CMRNet 카메라와 LiDAR 맵 정합
CMRNet은 실시간 CNN 기반 방법으로, 단일 RGB 이미지와 사전에 구축된 LiDAR 포인트 클라우드 맵을 매칭해 6자유도 카메라 자세를 추정한다. 네트워크는 특정 지역에 대해 학습되지 않으며, 초기 거친 자세 추정(최대 3.5 m·17°)에서 시작해 중간 정밀도(0.27 m·1.07°)를 달성한다. KITTI odometry 시퀀스 00을 이용한 실험 결과, 프레임당 독립 처리와 반복적인 정제 과정을 통해 높은 정확도를 보였다.
저자: Daniele Cattaneo, Matteo Vaghi, Augusto Luis Ballardini
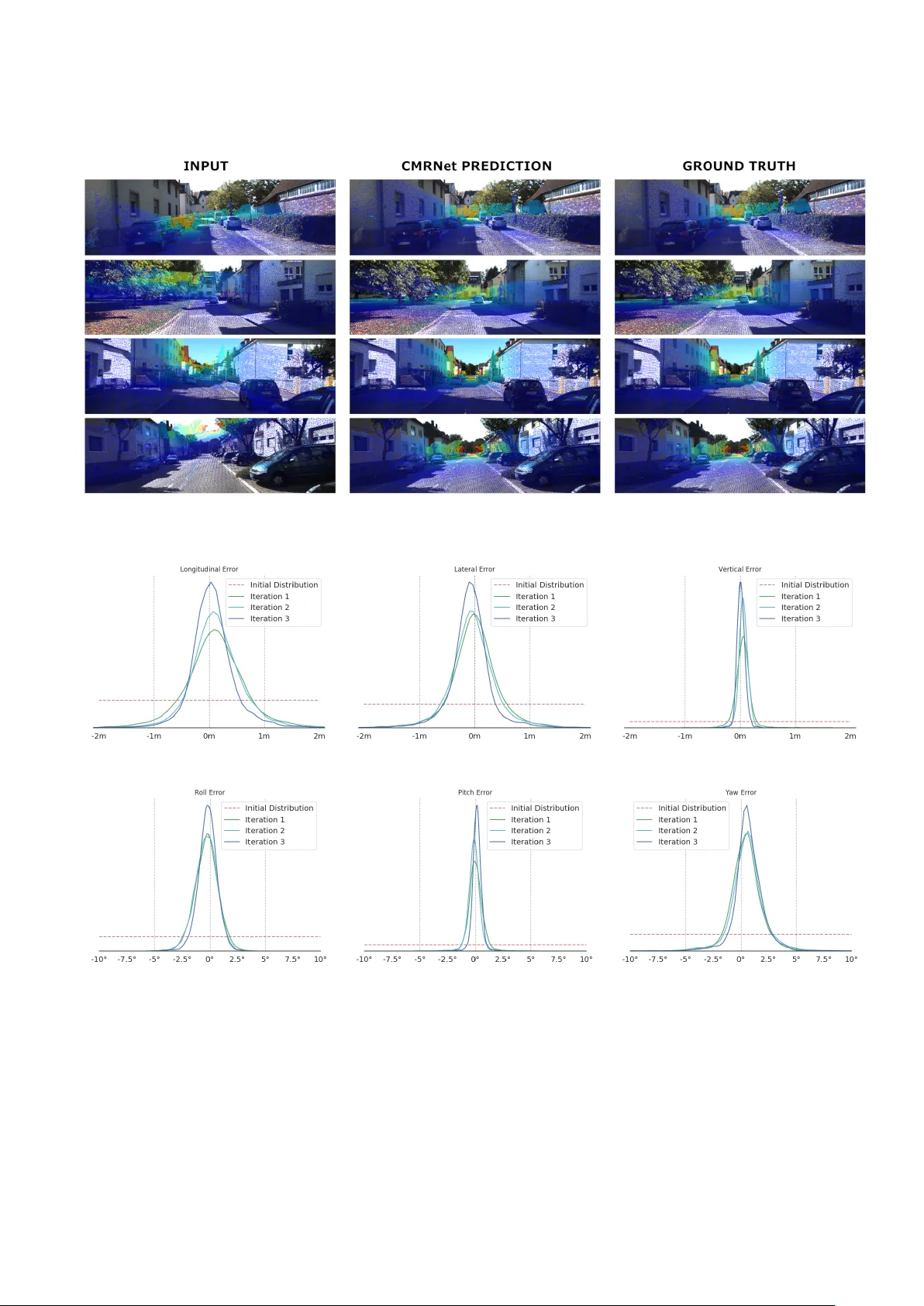
본 논문은 자율주행 차량이 저비용 RGB 카메라만을 이용해 고정밀 LiDAR‑map에 정합함으로써 정확한 위치 추정을 할 수 있는 새로운 방법, CMRNet을 제안한다. 기존의 비전‑전용 로컬라이제이션은 학습 데이터에 포함된 환경에만 일반화가 가능하고, 비전‑LiDAR 결합 방식은 실시간 성능이나 센서 비용 면에서 한계가 있었다. CMRNet은 이러한 문제점을 해결하기 위해 “지도‑학습이 아닌 지도‑매칭” 접근법을 채택한다. 구체적인 흐름은 다음과 같다.
1. **입력 준비**: 차량에 장착된 GNSS·IMU 등으로부터 얻은 거친 6‑DoF 자세 H_init 을 사용해, 사전에 구축된 LiDAR 포인트 클라우드 맵을 가상 이미지 평면에 투사한다. 투사 과정에서는 카메라 내부 파라미터 K 를 적용하고, z‑버퍼와 occlusion filter(
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기