심볼릭 악보 멜로디 라인 자동 식별을 위한 CNN 기반 접근법
본 논문은 피아노 롤 형태의 심볼릭 악보를 입력으로, 각 음표가 멜로디 라인에 속할 확률을 추정하는 합성곱 신경망(CNN)을 제안한다. CNN 출력에 통계적 임계값을 적용하고, 그래프 기반 최단 경로 탐색을 통해 단일 멜로디 시퀀스를 추출한다. Mozart, Pop, Web 데이터셋에서 기존 Skyline 및 VOSA 알고리즘보다 높은 F‑measure를 달성하였다.
저자: Federico Simonetta, Carlos Cancino-Chacon, Stavros Ntalampiras
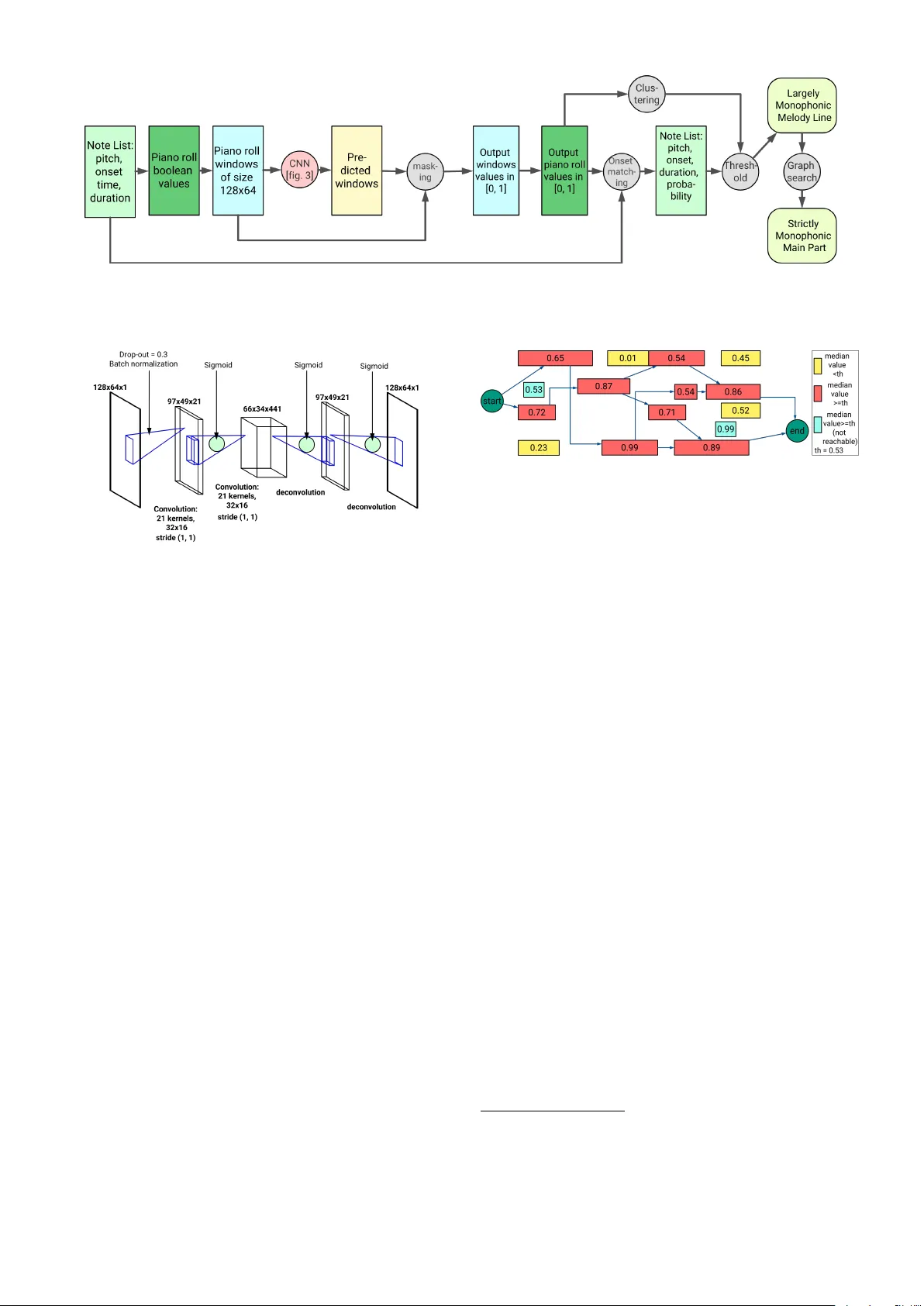
본 논문은 악보만을 가지고 멜로디 라인을 자동으로 식별하는 문제에 접근한다. 서론에서는 서양 고전 음악을 중심으로 멜로디가 가장 의미 있는 음성이라는 음악학적 배경을 제시하고, 청각적 단서가 없는 심볼릭 데이터에서 멜로디를 구분하는 어려움을 강조한다. 관련 연구에서는 음성 분리, 메인 트랙 식별, 오디오 기반 멜로디 추출 등 세 가지 큰 흐름을 소개하고, 특히 심볼릭 악보에서의 음성 분리(VOSA 등)와 그 한계점을 논한다.
베이스라인으로는 가장 높은 음을 선택하는 Skyline 알고리즘과, 음성 분리 후 최고 F‑measure를 갖는 음성을 멜로디로 선택하는 VOSA를 채택한다. 두 방법 모두 규칙 기반이거나 복잡한 연결 가중치를 필요로 한다.
제안 방법은 크게 세 단계로 구성된다. 첫째, 피아노 롤을 8픽셀/박자 해상도로 변환하고 64픽셀(8박자) 길이의 윈도우를 50 % 겹쳐 슬라이딩한다. 둘째, 2개의 합성곱 층(각 21개의 32 × 16 커널)으로 이루어진 FC‑CNN을 통해 각 픽셀에 멜로디 확률을 부여한다. 학습은 MSE 손실, AdaDelta 옵티마이저, 드롭아웃·L1 정규화·배치 정규화를 적용해 20 epoch 조기 종료한다. 데이터 증강으로는 멜로디를 2옥타브 하향·1옥타브 상승 변조한 복제본을 추가한다.
둘째 단계에서는 각 음표의 확률을 중앙값으로 요약하고, 곡 전체 확률 분포에 대해 계층적 단일 연결 클러스터링을 수행한다. 두 클러스터 중 낮은 클러스터의 최대값을 임계값으로 설정해 멜로디 후보 음표를 선정한다.
셋째 단계에서는 후보 음표들을 노드로 하는 DAG를 구축한다. 시작·종료 가상 노드를 추가하고, 시간·피치·길이 제약을 만족하는 경우에만 에지를 만든다. 에지 가중치는 음표 확률의 음수이며, Bellman‑Ford 알고리즘을 이용해 시작 노드에서 종료 노드까지의 최단 경로를 찾는다. 이 경로가 최종 멜로디 라인이 된다. 이 과정을 “CNN‑Mono”라 부르고, 임계값만 적용한 “CNN”은 다중 음을 허용한다.
실험에서는 세 데이터셋을 사용한다. Mozart(38곡)와 Pop(83곡)은 학습·검증·테스트에 모두 활용했으며, Web(169곡)은 오직 테스트용으로 사용했다. 평가 지표는 정밀도·재현율·F‑measure이며, 10‑fold 교차 검증을 통해 모델의 일반화 성능을 확인했다. Mozart 데이터셋에서는 CNN‑Mono가 Skyline·VOSA 모두보다 유의미하게 높은 F‑measure를 기록했고, Pop 데이터셋에서는 Skyline과 차이가 없었지만 VOSA보다 우수했다. Web 데이터셋에서도 CNN‑Mono가 일관적으로 가장 높은 점수를 얻었다. 통계적 검증으로 Wilcoxon 부호 순위 검정을 사용했으며, 대부분의 경우 제안 모델이 기존 방법보다 유의미하게 우수함을 확인했다.
논문의 주요 기여는 (1) 피아노 롤 기반 멜로디 확률 추정을 위한 CNN 설계, (2) 곡별 확률 분포에 적응하는 클러스터링 기반 임계값 설정, (3) 확률 기반 그래프 탐색을 통한 단일 멜로디 라인 추출이다. 한계점으로는 복잡한 다성부 현대 음악에서 음표 간 상호작용을 충분히 모델링하지 못하고, 그래프 구축 비용이 악보 길이에 비례해 증가한다는 점을 들 수 있다. 향후 연구에서는 어텐션 메커니즘을 도입해 장기 의존성을 강화하고, 실시간 적용을 위한 경량화 및 다성부 멜로디 동시 식별 방법을 탐구할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기