Astraea: Self-balancing Federated Learning for Improving Classification Accuracy of Mobile Deep Learning Applications
Federated learning (FL) is a distributed deep learning method which enables multiple participants, such as mobile phones and IoT devices, to contribute a neural network model while their private training data remains in local devices. This distribute…
Authors: Moming Duan, Duo Liu, Xianzhang Chen
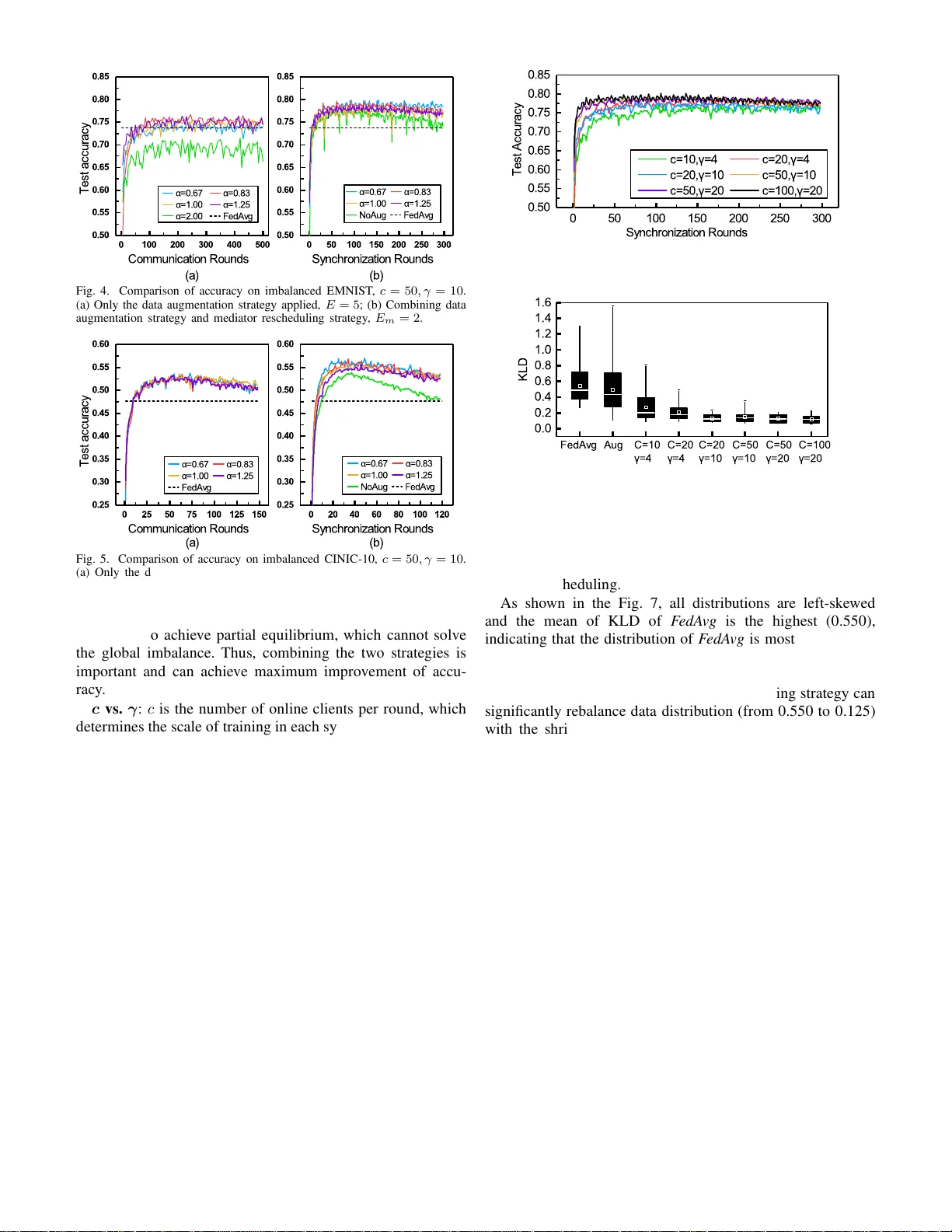
Astraea: Self-bala ncing Federated Learning for Impro ving Classificat ion Accurac y of Mobile Deep Learning Applications Moming Duan ∗ , Duo Liu ∗ , Xianzha ng Chen ∗ , Y ujuan T an ∗ , Jinting Re n ∗ , Lei Qiao † , Liang Liang ∗ ∗ College of Comp u ter Science, Chon gqing Univ ersity , Chon gqing, China † Beijing Institute of Control Eng ineering, Beijing, China Abstract —Federa ted learning (FL) is a distributed deep learn- ing method which enables multiple participants, such as mobile phones and IoT d evices, to contribute a neural network model while their private training data remains in l ocal devices. This distributed approach is promising in the edge computing system where ha v e a large corpus of decentralized data and r equire high priva cy . Ho wev er , unl i ke th e com mon trainin g d ataset, the data distribution of the edge computi ng system is imbalanced wh i ch will introduce bi ases in th e model training and cause a decrea se in accuracy of federated learning app lications. In this paper , we demonstrate that the imbalanced distributed training data will cause accuracy degradation in FL. T o counter thi s problem, we build a self-b alancing federated learning framework call Astraea, which alleviates the imbalances by 1) Global data distribution based data augmentation, and 2) Mediator based multi-cli ent rescheduling. The p roposed framework relie ves global imbalance by runtime data augmentation, and for av eraging the local imbalance, i t creates the mediator to reschedule the training of clients b ased on KullbackLeibler d iv ergence (KLD) of their data distribution. Compar ed wi th F edA vg , the state-of-the-art FL algorithm, Astraea sh ows +5.59% and +5.89% improv ement of top-1 accuracy on the imbalanced EMNIST and imbalanced CINIC-10 datasets, respectively . Meanwhi le, the communication traffic of Astraea can be 92% lo wer than that of F edA vg . I . I N T R O D U C T I O N Federated Learnin g (FL) is a promising distributed neu ral network training ap proach for deep lea r ning applicatio ns such as image classification [1] and natu re languag e process [ 2]. FL enables the mobile devices to collabor ati vely train a shared neural network m odel with the training data distributed on the local de vices. In a FL application , any mobile device can participate in the neural network model training task as a client. Each client ind e pendently tr ains the neural network model based on its local data. A FL server then av erages the models’ u pdates from a r andom subset of FL clients and aggregates them in to a new global mo del. In this way , FL no t only ensures priv acy , costs lower latency , but also makes the mobile ap plications adaptive to the change s o f its da ta . Nev ertheless, a main challenge of the mobile feder ated learning is that the training data is unevenly distributed on the m obile d evices, which results in lo w pr ediction accu racy . Sev eral efforts have been made to tackle the ch allenge. McM a - han et al. pro pose a commun ication-efficient FL algorithm Correspondi ng aut hors: Duo Liu and Y ujuan T an, College of Computer Science , Chongqing Uni ver sity , Chong qing, China. E-mail: { liu duo, tan yujuan } @cqu.edu.cn. F ederated A veraging (F edA vg) [3], and show that the CNN model tr ained b y FedA vg can achieve 99% test accura cy on non-I ID MNIST d ataset, i.e., any particular user of the local dataset is not represen tati ve of the pop ulation distribution. Zhao et a l. [4] poin t out that the CNN model trained by F edA vg o n non -IID CIF AR-10 d ataset has 37% accuracy loss. Existing stud ie s assume that the expectation of the global data distribution is balanced ev en tho ugh the volume of data on the de vices may be dispr oportion ate. In mo st real scenarios o f d istributed mobile d evices, howe ver , the global data distribution is imbalanced. In th is paper, we co n sider o n e mor e type o f imbala n ced distribution, named glo bal imbalan ced, of distrib uted trainin g data. In global imbalanced distrib ution, the collection of d is- tributed data is class imb a lanced. W e draw a global imbalan c ed subset from EMNIST dataset and explo re its impact on the accuracy of FL in Section II-B. The exper imental results show that the global imbalan ced training data leads to 7.92% accuracy loss fo r F edA vg . The accuracy degrad ation caused by imbalan ces drives us to design a novel self-balancin g fed erated learning fr amew ork, called Astraea. The Astraea fr a m ew ork co unterweigh s the training of FL with imbalanced datasets by two strategies. First, befo r e tra in ing the mod e l, Astraea p e rforms data aug- mentation [5] to alleviate g lobal imbalance . Seco nd, Astraea propo ses to use some mediators to reschedu le the training of clients according to the KLD betwee n the mediators and the unifor m distribution. By combin in g the training of ske wed clients, the m e d iators may be able to achieve a new pa rtial equilibriu m . W ith th e above m ethods, Astraea improves 5.59% top-1 accuracy on the imbalan ced EMNIST a nd 5. 8 9% on imb al- anced CINI C-10 [6] over F ed A vg . Our rescheduling strategy can significa n tly reduce the impact of local imbalanc e an d decrease the m ean of the KLD between the mediato rs and the unifor m distribution to below 0.2. The pr oposed framework is also comm unication- efficient. For example, the experimenta l results show that Astrae a can redu ce 92 % com m unication traffic than that of F edA vg in achieving 75% accuracy on imbalanced EMNI ST . The ma in contributions of this pap er are summarized as follows. • W e first find o ut tha t the global im balanced training data will degrade the accuracy o f CNN models trained by FL. • W e prop ose a self-balan cing federa te d learn ing frame- work, Astraea, along with two strategies to prevent the bias of training caused by imbalanced data distribution. • W e im plement and measure the pr oposed Astraea b ased on the T ensorflow Federated Frame work [7]. Th e exper- imental results show that Astrae a can ef ficiently retrieve 70.5% acc u racy loss on imbalanced EMNI ST and retrieve 47.83 % a ccuracy loss on imbalanced CINIC-10 dataset. I I . B A C K G RO U N D A N D M O T I V AT I O N A. Bac kgr ound Federated lea rning . FL is propo sed in [3], whic h includ es the mo del agg regation algo rithm F edA vg . In th e FL system, all clients calculate and update their weights using asy n chrono us stochastic gr adient descent (SGD) in p arallel, then a server collects the upd ates of clients and aggregates the m using F edA vg algorith m. W ith the distributed tra in ing method, a number of mobile deep learning applications b ased on FL have recen tly emerged. Hard et al. [8] improve the n ext word prediction s o f Google keyboard thro ugh FL. Bonawitz et al. [9] b uild a large scale FL sy stem in th e domain of mobile devices. Recent research on fed erated lea r ning h as fo cused on re- ducing co m munication overhead [3], [10]–[1 2] and pro te c tin g priv acy [1 3]–[1 6], but only a f ew studies hav e noticed the problem of accuracy degradation due to imbalanc e [ 4], [17]. Howe ver , [3], [ 4], [17] on ly discuss the impact of local imbalanced data and a ssume the g lobal data distribution is balanced, which is rare in the distributed mobile sy stem . Imbalanced data lea rning . Most real-world classification tasks have class imbalance wh ich will inc rease the bias o f machine learning algor ithms. Lear n ing with imbalanced dis- tribution is a c lassic prob lem in the field of data scien ce [1 8], and its main solutions are sampling and ensemble le a r ning. Undersamp ling method samples th e dataset to get a balanced subset, wh ich is ea sy to impleme n t. This meth o d requires a large data set while the loca l database of the FL clien t is usually small. Chawla et a l. propo se an over-sampling method SMO TE [19], which can generate min ority classes samples to rebalan c e the dataset. Han et al. impr ove SMO TE by consider ing th e data distribution of mino rity classes [20]. Howe ver , the above method is unsuitab le for FL, beca u se the data of clien ts is distributed and priv ate. Some ensemble methods, such as AdaBoost [21] and Xgb oost [22], can learn from m isclassification and reduc e b ias. Howe ver these machine lea r ning algo rithms are sensitiv e to noise and ou tliers, which are common in th e distributed dataset. B. Motivation Federated learning is design e d to b e widely d eployed o n mobile phon es and IoT devices, where e a c h device trains model u sin g its local data. It means th at the data distribution of different devices depend s on their usages wh ich ar e likely to b e different. For examp le, cameras deployed in th e school capture more human pictures th an the cameras d eployed in the wild. Furthermo re, ano ther kind of imbalan ce is class imbalance in the collection o f distrib uted data, such as the word f r equency T ABLE I S E T T I N G S O F D I S T R I BU T E D E M N I S T D ATAS E T . T ypes of Data Distrib ution Sample Size Notatio n Scalar Global Local Tra in/T est B AL1 Even Balanc ed Balanc ed 117500/18800 B AL2 Even Balanc ed Random 117500/18800 INS Instagram uplo ads Bala nced Rando m 11750 0/18800 L TRF1 Instagram uplo ads Lette rs frequenc y Random 117500/18800 L TRF2 Instagram uplo ads Lette rs frequenc y Random 230752/18800 of English literatu re ( following Zipf ’ s law [23]). I n o rder to distinguish between these imbalances in federated learning, we summarize ab ove cases into three categorie s: 1) Size Imbalance , wh ere the da ta size on each device (or client) is uneven; 2) Local I m balance, i.e., independ ent and non- identically distribution (n on-IID) , wher e each d evice d oes not follo w a common d ata distribution; 3) Global Imbalance, means that the co llection of data in all devices is class imbalanced . T o clarify the impact of im balanced training data on f ed- erated learn in g, we u se the FL fra m ew ork to tr ain con- volutional neur al networks ( CNNs) based on a imb alanced dataset. Howev er , sinc e there is no large distributed im age classification data sets, we build n ew distributed d atasets b y resampling EMNI ST [24] dataset. E MNIST is a image class- fication dataset which contains 47 c la ss of h andwritten Eng lish letters and digits. Althoug h there h as a feder ated version called FEMNIST [25], some unaccoun ted imbalances contain e d in training set a nd test set. Imbalance dat aset . W e build five distributed EMNIST datasets: B AL1, B AL2, INS, L TRF1 and L TRF2, th e detail settings are shown in T ABLE I. BAL1 and B AL2 a re b oth scalar balan ced and g lobal calss balanced , the difference is B AL1 is local balan c e d and th e local distribution of B AL2 is ran dom. INS is a scalar imbalanced dataset an d the client data size is following the images uploads number of In stagram users [2 6]. L TRF1 and L TRF2 futher have glob al imbalance by making the g lobal class distribution following the frequ ency of the English letters, which is obtained through a corpus of the Simple En glish W ikipedia(504 41 articles in total). In addition, the training data size of L TRF2 is alo most twice th an of L TRF1. Note that there is no ide n tical sample b etween any clients an d the test set is balanced . Model architecture . The imp le m ented CNN model h as three co n volution laye r s and two dense lay e r s: the first two conv olution layers have 1 2 and 1 8 chann els, 5 × 5 and 3 × 3 kernel size (strides is 2), respectively . Above covolution laye r s followed by a dr opout [27] with keep pr obability 0.5; T he third conv olution lay er has 2 4 channels, 2 × 2 kernel size (strides is 1 ) a nd fo llowing a flatten ope r ation. The last two de n se layers are a fully connected layer with 150 u n its activ ated b y ReLu an d a softm ax outpu t layer . By the way , the loss fun ction is categorical cross-entropy and the metric is top-1 accuracy . This CNN mod el h as total 68 , 873 p arameters and can ach iev e 87.85 % te st accuracy after 20 e pochs on EMNIST . FL settings . W e use the same n otation for feder ated learn in g settings as [3]: the size B o f lo cal mini b atch is 20 and the local epochs E is 10 . Th e total number of clients K is 500 and the fra ction C of clien ts that perfo rms computation on 0 1 0 0 2 0 0 3 0 0 4 0 0 5 0 0 0 . 6 0 0 0 . 6 2 5 0 . 6 5 0 0 . 6 7 5 0 . 7 0 0 0 . 7 2 5 0 . 7 5 0 0 . 7 7 5 0 . 8 0 0 0 . 8 2 5 0 . 8 5 0 ( c ) ( b ) T e s t A c c u r a c y C o m m u n i c a t i o n R o u n d s B A L 1 B A L 2 I N S L T R F 1 L T R F 2 ( a ) 0 1 0 2 0 3 0 4 0 1 9 2 6 3 3 3 5 4 0 4 4 P r e d i c t e d L a b e l T r u e L a b e l 0 1 0 2 0 3 0 4 0 1 9 2 6 3 3 3 5 4 0 4 4 P r e d i c t e d L a b e l T r u e L a b e l 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 Fig. 1. Accuracy and confusion matrixe s on distribu ted EMNIST . (a) T est accurac y versus communicatio n rounds on distrib uted EMNIST ; (b) Comparison betwee n the confusion matrixes of CNN models tra ined on B AL1 dataset and (c) L TRF1 dat aset. each round is 0.05 . For local training , each clien t updates the weights via Adam [28] optimizer with learnin g rate η = 0 . 001 and no weight decay . The test top -1 accura cy on fiv e distributed EMNIST is shown in Fig. 1(a). Ex p erimental results sho w that the global im balance leads to a significant decrease in accuracy . Qualitativ ely , th e accuracy on B AL1 and BAL2 is 79.99% and 80.1 3%, respectiv ely . For th e global imb alanced dataset L TRF1, 7.92% reduction in accuracy c o mpared to INS1 was observed ( from 81.6 0 % to 7 3.68%). For L TRF 2, 6.2 0 % re - duction in accu racy co m pared to INS1 was observed (from 81.60 % to 75.4 0%) although L TRF2 has twice amoun t of training d a ta than L TRF1. In addition , the ra n dom local imbalance d oes n o t lead to accuracy degradation and the test accuracy is slightly impr oved in scalar imbalan ce case (fr om 79.99 % to 81.60 %). In or der to eluc id ate the influen ce of glob al imbalance on the m o del, Fig. 1(b) and Fig. 1 ( c) show th e con fusion matrixes of BAL1 and L TRF1. The meaning of labels is the same as EMNIST , labels 0 to 9 correspon d to digitals, labels 10 to 46 correspo n ding English letters (15 letters are merged a c cording to [24]). As shown in the confusion m a trix of B AL1, most images are classified correctly , wh ich is represented in the confusion matrix as most of the b lue squares spread over the diago nal. Ho wev er , fo r the confu sio n matrix of L TRF 1, 6 classes o f imag es (which correspo nd to the 6 letters with the lowest fr e quency in English writings) are no t well classified as shown by the gr ay line s. Du e to the global imbalance d training set, the CNN models are more biased to wards c lassify ing the majority classes samples. In summary , glo bal imbalance will cause an accuracy loss of the mo del trained thro ugh FL. The ma in challenge of th e mobile FL application s is to train n eural networks in th e various distributed data distribution. Note th at uplo ading o r sharing user s’ local data is not optio nal because it exposes user data to priv acy risks. T o ad dress the challen ge, we put forward a self-balancin g federated lear n ing fr a mew ork named Astraea, which im p roving classification accura cy by g lo bal data distrib ution based data aug mentation and mediator based multi-client r escheduling . I I I . D E S I G N O F A S T R A E A As aforementio ned, the p recision o f fe d erated learnin g on the distributed imbalanced d ataset is lower than th at o n the balanced dataset. T o find ou t th e cause of the decline in the accuracy , we mathematically prove that the imbalance of distributed train ing data can lead to a d ecrease in accur a cy of FL app lications. Based on this conclusion, we design the Astraea framework, the goal of which is to relie ve th e global imbalance and local imb a lance of clien ts data, and recover the accuracy . A. Mathematical Demonstration W e define the pro blem of federated learnin g training on imbalanced dataset that leads to precision degradatio n. T o show th e accura cy degradation in f ederated learning , we u se traditional SGD-b ased deep le a r ning [29] as th e ideal c ase an d derive the up date formu la of o ptimal weights. For SGD-based deep lear n ing, the op timization objective is: min w E ( x , y ) ∼ ˆ p data L [ f ( x ; w ) , y )] , (1) where L a n d ˆ p data are the loss function an d the distribution of training data, respec tively . Since the goal is to m in imize the te st loss, we a ssum e ˆ p data = p test , wh ere p test means the distribution o f test set that is balanced for image classification tasks. Both SGD-based d eep learn ing and f ederated learn ing use the same test set. W e assume th at the initial weigh ts for SGD-based deep learning an d federated lea rning are the same: w ( k ) 0 = w 0 = w ∗ 0 . (2) The o ptimal w e ig hts of SGD- based d eep learnin g is upd ated by: w ∗ t +1 = w ∗ t − η ∇ w ∗ t n X i =1 L ( f ( x ( i ) ; w ∗ t ) , y ( i ) ) , ( x ( i ) , y ( i ) ) ∼ p test . (3) Because w ∗ is the w e ights that achieves the b est ac c uracy on the test set, so it is the optimal weights of fed e rated learning too. For fed erated learning , the optimization o b jectiv e is: min w E ( x , y ) ∼ ˆ p ( k ) data L [ f ( x ; w ( k ) ) , y )] , k = 1 , 2 , ..., K . (4) where ˆ p ( k ) data means the training data distrib ution of any client k . Given any client k , th e corre sponding training da ta d istribu- tion ˆ p ( k ) data is imbalanced for the considered fede rated learning . w ( k ) is the weights of client k . The weights of each client k that is optimized by gr adient descent with learn ing rate η is updated by : w ( k ) t +1 = w ( k ) t − η ∇ w ( k ) t 1 n k n k X i =1 L ( f ( x ( i ) ; w ( k ) t ) , y ( i ) ) , ( x ( i ) , y ( i ) ) ∼ ˆ p ( k ) data . (5) The weights of federated learning server is calculated by the F edA vg [3] alg orithm: w ( Avg ) t +1 = K X k =1 n k n w ( k ) t +1 , = K X k =1 n k n w ( k ) t − η n ∇ w ( k ) t n k X i =1 L ( f ( x ( i ) ; w ( k ) t ) , y ( i ) ) , ( x ( i ) , y ( i ) ) ∼ ˆ p ( k ) data . (6) Since ˆ p ( k ) data 6 = p test , we have w ( Avg ) t +1 6 = w ∗ t +1 , which means that federated learnin g cannot achiev e optimal weights when training data distribution is imbalanced. Next, we prove that federated learning c a n r estore the accuracy of models if co ndition ˆ p ( k ) data = p test is satisfied by mathematical indu ction. Pr oposition: w ( Avg ) t = w ∗ t is true f o r t is any non -negativ e integer and ˆ p ( k ) data = p test . Proof : Basis case : Statement is tru e for t = 0 : w ( Avg ) 0 = K X k =1 n k n w 0 = w ∗ 0 . (7) Inductive assumption : Assum e w ( Avg ) t = w ∗ t is true f or t = µ and ˆ p ( k ) data = p test , µ ∈ Z + . Then, for t = µ + 1 : w ( Avg ) µ +1 = K X k =1 n k n w ∗ µ − η n ∇ w ∗ µ n X i =1 L ( f ( x ( i ) ; w ∗ µ ) , y ( i ) ) , = w ∗ µ − η ∇ w ∗ µ L ( f ( x ( i ) ; w ∗ µ ) , y ( i ) ) = w ∗ µ +1 , ˆ p ( k ) data = p test . (8) Therefo re, b y indu c tion, the statement is proved. According to the above conclusion, the dif ference between the distributions of the training set and test set accounts f or the accuracy degradation of federated learning. Theref ore, to achieve a new par tial equilibriu m, we propo se the Astraea framework to augmen t mino rity classes an d create mediators to combin e the ske wed d istribution of m ultiple clients. The details of Astraea are shown in the next section. B. Astr aea F r amework In o rder to solve the pro b lem o f accu r acy d egradation, the tr a ining data o f each client should be reb a lanced. An instinct meth od is to re distributing the clients’ local data until the distribution is unifor m. Howe ver , sharin g data r a ises a priv acy issue and cause high commu nication overhead. Another way to rebala n ce training is to update the glob al model asynchr onously . E ach client calculates u p dates based on th e latest global mo d el and applies its upd ates to the glob al model seque ntially . It means th at the commun ication overhead and time consu m ption of the method is K times that of the federated learnin g (FL). Combining the above two id e as, we propo se Astraea, which intro duces mediators b etween the FL server and clients to rebalanc e training. ,2 9KX \KX 3 K J O G Z U X 3K JOGZUX 3 K J O G Z U X 3K JOG Z UX 3 K J O G Z U X 3KJ OGZUX ɧ ] ] ] ɧ ] ] ɧ ] ] ] ɧ ] ɧ ] ] ɧ ] ɧ ] ɧ ] ɧ ] ,KJK XGZ KJ' \KXG MO TM 8KH G R GTIK J )ROKT ZY 'Y _TINXU T U[ Y ;V J GZK 9_T I N X U TU [ Y ;V J GZK ] ] GXMS OT Q * 12 6 S 6 Q bb 6 [ 8KY INKJ[ R OTM Ȝ ] ' ( ) * + , - . 4 Ȝ Fig. 2. Astraea Frame w ork Overvi e w . The overvie w of the pr o posed Astraea framework is sh own in Fig. 2. Astraea c o nsists three parts: FL server , mediator, and clients. The FL server is respon sible f o r maintainin g a global model w 0 , deploying the mo del to m ediators, and synchro n ously aggr egatin g the upd a tes ∆ w 4 , ∆ w 7 , ∆ w 8 (as shown in Fig. 2 ) from them usin g th e federated averaging al- gorithm. The clients can be mo bile phones or I oT de vices that maintain a local train ing dataset. The four shapes in the c lien ts represent four classes o f data. The clients can b e di vided into three categories accor ding to their data distribution: • Uniform clien ts, which hav e eno u gh b alanced training data and a r e ready to run FL ap plications (e.g. clien t E and F in Fig. 2) . • Slight clients, which have relatively small amou nts of d a ta and are hard to particip ate in the training process. • Biased clients, which h ave enough training data but pre f er to hold cer tain classes of data which leads to a glob al imbalance (i.e. client A-D, G, H). In short, th e slight clients and biased clients introdu ce scalar imbalance and global imbalanc e resp ecti vely . Mediators h ave two jobs. On e is to reschedu le the trainin g processing of the three kin ds of clien ts. For example, as shown in Fig. 2, client G h as d ata with label 0 an d label 1, mean while client H has data with label 2 and label 3. Then, the mediator can combine the training of G and H to archive a pa rtial equilibriu m . Mediators also need to make the distribution of th e co l- lection of data close to th e u niform. T o mea sure the extent of partial equilibr ium, we using KullbackLeib ler divergence /TOZO GRO`GZ OUT 3K JOG Z UX 3K JOG Z U X / T OZOG RO `K ] KOM N Z Y / T OZOG RO `K U VZOSO`K X *OY Z XOH [ ZO U T Y Z GZ OY Z OIY :X G O TOTM :X G O TO T M :X G O TOTM :X G O TO T M ;VJ G ZK *GZ GG [ MS K T Z *GZ G G[MS K T Z *GZ G G[MS K T Z *GZ G G[MS K T Z ;V JG ZK ,KJ' \M , 2 9K X \KX )RO KTZ' 8KHGR GTIOTM :X GOTOTM 'MMX KMGZO U T )RO KTZ ( )RO KTZ ) )RO KTZ * 9_ TIN X UT O`G Z O UT8U[ T J ) U SS [ T OI G Z O U T 8 U [ T J Ś ś Ŝ ŝ ŝ Ş ş 2 UIGR+VU I N 3 KJOGZ U X +V U IN Š Fig. 3. Astraea W orkflow . Reba lance the training by data augmentation( ➁ ) and mediator based resch eduling ( ➂➃ ). Algorithm 1 Astraea distrib uted neur al network training . 1: procedure F L S E RV E R T R A I N I N G 2: Initialize w 0 , w 1 ← w 0 . 3: fo r each synchronization r ound r = 1 , 2 , ..., R do 4: fo r each mediator m in 1 , 2 , ..., M parallelly d o 5: ∆ w m r +1 ← MediatorUpdate ( m, w r ). 6: w r +1 ← w r − P M m =1 n m n ∆ w m r +1 . // F edA vg . 7: function M E D I A T O R U P DAT E ( m, w ) 8: w ∗ ← w . 9: fo r each mediator epoch e m = 1 , 2 , ..., E m do 10: f or each clients i in mediator 1 , 2 , ... , M do 11: for each l ocal epoch e = 1 , 2 , ..., E do 12: // A synch r onou s SGD . 13: w e ← w − η ∇ ℓ ( w ; X ( i ) , Y ( i ) ) . 14: w ← w e . 15: ∆ w ← w − w ∗ . 16: retur n ∆ w between P m + P k and P u , where P m , P k , P u means the probab ility distributions of mediato r , reschedu lin g client, and unifor m distribution, r espectiv ely . In addition , by co mbining multi-client training , a m ediator can expand the size of the training set and learn mo re patterns th an a separate clien t. Note that the me d iators are virtual compo nents, it can be dep loyed directly on the FL server or the mobile edge com puting (MEC) server to red u ce commu nication overhe ad. Algorithm 1 shows the training p rocess o f Astraea. First, the FL server needs the initialization weights as the global m odel to start the training. Then, the FL server starts a new rou nd r of training and sends the global model to the mediators. Next, each med iator m coord inates the assigned clients f or trainin g and calculate s the up d ates of weights ∆ w m r +1 in parallel. Finally , the FL server co llects the u p dates of a ll m ediators, aggregates the updates with th e weig ht o f n m /n ( n m is the total tr ain size fo r th e clien ts assigned to mediator m ), then updates the g lobal model to w r +1 and ends this r ound. w r +1 is the start model for the next rou nd. C. Astr aea W orkflow The workflow of Astraea includes initialization, rebalan cing, training, and aggregation, as shown in Fig. 3. Initialization . In the initialization phase, the FL server first waits for th e mob ile devices to join the FL model tr a ining task. The devices p articipate in th e training by sending their local data distribution in formation to th e server ( ➀ ). After determinin g the d e vices ( c lients) to be in v olved in the tr aining, the FL server counts the global data distribution an d initializes the weights and the op timizer of the learning model. Rebalancing . In the rebalan c ing phase, the server first calculates the amount of augmentatio n s f or each class based on the global data distrib ution. Then, all clients per form data augmen t in parallel accord ing to the calcu lation results ( ➁ ). Algorithm 2 sho ws the detail of rebalan cing. The Augment function in line 11 takes one sam ple and generates aug- mentations, including random sh ift, random ro tation, random shear , and rando m zo om, for the sample. Th e numb e r of augmen ta tio ns d epends on the second parameter ( ¯ C /C y ) α , where α ind icates th e d egree of d ata augm e n tation. Larger α mea n s greater amo unt of augm entations. In add itio n, we do not augment the samples, the total sample size of their classes is gr eater than ¯ C . T h e goal of d ata aug m entation is to mitigate global imbalan ce rath er than eliminate it while a large α will generate too many similar samp les, wh ich makes the model training mor e prone to overfitting. Algorithm 2 Gobal d a ta distribution based data augmentation . 1: FL Serv er: 2: Calculate the data size of each class C 1 , ... , C N , and the mean ¯ C . 3: for each cl ass i in 1 , ... , N do 4: if C i < ¯ C then 5: Augmentaion set Y aug ∪ i . 6: 7: Clients: 8: for each cl i ent 1 , ..., k in K parallelly do 9: fo r each sample ( x , y ) in client k dataset ( X ( k ) , Y ( k ) ) d o 10: if label y in augmen taion set Y aug then 11: ( X ( k ) aug , Y ( k ) aug ) ∪ A ugment( ( x, y ) , ( ¯ C /C y ) α ) . 12: ( X ( k ) , Y ( k ) ) ∪ ( X ( k ) aug , Y ( k ) aug ) . 13: ShuffleDataset ( X ( k ) , Y ( k ) ) . Once all th e clients have co mpleted data aug mentation, the FL server creates m ediators ( ➂ ) to resch eduling clients ( ➃ ) in order to achieve partial eq uilibrium. In order to get more bala n ced training, we c an incr ease the co llab orating clients of e a c h med iator . Howe ver , this will also induce high commun ication overhead. Thu s, we req uire tha t each mediator can on ly coord in ate train ing for γ clien ts. W e w ill ev aluate the commun ication overhead of mediators in Section IV -C. The policy of reschedulin g is shown in Algo r ithm 3. W e design a g reedy strategy to a ssign clients to the m ediators. A mediator traverses the data distribution of all the unassigned clients and selects the clients whose data distrib utions can make the m ediator’ s data d istribution to be closest to the unifor m distribution. As shown in line 7 o f Algorithm 3 , we minimize the KLD betwe e n med iator’ s data distribution P m and unifo r m distribution P u . The FL server will cr eate a new mediator wh e n a mediator reaches the max assigne d clients limitation and repeat th e above pr o cess u ntil all clients trainin g are resched uled. Algorithm 3 Med iator based multi-client reschedu ling. D K L is Kullback-L eibler di vergence. 1: procedure R E S C H E D U L I N G 2: Initialize: 3: S mediator ← ∅ , S client ← 1 , ..., K . 4: repeat 5: Create mediator m . 6: fo r | S client | > 0 and | m | < γ do 7: k ← arg min i D K L ( P m + P i || P u ) , i ∈ S client 8: Mediator m add client k . 9: S client ← S client − k . 10: S mediator ← S mediator ∪ m . 11: until S client is ∅ 12: retur n S mediator T raining . At the beginning of each comm unication rou nd, each mediator send s the model to the subordinate clien ts ( ➄ ). Each client train s the mod el with the mini-batch SGD for E local epoch s and returns the upd ated mod el to the corre- sponding mediator . The local e poch E affects only th e time spent on tr aining p er client and does not increa se add itional commun ication overhead. Then, the med iator receives th e u p dated m odel ➅ and sends it to the n ext waiting tr aining client. W e call it a mediator epoch that all clients have com pleted a roun d of training. Astraea lo o ps this p rocess E m times. Th en, all the mediators send the up d ates of m o dels to the FL server ( ➆ ). There is a trade- o ff between co mmunicatio n overhead and model accuracy for the mediator ep ochs E m times for updating the model. W e will discuss the trade-off in Section IV -C. Aggregation . First, the FL server agg regates a ll the update s using F edA v g algo r ithm as shown in Eq uation 6. Th e n, the FL server sends the upd ated model to the me d iators and starts the next synchro nization rou n d. The main difference between Astraea and the existing FL algor ith ms in the model integra- tion pha se is th at Astraea can achieve partial equilibrium . As a r esult, the integrated model in Astraea is more balanced than that in the existing feder ated learning algo r ithms. I V . E V A L UA T I O N A. Experimental Setup W e implement the p roposed Astraea by mo d ifying the T ensorFlow Federated Framew ork (TFF) [7] and e valuate it throug h the single - machine simu la tio n ru n time pr ovided by T ABLE II N O TA T I O N S A N D D E F I N I T I O N S . Notatio n Definition K T otal number of client s. B Local batc h size. c Number of online client s per synchroniza tion round (per communicat ion round if no mediator). α Data augmentati on f actor . γ Maximum number of cli ents assigned to a mediat or . E m Mediat or epochs. All client s in a mediator are updated se- quentia lly of E m times in a synchroni zation round. E Local epochs. Each cli ent updates weights E times on local data in a communicat ion round. TFF . The notations u sed in the expe r iments are listed in the T ABLE II. Datasets and models . W e ado pt two widely used datasets and the co rrespond ing mo dels in the evaluation: 1) I mbalanced EMNIST and its corr e sp onding m odel. Same as L TRF2 dataset and the CNN mo del m entioned in Section II- B, K and B are set to 500 and 20, respectively . 2) I mbalanced CINIC-10 [6] and th e CIF AR-1 0 [30] model described in Keras d ocumen - tation, wh ere K and B are set to 10 0 and 50, r espectiv ely . W e get the imbalan ced CINIC-10 by re-sam pling CINI C-1 0 and m ake its global d istribution following the standard normal distribution. Baseline . W e choose th e state-of -the-art feder ated learnin g algorithm F edA v g as the baseline [ 3], which has been applied to Goog le keyboard for improvin g que r y suggestion s [31]. B. Effect o f Accuracy W e use the top-1 a c c uracy as metrics to the evaluate CNN models. W e do not use o th er metrics, such as recall rates or F1 score becau se our test set is balan ced and all classes o f data have the same c o st of misclassifi cation. A ugmentation vs. media tor : Fig. 4 shows the a c curacy improvement on imbalanced EMNIST ( c = 5 0 , γ = 10 ), including the improved acc u racy with the aug mentation strat- egy an d the im proved accuracy with both re scheduling and augmen ta tio n. The experimental results show tha t our aug- mentation strategy can im prove accu racy +1.28% f or α = 0 . 8 3 except when α = 2 , a significant decrease in ac curacy occurs. The am ount o f d ata a f ter aug mentation will greatly exceed the mean ¯ C when α = 2 , w h ich will introduce a new imbalance to the training set for the amo unt of augmentation is calcu lated by ( ¯ C /C y ) α . Hence, the recom mended ran ge for α is 0 to 1. For our rescheduling strategy , the accu r acy of the model is further impr oved from 73.7 7% to 78. 57% when α = 0 . 67 . In or der to explore the accuracy improvement o f resched uling in detail, we m easure the accuracy of the mo del that data augmen t is d isabled. The results are expressed as NoAug in Fig. 4(b). Th e cu rve indicates that the accuracy is gradu ally reduced after 200 synchron ization rounds. The accura cy improvement on imb alanced CINIC-10 is shown in Fig. 5. The data augmen tation strategy can improve +4.12% top-1 accuracy when α = 1 . 00 . The accuracy of the model is significan tly imp roved (+5 .89% when α = 0 . 67 ) after applying the proposed rescheduling strategy . Similar to imb alanced EMNIST , Fig. 5(b) shows that th e curve of NoAug is gradually r educed after 40 synchron ization round s. It means th at the mod el would suffer f rom overfitting if 0 1 0 0 2 0 0 3 0 0 4 0 0 5 0 0 0 . 5 0 0 . 5 5 0 . 6 0 0 . 6 5 0 . 7 0 0 . 7 5 0 . 8 0 0 . 8 5 0 5 0 1 0 0 1 5 0 2 0 0 2 5 0 3 0 0 0 . 5 0 0 . 5 5 0 . 6 0 0 . 6 5 0 . 7 0 0 . 7 5 0 . 8 0 0 . 8 5 T e s t a c c u r a c y C o m m u n i c a t i o n R o u n d s = 0 . 6 7 = 0 . 8 3 = 1 . 0 0 = 1 . 2 5 = 2 . 0 0 F e d A v g ( a ) S y n c h r o n i z a t i o n R o u n d s = 0 . 6 7 = 0 . 8 3 = 1 . 0 0 = 1 . 2 5 N o A u g F e d A v g ( b ) Fig. 4. Comparison of acc urac y on imbalanced EMNIST , c = 50 , γ = 10 . (a) Only the data augmentat ion strate gy appl ied, E = 5 ; (b) Combining data augmenta tion strategy and mediator resched uling strategy , E m = 2 . 0 2 5 5 0 7 5 1 0 0 1 2 5 1 5 0 0 . 2 5 0 . 3 0 0 . 3 5 0 . 4 0 0 . 4 5 0 . 5 0 0 . 5 5 0 . 6 0 0 2 0 4 0 6 0 8 0 1 0 0 1 2 0 0 . 2 5 0 . 3 0 0 . 3 5 0 . 4 0 0 . 4 5 0 . 5 0 0 . 5 5 0 . 6 0 T e s t a c c u r a c y C o m m u n i c a t i o n R o u n d s = 0 . 6 7 = 0 . 8 3 = 1 . 0 0 = 1 . 2 5 F e d A v g ( b ) S y n c h r o n i z a t i o n R o u n d s = 0 . 6 7 = 0 . 8 3 = 1 . 0 0 = 1 . 2 5 N o A u g F e d A v g ( a ) Fig. 5. Comparison of accu racy on imbala nced CINIC-10, c = 50 , γ = 10 . (a) Only the data augmentati on strate gy is appli ed, E = 1 ; (b) Combining data augme ntatio n strat egy and mediator reschedul ing strate gy , E m = 2 . augmen ta tio n is not ap p lied. The main goal of th e resche d uling strategy is to achie ve partial equilibrium, which cann ot solve the glo b al imbalan ce. T hus, com bining the two strategies is importan t and can achieve maximum imp r ovement of accu - racy . c v s. γ : c is th e number o f o nline clients p er round, wh ich determines the scale of trainin g in each syn c hronization ro und. γ is the max assigned clients limitation of the mediator, which determines the scope of partial equ ilibrium. W e explore the impact of c and γ on the training p rocess of Astraea . The experime n tal results on imbalan ced EMNIST are shown in Fig. 6. In the first 10 0 round s, the train ing o f model conv erges faster an d the ac c u racy of the model increases with the increase of c . Howev er , after 150 r ounds, the ac c uracy is slightly r educed, especially for the mo dels trained with a large c . For example, the accuracy is reduced f rom 79.0 3% to 77. 79% when c = 100 and γ = 20 . I t means th at the CNN mo dels are over-training and suffered fr o m overfitting. In order to remedy the loss of accuracy caused by ov erfitting, we can use the regularization strategy early stopping [3 2], in which optimization is halted based on the per forman ce on a validation set, du r ing training . Fur ther more, exper imental results show that a larger γ does no t help im proving the accuracy of the model. T o further explore the impact of mediato r configu ration on the e quilibrium degree, we show the distribution of D K L ( P m || P u ) in Fig. 7 . The KLD o f F edA vg is calculated by D K L ( P k || P u ) , which means the eq uilibrium degre e of FL 0 5 0 1 0 0 1 5 0 2 0 0 2 5 0 3 0 0 0 . 5 0 0 . 5 5 0 . 6 0 0 . 6 5 0 . 7 0 0 . 7 5 0 . 8 0 0 . 8 5 T e s t A c c u r a c y S y n c h r o n i z a t i o n R o u n d s c = 1 0 , = 4 c = 2 0 , = 4 c = 2 0 , = 1 0 c = 5 0 , = 1 0 c = 5 0 , = 2 0 c = 1 0 0 , = 2 0 Fig. 6. T est accurac y on imbala nced EMNIST , train with dif ferent numbers of participa ting clients per round and diffe rent maximum assigned clie nts limitat ions of mediato r . 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 1 . 2 1 . 4 1 . 6 C = 1 0 0 = 2 0 C = 5 0 = 2 0 C = 5 0 = 1 0 C = 2 0 = 1 0 C = 1 0 = 4 C = 2 0 = 4 A u g K L D F e d A v g Fig. 7. Kullbac kLeibler di vergenc e between P m and P u after scheduling . The horizontal axis represents diffe rent configurat ions of mediator , the white line indicates the m ean and the white square indicates the median, the augmenta tion factor is 0.83. framework withou t data augm entation and rescheduling . Th e KLD of Aug is the equilib rium degree of Astraea fra mew ork without resch eduling. As shown in th e Fig. 7, all d istributions are left-skewed and the mean of KLD o f F edA vg is th e h ighest ( 0 .550) , indicating that the distribution o f F edA vg is most imbalanced. Our augmen tation strategy can make the distribution more balanced (from 0.550 to 0.498) , but m ay introduce some new outliers. As shown in the Fig. 7, our reschedulin g strategy can significantly r ebalance d ata distribution (from 0.550 to 0 .125) with the shrink o f interquar tile ra n ge and the increase of c . In addition, large γ can redu ce the variation o f D K L . This suggests that mediators can ac hiev e better p artial equ ilibrium when m ore clien ts pa r ticipate in training or more clients are assigned to the mediator s. In summar y , the accuracy improvement o f Astraea incre ases as the scale of the training expands. Local epochs vs. mediato r epochs . He r e we explore the imp act of lo cal epoc hs E and m ediator epoch s E m on training, wh ich rep resent the number of epo c h s for local gradients update in a commun ication roun d an d the numb er of ep o chs for mediator weig hts upd ate in a syn chroniza tion round , r e sp ecti vely . The experime ntal results are shown in Fig. 8. Fig. 8 shows that increasin g loca l epochs does not b ring significant improvement of accur acy . A large local epochs can ev en cause a drop in accuracy . In our exper im ents, the accura cy of the CNN model drops 2.1 7% on a verage if the local epoch s of train ing set from 10 to 1. For mediator epo c hs, we ob serve that tr aining with E m = 2 can significant improve accuracy (+1.4%) comp a red with E m = 1 when the lo cal epoch E is 1. Howe ver , the improvement achieved by mediato r epoch s E=1 E=3 E=5 E=10 0.60 0.65 0.70 0.75 0.80 0.85 Test Ac curacy E m =1 E m =2 E m =3 E m =4 Fig. 8. T est accurac y on imbalanced EMNIST . Tra ined with diffe rent mediator epochs E m and local epochs E . requires additio n al comm unication resou rces a n d training time. C. Overhead W e discuss th ree kinds o f overheads o f Astraea fr amew ork: T ime, storage an d commu n ication. W e ig nore the co mputa- tional overhead of Astraea f or the ad ditional calculations, such as aug mentation and resch eduling, require few compu ta tio nal resources and ca n b e calculated on the FL server . W e use imbalanced EMNI ST dataset in this section. Time overhead . There are three major tasks that require additional time in Astraea: Data au gmentation , resche d ul- ing, an d extra trainin g epo chs of the mediator s. As sho wn in Algorithm 2, the time co mplexity is O ( x α n i ) , wh ere i = arg max k ¯ C /C k , x = ¯ C /C i . Since data au g mentation is o n ly perfo rmed o nce at the in itialization phase, the tim e consump tion is negligible to the whole training process. The process of rescheduling is sh own in Algorithm 3, wh ere we use a greedy strategy to search the c lients fo r reschedulin g. The time complexity of the sear c h ing proc e ss is O ( c 2 ) . If the data distribution of clients is static, Astraea only perf o rms reschedulin g once. In con trast, if th e da ta distribution of the client is dy namically an d rapidly changin g, Astraea need s to r eschedule in each synchron ization round. Th e m ain tim e overhead of Astraea framework is the mo del tr aining. In FL, the time spent on each comm unication rou nd is E × T , T is the training time of a local epoch. In Astraea, the time spent on each synchronization roun d is E m γ E × T . Storage overhead . Th e propo sed A stra e a requires the clients to pr ovid e additional storag e space to store the au g- mentation data. W e show th e trad e-off between storag e and accuracy in Fig. 9 . T he experim e n tal results show that Astraea can improve 1 .61% accu racy on imbalanced EMNIST withou t additional storag e requiremen t. It further imp roves 3.28 % ac- curacy with 25. 5% add itional storage space. Altho ugh it seems that the storag e overhead is large, but it is ac c e ptable when the overhead is allotted to every c lien t. I n o ur experim ents, the to tal additional storag e space for data augm entation is 90 MB, i.e., 185 KB per client. The requir e d stor age space is increased with the increase of α . α = 2 fails the train ing due to timeo ut. Communication overhead . Du e to the tra ining o f the clients in each mediator is asynchrono us, ea c h sync hronization round in Astraea costs more traffic tha n each com munication round in FL. Th e traffic of each c o mmunicatio n rou nd can be calcu lated by 2 c | w | , where | w | is the size of all p a- rameters. Hence, the traffic of each synchro nization r o und is 2 | w | ( ⌈ c/γ ⌉ + c ) . s t o r a g e a c c u r a c y S t o r a g e r e q u i r e m e n t ( M B ) 0 . 5 0 0 . 5 5 0 . 6 0 0 . 6 5 0 . 7 0 0 . 7 5 0 . 8 0 0 . 8 5 T e s t a c c u r a c y Fig. 9. Overhead of storage versus improvemen t of accurac y on imbala nced EMNIST . The training of α = 2 . 00 is f ail due to timeout. T ABLE III C O M M U N I C A T I O N C O N S U M P T I O N T O R E AC H A TA R G E T A C C U R A C Y F O R A S T R A E A ( W I T H D I FF E R E N T V A L U E O F M E D I A TO R E P O C H S N OT E A S M E D 1 - 4 , E = 1 ) , V E R S U S F E D A V G ( B A S E L I N E , E = 20 ) , T H E L O C A L E P O C H S D O E S N OT A FF E C T C O M M U N I C ATI O N OV E R H E A D . Imbalanced EMNIST , T arget T op-1 Accurac y: 75% Notaion c γ α E E m Cost(MB) FedA vg(baselin e) 10 ✗ ✗ 20 ✗ 1176 Med1 50 10 0.67 1 1 284 (0.24 × ) Med2 50 10 0.67 1 2 215 (0.18 × ) Med3 50 10 0.67 1 3 221 (0.19 × ) Med4 50 10 0.67 1 4 284 (0.24 × ) Experime ntal results in T ABLE III sho w th at Astraea is actually more communication -efficient than FL. It is becau se Astraea r e q uires less communication costs th at FL in ach iev- ing a require d accuracy . The communica tio n consumptio n of training a CNN using FL to reach 75% top- 1 accur acy is 117 6 MB whereas Astrae a uses merely 2 15 MB ( n ote as Med2 in T ABLE III). Th at is, Astraea ach iev es 81. 7% reduction in commun ication cost. Although the m odel trained by FL can reach 75 % accuracy , it is finally stabled at around 74 %. V . C O N C L U S I O N Federated learning is a promising d istributed machine learn- ing fram ew ork with the advantage of pr i vac y-preserv ing. How- ev er , FL d oes n ot handle imbalanc e d datasets w e ll. In this work, we hav e explor ed the imp act of imbalanced training d a ta on the FL and 7 .92% accuracy loss on imbalanced EMNIST caused b y global imbalance be observed. As a solution, we propo se a self-balancing FL fr a m ew ork Astraea which rebal- ances the training tho ught 1) Perf orming d ata au gmentation to minority classes; 2) Rescheduling clients by mediato rs in o rder to achieve a partial eq uilibrium. Expe rimental r esults show that the top-1 accur acy improvement of Astraea is +5.59% on imbalanced E MNIST and +5.89 % o n imbalanc e d CINIC-10 (vs. F edA vg ). Finally , w e measur e the overheads of Astrae a and show its communication is effectiv e. A C K N O W L E D G M E N T W e would like to thank the anonym ous revie wers for their valuable feed back and improvements to this paper . This work is partially supp orted by gran ts fr o m the National Natural Science Foundation of China (61672 116, 6160 1 067, 61802 038), Chongqin g High-T e c h Research Ke y Pr ogram (cstc2019 jscx-mbdx 0063), the Fundamental Research Fun ds for the Central Universities und er Grant (02 14005 20700 5, 2019CDJGFJSJ001) , China Po stdoctoral Science Foundation (2017 M62041 2). R E F E R E N C E S [1] A. Krizhe vsky , I. Sutsk e ve r , and G. E. Hinton , “Imagene t classifica tion with deep con volutional neural networks, ” in A dvance s in neural inf or- mation pr ocessing systems , 2012, pp. 1097–1105. [2] G. Hinton, L. Deng, D. Y u, G. Dahl, A. -r . Mohamed, N. Jaitly , A. Senior , V . V anhoucke, P . Nguyen, B. Kingsbury et al. , “Deep neural networks for acousti c m odeling in speech recognitio n, ” IEEE Signal pr oce ssing magazin e , vol. 29, 2012. [3] H. B. McMahan, E . Moore, D. Ramage, S. Hampson et al. , “Communica tion-ef fic ient learning of deep networks from decentral ized data, ” arXiv preprint arXiv:16 02.05629 , 2016. [4] Y . Zhao, M. Li, L. Lai, N. Suda, D. Ci vin, and V . Chandra, “Federated learni ng with non-iid data , ” arXiv pre print arXiv:1806.00582 , 2018. [5] S. C. W ong, A. Gatt, V . Stamatescu, and M. D. McDonn ell, “Under- standing data augmen tation for classifica tion: when to warp?” in 2016 internat ional confere nce on digital image computing : techniqu es and applica tions (DICTA) . IEEE, 2016, pp. 1–6. [6] L. N. D arlow , E . J. Crowle y , A. Antoniou, and A. J. Storke y , “Cinic-10 is not imagenet or cifar -10, ” arXiv preprin t arXiv:1810 .03505 , 2018. [7] M. Abadi, P . Barham, J. Chen, Z. Chen, A. Davis, J. Dean, M. De vin, S. Ghemaw at, G. Irving, M. Isard et al. , “T ensorflow: A system for large- scale machine learning, ” in 12th { USENIX } Symposium on Oper ating Systems Design and Implemen tation ( { OSDI } 16) , 2016, pp. 265–283. [8] A. Hard, K. Rao, R. Mathe ws, F . Beaufays, S. Augenstein , H. Eichne r , C. Kiddon, and D. Ramage, “Federated learning for m obile ke yboard predict ion, ” arXiv preprint , 2018. [9] K. Bonawitz, H. Eichner , W . Griesk amp, D. Huba, A. Inge rman, V . Ivano v , C. Kiddon, J. K onecn y , S. Mazzocc hi, H. B. McMahan et al. , “T ow ards federated learning at scale: System design, ” in P rocee dings of the 2nd SysML Confer enc e , 2019. [10] J . Kone ˇ cn ` y, H. B. McMahan, F . X. Y u, P . Richt ´ arik, A. T . Suresh, and D. Bacon, “Federat ed learning: Strategi es for improving communicati on ef ficienc y , ” arXiv pr eprint arXiv:1610.05492 , 2016. [11] S . Samara koon, M. Bennis, W . Saad, and M. Debbah, “Federated learni ng for ultra-relia ble low-la tenc y v2v communica tions, ” in 2018 IEEE G lobal Communic ations Confer enc e (GLO B ECOM) . IEEE, 2018, pp. 1–7. [12] D . Liu, C. Y ang, S. L i, X. Chen, J. Ren, R. L iu, M. Duan, Y . T an, and L. Liang, “Fitcnn: A cloud-assi sted and lo w-cost frame work for updating cnns on iot de vices, ” Future Generati on Computer Systems , vol. 91, pp. 277–289, 2019. [13] K . Bona witz , V . Ivano v , B. Kreuter , A. Marcedone, H. B. McMaha n, S. Patel, D. Ramage, A. Segal , and K. Seth, “Practica l secure aggre gatio n for priv ac y-preser ving machine learning, ” in Procee dings of the 2017 ACM SIGSAC Confer enc e on Computer and Communicatio ns Security . A CM, 2017, pp. 1175–1191 . [14] N . Agarwal, A. T . Suresh, F . X. X. Y u, S. Kumar , and B. McMa han, “cpsgd: Communication-ef fic ient and dif ferenti ally-p ri vate distribut ed sgd, ” in A dvance s in Neur al Information P rocessi ng Systems , 2018, pp. 7564–7575. [15] Z . W ang, M. Song, Z. Zhang, Y . Song, Q. W ang, and H. Qi, “Be yond inferrin g class representa ti ve s: User-le v el pri v ac y leakage from federated learni ng, ” in IEE E INFOCOM 2019-IEEE Confere nce on Computer Communicat ions . IEEE, 2019, pp. 2512–2520. [16] G . Xu, H. Li, S. Liu, K . Y ang, and X. L in, “V erifyne t: Secure and veri- fiable fede rated learn ing, ” IEEE T ransact ions on Informatio n F or ensics and Sec urity , 2019. [17] F . Sattler , S. Wied emann, K.-R. M ¨ uller , and W . Samek, “Robust and communicat ion-ef fici ent federated learning from non-iid data, ” arXiv pre print arXiv:1903.02891 , 2019. [18] H . He and E. A. Garcia, “Learning from imbalanced data, ” IEEE T r ansactio ns on Knowledg e & Data Engineering , no. 9, pp. 1263–1284, 2008. [19] N . V . Chawl a, K. W . Bowye r , L. O. Hall, and W . P . Ke gelme yer , “Smote: syntheti c minority ove r-sampli ng technique , ” Jo urnal of artific ial intel- lig ence re sear ch , vol. 16, pp. 321–357, 2002. [20] H . Han, W .-Y . W ang, and B.-H. Mao, “Borde rline-smot e: a ne w over - sampling m ethod in imbalanced data sets learning, ” in Internatio nal confer en ce on intel lige nt comput ing . Springer , 2005, pp. 878–887. [21] G . R ¨ atsch, T . Onoda, and K.-R. M ¨ ulle r , “Soft margi ns for adaboost, ” Mach ine learning , vo l. 42, no. 3, pp. 287–320, 2001. [22] T . Chen and C. Guestrin, “Xgbo ost: A scalabl e tree boosting system, ” in Pr oceedi ngs of the 22nd acm sigkdd internat ional confe re nce on knowle dge discove ry and data mining . AC M, 2016, pp. 785–794. [23] L . A. Adamic and B. A. Huberman, “Zipf ’ s law and the internet . ” Glottome trics , vol. 3, no. 1, pp. 143–150, 2002. [24] G . Cohen, S. Afshar , J. T a pson, and A. va n Schaik, “Emnist: E xtendi ng mnist to handwritte n let ters, ” in 2017 Internati onal Joint Confer ence on Neural Networks (IJCNN) . IEEE, 2017, pp. 2921– 2926. [25] S . Cal das, P . Wu, T . Li, J. Ko ne ˇ cn ` y, H. B. McMaha n, V . Smith, and A. T al wa lkar , “Leaf: A benchmark for federated settings, ” arX iv pre print arXiv:1812.01097 , 2018. [26] A . Bodaghi and S. Goliaei, “Dyna mics of instagram users, ” Jul. 2017. [Online]. A v ailabl e: https://doi.or g/10.5281 /zenodo.823283 [27] L . W an, M. Zeiler , S. Zhang, Y . Le Cun, and R. Fergus, “Reg ulariza tion of neural networks using dropconne ct, ” in Internat ional confe re nce on machi ne learnin g , 2013, pp. 1058–1066. [28] D . P . Kingma and J. Ba, “ Ada m: A method for stochasti c optimizati on, ” arXiv pr eprint arXiv:1412.6980 , 2014. [29] Y . L eCun, Y . Bengio , and G. Hinton, “Deep learning, ” natur e , vol. 521, no. 7553, p. 436, 2015. [30] A . K rizhevsk y and G. Hinton, “Learning multiple layers of features from tin y images, ” Citese er , T ec h. Rep., 2009. [31] T . Y ang, G. Andrew , H. Eichn er , H. Sun, W . Li, N. Kong, D. Ram- age, and F . Beaufays, “ Applied federa ted learnin g: Improving googl e ke yboard query suggestions, ” arX iv prep rint arX iv:1812.029 03 , 2018. [32] Y . Y ao, L. Rosasco, and A. Caponnetto , “On ear ly stoppi ng in gradient descent learning, ” Construc tive Appr oximat ion , vol. 26, no. 2, pp. 289– 315, 2007.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment