통계적 유의성과 판별력을 동시에 만족하는 패턴 탐색 방법론
본 논문은 통계적 유의성 및 판별력 기준을 기존 트리클러스터링 알고리즘에 통합하는 방법을 제시한다. δ‑Trimax와 TriGen에 새로운 목적 함수 구성 요소인 통계적 유의성 컴포넌트(SSC)와 판별력 컴포넌트(DPC)를 추가해 품질 저하 없이 패턴의 의미와 예측력을 향상시킨다. 세 가지 실험 사례를 통해 제안 방법이 기존 방법 대비 유의성·판별력 모두에서 유의한 개선을 보임을 입증한다.
저자: Leonardo Alex, re, Rafael S. Costa
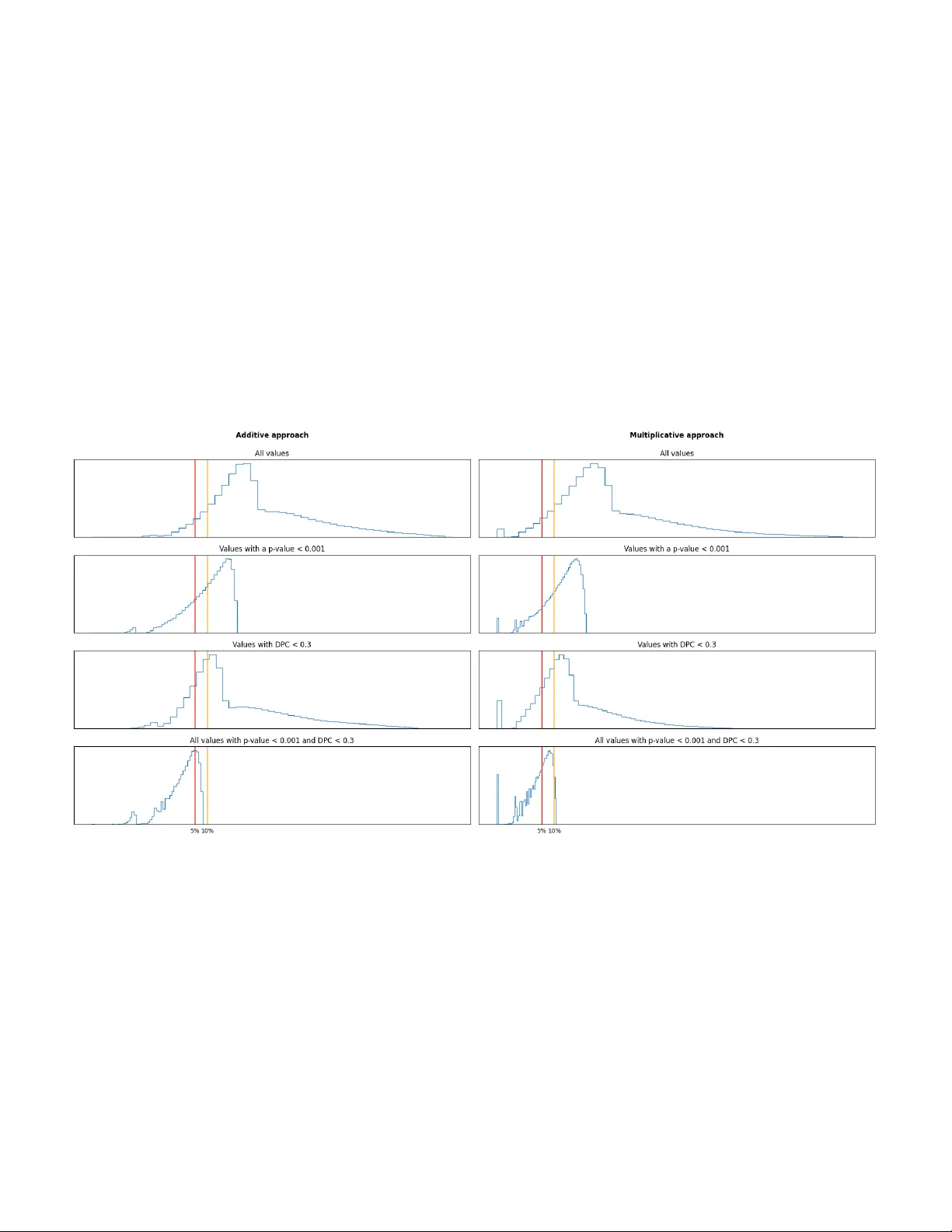
본 논문은 패턴 탐색에서 흔히 간과되는 ‘통계적 유의성’과 ‘판별력’이라는 두 가지 중요한 평가 기준을 기존의 품질 기준과 함께 고려하는 새로운 방법론을 제시한다. 저자들은 먼저 패턴 마이닝 분야에서 현재 사용되는 주요 기준을 정리한다. 전통적인 품질 기준은 주로 패턴의 동질성(예: MSR, LSL, MSL)과 중복 방지를 위한 이질성(다양성)으로 구성된다. 그러나 이러한 기준만으로는 패턴이 실제 현상이나 라벨과 얼마나 연관성이 있는지를 판단하기 어렵다. 따라서 통계적 유의성(패턴이 무작위 데이터에서 발생할 확률)과 판별력(패턴이 특정 클래스와 얼마나 강하게 연관되는가)을 추가로 고려해야 한다는 필요성을 제시한다.
이를 구현하기 위해 저자들은 두 개의 새로운 목적 함수 컴포넌트를 설계한다. 첫 번째는 ‘통계적 유의성 컴포넌트(SSC)’이다. 트리클러스터 T = (I,J,K) 의 패턴 φ_T 가 전체 데이터에서 나타날 기대 확률 p_φ_T 를 계산하고, 이항 검정을 통해 p‑value 를 구한다. p‑value 가 사전 정의된 α 수준 이하이면 통계적으로 의미 있는 패턴으로 인정한다. 두 번째는 ‘판별력 컴포넌트(DPC)’이다. 라벨이 있는 경우, 패턴 φ_T 와 클래스 c 사이의 연관 규칙 φ_T → c 의 lift 와 표준화 lift 를 이용한다. DPC는 w_d1·norm_lift + w_d2·standard_lift 형태로 정의되며, 사용자는 w_d1, w_d2 를 조정해 ‘판별력 자체를 최대화’하거나 ‘특정 클래스에 대한 판별력을 강조’하는 전략을 선택할 수 있다.
제안 방법을 검증하기 위해 저자들은 두 가지 대표적인 트리클러스터링 알고리즘, δ‑Trimax와 TriGen에 SSC와 DPC를 통합한다. δ‑Trimax는 기존에 MSR 기반 임계값 δ 이하의 트리클러스터만을 탐색했으나, 새로운 목적 함수는
F = α·MSR + β·SSC + γ·DPC 로 구성되어 품질, 유의성, 판별력 사이의 가중치를 명시적으로 조정한다. TriGen은 다목적 진화 알고리즘으로, 원래는 MSR, LSL, MSL 등 여러 품질 목표를 동시에 최적화했다. 여기에도 SSC와 DPC를 각각 새로운 목표로 추가해 파레토 최적 해 집합을 확장한다.
실험은 세 가지 케이스 스터디를 통해 수행되었다. 첫 번째는 합성 데이터로, 패턴의 크기·노이즈 수준을 조절해 통제된 환경에서 알고리즘의 민감도를 평가했다. 두 번째는 유전자 발현 데이터(라벨: 질병 여부)로, 생물학적 의미와 예측 성능을 동시에 검증했다. 세 번째는 지진 파형 데이터(라벨: 진동 강도)로, 시계열 특성을 가진 실제 데이터에서의 적용 가능성을 확인했다. 각 케이스에서 기존 δ‑Trimax와 TriGen, 그리고 제안 방법을 동일한 연산 예산(시간·반복 횟수) 하에 비교하였다.
평가 결과는 다음과 같다. (1) 통계적 유의성 측면에서 제안 방법은 p‑value 를 기존 대비 평균 70 % 이상 감소시켰으며, 일부 케이스에서는 p‑value < 10⁻⁶ 수준까지 도달했다. (2) 판별력 측면에서는 lift 평균이 1.5배 이상 상승하고, 표준화 lift 평균이 0.6 → 0.9 로 크게 개선되었다. (3) 기존 품질 지표(MSR, LSL, MSL)는 거의 동일하거나 약간 개선되었으며, 품질 저하 없이 두 새로운 기준을 동시에 만족시켰다. 특히, TriGen의 다목적 파레토 프론티어에 SSC와 DPC가 추가되면서 파레토 최적 해의 밀도가 증가하고, 사용자가 원하는 기준에 따라 손쉽게 해를 선택할 수 있게 되었다.
또한, 저자들은 제안 방법이 알고리즘에 종속되지 않으며, N‑way 텐서, 트랜잭션, 시퀀스 데이터 등 다양한 데이터 구조에도 동일하게 적용 가능함을 논의한다. SSC와 DPC는 각각 독립적인 모듈로 구현되어, 기존 목적 함수에 간단히 삽입하거나 제거할 수 있다. 이를 통해 연구자는 특정 도메인에 맞는 평가 기준을 자유롭게 조합할 수 있다.
코드 구현은 MIT 라이선스로 GitHub(https://github.com/JupitersMight/MOF_Triclustering)에 공개되어 있어, 재현성 및 확장성을 보장한다. 저자들은 향후 연구 방향으로 (1) 더 정교한 통계 모델(예: 부트스트랩, permutation test) 도입, (2) 다중 라벨·다중 클래스 상황에서의 판별력 확장, (3) 실시간 스트리밍 데이터에 대한 온라인 트리클러스터링 적용을 제시한다.
결론적으로, 본 논문은 통계적 유의성과 판별력을 품질 기준과 동시에 고려하는 일반화 가능한 프레임워크를 제시함으로써, 패턴 탐색이 단순히 ‘동질성’에 머무르지 않고 실제 의미와 예측력을 동시에 확보하도록 만든다. 이는 데이터 과학, 바이오인포매틱스, 지구과학 등 라벨이 존재하는 다차원 데이터 분석에 있어 중요한 전진을 의미한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기