금속 인공물 아티팩트 감소를 위한 생성 마스크 피라미드 네트워크와 투영‑시노그램 공동 보정
본 논문은 CT/CBCT 영상에서 금속 인공물에 의해 발생하는 아티팩트를 제거하기 위해, 금속 마스크 정보를 다중 스케일로 전달하는 마스크 피라미드 네트워크(MPN)와 투영‑시노그램 이중 보정 구조를 제안한다. GAN 기반의 적대적 학습과 마스크 융합 손실을 도입해 금속 트레이스 영역을 해부학적으로 일관된 내용으로 복원하며, 합성 및 임상 데이터에서 기존 최첨단 방법들을 능가하는 정량·정성 결과를 보인다.
저자: Haofu Liao, Wei-An Lin, Zhimin Huo
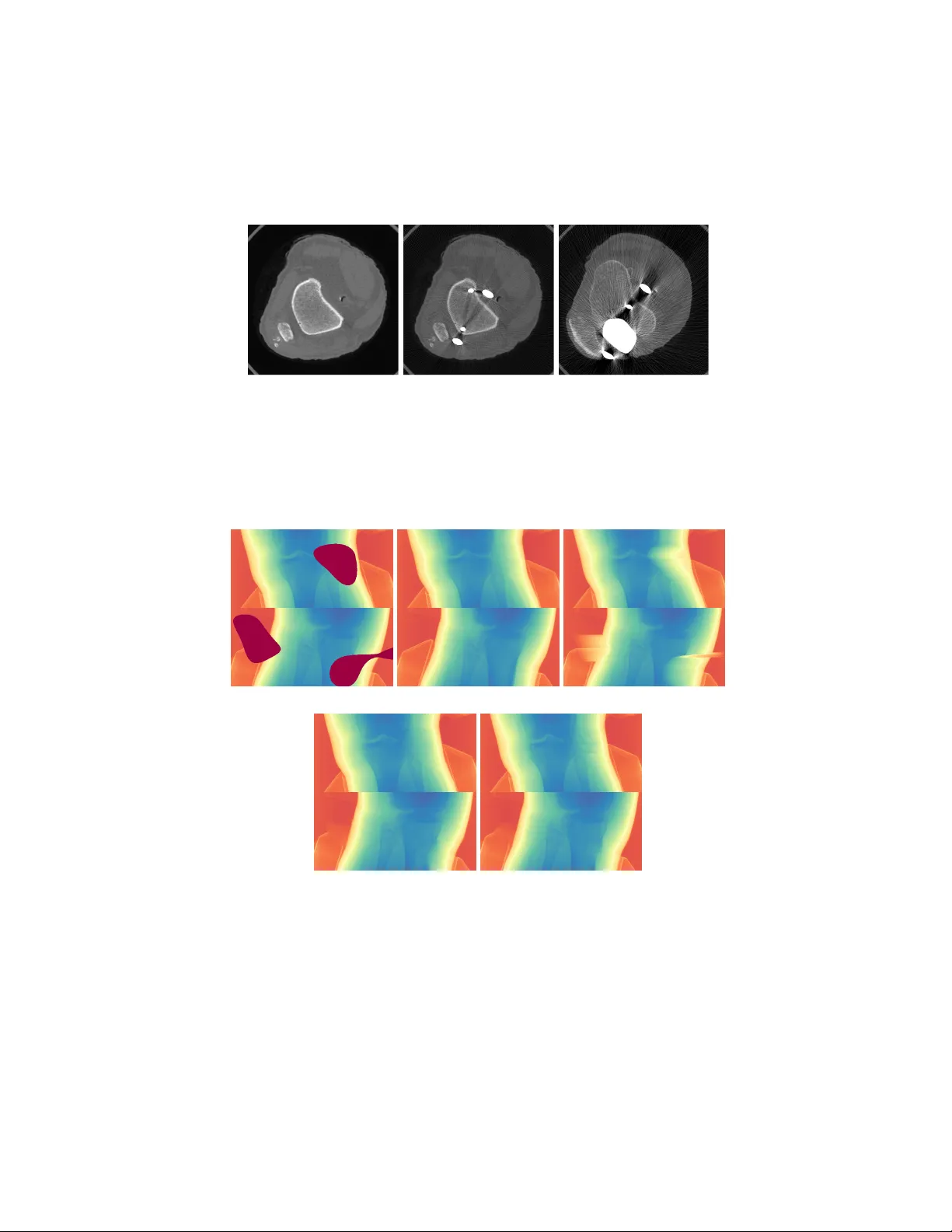
본 논문은 CT·CBCT 영상에서 금속 임플란트가 초래하는 심각한 아티팩트를 감소시키기 위한 새로운 딥러닝 기반 프레임워크를 제시한다. 기존의 금속 아티팩트 감소(MAR) 방법은 금속 트레이스 영역을 선형 보간이나 사전 이미지 기반으로 채우는 NMAR, LI, BHC와 같은 전통적 기법이나, 시노그램을 직접 보정하거나 이미지‑투‑이미지 변환을 이용하는 딥러닝 기법으로 크게 두 갈래로 나뉜다. 전통적 방법은 구조적 정보를 충분히 복원하지 못해 큰 금속이나 복잡한 형태에서 이차 아티팩트를 유발한다. 이미지‑도메인 딥러닝은 합성된 금속 아티팩트 데이터에 크게 의존해 임상 적용 시 일반화가 떨어지는 문제가 있다.
이에 저자들은 두 가지 핵심 아이디어를 결합한 시스템을 설계하였다. 첫 번째는 투영 단계와 시노그램 단계의 두 단계 보정을 순차적으로 수행하는 ‘투영‑시노그램 공동 보정’이다. 투영 이미지에는 금속 마스크가 명확히 존재하므로, 여기서 GAN 기반 이미지‑투‑이미지 변환을 통해 금속 트레이스 내부를 해부학적으로 일관된 내용으로 복원한다. 복원된 투영을 시노그램으로 재구성한 뒤, 동일한 구조의 네트워크가 잔차 맵을 예측해 시노그램 전체를 정교하게 보정한다. 이 과정은 투영과 시노그램 사이의 일관성을 강제함으로써 단일 단계 보정보다 더 높은 품질의 복원을 가능하게 한다.
두 번째 핵심은 ‘마스크 피라미드 네트워크(MPN)’이다. 금속 임플란트는 형태와 크기가 다양하고, 각 투영 각도마다 투영된 형태가 크게 달라진다. 따라서 마스크 정보를 단순히 입력 채널에 결합하는 것만으로는 충분히 전달되지 않는다. MPN은 금속 마스크를 별도의 경로로 받아 각 인코더 블록마다 평균 풀링을 적용해 동일한 해상도·리셉티브 필드를 갖는 마스크 피처를 생성하고, 이를 해당 인코더 블록의 피처와 채널 차원에서 concat한다. 이렇게 하면 마스크 정보가 네트워크 전반에 걸쳐 지속적으로 유지되며, 다양한 스케일의 마스크 형태를 효과적으로 학습한다.
또한, 기존 GAN 손실은 전체 이미지에 대해 L1·L2 손실을 계산해 학습 효율을 저하시키고, 마스크 영역 외부의 손실이 과도하게 지배해 마스크 내부 복원이 조기에 포화되는 문제를 가지고 있다. 이를 해결하기 위해 ‘마스크 융합 손실’이 도입되었다. 내용 손실은 마스크 내부(𝑠)와 외부(1‑𝑠)를 구분해 마스크 내부에서만 L1 차이를 계산하고, 판별기 출력 역시 마스크와 곱해 마스크 외부를 무시한다. 이 설계는 생성기가 마스크 영역에 집중하도록 유도하고, 판별기도 마스크 내부 진위만 판단하도록 하여 적대적 학습의 안정성을 크게 향상시킨다.
실험은 두 종류의 데이터셋을 사용했다. 첫 번째는 하부 사지 전용 CBCT 스캐너에서 획득한 27개의 스캔(총 600개 투영)으로, 금속 마스크와 무작위 블롭 마스크를 합성해 훈련·테스트를 수행했다. 금속 마스크는 실제 임상 기록에서 추출한 3D 금속 임플란트를 전방 투영해 만든 2D 마스크이며, 18,000개의 마스크를 사용했다. 두 번째는 SpineWeb에서 제공한 척추 CT 데이터로, 실제 금속 임플란트를 포함한 이미지와 금속이 없는 이미지를 각각 사용해 훈련하였다. 평가 지표는 RMSE와 SSIM이며, 마스크 크기에 따른 성능 변화를 상세히 분석했다.
정량적 결과는 제안된 투영‑시노그램 공동 보정 모델(PC+SC)이 모든 비교 대상(LI, BHC, NMAR, CNNMAR)보다 우수함을 보여준다. 특히 마스크 크기가 1000픽셀을 초과하는 큰 금속에 대해 CNNMAR의 RMSE가 60~70 HU 수준인 반면, PC+SC는 30~35 HU 수준으로 약 50% 감소하였다. SSIM에서도 0.94 수준으로 가장 높은 점수를 기록했다. 마스크 융합 손실을 적용하지 않은 경우와 비교했을 때, 초기 학습 단계에서의 손실 감소와 최종 성능 향상이 확인되었다.
정성적 결과에서도 차이가 뚜렷했다. 기존 방법들은 금속 트레이스 주변에 남아 있는 스트리크와 어두운 영역을 완전히 제거하지 못하고, 종종 새로운 인공적인 경계나 흐림을 생성한다. 반면 제안 방법은 금속 트레이스 내부를 자연스러운 조직 밀도로 채워 넣으며, 주변 골격과 연부 조직의 경계가 명확히 복원된다. 임상 데이터에서도 동일한 경향이 관찰되었으며, 특히 이미지‑도메인 방식이 합성된 금속 아티팩트에 과도하게 의존해 임상 적용 시 성능이 저하되는 반면, 본 방법은 투영·시노그램 도메인에서 직접 마스크를 마스킹하고 복원하기 때문에 일반화가 뛰어나다는 점이 강조된다.
논문의 한계점으로는 현재 2D 투영·시노그램을 독립적으로 처리하고 있어 3D 연속성(예: 전체 볼륨의 구조적 일관성)을 완전히 활용하지 못한다는 점이 있다. 또한 마스크 피라미드가 평균 풀링 기반이므로 매우 복잡한 마스크 경계에서 세밀한 정보를 손실할 가능성이 있다. 향후 연구에서는 3D U‑Net 기반의 볼륨‑레벨 마스크 피라미드와 Transformer‑형 컨텍스트 어그리게이션을 결합해 전역적인 해부학적 일관성을 강화하고, 다중 모달(예: 원시 X‑ray와 재구성 이미지) 정보를 동시에 활용하는 방안을 모색할 수 있다.
결론적으로, 본 연구는 금속 마스크 정보를 다중 스케일로 전달하고, 투영‑시노그램 이중 보정을 통해 금속 트레이스 영역을 해부학적으로 일관된 내용으로 복원함으로써, 기존 MAR 방법들이 겪는 이차 아티팩트와 일반화 문제를 효과적으로 해결한다는 점에서 CT·CBCT 분야의 임상 적용 가능성을 크게 확대한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기