Performance evaluation of deep neural networks for forecasting time-series with multiple structural breaks and high volatility
The problem of automatic and accurate forecasting of time-series data has always been an interesting challenge for the machine learning and forecasting community. A majority of the real-world time-series problems have non-stationary characteristics t…
Authors: Rohit Kaushik, Shikhar Jain, Siddhant Jain
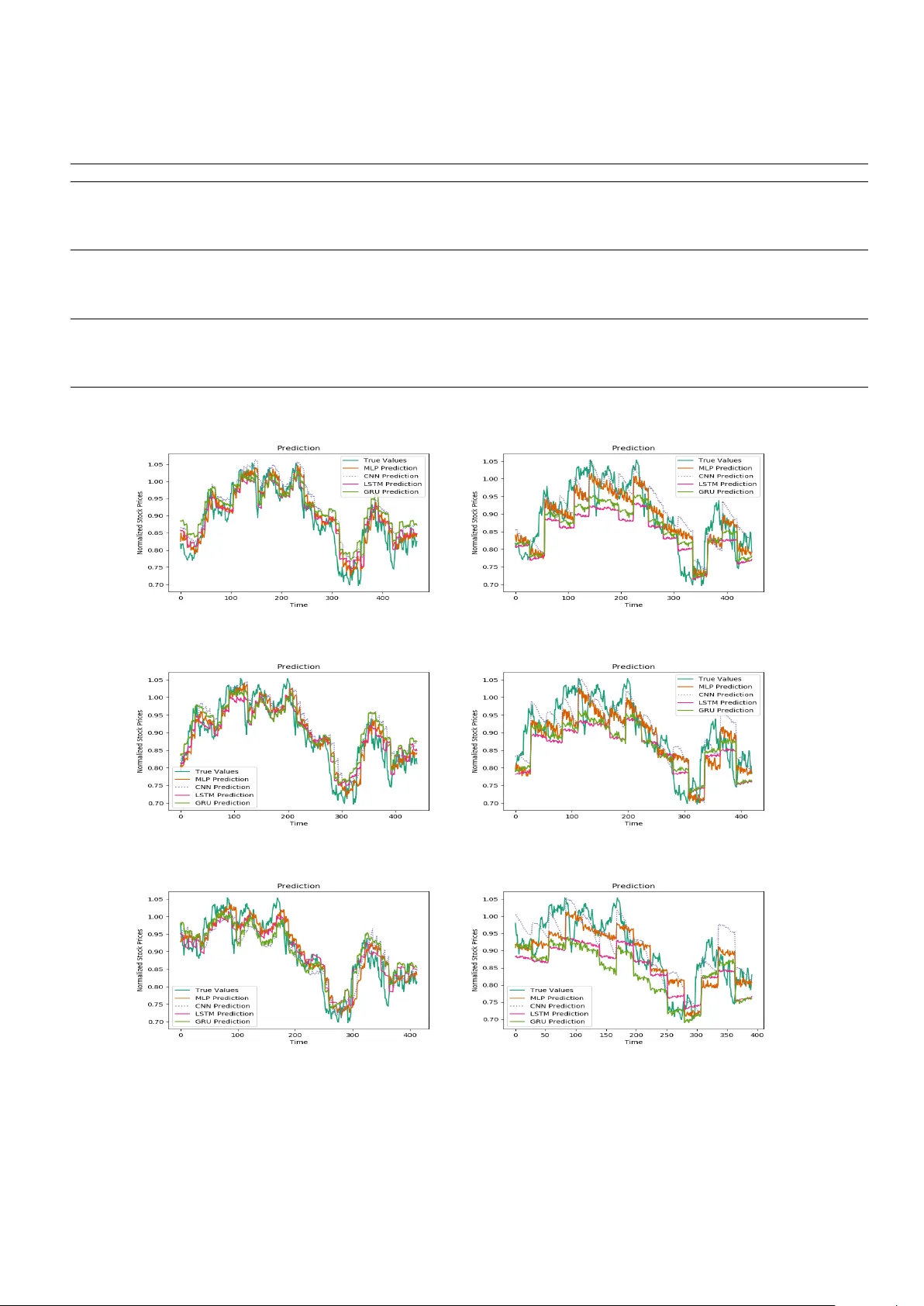
P erformance ev aluation of deep neural net w orks for forecasting time-series with m ultiple structural breaks and high v olatilit y Rohit Kaushik, Shikhar Jain, Siddhan t Jain, Tirthara j Dash Dep artment of Computer Scienc e and Information Systems Birla Institute of T e chnolo gy and Scienc e Pilani K.K. Birla Go a Campus, Zuarinagar, Go a 403726, India Email: { r ohit.koush, jain.shikhar97, jainsiddhant29 } @gmail.c om, dashtirthar aj@acm.or g Abstract The problem of automatic and accurate forecasting of time-series data has alw a ys b een an in teresting c hallenge for the machine learning and forecasting comm unity . A ma jority of the real-w orld time-series problems ha ve non-stationary characteristics that make the understanding of trend and seasonalit y difficult. Our interest in this pap er is to study the applicabilit y of the p opular deep neural netw orks (DNN) as function approximators for non-stationary TSF. W e ev aluate the following DNN mo dels: Multi-la yer Perceptron (MLP), Conv olutional Neural Net work (CNN), and RNN with Long-Short T erm Memory (LSTM-RNN) and RNN with Gated-Recurren t Unit (GRU-RNN). These DNN metho ds hav e b een ev aluated ov er 10 p opular Indian financial sto c ks data. F urther, the p erformance ev aluation of these DNNs has b een carried out in m ultiple independent runs for t wo settings of forecasting: (1) single- step forecasting, and (2) m ulti-step forecasting. These DNN metho ds show con vincing p erformance for single-step forecasting (one-day ahead forecast). F or the m ulti-step forecasting (multiple days ahead forecast), we ha ve ev aluated the metho ds for different forecast perio ds. The p erformance of these metho ds demonstrates that long forecast p eriods hav e an adverse effect on p erformance. 1 In tro duction In recen t years, with the dev elopmen t of countries, the stock mark et is becoming a more and more essential and in tricate part of their economy . One such study can b e found in [ 1 ]. No wada ys, inv estors in vesting in sto cks need to consider a large num ber of factors and ev aluate a considerable amount of risks b efore in vesting in it in an y form [ 2 ]. This issue is because of the c haotic and dynamic nature of the sto c k prices in the presen t times. These inv estors exp ect to mak e decent profits after the in v estments. How ever, analysing factors and risks affecting the sto c k prices and predicting them could b e highly exhaustive. They could require a higher degree of skilled task [ 3 ]. Hence, the prediction of sto ck prices could b e a significant reference for the in vestors and financial pundits for trading and inv esting strategies. With the streaming dev elopments in mac hine learning (ML) to ols and tec hniques, esp ecially deep learn- ing (DL) algorithms along with an adequate increase in the p otential of computational p o wer, predicting sto c k prices hav e b ecome less hectic and do es not require muc h skill on the economic fron ts. These DL to ols and algorithms, suc h as Deep Neural Net w orks (DNNs), w ould learn the trend and factors resp onsible for the fluctuations (like sudden rise or drop) in the prices and accordingly predict v alues with acceptable appro ximations [ 4 ]. F urthermore, the primary adv antage of suc h metho ds is that they ma y b e able to handle the raw time-series suitably and forecast the future raw outputs. These outputs, ho wev er, could b e one or m ultiple: resp ectiv ely , we can call it as ‘single-step’ and ‘m ulti-step’ forecasting. Recen tly , there ha ve b een man y successful attempts to use mac hine learning metho ds for automatic time-series forecasting. Some of these metho ds do incorp orate the information from social media, some w ays deal with a transformed feature space, and some work with v arious economic indicators. One could follo w some recen t w orks that are published under this um brella in [ 5 , 6 , 7 , 8 ]. 1 In this pap er, w e emplo y and explore v arious state-of-the-art deep neural net w ork metho ds to build mo dels predicting sto c k prices. As we wish the mo del to analyse and understand the factors affecting the prices ov er a time p erio d and predict accurately , this problem could also b e treated as a kind of time-series analysis problem, where the goal is not only to predict the sto c k prices but instead sho w some understanding of the effects of volatilit y and structural breaks on the prediction [ 9 , 10 ]. In what follo ws, w e outline our significant ob jectiv es and con tributions to this work. 1.1 Ob jectiv es and contributions of the study Our goal is to study the p erformance of neural machine learning mo dels to w ards forecasting the prices of sto c ks that hav e exhibited a significant degree of volatilit y with numerous structural breaks. Our study is fo cused on the application of deep neural netw orks. T o the b est of our knowledge, less num ber of studies has b een conducted on Indian sto ck mark et data. Therefore our research inv olves implemen tations for Indian sto c k market. This mak es our presen t study a new case study in the field of forecasting in the Indian sto c k market. How ev er, this do es not limit our resulting analysis and conclusion to our datasets only; instead can b e applied to other generic datasets as well. T o analyse the relativ e performances of Deep Neural Net works in Time Series F orecasting, we employ the following neural net work mo dels: 1. Multila yered Netw ork: Multila yer Perceptron (MLP) 2. Spatial Netw orks: Conv olutional Neural Net works (CNN) 3. T emp oral Netw orks: Recurrent Neural Netw orks using: (a) Gated Recurren t Unit (GRU) cells; and (b) Long Short-T erm Memory (LSTM) cells These deep netw orks are ev aluated for t wo different wa ys of time series forecasting viz. single-step ahead sto c k price prediction and m ultiple-step ahead 1 sto c k price prediction. By emplo ying four differen t state- of-the-art deep netw ork mo dels and with ten differen t datasets with sto ck price data from last 17 years, our presen t work serves as a go o d case study on the applicability of deep neural netw orks on Indian sto ck mark et data. 1.2 Organisation of this pap er This pap er is organised as follo ws: Section 1 in tro duced the motiv ation, problem statemen t, and ma jor con tributions of this study . In section 2 , we provide brief details ab out research efforts made by the comm unity in the field of statistics and machine learning for time-series forecasting. Section 3 provides a detailed description of the data and metho dology used by our work. Section 4 describ es the sim ulation setup, summarises the results, and discusses the findings. The pap er is concluded in section 5 . The detailed results and time-series prediction plots for v arious sto cks for both one-step as w ell as m ulti-step forecasting are provided in App endix A . 2 Related W orks A useful review of multi-step ahead forecasting is published in [ 11 ]. These metho ds describ e the differen t us- ages of neural net works. They conducted exp eriments whic h proposed tw o constructiv e algorithms initially dev elop ed to learn long-range dep endencies in time-series, p erform a selective addition of time-dela y ed to recurren t netw orks pro ducing noticeable results on single-step forecasting. These results, together with the fact that longer-range delays embo died in the time-delays should b e allo wed for the system to b et- ter learn the series and when predicting for m ultiple steps and improv ed results on multi-step prediction problems as can b e seen from the exp erimen tal evidence. Statistical mo dels are another class of to ols 1 a windo w of sto ck prices 2 suitable and successful for time-series forecasting. One such model is the Autoregressive in tegrated moving a verage (ARIMA) [ 12 ]. These models ha ve b een quite successful for one-step and sometimes multi-step forecasting. F urther, researc hers hav e explored the idea of hybridising ARIMA and other non-statistical mo dels for forecasting: [ 13 , 14 ]. Most successful h ybrids are the techniques com bining neural net works and statistical mo dels suc h as as [ 13 , 15 , 16 ]. How ev er, comm unities con tinue to explore the comparative domain of statistical mo del v ersus neural netw ork models. One of the latest studies on a similar line is w ork done by Namini and Namini [ 17 ], where the authors explore the applicability of ARIMA and LSTM based RNNs. The authors’ empirical study on this suggested that deep learning-based algorithms such as LSTM outp erform traditional algorithms suc h as the ARIMA mo del. More specifically , the av erage reduction in error rates obtained by LSTM is around 85% when compared to ARIMA, indicating the sup eriorit y of LSTM to ARIMA. Ma jumder and Hussian [ 18 ] hav e used an artificial neural netw ork model with bac k-propagation to build the net w ork for forecasting. They hav e studied the effects of hyperparameters, including activ ation functions. They ha v e critically selected the input v ariables and hav e in tro duced lags b etw een them. They ha ve tried building models with v arious delays ranging from 1 to 5 da y-lags. The input v ariables c hosen for this mo del are the lagged observ ation of the closing prices of the NIFTY Index. The experimental results sho wed that tanh activ ation function p erformed better. How ev er, the v arious day-lags b eing compared pro duced v aried results based on the loss function used. Neera j et al. [ 19 ] hav e used Artificial Neural Netw ork (F eedforward Backpropagation Netw orks) mo del for mo delling BSE Sensex data. After p erforming initial exp erimen ts, a mo del was finalised, whic h had 800 neurons with tan-sigmoid transfer function in the input lay er, three hidden la yers with 600 neurons eac h, and the output lay er with one neuron predicting the sto ck price. They built t wo net w orks. The first used 10-week oscillator and the second one had 5-week v olatility . A 10-week oscillator (momen tum) is an indicator that gives information regarding the future direction of sto ck v alues. When combined with the moving a verages, it is observed that it improv es the p erformance of ANN. They used RMSE(Ro ot Mean Squared Error) to calculate errors. They concluded that the first net work p erformed b etter than the second one for predicting the weekly closing v alues of BSE Sensex. In a recen t study [ 20 ], the authors ha ve used different DL arc hitectures like RNNs, LSTMs, CNNs, and MLPs to generate the netw ork for the first dataset where they used T A T AMOTORS sto ck prices for training and hav e used the trained mo del to test on sto ck prices of Maruti, Axis Bank, and HCL T ech. They also built linear mo dels like ARIMA to compare the nonlinear DNN arc hitectures. They made the netw ork ha ving 200 input neurons and ten output neurons. They chose windo w size as 200 after p erforming error calculations on v arious windo w sizes. They also used this mo del to test on the other tw o sto cks, which were Bank of America (BAC) and Chesap eak e Energy (CHK), to iden tify the typical dynamics b etw een different stock exc hanges. It could b e seen from their exp erimen tal results that the mo dels w ere capable of detecting the patterns existing in b oth the stock markets. Linear models lik e ARIMA w ere not able to identify the underlying dynamics within v arious time series. They concluded that deep arc hitectures (particularly CNNs) performed b etter than the other net works in capturing the abrupt c hanges in the system. Our study is a comprehensive addition to the literature in the sense that this w ork emplo ys four differen t deep mo dels for ten differen t Indian time series data with v arying degrees of v olatility and significan t structural breaks o v er 17 y ears. F urther, it also explores the performances of suc h mo dels with regard to one-step and m ulti-step forecasting. This work could b e considered as a significan t b enchmarking study concerning the Indian sto c k market. 3 Materials and Metho ds 3.1 Data In order to provide generalised inferences and v alue judgements on the p erformance of neural netw orks to wards single-step and m ulti-step time-series forecasting, stock price datasets are quite lucrative as their 3 time-series data t ypically exhibit characteristics lik e non-stationarity , multiple structural breaks, as well as high volatilit y . F urther, instead of using a single sto ck, w e used a div ersified dataset of 10 differen t sto cks in the Indian sto ck market. T able 1 describ es all the ten sto c ks that were used for the study . It should b e noted that the duration or time-frame of the data for each sto c k is the same. F urthermore, w e use the same dataset of 10 sto ck prices for b oth single-step and multi-step forecasting in order to provide b etter con trasts into the p erformance of v arious deep neural netw ork mo dels across b oth the t yp es of prediction. T able 1: Indian sto c k price data: 10 companies. The p erio d is fixed for all the sto c ks: 1st Jan uary 2002 to 15th Jan 2019 (ov er 17 years) Dataset Description A CC American Campus Comm unities, Inc. AXISBANK Axis Bank Ltd BHAR TIAR TL Bharti Airtel Limited CIPLA Cipla Ltd HCL TECH HCL T echnologies Ltd HDF C HDF C Bank Limited INFY Infosys Ltd. JSWSTEEL JSW Steel Limited F ully Paid Ord. Shrs MAR UTI Maruti Suzuki India Ltd UL T A CEMCO UltraT ec h Cemen t Ltd 3.2 Deep Neural Netw orks (DNN) W e formulate the problem in the follo wing w ay . Let x b e a time-series defined as x = ( x 1 , . . . , x w , . . . , x w + p ), where x i represen ts the sto c k price at time-step i , w refers to windo w-size and w test refers to the test p erio d for which forecast is to b e ev aluated. So, a time-s teps ( w + 1 , . . . , w + w test means a w test -p erio d windo w. Corresp ondingly , we will denote neural netw ork predictions for this w + 1 to w + w test time-steps as ( ˆ x w +1 , ˆ x w +2 , . . . , ˆ x w + w test ). F or single-step forecasting, the goal is to predict ˆ x w +1 giv en ( x 1 , x 2 , . . . , x w ). Mathematically , we can express this as: ˆ x w +1 = f (( x 1 , x 2 , . . . , x w ); θ ) (1) where, θ is the learnable mo del parameters and f represents a deep net work. Multi-step prediction can be done using tw o approaches: iterative approach, and direct approac h [ 21 ]. In iterativ e metho d, first subsequen t p eriod information is predicted through past observ ations. Afterwards, the estimated v alue is used as an input 2 ; thereby the next p erio d is predicted. The pro cess is carried on un til the end of the forecast horizon 3 . The function pro duces single v alue at every future time-step. Let ( x 1 , . . . , x w ) b e the last window of the input time-series, and ( x w +1 , . . . , x w + w test ) is the sto c k v alues for the forecast horizon w test . The goal is to predict ( ˆ x w +1 , . . . , ˆ x w + w test ). Using iterative approach, this can b e defined as follo ws: Consider an iterator v ariable j ∈ { w + 1 , . . . , w + w test } . If w + 1 ≤ j ≤ 2 w , ˆ x j = f (( x j − w , x j − w +1 , . . . , x w , ˆ x w +1 , . . . , ˆ x j − 1 ); θ ); (2) and, if j > 2 w , ˆ x j = f (( ˆ x j − w , ˆ x j − w +1 , . . . , ˆ x j − 1 ); θ ) (3) In the direct multi-step forecast metho d, successiv e p erio ds can b e predicted all at once. Each prediction is related only to the stock v alues in the input window. W e can write this as: ˆ x j = f (( x k , . . . , x w + k − 1 ); θ ) (4) 2 the prediction go es as an input feature 3 a synon ym for forecast windo w commonly used in time-series communit y 4 where, j ∈ { w + k , . . . , w + k − 1 + w test } and k is a v ariable used to denote the iterator o v er the da y instance. In the follo wing subsections, we briefly describ e the existing deep net work to ols used in this work. These to ols are standard, and the mathematical details could b e found in the corresp onding references, and therefore, w e do not explicitly provide the precise mathematical workings of these models. 3.2.1 Multila y er Perceptron (MLP) An MLP consists of at least three lay ers of no des: an input lay er, a hidden lay er, and an output lay er [ 22 ]. Except for the input no des, each no de is a neuron that uses a nonlinear activ ation function. MLP utilises a sup ervised learning tec hnique called back-propagation for training [ 23 ]. The inputs in our case will b e time-series data from a sp ecific window. 3.2.2 Con v olutional Neural Netw ork (CNN) The idea b ehind CNNs [ 24 ] is to con v olve a k ernel (whose size can b e v aried) across an arra y of input v alues (lik e in time series data) and extract features at ev ery step. The kernel con volv es along the array based on the stride parameter provided. The stride parameter determines the amount with whic h the kernel mov es along the input to learn the required features for predicting the final output. In our case, we hav e done 1D con volution on our arra y of sto c k prices from v arious time steps with appropriate k ernel size. This k ernel learns the features from that windo w of the input in order to predict the next v alue as accurately as p ossible. This technique, how ev er, do es not capture time-series co-relations and treats each window size separately . 3.2.3 Recurren t Neural Net work (RNN) RNNs make use of sequen tial information to learn and understand the input features. These are differen t from MLPs, where inputs and outputs are assumed to b e indep enden t. But the conv en tional metho ds fail in situations where inputs and outputs influence each other (time-dep endence) [ 25 ]. RNNs are recurrent as they pro cess all the steps in a sequence in the same wa y and produce outputs that dep end on previous outputs. In other words, RNNs hav e a memory that stores all the information gained so far. Theoretically , they are expected to learn and remem b er information from long sequences, but practically , they hav e found to b e storing information only from a few steps back. In our w ork, w e hav e passed the input time series data sequentially one by one into the netw ork. The hidden states are trained accordingly and are used to predict the next sto c k price. During training, we com pare the predicted and true v alues and try to reduce the error difference. During testing, w e use the previous predicted v alue to calculate the next time steps (future sto ck prices). (a) Gate d-R e curr ent Units (GRU) b ase d RNN: The principle of b oth GRU and LSTM [ 26 ] cells are similar, in the sense that they b oth are used as ”memory” cells and are used to o vercome the v anishing gradien t problem of RNNs. A GR U cell, how ev er, has a differen t gating mec hanism in which it has t wo gates, a reset gate, and an up date gate [ 27 ]. The idea b ehind the reset gate is that it determines how muc h of the previously gained memory or hidden state needs to b e forgotten. The up date gate is resp onsible for deciding ho w muc h of the past gained information needs to b e passed along the netw ork. The adv an tage of using the gating mechanism in these cells is to learn long-term dep endencies. (b) L ong-Short T erm Memory Cel ls (LSTM) b ase d RNN: LSTMs [ 26 ] cells were designed to ov ercome the problem of v anishing gradients in RNNs. V anishing gradients is a problem faced in deep er netw orks when the error propagated through the system b ecomes smaller due to which training and up dating of weigh ts do not happen efficiently . LSTMs ov ercome this problem b y em b edding the gating mechanism in each of their cells. They ha ve input, forget, and output gates whic h up dates and con trols the cell states. The input gate is resp onsible for the amount of new hidden state computed after the curren t input you wish to pass through the ahead net w ork. The forget netw ork decides how m uch the previous state it has to let 5 through. In the end, the output gate defines how muc h of the curren t state it has to exp ose to the higher la yers (next time steps). 3.3 Implemen tation F or single-step forecasting, the input windo w (i.e. back cast windo w) size is studied in the set { 3, 5, 7, 9, 11, 13, 15 } . The implemen tation for this is straigh tforward, as explained in section 3.2 , where the testing window is a single sto c k v alue in the future. F or the multi-step forecasting, the implementation is conducted for 3 different bac kcast windows { 30, 60, 90 } and 4 differen t forecast windows such as { 7, 14, 21, 28 } . The implemen tation for the multi-step forecasting is carried out using the direct strategy as describ ed earlier. F urther, the following details are relev an t in our implementations: The original data for prices of all the sto cks w ere normalised to the in terv al range [0 , 1]. F or each sto c k, the goal w as to use the training set for mo del building, p ost whic h the trained model w ould b e used to predict the whole test set. The train-test split for each sto ck w as done in such a w a y that the training set comprised of sto c k prices from 1st January 2002 to 1st January 2017, and the subsequen t prices formed the testing set. It should b e noted that for all the deep netw ork mo dels, the input size remains equal to the windo w size ( w ). The deep netw orks in volv e man y differen t hyperparameters; how ev er, given the amount of data and computational resources av ailable to us, we were limited to p erform some man ual tuning of these parameters. Due to reason of space, we are unable to provide these details. W e note that automatically tuning v arious hyperparameters of these deep netw orks could result in b etter forecast p erformance. The man ually fixed set of h yp erparameter details are furnished b elow: MLP: There are 2 hidden la yers with sizes (16 , 16). The output lay er has 1 neuron. The activ ation functions in all la yers are relu (rectified linear unit). CNN: There are 4 hidden lay ers with sizes (32 , 32 , 2 , 32) with the third lay er b eing a Max-Pooling Lay er. The output la y er has the size 1. The activ ation function used in ev ery lay er is relu . GR U-RNN: There are 2 hidden lay ers with sizes (256 , 128). The output la yer has 1 neuron. The activ ation function used in each la yer is relu with linear activ ation for the final la yer. LSTM-RNN: There are 2 hidden lay ers with sizes (256 , 128). The output lay er has 1 neuron. The activ ation function used for every la yer is relu with linear activ ation for the final la yer. The ev aluation or loss metric for these mo dels is ‘mean-squared-error (MSE)’. F urther, for reliable mo del ev aluation, and each mo del was indep endently run (trained and tested) for 5 different times to obtain statistically reliable p erformance estimates. Consequen tly , we obtained results in the form of loss in terv als corresp onding to our predictions on the test datasets vs the actual sto c k prices. These testing loss in terv als hav e been rep orted in the results’ tables. These test loss interv als provide a summary in the form of the mean and standard deviation of MSE obtained o ver five different runs. In the tables, the represen tation of the loss in terv als is mean ( ± std.dev . ). All our implemen tations are carried out in the Python en vironment. The deep neural netw orks are implemen ted using the Python library: Keras . All the exp eriments are conducted in a machine with In tel i7 pro cessor, 16GB main memory and NVIDIA 1050 GPU that has 4GB of video memory . W e used the Python nsepy library to fetc h the historical data for all Indian sto cks from the National Stock Exc hange (NSE: https://www.nseindia.com/ ). The co de and data are shared via GitHub rep ository: https://github.com/kaushik- rohit/timeseries- prediction . 4 Result and Discussion In this section, we provide a summary of results that are obtained for single- and multi-step forecasting of the 10 differen t Indian sto c k data. F or clear presen tation, w e place all the result tables, and some sample 6 forecast plots in App endix A and only provide the statistical test results in this section. How ev er, the individual forecast result tables are referred to in the discussion text. 4.1 Single-Step F orecasting The p erformance observed for the A CC sto ck depicts that all four deep mo dels seem to p erform the prediction task similarly . How ev er, as w e increase the window sizes, the predictions of all the mo dels go further aw a y from the true v alues increasing the error rate. Hence, it can b e concluded that the future single sto c k price is highly dep endent on the immediate previous prices and less dep enden t on further past prices. How ev er, a different kind of prediction trend was sho wn by the mo dels for the AXISBANK sto c ks. It can b e seen from the graphs of AXISBANK sto cks that all the models performed quite well for the smallest windo w-size of 3. The predictions for the windo w-size 7 w ere also go o d for all the mo dels. Ho wev er, the results for the other window-sizes v aried irregularly and didn’t p erform as well. A very differen t trend w as seen for BHAR TIAR TL stock prediction. T able A3 suggests that for smaller windo w- sizes, MLP p erformed sligh tly b etter than the others. Ho wev er, as windo w-sizes increases, CNN starts outp erforming all the other mo dels. One unique asp ect of these mo dels can b e observ ed in the forecasting graphs (refer App endix A ): all the mo dels failed to predict the sudden increases in the prices to the actual exten t. Hence, it could b e emphasised that the information from the previous trends of stock prices is not sufficien t enough for predicting future prices, and thus, it ma y dep end on a v ariet y of factors that ha ve not b een incorporated in these mo dels. A filter-based deep netw ork such as CNN outp erforms other deep mo dels for CIPLA sto c k dataset as shown in T able A4 . This holds for all window sizes. How ever, the results obtained for the HCL TECH sto c k is quite con tradictory . T able A5 represents that GRU-RNN p erforms m uch b etter compared to other mo dels. The window-size of 13 pro duced the b est result within the GRU mo del. This demonstrates that the GR U-RNN structure could certainly handle the deviation within the sto ck prices for an extended p erio d (i.e., w = 13). The almost similar inference could also b e made for HDFC sto c k, where b oth LSTM-RNN and GRU-RNN hav e p erformed v ery well for w = 9 (refer T able A6 ). T able A7 shows that an iden tical trend in p erformance w as observed across differen t window sizes for INFY sto ck price prediction. Additionally , CNN required a higher num b er of input features (i.e., w = 11) to perform to its capacity for this dataset. The JSWSTEEL sto c k dataset contains a very high n umber of structural breaks and is highly volatile. T able A8 shows that this characteristic b eha ved as an adversarial feature for all the mo dels, and hence the mo dels were not able to p erform well. How ev er, LSTM-RNN shows some improv ed p erformance giv en a higher input window of 13. T able A9 suggests that a similar trend in p erformance w as also observed for the MARUTI sto c k dataset with a surprising result that the mo del like MLP could p erform b etter than other deep mo dels with minimal input windo w of 3. MLP also p erforms b etter than its counterparts for the UL TRACEMCO dataset, as shown in T able A10 . 4.1.1 Statistical significance test The results obtained ov er five different indep endent runs of the mo dels are sub jected to a statistical significance test. F or this, w e conduct the Dieb old-Mariano test [ 28 , 29 ]. How ev er, w e conduct the DM- test only for the single-step forecasting results. The DM-test compares tw o hypotheses at a time, and the v alue is con verted in to the p -v alue. F rom T able 2 , it could b e concluded that most of the results are significan t giv en an y hypotheses pair. The results of Dieb old-Mariano T est at 0.01% level of significance ( α = 0 . 0001) suggests that the relative order of p erformance of the deep net work mo dels for single-step forecasting is: GRU-RNN, CNN, LSTM-RNN and MLP , where MLP outp erforms all others. W e note that the statistical significance strongly lo oks at ov erall p erformance of the mo del rather than the p erformance on individual dataset. Althoguh, MLP do es not enco de an y long-term dep endency arising in the time- series data, it ma y not b e exp ected to p erform as go o d as standard dep endency-learning mo dels such as LSTM- or GRU-RNNs. Another observ ation that could b e made is that the data used in our present w ork ma y not b e containing any suc h long-term dep endencies for whic h a sequence-based deep mo del or a 7 con volution-based deep mo del could b e v ery useful. Our goal here is not to recommend MLP as the best mo del for real-w orld applications to time-series mo delling, rather as a typical deep mo del that p erforms w ell on data that has mutiple structural breaks and is highly v olatile. How ev er, readers should note that the level of significance plays a crucial role in c ho osing the performance ordering of the models. T able 2: Statistical significance test for single step forecasting results. The table shows the v alue of DM-statistic follow ed by the corresponding p-v alue within paren thesis. Sto c ks MLP-CNN LSTM-GR U MLP-LSTM LSTM-CNN CNN-GR U A CC -1.6825 (0.09) -2.2266 (0.02) 1.9484 (0.05) 1.1225 (0.26) -1.4563 (0.14) AXISBANK 1.0484 (0.29) 4.3022 (0.02e-3) -4.2013 (0.03e-3) 4.2392 (0.02e-3) 1.0799 (0.28) BHAR TIAR TL 3.2570 (0.00) -3.5133 (0.00) -2.3957 (0.01) 2.7976 (0.00) -3.4586 (0.00) CIPLA -0.0928 (0.92) -3.5751 (0.00) -3.9925 (0.07e-3) 3.8955 (0.00) -4.3625 (0.15e-4) HCL TECH -5.6934 (0.02e-6) 6.2360 (0.09e-8) -6.2722 (0.07e-8) 6.4186 (0.03e-8) 5.5730 (0.41e-8) HDF C -1.8418 (0.06) 1.1548 (0.24) -0.1273 (0.89) -0.5156 (0.60) 2.2790 (0.02) INFY -0.8889 (0.37) 1.3987 (0.16) -1.1016 (0.27) 1.2804 (0.20) -1.0152 (0.31) JSWSTEEL 0.9842 (0.32) 1.0997 (0.27) 0.9799 (0.32) -0.9794 (0.32) 1.0017 (0.31) MAR UTI 0.6225 (0.53) -7.6933 (0.07e-12) -2.2788 (0.02) 2.2733 (0.02) -7.6887 (0.80e-13) UL TRACEMCO -1.3570 (0.17) -1.5115 (0.13) -0.2501 (0.80) -1.5288 (0.12) -1.4971 (0.13) 4.2 Multi-step F orecasting Multi-step forecasting has alwa ys b een a c hallenging problem in time-series prediction problems. The results are in T able A . F or T able B1 through to T able B10 , the multi-step forecast results suggest that for small forecast windo w the deep netw ork metho ds are p erforming well for all the datasets. As the forecast windo w size is increased (suc h as 28), the performance drops significantly . The p erformance of the four deep net work mo dels for the ACC sto ck data suggests that the MLP needs to observ e as high as 30 input da ys to predict accurately 7 days of future data. This is exp ected for a densely connected netw ork like an MLP where the salient features are constructed in its in termediate hidden la yers. This observ ation also holds for other stocks exp ect for the JSWSTEEL sto c ks. F urthermore, it is in contradiction to more inputs as 60 or 90, where additional days don’t aid an y useful information to the mo del. Similarly , for the JSWSTEEL sto cks, the p erformance for the MLP mo del is b est at 60 input days to pro duce 7 days ahead forecast of stock prices. The GRU-RNN mo del lo oks into a large sized input such as 60 or 90 to make predictions for 7 days in the future, whereas for the LSTM-RNN and CNN, 30 days of input is sufficient to pro duce accurate future predictions. Similarly , lo oking at all the p erformance models for all p ossible forecast windows considered in this work such as { 7, 14, 21, 28 } , w e note that MLP outp erforms all other deep mo dels for the ma jorit y of sto cks. T o supp ort the observ ation, w e conduct a statistical significance test for a sample input-output com bination. 4.2.1 Statistical significance test The DM test results for m ulti step forecasting with input windo w size 30 and output window size 7 is in T able 3 . The level of significance is set at 0.1%. F or comparing the relativ e forecasting p erformance of an y pair of mo dels from the table, we tak e a ma jorit y vote based on DM-test analysis for eac h of the 10 sto c ks. Accordingly , for each pair of mo del comparison, one mo del is c hosen as the b est among the pair if it is found to b e the b est mo del for more than 5 out of 10 sto cks based on the DM-test p-v alue analysis for that pair of mo dels. It is observ ed that MLP outp erforms all the other deep netw ork approaches for this setting of input and output windo w combination. This observ ation is consisten t with the observ ation for the single-step forecasting p erformance as w ell. The ov erall order of relativ e forecasting p erformance of differen t neural netw orks for multi-step forecasting is found to be: CNN, LSTM-RNN, GRU-RNN, and MLP . Readers should note that the lev el of significance pla ys a crucial role in choosing the p erformance ordering of the mo dels. 8 T able 3: Statistical significance test for m ulti step forecasting results with input windo w size 30 and output windo w size 7. The table shows the v alue of DM-statistic follow ed by the corresp onding p-v alue within paren thesis. Sto c ks MLP-CNN LSTM-GR U MLP-LSTM LSTM-CNN MLP-GR U A CC -2.7965 (0.01) -2.4170 (0.02) 1.9168 (0.06) -2.6386 (0.01) -1.3845 (0.16) AXISBANK -1.6748 (0.09) -2.9254 (0.03e-1) -2.8932 (0.03e-1) 2.5876 (0.01e-1) -2.9673 (0.00) BHAR TIAR TL -2.2470 (0.03) 3.5146 (0.00) -2.3641 (0.02) -0.4689 (0.64) 0.4332 (0.66) CIPLA -1.9501 (0.05) 3.3701 (0.01e-2) 0.1213 (0.90) -1.8521 (0.06) 0.7197 (0.47) HCL TECH -6.5086 (1.95e-10) 7.8612 (0.02e-10) -7.8557 (0.02e-12) -5.3166 (1.63e-14) -6.6640 (0.75e-10) HDF C -2.4685 (0.01) 4.4679 (0.09e-2) -0.0014 (0.99) -2.2448 (0.02) 2.8395 (0.00) INFY 2.5914 (0.01) 2.0002 (0.05) -2.3651 (0.02) 2.4460 (0.01) -2.3381 (0.01) JSWSTEEL 0.8546 (0.39) 8.4322 (4.23e-16) 1.3509 (0.18) -2.7461 (0.01) 1.6018 (0.10) MAR UTI -1.8351 (0.07) -10.1729 (4.27e-22) -5.6069 (3.52e-8) 5.5603 (4.53e-8) -10.1630 (0.46e-21) UL TRACEMCO -1.7387 (0.08) -1.5022 (0.13) 1.5481 (0.12) -2.0443 (0.04) 0.3046 (0.76) 5 Conclusion In this pap er, w e studied the applicability of the p opular deep neural net works (DNN) comprehensively as function approximators for non-stationary time-series forecasting. Sp ecifically , we ev aluated the follo wing DNN mo dels: Multi-la yer Perceptron (MLP), Con volutional Neural Net work (CNN), RNN with Long- Short T erm Memory Cells (LSTM-RNN), and RNN with Gated-Recurrent Unit (GR U-RNN). These four p o werful DNN metho ds hav e b een ev aluated ov er ten p opular Indian financial sto c ks’ datasets. F urther, the ev aluation is carried out through predictions in both fashions: (1) single-step-ahead, (2) multi-step- ahead. The training of the deep mo dels for b oth single-step and m ulti-step forecasting has b een carried out using ov er 15 y ears of data and tested on t wo y ears of data. Our exp eriments show the follo wing: (1) The neural netw ork mo dels used in this exp eriments demonstrate go o d predictive p erformance for the case of single-step forecasting across all sto c ks datasets; (2) the predictive p erformance of these mo dels remains consisten t across v arious forecast windo w sizes; and (3) given the limited input window condition for multi-step forecasting, the p erformance of the deep net work models are not as go o d as that was seen in the case of single-step forecasting. How ev er, not withstanding the ab ov e limitation of the mo dels for the m ulti-step forecasting, given the v ast amount of data collected ov er a duration of 17 years on whic h the mo dels are built, this w ork could b e considered as a significant b enchmark study with regard to the Indian sto c k market. F urther, w e note the following observ ation. The deep netw ork mo dels are built with ra w time-series of sto c k prices. That is: no external features such as micro- or macro-economic factors, other statistically handcrafted parameters, relev ant news data are provided to these mo dels. These parameters are often considered to b e useful to impact sto c k price prediction. A mo del that takes in to accoun t these additional factors could b etter the predictive p erformance of b oth single-step as well as m ulti-step forecasting. References [1] Ankita Mishra, Vino d Mishra, and Russell Sm yth. The random-walk hypothesis on the indian sto c k mark et. Emer ging markets financ e and tr ade , 51(5):879–892, 2015. [2] Heikki Lehkonen and Kari Heimonen. Democracy , p olitical risks and sto c k market p erformance. Journal of International Money and Financ e , 59:77–99, 2015. [3] Neb o jsa Dimic, Vitaly Orlov, and V anja Piljak. The p olitical risk factor in emerging, frontier, and dev elop ed sto ck mark ets. Financ e R ese ar ch L etters , 15:239–245, 2015. 9 [4] Ro dolfo C Cav alcante, Ro drigo C Brasileiro, Victor LF Souza, Jarley P Nobrega, and Adriano LI Oliv eira. Computational in telligence and financial markets: A surv ey and future directions. Exp ert Systems with Applic ations , 55:194–211, 2016. [5] Harald Sc ho en, Daniel Ga yo-Av ello, P anagiotis T akis Metaxas, Eni Mustafara j, Markus Strohmaier, and P eter Glo or. The p o wer of prediction with so cial media. Internet R ese ar ch , 23(5):528–543, 2013. [6] Ch ung-Ho Su and Ching-Hsue Cheng. A hybrid fuzzy time series mo del based on anfis and in tegrated nonlinear feature selection metho d for forecasting sto c k. Neur o c omputing , 205:264–273, 2016. [7] Ming-Chi Tsai, Ching-Hsue Cheng, Meei-Ing Tsai, and Huei-Y uan Shiu. F orecasting leading industry sto c k prices based on a h ybrid time-series forecast mo del. PloS one , 13(12):e0209922, 2018. [8] Sibarama P anigrahi and HS Behera. A study on leading machine learning tec hniques for high order fuzzy time series forecasting. Engine ering Applic ations of Artificial Intel ligenc e , 87:103245, 2020. [9] Hans R Stoll and Rob ert E Whaley . V olatility and futures: Message versus messenger. Journal of Portfolio Management , 14(2):20, 1988. [10] Ky ongwook Choi, W ei-Choun Y u, and Eric Zivot. Long memory v ersus structural breaks in mo deling and forecasting realized volatilit y . Journal of International Money and Financ e , 29(5):857–875, 2010. [11] R Bon´ e and M Crucian u. Multi-step-ahead prediction with neural netw orks: a review. 9emes r enc on- tr es internationales: Appr o ches Connexionnistes en Scienc es , 2:97–106, 2002. [12] Ja vier Contreras, Rosario Espinola, F rancisco J Nogales, and An tonio J Conejo. Arima mo dels to predict next-day electricity prices. IEEE tr ansactions on p ower systems , 18(3):1014–1020, 2003. [13] G P eter Zhang. Time series forecasting using a hybrid arima and neural net work mo del. Neur o c om- puting , 50:159–175, 2003. [14] An tonio J Conejo, Miguel A Plazas, Rosa Espinola, and Ana B Molina. Day-ahead electricit y price forecasting using the wa v elet transform and arima mo dels. IEEE tr ansactions on p ower systems , 20(2):1035–1042, 2005. [15] Mehdi Khashei, Sey ed Reza Hejazi, and Mehdi Bijari. A new h ybrid artificial neural net works and fuzzy regression model for time series forecasting. F uzzy Sets and Systems , 159(7):769–786, 2008. [16] Mehdi Khashei and Mehdi Bijari. A no vel h ybridization of artificial neural net w orks and arima models for time series forecasting. Applie d Soft Computing , 11(2):2664–2675, 2011. [17] Sima Siami-Namini and Akbar Siami Namin. F orecasting economics and financial time series: Arima vs. lstm. arXiv pr eprint arXiv:1803.06386 , 2018. [18] Manna Ma jumder and MD A Hussian. F orecasting of indian sto ck mark et index using artificial neural net work. Information Scienc e , pages 98–105, 2007. [19] Goutam Dutta, P ank a j Jha, Arnab Kumar Laha, and Neera j Mohan. Artificial neural net work mo dels for forecasting sto ck price index in the b omba y sto c k exchange. Journal of Emer ging Market Financ e , 5(3):283–295, 2006. [20] M Hiransha, E Ab Gopalakrishnan, Vija y Krishna Menon, and KP Soman. Nse sto c k mark et prediction using deep-learning models. Pr o c e dia c omputer scienc e , 132:1351–1362, 2018. [21] Co ¸ skun Hamza¸ cebi, Diyar Ak a y , and F evzi Kutay . Comparison of direct and iterative artificial neural net work forecast approaches in multi-perio dic time series forecasting. Exp ert Systems with Applic a- tions , 36(2):3839–3844, 2009. 10 [22] T revor Hastie, Rob ert Tibshirani, Jerome F riedman, and James F ranklin. The elemen ts of statistical learning: data mining, inference and prediction. The Mathematic al Intel ligenc er , 27(2):83–85, 2005. [23] Da vid E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. Learning in ternal representations by error propagation. T echnical rep ort, California Univ San Diego La Jolla Inst for Cognitive Science, 1985. [24] Y ann LeCun, Y oshua Bengio, et al. Con volutional net works for images, sp eech, and time series. The handb o ok of br ain the ory and neur al networks , 3361(10):1995, 1995. [25] Alex Grav es, Marcus Liwicki, San tiago F ern´ andez, Roman Bertolami, Horst Bunke, and J ¨ urgen Sc hmidhuber. A no v el connectionist system for unconstrained handwriting recognition. IEEE tr ans- actions on p attern analysis and machine intel ligenc e , 31(5):855–868, 2008. [26] Sepp Ho chreiter and J ¨ urgen Schmidh uber. Long short-term memory . Neur al c omputation , 9(8):1735– 1780, 1997. [27] Kyungh yun Cho, Bart v an Merri ¨ en b o er, Caglar Gulcehre, Dzmitry Bahdanau, F ethi Bougares, Hol- ger Sch w enk, and Y osh ua Bengio. Learning phrase represen tations using RNN encoder–deco der for statistical machine translation. In Pr o c e e dings of the 2014 Confer enc e on Empiric al Metho ds in Nat- ur al L anguage Pr o c essing (EMNLP) , pages 1724–1734, Doha, Qatar, Octob er 2014. Asso ciation for Computational Linguistics. [28] F DIEBOLD and R MARIANO. Comparing predictive accuracy . Journal of Business and Ec onomics Statistics , 13:253–265, 1995. [29] Da vid Harvey , Stephen Leyb ourne, and P aul Newb old. T esting the equality of prediction mean squared errors. International Journal of for e c asting , 13(2):281–291, 1997. 11 A App endix: F orecasting Results The forecasting plots during testing. The plots are showing the a verage of fiv e indep endent runs of the programs, and this a verage is compared with the true v alue. Due to the reason of space, we pro vide results for only one stock dataset (ACC). How ev er, similar p erformances were also observ ed for other datasets, whic h can b e lo cated in the link https://github.com/kaushik- rohit/timeseries- prediction . T able A1: Single-step forecast results for ACC stock: T est MSE (mean and std. dev. o ver 5 differen t runs) Windo w-sizes MLP CNN GR U-RNN LSTM-RNN 3 0.0004221 (0.0000444) 0.0005847 (0.0000562) 0.0016516 (0.0008691) 0.0015011(0.0008549) 5 0.0006502 (0.0002251) 0.0007508 (0.0001441) 0.0016215 (0.0006634) 0.0016570 (0.0013026) 7 0.0008696 (0.0002147) 0.0011275 (0.0004138) 0.0026603 (0.0010596) 0.0017234 (0.0010127) 9 0.0010079 (0.0001728) 0.0011650 (0.0002645) 0.0030460 (0.0009964) 0.0021387 (0.0014420) 11 0.0010929 (0.0002465) 0.0011588 (0.0000686) 0.0027522 (0.0015047) 0.0021330 (0.0010239) 13 0.0012379 (0.0001855) 0.0015122 (0.0001267) 0.0036655 (0.0009325) 0.0014072 (0.0008664) 15 0.0017524 (0.0003690) 0.0017017 (0.0003527) 0.0039116 (0.0023042) 0.0020953 (0.0005682) T able A2: Single-step forecast results for AXISBANK sto c k: T est MSE (mean and std. dev. o ver 5 differen t runs) Windo w-sizes MLP CNN GR U-RNN LSTM-RNN 3 0.0000515(0.0000260) 0.0000487(0.0000217) 0.0004417(0.0004302) 0.0003082(0.0003509) 5 0.0000693(0.0000336) 0.0000771(0.0000287) 0.0001848(0.0001252) 0.0005975(0.0002366) 7 0.0000690 (0.0000313) 0.0001497(0.0000982) 0.0003395(0.0001962) 0.0001344(0.0000540) 9 0.0000811(0.0000116) 0.0001389(0.0000653) 0.0003509 (0.0004081) 0.0004543(0.0003342) 11 0.0001067(0.0000279) 0.0000850(0.0000448) 0.0005067(0.0006814) 0.0001788 (0.0001291) 13 0.0000782(0.0000347) 0.0000722(0.0000281) 0.0003205(0.0002610) 0.0005240(0.0001061) 15 0.0001111(0.0000170) 0.0001805 (0.0000904) 0.0004173(0.0005002) 0.0002738(0.0002042) T able A3: Single-step forecast results for BHAR TIAR TL stock: T est MSE (mean and std. dev. ov er 5 differen t runs) Windo w-sizes MLP CNN GR U-RNN LSTM-RNN 3 0.0002035(0.0000681) 0.0002797 (0.0001659) 0.0005684 (0.0000984) 0.0004817(0.0001587) 5 0.0002316(0.0001263) 0.0002699(0.0001950) 0.0015586 (0.0002458) 0.0005880 (0.0001752) 7 0.0003627(0.0000733) 0.0004076(0.0002003) 0.0011911 (0.0005273) 0.0005556 (0.0002353) 9 0.0004252(0.0001691) 0.0003931(0.0002384) 0.0014297 (0.0006784) 0.0007216 (0.0001412) 11 0.0005564 (0.0000862) 0.0005313 (0.0002783) 0.0018257 (0.0005343) 0.0008124 (0.0003259) 13 0.0004261 (0.0002045) 0.0003093 (0.0001621) 0.0011227 (0.0004965) 0.0006211 (0.0001480) 15 0.0007215 (0.0001667) 0.0002497 (0.0001458) 0.0010685 (0.0008361) 0.0007042 (0.0003836) 12 T able A4: Single-step forecast results for CIPLA sto ck: T est MSE (mean and std. dev. ov er 5 different runs) Windo w-sizes MLP CNN GR U-RNN LSTM-RNN 3 0.0000871 (0.0000337) 0.0001130 (0.0000594) 0.0009330 (0.0004240) 0.0001653 (0.0000617) 5 0.0000856 (0.0000145) 0.0001262 (0.0000551) 0.0012812 (0.0006000) 0.0003738 (0.0002768) 7 0.0001197 (0.0000311) 0.0001435 (0.0000379) 0.0009877 (0.0008997) 0.0004203 (0.0002756) 9 0.0001462 (0.0000355) 0.0001614 (0.0000390) 0.0010927 (0.0003391) 0.0008656 (0.0007267) 11 0.0001899 (0.0000823) 0.0001907 (0.0000721) 0.0007634 (0.0002993) 0.0003982 (0.0001604) 13 0.0001976 (0.0001014) 0.0002209 (0.0000843) 0.0014596 (0.0012414) 0.0010129 (0.0004355) 15 0.0002379 (0.0000800) 0.0001144 (0.0000328) 0.0013618 (0.0005843) 0.0007791(0.0001930) T able A5: Single-step forecast results for HCL TECH sto ck: T est MSE (mean and std. dev. ov er 5 differen t runs) Windo w-sizes MLP CNN GR U-RNN LSTM-RNN 3 0.0016502 (0.0011387) 0.0023050 (0.0023157) 0.0004055 (0.0003749) 0.0009085 (0.0004147) 5 0.0029187 (0.0026613) 0.0034353 (0.0027634) 0.0003305 (0.0002079) 0.0026182 (0.0026467) 7 0.0019523 (0.0024012) 0.0022142 (0.0016357) 0.0015353 (0.0014942) 0.0087284 (0.0032211) 9 0.0032018 (0.0019762) 0.0057737 (0.0032285) 0.0006866 (0.0006232) 0.0076727 (0.0056202) 11 0.0051562 (0.0020755) 0.0053916 (0.0030622) 0.0003930 (0.0002421) 0.0042450 (0.0025408) 13 0.0022825 (0.0018382) 0.0071111 (0.0020174) 0.0001733 (0.0000372) 0.0075984 (0.0015168) 15 0.0050976 (0.0028671) 0.0081210 (0.0038284) 0.0018683 (0.0023934) 0.0048502 (0.0042392) T able A6: Single-step forecast results for HDF C sto ck: T est MSE (mean and std. dev. o ver 5 different runs) Windo w-sizes MLP CNN GR U-RNN LSTM-RNN 3 0.0001835 (0.0000824) 0.0007788 (0.0005064) 0.0016444 (0.0021480) 0.0005317 (0.0003852) 5 0.0003086 (0.0003135) 0.0005371 (0.0001659) 0.0013700 (0.0015615) 0.0010208 (0.0010850) 7 0.0006299 (0.0005823) 0.0005523 (0.0002540) 0.0012404 (0.0008231) 0.0006913 (0.0006490) 9 0.0006540 (0.0002297) 0.0008980 (0.0000963) 0.0014943 (0.0016051) 0.0005813 (0.0008020) 11 0.0008674 (0.0003254) 0.0008349 (0.0002675) 0.0003954 (0.0002056) 0.0010702 (0.0014710) 13 0.0007940 (0.0003468) 0.0006309 (0.0003891) 0.0012609 (0.0013088) 0.0023305 (0.0012481) 15 0.0007099 (0.0001384) 0.0010326 (0.0008803) 0.0026690 (0.0025715) 0.0020410 (0.0017725) T able A7: Single-step forecast results for INFY sto ck: T est MSE (mean and std. dev. o ver 5 differen t runs) Windo w-sizes MLP CNN GR U-RNN LSTM-RNN 3 0.0005255 (0.0001396) 0.0002269 (0.0000797) 0.0001357 (0.0000900) 0.0004860 (0.0003214) 5 0.0005674 (0.0001610) 0.0003122 (0.0001724) 0.0003263 (0.0002350) 0.0002029 (0.0001462) 7 0.0004635 (0.0001925) 0.0002579 (0.0001686) 0.0001498 (0.0000581) 0.0002305 (0.0000931) 9 0.0006265 (0.0002582) 0.0002504 (0.0001102) 0.0000956 (0.0000186) 0.0001955 (0.0000614) 11 0.0007612 (0.0001806) 0.0003764 (0.0002317) 0.0001351 (0.0000309) 0.0001972 (0.0000733) 13 0.0007907 (0.0001193) 0.0004738 (0.0001561) 0.0002171 (0.0000975) 0.0001739 (0.0000517) 15 0.0007154 (0.0003186) 0.0005986 (0.0003641) 0.0001353 (0.0000668) 0.0002354 (0.0000706) T able A8: Single-step forecast results for JSWSTEEL sto ck: T est MSE (mean and std. dev. o ver 5 differen t runs) Windo w-sizes MLP CNN GR U-RNN LSTM-RNN 3 0.0008873 (0.0002596) 0.0030845 (0.0004266) 0.0022322 (0.0002757) 0.0021728 (0.0001631) 5 0.0006888 (0.0004107) 0.0013932 (0.0005308) 0.0006842 (0.0003586) 0.0013430 (0.0004050) 7 0.0006232 (0.0003326) 0.0017431 (0.0009391) 0.0016630 (0.0010976) 0.0005379 (0.0001549) 9 0.0008845 (0.0004175) 0.0013794 (0.0007401) 0.0009644 (0.0004872) 0.0003038 (0.0001008) 11 0.0012099 (0.0005770) 0.0018192 (0.0009440) 0.0006822 (0.0004396) 0.0004553 (0.0001950) 13 0.0010368 (0.0004484) 0.0012310 (0.0006584) 0.0009355 (0.0003718) 0.0009499 (0.0010030) 15 0.0014731 (0.0005437) 0.0015114 (0.0008925) 0.0008119 (0.0007530) 0.0010866 (0.0011773) 13 T able A9: Single-step forecast results for MARUTI sto ck: T est MSE (mean and std. dev. ov er 5 different runs) Windo w-sizes MLP CNN GR U-RNN LSTM-RNN 3 0.0022925 (0.0006457) 0.0006474 (0.0000423) 0.0366665 (0.0112447) 0.0136058 (0.0080959) 5 0.0021511 (0.0021414) 0.0008467 (0.0000926) 0.0318909 (0.0267657) 0.0208617 (0.0050294) 7 0.0009793 (0.0001314) 0.0009672 (0.0000539) 0.0928953 (0.0106618) 0.0183959 (0.0164570) 9 0.0020073 (0.0014313) 0.0010510 (0.0001043) 0.0802620 (0.0406923) 0.0349464 (0.0266224) 11 0.0013546 (0.0005229) 0.0013423 (0.0003510) 0.0766645 (0.0218722) 0.0270535 (0.0174924) 13 0.0015955 (0.0006773) 0.0013866 (0.0002926) 0.0727358 (0.0558740) 0.0619624 (0.0391621) 15 0.0019786 (0.0009192) 0.0022918 (0.0004053) 0.0743994 (0.0463265) 0.0304260 (0.0264045) T able A10: Single-step forecast results for UL TRA CEMCO sto c k: T est MSE (mean and std. dev. ov er 5 differen t runs) Windo w-sizes MLP CNN GR U-RNN LSTM-RNN 3 0.0003553 (0.0000743) 0.0004674 (0.0000524) 0.0011129 (0.0006957) 0.0010138 (0.0006587) 5 0.0005149 (0.0001737) 0.0005909 (0.0000670) 0.0033692 (0.0024419) 0.0013757 (0.0012501) 7 0.0006438 (0.0000922) 0.0007646 (0.0000962) 0.0018719 (0.0009955) 0.0008442 (0.0003019) 9 0.0009227 (0.0002358) 0.0008155 (0.0001067) 0.0027970 (0.0020777) 0.0010058 (0.0004020) 11 0.0010645 (0.0001750) 0.0009565 (0.0001088) 0.0058653 (0.0053221) 0.0005961 (0.0002074) 13 0.0010508 (0.0001368) 0.0010494 (0.0001358) 0.0060068 (0.0052101) 0.0018897 (0.0014145) 15 0.0010278 (0.0001846) 0.0008928 (0.0000935) 0.0017564 (0.0015364) 0.0026440 (0.0029301) (a) w = 3 (b) w = 7 (c) w = 11 (d) w = 15 Figure A1: Single-step forecasting plots for ACC dataset for each deep mo del against the true prices for differen t window size ( w ). In the figure legend, ANN refers to MLP . Due to reason of space, we are unable to provide the plots for w = { 5 , 9 , 13 } . 14 T able B1: Multi-step forecast results for ACC sto ck: T est MSE (mean and std. dev. ov er 5 differen t runs) (Input, Output) window MLP CNN GRU-RNN LSTM-RNN (30, 7) 0.0019233 (0.0001796) 0.0032655 (0.0007156) 0.0028288 (0.0008798) 0.0014831 (0.0001296) (30, 14) 0.0023715 (0.0001695) 0.0034703 (0.0008722) 0.0024650 (0.0008660) 0.0024763 (0.0006420) (30, 21) 0.0033350 (0.0003381) 0.0044773 (0.0005973) 0.0028721 (0.0000534) 0.0039920 (0.0006566) (30, 28) 0.0035716 (0.0002659) 0.0043508 (0.0006285) 0.0042296 (0.0006304) 0.0054476 (0.0006860) (60, 7) 0.0020720 (0.0001856) 0.0028166 (0.0006529) 0.0024679 (0.0007471) 0.0014707 (0.0001257) (60, 14) 0.0028144 (0.0002397) 0.0041619 (0.0009518) 0.0030039 (0.0007646) 0.0023017 (0.0002294) (60, 21) 0.0037724 (0.0002339) 0.0053926 (0.0009353) 0.0035389 (0.0008466) 0.0036483 (0.0003987) (60, 28) 0.0045590 (0.0003729) 0.0047837 (0.0005719) 0.0044799 (0.0000797) 0.0051585 (0.0005595) (90, 7) 0.0022322 (0.0002161) 0.0022918 (0.0002077) 0.0025558 (0.0008330) 0.0013354 (0.0001188) (90, 14) 0.0031306 (0.0004378) 0.0038712 (0.0006698) 0.0028143 (0.0003417) 0.0021925 (0.0002722) (90, 21) 0.0036370 (0.0006305) 0.0054046 (0.0015030) 0.0042265 (0.0014142) 0.0034945 (0.0006990) (90, 28) 0.0039776 (0.0003342) 0.0050536 (0.0007407) 0.0067699 (0.0012256) 0.0053037 (0.0012531) T able B2: Multi-step forecast results for AXISBANK stock: T est MSE (mean and std. dev. o ver 5 differen t runs) (Input, Output) window MLP CNN GRU-RNN LSTM-RNN (30, 7) 0.0004412 (0.0002132) 0.0003427 (0.0001689) 0.0007955 (0.0002145) 0.0005701 (0.0002627) (30, 14) 0.0006175 (0.0003172) 0.0005083 (0.0004398) 0.0003222 (0.0001544) 0.0006500 (0.0002760) (30, 21) 0.0010073 (0.0005057) 0.0011542 (0.0009714) 0.0002325 (0.0000245) 0.0004799 (0.0000963) (30, 28) 0.0005589 (0.0002897) 0.0014537 (0.0009028) 0.0004072 (0.0000335) 0.0005838 (0.0001089) (60, 7) 0.0007062 (0.0002869) 0.0007021 (0.0003361) 0.0005125 (0.0003105) 0.0006901 (0.0002465) (60, 14) 0.0010972 (0.0003644) 0.0020001 (0.0010282) 0.0005726 (0.0002575) 0.0009651 (0.0008234) (60, 21) 0.0009101 (0.0006839) 0.0020065 (0.0003630) 0.0003826 (0.0000839) 0.0006265 (0.0002844) (60, 28) 0.0010542 (0.0005515) 0.0025980 (0.0009502) 0.0009835 (0.0003565) 0.0006103 (0.0000680) (90, 7) 0.0012354 (0.0001973) 0.0013462 (0.0007233) 0.0007331 (0.0007168) 0.0006744 (0.0000642) (90, 14) 0.0007307 (0.0003338) 0.0032691 (0.0010425) 0.0006951 (0.0003462) 0.0007027 (0.0002224) (90, 21) 0.0007812 (0.0005256) 0.0020593 (0.0013153) 0.0008963 (0.0005536) 0.0005048 (0.0004352) (90, 28) 0.0012692 (0.0004672) 0.0028267 (0.0018528) 0.0013811 (0.0010722) 0.0007381 (0.0002818) T able B3: Multi-step forecast results for BHAR TIAR TL sto ck: T est MSE (mean and std. dev. ov er 5 differen t runs) (Input, Output) window MLP CNN GRU-RNN LSTM-RNN (30, 7) 0.0007121 (0.0000345) 0.0008513 (0.0001565) 0.0009969 (0.0001635) 0.0010978 (0.0001433) (30, 14) 0.0010981 (0.0000389) 0.0011236 (0.0000643) 0.0011692 (0.0002449) 0.0011961 (0.0000745) (30, 21) 0.0012744 (0.0000772) 0.0012579 (0.0000285) 0.0015933 (0.0001660) 0.0016921 (0.0001325) (30, 28) 0.0015675 (0.0001162) 0.0015081 (0.0001651) 0.0017918 (0.0001788) 0.0021673 (0.0003877) (60, 7) 0.0010015 (0.0002596) 0.0010944 (0.0002717) 0.0010745 (0.0005075) 0.0012880 (0.0002166) (60, 14) 0.0011869 (0.0001420) 0.0014233 (0.0003696) 0.0014679 (0.0002400) 0.0012717 (0.0001411) (60, 21) 0.0013676 (0.0001464) 0.0014766 (0.0000671) 0.0019011 (0.0001783) 0.0017968 (0.0007132) (60, 28) 0.0016297 (0.0002142) 0.0019439 (0.0001053) 0.0023031 (0.0002640) 0.0026234 (0.0006751) (90, 7) 0.0011117 (0.0002259) 0.0012117 (0.0002445) 0.0011537 (0.0001674) 0.0016117 (0.0005630) (90, 14) 0.0014819 (0.0004442) 0.0017466 (0.0002888) 0.0013579 (0.0001385) 0.0014604 (0.0000723) (90, 21) 0.0016159 (0.0002179) 0.0019717 (0.0002747) 0.0019266 (0.0002001) 0.0018657 (0.0001663) (90, 28) 0.0018643 (0.0003053) 0.0020731 (0.0000764) 0.0030601 (0.0011354) 0.0022151 (0.0002840) 15 T able B4: Multi-step forecast results for CIPLA sto ck: T est MSE (mean and std. dev. ov er 5 different runs) (Input, Output) window MLP CNN GRU-RNN LSTM-RNN (30, 7) 0.0004201 (0.0000362) 0.0004331 (0.0000285) 0.0008517 (0.0010172) 0.0006759 (0.0002686) (30, 14) 0.0004461 (0.0000768) 0.0011685 (0.0005255) 0.0005645 (0.0002275) 0.0005727 (0.0003765) (30, 21) 0.0005684 (0.0000595) 0.0016531 (0.0006358) 0.0006004 (0.0000952) 0.0006103 (0.0001419) (30, 28) 0.0008273 (0.0000740) 0.0020585 (0.0002764) 0.0006305 (0.0000400) 0.0006017 (0.0000733) (60, 7) 0.0006738 (0.0002826) 0.0005085 (0.0000557) 0.0004554 (0.0001790) 0.0006545 (0.0002807) (60, 14) 0.0010456 (0.0002915) 0.0007123 (0.0001254) 0.0008674 (0.0005314) 0.0007284 (0.0001981) (60, 21) 0.0011300 (0.0002376) 0.0007077 (0.0001503) 0.0010405 (0.0002846) 0.0008404 (0.0005486) (60, 28) 0.0015181 (0.0003672) 0.0013755 (0.0006623) 0.0009845 (0.0003440) 0.0008004 (0.0002936) (90, 7) 0.0011760 (0.0006906) 0.0005961 (0.0002675) 0.0005299 (0.0000354) 0.0009868 (0.0010842) (90, 14) 0.0026245 (0.0006215) 0.0011966 (0.0008937) 0.0015202 (0.0009906) 0.0007429 (0.0001703) (90, 21) 0.0018995 (0.0003939) 0.0011213 (0.0003460) 0.0011317 (0.0005927) 0.0012397 (0.0004427) (90, 28) 0.0039327 (0.0044482) 0.0009193 (0.0000588) 0.0012073 (0.0003054) 0.0007912 (0.0000699) T able B5: Multi-step forecast results for HCL TECH sto ck: T est MSE (mean and std. dev. ov er 5 different runs) (Input, Output) window MLP CNN GRU-RNN LSTM-RNN (30, 7) 0.0031963 (0.0007954) 0.0128769 (0.0019133) 0.0051413 (0.0010541) 0.0112670 (0.0021289) (30, 14) 0.0026673 (0.0010671) 0.0139527 (0.0055610) 0.0123741 (0.0021109) 0.0095371 (0.0062635) (30, 21) 0.0033571 (0.0017455) 0.0184534 (0.0016407) 0.0118404 (0.0023245) 0.0107927 (0.0043291) (30, 28) 0.0038904 (0.0016345) 0.0151611 (0.0020196) 0.0244928 (0.0057851) 0.0104605 (0.0035029) (60, 7) 0.0021283 (0.0014088) 0.0109632 (0.0021675) 0.0077522 (0.0041052) 0.0143966 (0.0060136) (60, 14) 0.0038363 (0.0016056) 0.0213113 (0.0066804) 0.0132269 (0.0031572) 0.0094325 (0.0038677) (60, 21) 0.0038672 (0.0013679) 0.0162212 (0.0083456) 0.0235211 (0.0040127) 0.0081314 (0.0040108) (60, 28) 0.0054724 (0.0022313) 0.0196803 (0.0112306) 0.0319193 (0.0048348) 0.0123502 (0.0060779) (90, 7) 0.0058540 (0.0025836) 0.0105892 (0.0029056) 0.0008600 (0.0007130) 0.0051682 (0.0030051) (90, 14) 0.0071620 (0.0033313) 0.0309257 (0.0070107) 0.0035058 (0.0028799) 0.0050845 (0.0028523) (90, 21) 0.0077732 (0.0048928) 0.0241231 (0.0102371) 0.0086925 (0.0014761) 0.0074075 (0.0057231) (90, 28) 0.0075716 (0.0064593) 0.0270582 (0.0119271) 0.0082987 (0.0017760) 0.0055403 (0.0024363) T able B6: Multi-step forecast results for HDF C stock: T est MSE (mean and std. dev. ov er 5 differen t runs) (Input, Output) window MLP CNN GRU-RNN LSTM-RNN (30, 7) 0.0014993 (0.0001856) 0.0022640 (0.0008543) 0.0004043 (0.0002280) 0.0016212 (0.0010235) (30, 14) 0.0029107 (0.0006320) 0.0035546 (0.0007540) 0.0008814 (0.0003569) 0.0008856 (0.0004405) (30, 21) 0.0046339 (0.0009452) 0.0056335 (0.0004270) 0.0008844 (0.0003937) 0.0006469 (0.0001056) (30, 28) 0.0056033 (0.0006032) 0.0082196 (0.0016140) 0.0017710 (0.0006404) 0.0011004 (0.0000466) (60, 7) 0.0024260 (0.0005739) 0.0034951 (0.0027383) 0.0012631 (0.0008066) 0.0017102 (0.0016013) (60, 14) 0.0034203 (0.0012190) 0.0047431 (0.0005306) 0.0012097 (0.0007921) 0.0013114 (0.0007453) (60, 21) 0.0066358 (0.0007448) 0.0081363 (0.0028405) 0.0008241 (0.0000640) 0.0014144 (0.0011814) (60, 28) 0.0065224 (0.0016475) 0.0119449 (0.0034957) 0.0013372 (0.0001863) 0.0012217 (0.0001187) (90, 7) 0.0023300 (0.0012620) 0.0090839 (0.0042322) 0.0033794 (0.0024053) 0.0021608 (0.0024645) (90, 14) 0.0054503 (0.0017082) 0.0099783 (0.0047804) 0.0014637 (0.0006768) 0.0012345 (0.0006202) (90, 21) 0.0077797 (0.0016669) 0.0115749 (0.0095457) 0.0010936 (0.0005853) 0.0009897 (0.0001870) (90, 28) 0.0095018 (0.0031604) 0.0112411 (0.0038547) 0.0017048 (0.0006377) 0.0011751 (0.0004205) 16 T able B7: Multi-step forecast results for INFY sto c k: T est MSE (mean and std. dev. ov er 5 differen t runs) (Input, Output) window MLP CNN GRU-RNN LSTM-RNN (30, 7) 0.0008039 (0.0002816) 0.0005298 (0.0000788) 0.0004394 (0.0001770) 0.0003833 (0.0000810) (30, 14) 0.0010837 (0.0006352) 0.0007653 (0.0002916) 0.0005086 (0.0001160) 0.0005351 (0.0000950) (30, 21) 0.0011262 (0.0002798) 0.0010261 (0.0001624) 0.0010603 (0.0002050) 0.0011424 (0.0001741) (30, 28) 0.0010185 (0.0002701) 0.0010253 (0.0002893) 0.0007198 (0.0001526) 0.0007297 (0.0000437) (60, 7) 0.0012397 (0.0001411) 0.0004898 (0.0002666) 0.0003308 (0.0001858) 0.0003605 (0.0000608) (60, 14) 0.0013622 (0.0007259) 0.0006215 (0.0001482) 0.0006564 (0.0001803) 0.0010193 (0.0004008) (60, 21) 0.0013731 (0.0007609) 0.0008720 (0.0001914) 0.0007246 (0.0000544) 0.0015434 (0.0000978) (60, 28) 0.0011040 (0.0000702) 0.0012745 (0.0002797) 0.0008392 (0.0001180) 0.0009567 (0.0002125) (90, 7) 0.0011997 (0.0006184) 0.0005635 (0.0005604) 0.0003365 (0.0000540) 0.0006026 (0.0002255) (90, 14) 0.0018267 (0.0007732) 0.0010913 (0.0006205) 0.0006243 (0.0000194) 0.0007335 (0.0000828) (90, 21) 0.0013901 (0.0009740) 0.0009851 (0.0002199) 0.0009886 (0.0000533) 0.0010992 (0.0000903) (90, 28) 0.0019559 (0.0012953) 0.0014412 (0.0003111) 0.0008899 (0.0000883) 0.0010402 (0.0001649) T able B8: Multi-step forecast results for JSWSTEEL sto ck: T est MSE (mean and std. dev. o ver 5 differen t runs) (Input, Output) window MLP CNN GRU-RNN LSTM-RNN (30, 7) 0.0008159 (0.0002204) 0.0015366 (0.0010747) 0.0007248 (0.0004859) 0.0010302 (0.0008532) (30, 14) 0.0012793 (0.0006275) 0.0008200 (0.0002332) 0.0011439 (0.0003228) 0.0010638 (0.0005344) (30, 21) 0.0009010 (0.0002266) 0.0008294 (0.0002427) 0.0008718 (0.0003286) 0.0007978 (0.0001207) (30, 28) 0.0014537 (0.0003449) 0.0008152 (0.0001385) 0.0014504 (0.0002590) 0.0015659 (0.0009209) (60, 7) 0.0006371 (0.0002588) 0.0035135 (0.0014058) 0.0010019 (0.0007528) 0.0005054 (0.0002913) (60, 14) 0.0015956 (0.0002350) 0.0038904 (0.0019989) 0.0008280 (0.0005101) 0.0010641 (0.0009801) (60, 21) 0.0015652 (0.0003992) 0.0023567 (0.0006488) 0.0007918 (0.0002060) 0.0009342 (0.0006045) (60, 28) 0.0022744 (0.0012208) 0.0024875 (0.0011985) 0.0010372 (0.0002349) 0.0011837 (0.0004319) (90, 7) 0.0011166 (0.0004300) 0.0035503 (0.0022253) 0.0004170 (0.0002284) 0.0005311 (0.0001889) (90, 14) 0.0016961 (0.0004295) 0.0049484 (0.0025952) 0.0005950 (0.0003462) 0.0006270 (0.0002636) (90, 21) 0.0019113 (0.0002832) 0.0041109 (0.0006370) 0.0007005 (0.0001861) 0.0006317 (0.0001386) (90, 28) 0.0023677 (0.0004270) 0.0038738 (0.0010972) 0.0009316 (0.0002275) 0.0015127 (0.0005895) T able B9: Multi-step forecast results for MAR UTI stock: T est MSE (mean and std. dev. o ver 5 differen t runs) (Input, Output) window MLP CNN GRU-RNN LSTM-RNN (30, 7) 0.0036446 (0.0014446) 0.0053164 (0.0022883) 0.1113903 (0.0217113) 0.0341339 (0.0091429) (30, 14) 0.0044910 (0.0008551) 0.0064419 (0.0009121) 0.0659209 (0.0611601) 0.0559117 (0.0358284) (30, 21) 0.0084389 (0.0010078) 0.0082142 (0.0006503) 0.0914546 (0.0711125) 0.0430067 (0.0210945) (30, 28) 0.0124981 (0.0037026) 0.0187498 (0.0043378) 0.0661392 (0.0479253) 0.0643477 (0.0320369) (60, 7) 0.0084413 (0.0036564) 0.0144930 (0.0102842) 0.0265717 (0.0219347) 0.0376275 (0.0094258) (60, 14) 0.0085299 (0.0031797) 0.0139296 (0.0035586) 0.1302003 (0.1588328) 0.0374050 (0.0193156) (60, 21) 0.0123392 (0.0037315) 0.0308576 (0.0071213) 0.0778246 (0.0261484) 0.0631713 (0.0226513) (60, 28) 0.0151471 (0.0025340) 0.0617911 (0.0132642) 0.0619888 (0.0188969) 0.0508528 (0.0106388) (90, 7) 0.0121688 (0.0057908) 0.0139867 (0.0067465) 0.0188332 (0.0087000) 0.0335358 (0.0163816) (90, 14) 0.0152392 (0.0052767) 0.0332158 (0.0108789) 0.0510381 (0.0252156) 0.0399558 (0.0212659) (90, 21) 0.0204686 (0.0027830) 0.0607542 (0.0224152) 0.0411452 (0.0110080) 0.0650783 (0.0372264) (90, 28) 0.0206555 (0.0054890) 0.0627885 (0.0128993) 0.0401244 (0.0165746) 0.0865678 (0.0323832) 17 T able B10: Multi-step forecast results for UL TRACEMCO sto ck: T est MSE (mean and std. dev. o ver 5 differen t runs) (Input, Output) window MLP CNN GRU-RNN LSTM-RNN (30, 7) 0.0020023 (0.0002984) 0.0026930 (0.0005455) 0.0033386 (0.0020864) 0.0017219 (0.0006294) (30, 14) 0.0024367 (0.0001538) 0.0033537 (0.0001399) 0.0044677 (0.0010579) 0.0019778 (0.0005814) (30, 21) 0.0033515 (0.0001442) 0.0037870 (0.0001854) 0.0056589 (0.0037724) 0.0027700 (0.0002355) (30, 28) 0.0038125 (0.0004258) 0.0039539 (0.0000881) 0.0045104 (0.0012098) 0.0030197 (0.0002363) (60, 7) 0.0024746 (0.0002628) 0.0042345 (0.0016226) 0.0031997 (0.0014948) 0.0017283 (0.0005668) (60, 14) 0.0034616 (0.0005681) 0.0046157 (0.0013290) 0.0048650 (0.0016006) 0.0022667 (0.0006604) (60, 21) 0.0034066 (0.0003507) 0.0045258 (0.0005243) 0.0031052 (0.0005199) 0.0023807 (0.0003801) (60, 28) 0.0040590 (0.0002551) 0.0049600 (0.0005849) 0.0098274 (0.0039146) 0.0030861 (0.0002780) (90, 7) 0.0040636 (0.0011404) 0.0090143 (0.0035609) 0.0025351 (0.0015730) 0.0020238 (0.0007153) (90, 14) 0.0044154 (0.0006285) 0.0063803 (0.0038330) 0.0079744 (0.0019826) 0.0020690 (0.0004533) (90, 21) 0.0047966 (0.0007563) 0.0052869 (0.0008835) 0.0075306 (0.0049383) 0.0025133 (0.0002801) (90, 28) 0.0059788 (0.0006318) 0.0066679 (0.0017524) 0.0163860 (0.0097798) 0.0029608 (0.0003193) (a) inp w = 30 , output w = 7 (b) inp w = 30 , output w = 28 (c) inp w = 60 , output w = 7 (d) inp w = 60 , output w = 28 (e) inp w = 90 , output w = 7 (f ) inp w = 90 , output w = 28 Figure B1: Multi-step forecasting plots for ACC dataset for each deep mo del against the true prices for differen t window size combinations( w ). Due to reason of space, W e are unable to provide the plots for the output window sizes: 14 and 21. 18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment