스케일러블 딥러닝 벤치마크 플랫폼 설계와 구현
본 논문은 딥러닝 모델, 프레임워크, 하드웨어의 다양성과 급격한 변화에 대응하기 위해 10가지 설계 목표를 정의하고, 이를 구현한 오픈소스 벤치마크 플랫폼 MLModelScope를 제안한다. 모델 매니페스트 기반의 표준 사양, 프레임워크·하드웨어 독립성, 확장 가능한 분산 실행, 자동화된 분석·보고, 그리고 전·후처리와 실행 추적 기능을 제공한다. 37개 모델을 4대 시스템에서 평가한 사례를 통해 정확도·성능·병목을 종합적으로 분석한다.
저자: Cheng Li, Abdul Dakkak, Jinjun Xiong
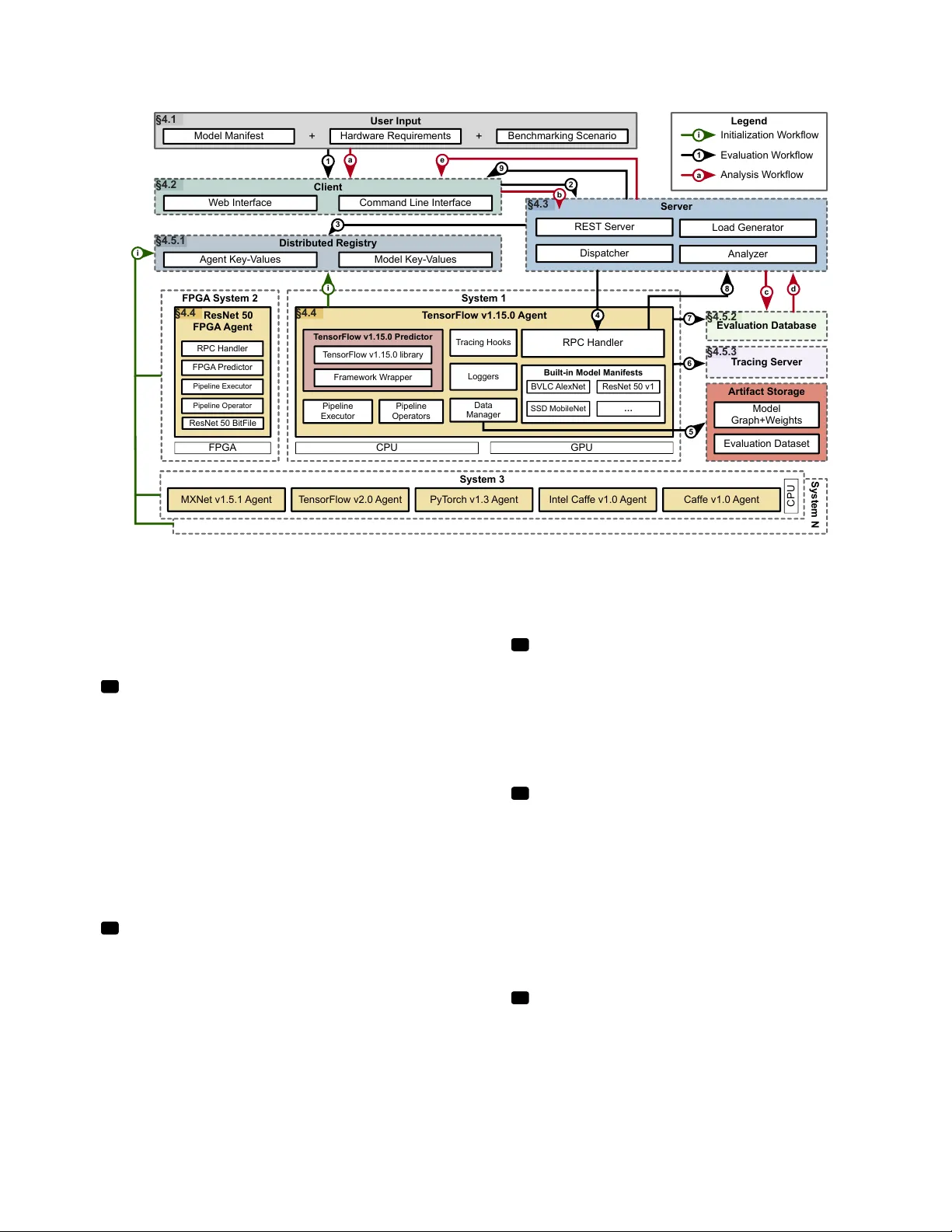
본 논문은 딥러닝 분야에서 모델, 프레임워크, 하드웨어가 급속히 다양화되고 진화함에 따라, 이러한 요소들을 일관되고 재현 가능하게 비교·평가할 수 있는 벤치마크 플랫폼의 부재가 큰 문제점으로 대두되고 있음을 지적한다. 기존의 벤치마크 스위트는 소수의 모델만을 대상으로 하며, 각 모델마다 별도 스크립트를 작성해야 하는 비효율적인 구조를 가지고 있다. 이러한 상황을 해결하고자 저자들은 **10가지 설계 목표(F1–F10)**를 정의한다.
- **F1 재현 가능한 평가**: 모델, 데이터셋, 평가 방법, HW/SW 스택을 모두 명시적으로 기술한다.
- **F2 일관된 평가**: 공통된 실행 파이프라인과 표준 사양을 통해 동일 조건에서 비교한다.
- **F3 프레임워크·하드웨어 독립성**: 다양한 프레임워크(TensorFlow, PyTorch, MXNet 등)와 CPU, GPU, FPGA 등 하드웨어를 지원한다.
- **F4 확장 가능한 평가**: 분산 에이전트와 중앙 스케줄러를 이용해 다수의 평가를 병렬로 수행한다.
- **F5 아티팩트 버전 관리**: 프레임워크, 모델, 데이터셋의 버전을 추적한다.
- **F6 효율적인 워크플로우**: 데이터 로딩·전처리·후처리를 최적화해 평가 속도를 높인다.
- **F7 벤치마크 시나리오**: 온라인, 오프라인, 인터랙티브 등 실제 서비스 상황을 모델링한다.
- **F8 자동 분석·보고**: 원시 결과를 정량적 메트릭과 시각화 보고서로 자동 변환한다.
- **F9 모델 실행 검사**: 전·후 스택 트레이싱을 통해 병목을 식별한다.
- **F10 다양한 사용자 인터페이스**: CLI와 웹 UI를 제공한다.
이러한 목표를 구현하기 위해 제안된 플랫폼은 **MLModelScope**이다. 핵심 설계는 **모델 매니페스트**(YAML/JSON 형식)로, 모델 그래프 경로, 가중치 체크섬, 입력·출력 스키마, 프레임워크 버전 제약, 전·후처리 파이프라인 등을 포함한다. 매니페스트는 **Specification** 단계에서 검증되고, **Provisioning** 단계에서 사용자가 지정한 HW/SW 스택에 맞춰 컨테이너 혹은 가상 환경을 자동으로 구성한다.
플랫폼 아키텍처는 **클라이언트 → 레지스트리 → 스케줄러 → 에이전트**의 흐름을 가진다. 레지스트리는 모델·데이터·아티팩트 메타데이터를 저장하고, 스케줄러는 평가 요청을 큐에 넣어 에이전트에게 할당한다. 에이전트는 프레임워크 래퍼를 로드하고, 매니페스트에 정의된 전처리·모델 실행·후처리 파이프라인을 수행한다. 실행 중에 **Tracing Server**가 HW 레벨(PCIe, 메모리 대역폭), OS 레벨(스케줄링), 프레임워크 레벨(Op 실행 시간) 등을 수집한다.
MLModelScope는 **오픈소스**로 제공되며, 현재 TensorFlow, TensorFlow Lite, TensorRT, PyTorch, MXNet, CNTK, Caffe 등 주요 프레임워크와 ARM, x86, PowerPC 기반 CPU, NVIDIA/AMD GPU, FPGA 등을 지원한다. 300여 개의 사전 구축 모델(ResNet, MobileNet, BERT 등)과 다양한 데이터셋이 포함되어 있어 사용자는 즉시 평가를 시작할 수 있다.
실험에서는 37개의 모델을 4대 시스템(고성능 GPU 서버, ARM 기반 엣지 디바이스, FPGA 보드, 일반 CPU 서버)에서 평가하였다. 결과는 모델 크기와 정확도, 지연, 처리량 사이의 상관관계를 정량화했으며, 프레임워크별 최적화 차이(예: TensorRT가 동일 모델에서 2배 이상의 처리량 향상)를 보여준다. 또한, **Tracing**을 통해 특정 모델이 GPU 메모리 전송에 과도한 시간을 소모하거나, TensorFlow Lite가 일부 연산을 CPU로 오프로드하는 등 병목을 정확히 파악하였다. 이러한 인사이트는 하드웨어 선택, 프레임워크 튜닝, 모델 경량화 전략 수립에 직접 활용될 수 있다.
마지막으로, MLModelScope는 **CLI**와 **Web UI**를 제공한다. CLI는 스크립트 기반 대규모 실험에 적합하고, Web UI는 매니페스트 작성, 평가 진행 상황 모니터링, 결과 시각화 등을 직관적으로 수행한다. 이를 통해 연구자와 엔지니어 모두가 손쉽게 최신 DL 혁신을 평가·비교하고, 병목을 찾아 최적화할 수 있는 통합 환경을 제공한다.
결론적으로, 본 논문은 딥러닝 벤치마크의 핵심 문제를 체계적으로 정의하고, 이를 해결하기 위한 설계 원칙과 구현체를 제시함으로써, 빠르게 변화하는 DL 생태계에서 신뢰성 있는 성능 평가와 효율적인 최적화를 가능하게 하는 중요한 기반을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기