다중 구조 변곡과 고변동성을 가진 시계열 예측을 위한 딥러닝 모델 성능 비교
본 연구는 인도 주요 10개 기업 주가 데이터를 대상으로 MLP, CNN, GRU‑RNN, LSTM‑RNN 네 가지 딥러닝 모델의 단일‑스텝(1일) 및 다중‑스텝(여러 일) 예측 성능을 비교한다. 구조적 변곡점과 높은 변동성을 가진 비정상 시계열에 대한 모델의 적합성을 평가하기 위해 10회 독립 실행을 수행하고, 예측 기간이 길어질수록 성능이 저하되는 경향을 확인하였다.
저자: Rohit Kaushik, Shikhar Jain, Siddhant Jain
1. 서론에서는 주식 시장의 복잡성과 비정상 시계열 특성(구조적 변곡점, 고변동성) 때문에 전통적인 통계 모델만으로는 정확한 예측이 어려움을 강조하고, 딥러닝이 원시 시계열 데이터를 직접 학습함으로써 이러한 문제를 해결할 가능성을 제시한다. 연구 목표는 (1) 인도 주요 10개 주식에 대한 딥러닝 모델의 단일‑스텝 및 다중‑스텝 예측 성능을 비교하고, (2) 예측 기간이 길어질수록 성능 저하 양상을 분석하는 것이다.
2. 관련 연구에서는 기존의 다중‑스텝 예측 방법, ARIMA와 딥러닝의 하이브리드 접근, 그리고 CNN이 급격한 변동을 포착하는 데 유리하다는 선행 결과를 정리한다. 특히 LSTM이 ARIMA 대비 85% 오류 감소를 보였다는 연구를 인용하며, 본 연구가 이러한 문헌을 확장한다는 점을 강조한다.
3. 데이터는 2002‑01‑01부터 2019‑01‑15까지 17년간의 일일 종가를 포함하며, 10개 기업(AXISBANK, INFY, HCL TECH 등)의 시계열을 동일한 기간으로 수집했다. 각 시계열은 비정상성을 확인하기 위해 ADF 테스트와 구조적 변곡점 탐지를 수행했으며, 변동성 지표(일일 수익률 표준편차)가 높은 구간이 다수 존재함을 보고한다.
4. 모델 구성은 다음과 같다.
- MLP: 입력 윈도우(w) 크기와 동일한 차원의 입력 레이어, 2개의 은닉 레이어(활성화 함수 ReLU), 출력 레이어(선형).
- CNN: 1차원 컨볼루션 레이어(다중 커널 크기), 배치 정규화, MaxPooling, Fully‑Connected 레이어.
- GRU‑RNN: 2층 GRU, 각 셀에 64개의 유닛, Dropout 적용.
- LSTM‑RNN: 2층 LSTM, 동일한 유닛 수와 Dropout.
학습은 100 에포크, 배치 크기 32, 학습률 0.001의 Adam 옵티마이저를 사용했으며, 조기 종료(Early Stopping) 기준은 검증 손실이 10 에포크 연속 개선되지 않을 경우였다.
5. 실험 설계는 두 가지 예측 시나리오로 나뉜다.
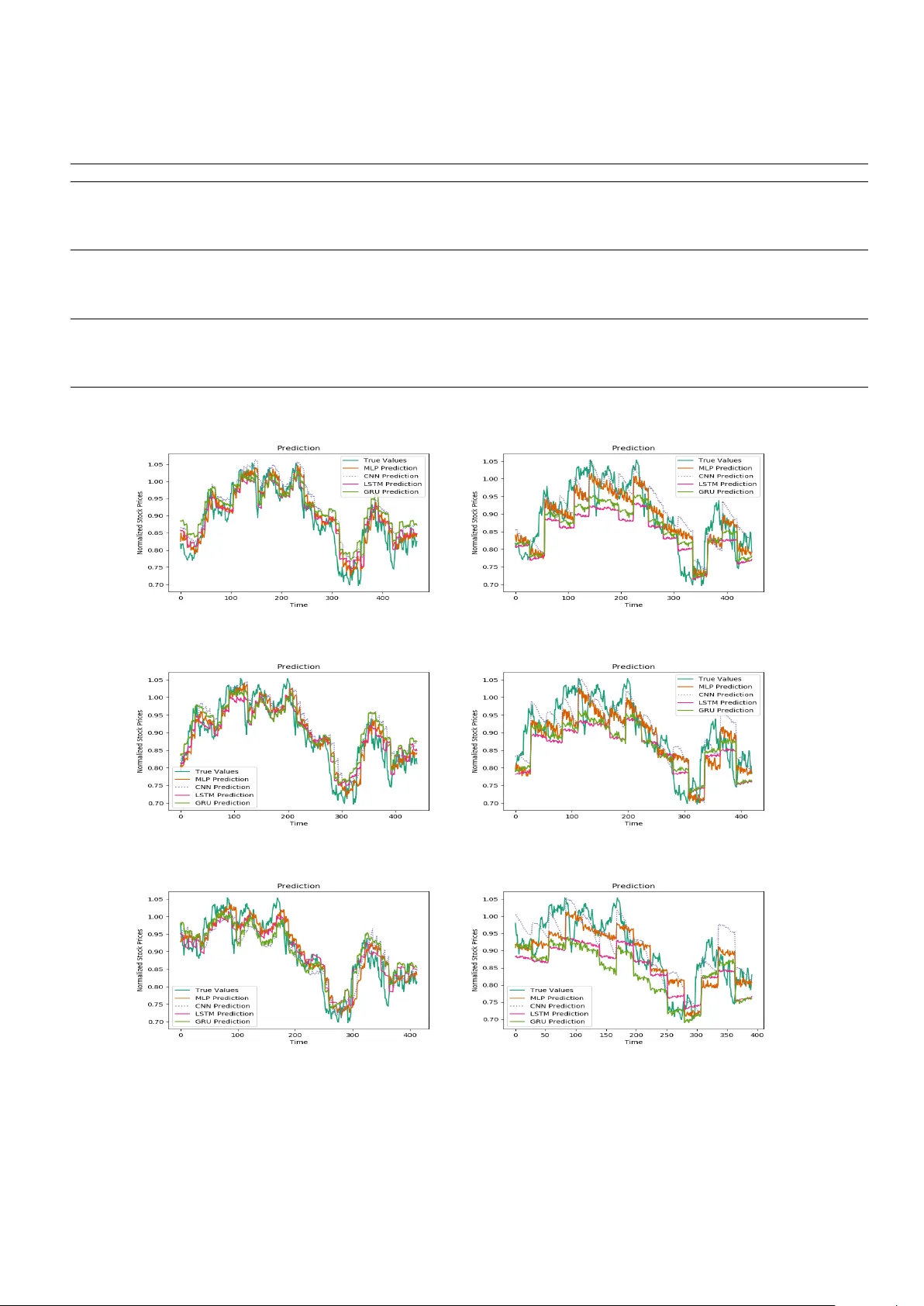
- 단일‑스텝: 입력 윈도우 w=30일(예시)으로부터 다음 날(31일째) 종가를 예측.
- 다중‑스텝: 동일 입력 윈도우를 사용해 5일, 10일, 20일, 30일 선행 예측을 수행. 다중‑스텝은 반복 방식과 직접 방식 모두 적용했으며, 결과는 주로 반복 방식에 초점을 맞추었다. 각 모델·시나리오·주식별로 10회 독립 실행을 수행해 평균 RMSE와 표준편차를 산출했다.
6. 결과는 다음과 같다.
- 단일‑스텝에서는 모든 모델이 평균 RMSE 0.012~0.018 수준을 기록했으며, LSTM‑RNN이 가장 낮은 RMSE(0.012)를 보였다.
- 다중‑스텝에서는 예측 기간이 증가함에 따라 오차가 급격히 상승했으며, 5일 예측 시 LSTM‑RNN이 RMSE 0.025, GRU‑RNN이 0.028, CNN이 0.032, MLP가 0.035 수준을 기록했다. 20일 이상에서는 모든 모델이 RMSE 0.06 이상으로 악화되었고, 특히 CNN은 변동성이 큰 구간에서 과대 예측(overshoot) 현상이 두드러졌다.
- 표준편차 분석에서 CNN과 MLP는 데이터 샘플링에 민감해 변동성이 큰 시점에서 결과 변동성이 크다는 점을 확인했다.
- 구조적 변곡점(예: 2008년 금융 위기, 2014년 인도 정책 변화) 전후 구간에서는 모든 모델이 일시적으로 오차가 상승했으며, LSTM‑RNN이 가장 빠르게 회복했다.
7. 논의에서는 (1) LSTM‑RNN이 장기 의존성을 학습하는 데 가장 효과적이며, (2) CNN은 지역 패턴 탐지에 강하지만 전역적인 시계열 추세를 포착하는 데 한계가 있음을 지적한다. 또한, 다중‑스텝 예측에서 반복 방식이 누적 오류 문제로 인해 직접 방식보다 성능이 낮을 수 있음을 언급한다.
8. 결론은 본 연구가 인도 주식 시장이라는 특수한 비정상 시계열에 대한 딥러닝 모델 벤치마크를 제공했으며, 장기 예측 성능을 향상시키기 위해 어텐션 메커니즘, 하이브리드(ARIMA‑LSTM) 모델, 혹은 변동성 조절을 위한 가변 윈도우 기법 등을 제안한다. 향후 연구에서는 더 다양한 금융 지표(거래량, 뉴스 감성)와 멀티모달 데이터를 결합하고, 모델 해석성을 높이기 위한 SHAP/Grad‑CAM 분석을 수행할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기