Generative Mask Pyramid Network for CT/CBCT Metal Artifact Reduction with Joint Projection-Sinogram Correction
A conventional approach to computed tomography (CT) or cone beam CT (CBCT) metal artifact reduction is to replace the X-ray projection data within the metal trace with synthesized data. However, existing projection or sinogram completion methods cann…
Authors: Haofu Liao, Wei-An Lin, Zhimin Huo
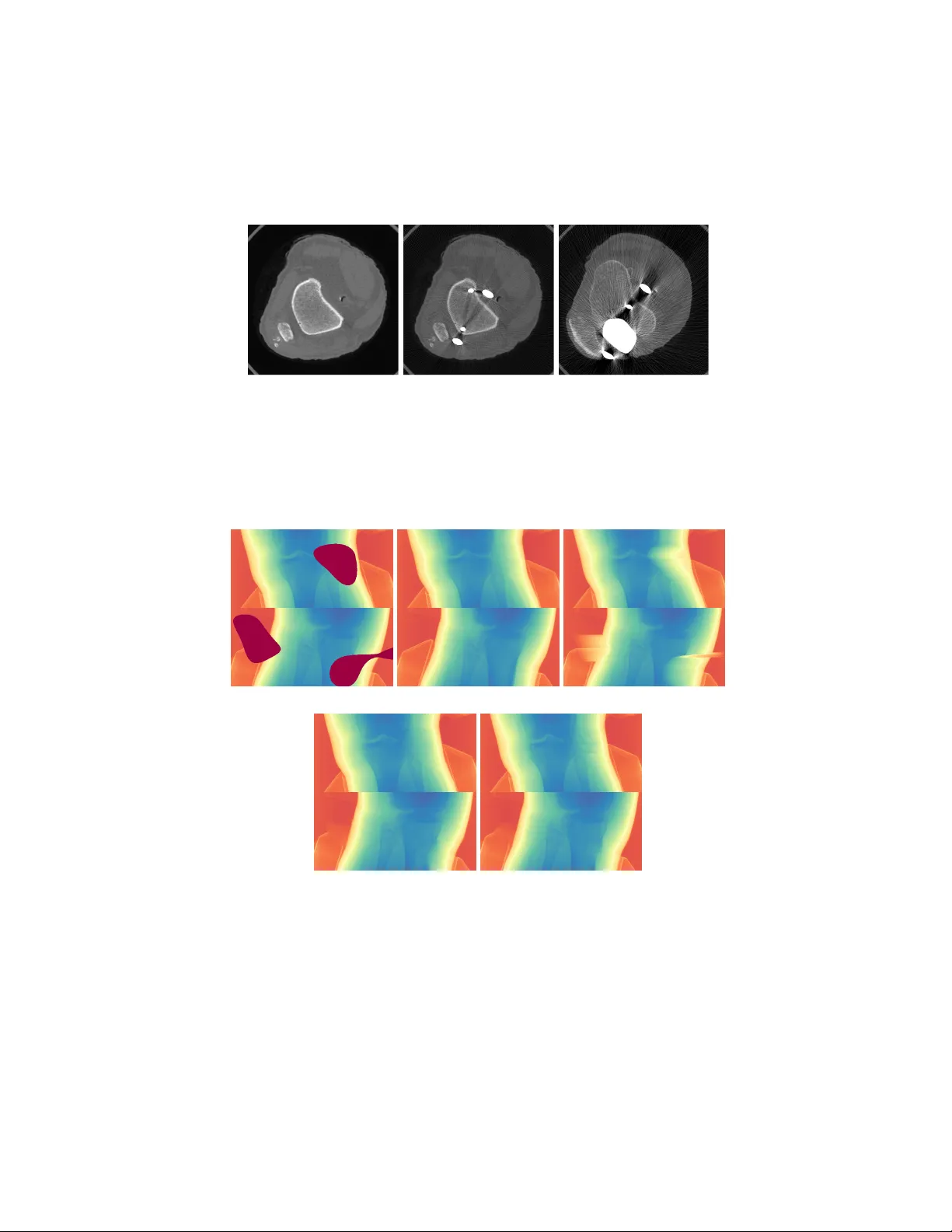
Generativ e Mask Pyramid Net w ork for CT/CBCT Metal Artifact Reduction with Join t Pro jection-Sinogram Correction Haofu Liao 1( ) , W ei-An Lin 2 , Zhimin Huo 4 , Lev on V ogelsang 4 , William J. Sehnert 4 , S. Kevin Zhou 3 , and Jieb o Luo 1 1 Departmen t of Computer Science, Universit y of Ro chester haofu.liao@rochester.edu 2 Departmen t of ECE, Universit y of Maryland, College Park 3 Institute of Computing T echnology , Chinese Academy of Sciences 4 Carestream Health, Inc. Abstract. A conv entional approach to computed tomography (CT) or cone b eam CT (CBCT) metal artifact reduction is to replace the X-ra y pro jection data within the metal trace with synthesized data. How ever, existing pro jection or sinogram completion metho ds cannot alwa ys pro- duce anatomically consisten t information to fill the metal trace, and th us, when the metallic implant is large, significant secondary artifacts are often in tro duced. In this work, w e prop ose to replace metal arti- fact affected regions with anatomically consistent con tent through joint pr oje ction-sino gr am c orre ction as well as adversarial le arning . T o handle the metallic implants of diverse shapes and large sizes, we also prop ose a no vel mask pyr amid network that enforces the mask information across the netw ork’s enco ding lay ers and a mask fusion loss that reduces early saturation of adv ersarial training. Our exp erimental results show that the prop osed pro jection-sinogram correction designs are effective and our metho d reco vers information from the metal traces b etter than the state-of-the-art metho ds. 1 In tro duction Metal artifact is one of the most prominent artifacts which imp ede reliable com- puted tomography (CT) or cone b eam CT (CBCT) image in terpretation. It is commonly addressed in the sino gr am domain where the metal-affected regions in the sinograms are segmen ted and replaced with syn thesized v alues so that metal- free CT images can be ideally reconstructed from the corrected sinograms. Early sinogram domain approac hes fill the metal-affected regions b y interpolation [4] or from prior images [7]. These metho ds can effectively reduce metal artifacts, but secondary artifacts are often introduced due to the loss of structural in- formation in the corrected sinograms. Recen t works prop ose to leverage deep neural net works (DNNs) to directly learn the sinogram correction. Park et al. [8] applies U-Net [11] to correct metal-inserted sinogram, and Gjesteby et al. [1] prop oses to refine NMAR-corrected sinograms [7] using a conv olutional neural 2 H. Liao et al net work (CNN). Although b etter sinogram completions are achiev ed, the results are still sub ject to secondary artifacts due to the imp erfect completion. The developmen t of DNNs in recen t years also enables an image domain ap- proac h that directly reduces metal artifacts or the related artifacts in CT/CBCT images. Specifically , the existing metho ds [2,14,13,9,5] train image-to-image CNNs to transform artifact-affected CT images to artifact-free CT images. Gjesteb y et al. [2] prop oses to include the NMAR-corrected CT as the input with a tw o- stream CNN. Zhang et al. [14] fuses beam hardening corrected and linear in terp o- lated CT images for b etter correction. All the curren t image domain approaches use synthesized data to generate the metal-affected and metal-free image pairs for training. How ev er, the synthesized data ma y not fully simulate the CT imag- ing under the clinical scenario making the image domain approaches less robust to clinical applications. In this work, we prop ose a nov el learning-based sinogram domain approach to metal artifact reduction (MAR). Unlike the existing image domain methods, the proposed method does not require syn thesized metal artifact during training. Instead, w e treat MAR as an image inpainting problem, i.e., we apply random metal traces to mask out artifact-free sinograms, and train a DNN to reco ver the data within the m etal traces. Since metal-affected regions are viewed as missing, factors suc h as X-ra y spectrum and the material of metal implan ts will not affect the generalizability of the prop osed metho d. Unlike the existing learning-based sinogram domain approaches, our metho d delivers high-qualit y sinogram com- pletion with three designs. First , w e propose a tw o-stage pro jection-sinogram 1 completion scheme to achiev e more contextually consistent correction results. Se c ond , we introduce adversarial learning into the pro jection-sinogram comple- tion so that more structural and anatomically plausible information can b e re- co vered from the metal regions. Thir d , to make the learning more robust to the v arious shapes of metallic implants, w e introduce a no vel mask p yramid netw ork (MPN) to distill the geometry information of different scales and a mask fusion loss to p enalize early saturation. Our extensive exp eriments on both syn thetic and clinical datasets demonstrate that the prop osed method is indeed effective and p erform b etter than the state-of-the-art MAR approac hes. 2 Metho dology An ov erview of the prop osed metho d is sho wn in Fig. 1. Our metho d consists of t wo ma jor mo dules: a pro jection completion mo dule (blue) and a sinogram cor- rection mo dule (green). The pro jection completion mo dule is an image-to-image translation mo del enhanced with a nov el mask pyramid netw ork. Given an in- put pro jection image and a pre-segmen ted metal mask, the pro jection completion mo dule generates anatomically plausible and structurally consisten t surrogates within the metal-affected regions. The sinogram correction mo dule predicts a 1 W e denote the X-ra y data that captured at the same view angle as a “pro jection” and a stack of pro jections corresp onding to the same CT slice as a “sinogram”. Generativ e Mask Pyramid Netw ork for CT/CBCT Metal Artifact Reduction 3 Fig. 1: Metho d o verview. Fig. 2: The base framew ork. residual map to refine the pro jection-corrected sinograms. This joint pro jection- sinogram correction approach enforces in ter-pro jection consistency and makes use of the context information b etw een different viewing angles. Note that w e p erform pro jection completion first due to the observ ation that the pro jection images contain better structural information that facilitates the learning of an image inpain ting mo del. Base F ramew ork Inspired b y recent adv ances in deep generativ e models [10,3], w e formulate the pro jection and sinogram correction problems under a generativ e image-to-image translation framework. The structure of the prop osed mo del is illustrated in Fig. 2. It consists of tw o individual net works: a generator G and a discriminator D . The generator G takes a metal-segmented pro jection x as the input and generates a metal-free pro jection G ( x ). The discriminator D is a patc h-based classifier that predicts if the metal-free pro jection y or G ( x ), is real or not. Similar to the P atchGAN [3] design, D is constructed as a CNN without fully-connected lay ers at the end to enable the patch-wise prediction. The detailed structures of G and D are presen ted in the supplemen tary material. G and D are trained adv ersarially with LSGAN [6], i.e., min D L GAN = E y [ k 1 − D ( y ) k 2 ] + E x [ k D ( G ( x )) k 2 ] , (1) min G L GAN = E x [ k 1 − D ( G ( x )) k 2 ] . (2) In addition, we also expect the generator output G ( x ) to be close to its metal- free coun terpart y . Therefore, we add a conten t loss L c to ensure the pixel-wise consistency b et ween G ( x ) and y , min G L c = E x,y [ k G ( x ) − y k 1 ] . (3) Mask Pyramid Netw ork Metallic implants hav e v arious shap es and sizes, suc h as me tallic balls, bars, screws, wires, etc. When X-ra y pro jections are ac- quired at differen t angles, the pro jected implants would exhibit complicated 4 H. Liao et al Fig. 3: Generator and discriminator. Fig. 4: Sinogram correction. geometries. Hence, unlik e typical image inpainting problems, where the shap e of the mask is usually simple and fixed, pro jection completion is more challenging since the netw ork has to learn ho w to fuse such diversified mask information of the metallic implants. Directly using metal-mask ed image as the input requires the metal mask information to b e encoded b y eac h lay er and passed along to the later la yers. F or unseen masks, this enco ding may not work very well and hence the mask information ma y b e lost. T o retain sufficient amoun t of mask information, w e in tro duce a mask p yramid net work (MPN) into the generator to feed the mask information in to each lay er explicitly . The architecture of the generator G with this design is illustrated in Fig. 3. The MPN M tak es a metal mask s as the input, and each blo c k (in yello w) of M is coupled with an enco ding blo ck (in grey) in G . Let l i M denote the i th blo ck of M and l i G denote the i th blo c k of G . When l i M and l i G are coupled, the output of l i M will b e concatenated to the output of l i G . In this w ay , the mask information will then be used by l i +1 G , and a recall of the mask is ac hieved. Eac h block l i M of M is implemented with an av erage p o oling lay er that has the same kernel, stride, and padding size as the conv olutional lay er in l i G . Hence, the metal mask output by l i M not only has the same size as the feature maps from l i G , but also tak es into account the receptive field of the con volution op eration in l i G . Mask F usion Loss In conv entional image-to-image framework, the loss is usu- ally computed on the entire image. On the one hand, this makes the generation less efficien t, as a significan t portion of the generator’s computation will b e spent on reco vering the already kno wn information. On the other hand, this also intro- duces early saturation during adv ersarial training, in which the generator stops impro ving in the mask ed regions, since the generator do es not hav e information ab out the mask. W e address this issue with tw o strategies. First, when comput- ing the loss function, we only consider the conten t within the metal mask. That is, the con tent loss is rewritten as min G L c = E x,y [ k ˆ y − y k 1 ] , (4) where ˆ y = s G ( x ) + ( 1 − s ) x . Second, we mo dulate the output score matrix from the discriminator by the metal mask s so that the discriminator can selectively ignore the unmasked Generativ e Mask Pyramid Netw ork for CT/CBCT Metal Artifact Reduction 5 regions. As sho wn in Fig. 3, we implement this design using another MPN N . But this time, we do not feed the intermediate outputs from N to the coupled blo c ks in D , since the metal mask will, in the end, b e applied to the loss. The adv ersarial part of the mask fusion loss is given as min D L GAN = E y [ k N ( s ) ( 1 − D ( y )) k 2 ] + E x [ k N ( s ) D ( ˆ y ) k 2 ] , (5) min G L GAN = E x [ k N ( s ) ( 1 − D ( ˆ y )) k 2 ] , (6) and the total mask fusion loss can b e written as L = L GAN + λ L c , (7) where λ balances the imp ortance b et ween L GAN and L c . Sinogram Correction with Residual Map Learning Although the pro- p osed pro jection completion framework in previous sections can pro duce an anatomically plausible result, it only considers the contextual information within a pro jection. Observing that a stack of consecutive pro jections form a set of sinograms. W e use a simple yet effective model to enforce the inter-pro jection consistency b y having the completion results lo ok like sinograms. Let x denote a sinogram formed from previous pro jection completion step. A generator, as shown in Fig. 4, predicts a residual map G ( x ) which is then added to x to correct the pro jection completion results. Here, w e use the same generator structure as the one introduced in Fig. 3. F or the ob jective function, we apply the same one as used in Eq. 7, except that w e hav e ˆ y = s ( G ( x ) + x ) + ( 1 − s ) x . 3 Exp erimen tal Ev aluations Implemen tation Details and Baselines W e implement the prop osed mo del using PyT orc h and train the model with the Adam optimization method. F or the h yp er-parameters, w e set learning rate = 5 e − 4 , β 1 = 0 . 5, λ = 100, and batc h size = 16. W e compare our pro jection completion (PC) mo del and joint pro jection- sinogram correction (PC+SC) mo del with the following baseline MAR approac hes: 1) LI, sinogram correction b y linear interpolation [4]; 2) BHC, b eam harden- ing correction for MAR [12]; 3) NMAR, a state-of-the-art MAR mo del [7] that pro duces a prior CT image to correct metal artifacts; and 4) CNNMAR, the state-of-the-art deep learning based metho d [14] that uses a CNN to output the prior image for MAR. Datasets and Simulation Details F or the synthesized dataset, w e use the images collected from a CBCT scanner that is dedicated for lo wer extremities. The size of the CBCT pro jections is 448 × 512 and the pro jections con tain no metal ob jects. W e randomly apply masks to the pro jections to obtain mask ed and unmask ed pro jection pairs. In total, there are 27 CBCT scans, eac h with 6 H. Liao et al (a) RMSE (b) SSIM Fig. 5: Quan titative MAR results of different mo dels with resp ect to differen t mask sizes. F or RMSE/SSIM, the lo wer/higher v alues are b etter. 600 pro jections. Pro jections from 24 of the CBCT scans are used for training, and the rest are held out for testing. Tw o t ypes of ob ject masks are collected for the exp eriments: metal masks and blob masks. F or the metal masks, w e collect 3D binary metal implant volumes from clinical records and forward pro ject them to obtain 2D metal pro jection masks. In total, w e obtain 18,000 pro jection masks from 30 binary metal implan t v olumes. During training, we simulate the metal implants insertion pro cess by randomly placing metal segmentation masks on the metal-free pro jections. F or the blob masks, we adopt the metho d from [10] by dra wing randomly shaped blobs on the image. Results for pro jection and sinogram completion with the metal and blob masks are pro vided in the supplementary material. F or a fair comparison, we adopt the same pro cedures as in [14] to synthesize metal-affected CBCT volumes. W e assume a 120 kVp X-ray source with 2 × 10 7 photons. The distance from the X-ra y source to the rotation center is set to 59.5cm, and 416 pro jection views are uniformly spaced b etw een 0-360 degrees. The size of the reconstructed v olume is 448 × 448 × 448. During simulation, w e set the material to iron for all the metal masks. Note that since the metal masks are from clinical records, the geometries and in tensities of the metal artifacts are extremely div erse, which makes MAR highly challenging. F or the clinical dataset, we use the v ertebrae lo calization and iden tification dataset from Spineweb 2 . W e first define regions with HU v alues greater than 2,500 as metal regions. Then, we select images with the largest-connected metal region greater than 400 pixels as metal-affected images and images with the largest HU v alue smaller than 2,000 as metal-free images. The metal masks for the pro jections and sinograms are obtained by forward pro jecting the metal regions in the CT image domain. The training for this dataset is p erformed on the metal-free images with metal masks obtained from the metal-affected images. Quan titative Comparisons W e use tw o metrics: the rooted mean square error (RMSE) and structural similarit y index (SSIM) for quantitativ e ev aluations. W e conduct a thorough study b y ev aluating RMSE and SSIM for a wide range of 2 spinew eb.digitalimaginggroup.ca Generativ e Mask Pyramid Netw ork for CT/CBCT Metal Artifact Reduction 7 (a) Input: 286/0.73 (b) Ground T ruth (c) LI: 79/0.93 (d) BHC: 226/0.69 (e) NMAR: 57/0.93 (f ) CNNMAR :41/0.92 (g) PC: 30/0.93 (h) PC+SC: 29/0.94 Fig. 6: MAR results on images with syn thesized metal artifacts. Metallic implan ts are replaced with constant v alues (white) after MAR. The rep orted num bers are RMSE (HU) / SSIM. mask sizes. The results are summarized in Fig. 5. W e observe that the prop osed metho d ac hieves superior p erformance ov er the other metho ds. F or example, the RMSE error of the second-b est metho d CNNMAR [14] almost doubles that of the prop osed metho d when the implant size is large. In addition, by further refining in the sinogram domain, improv ed p erformance can b e achiev ed esp ecially in terms of the SSIM metric. F rom Fig. 5, w e also p erceive that metho ds whic h require tissue segmentation (e.g. NMAR and CNNMAR) perform well when the metallic ob ject is smaller than 1000 pixels. How ev er, when the size of the metallic implants b ecomes larger, these metho ds deteriorate significantly due to erroneous segmen tation. The prop osed join t correction approac h, whic h does not rely on tissue segmen tation, exhibits less degradation. Qualitativ e Comparisons Fig. 6 shows MAR results on synthesized metal- affected images. It is clear that the proposed method successfully restores streak- ing artifacts caused b y metallic implan ts. Unlik e other approac hes that generates erroneous surrogates, our metho d fills in contextually consistent v alues through generativ e mo deling and join t correction. F or the results with clinical data (Fig 7), w e also observe that our metho d pro duces qualitatively b etter results. BHC and NMAR cannot totally reduce the metal artifacts. LI and CNNMAR can re- co ver most of the metal-affected regions. How ev er, they also pro duce secondary artifacts. W e notice a p erformance degradation for CNNMAR on the clinical data compare to the synthesized data, which demonstrates that image domain approac hes relying on synthesizing metal artifact hav e worse generalizability . 8 H. Liao et al Fig. 7: MAR results on clinical images. Metallic implants are replaced with con- stan t v alues (white) after MAR. 4 Conclusion W e present a nov el MAR approach based on a generative adversarial framew ork with joint pro jection-sinogram correction and mask pyramid netw ork. F rom the exp erimen tal ev aluations, we sho w that existing MAR metho ds do es not effec- tiv ely reduce metal artifact. By contrast, the proposed approach leverages the extra contextual information from sinogram and achiev es a sup erior performance o ver other MAR metho ds in b oth the synthesized and clinical datasets. Ac knowledgemen t. This w ork was supp orted in part by NSF a w ard #1722847, the Morris K. Udall Center of Excellence in Parkinson’s Disease Research by NIH, and the corp orate sp onsor Carestream. References 1. Gjesteb y , L., Y ang, Q., Xi, Y., Zhou, Y., Zhang, J., W ang, G.: Deep learning metho ds to guide ct image reconstruction and reduce metal artifacts. In: SPIE Medical Imaging (2017) 2. Gjesteb y , L., Y ang, Q., Xi, Y., Claus, B., Jin, Y., De Man, B., W ang, G.: Reduc- ing metal streak artifacts in ct images via deep learning: Pilot results. In: The 14th International Meeting on F ully Three-Dimensional Image Reconstruction in Radiology and Nuclear Medicine. pp. 611–614 (2017) 3. Isola, P ., Zhu, J.Y., Zhou, T., Efros, A.A.: Image-to-image translation with condi- tional adversarial netw orks. In: Pro c. CVPR. pp. 1125–1134 (2017) 4. Kalender, W.A., Heb el, R., Eb ersberger, J.: Reduction of ct artifacts caused by metallic implants. Radiology 164 (2), 576–577 (1987) 5. Liao, H., Huo, Z., Sehnert, W.J., Zhou, S.K., Luo, J.: Adversarial sparse-view cb ct artifact reduction. In: International Conference on Medical Image Computing and Computer-Assisted Interv en tion. pp. 154–162. Springer (2018) 6. Mao, X., Li, Q., Xie, H., Lau, R.Y., W ang, Z., Paul Smolley , S.: Least squares gen- erativ e adversarial netw orks. In: Proceedings of the IEEE In ternational Conference on Computer Vision. pp. 2794–2802 (2017) 7. Mey er, E., Raupach, R., Lell, M., Sc hmidt, B., Kac helrieß, M.: Normalized metal artifact reduction in computed tomography . Medical physics 37 (10) (2010) Generativ e Mask Pyramid Netw ork for CT/CBCT Metal Artifact Reduction 9 8. P ark, H.S., Chung, Y.E., Lee, S.M., Kim, H.P ., Seo, J.K.: Sinogram-consistency learning in ct for metal artifact reduction. arXiv preprint arXiv:1708.00607 (2017) 9. P ark, H.S., Lee, S.M., Kim, H.P ., Seo, J.K.: Machine-learning-based nonlin- ear decomp osition of ct images for metal artifact reduction. arXiv preprint arXiv:1708.00244 (2017) 10. P athak, D., Krahenbuhl, P ., Donahue, J., Darrell, T., Efros, A.A.: Context en- co ders: F eature learning by inpain ting. arXiv preprin t arXiv:1604.07379 (2016) 11. Ronneb erger, O., Fischer, P ., Brox, T.: U-net: Conv olutional netw orks for biomed- ical image segmentation. In: Pro c. MICCAI. pp. 234–241. Springer (2015) 12. V erburg, J.M., Seco, J.: Ct metal artifact reduction metho d correcting for beam hardening and missing pro jections. Physics in Medicine & Biology 57 (9) (2012) 13. Xu, S., Dang, H.: Deep residual learning enabled metal artifact reduction in ct. In: Medical Imaging 2018: Physics of Medical Imaging. vol. 10573, p. 105733O. In ternational So ciety for Optics and Photonics (2018) 14. Zhang, Y., Y u, H.: Conv olutional neural netw ork based metal artifact reduction in x-ra y computed tomograph y . IEEE T ransactions on Medical Imaging (2018) 10 H. Liao et al Supplemen tary Material (a) Generator. (b) Discriminator. Fig. 8: Detailed net work architecture. k: kernel, s: stride, and p: padding sizes. Generativ e Mask Pyramid Netw ork for CT/CBCT Metal Artifact Reduction 11 Fig. 9: Samples from synthesized CBCT image dataset with (a) no, (b) mild, and (c) sev ere artifact. (a) Masked (b) Unmasked (c) LI (d) BF. (e) With MFL. Fig. 10: Visual comparison of models completing blob-masked X-ra y pro jections. (c) LI: linear in terp olation (d) BF: base framework. (e) MFL: base framework with mask fusion loss. A colormap is applied for improv ed details of the b one region. 12 H. Liao et al (a) Masked (b) Unmasked (c) MFL-blob (d) MFL-metal (e) PC Fig. 11: Visual comparison of mo dels completing metal-masked X-ray pro jec- tions. (c) MFL trained using blob-masked pro jections. (d) MFL trained using metal-mask ed pro jections. (e) MFL with mask pyramid netw ork trained using metal-mask ed pro jections. A colormap is applied for improv ed details of the b one region. (a) Masked (b) Unmasked (c) PC (d) PC+SC Fig. 12: Pro jection (top) and sinogram (b ottom) completion results with and without SC. A colormap is applied for impro ved details of the b one region.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment