Integrating Statistical Significance and Discriminative Power in Pattern Discovery
Pattern discovery plays a central role in both descriptive and predictive tasks across multiple domains. Actionable patterns must meet rigorous statistical significance criteria and, in the presence of target variables, further uphold discriminative …
Authors: Leonardo Alex, re, Rafael S. Costa
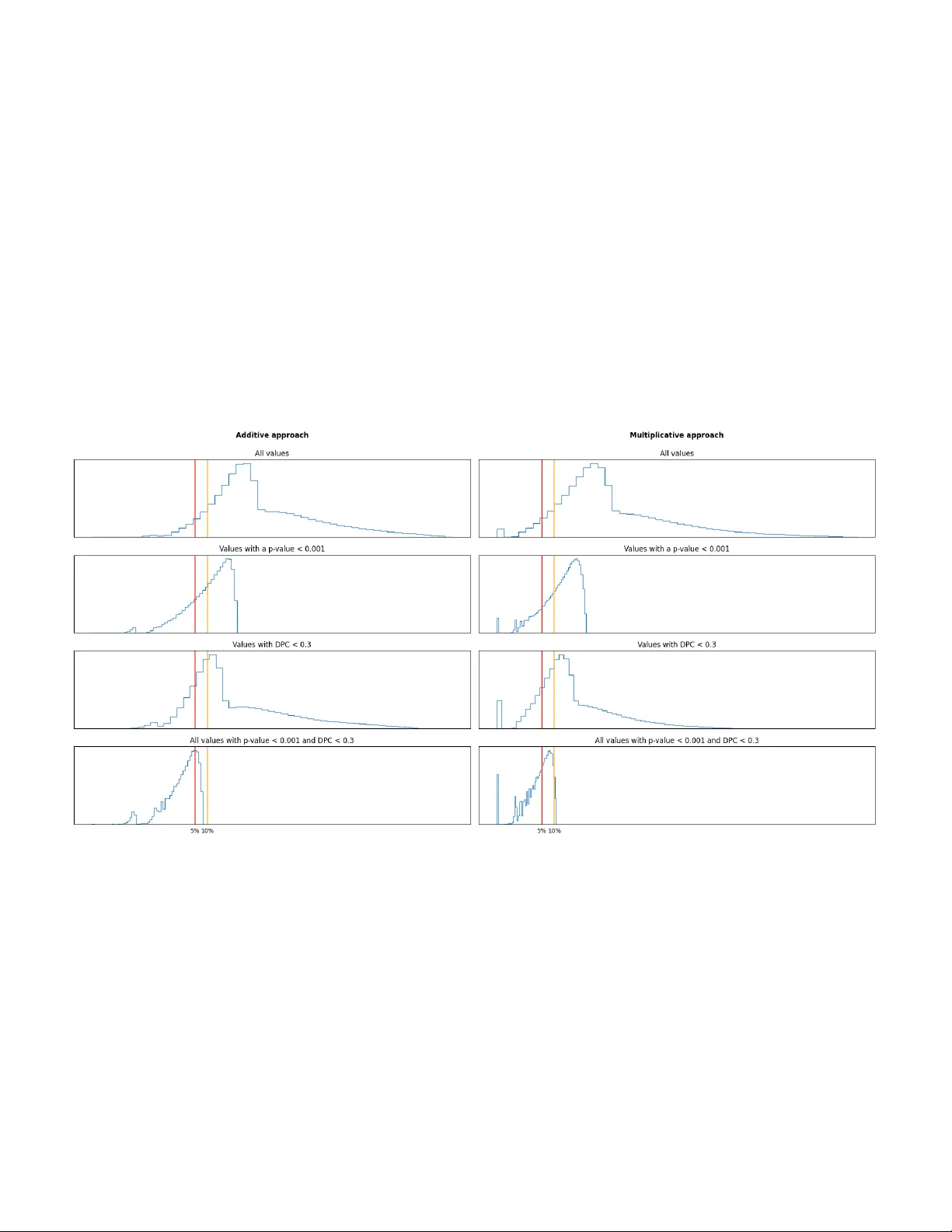
In tegrating Statistical Significance and Discriminativ e P o w er in P attern Disco v ery Leonardo Alexandre 1,2,* , Rafael S. Costa 2 , Rui Henriques 1,* 1 INESC-ID and Instituto Sup erior T ´ ecnico, Univ ersidade de Lisb oa, Lisb oa, Portugal 2 LA QV-REQUIMTE, Departmen t of Chemistry , NO V A Sc ho ol of Science and T echnology , Uni- v ersidade NOV A de Lisboa, 2829-516 Caparica, Portugal ∗ Abstract P attern discov ery pla ys a central role in both descriptive and predictive tasks across multiple do- mains. Actionable patterns m ust meet rigorous statistical significance criteria and, in the presence of target v ariables, further uphold discriminative pow er. Our work addresses the underexplored area of guiding pattern discov ery by in tegrating statistical significance and discriminativ e pow er crite- ria into state-of-the-art algorithms while preserving pattern qualit y . W e also address how pattern qualit y thresholds, imp osed by some algorithms, can b e rectified to accommo date these additional criteria. T o test the prop osed methodology , w e select the triclustering task as the guiding pat- tern discov ery case and extend well-kno wn greedy and multi-ob jective optimization triclustering algorithms, δ -T rimax and T riGen, that use v arious pattern quality criteria, such as Mean Squared Residual (MSR), Least Squared Lines (LSL), and Multi Slop e Measure (MSL). Results from three case studies show the role of the prop osed metho dology in discov ering patterns with pronounced impro vemen ts of discriminative p o wer and statistical significance without qualit y deterioration, highligh ting its imp ortance in sup ervisedly guiding the search. Although the proposed metho dol- ogy is motiv ated ov er multiv ariate time series data, it can b e straightforw ardly extended to pattern disco very tasks inv olving multiv ariate, N-wa y (N > 3), transactional, and sequential data structures. Av ailabilit y: The co de is freely av ailable at h ttps://gith ub.com/JupitersMight/MOF T riclustering under the MIT license. 1 In tro duction P attern mining is a widely rese arc hed field of data analysis that has served as the backbone of decision-making across many fields of expertise [33]. In this context, kno wledge acquisition is driv en b y the discov ery of unexp ectedly frequen t substructures from a given data structure. In tabular data, pattern discov ery generally aims to find coherent subspaces defined b y subsets of observ ations and v ariables [24]. When handling more complex data structures (e.g. cubic data, three-wa y data) triclustering algorithms define coheren t subspaces across the three dimensions, t ypically referred to as sub-cubes or triclusters [20]. Finding coherent subspaces dep ends on the merit function implemen ted by the algorithm to guide the search. T ypically , algorithms ensure that extracted patterns (1) are dissimilar, (2) yield statistical significance e.g. an unexp ectedly low probability of o ccurrence against a null data mo del, and (3) meet rigorous quality criteria [20]. Additionally , in the presence of annotated data, patterns can b e assessed using interestingness measurements [2]. P atterns exhibiting a high discriminative p o wer tow ards an outcome of in terest play a central role in enhancing predictiv e tasks [4, 31]. ∗ Correspondence { leonardoalexandre,rmch } @tecnico.ulisboa.pt 1 Curren t research in the field of discriminativ e pattern mining aims at improving the efficiency of the searches [30], reducing false p ositive discov eries [19], promoting actionabilit y [29], and using discriminativ e patterns to guide predictive approaches [21]. Complemen tarily , statistical tests for assessing the statistical significance of patterns hav e been considered for transactional data struc- tures [32]. In this context, statistical significance criteria are applied to the pattern discriminativ e p o wer and not the pattern itself [32]. Additionally , others in the field fo cus on capturing differen t t yp es of correlation [13, 14], improving algorithms to handle differen t data types [10] and their scalabilit y [26]. T o the b est of our kno wledge, there are no approaches that integrate quality crite- ria, discriminativ e criteria, and statistical significance to guide pattern discov ery . In this con text, w e provide an in-depth discussion on how to prop erly incorp orate statistic al signific anc e and dis- criminative criteria into the merit functions of state-of-the-art algorithms without forgoing pattern qualit y . F urthermore, we discuss how to automatically revise the qualit y thresholds asso ciated with the pursued merit functions as imp osed b y some algorithms (e.g. δ -T rimax [8]). Considering the increasing ability to monitor the b ehavior of systems along time, a notable rise in the av ailabilit y of tensor data structures, particularly three-w ay data, has b een observed. The in trinsic prop erties of three-wa y data play a significan t role in the understanding of underlying pro- cesses and relationships, rendering it a v aluable resource for pattern-guided kno wledge acquisition and decision supp ort. T o this end, we modify tw o w ell-known greedy-based triclustering algorithms for temp oral pattern disco very in three-w ay data, δ -T rimax[8] and T riGen[17], and assess the pro- p osed metho dology in the context of three case studies. W e observe that the algorithms pro duce significan t improv ements in b oth the discriminative p ower and statistic al signific anc e of the formed patterns. The prop osed methodology is not algorithm-constrained nor data-constrained, thus it can b e extended and used with an y N -dimensional pattern mining algorithm. The pap er is organized as follo ws: the remainder of this section pro vides the essential bac k- ground. Section 2 introduces the prop osed metho dology . Section 3 discusses the gathered results from real-w orld and synthetic data. Concluding remarks and implications are finally drawn. 1.1 Bac kground Consider a t wo-dimensional dataset (matrix data), denoted as A , defined b y n observ ations ( X = x 1 , ..., x n ) and m v ariables ( Y = y 1 , ..., y m ), featuring n × m elemen ts a ij . The tasks of clustering and biclustering aim to extract clusters I i ⊆ X or biclusters B k = ( I k , J k ), eac h represen ted b y a subset of observ ations I k ⊆ X correlated on a subset of v ariables J k ⊆ Y . Homogeneit y criteria, t ypically ensured through the application of a merit function, guide the formation of (bi)clusters [24]. F or a giv en bicluster, its v alues a ij = c j + γ i + η ij can be explained by v alue exp ectations c j , adjustments γ i , and noise η ij . If eac h element of A corresp onds to a bicluster, the bicluster pattern φ B is the ordered set of v alues in the absence of adjustments and noise, expressed as φ B = { c j | y j ∈ J } . In addition to the homogeneit y criteria, criteria for statistic al signific anc e [19] ensure that the probability of a bicluster’s occurrence (compared to a n ull model) deviates from exp ectations. Moreo ver, dissimilarity criteria [18] can b e applied to further ensure the absence of redundan t biclusters. A three-dimensional dataset (three-w ay tensor data), denoted as A , is c haracterized b y n ob- serv ations X = { x 1 , ..., x n } , m v ariables Y = { y 1 , ..., y m } , and p contexts Z = { z 1 , ..., z p } . The elemen ts a ij k establish a connection b etw een observ ation x i , attribute y j , and con text z k . Similar to tw o-dimensional data, three-dimensional data can b e r e al-value d ( a ij k ∈ R ), symbolic ( a ij k ∈ Σ, where Σ is a set of nominal or ordinal symbols), in teger ( a ij k ∈ Z ), or non-identic al ly distribute d 2 ( a ij k ∈ A j , where A j is the domain of v ariable y j ), and ma y contain missing elemen ts, a ij k ∈ A j ∪ ∅ . When the con text dimension represents a set of time p oints ( Z = { t 1 , t 2 , ..., t p } ), w e encoun ter a temp oral three-dimensional dataset, also kno wn as m -order multiv ariate time series data. Giv en three-wa y tensor data A with n observ ations, m v ariables, and p contexts/time p oin ts, a tricluster T = ( I , J, K ) represen ts a subspace of the original space, where I ⊆ X , J ⊆ Y , and K ⊆ Z are subsets of observ ations, v ariables, and con texts/time p oints, resp ectiv ely [20]. The triclustering task aims to discov er a set of triclusters T = { T 1 , ..., T l } such that eac h tricluster T i satisfies sp ecific criteria of homogeneity , dissimilarity , and statistic al signific anc e . Each element of a tricluster, a ij k , is describ ed by a base v alue c j k , observ ation adjustmen t γ i , and noise η ij k . The tricluster pattern , φ T , constitutes an ordered set of v alue exp ectations along the subset of v ariables and context dimensions in the absence of adjustments and noise: φ T = { c j k | y j ∈ J, z k ∈ K, c j k ∈ Y k } . The co verage Φ of the tricluster pattern φ T , denoted as Φ( φ T ), corresp onds to the n umber of observ ations containing the tricluster pattern φ T . This same logic can b e extended to a nominal outcome of in terest c , where c can take an y v alue in the class v ariable. The co verage of the outcome, defined as Φ( c ), represen ts the n umber of observ ations with the outcome of interest. F or instance, considering the class v ariable y out = [ a, b, a, a ], the co verage Φ( a ) is equal to 3 / 4. Homogeneit y criteria play a crucial role in determining the structure, coherence, and quality of a triclustering solution [20]. In this context: – the structur e is defined by the num b er, size, shap e, and p osition of triclusters; – the c oher enc e of a tricluster is defined by the observed correlation of v alues (coherence as- sumption) and the allo wed deviation from exp ectations (coherence strength); – the quality of a tricluster is defined b y the type and amount of tolerated noise. A tricluster exhibits constant coherence when the subspace demonstrates constan t v alues (for sym b olic data) or approximately constant v alues (for real-v alued data). Dissimilarit y criteria ensure that any tricluster similar to another tricluster with higher priority is remo ved from T and p ossibly used to refine similar triclusters in T . A tricluster T = ( I , J, K ) is considered maximal if and only if there is no other tricluster ( I’,J’,K’ ) such that I ⊆ I ′ ∧ J ⊆ J ′ ∧ K ⊆ K ′ , satisfying the giv en criteria. F oremost, statistic al signific anc e criteria ensure that the probabilit y of eac h retrieved tri- cluster o ccurring against a null data mo del is unexpectedly lo w. Giv en the probability of the o ccurrence of a tricluster pattern, p φ T , binomial tails can be emplo yed to robustly compute the probabilit y of a tricluster T = ( I , J, K ) with pattern φ T o ccurring for | I | or more observ ations [19]. Accordingly , p -v alue = P ( x ≥ | I | | x ∼ B in ( p φ T , | X | )) = | X | X x = | I | | X | x p x φ T (1 − p φ T ) | X |− x , (1) where B in ( p φ T , | X | ) is the null binomial distribution, p φ T the tricluster pattern probabilit y , | X | the sample size, and | I | the num b er of successes. A more detailed formulation can b e found at [3]. The discriminative prop erties of a tricluster pattern φ T , along with other interestingness measuremen ts, can b e ev aluated using asso ciation rules [2]. Asso ciation rules depict a connection b et ween tw o even ts, defined b y a left-hand side (anteceden t) and a right-hand side (consequent). In this con text, an asso ciation rule may tak e the form φ T → c , where a pattern in the an tecedent discriminates an outcome of in terest in the consequen t. The co v erage of the asso ciation rule, Φ( φ T → c ), is determined by the n umber of observ ations where b oth the pattern φ T and the outcome c co-o ccur. 3 Tw o established interestingness measures are the c onfidenc e , Φ( φ T → c ) / Φ( φ T ), assessing the probabilit y of c o ccurring when φ T o ccurs, and the lift , (Φ( φ T → c ) / (Φ( φ T ) × Φ( c )) × N , which further considers the probabilit y of the consequent to ev aluate the dep endence b etw een the con- sequen t and anteceden t. Additionally , a standardized version of the lift measure [25] has prov en to b e particularly useful as a complementary measuremen t. In con trast to the lift measure, the standardized lift measure returns v alues b etw een [0; 1], indicating whether the pattern has achiev ed its maxim um lift, with a v alue of 1 implying it has. standar d lif t = lif t − ω v − ω , (2) where ω is defined as: ω = max 1 Φ( φ T ) + 1 Φ( c ) − 1 , (1 / | X | ) (1 / Φ( φ T )) × (1 / Φ( c )) , (3) and v is defined as: v = 1 max(1 / Φ( φ T ) , 1 / Φ( c )) . (4) T riclustering algorithmic approac hes b elong to t w o ma jor categories: 1) greedy or stochastic, or, 2) (quasi-)exhaustiv e [20]. Each approach can be further categorized according to the underlying b eha vior that it relies on, such as biclustering-based searches, and evolutionary multiob jective op- timization algorithms, among others. Considering the scalability limits of exhaustive searches, this w ork places a fo cus on greedy-based approac hes. Greedy algorithms follow tw o ma jor approaches: 1) initialize a big pattern and iterativ ely refine it based on quality criteria until a satisfactory so- lution is obtained[8], or 2) initialize multiple small patterns and iteratively merge them based on qualit y criteria until a maximum predefined n umber of iterations is reac hed[17]. The latter approac h is usually emplo yed by ev olutionary algorithms [27]. Irresp ectively of the selected approach, the extracted patterns will reflect a coherent temp oral progression with a sp ecific structure and qualit y , that represent the homo geneity of the pattern. Largely applied triclustering algorithms, including MOGA3C [23] and δ -T rimax [8], fo cus on optimizing each pattern with regards to pattern size, or pattern quality (e.g. mean squared residual score[11]). Others in the field hav e fo cused their efforts on developing new merit functions or extending already well-established ones to b e used in more complex data structures. Kak ati et al. [22], implements the Shifting-and-Scaling Similarity measure (SSSim) [1] in the context of tensor data. Similarly , b oth Bhar et al. [8] and Guti´ errez-Avil ´ es and Rubio-Escudero [16], prop osed an extension of the mean square residue score (MSR) [11] to be incorp orated into merit functions of triclustering algorithms. Guti ´ errez-Avil´ es and Rubio-Escudero [13, 14] prop osed tw o ev aluation measures for triclusters, termed Least Squared Lines (LSL) and Multi Slop e Measure (MSL), that fo cus on the similarity among the angles of the slop es formed by eac h profile of a tricluster pattern. Both LSL and MSL are embedded in merit functions employ ed b y T riGen [17], a multi-ob jective evolutionary algorithm, and its’ extension ST riGen [26]. Merit functions ha ve also b een tailored to fit domain-sp ecific problems. Amaro-Mellado et al. [5] ex- tracted seismic source zones by mo difying T riGen merit functions to accommo date the geophysical indicators. In the presence of gene expression data, Guti´ errez-Avil´ es and Rubio-Escudero [15], pro- p osed the addition of biological qualit y to merit functions (functional enric hment of the extracted regulatory patterns [12]). 4 Tw o w ell-established greedy-based triclustering algorithms are: 1) delta -T rimax [8], a greedy it- erativ e searc h algorithm that finds maximal triclusters having a score below a user-defined threshold ( δ ), and, 2) T riGen [17], an ev olutionary multiob jective algorithm. Evolutionary algorithms hav e three main steps: 1) an initialization step that creates the initial p opulation, 2) an ev aluation step to assess the quality of eac h individual, given by a fitness function, to decide which individuals sur- viv e for the next iteration, and, 3) crossov er and mutation, where individuals form connections and p erform changes that will pass onto future generations (for more detailed formulations, the reader can c heck [17]). Despite the t wo aforementioned algorithms ha ving different underlying behaviors to extract patterns, b oth implement w ell-established ob jectiv e functions. The δ -T rimax utilizes the mean square residue score (MSR) describ ed b y: M S R = 1 | I | × | J | × | K | X i ∈ I ,j ∈ J,k ∈ K ( a ij k − a iJ K − a I j K − a I J k + 2 × a I J K ) 2 , (5) where a iJ K , a I j K , and a I J k , corresp ond to the a verage of v alues for observ ation x i giv en the subset of v ariables J and contexts K , a verage of v alues for v ariable y j giv en the subset of observ ations I and con texts K , and a v erage of v alues for con text z k giv en the subset of observ ations I and v ariables J respectively . T rigen implements a wide v ariety of ob jective functions, of which we will fo cus on MSR, multi- slop e measure (MSL), and least-squared line (LSL). Both LSL and MSL fo cus on graphical simi- larit y . LSL measures the similitude b etw een the least squares appro ximation for the p oints in each graphic of the three views, describ ed b y the following equation: LS L = AC lsl ( { I , J, K } ) + AC lsl ( { I , K , J } ) + AC lsl ( { K, I , J } ) 3 , (6) where AC lsl ( { I , J, K } ), AC lsl ( { I , K , J } ), and AC lsl ( { K, I , J } ) represent the least squares approx- imation op eration o ver the graphical representation of the tricluster. MSL measures the similarit y among the angles of the slop es formed by each profile, M S L = AC multi ( { I , J, K } ) + AC multi ( { I , K , J } ) + AC multi ( { K, I , J } ) 3 , (7) where AC multi ( { I , J, K } ), AC multi ( { I , K , J } ), and AC multi ( { K, I , J } ) represen t a multiangular comparison op eration ov er the graphical representation of the tricluster. Due to the detailed extent of eac h comp onent, we refer the reader to [17, 14] for a more detailed formulation. 2 Metho dology The prop osed metho dology offers principles on ho w to extend ob jective functions to accommo date b oth statistic al signific anc e views and discriminative criteria without compromising pattern qualit y . T o this end, we prop ose the creation of t wo comp onents based on well-established in terestingness measures in the presence of annotations [2] - discriminative p ower component (DPC) - and on sound statistical tests [3] - statistic al signific anc e comp onen t (SSC). By default, DPC incorp orates tw o measures, the lift measure, and its’ standardized version [25], D P C = w d 1 × nor mal iz ed l if t + w d 2 × standar d l if t, (8) 5 A x 1 x 2 x 3 x 4 x 5 x 6 x 7 x 8 x 9 class variable A A A A B B B B B C C C x 10 x 11 x 12 x 13 I = {x 1 , x 2 , x 3 , x 6 , x 7 } Lift = 1.56 Standardised Lift = 0.5 I = {x 1 , x 2 , x 3 , x 1 1 , x 12 } Lift = 1.73 Standardised Lift = 0.5 I = {x 3 , x 4 , x 5 , x 1 1 , x 12 , x 13 } Lift = 2.16 Standardised Lift = 1.0 I = {x 4 , x 5 , x 12 , x 13 } Lift = 2.16 Standardised Lift = 0.5 Figure 1: Example of standard lift and lift measurements in the context of four patterns and one class v ariable with three outcomes. The red pattern discriminates outcome A with a lift of 1 . 56 and standardized lift of 0 . 5, the blue pattern discriminates outcome C with a lift of 1 . 73 and standardized lift of 0 . 5, the green pattern discriminates outcome C with a lift of 2 . 16 and standardized lift of 1, the purple pattern discriminates outcome C with a lift of 2 . 16 and standardized lift of 0 . 5. where w d 1 and w d 2 represen t user-defined w eights, and nor mal iz ed l if t - defined as desir e d lift / lift , if l if t > desired lif t , and 1 otherwise. By default, b oth w d 1 and w d 2 ha ve the same v alue but can b e adjusted dep ending on user preferences for finding patterns with a higher discriminative p ower ( w d 2 ) versus maximizing the discriminative p ower of eac h pattern ( w d 1 ). Figure 1 provides an example of how patterns with the same discriminative p ow er v ary in terms of completeness and vice versa. Additionally , the user can also adjust the minimum lift necessary for a pattern to b e discriminativ e - giv en b y the desir e d lift v ariable. By default, desir e d lift has a v alue of 1 . 2, but an y v alue ab ov e 1 . 0 already forces the formation of patterns with discriminative prop erties. The SSC implements the statistic al signific anc e tests prop osed b y Alexandre et al. [3], but the use of other significance tests is also supp orted. A significance threshold ( θ ) of < 0 . 05, where we test the probability of each pattern against a n ull data model, is set as a standard threshold to inhibit false p ositives. Depending on the algorithmic approac h (e.g. if w e know the num b er of patterns before the search), further adjustmen ts to this threshold can be done via the Bonferroni Correction [19]. T o allow for a less abrupt transition when ev aluating statistic al signific anc e , we adjust the significance comp onent by scaling the p-v alues with a logarithmic function. Given the aforesaid, the SSC is then defined as: S S C = ( 1 | log( p -v alue) | , if p -v alue < θ 1 , otherwise . (9) Finally , to embed the prop osed comp onents into existing ob jectiv e functions we consider tw o main approac hes, one based on addition and one on multiplication. The choice dep ends on how w e choose to view the comp osition of comp onents. If we assume that it is linear, addition is a natural wa y of capturing that behavior. Additionally , b y using addition it is easier to mo del the degree to whic h b oth the discriminative p ower and statistic al signific anc e components comp ensate for pattern qualit y . Multiplication is suggested to p enalize the score of patterns more abruptly . Con trary to the additive approach, the changes in the v alues of one of the components pro duce a prop ortional impact on the outcome statistic. With this in mind, we define the mo dified ob jective function (MOF), M O F = ( β 1 P QC α 1 + β 2 ( D P C × P QC ) α 2 + β 3 ( S S C × P QC ) α 3 , if additiv e, P QC α 1 × D P C α 2 × S S C α 3 , if m ultiplicative , (10) 6 where β (1 − 3) and α (1 − 3) represen t the weigh ts and adjustments of eac h comp onent. The default v alue for the β w eights is 1 and for the α adjustments is 1 /k where k is the num b er of comp onents. F urther adjustments can b e made to b etter understand the reasoning b ehind the prop osed default v alues recall that state-of-the-art algorithms follow one of tw o approaches, either b ottom-up or top-do wn. F or algorithms that follow a top-do wn approach with a strict PQC threshold, w e need to consider how the incorp oration of DPC and SSC mo dules impacts the imposed threshold. Therefore, w e explore the b ehavior of the MOF when a constant PQC v alue is applied. Figure 2 illustrates how MOF v aries for different DPC v alues and p -v alues. W e observe that in b oth approaches the distribution of v alues approximately follows a normal distribution, and as a result, w e can examine binomial tails to study stricter and rarer MOF v alues. In this con- text, low er v alues translate into a b etter pattern solution, as such w e concentrate on the right tail of the binomial distribution marked by the commonly applied b oundaries of 5% and 10%. By filtering out v alues using slightly stricter criteria for each comp onent, w e notice that almost all p ossible pattern solutions abiding b y the criteria, fall under the 10% right tail. Since the Figure 2: Illustration of the modified ob jective function based on additiv e approac h, left column plots, m ultiplicative approach, right column plots. F rom top to b ottom, each plot represents the distribution of v alues when considering: 1) all v alues, 2) v alues whose original p -v alues are less than 0 . 001, 3) v alues whose DPC has a v alue less than 0 . 3, and, 4) v alues with the tw o aforesaid restrictions. The x-axis presents the v alue returned by the modified ob jective function and the y-axis is the frequency of each v alue. T o generate the v alues for the distribution a fixed PQC is used, D P C ∼ U (0 , 1) and p -v alues are either sampled from U (0 , θ ) or U ( θ , 1) with equal probability . V alues to the left of the red line b elong to the 5% low est v alues of the distribution. Similarly , the yello w line marks the v alue of the 10th p ercentile. 7 aforemen tioned MOF distribution is not molded by PQC v alues, we can use these b oundaries to redefine the original user-inputted pattern quality threshold. The new threshold is then defined as M O F m 20 , where M OF m 20 is the m 20 th modified ob jective function v alue from an ordered arra y of v alues ⟨ M O F 1 , M O F 2 , ..., M O F m ⟩ , with size m . Each v alue is defined b y equation 10 where D P C ∼ U (0 , 1) and p -v alues are either sampled from U (0 , θ ) or U ( θ, 1) with equal probability . 3 Computational Exp erimen tal Setup In order to assess the effectiv eness of the proposed ob jectiv e function in aiding the discov ery of patterns with discriminativ e and statistical significance guaran tees, we selected tw o greedy-based triclustering algorithms. Each algorithm represents one of the tw o ma jor s earc h approaches. First, δ -T rimax [9], an iterative search algorithm that follows a top-down approach. F or a v alid pattern solution, it imposes a strict MSR threshold that must be satisfied. Second, T riGen [17], a multi- ob jectiv e ev olutionary algorithm that follo ws a b ottom-up approac h. It uses a fitness function based on pattern qualit y measures to guide pattern formation. The mo dified algorithms are then applied in the context of three publically a v ailable datasets : activity r e c o gnition data [28], b asketb al l movements data [6], and sp orts activies data [7]. T able 1 provides a brief description of eac h dataset and the applied prepro cessing. In the case of the δ -T rimax algorithm, the imp osed MSR threshold is based on the dataset and also on the approach. F or the activity r e c o gnition data δ orig inal = 10 − 2 , δ additiv e = 10 − 3 , and δ multiplicativ e = 10 − 4 , for the original algorithm, the algorithm mo dified with the additive approach, and the algorithm mo dified with a multiplicativ e approac h, respectively . F or the b asketb al l movements data δ orig inal = 10 − 3 , δ additiv e = 10 − 3 , and δ multiplicativ e = 10 − 4 . Finally , for the sp orts activities data, δ orig inal = 10 − 4 , δ additiv e = 10 − 4 , and δ multiplicativ e = 10 − 3 . Regarding the T riGen parameter setup, we select a total of 20 clusters to b e extracted with every other parameter set to their default v alues. Finally , we assess pattern solutions returned by b oth δ -T rimax and T rigen, and their mo dified v ersions, assessing them against each other. W e use the t-studen t test to understand if there is a significan t impro vemen t on (1) pattern qualit y; (2) sp earman and p earson correlation metrics, used to test improv ements in similar instances [13, 14]; and (3) discriminative and statistical significant criteria. Additionally , we provide the outcome distribution b etw een the original algorithms and their mo dified v ersions. T able 1: Summary of the selected case studies, including the size and domain of each dimension (e.g., sp orts, sensor data, time), and the applied prepro cessing. Datasets Description Preprocessing activity re c o gnition (activity x sensor data x time) (88 x 6 x 480) Real-life b enchmark in the area of Activity Recognition to predict the ac- tivity p erformed by a user from time-series generated by a Wireless Sen- sor Network (WSN), according to the EvAAL comp etition technical annex (http://ev aal.aaloa.org/). – F eature scaling; b asketb al l movements (basketball mov ement x sensor data x time) (79 x 6 x 100) A total of 4 users w ere asked to do the following 5 activities: pass, hold the ball, shoot pick up the ball, and dribble. Data was gathered using accelerometer measures and gyroscop e measures. – F eature scaling; – Piecewise Aggregate Approximation (P AA); (100 time p oints) sp orts activities (sport x sensor data x time) (152 x 46 x 375) The sub jects were asked to p erform the activities in their own style and were not restricted on how the activities should b e p erformed. Sensor units were used to acquire data at 25 Hz sampling frequency . The 5-min signals are divided in to 5-sec segmen ts so that 480(=60x8) signal segments are obtained for each activity . – F eature scaling; – Piecewise Aggregate Approximation (P AA); (375 time p oints) 8 4 Results and Discussion W e h yp othesize that the extension of triclustering algorithms, with the prop osed mo dified ob jec- tiv e functions, pro duce triclustering solutions where patterns exhibit an ov erall impro vemen t in b oth discriminative p ower and statistic al signific anc e against traditional searches solely fo cused on homogeneity criteria. In T able 2 we present the results of this analysis for each case study and metho dologic approac h. Eac h pattern solution is assessed with regard to the a verage v olume of pat- terns, pattern quality measurements, discriminative p ower criteria, statistic al signific anc e criteria , v ariable correlation criteria, and ob jective function v alues. Considering the activity r e c o gnition data, we observ e an ov erall improv ement of metric v alues across all pattern solutions using mo dified ob jective functions. Specifically , the additiv e approac h in the T riGen algorithm revealed significant improv ements in the discriminative p ower and sta- tistic al signific anc e of the returned patterns. The m ultiplicative approac h shows more mo derate impro vemen ts, under the MST or MLS pattern qualit y functions. It nev ertheless yields high gains in v ariable correlation. Notably , the mo dified ob jective functions did not strongly alter pattern qual- it y . Interestingly , in some instances, the MOF contributed to an increase in the av erage pattern qualit y , as seen in the case of the δ -T rimax algorithm. Considering the b asketb al l data, the results also show an ov erall improv ement in discriminative p ower criteria for T rigen. The m ultiplicative MOF with T riGen yields consistent gains of discrimi- native p ower under b oth MSR or LSL pattern quality measuremen ts, and, T riGen using an additiv e approac h under the MLS measuremen t. As with the activity recognition data, gains of v ariable correlation were also observed when T riGen used a multiplicativ e approac h with MSR as a pattern qualit y measure. Additionally , in b oth MOF versions of the δ -T rimax algorithm, patterns achiev ed their maximum standard lift v alue but a low er lift v alue than the original approach. Both MOF v ersions of T riGen, under the LSL pattern qualit y measuremen t, and δ -T rimax had significan t gains in statistic al signific anc e . Finally , consider the results pro duced using the sp orts data. W e observ e an increase of discrimi- native p ower in all MOF v ersions of the T riGen algorithm v ersus its’ original approac h. Similarly to b oth activity recognition and basketball data results, results pro duced b y the δ -T rimax algorithm pro duced patterns with higher completeness of discriminative p ower . The MOF m ultiplicativ e approac h of T riGen, under the MLS and LSL pattern quality measurement, pro duced significant impro vemen ts in pattern statistic al signific anc e . Similarly , b oth MOF v ersions of δ -T rimax also pro duced patterns with higher statistic al signific anc e . In addition to the previous analysis, w e provide an in-depth view of the discriminative p ow er of patterns for eac h dataset. Figure 3 displays three distinct patterns. The first pattern is extracted from the activity dataset using the MOF additive v ersion of T riGen, assessed under the MSR pattern qualit y measuremen t. The second pattern originates from the b asketb al l dataset, extracted b y the MOF m ultiplicative version of T riGen, and ev aluated under the LSL pattern qualit y measurement. Lastly , the third pattern is obtained from the sp orts dataset using the MOF additive version of δ - T rimax. All of the patterns presen ted are from pattern solutions whose pattern exhibited significan t impro vemen ts in discriminative p ower . W e note that the activity dataset pattern only discriminates ’w alking.’ In the b asketb al l dataset, the pattern strongly discriminates ’hold’ but also ’pass.’ The selected pattern in sp orts data exhibits high discriminative p ow er across walking-related tasks, most lik ely due to the similarity b etw een tasks. 9 T able 2: Statistics of the pattern solutions extracted by eac h triclustering algorithm version (original, additiv e-based, multiplicativ e-based), with different pattern qualit y metrics, ov er the three case study datasets. Column ” | I | × | J | × | K | ” presents details p ertaining to the av erage num b er of observ ations ( | I | ), v ariables ( | J | ), and contexts ( | K | ). The remaining columns corresp ond to the av erage ± standard deviation of the measurement corresp onding to the column name. a) Activity dataset | I |×| J |×| K | MSR MLS LSL lift standar d lift DPC SSC Pearson Spearman M OF add. M OF mul. T rigen Original (MSR) 18 x 5 x 90 0.01 ± 0.003 - - 2.48 ± 0.9 0.45 ± 0.23 0.55 ± 0.20 0.004 ± 0.01 0.25 ± 0.07 0.25 ± 0.06 - - Additive (MSR) 16 x 5 x 97 0.01 ± 0.004 - - 4.4 ± 2.04 0.75 ± 0.23 0.29 ± 0.18 0.003 ± 0.0005 0.24 ± 0.11 0.24 ± 0.12 0.40 ± 0.06 - Multiplicative (MSR) 14 x 4 x 86 0.01 ± 0.003 - - 3.52 ± 1.60 0.54 ± 0.23 0.44 ± 0.20 0.004 ± 0.0009 0.45 ± 0.19 0.42 ± 0.19 - 0.02 ± 0.06 Original (MLS) 13 x 5 x 92 - 0.48 ± 0.07 - 2.85 ± 1.43 0.35 ± 0.18 0.58 ± 0.17 0.005 ± 0.001 0.27 ± 0.06 0.25 ± 0.06 - - Additive (MLS) 14 x 4 x 89 - 0.49 ± 0.04 - 4.49 ± 1.24 0.76 ± 0.19 0.26 ± 0.12 0.004 ± 0.0009 0.26 ± 0.10 0.26 ± 0.11 1.4 ± 0.09 - Multiplicative (MLS) 16 x 3 x 83 - 0.51 ± 0.07 - 3.04 ± 1.00 0.51 ± 0.21 0.47 ± 0.18 0.004 ± 0.0008 0.36 ± 0.15 0.36 ± 0.16 - 0.09 ± 0.01 Original (LSL) 16 x 5 x 86 - - 0.67 ± 0.22 2.98 ± 1.24 0.48 ± 0.18 0.49 ± 0.16 0.005 ± 0.001 0.31 ± 0.13 0.31 ± 0.14 - - Additive (LSL) 16 x 4 x 86 - - 0.57 ± 0.21 4.18 ± 1.20 0.78 ± 0.22 0.27 ± 0.15 0.004 ± 0.0009 0.34 ± 0.16 0.33 ± 0.16 1.42 ± 0.27 - Multiv ative (LSL) 15 x 4 x 83 - - 0.60 ± 0.13 3.33 ± 1.33 0.55 ± 0.24 0.44 ± 0.20 0.004 ± 0.001 0.33 ± 0.13 0.33 ± 0.13 - 0.09 ± 0.02 δ -T rimax Original 32 x 5 x 50 0.009 ± 0.0008 - - 2.18 ± 0.35 0.75 ± 0.19 0.41 ± 0.1 0.11 ± 0.30 0.40 ± 0.12 0.39 ± 0.14 - - Additive 27 x 4 x 37 0.004 ± 0.001 - - 2.42 ± 0.67 0.70 ± 0.24 0.41 ± 0.13 0.01 ± 0.03 0.44 ± 0.23 0.40 ± 0.21 0.30 ± 0.01 - Multiplicative 28 x 4 x 71 0.008 ± 0.001 - - 2.45 ± 0.42 0.74 ± 0.12 0.38 ± 0.06 0.01 ± 0.01 0.35 ± 0.14 0.35 ± 0.15 - 0.02 ± 0.06 b) Basketball dataset | I |×| J |×| K | MSR MLS LSL Lift Std. Lift DPC SSC Pearson Spearman M OF add. M OF mul. T rigen Original (MSR) 17 x 6 x 22 0.009 ± 0.003 - - 1.67 ± 0.35 0.31 ± 0.06 0.72 ± 0.09 0.08 ± 0.21 0.19 ± 0.06 0.20 ± 0.06 - - Additive (MSR) 17 x 6 x 22 0.008 ± 0.003 - - 1.79 ± 0.35 0.35 ± 0.09 0.67 ± 0.1 0.02 ± 0.008 0.19 ± 0.08 0.19 ± 0.08 0.42 ± 0.06 - Multiplicative (MSR) 13 x 4 x 22 0.006 ± 0.005 - - 2.36 ± 0.87 0.47 ± 0.18 0.56 ± 0.19 0.013 ± 0.006 0.27 ± 0.17 0.26 ± 0.14 - 0.03 ± 0.12 Original (MLS) 13 x 5 x 20 - 0.53 ± 0.04 - 1.79 ± 0.40 0.30 ± 0.11 0.70 ± 0.11 0.05 ± 0.05 0.22 ± 0.15 0.23 ± 0.10 - - Additive (MLS) 10 x 5 x 18 - 0.54 ± 0.04 - 3.17 ± 0.83 0.62 ± 0.22 0.39 ± 0.16 0.03 ± 0.02 0.24 ± 0.13 0.26 ± 0.16 1.65 ± 0.10 - Multiplicative (MLS) 11 x 3 x 20 - 0.58 ± 0.05 - 2.19 ± 0.63 0.34 ± 0.14 0.62 ± 0.13 0.13 ± 0.006 0.30 ± 0.18 0.30 ± 0.16 - 0.16 ± 0.02 Original (LSL) 14 x 4 x 17 - - 0.45 ± 0.13 1.80 ± 0.38 0.32 ± 0.11 0.69 ± 0.13 0.22 ± 0.33 0.33 ± 0.16 0.31 ± 0.16 - - Additive (LSL) 14 x 4 x 20 - - 0.45 ± 0.13 1.96 ± 0.46 0.36 ± 0.10 0.64 ± 0.11 0.02 ± 0.01 0.37 ± 0.16 0.34 ± 0.17 1.64 ± 0.13 - Multiv ative (LSL) 11 x 3 x 20 - - 0.61 ± 0.16 2.62 ± 0.84 0.48 ± 0.23 0.52 ± 0.19 0.02 ± 0.007 0.33 ± 0.22 0.33 ± 0.23 - 0.15 ± 0.03 δ -T rimax Original 15 x 3 x 15 0.0009 ± 0.0004 - - 2.77 ± 0.43 0.57 ± 0.21 0.44 ± 0.13 0.36 ± 0.46 0.52 ± 0.30 0.52 ± 0.28 - - Additive 38 x 5 x 20 0.003 ± 0.0006 - - 2.11 ± 0.30 1.0 ± 0.0 0.29 ± 0.04 0.02 ± 0.02 0.34 ± 0.12 0.34 ± 0.11 1.52 ± 0.07 - Multiplicative 53 x 6 x 43 0.004 ± 0.0006 - - 1.50 ± 0.19 1.0 ± 0.0 0.41 ± 0.04 0.003 ± 0.0003 0.22 ± 0.02 0.22 ± 0.02 - 0.01 ± 0.02 c) Sp orts dataset | I |×| J |×| K | MSR MLS LSL Lift Std. Lift DPC SSC Pearson Spearman M OF add. M OF mul. T rigen Original (MSR) 19 x 25 x 95 33.58 ± 34.89 - - 3.72 ± 1.80 0.39 ± 0.22 0.49 ± 0.16 0.004 ± 0.0006 0.03 ± 0.01 0.03 ± 0.01 - - Additive (MSR) 16 x 21 x 90 37.81 ± 53.94 - - 7.82 ± 4.88 0.69 ± 0.31 0.26 ± 0.21 0.004 ± 0.0009 0.04 ± 0.03 0.04 ± 0.03 3.62 ± 3.97 - Multiplicative (MSR) 15 x 18 x 89 35.92 ± 60.10 - - 7.92 ± 4.82 0.60 ± 0.31 0.31 ± 0.22 0.004 ± 0.0007 0.07 ± 0.11 0.07 ± 0.09 - 0.18 ± 3.92 Original (MLS) 17 x 19 x 87 - 0.50 ± 0.01 - 4.72 ± 2.37 0.47 ± 0.31 0.43 ± 0.23 0.004 ± 0.001 0.05 ± 0.03 0.05 ± 0.02 - - Additive (MLS) 13 x 19 x 85 - 0.50 ± 0.01 - 11.20 ± 4.72 0.86 ± 0.22 0.14 ± 0.14 0.004 ± 0.0008 0.05 ± 0.03 0.05 ± 0.03 1.28 ± 0.12 - Multiplicative (MLS) 15 x 14 x 91 - 0.49 ± 0.02 - 7.59 ± 3.96 0.63 ± 0.31 0.29 ± 0.21 0.003 ± 0.0003 0.09 ± 0.07 0.10 ± 0.07 - 0.07 ± 0.02 Original (LSL) 18 x 20 x 88 - - 0.57 ± 0.10 3.93 ± 1.33 0.39 ± 0.22 0.47 ± 0.14 0.004 ± 0.001 0.04 ± 0.03 0.05 ± 0.03 - - Additive (LSL) 14 x 16 x 77 - - 0.52 ± 0.14 10.34 ± 4.28 0.84 ± 0.21 0.15 ± 0.13 0.004 ± 0.002 0.05 ± 0.03 0.06 ± 0.04 1.31 ± 0.14 - Multiv ative (LSL) 15 x 16 x 94 - - 0.56 ± 0.12 7.99 ± 5.33 0.62 ± 0.29 0.30 ± 0.20 0.003 ± 0.0003 0.06 ± 0.03 0.06 ± 0.03 - 0.07 ± 0.02 δ -T rimax Original 9 x 6 x 63 9 × 10 − 5 ± 7 × 10 − 6 - - 7.45 ± 2.06 0.36 ± 0.14 0.40 ± 0.09 0.50 ± 0.49 0.27 ± 0.15 0.27 ± 0.17 - - Additive 30 x 7 x 326 6 × 10 − 4 ± 2 × 10 − 4 - - 4.67 ± 0.38 0.91 ± 0.06 0.17 ± 0.04 0.003 ± 9 × 10 − 7 0.19 ± 0.05 0.20 ± 0.05 0.14 ± 0.01 - Multiplicative 41 x 45 x 372 1.03 ± 1.02 - - 3.81 ± 0.65 1.0 ± 0.0 0.16 ± 0.02 0.003 ± 9 × 10 − 7 0.01 ± 6 × 10 − 4 0.01 ± 0.0002 - 0.05 ± 0.86 10 lift std. lift - bending2 cycling lying sitting bending1 standing walking - - - - - - - - - - - 5.87 1.0 lift std. lift 0.94 hold pass pickup shoot 0.0 2.82 0.33 1.78 0.33 - - - - lift std. lift - moving in an elevator walking (parking lot) walking (treadmill 4km/h flat) walking (treadmill 4km/h in 15 deg inclined) standing still in elevator walking (treadmill 8kn/h) exercising on stepper 3.28 0.57 5.24 1.0 5.24 1.0 3.93 0.71 0.66 0.0 0.66 0.0 * Activity dataset pattern example T rigen (MSR) additive Basketball dataset pattern example T rigen (LSL) multiplicative Sports dataset pattern example lift std. lift * - * This table only contains a subset of the outcomes relevant to this pattern Mean RSS (sensor 1-2) Mean RSS (sensor 2-3) V ariance RSS (sensor 2-3) Accelerometer (X-axis) Accelerometer (Y -axis) Accelerometer (Z-axis) Gyroscope R measurement T orso Accelerometer (X-axis) T orso Gyroscope (Y -axis) Left Arm Gyroscope (Y -axis) T orso Gyroscope (Z-axis) dribble -T rimax additive Time Time Time Time Time Time T ime Time Time Time Time V alue V alue V alue Figure 3: P atterns and their corresponding discriminativ e p o wer on outcomes of in terest. F or each pattern, eac h line represents how one of the v ariables in the pattern v aries across time, with the x-axis representing the passage of time and the y-axis the measurement. The pattern example of the activity dataset w as extracted b y T riGen (MSR) with the additive approach. The pattern example of the Basketball dataset w as extracted by T riGen (LSL) using the m ultiplicative approac h. Finally , the pattern example for the sp orts dataset was extracted by δ -T rimax using the additive approac h. V ariable description: Activit y dataset [28]: – Mean RSS (sensor 1-2) - mean received signal strength (RSS) b etw een sensors 1 and 2; – Mean RSS (sensor 2-3) - mean received signal strength (RSS) b etw een sensors 2 and 3; – V ariance RSS (sensor 2-3) - v ariance received signal strength (RSS) b etw een sensors 2 and 3. – R(m/ s 2 ) - gyroscop e measurement. Bask etball dataset [6]: – Accelerometer (X-axis/Y-axis/Z-axis) - accelerometer measurement for specified axis; – Gyroscop e R measurement - gyroscope measurement. Sp orts dataset [7]: – T orso Accelerometer (X-axis) - torso accelerometer measurement for the x-axis; – T orso Gyroscop e (Y-axis), T orso Gyroscope (Z-axis) - torso gyroscop es measurements for the y and x-axis; – Left Arm Gyroscop e (Y-axis) - left arm gyroscop e measurements for the y-axis. 5 Conclusion This work prop osed a no vel approac h for extracting patterns from tensor data, ensuring guaran tees of pattern quality , statistical significance, and discriminative p o wer. Firstly , we pro vided an in- depth discussion on the challenges faced b y different greedy-based approac hes and ho w to tac kle them. Secondly , we pro vided sound statistical reasoning on how to parameterize threshold-based greedy approaches to accommo date the prop osed mo dified ob jectiv e functions. Finally , we show ed the effectiv eness of our metho dology b y testing it in the context of three case studies. Pattern solutions extracted by the mo dified versions of the algorithms had significant impro vemen ts in pattern discriminative p ower , pattern statistic al signific anc e , and in some cases, higher pattern 11 qualit y , against the classic quality-driv en solutions pro duced by the original approaches. While our metho dology rev eals notable quan titative and qualitativ e impro vemen ts against the original approaches, w e ackno wledge that the imp ortance of eac h criterion may v ary b etw een do- mains. In this con text, the hyperparametization of the in tegrative scoring function should be con- sidered. F urthermore, the inclusion of domain relev ance as a fourth criteria class can b e pursued to enhance the actionability of patterns without forgoing the established improv emen ts. Finally , as our metho dology can b e straigh tforwardly extended tow ards the discov ery of patterns in other data structures, a broader assessmen t of its impact for knowledge acquisition from tabular and N -wa y tensor (e.g., N > 4) data structures is highlighted for future work. F unding This work was supp orted by F unda¸ c˜ ao para a Ciˆ encia e T ecnologia (FCT) under con tract CEECIND/01399/ 2017/CP1462/CT0015 to RSC, FCT individual PhD grant to LA (2021.07759.BD), INESC-ID plurian ual (UIDB/50021/2020), and further supp orted b y the Asso ciate Lab oratory for Green Chemistry (LAQV), financed by national funds from FCT/MCTES (UIDB/50006/2020 and UIDP/50006/2020). References [1] Hasin Afzal Ahmed, Priyakshi Mahanta, Dhruba Kumar Bhattacharyy a, and Jugal Kumar Kalita. Shifting- and-scaling correlation based biclustering algorithm. IEEE/ACM tr ansactions on c omputational biolo gy and bioinformatics , 11(6):1239–1252, 2014. [2] Leonardo Alexandre, Rafael S Costa, and Rui Henriques. Disa to ol: Discriminative and informative subspace assessment with categorical and numerical outcomes. Plos one , 17(10):e0276253, 2022. [3] Leonardo Alexandre, Rafael S Costa, and Rui Henriques. T risig: Assessing the statistical significance of triclus- ters. arXiv pr eprint arXiv:2306.00643 , 2023. [4] Leonardo Alexandre, Rafael S Costa, L ´ ucio Lara Santos, and Rui Henriques. Mining pre-surgical patterns able to discriminate post-surgical outcomes in the oncological domain. IEEE Journal of Biome dical and He alth Informatics , 25(7):2421–2434, 2021. [5] Jos ´ e L Amaro-Mellado, Laura Melgar-Garc ´ ıa, Cristina Rubio-Escudero, and David Guti´ errez-Avil ´ es. Gener- ating a seismogenic source zone model for the p yrenees: A gis-assisted triclustering approac h. Computers & Ge oscienc es , 150:104736, 2021. [6] Unkno wn Author. Bask etball dataset. UCI Machine Learning Rep ository , 2019. DOI: https://doi.org/10.24432/C56G77. [7] Billur Barshan and Kerem Altun. Daily and Sp orts Activities. UCI Machine Learning Rep ository , 2013. DOI: https://doi.org/10.24432/C5C59F. [8] Anirban Bhar, Martin Haubro ck, Anirban Mukhopadhya y , Ujjwal Maulik, Sanghamitra Bandyopadh ya y , and Edgar Wingender. Co expression and coregulation analysis of time-series gene expression data in estrogen-induced breast cancer cell. Algorithms for mole cular biolo gy , 8:1–11, 2013. [9] Anirban Bhar, Martin Haubro c k, Anirban Mukhopadhy ay , and Edgar Wingender. Multiob jective triclustering of time-series transcriptome data reveals key genes of biological processes. BMC bioinformatics , 16(1):1–19, 2015. [10] Bernard Chen, Christopher Rho des, Alexander Y u, and V alentin V elchev. The computational wine wheel 2.0 and the trimax triclustering in wineinformatics. In A dvanc es in Data Mining. Applic ations and The or etic al Asp e cts: 16th Industrial Confer enc e, ICDM 2016, New Y ork, NY, USA, July 13-17, 2016. Pr o c e e dings 16 , pages 223–238. Springer, 2016. [11] Yizong Cheng and George M Churc h. Biclustering of expression data. In Ismb , volume 8, pages 93–103, 2000. [12] Gene Ontology Consortium et al. Ashburner m, ball ca, blake ja, b otstein d, butler h, c herry jm, da vis ap, dolinski k, dwight ss, et al. 2000. Gene Ontolo gy: to ol for the unific ation of biology. Nat Genet , 25:25–29, 2000. 12 [13] Da vid Guti´ errez-Avil ´ es and Cristi na Rubio-Escudero. Lsl: A new measure to ev aluate triclusters. In 2014 IEEE International Confer enc e on Bioinformatics and Biome dicine (BIBM) , pages 30–37. IEEE, 2014. [14] Da vid Guti´ errez-Avil´ es and Cristina Rubio-Escudero. Msl: a measure to ev aluate three-dimensional patterns in gene expression data. Evolutionary Bioinformatics , 11:EBO–S25822, 2015. [15] Da vid Guti ´ errez-Avil´ es and Cristina Rubio-Escudero. T riq: a comprehensive ev aluation measure for triclustering algorithms. In Hybrid Artificial Intel ligent Systems: 11th International Confer enc e, HAIS 2016, Sevil le, Sp a in, April 18-20, 2016, Pr o c e e dings 11 , pages 673–684. Springer, 2016. [16] Da vid Guti ´ errez-Avil´ es, Cristina Rubio-Escudero, et al. Mining 3d patterns from gene expression temporal data: a new tricluster ev aluation measure. The Scientific World Journal , 2014, 2014. [17] Da vid Guti´ errez-Avil´ es, Cristina Rubio-Escudero, F rancisco Mart ´ ınez- ´ Alv arez, and Jos´ e C Riquelme. T rigen: A genetic algorithm to mine triclusters in temp oral gene expression data. Neuro c omputing , 132:42–53, 2014. [18] Rui Henriques, F rancisco L F erreira, and Sara C Madeira. Bicpams: softw are for biological data analysis with pattern-based biclustering. BMC bioinformatics , 18:1–16, 2017. [19] Rui Henriques and Sara C Madeira. Bsig: ev aluating the statistical significance of biclustering solutions. Data Mining and Know le dge Discovery , 32:124–161, 2018. [20] Rui Henriques and Sara C Madeira. T riclustering algorithms for three-dimensional data analysis: a comprehen- sive survey . ACM Computing Surveys (CSUR) , 51(5):1–43, 2018. [21] Rui Henriques and Sara C Madeira. Flebic: Learning classifiers from high-dimensional biomedical data using discriminative biclusters with non-constant patterns. Pattern Re c o gnition , 115:107900, 2021. [22] T ulik a Kak ati, Hasin A Ahmed, Dhruba K Bhattacharyy a, and Jugal K Kalita. Thd-tricluster: A robust triclustering technique and its application in condition sp ecific change analysis in hiv-1 progression data. Com- putational biolo gy and chemistry , 75:154–167, 2018. [23] Jun wan Liu, Zhoujun Li, Xiaohua Hu, and Yiming Chen. Multi-ob jectiv e evolutionary algorithm for mining 3d clusters in gene-sample-time microarray data. In 2008 IEEE International Conferenc e on Gr anular Computing , pages 442–447. IEEE, 2008. [24] Sara C Madeira and Arlindo L Oliveira. Biclustering algorithms for biological data analysis: a survey . IEEE/ACM tr ansactions on c omputational biolo gy and bioinformatics , 1(1):24–45, 2004. [25] P aul David McNicholas, Thomas Brendan Murphy , and M O’Regan. Standardising the lift of an association rule. Computational Statistics & Data Analysis , 52(10):4712–4721, 2008. [26] Laura Melgar-Garc ´ ıa, Da vid Guti´ errez-Avil ´ es, Cristina Rubio-Escudero, and Alicia T roncoso. Discov ering three- dimensional patterns in real-time from data streams: An online triclustering approach. Information Sciences , 558:174–193, 2021. [27] Anirban Mukhopadhy a y , Ujjwal Maulik, and Sanghamitra Bandyopadh ya y . A survey of multiob jective ev olu- tionary clustering. ACM Computing Surveys (CSUR) , 47(4):1–46, 2015. [28] P alumbo, Filippo and Gallicc hio, Claudio and Pucci, Rita, and Micheli, Alessio. Activity Recognition system based on Multisensor data fusion (AReM). UCI Machine Learning Rep ository , 2016. DOI: https://doi.org/10.24432/C5SS33. [29] Leonardo Pellegrina, Matteo Riondato, and F abio V andin. Spumante: Significan t pattern mining with uncon- ditional testing. In Pr o c ee dings of the 25th ACM SIGKDD International Confer enc e on Know le dge Discovery & Data Mining , pages 1528–1538, 2019. [30] Ma jid Seyfi and Y ue Xu. H-dac: discriminative asso ciative classification in data streams. Soft Computing , 27(2):953–971, 2023. [31] Diogo F Soares, Rui Henriques, Marta Gromicho, Mamede de Carv alho, and Sara C Madeira. Learning prog- nostic mo dels using a mixture of biclustering and triclustering: Predicting the need for non-inv asive ven tilation in amy otrophic lateral sclerosis. Journal of Biomedic al Informatics , 134:104172, 2022. [32] Huijun T ang, Jiangb o Qian, Y angguang Liu, and Xiao-Zhi Gao. Mining statistically significant patterns with high utility . International Journal of Computational Intel ligenc e Systems , 15(1):88, 2022. [33] Juan Xie, Anjun Ma, Anne F ennell, Qin Ma, and Jing Zhao. It is time to apply biclustering: a comprehensive review of biclustering applications in biological and biomedical data. Briefings in bioinformatics , 20(4):1450– 1465, 2019. 13
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment