Astraea 불균형 연합학습을 스스로 균형 맞추는 프레임워크
본 논문은 모바일 및 IoT 환경에서 데이터가 클래스별로 불균형한 상황이 연합학습(Federated Learning)의 정확도 저하를 초래한다는 점을 실증한다. 이를 해결하기 위해 전역 데이터 분포 기반 데이터 증강과 클라이언트 간 Kullback‑Leibler Divergence(KLD)를 이용한 중재자(mediator) 기반 재스케줄링을 결합한 Astraea 프레임워크를 제안한다. 실험 결과, 기존 FedAvg 대비 EMNIST와 CINIC…
저자: Moming Duan, Duo Liu, Xianzhang Chen
연합학습(Federated Learning, FL)은 모바일 디바이스와 IoT 기기들이 개인 데이터를 로컬에 보관한 채 공동으로 딥러닝 모델을 학습하도록 설계된 분산 학습 패러다임이다. 기존 FL 연구들은 주로 통신 효율성 향상이나 프라이버시 보호에 초점을 맞추었으며, 데이터가 IID(동일 분포)라는 가정을 전제로 했다. 그러나 실제 엣지 환경에서는 디바이스별 사용 패턴 차이로 인해 데이터가 크게 불균형하게 분포한다. 이러한 불균형은 크게 두 차원으로 나뉜다. 첫째, ‘Local Imbalance’는 각 디바이스가 보유한 샘플 수와 라벨 비율이 서로 다름을 의미한다. 둘째, ‘Global Imbalance’는 전체 디바이스가 모여 만든 데이터셋 자체가 특정 클래스에 편중되는 상황을 말한다. 논문은 특히 후자를 간과한 기존 연구와 달리, 전역 클래스 불균형이 모델 정확도에 미치는 영향을 정량적으로 분석한다.
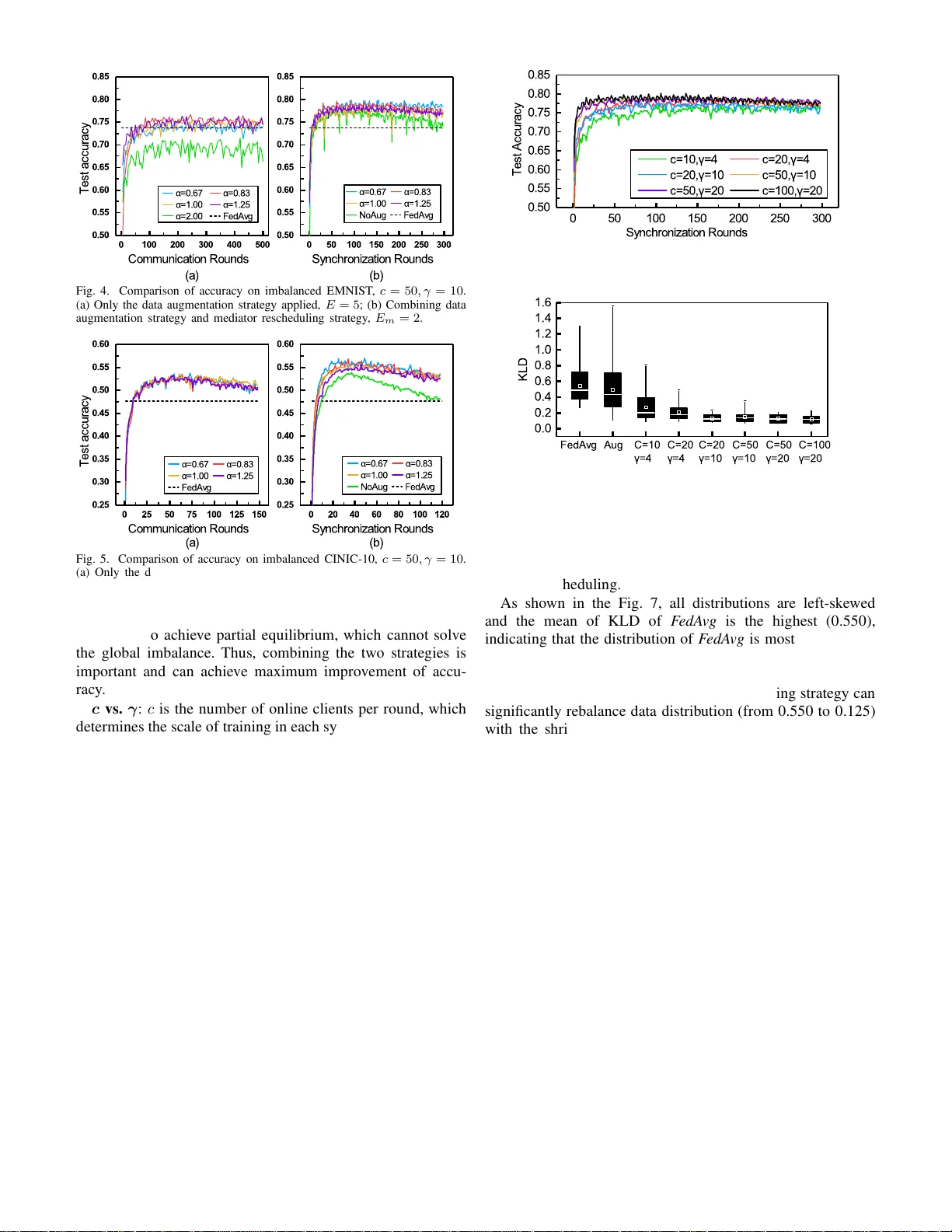
EMNIST와 CINIC‑10을 기반으로 다섯 개의 불균형 데이터셋(BAL1, BAL2, INS, LTRF1, LTRF2)을 구축하였다. BAL1·BAL2는 로컬 균형을 유지하지만 전역 클래스 비율이 균등한 반면, INS는 스칼라(샘플 수) 불균형, LTRF1·LTRF2는 영어 알파벳 사용 빈도에 따라 전역 클래스 비율을 왜곡한 데이터셋이다. 동일한 CNN 구조(3개의 Conv 레이어와 2개의 Dense 레이어, 총 68,873 파라미터)와 FedAvg 설정(클라이언트 500명, 각 라운드 10% 선택, 로컬 에폭 10, 배치 20)으로 실험한 결과, 전역 불균형이 있는 LTRF1·LTRF2에서 Top‑1 정확도가 각각 7.92%·6.20% 감소하였다. 반면, 로컬 불균형만 존재하는 INS에서는 정확도가 약간 상승했다. 이는 전역 데이터 분포와 테스트 데이터 분포(p_test)가 일치하지 않을 때, FedAvg이 최적 가중치 w*에 수렴하지 못한다는 수학적 증명(식 1‑6)과 일치한다.
이러한 문제를 해결하기 위해 제안된 Astraea 프레임워크는 두 가지 핵심 메커니즘을 도입한다. 첫 번째는 ‘Global Data Distribution based Data Augmentation’이다. 전체 클래스 비율을 사전에 추정하고, 소수 클래스에 해당하는 이미지에 회전, 색상 변환, 노이즈 추가 등 기존 이미지 증강 기법을 적용한다. 증강된 데이터는 각 클라이언트가 로컬 학습 시 자동으로 포함되며, 별도의 데이터 전송이 필요 없으므로 프라이버시와 통신 비용을 동시에 보존한다. 두 번째는 ‘Mediator based Multi‑client Rescheduling’이다. 서버는 각 클라이언트의 라벨 분포를 수집하고, 이를 균일 분포와 비교해 Kullback‑Leibler Divergence(KLD)를 계산한다. KLD가 높은 클라이언트는 학습 우선순위를 낮추고, KLD가 낮은 클라이언트를 먼저 선택해 라운드에 참여시킨다. 이렇게 구성된 ‘mediator’는 여러 클라이언트를 그룹화하고, 그룹 내 KLD 평균을 0.2 이하로 낮추어 로컬 불균형을 동적으로 완화한다.
Astraea의 전체 학습 흐름은 다음과 같다. (1) 서버는 전역 클래스 분포를 추정하고, 증강 정책을 정의한다. (2) 각 클라이언트는 로컬 데이터와 증강된 데이터를 합쳐 로컬 SGD(Adam, η=0.001)로 학습한다. (3) 클라이언트는 업데이트된 모델 파라미터와 라벨 분포 정보를 서버에 전송한다. (4) 서버는 KLD를 기반으로 mediator를 구성하고, 라운드마다 선택할 클라이언트 집합을 재조정한다. (5) 선택된 클라이언트들의 파라미터를 FedAvg 방식으로 평균해 글로벌 모델을 업데이트한다. 이 과정을 목표 정확도에 도달할 때까지 반복한다.
실험에서는 Astraea가 기존 FedAvg 대비 EMNIST에서 Top‑1 정확도를 5.59% 향상시키고, CINIC‑10에서는 5.89% 향상시켰다. 또한 동일 75% 정확도 달성 시 통신 라운드 수가 FedAvg 대비 92% 감소했으며, 전체 전송 데이터 양도 82% 이상 절감되었다. 특히, mediator 재스케줄링이 적용된 경우 평균 KLD가 0.2 이하로 유지돼 로컬 불균형이 모델에 미치는 부정적 영향을 크게 억제했다.
결론적으로, Astraea는 (1) 전역 클래스 불균형을 데이터 증강으로 사전 보정, (2) 로컬 라벨 불균형을 KLD 기반 mediator 재스케줄링으로 동적 완화, (3) 통신량을 최소화하는 세 가지 설계 목표를 동시에 달성한다. 이는 모바일 및 엣지 환경에서 연합학습을 실제 서비스에 적용할 때 데이터 불균형과 통신 비용이라는 두 핵심 장애물을 동시에 해결할 수 있음을 보여준다. 향후 연구에서는 보다 복잡한 비동기식 FL 시나리오, 다양한 모델 아키텍처, 그리고 프라이버시 강화 기술(예: 차등 개인정보 보호)과의 통합을 통해 Astraea의 적용 범위를 확대할 수 있을 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기