Towards Assessing Data Replication in Music Generation with Music Similarity Metrics on Raw Audio
Recent advancements in music generation are raising multiple concerns about the implications of AI in creative music processes, current business models and impacts related to intellectual property management. A relevant discussion and related technic…
Authors: Roser Batlle-Roca, Wei-Hsiang Liao, Xavier Serra
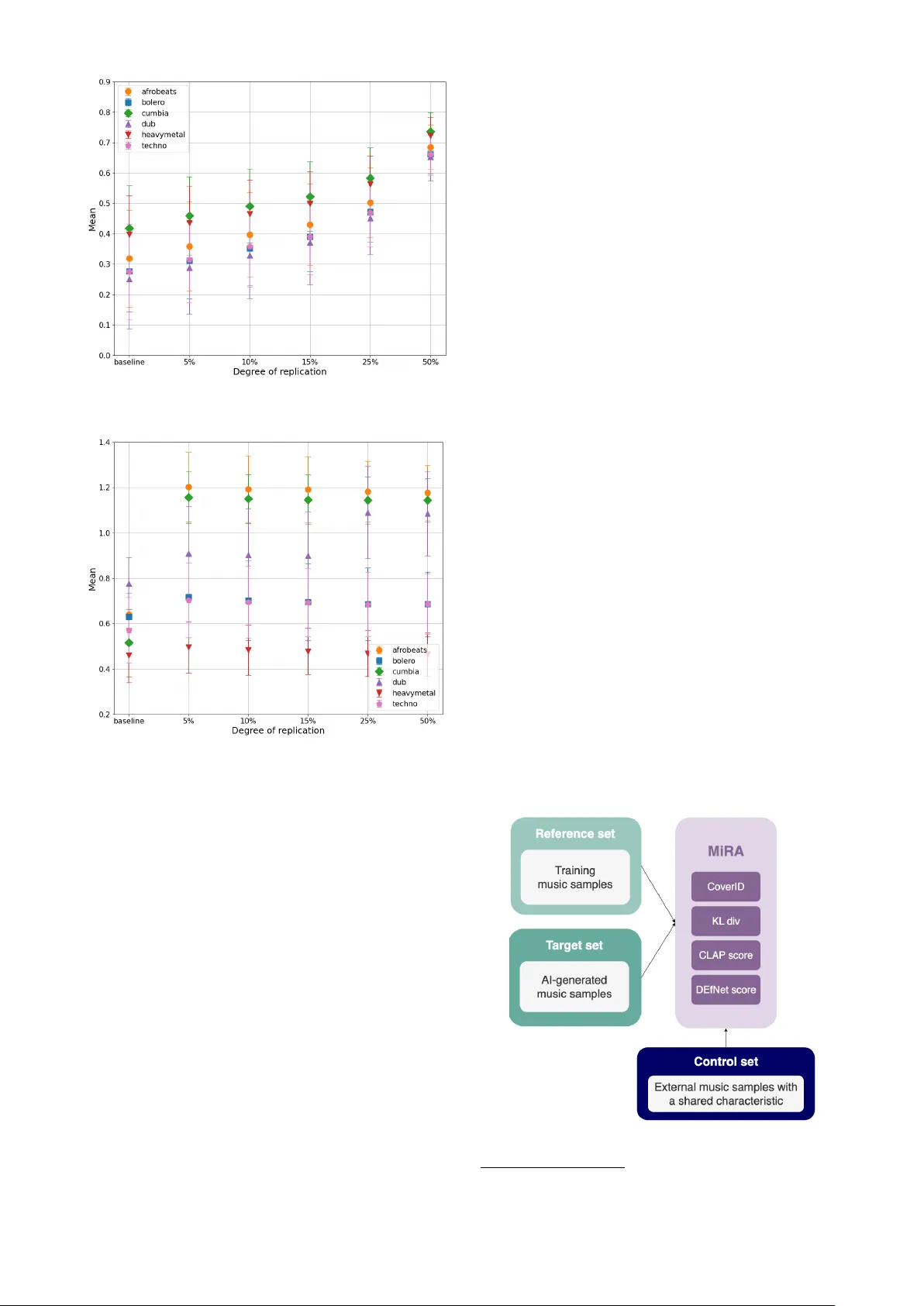
T O W ARDS ASSESSING D A T A REPLICA TION IN MUSIC GENERA TION WITH MUSIC SIMILARITY METRICS ON RA W A UDIO Roser Batlle-Roca 1 W ei-Hsiang Liao 2 Xa vier Serra 1 Y uki Mitsufuji 3 Emilia Gómez 1 , 4 1 Music T echnology Group, Uni v ersitat Pompeu F abra, Spain 2 Sony AI, Japan 3 Sony AI, USA 4 Joint Research Centre, European Commission, Spain roser.batlle@upf.edu ABSTRA CT Recent adv ancements in music generation are raising mul- tiple concerns about the implications of AI in creati ve mu- sic processes, current business models and impacts related to intellectual property management. A relev ant discus- sion and related technical challenge is the potential repli- cation and plagiarism of the training set in AI-generated music, which could lead to misuse of data and intellectual property rights violations. T o tackle this issue, we present the Music Replication Assessment (MiRA) tool: a model- independent open ev aluation method based on di verse au- dio music similarity metrics to assess data replication. W e ev aluate the ability of fiv e metrics to identify exact repli- cation by conducting a controlled replication experiment in different music genres using synthetic samples. Our results show that the proposed methodology can estimate exact data replication with a proportion higher than 10% . By in- troducing the MiRA tool, we intend to encourage the open ev aluation of music-generati ve models by researchers, de- velopers, and users concerning data replication, highlight- ing the importance of the ethical, social, legal, and eco- nomic consequences. Code and examples are a v ailable for reproducibility purposes. 1 1. INTR ODUCTION Significant adv ancements in generati v e algorithms for dig- ital art creation are challenging the role of artificial intel- ligence (AI) in artistic practices. Regarding generati ve AI in the music domain, there is an increasing discussion re- lated to the use of computational tools in music creati v e processes [1], the effects on artists’ work, existing listen- ing experiences and business models, and the impacts on intellectual property (IP) management [2, 3]. A key point is the potential replication and plagiarism of the training set in AI-generated music [3, 4], which can lead to data misuse and IP violations. 1 https://github.com/roserbatlleroca/mira © R. Batlle-Roca, W . Liao, X. Serra, Y . Mitsufuji and E. Gómez. Licensed under a Creative Commons Attribution 4.0 Interna- tional License (CC BY 4.0). Attribution: R. Batlle-Roca, W . Liao, X. Serra, Y . Mitsufuji and E. Gómez, “T owards Assessing Data Replication in Music Generation with Music Similarity Metrics on Raw Audio”, in Pr oc. of the 25th Int. Society for Music Information Retrieval Conf., San Francisco, United States, 2024. The inherent opaque nature of music generation mod- els complicates tracing replications or references to train- ing set samples in AI-generated music, limiting the inter- pretation of whether generated samples contain replicated fragments. In addition, diffusion models, one of the most popular generativ e AI architectures, tend to memorise and replicate training data [5–7]. Understanding the behaviour of these models has become critical to address legal is- sues [8], especially when dealing with data protected by IP rights. This is significant in the music domain as the vast majority of music is protected by authorship and copyright. Despite multiple claims emphasising the importance of assessing music-generati v e algorithms, there is a lack of ev aluation tools directly focused on detecting data replica- tion based on raw audio. Considering this research gap, the present in v estigation is moti v ated by two main questions: • Are audio-based music similarity metrics suitable to assess data replication in AI-generated music? • Can we propose an open model-agnostic e v aluation method and tool found on div erse audio-based music similarity metrics? Thus, this work proposes assessing the effecti v eness of fiv e music similarity metrics 2 (four state-of-the-art widely-used and a novel one) in estimating exact data repli- cation in music. W e revie w the implications of poten- tial data replication in AI-generated music (Section 2) and present our e xperimental setup, including the selected mu- sic similarity metrics and specific methodology to control and estimate exact data replication (Section 3). W e anal- yse metrics’ behaviour in different music materials (Sec- tion 4.1), aiming to assess later their data replication detec- tion sensiti vity (Section 4.2). The proposed methodology is implemented in tool MiRA (Music Replication Assess- ment), which computes music similarity between reference and target samples to obtain global and per-pair distances (Section 5). Finally , we discuss our research’ s insights, limitations and future perspectiv es (Section 6). By introducing MiRA tool, we advance to wards the as- sessment of data replication in AI-generated music using similarity metrics, contributing to open e v aluation meth- ods for accessibility for researchers, de velopers and users. W e stri ve to raise a wareness, detect and prev ent misappro- priation of training sets, and hope to motiv ate research on these issues. 2 Hereafter , music similarity metrics refer to audio-based metrics. 2. B A CKGROUND AND RELA TED WORK 2.1 Implications of potential data replication in AI-generated music Music-generativ e AI is adv ancing rapidly with no vel high- quality models driv en by a strong push from the indus- try , which is encouraging a suitable en vironment for real- world deployment. Y et, music generation algorithms bring significant concerns regarding their ethical, social, legal and economic implications. A key challenge is the po- tential data replication in AI-generated music—inquiring whether a generative model extracts and copies fragments from the training data and whether AI-generated music can be considered novel and original [3, 4]. This issue is fur- ther complicated by the implications deriv ed concerning data misuse and IP violations such as copyright infringe- ment. Moreov er , diffusion models, one of the most pop- ular architectures for generative AI, present high risks of data replication as they ha ve shown a tendency to mem- orise their training data [5–7]. In the image generation domain, Somepalli et al. [9] demonstrate instances where generated images with diffusion models contain object- lev el copies of their training data. Based on image retrie v al framew orks, they compare generated images with training samples and detect when content has been replicated. Sim- ilarly , Carlini et al. [5] demonstrate that diffusion models memorize and reproduce images from their training data. Memorising training data and potential IP violations is highly under-discussed in music generati ve models lit- erature, despite being one of generativ e AI’ s main ne ga- tiv e ethical implications in the music domain [10]. How- ev er , the recently proposed music generati ve model Musi- cLM [11] has been refrained from releasing due to the eth- ical risks and potential work replication. In addition, Mu- sicLDM [12] ackno wledges potential issues linked to data replication and plagiarism and, to address them, proposes two beat-synchronous mix-up strategies for data augmen- tation. The exemplified initiativ es underscore the relev ance of considering and addressing the ethical implications of these algorithms. 2.2 Evaluation methodologies in music generation Xiong et al. [13] present a surve y on music generation ev aluation methodologies divided into objecti ve, subjec- tiv e and combined approaches. They highlight a cur - rent claim in finding a standardised proper method that aligns with all stakeholders, from dev elopers to musicians and music listeners. Howe v er , ev en if multiple e v aluation methodologies exist for music generation models, the lit- erature highlights a lack of e v aluation methodologies fo- cused on assessing data replication and the originality of AI-generated music [4, 14]. In the symbolic domain, Y in et al. [4] introduce the originality scor e to measure the e xtent to which an algorithm might be copying from the train- ing set. Nonetheless, there is a growing interest in models outputting directly audio music instead of symbolic repre- sentations. Thus, a research gap exists in detecting data replication in AI-generated music based on raw audio. A recent work by Barnett et al. [15] proposes a frame- work based on two music audio embeddings to assess the similarity between the training data and AI-generated sam- ples for understanding training data attribution. Their ap- proach, based on V ampNet [16], computes cosine distance on embeddings obtained from CLMR (Contrastiv e Learn- ing of Musical Representations) [17] and CLAP (Con- trastiv e Language-Audio Pretraining) [18]. Our perspective is that combining metrics based on au- dio embeddings, acoustic qualities, and features capturing music characteristics, such as chord progression or tonal similarity , provides a comprehensiv e assessment of poten- tial data replication in AI-generated music. In this study , we aim to validate the effecti veness of fi ve music similarity metrics and b uild an open tool to assess e xact data replica- tion in AI-generated music using these metrics. 3. FORCED-REPLICA TION EXPERIMENT 3.1 A udio Music Similarity Metrics For this study , we consider fi ve music similarly metrics: four state-of-the-art approaches and a nov el one, cov ering a div ersity of characteristics. W e here describe the metrics (summarised in T able 1) and methods used to implement them. 3 Cover Song Identification (CoverID) [19–21]: Cov er song identification is a task aiming to detect whether two music recordings are based on the same composition, ac- counting for v ariations in tempo, structure, and instrumen- tation while keeping a similar melodic or harmonic line. Cov erID relies on pitch-content features and local align- ment. T o obtain CoverID distance, we use the implemen- tation av ailable in Essentia. 4 A low CoverID value sug- gests substantial composition similarity between the two analysed music samples. Kullback-Leibler (KL) divergence : This metric pro- vides a non-symmetric statistical measurement between reference and tar get probability distributions relative to their entropy . KL diver gence has been employed in the literature to estimate similarity in music (e.g. [22, 23]), and more recently , to assess automatic music generation prompt adherence (e.g. [24]). W e aim to explore its capa- bilities to estimate data replication in music samples. T o obtain probability distributions, we use the PaSST audio classifier proposed in K outini et al. [25], trained on Au- dioset. This methodology aligns with common practice in the literature, such as in AudioGen [26] and MusicGen [27] to obtain the probabilities of the labels in their audio and music samples. T o av oid the non-symmetry of KL div er - gence, we compute reference to tar get and tar get to ref- erence KL div er gence and, subsequently , average both re- sults to obtain symmetric KL diver gence. Low KL div er- gence indicates a closer similarity between distributions. 3 T wo of the metrics rely on Essentia implementation. Essentia is an open-source library and tools for audio and music analysis, description and synthesis, developed in the Music T echnology Group at Univ ersitat Pompeu Fabra: https://essentia.upf.edu . 4 https://essentia.upf.edu/reference/std_ CoverSongSimilarity.html T able 1 : Summary of the considered music similarity met- rics, indicating whether v alues correspond to higher or lower similarity ( ↓ / ↑ ). Metric Description CoverID ( ↓ ) Musical composition similarity based on music-specific characteristics. KL diver gence ( ↓ ) Differences in distrib utions from an audio classifier . CLAP ( ↑ ) Distance between embeddings from a music pre-trained model. DEfNet ( ↑ ) Nov el metric based on distance between embeddings from a contrastiv e learning model for music similarity . F AD ( ↓ ) Distance between embeddings based on CLAP music model. Contrastive Language-A udio Pretraining (CLAP) score [18]: CLAP embeddings 5 allow to obtain latent rep- resentations of audio or text by conditioning information. For instance, MusicLDM [12] uses this metric to assess the novelty in text-to-music generations. T o compute the CLAP score between two music samples, we extract the audio embeddings from the pre-trained music model 6 for each one and compute the cosine distance between them. A high CLAP score indicates a high similarity between the two music samples. Discogs-EffNet (DEfNet) score : In addition to state- of-the-art distances between audio embeddings, we incor- porate a novel approach based on Essentia models [28]. Essentia’ s Discogs-Ef fNet model 7 provides music au- dio embeddings trained on Discogs metadata with con- trastiv e learning purposes for music similarity . W e con- sider DEfNet score to observe the effecti veness of embed- dings of a model trained for a music-related task on es- timating data replication. Embeddings are extracted based on track self-supervised annotations 8 and compute the co- sine distance between reference and target samples. A high DEfNet score rev eals high track similarity . Fréchet A udio Distance (F AD) [29, 30]: F AD is an adaptation of Fréchet Inception Distance (FID) for music, comparing embedding distributions of a reference and a target set, based on the V iGGish model [31]. Nonetheless, a recent study by Gui et al. [30] questions whether VG- Gish is the optimal model for F AD computation for music generation ev aluation. They propose a tool kit 9 with mul- tiple models to obtain more accurate embeddings to assess AI-generated music when calculating F AD. Consequently , we implement the adapted version of F AD using the CLAP audio music pre-trained model. A low F AD score indicates a high resemblance between the compared music samples. 5 https://github.com/LAION- AI/CLAP 6 Checkpoints: music_audioset_epoch_15_esc_90.14.pt . 7 https://essentia.upf.edu/models.html# discogs- effnet 8 Embeddings extracted with weights discogs_track_ embeddings-effnet-bs64-1.pb . 9 https://github.com/microsoft/fadtk 3.2 Experimental Appr oach T o v alidate the effecti veness of the selected music similar - ity metrics in detecting exact data replication, we carried out a controlled forced-replication experiment with syn- thetic data, i.e. replicating music excerpts into another song under controlled conditions. Synthetic data guaran- teed that the analysed music samples contained copied in- stances, limiting our scope to exact data replication. For this experiment, we use an in-house dataset of 30- second audio previe ws from the Spotify API 10 , composed of over 18,000 samples and 24 music genre classes. W e focus on six music genre classes defined by Spotify API internal class labels: heavy metal , afr obeats , techno , dub , cumbia and boler o . These genres were chosen for their di- verse musical compositions and elements, allo wing us to examine the metrics across multiple scenarios. This se- lection was supported using ChatGPT , which affirmed that these genres hav e distinct musical characteristics. W e divide data into three groups: (1) refer ence set : act- ing as training data, (2) target set : composed of synthetic data, representing AI-generated music, and (3) mixture set : containing different songs from the reference set but from the same music genre to build synthetic data. Syn- thetic data with replication contains a controlled percent- age of copy from a song in our reference set: 5% (1.5s), 10% (3s), 15% (4.5s), 25% (7.5s) and 50% (15s). A syn- thetic sample is created by introducing the copied propor- tion at a random point of a music sample in the mixture set. W e create 10 samples with a proportion of replication per song in the reference set. Figure 1 illustrates the pro- cedure to build synthetic data with 5% of replication. For each music genre, the reference and mixture sets are com- posed of 400 songs each. Thus, the target set comprises 4,000 (400 x 10) songs per percentage of replication for each genre. Music samples are 30 seconds long as cur- rently it is the common length in full song composition music generativ e models. W e assess each metric for all the songs within the ref- erence set against themselves to establish a baseline (400 x 400 = 160,000 per-pair ev aluations). Then, we compute them for each reference song and its copied instances to only consider cases with e xact data replication (4,000 per- pair ev aluations). Our experiment considers 120,000 sam- ples of synthetic data (approximately 167h of music with a proportion of data replication). Figure 1 : Synthetic data procedure with 5% of replication. 10 https://developer.spotify.com/documentation/ web- api 4. RESUL TS 4.1 Analysing metric behaviour Figures 2, 3, 4, 5 and 6 depict the av erage µ and standard deviations σ of the dif ferent metrics per degree of repli- cation and music genre. W e observe a steady and similar behaviour by three metrics (CoverID, CLAP and DEfNet) through all studied music genres, showing higher simi- larity values for cases with higher replication levels (i.e., 50% ). Standard deviation decreases with increasing repli- cation level, which suggests less disparity within the anal- ysed pairs. These three metrics show the sensitivity 11 to estimate data replication. Instead, KL di ver gence presents a different behaviour with v ery similar v alues of µ and σ for all degrees of repli- cation. Some sensitivity is observed in all music genres, except for dub , where the baseline mean µ b is smaller than in replication cases µ r , despite the standard deviation being higher ( µ b =0.757, σ b =0.511; µ r =0.862, σ r =0.462). Thus, KL div ergence demonstrates the capability of detect- ing replication but is ineffecti v e in distinguishing between degrees of replication. Contrasting with the other metrics, F AD based on CLAP music embeddings completely differs from them. On the one side, its behaviour is inconsistent as it exhibits fluctuating trends for the dif ferent examined cases. On the other side, it fails to detect data replication. A higher sim- ilarity v alue (lo w F AD) is always obtained for the base- line. Instead, for the different degrees of replication, higher F AD is achie ved. Consequently , F AD based on CLAP mu- sic embeddings does not appear to be a suitable metric to assess exact data replication in music samples. By analysing the metrics’ behaviour , we could directly conclude that CoverID, KL di vergence, CLAP and DEfNet are suitable for our posed research aim. Howe v er , further exploration is required before determining their ability to detect replication and degree of replication. W e delve into this analysis in the next subsection. 4.2 Assessing data replication detection sensiti vity In this section, we complement the previous analysis with an assessment of statistical differences. Because our data is not normally distributed and variance is heterogeneous, the Kruskal-W allis test [32] is the most adequate statistical analysis to examine our results, as is non-parametric, does not rely on normality and handles unequal sample sizes. W e perform the Kruskal-W allis test on CoverID, KL di- ver gence, CLAP and DEfNet. Significant statistical dif fer - ences ( p < 0 . 05 ) are observed across all music genres and degrees of replication, consistent with our earlier findings. Nonetheless, the insight of this analysis relies on the pairwise comparisons between the baseline and dif ferent degrees of replication. CoverID pairwise comparison re- veals a statistically significant dif ference between the base- line and the 5% replication degree for afr obeat , cumbia and techno . For the three other music genres, this happens 11 Sensitivity is understood as the capability to differentiate between degrees of replication. Figure 2 : CoverID ( ↓ ) Figure 3 : KL div ergence ( ↓ ) Figure 4 : CLAP ( ↑ ) Figure 5 : DEfNet ( ↑ ) Figure 6 : F AD ( ↓ ) for a 10% replication degree. Then, statistical significance also appears in pairwise comparisons of different degrees of replication. W e can derive that Cov erID is sensible for 10% of replication, and in some cases at 5% . When consid- ering KL div er gence, pairwise comparison depicts a statis- tically significant difference between the baseline and the 5% replication degree. Between degrees of replication, no statistical significance is revealed for an y pairwise com- parison, except for heavy metal between 5% and the other replication degrees. Regarding the CLAP and DEfNet, a significant dif ference already appears when comparing the baseline against the samples with 5% replication, indicat- ing that these metrics are sensiti ve to 1.5 seconds of repli- cation. In all cases, a notable difference emerges among the levels of replication, enhancing the sensitivity of these metrics’ detection capabilities. They demonstrate sensiti v- ity to varying replication de grees. W ithal, this statistical analysis sustains the v alidity of these four metrics to assess exact data replication in the training set and determines their degree of sensiti vity . 5. MUSIC REPLICA TION ASSESSMENT TOOL Deriv ed from the presented e xperiment, we implement the proposed methodology into an ev aluation tool. W e intro- duce the Music Replication Assessment (MiRA) tool: an open ev aluation method based on four di v erse raw audio music similarity metrics. MiRA computes music similarity between reference and target samples to obtain global and per -pair distances, based on CoverID, KL di ver gence, CLAP and DEfNet. It can estimate data replication with a proportion higher than 10% (3 seconds), b ut in most of the examined scenarios, it is sensible to 5% of replication. Per-pair distances are highly beneficial for detecting close pairs, outliers and sus- picious cases with potential data replication. Considering that replication detection requirements may vary depend- ing on the ev aluation, users are left to set their replication threshold. In addition, MiRA is model-independent as no information about the model architecture or its characteris- tics is necessary . The ev aluation is conducted directly with the training ( refer ence ) and generated samples ( target ) of the analysed generativ e model. Howe ver , designating a baseline value is encouraged to accurately interpret the music similarity between the refer - ence and target samples. W e propose a third comparison group of samples ( control ) based on songs related to the reference songs but unseen by the model (e.g. shared mu- sic genre). Again, this is a decision for the users condi- tioned to their ev aluation scope. Note that using a control group allows us to understand and interpret the results ob- tained by acting as the baseline similarity le vel of indepen- dent songs with a shared characteristic. The complete structure of the implemented system is depicted in Figure 7. W e release MiRA as an open-source tool, built into a PyPI package 12 . T ogether with the code, we provide examples and best practice recommendations for using this methodology . W ith the release of MiRA, we hope to enhance transparency in music generation models and data replication assessment. Figure 7 : MiRA ’ s structure scheme. 12 https://pypi.org/project/mira- sim/ 6. DISCUSSION AND CONCLUSIONS This work focused on v alidating the use of music similar- ity metrics for assessing data replication in AI-generated music. W e hypothesise that similarity metrics are effec- tiv e in estimating data replication. Therefore, we framed the scope of our study to e xact data replication in music samples, while conducting a controlled forced-replication experiment with synthetic data. W e examined fiv e diverse audio-based metrics: four standard metrics (Cov erID, KL di v er gence, CLAP and F AD) and a novel one (DEfNet). Our results indicate that four of the five studied metrics can detect data replication to a certain e xtent. Instead, F AD based on CLAP music embeddings presented an opposite behaviour compared to the other metrics. Higher similarity is obtained for the baseline group and F AD shows unstable trends throughout the div erse music genres. Thus, we do not find it suitable for our case study . Howe v er , it must be ackno wledged that the recent publication by Gui et al. [30] offered multiple classifiers to compute F AD. There is the possibility that we did not consider the appropriate classifier for our task. Thus, we should consider e xploring other classifiers before determining the v alidity of F AD in detecting replication in music. Regarding the other four metrics, our results show in- teresting insights. First, we find Cov erID to be sensible to different replication degrees, establishing a robust thresh- old level at 10% of replication. Furthermore, in some of the studied cases, replication sensitivity is lowered to 5% of replication. This is a substantial finding to validate the suitability of metrics oriented to specific music character- istics, such as tempo, structure and composition. Next, we observe that KL di vergence can be sensitive to replication as pairwise comparison between baseline and degrees of replication is statistically significant. Nev erthe- less, the other pairwise results rev eal that KL diver gence is ineffecti ve for differentiating between replication degrees. W e consider this an unexpected turnout in our analysis. Considering CLAP and DEfNet scores, both embedding-based metrics, our experiment validates their suitability to detect data replication. Not only do they show robustness by increasing their similarity value parallel to the replication degrees (i.e. higher similarity for higher level of replication), but they also show high sensitivity for different degrees of replication. All results suggest their sensitivity might be higher than we en vi- sioned and might be able to detect replication in smaller samples (i.e. < 1.5 seconds). As a result of these findings, we achiev e our second goal within the scope of this research: to build an open model- agnostic tool based on music similarity metrics on ra w au- dio. In this article, we have introduced the MiRA tool, lev eraging the four v alidated similarity metrics, which can be used to ev aluate any music-generativ e model with au- dio output. MiRA does not require any information about the model architecture or its characteristics. Instead, sim- ilarity e v aluation relies on comparing reference and target samples. By introducing the MiRA tool, we are contributing to the research gap of lack of e v aluation methodologies di- rectly assessing potential data replication in AI-generated music. Our study v alidates the use of similarity metrics to estimate training data replication. W e intend to encour - age the open e v aluation of music generation models by re- searchers, developers and users concerning data replica- tion. In addition, our research stri ves for the importance of ethical, social, legal and economic consequences of gen- erativ e AI in the music domain, together with the need to address their risks and issues. 6.1 Limitations and Future W ork Despite our contribution to advance towards data replica- tion assessment with music similarity metrics, there are multiple opportunities to complement our in v estigation. First, we limited the scope of our e xperimental ap- proach to assessing the use of different music similarity metrics for e xact data replication, consequently reducing the definition of plagiarism to exact replication of frag- ments in the training set. W e follo wed such an approach to validate our hypothesis and ensure an attainable method to address this issue. While this reduced scope could poten- tially be solved using audio fingerprinting strategies [33], we believe that by employing a di verse range of metrics we can provide a more comprehensiv e assessment of data replication. Framing our aim to exact data replication also intro- duced a limitation in considering typical perturbations that music samples e xperience when training the model or dur- ing the model procedure to generate a music sample. Thus, it would be a key point for future work to validate the ro- bustness of these metrics towards typical data augmenta- tion techniques, such as pitch shifting and re v erberation. Proving them to be robust would also enhance the capa- bilities of MiRA for detecting potential replication in AI- generated music. At the same time, we intend to expand the abilities of MiRA for data replication by incorporating complementary metrics, if necessary . In addition, our e xperimental process w as limited to the high computational costs of some of the metrics. In partic- ular , we faced significantly large amounts of time to com- pute F AD and KL di ver gence. This is a rele v ant concern as we want MiRA to be an open tool that can be used by any researcher or user . Thus, considering the computational capacity required to compute the integrated metrics within is a relev ant issue in our research. Another limitation is the type of data that we use. W e base our experiment on synthetic data despite our goal be- ing oriented to AI-generated music. W e must use synthetic data with a controlled percentage of replication to guaran- tee and assess the capabilities of detection and sensiti vity of music similarity metrics. Howe ver , we would like to test the validity of the introduced tool when used in a genera- tion context. T o do so, we require not only a generative model but its details on training data and generation sam- ples. W e plan to e xpand our research in with AI-generated content in upcoming studies. 7. A CKNO WLEDGMENTS The authors would like to thank Gaëtan Hadjeres and W illiam Thong from Sony AI, as well as Dmitry Bog- danov and Pablo Alonso-Jiménez from the Music T ech- nology Group at Uni versitat Pompeu Fabra, for their in- sightful discussions and valuable feedback throughout the dev elopment of this research. 8. ETHICS ST A TEMENT The late rapid popularity gro wth of generative AI in the music domain brings significant ethical implications. The main challenges are linked to the role of AI within mu- sic creative processes, such as composition, potential mis- appropriation of data in AI-generated music, inquiries on the nov elty of generations, deriv ed authorship attribution, effects on intellectual property rights and sustainability of current business models. In addition, there are notable con- cerns about the cultural bias in these systems and their en- vironmental impact. Our research focused on the issue of assessing potential data replication in AI-generated music. W e observed a lack of ev aluation methodologies to examine replication in raw audio. W e contributed to this issue by proposing a method- ology based on audio-based music similarity metrics. W e demonstrated its effecti v eness and provided an open tool to ev aluate AI-generated music. Our introduced approach is contributing to the transparency of music generation al- gorithms. Despite the positiv e contribution of our in v estigation, we must be critical of some methodological aspects of our work. Our principal ethical concern falls under the type of data used to conduct our forced-replication experiment. In particular, we employ an internal dataset created with Spotify previe ws (30-second samples of music). Even if these practices are common in the ISMIR community , we see the need for guidelines for the legal assessment of MIR data included in datasets, incorporating country dependen- cies, origin and intended use, personal data in volved (from artists and listeners) and potential future consequences 13 . 9. REFERENCES [1] F . Carnovalini and A. Rodà, “Computational creati v- ity and music generation systems: An introduction to the state of the art, ” F r ontiers in Artificial Intelligence , vol. 3, 2020. [2] E. Gómez, M. Blaauw , J. Bonada, P . Chandna, and H. Cuesta, “Deep learning for singing processing: Achiev ements, challenges and impact on singers and listeners, ” ArXiv , 2018. [Online]. A v ailable: https://arxiv .or g/abs/1807.03046v1 [3] B. L. T . Sturm, M. Iglesias, O. Ben-T al, M. Miron, and E. Gómez, “ Artificial intelligence and music: Open 13 W e refer to a recently documented example of research vs legal clash linked to algorithmic auditing in the music do- main https://www.rollingstone.com/pro/features/ spotify- teardown- book- streaming- music- 790174/ questions of copyright law and engineering praxis, ” Arts , vol. 8, p. 115, 2019. [4] Z. Y in, F . Reuben, S. Stepney , and T . Collins, “Mea- suring when a music generation algorithm copies too much: The originality report, cardinality score, and symbolic fingerprinting by geometric hashing, ” SN Computer Science , vol. 3, 2022. [5] N. Carlini, J. Hayes, M. Nasr , M. Jagielski, V . Sehwag, F . T ramer , B. Balle, D. Ippolito, and E. W allace, “Ex- tracting training data from diffusion models, ” in 32nd USENIX Security Symposium (USENIX Security 23) , 2023, pp. 5253–5270. [6] N. Carlini, D. Ippolito, M. Jagielski, K. Lee, F . Tramer , and C. Zhang, “Quantifying memorization across neu- ral language models, ” ArXiv , 2023. [7] D. Bralios, G. W ichern, F . G. Germain, Z. Pan, S. Khu- rana, C. Hori, and J. L. Roux, “Generation or repli- cation: Auscultating audio latent diffusion models, ” ArXiv , 2023. [8] H. W ang, “ Authorship of artificial intelligence- generated works and possible system improvement in china, ” Beijing Law Re view , vol. 14, pp. 901–912, 2023. [9] G. Somepalli, V . Singla, M. Goldblum, J. Geiping, and T . Goldstein, “Diffusion art or digital forgery? in ves- tigating data replication in diffusion models, ” ArXiV , 2022. [10] J. Barnett, “The ethical implications of generativ e au- dio models: A systematic literature revie w , ” AIES 2023 - Pr oceedings of the 2023 AAAI/A CM Conference on AI, Ethics, and Society , pp. 146–161, 2023. [11] A. Agostinelli, T . I. Denk, Z. Borsos, J. Engel, M. V erzetti, A. Caillon, Q. Huang, A. Jansen, A. Roberts, M. T agliasacchi, M. Sharifi, N. Ze ghidour , and C. Frank, “Musiclm: Generating music from text, ” ArXiv , 2023. [12] K. Chen, Y . W u, H. Liu, M. Nezhurina, T . Berg- Kirkpatrick, and S. Dubnov , “MusicLDM: Enhanc- ing novelty in text-to-music generation using beat- synchronous mixup strategies, ” ArXiv , 2023. [13] Z. Xiong, W . W ang, J. Y u, Y . Lin, and Z. W ang, “ A comprehensiv e surve y for ev aluation methodologies of AI-generated music, ” ArXiv , 2023. [14] R. Batlle-Roca, E. Gómez, W . Liao, X. Serra, and Y . Mitsufuji, “T ransparenc y in music-generati ve AI: A systematic literature revie w , ” Researc h Squar e pr eprint , 2023. [15] J. Barnett, H. F . Garcia, and B. Pardo, “Exploring mu- sical roots: Applying audio embeddings to empower influence attribution for a generative music model, ” arXiv , 2024. [16] H. F . Flores Garcia, P . Seetharaman, R. Kumar , and B. Pardo, “V ampnet: Music generation via masked acoustic token modeling, ” in Pr oceedings of the 24th International Society for Music Information Retrieval Confer ence, ISMIR 2023, Milan, Italy , 2023. [17] J. Spijk ervet and J. A. Burgoyne, “Contrastiv e learning of musical representations, ” Pr oceedings of the 22nd International Society for Music Information Retrieval Confer ence, ISMIR 2021, Online , 2021. [18] Y . W u, K. Chen, T . Zhang, Y . Hui, T . Berg-Kirkpatrick, and S. Dubnov , “Large-scale contrastiv e language- audio pretraining with feature fusion and ke yword-to- caption augmentation, ” ArXiv , 2023. [19] J. Serrà, X. Serra, and R. Andrzejak, “Cross recurrence quantification for cov er song identification, ” New Jour - nal of Physics , vol. 11, 2009. [20] J. Serrà, E. Gómez, P . Herrera, and X. Serra, “Chroma binary similarity and local alignment applied to cover song identification, ” IEEE T r ansactions on Audio, Speech, and Language Pr ocessing , vol. 16, no. 6, pp. 1138–1151, 2008. [21] J. Serrà, E. Gómez, and P . Herrera, “T ransposing chroma representations to a common key , ” IEEE CS Confer ence on The Use of Symbols to Repr esent Music and Multimedia Objects , 2008. [22] M. Hoffman, D. Blei, and P . Cook, “Content-based musical similarity computation using the hierarchical dirichlet process. ” in Pr oceedings of the 9th Interna- tional Society for Music Information Retrie val Confer - ence, ISMIR 2008, Philadelphia, USA , 2008. [23] D. Schnitzer , A. Flexer , G. W idmer , and M. Gasser , “Islands of gaussians: The self organizing map and gaussian music similarity features, ” in Pr oceedings of the 11th International Society for Music Information Retrieval Conference , ISMIR 2010, Utrec ht, Nether- lands , 2010. [24] Z. Evans, C. Carr , J. T aylor , S. H. Hawley , and J. Pons, “Fast timing-conditioned latent audio diffu- sion, ” ArXiv , 2024. [25] K. K outini, J. Schlüter, H. Eghbal-zadeh, and G. W id- mer , “Efficient training of audio transformers with patchout, ” in Interspeec h 2022, 23r d Annual Confer- ence of the International Speech Communication Asso- ciation, Incheon, K or ea . ISCA, 2022, pp. 2753–2757. [26] F . Kreuk, G. Synnaev e, A. Polyak, U. Singer , A. Dé- fossez, J. Copet, D. Parikh, Y . T aigman, and Y . Adi, “ Audiogen: T extually guided audio generation, ” 2023. [27] J. Copet, F . Kreuk, I. Gat, T . Remez, D. Kant, G. Syn- naev e, Y . Adi, and A. Défossez, “Simple and control- lable music generation, ” ArXiv , 2023. [28] P . Alonso-Jiménez, D. Bogdanov , J. Pons, and X. Serra, “T ensorflo w audio models in Essentia, ” in In- ternational Conference on Acoustics, Speech and Sig- nal Pr ocessing (ICASSP) , 2020. [29] K. Kilgour , M. Zuluaga, D. Roblek, and M. Sharifi, “Fréchet Audio Distance: A Reference-Free Metric for Evaluating Music Enhancement Algorithms, ” in Pr oc. Interspeech 2019 , 2019, pp. 2350–2354. [30] A. Gui, H. Gamper , S. Braun, and D. Emmanouilidou, “ Adapting frechet audio distance for generativ e music ev aluation, ” ArXiv , 2023. [31] S. Hershe y , S. Chaudhuri, D. P . W . Ellis, J. F . Gem- meke, A. Jansen, R. C. Moore, M. Plakal, D. Platt, R. A. Saurous, B. Seybold, M. Slaney , R. J. W eiss, and K. W ilson, “Cnn architectures for large-scale au- dio classification, ” ArXiv , 2017. [32] W . H. Kruskal and W . A. W allis, “Use of ranks in one- criterion v ariance analysis, ” Journal of the American Statistical Association , vol. 47, no. 260, pp. 583–621, 1952. [33] P . Cano and E. Batlle, “ A re vie w of audio fingerprint- ing, ” J ournal of VLSI Signal Pr ocessing , vol. 41, pp. 271–284, 11 2005.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment