음성 변환 품질을 예측하는 MOSNet 딥러닝 기반 객관적 평가 모델
본 논문은 Voice Conversion Challenge 2018의 대규모 청취 테스트 데이터를 활용해, 변환 음성의 자연스러움과 화자 유사성을 인간 청취자 평점과 일치하도록 예측하는 딥러닝 모델 MOSNet을 제안한다. CNN, BLSTM, CNN‑BLSTM 세 가지 아키텍처를 비교한 결과, CNN‑BLSTM이 시스템 수준에서 0.957의 높은 선형 상관계수를 달성했으며, 발화 수준에서도 의미 있는 상관성을 보였다. 또한 프레임‑레벨 MSE…
저자: Chen-Chou Lo, Szu-Wei Fu, Wen-Chin Huang
본 논문은 음성 변환(Voice Conversion, VC) 시스템의 품질을 객관적으로 평가하기 위한 딥러닝 기반 모델 MOSNet을 제안한다. 기존에 널리 사용되는 Mel‑cepstral distance(MCD)와 같은 객관적 지표는 인간 청취자가 느끼는 자연스러움과 화자 유사성을 충분히 반영하지 못한다는 한계가 있다. 따라서 저자들은 대규모 청취 테스트 결과를 활용해 인간 평점과 직접 매핑되는 모델을 설계하고, 이를 통해 인간 청취 없이도 VC 시스템을 평가할 수 있는 방안을 모색한다.
데이터는 Voice Conversion Challenge 2018(VCC 2018)에서 제공된 20 580개의 변환 음성 발화와 각각에 대한 4인 청취자 평점(MOS) 및 화자 유사도 점수를 사용한다. 평균 MOS는 약 3.0에 집중돼 있으며, 발화별 표준편차가 1 이상인 경우가 절반에 달해 인간 평점의 변동성이 크다는 점을 확인한다. 이러한 변동성을 고려해 모델 설계와 손실 함수에 프레임‑레벨 MSE를 포함시켜 학습 안정성을 높였다.
모델 구조는 크게 세 가지 아키텍처로 구성된다. 첫 번째는 순수 BLSTM(2층, 128 유닛)으로, Quality‑Net에서 사용된 구조와 동일하다. 두 번째는 12층 CNN으로, 각 레이어는 3×3 필터와 점진적인 채널 증가(16→32→64→128)를 적용하며, 마지막 레이어의 receptive field가 약 25프레임(≈400 ms)이다. 세 번째는 CNN과 BLSTM을 결합한 CNN‑BLSTM으로, CNN이 저수준 스펙트로그램 특징을 추출하고 BLSTM이 시간적 의존성을 모델링한다. 각 아키텍처 뒤에는 2개의 fully‑connected 레이어와 ReLU, dropout(0.3)이 이어지며, 프레임‑레벨 스코어를 출력한다. 최종 발화‑레벨 MOS는 프레임 스코어의 평균으로 계산한다.
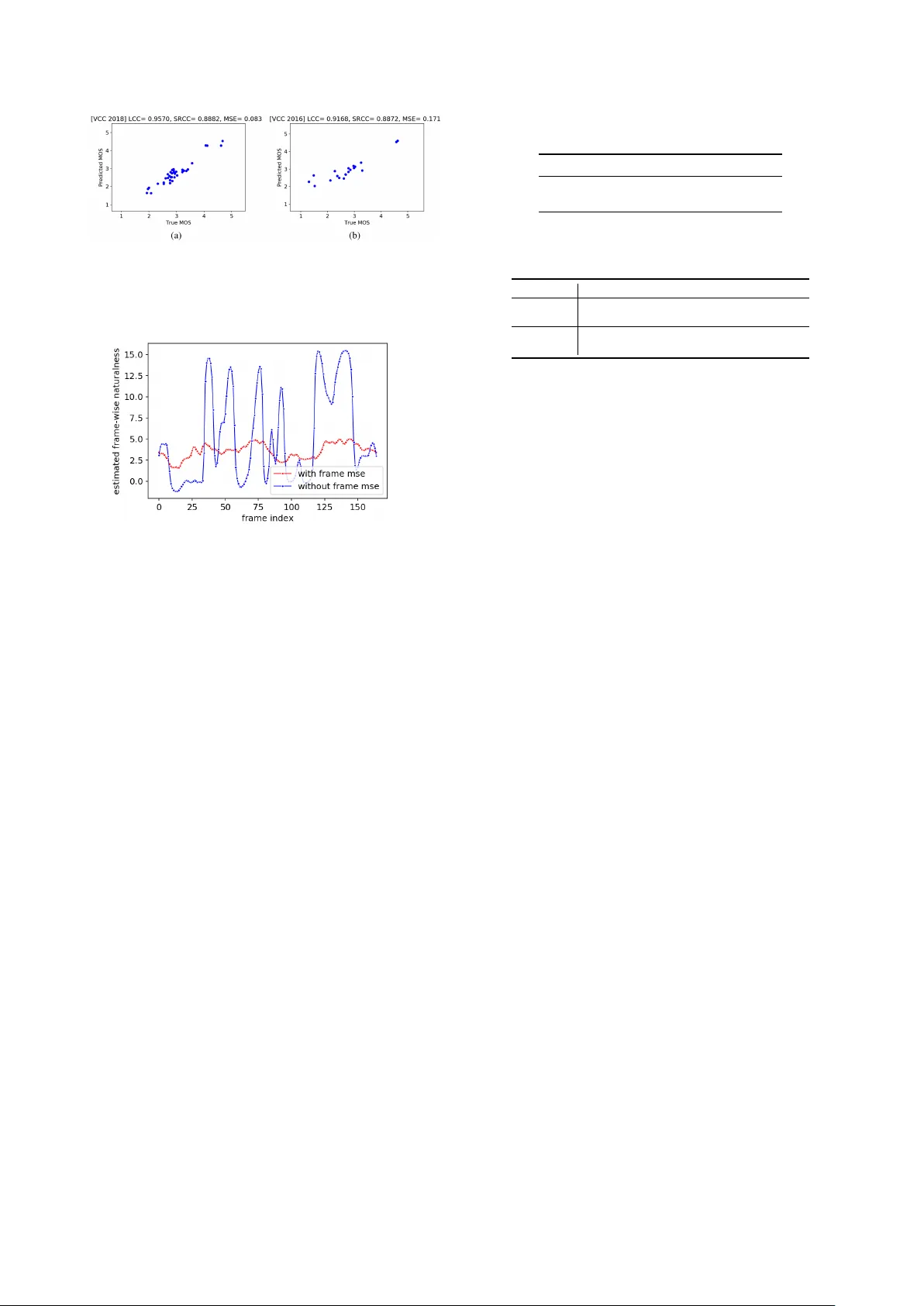
학습은 Adam 옵티마이저(learning rate = 1e‑4)와 early stopping(검증 MSE 기준, patience = 5)으로 진행했으며, 배치 크기(1, 16, 64)에 따라 성능 변화를 관찰했다. BLSTM은 배치가 커질수록 zero‑padding에 의해 성능이 급격히 저하되었고, CNN 기반 모델은 배치 크기에 비교적 강인했다. 가장 좋은 결과는 CNN‑BLSTM(배치 64)에서 얻었으며, 발화‑레벨 LCC = 0.642, SRCC = 0.589, MSE = 0.538, 시스템‑레벨 LCC = 0.957, SRCC = 0.888, MSE = 0.084을 기록했다. 이는 인간 평가와 거의 일치하는 수준이며, 시스템‑레벨에서는 인간 간 상관계수 0.994에 근접한다.
프레임‑레벨 MSE를 손실에 포함시킨 경우와 제외한 경우를 비교한 결과, 포함했을 때 프레임 스코어가 안정적으로 수렴하고 전체 MOS 예측 정확도가 향상됨을 확인했다. 이는 MOS가 발화 전체에 걸쳐 비교적 일정한 특성을 가지므로, 프레임‑레벨 정규화가 모델 학습에 도움이 됨을 의미한다.
또한, VCC 2016 데이터에 대해 사전 학습된 MOSNet을 적용했을 때 시스템‑레벨 LCC = 0.917을 달성, 데이터와 시스템이 달라도 일반화 능력이 있음을 보여준다. 화자 유사도 점수 예측을 위한 확장 모델도 초기 실험에서 인간 청취자와의 상관성을 확보했으며, 향후 화자 유사도 자동 평가에 활용 가능성을 시사한다.
결론적으로 MOSNet은 비침입적(non‑intrusive) 방식으로 VC 시스템의 자연스러움과 화자 유사도를 신뢰성 있게 추정할 수 있는 도구이며, 대규모 청취 테스트 비용을 크게 절감할 수 있다. 향후 연구에서는 손실 함수를 개선해 발화‑레벨 예측 범위를 넓히고, 다중 언어·다중 스피커 환경에서의 성능을 검증하는 것이 필요하다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기