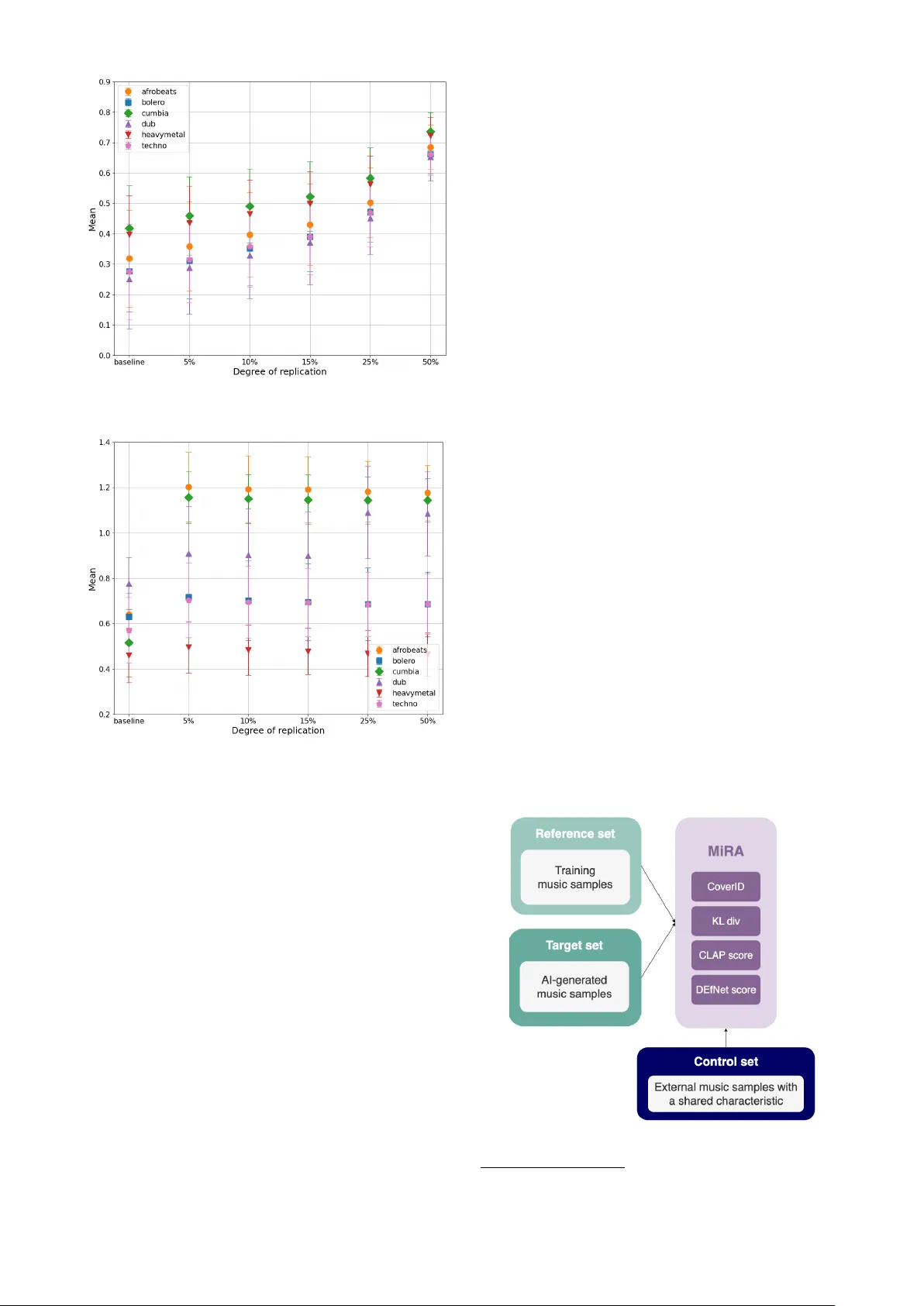
이를 해결하고자 저자들은 ‘Music Replication Assessment (MiRA)’라는 모델‑독립 평가 툴을 설계했다. MiRA는 다섯 가지 오디오 기반 음악 유사도 지표를 통합한다. 첫 번째는 Cover Song Identification (CoverID)으로, 피치‑콘텐츠와 로컬 정렬을 이용해 두 곡이 동일한 작곡을 공유하는지를 판단한다. 두 번째는 Kullback‑Leibler (KL) divergence로, PaSST 오디오 분류기가 출력한 확률 분포 간 비대칭 차이를 측정한다. 세 번째는 Contrastive Language‑Audio Pretraining (CLAP) 임베딩을 활용한 코사인 거리이며, 네 번째는 Discogs‑EffNet (DEfNet) 임베딩을 기반으로 한 거리이다. 마지막으로 Fréchet Audio Distance (FAD)를 CLAP 임베딩으로 대체해 구현했지만, 실험 결과 복제 탐지에 부적합함을 확인했다.
실험 설계는 강제 복제(Forced‑Replication) 방식으로 진행되었다. Spotify API에서 30초 길이의 프리뷰 트랙 18,000개를 수집하고, 장르 라벨을 기반으로 헤비 메탈, Afrobeat, Techno, Dub, Cumbia, Bolero 등 6개 장르를 선정했다. 각 장르는 레퍼런스 세트와 믹스 세트(동일 장르 내 다른 곡) 각각 400곡씩 배치하였다. 복제 비율을 5 %, 10 %, 15 %, 25 %, 50 %로 설정하고, 믹스 세트의 임의 구간에 레퍼런스 곡의 해당 구간을 삽입해 합성 복제 샘플을 생성했다. 이렇게 만들어진 타깃 세트는 장르당 4,000개(복제 비율당 10개 × 400곡)이며, 전체 120,000개의 합성 샘플(≈167시간)과 레퍼런스‑레퍼런스 160,000쌍을 대상으로 각 지표를 계산하였다.
분석 결과, CoverID, CLAP, DEfNet은 복제 비율이 증가함에 따라 평균 거리(µ)가 일관되게 상승하고 표준편차(σ)가 감소하는 경향을 보였다. 이는 높은 복제 비율일수록 유사도 판단이 명확해짐을 의미한다. KL divergence는 복제 여부를 구분하는 데는 유의미했지만, 복제 정도를 세밀히 구분하는 데는 한계가 있었으며, 특히 Dub 장르에서는 베이스라인보다 복제 샘플의 µ가 낮아 역전 현상이 나타났다. FAD는 CLAP 임베딩을 사용했음에도 불구하고, 복제 샘플에서 오히려 거리가 커지는 역효과를 보여 현재 음악 복제 탐지에 적합하지 않다는 결론을 내렸다.
통계적 검증을 위해 비정규성 및 이분산을 고려한 Kruskal‑Wallis 검정을 수행했으며, 모든 지표가 p < 0.05 수준에서 베이스라인과 복제 그룹 간 차이를 보였다. 특히 CoverID는 5 % 복제에서도 Afrobeat, Cumbia, Techno에서 유의미한 차이를 나타냈으며, 다른 장르에서는 10 % 이상에서 의미가 뚜렷했다. 이는 복제 비율이 낮아도 특정 장르와 지표 조합에서는 감지가 가능함을 시사한다.
MiRA 도구는 Python 패키지 형태로 공개되어, Essentia, PaSST, CLAP 등 오픈소스 라이브러리를 활용한다. 사용자는 레퍼런스와 타깃 오디오 폴더를 지정하면, 자동으로 네 가지 주요 지표(CoverID, KL, CLAP, DEfNet)를 계산하고 전역 평균 거리와 개별 쌍 거리 행렬을 출력한다. 이를 통해 연구자와 개발자는 모델 출력물의 복제 위험을 정량적으로 평가하고, 필요 시 데이터 정제, 모델 재학습, 혹은 생성 파라미터 조정을 수행할 근거를 얻을 수 있다.
논문의 한계점으로는 (1) 합성 복제 실험이 실제 diffusion 기반 음악 생성 모델의 복제 패턴을 완전히 대변하지 못한다는 점, (2) 장르 선택이 제한적이며 더 다양한 문화적·음악적 특성을 포함하지 못했다는 점, (3) CLAP·DEfNet 임베딩이 사전 학습 데이터에 따라 편향될 가능성이 있다는 점을 들 수 있다. 향후 연구에서는 실제 MusicLM, MusicLDM 등 최신 diffusion 모델의 출력에 MiRA를 적용하고, 청취자 설문을 결합해 주관적 인식과 객관적 거리 간 상관관계를 탐색할 필요가 있다. 또한, 복제 탐지 정확도를 높이기 위해 멜 스펙트로그램 기반의 시계열 유사도 지표나, 악기별 분리 후 비교하는 다중 레이어 접근법을 도입할 수 있다.
결론적으로, MiRA는 오디오 기반 유사도 지표를 체계적으로 활용해 음악 복제 감지를 가능하게 하는 최초의 공개 도구이며, 특히 CoverID와 DEfNet이 높은 민감도와 안정성을 보여 향후 AI 음악 저작권 보호와 윤리적 AI 개발에 중요한 역할을 할 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기