A Convolutional Approach to Melody Line Identification in Symbolic Scores
In many musical traditions, the melody line is of primary significance in a piece. Human listeners can readily distinguish melodies from accompaniment; however, making this distinction given only the written score -- i.e. without listening to the mus…
Authors: Federico Simonetta, Carlos Cancino-Chacon, Stavros Ntalampiras
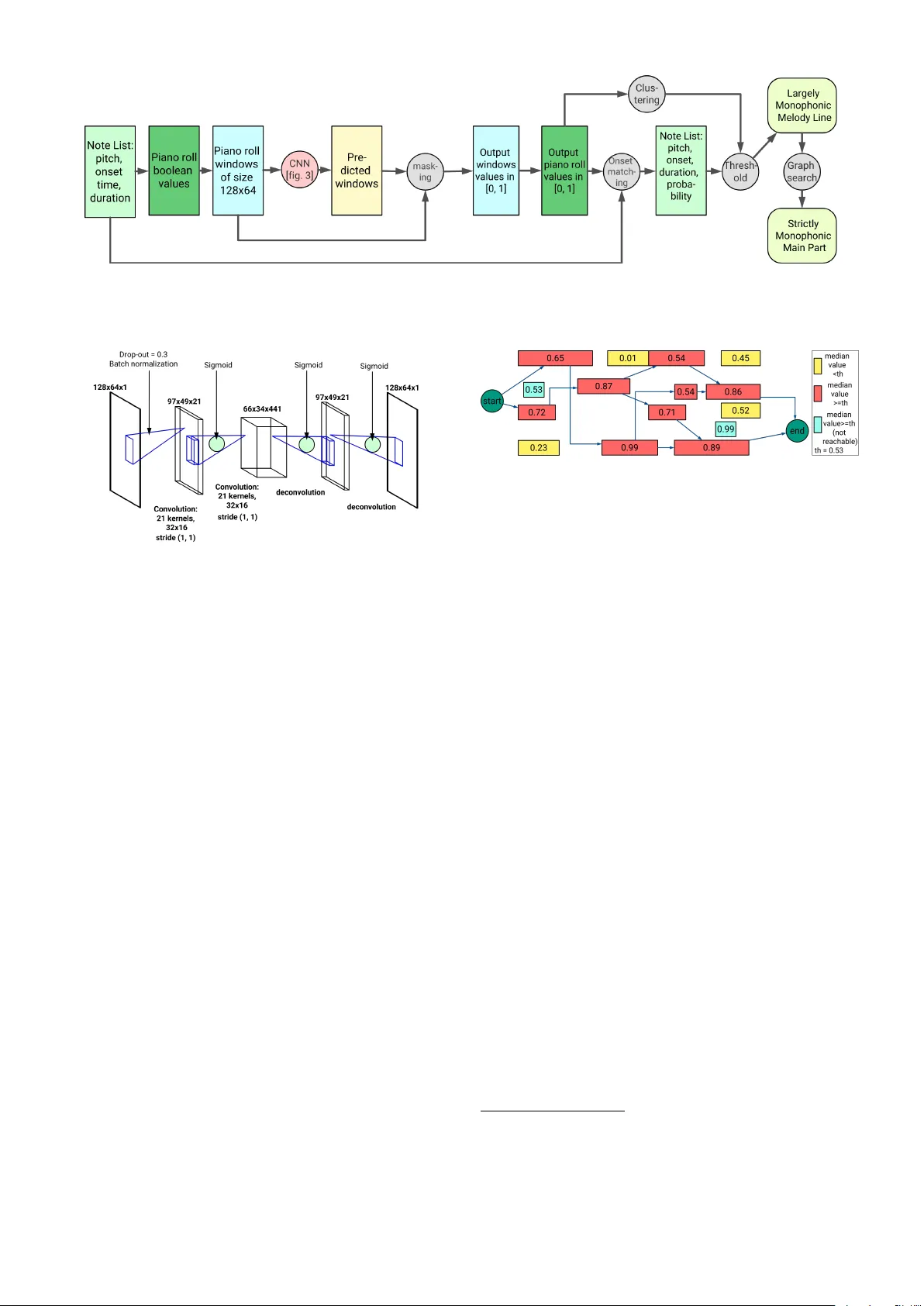
A CONV OLUTION AL APPR O A CH T O MELOD Y LINE IDENTIFICA TION IN SYMBOLIC SCORES F ederico Simonetta 1 Carlos Cancino-Chacón 2 Sta vros Ntalampiras 1 Gerhard Widmer 3 , 2 1 Music Informatics Laboratory , Dept. of Computer Science, Uni versity of Milano, Italy 2 Austrian Research Institute for Artificial Intelligence, V ienna, Austria 3 Dept. of Computational Perception, Johannes Kepler Uni versity Linz, Austria federico.simonetta@unimi.it, carlos.cancino@ofai.at ABSTRA CT In many musical traditions, the melody line is of primary significance in a piece. Human listeners can readily dis- tinguish melodies from accompaniment; ho wever , making this distinction giv en only the written score – i.e. with- out listening to the music performed – can be a difficult task. Solving this task is of great importance for both Mu- sic Information Retrie v al and musicological applications. In this paper , we propose an automated approach to identi- fying the most salient melody line in a symbolic score. The backbone of the method consists of a con v olutional neural network (CNN) estimating the probability that each note in the score (more precisely: each pix el in a piano roll encod- ing of the score) belongs to the melody line. W e train and ev aluate the method on various datasets, using manual an- notations where a v ailable and solo instrument parts where not. W e also propose a method to inspect the CNN and to analyze the influence e xerted by notes on the prediction of other notes; this method can be applied whene ver the output of a neural network has the same size as the input. 1. INTR ODUCTION Many musical traditions make use of melody- accompaniment structures. Generally , the melody line carries the most significant meaning, while the accompaniment provides harmonic and rhythmic support. In W estern art music – which, unlike music in some other traditions, is typically notated – special attention is paid to the construction of melodies during composition. Ideally , melodies in W estern art music styles should in- volv e an intervallic structure that is dependent on the spe- cific tonal hierarchy defined by the piece [24, 26]. Mu- sicians typically accentuate melody lines during perfor- mance as a way of clarifying the piece structure for lis- c Federico Simonetta, Carlos Cancino-Chacón, Stavros Ntalampiras, Gerhard Widmer . Licensed under a Creative Commons At- tribution 4.0 International License (CC BY 4.0). Attribution: Federico Simonetta, Carlos Cancino-Chacón, Stavros Ntalampiras, Gerhard Wid- mer . “A Conv olutional Approach to Melody Line Identification in Sym- bolic Scores”, 20th International Society for Music Information Retrie v al Conference, Delft, The Netherlands, 2019. teners: for example, melody lines may be played louder and with more fle xible timing than accompaniment [9, 10]. Most listeners readily distinguish melody lines from accompaniment. In contrast, identifying the melody line through visual inspection of a musical score – without hearing the piece – can be a difficult task, even for trained musicians [3]. In this paper , we propose a con v olutional approach for identifying the melody line of a piece us- ing a piano roll representation of the score. A solution for this task has potential implications for music infor- mation retriev al and musicology [27]. An effecti v e algo- rithm could be applied to music retriev al tasks such as query-by-humming, searching a database of MIDI files for melodies, de veloping performance models that account for melody in predicting musical expression, etc. Our focus is on music of the common practice period that uses melody-dominated homophonic textures (i.e., a sin- gle melody line plus accompaniment lines), rather than equal-voice polyphony (i.e., multiple independent melody lines) or monophony (i.e., unison melody shared by all voices). Howe ver , we provide extensiv e tests of the pro- posed method in styles other than common practice era, such as pop, baroque and contemporary art music. The rest of this paper is structured as follows: In Sec- tion 2, we discuss related work on voice separation and streaming. Section 3 briefly describes the baseline meth- ods that we used for comparison against our model. Sec- tion 4 presents a description of the proposed method. Sec- tion 5 describes the three datasets used in this work. Sec- tion 6 describes the experimental ev aluation of the pro- posed method. Section 7 discusses the results of the exper - imental e v aluation. Finally , Section 8 concludes this paper and proposes some future research directions. A compan- ion website was also created to show additional material for the sake of reproducibility . 1 2. RELA TED WORK 2.1 V oices and Streams Music perception research has in vestigated listeners’ abil- ities to distinguish between voices in homo- and poly- 1 https://limunimi.github.io/ Symbolic- Melody- Identification/ Figure 1 . T op: Excerpt of Mozart’ s Sonata K. 545 (melody highlighted in red). Middle: Piano roll represen- tation of the score (melody is highlighted in red). Bottom: Prediction of the CNN for this excerpt. In this piano roll, the intensity of the color of each pixel represents its prob- ability of belonging to the melody . phonic music, and has shown that the theoretical rules of voice leading are motiv ated by listeners’ abilities to follo w voices [15]. Cambouropoulos [4] proposed three ways of defining musical “voices”: (1) for multi-instrument music, each instrument can be said to constitute a separate voice; this would allow for the possibility of non-monophonic voices in instruments that produce chords; (2) voices can be assigned to melodic streams as they are perceiv ed and segmented by listeners, follo wing cogniti ve grouping prin- ciples; and (3) in monophonic music, the harmonic con- tent of the piece may imply a horizontal organization of polyphonic voices that unfold over time (i.e., implied polyphony), e.g., multiple temporally-overlapping v oices could be assigned to passages of Bach’ s Cello Suites. In this work, we use the second definition, and we define the melody line as the most salient voice. In the music information retriev al literature, three cor- responding tasks hav e been addressed: 1) voice separation from symbolic scores [6, 11, 13, 21]; 2) main track identifi- cation (from MIDI files with multiple tracks) [8, 14, 19, 20]; and 3) main melody identification from audio [1, 2, 25]. The latter is a different problem than that addressed here: it deals with the comple x task of identifying notes from an audio file, b ut can use performance cues (e.g., contrasts in timbre and dynamics, which are not present in MIDI data) to facilitate melody identification. Most relev ant to the current study is the task of voice separation from symbolic scores. Some of the proposed methods are computational implementations that attempt to capture perceptual rules of segmentation [4, 6, 11–13] – in particular those rules codified by Huron [15]. F or a more in-depth discussion on voice separation algorithms from symbolic scores, we refer the reader to [7, 12, 17, 29]. 3. B ASELINE METHODS 3.1 Skyline Algorithm The skyline algorithm is a heuristic that takes the highest note at each point in time [5, 28]. In W estern art music, pop and many folk traditions from around the world, melodies are often carried by the highest v oice. After the submission of this paper , we discovered that a new method was being submitted for this same task [18], confirming the rele v ance of this topic. 3.2 V oSA Proposed by Chew and W u [6], V oSA is a successful voice separation method. In this approach, a piece is split into segments based on voice entry and exit points, so that the number of sounding notes is constant within each segment. The segment with the highest number of sounding notes defines the number of voices in the piece. Notes are then connected into voices using connection weights, equal to the absolute size of the interv al between one note and the next. Like most v oice separation methods, V oSA was de- signed to work with polyphonic rather than homophonic music. In spite of its apparent simplicity , V oSA has been fa vorably compared against more sophisticated computa- tional models of voice separation [12, 13, 21]. 4. METHOD 4.1 Music Score Modeling Using CNNs A schematic representation of our method is given in Fig- ure 2. The backbone of the method consists of a fully con- volutional neural netw ork (shown in Figure 3), which takes as input segments of a music score, represented as a pi- ano roll, and estimates the probability that each note in the score (more precisely: each pixel in the piano roll encod- ing) belongs to the melody line. A piano roll can be described as a 2D representation of a musical score; the x-axis indicates score time and the y-axis indicates pitch. The piano rolls used in this study are constructed with a temporal resolution of 8 pixels/beat (i.e., a pixel represents a 32nd note in 4 4 ). The piano roll of each piece is di vided into overlapping fixed-length win- dows of 64 pixels (i.e., 8 beats). The length of the windo w was determined using hyper-parameter optimization, (see Section 6.2). The overlap between windows is 50% (i.e., 2 beats), and windows shorter than this size are padded with zeros. An output piano roll for each full piece is con- structed by averaging probabilities for the pixels located in ov erlapping windo ws. Afterwards, we apply a mask on the output piano roll by multiplying it by the (binary) input pi- ano roll, so that areas with no notes take values of zero, and non-zero probabilities only remain where there are notes. The probability of each note belonging to the melody is then calculated as the median across the output values of its pixels. In the following discussion, we will use note Figure 2 . The pipeline of the proposed method (see Section 4). Figure 3 . The architecture of the fully con volutional neu- ral network used in the proposed method. The architecture of the network was determined using hyper -parameter op- timization (see Section 6.2 for explanation). pr obability as a shorthand to refer to the probability of a note to belong to the melody . In Figure 1 we sho w an excerpt of Mozart’ s Piano Sonata K. 545 and three v ertically aligned piano rolls cor- responding to the excerpt. The second row of this figure is the input piano roll, while the third row gi ves the ground truth melody line that we aim to identify in the input. The bottom giv es the piano roll that we obtain as output. The output is color -coded with the notes that were identified as melody highlighted in red. A threshold is needed to determine which note probabil- ities should indicate melody notes. Distributions of prob- abilities differ between pieces, so a hard threshold (e.g. 0 . 5 ) would be inappropriate. Instead, we find a threshold for each piece using a statistical analysis of the values of the note probabilities. In the implementation of the pro- posed method we use hierarchical single-linkage cluster- ing [23]: two clusters across the values of note probabil- ities are identified, and a piece-wise threshold is selected as the lar gest v alue of the lo west cluster . W e then compare each note probability to this threshold and either retain the note as melody or filter it out as accompaniment. This pro- duces largely (b ut not entirely) monophonic melody out- put – in some cases, multiple simultaneous notes pass the threshold. A graph-based method, e xplained next, was thus implemented to select a strictly monophonic melody line from this output. Figure 4 . Example of graph built with Algorithm 1. Red notes are notes over threshold, yellow notes are under threshold, while blue notes are over threshold but are not reached by any path. The green circles are the starting and ending nodes. Numbers indicate note probabilities, which are computed as the median of their pixels. 4.2 Graph Search Having identified notes that pass the threshold as defined abov e, we have to select a sequence of these notes that maximizes the probability of the sequence being mono- phonic. This is achie ved using a graph-based approach. Algorithm 1 is used to build a directed acyclic graph (or digraph, see Figure 4). Such a graph consists of a set of nodes and a set of directed edges. Each of these edges specifies a connection from a node to another . In the graph defined by Algorithm 1, each note that passes the threshold is represented by a node, and the pitch, onset and duration information of this note are used to determine to which nodes is the note connected (in order to guarantee a strictly monophonic sequence). Note probabilities are used to de- termine the strength of the connection between nodes (sim- ilar to a “distance”; notes with high probabilities are con- sidered “closer”). Additionally , we set a start and end node at the beginning and end of the piece, respectiv ely . W e can then use a single-source shortest path algorithm to find the main melody line as the shortest path from the start to the end nodes. In our current implementation, we use the negati ve note probabilities as connection weights and the Bellman-Ford algorithm 2 to find the shortest path through the graph. 3 2 https://docs.scipy.org/doc/scipy- 1.2.1/ reference/generated/scipy.sparse.csgraph. bellman_ford.html 3 Depending on the choice of the connection weights, other shortest path algorithms (e.g., topological sorting, Dijkstra’ s, etc.) are possible. Algorithm 1 Melo-digraph building L ← list of notes α ← starting node (end time = 0 ) ω ← ending node (onset = ∞ , probability = − 0 . 5 ) Push α to the beginning of L Push ω to the end of L for note in L do L 0 ← notes with onset ≥ end time of note L 0 ← notes with onset = minimum onset in L 0 for note 0 in L 0 do if probability of note 0 ≥ threshold then p = probability of note 0 add an edge ( note, note 0 ) with weight − p end if end f or end f or 4.3 T raining The CNN is trained in a supervised fashion to filter out accompaniment parts. Inputs are provided in the form of piano roll segments and the targets are the corresponding piano rolls with only the melody notes. W e also augmented the training dataset by 50% by creating copies of the orig- inal examples in the dataset with the melody transposed down for 2 octa ves or up for 1 octa ve. Though the stan- dard loss function for binary classification problems like this one is the binary cross entropy , during development of the model, we achiev ed more accurate models by min- imizing mean squared error for the match between output and target piano rolls. The networks were trained using AdaDelta [30] with initial learning rate set to 1 . In or- der to av oid ov erfitting, we use dropout with probability p dropout = 0 . 3 and L 1 -norm weight regularization. Addi- tionally we use batch-normalization [16]. The training is stopped after 20 epochs without improv ement in validation loss [22] . 5. D A T ASETS W e used three dif ferent datasets to ev aluate the perfor- mances of our method. The first dataset (“Mozart”) con- sists of 38 mov ements from (13) Mozart Piano Sonatas, for which the main melody line w as annotated manually by a professional pianist. The second dataset (“Pop”) consists of 83 popular songs (including pop and jazz). W e used the vocal part of these songs as the melody line, and treated them as though they were compressed onto a single track (identifying the main track in multi-track music is a sepa- rate question, see [8, 14, 19, 20]). These datasets were used for training and testing. A third dataset (“W eb”), used only for testing, comprises MIDI files crawled from the web. This dataset includes 169 W estern art music compositions from the late 16th to the early 20th centuries. All of these pieces included a solo instrument (typically v oice, flute, violin or clarinet) and ac- companiment (typically strings or piano). The first and third of these datasets are publicly av ail- able for research purposes in the companion site – see foot- note 1. W e do not have distribution rights for the second dataset, which was professionally curated and annotated, but we pro vide the full list of pieces. 6. EXPERIMENTS 6.1 Evaluation Metrics and Baseline Methods In all experiments, we ev aluated the quality of the predic- tions using the F-measure. W e e xperimented on the lar gely monophonic (which we denote cnn in the follo wing discus- sion) and strictly monophonic (denoted as cnn mono ) v ari- ants of the proposed model described in Sections 4.1 and 4.2, respectively . As a baseline comparison, we used the skyline algorithm and V oSA (both described in Section 3). Since V oSA does not directly output the melody line, we first separate the piece into individual voices (as identified by V oSA), then select the voice with the highest F-measure as the melody . These modifications allowed us to consider the best case scenario of V oSA. 6.2 Network Architecture T o determine the architecture of the network, we used hyper-parameter optimization. 4 The number of conv olu- tional layers, kernel size and number, and window lengths were optimized. This hyper-parameter optimization was done on 100 pieces randomly selected from across the three datasets plus 65 MIDI files collected online using the same criteria as the W eb dataset. T o compare models, we constructed training, v alidation, and test sets from the 100 pieces. A model configuration was selected that performed most successfully on the test set. The selected network ar - chitecture is shown in Figure 3: 2 con volutional layers, each with 21 k ernels of size 32 × 16 (i.e., over tw o and a half octaves in the pitch dimension and 2 beats in the time dimension). 6.3 Evaluation of the Proposed Method T o e valuate the quality of the predictions of the proposed method, we conducted two experiments. In the first ex- periment, we were interested in e v aluating the predictiv e accuracy of the models trained on dif ferent datasets. In the second experiment we tested how well models generalize to different music styles. For the first experiment, we per- formed a 10-fold cross-validation on each of the Mozart and Pop datasets. In each of these cross-v alidations, the dataset w as split into 10 folds. The model was trained on 9 of these folds and tested on the remaining one. W e did this for all possible combinations so that each piece in each dataset appeared in the test set once. For the second ex- periment, we tested models trained on Mozart and models trained on Pop on the W eb dataset. 4 Using the “hyperopt” library in Python ( http://hyperopt. github.io/hyperopt/ ). Preci sion Recall F-me asure Mozar t Crossvalid ation Figure 5 . Cross-validation on Mozart and Pop datasets. W ith the W ilcoxon test applied to F-measure, we found a significant difference between CNN Mono and V oSA and between CNN Mono and CNN , but no significant dif ference was found between CNN Mono and Skyline in the Pop dataset (only in the Mozart dataset). The mean is marked with a white dash. Figure 6 . V alidation on the W eb music dataset. W ith the W ilcoxon test, we found a significant difference between Mono models and Skyline / V oSA , but there was not always a significant difference when comparing non- Mono models and Skyline / V oSA . The mean is marked with a white dash. 7. RESUL TS AND DISCUSSION 7.1 Model Perf ormance The violin plots summarizing the results of these experi- ments are shown in Figures 5 and 6, while detailed plots are av ailable in the companion website (see footnote 1). Our first experiment tested how well models predicted melody lines given training and testing on the same genre of music. W ilcoxon signed-rank tests were run on F- measures to assess potential differences between models. T est results are described in the caption of Figure 5. Over - all, our proposed method that identified strictly mono- phonic melody lines ( cnn mono ) performed better than the other models, but this dif ference was only significant for the Mozart dataset. The Mozart pieces are highly struc- tured and their melody lines tend to occur in the upper- most voice. The Pop dataset, in contrast, contains pieces with variable structure, with longer breaks in the melody (e.g., there is sometimes an interlude in the accompani- ment part). Furthermore, the accompaniment part often ov erlaps in register with the melody line. It seems that without additional timbral information, our model could not sufficiently distinguish between melody and accompa- niment lines when they shared a similar te xture. Our second experiment tested how well trained models generalize to ne w types of data (i.e., W eb dataset). W e hypothesized that models trained on the Mozart dataset would outperform models trained on the Pop dataset, as the Mozart and W eb datasets are more similar in style (though the W eb dataset is more heterogeneous). Ho we ver , no sig- nificant dif ference between models w as found – both mod- els performed well on the W eb dataset. Regarding the less-successful performance of the two baseline methods, the skyline method fails when the melody is not the highest voice; furthermore, this method cannot identify when pauses occur in the solo part. The V oSA method, which was developed for use with poly- phonic music, tends to create too many v oices and sho ws a bias to wards connecting notes separated by smal l intervals – this is not surprising, as polyphonic music tends to assign voices to small pitch ranges. As a result, accompaniment notes are often wrongly included in the melody line that V oSA identifies. 7.2 Saliency Maps T o in vestigate what the CNNs are learning, we propose a method (similar to a sensitivity analysis) that ev aluates the contribution of individual locations of the piano roll to predictions at other locations using saliency maps. 5 The method in v olves testing ho w the probability that a given note belongs to the melody changes (i.e., increases or de- creases) when certain other notes are removed (i.e., by con- verting the pix els belonging to those notes to 0). For example, take a rectangular input windo w I and its prediction P . A new input window I 0 with prediction P 0 is created by con verting the pix els inside a giv en rectangle R to 0. The difference between the original and new pre- dictions is denoted as d ( P , P 0 ) and can be interpreted as the contribution giv en by the notes inside R to the original 5 Kernels, saliency maps and additional material are available on the companion website – see footnote 1. 40 60 80 0 50 100 150 200 40 60 80 0 0.2 0.4 0.6 0.8 1 60 70 80 90 0 500 1000 1500 60 70 80 90 Figure 7 . Liszt’ s Ihr Glocken von Marling (left) and an e xcerpt from Schubert’ s A ve Maria (right). Input piano roll (above), prediction of the CNN (middle). In Liszt, the model fails to identify the main part because the texture is rather different from the most common case and the melody is in the middle voices. In Schubert, instead, the texture changes but the model is not able to identify when the main part starts and stops because the accompaniment plays similar notes. prediction. By testing different input windows across the piano roll, we can see how dif ferent elements of the music contribute to the predictions that are obtained for individ- ual notes. If we are interested in a particular note n , we can com- pute d ( P , P 0 ) specifically for the pixels belonging to n . For our analysis, for certain notes of interest, we define 5 randomly-positioned rectangles R and calculate d ( P , P 0 ) . This difference is summed to the pixels of the notes in- side each rectangle R . This procedure is repeated N times (where N is a trade-off between computational com- plexity and resolution of the saliency map; in our case N = 30000 ), and we select only the iterations in which the pixels of note n are not conv erted to 0. Each pixel is then normalized by the number of times it was conv erted to 0. As difference we use d ( P , P 0 ) = P i = n end i = n start P [ i ] − P 0 [ i ] Ar ea ( n start , n end ) (1) where n start and n end identify the region occupied by the note n . In general, n start and n end indicate two opposite corners of any rectangle. W ith this difference function, gi ven a rectangle R , if d ( P , P 0 ) > 0 , then P > P 0 in average across n and, thus, removing the notes inside R decreases the prediction v al- ues of n ; conv ersely , if d ( P, P 0 ) < 0 , then P < P 0 and removing the notes inside R increases the prediction. For example, in the bottom piano roll in Figure 8, the blue high-pitched notes occurring around beats 20 and 35 hav e non-positi ve saliency values. Because they are higher pitched, these notes contribute negati vely to the melody note highlighted with a green box, making it unlikely for this note to be identified as melody . In the companion web- site, we show the saliency of other regions highlighting that the prediction of some notes is influenced positively by some regions and negati vely by others and that the CNN exploits the regular patterns in the accompaniment to iden- tify the melody notes. Overall, our model incorporates features of both the skyline algorithm and V oSA. Like the skyline algorithm it focuses on the highest notes of the piece; on the other hand, by allowing for dif ferent probabilities like V oSA, it is more successful at drawing coherent melody lines. Un- like V oSA, ho wev er , our model does not incorporate ex- plicit perceptual constraints. 8. CONCLUSIONS W e implemented and analyzed a novel method to identify the melody line in a symbolic music score. Some of the functions of our model were found to be similar to func- tions of the skyline algorithm and V oSA (in particular , fo- cusing on the upper -most pitch, and defining a melody line as finding the sequence of notes that minimizes the connec- tion cost). Howe ver , our method does not tak e into account the long-term sequential nature of music; it can compute windows in any order . While such a property might have some practical benefits, it also makes the network unable to generalize to di verse textures, leading to poor results when musical texture is v aried (e.g., Figure 7). The next step for this line of research would be to de- velop a model that can take into account a larger temporal context. A promising approach would be to incorporate attention mechanisms into the network. Figure 8 . Input piano roll with ground truth in white (top), prediction of the CNN (middle) and proposed saliency computed with respect to the green rectangle (bottom). 9. A CKNO WLEDGEMENTS This research has recei ved funding from the European Re- search Council (ERC) under the European Union’ s Hori- zon 2020 research and innov ation programme under grant agreement No. 670035 (project “Con Espressione"). W e gratefully acknowledge the support of NVIDIA Corpora- tion with the donation of the Titan V GPU used for this research. W e thank Elaine Chew for sharing the code for V oSA. W e thank Laura Bishop for proofreading an earlier version of this manuscript. 10. REFERENCES [1] Rachel M. Bittner, Justin Salamon, Slim Essid, and Juan P ablo Bello. Melody Extraction by Contour Clas- sification. In Pr oceedings of the 16th International So- ciety for Music Information Retrieval Confer ence (IS- MIR 2015) , Malaga, Spain, 2015. [2] Juan J. Bosch, Rachel M. Bittner, Justin Salamon, and Emilia Gómez. A Comparison of Melody Extraction Methods Based on Source-Filter Modelling. In Pr o- ceedings of the 17th International Society for Music Information Retrie val Confer ence (ISMIR 2016) , Ne w Y ork, New Y ork, USA, 2016. [3] W arren Brodsky , A vishai Henik, Bat-She va Rubin- stein, and Moshe Zorman. Auditory imagery from mu- sical notation in expert musicians. P er ception & Psy- chophysics , 65(4):602–6012, 2003. [4] Emilios Cambouropoulos. V oice and Stream: A Per - ceptual and Computational Modeling of V oice Separa- tion. Music P er ception , 26(1):75–94, 2008. [5] W ei Chai and Barry V ercoe. Melody retrie v al on the web. In Martin G. Kienzle and Prashant J. Shenoy , editors, Multimedia Computing and Networking 2002 . SPIE, dec 2001. [6] Elaine Chew and Xiaodan W u. Separating voices in polyphonic music: A contig mapping approach. In Uffe Kock Wiil, editor, Computer Music Modeling and Retrieval , pages 1–20, Berlin, Heidelberg, 2005. Springer Berlin Heidelberg. [7] Reinier de V alk and T illman W eyde. Deep Neu- ral Networks with V oice Entry Estimation Heuristics for V oice Separation in Symbolic Music Representa- tions. In Pr oceedings of the 19th International Soci- ety for Music Information Retrieval Conference (IS- MIR 2018) , pages 281–288, Paris, France, 2018. [8] Anders Friberg and Sven Ahlbäck. Recognition of the main melody in a polyphonic symbolic score using per- ceptual kno wledge. Journal of New Music Resear ch , 38(2):155–169, 2009. [9] W erner Goebl. Melody lead in piano performance: Ex- pressiv e device or artifact? The Journal of the Acousti- cal Society of America , 110(1):563–572, 2001. [10] W erner Goebl. Geformte Zeit in der Musik. In W Kautek, R Neck, and H Schmidinger , editors, Zeit in den W issenschaften , volume 19, pages 179–199. Böh- lau V erlag, W ien, Köln, W eimar, 2016. [11] Patrick Gray and Razvan C. Bunescu. A neural greedy model for voice separation in symbolic music. In Michael I. Mandel, Johanna Dev aney , Douglas T urn- bull, and George Tzanetakis, editors, Pr oceedings of the 17th International Society for Music Information Retrieval Confer ence, ISMIR 2016, New Y ork City , United States, August 7-11, 2016 , pages 782–788, 2016. [12] Nicolas Guiomard-Kagan, Mathieu Giraud, Richard Groult, and Florence Levé. Comparing V oice and Stream Segmentation Algorithms. In Pr oceedings of the 16th International Society for Music Information Retrieval Confer ence (ISMIR 2015) , Malaga, Spain, 2015. [13] Nicolas Guiomard-Kagan, Mathieu Giraud, Richard Groult, and Florence Levé. Improving V oice Separa- tion by Better Connecting Contigs. In Michael I. Man- del, Johanna Dev aney , Douglas T urnbull, and Geor ge Tzanetakis, editors, Pr oceedings of the 17th Interna- tional Society for Music Information Retrieval Confer- ence, ISMIR 2016, New Y ork City , United States, Au- gust 7-11, 2016 , pages 164–170, 2016. [14] Zhi-gang Huang, Chang-le Zhou, and Min-juan Jiang. Melodic Track Extraction for MIDI. Journal of Xiamen University (Natural Science) , 1, 2010. [15] David Huron. T one and V oice: A Deriv ation of the Rules of V oice-Leading from Perceptual Principles. Music P er ception , 19(1):1–64, 2001. [16] Sergey Iof fe and Christian Szegedy . Batch normaliza- tion: Accelerating deep network training by reducing internal cov ariate shift, 2015. [17] Cihan Isikhan and Giyasettin Ozcan. A Survey of Melody Extraction T echniques for Music Information Retriev al. In Proceedings of the F ourth Conference on Inter disciplinary Musicology (CIM08) , Thessaloniki, Greece, 2008. [18] Zheng Jiang and Roger B. Dannenberg. Melody Iden- tification in Standard MIDI Files. In Pr oceedings of the 16th Sound & Music Computing Confer ence , pages 65–71, 2019. [19] Jiangtao Li, Xiaohong Y ang, and Qingcai Chen. MIDI melody extraction based on improved neural network. In Pr oceedings of the 2009 International Conference on Machine Learning and Cybernetics , v olume 2 of Machine Learning and Cybernetics, 2009 Interna- tional Confer ence on , pages 1133–1138. IEEE, July 2009. [20] Raúl Martín, Ramón A. Mollineda, and V icente Gar- cía. Melodic track identification in MIDI files con- sidering the imbalanced context. In Helder Araújo, Ana Maria Mendonça, Armando J. Pinho, and M. Inés T orres, editors, P attern Recognition and Image Anal- ysis, 4th Iberian Confer ence, IbPRIA 2009, Póvoa de V arzim, P ortugal, June 10-12, 2009, Pr oceedings , v ol- ume 5524 LNCS of Lectur e Notes in Computer Sci- ence , pages 489–496. Springer , 2009. [21] Andrew McLeod and Mark Steedman. HMM-Based V oice Separation of MIDI Performance. Journal of New Music Resear ch , 45(1):17–26, 2016. [22] N. Morgan and H. Bourlard. Generalization and pa- rameter estimation in feedforward nets: Some exper- iments. In D.S. T ouretzk y , editor , Advances in Neu- ral Information Pr ocessing Systems 2 , pages 630–637. Morgan-Kaufmann, 1990. [23] Daniel Müllner . fastcluster: Fast hierarchical, agglom- erativ e clustering routines for R and Python. J ournal of Statistical Softwar e , 53(9):1–18, 2013. [24] W alter Piston. Counterpoint . W . W . Norton & Com- pany , 1947. [25] Justin Salamon, Rachel M. Bittner , Jordi Bonada, Juan J. Bosch, Emilia Gómez, and Juan Pablo Bello. An Analysis/Synthesis Framew ork for Automatic F0 Annotation of Multitrack Datasets. In Pr oceedings of the 18th International Society for Music Information Retrieval Conference (ISMIR 2017) , Suzhou, China, 2017. [26] Felix Salzer and Carl Schachter . Counterpoint in Com- position . Columbia University Press, New Y ork, NY , USA, 1989. [27] F . Simonetta, S. Ntalampiras, and F . A v anzini. Multi- modal music information processing and retriev al: Sur- ve y and future challenges. In 2019 International W ork- shop on Multilayer Music Representation and Pr ocess- ing (MMRP) , pages 10–18, Jan 2019. [28] Alexandra L. Uitdenbogerd and Justin Zobel. Manipu- lation of music for melody matching. In W olfgang Ef- felsberg and Brian C. Smith, editors, Pr oceedings of the 6th A CM International Confer ence on Multimedia ’98, Bristol, England, September 12-16, 1998. , pages 235–240. A CM, 1998. [29] Frans W iering, Justin de Nooijer, Anja V olk, and Hermi J. M. T abachneck-Schijf. Cognition-based Se g- mentation for Music Information Retriev al Systems. Journal of New Music Resear ch , 38(2):139–154, 2009. [30] Matthew D Zeiler . AdaDelta: An Adaptive Learning Rate Method. arXiv pr eprint arXiv:1212.5701 , 2012.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment