CMRNet: Camera to LiDAR-Map Registration
In this paper we present CMRNet, a realtime approach based on a Convolutional Neural Network to localize an RGB image of a scene in a map built from LiDAR data. Our network is not trained in the working area, i.e. CMRNet does not learn the map. Inste…
Authors: Daniele Cattaneo, Matteo Vaghi, Augusto Luis Ballardini
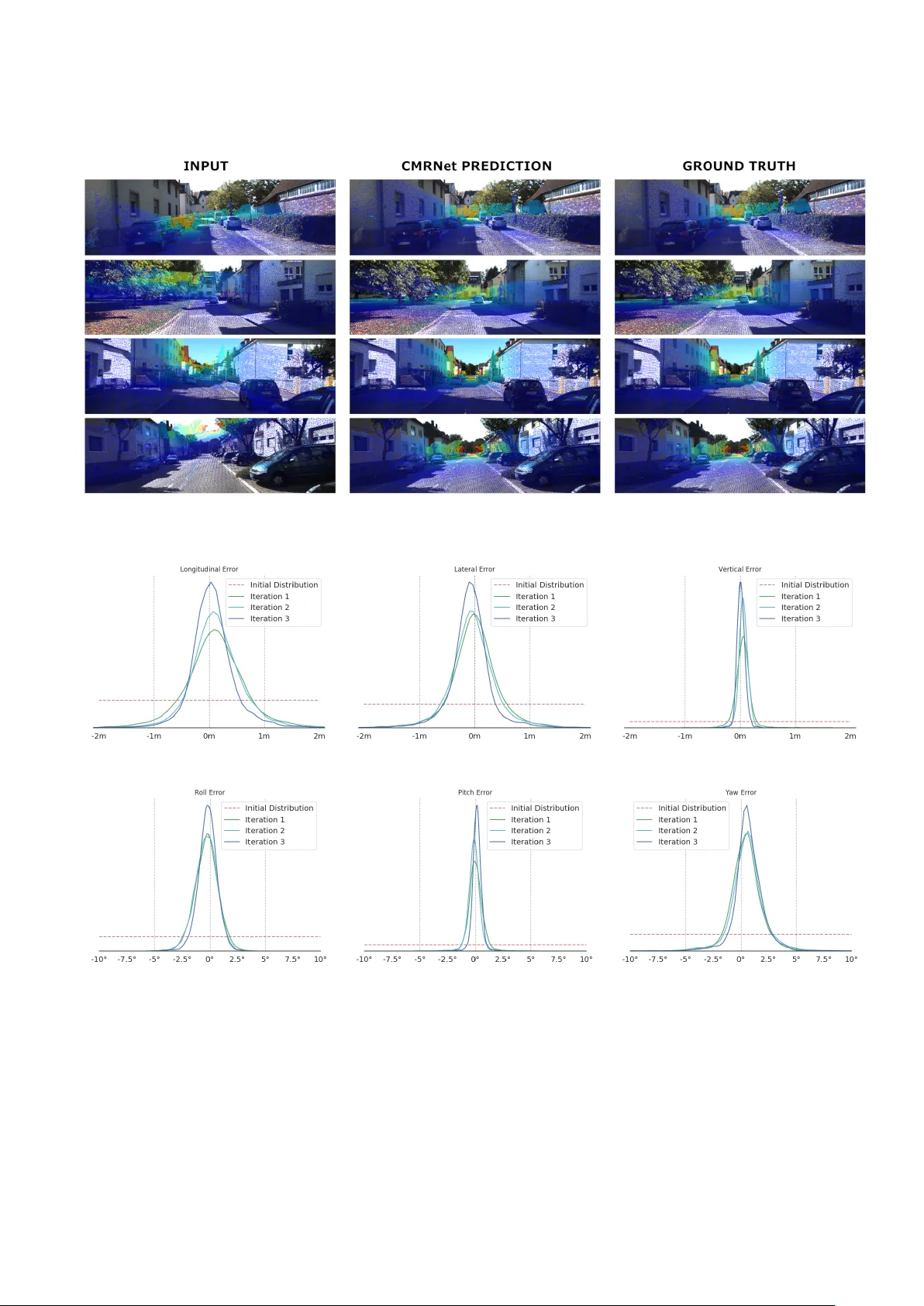
CMRNet: Camera to LiD AR-Map Registration D. Cattaneo ∗ , M. V aghi ∗ A. L. Ballardini † , S. Fontana ∗ , D. G. Sorrenti ∗ W . Burgard ‡ ∗ Univ ersit ` a degli Studi di Milano - Bicocca, Milano, Italy † Computer Science Department, Univ ersidad de Alcal ´ a, Alcal ´ a de Henares, Spain ‡ Albert-Ludwigs-Univ ersit ¨ at Freibur g, Freibur g, Germany ©2019 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collectiv e works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this w ork in other works. Abstract — In this paper we present CMRNet, a r ealtime approach based on a Con volutional Neural Network (CNN) to localize an RGB image of a scene in a map built from LiD AR data. Our network is not trained in the working area, i.e., CMRNet does not learn the map. Instead it learns to match an image to the map. W e validate our approach on the KITTI dataset, processing each frame independently without any tracking procedur e. CMRNet achieves 0.27m and 1.07 ◦ median localization accuracy on the sequence 00 of the odometry dataset, starting from a rough pose estimate displaced up to 3.5m and 17 ◦ . T o the best of our knowledge this is the first CNN-based approach that learns to match images from a monocular camera to a given, preexisting 3D LiD AR-map. I . I N T R O D U C T I O N Over the past few years, the effecti veness of scene un- derstanding for self-driving cars has substantially increased both for object detection and v ehicle na vigation [1], [2]. Even though these improvements allowed for more advanced and sophisticated Advanced Driver Assistance Systems (AD AS) and maneuvers, the current state of the art is far from the SAE full-automation level, especially in complex scenarios such as urban areas. Most of these algorithms depend on very accurate localization estimates, which are often hard to obtain using common Global Navigation Satellite Systems (GNSSs), mainly for non-line-of-sight (NLOS) and multi- path issues. Moreover , applications that require navig ation in indoor areas, e.g., valet parking in underground areas, necessarily require complementary approaches. Different options hav e been in vestigated to solve the local- ization problem, including approaches based on both vision and Light Detection And Ranging (LiD AR); they share the exploitation of an a-priori kno wledge of the en vironment in the localization process [3]–[5]. Localization approaches that utilize the same sensor for mapping and localization usually achiev e good performances, as the map of the scene is matched to the same kind of data generated by the on- board sensor . Ho wev er , their application is hampered by the need for a preliminary mapping of the working area, which represents a relev ant issue in terms of effort both for building the maps as well as for their maintenance. On the one hand, some approaches try to perform the localization exploiting standard cartographic maps, such as OpenStreetMap or other topological maps, lev eraging the † The work of A. L.Ballardini has been funded by European Union H2020, under GA Marie Skłodowska-Curie n. 754382 Got Ener gy . Fig. 1. A sketch of the proposed processing pipeline. Starting from a rough camera pose estimate ( e.g ., from a GNSS device), CMRNet compares an RGB image and a synthesized depth image projected from a LiDAR-map into a virtual image plane (red) to regress the 6DoF camera pose (in green). Image best viewed in color . road graph [6] or high-le vel features such as lane, round- abouts, and intersections [7]–[9]. On the other hand, compa- nies in the established market of maps and related services, like e.g., HERE or T omT om, are nowadays already dev elop- ing so-called High Definition maps (HD maps), which are built using LiD AR sensors [10]. This allows other players in the autonomous cars domain, to focus on the localization task. HD maps, which are specifically designed to support self- driving vehicles, provide an accurate position of high-level features such as traffic signs, lane markings, etc. as well as a representation of the en vironment in terms of point clouds, with a density of points usually reaching 0.1m. In the following, we denote as LiDAR-maps the point clouds generated by processing data from LiD ARs. Standard approaches to exploit such maps localize the observer by matching point clouds gathered by the on-board sensor to the LiD AR-map; solutions to this problem are known as point clouds registration algorithms. Currently , these approaches are hampered by the huge cost of LiD AR devices, the de-facto standard for accurate geometric recon- struction. In contrast, we here propose a novel method for re gistering an image from an on-board monocular RGB camera to a LiD AR-map of the area. This allows for the exploitation of the forthcoming market of LiD AR-maps embedded into HD maps using only a cheap camera-based sensor suite on the vehicle. In particular , we propose CMRNet, a CNN-based approach that achiev es camera localization with sub-meter accuracy , basing on a rough initial pose estimate. The maps and images used for localization are not necessarily those used during the training of the network. T o the best of our knowledge, this is the first work to tackle the localization problem without a localized CNN, i.e., a CNN trained in the working area [11]. CMRNet does not learn the map, instead, it learns to match images to the LiDAR-map. Extensi ve experimental ev aluations performed on the KITTI datasets [12] show the feasibility of our approach. The remainder of the paper is organized as follows: Section II giv es a short revie w of the most similar methods and the last achie vements with DNN-based approaches. In Section III we present the details of the proposed system. In Section IV we sho w the effecti veness of the proposed approach, and Sections V and VI present our conclusions and future work. I I . R E L AT E D W O R K In the last years, visual localization has been a trending topic in the computer vision community . Although many variations hav e been proposed, most of them are either based on images gathered from a camera sensor only or exploit some kind of 3-dimensional reconstruction of the en vironment. A. Camera-only appr oaches The first category of techniques deals with the 6-DoF estimate of the camera pose using a single image as input. On the one hand, traditional methods face this problem by means of a two-phase procedure that consists of a coarse localization, performed using a place recognition algorithm, followed by a second refining step that allows for a final accurate localization [13], [14]. On the other hand, the latest machine learning techniques, mainly based on deep learning approaches, face this task in a single step. These models are usually trained using a set of images taken from dif ferent points of view of the working environment, in which the system performs the localization. One of the most important approaches of this category , which inspired many subsequent works, is PoseNet [11]. It consists in a CNN trained for camera pose regression. Starting from this work, additional improv ements hav e been proposed by introducing new ge- ometric loss functions [15], by exploiting the uncertainty estimation of Bayesian CNNs [16], by including a data augmentation scheme based on synthetic depth information [17], or using the relative pose between two observ ations in a CNNs pipeline [18]. One of the many works that follow the idea presented in PoseNet is VLocNet++ [19]. Here the authors deal with the visual localization problem using a multi-learning task (ML T) approach. Specifically , they prov ed that training a CNN for different tasks at the same time yields better localization performances than single task learning. As for today , the literature still sees [19] as the best performing approach on the 7Scenes dataset [20]. Clark et al. [21] developed a CNN that exploits a sequence of images in order to improve the quality of the localization in urban en vironments. Brachmann et al. , instead, integrated a dif ferentiable version of RANSA C within a CNN-based ap- proach in an end-to-end fashion [22], [23]. Another camera- only localization is based on decision for ests , which consists of a set of decision trees used for classification or regression problems. For instance, the approach proposed by Shotton et al. [20] exploits RGBD images and regression forests to perform indoor camera localization. The aforementioned techniques, thanks to the generalization capabilities of ma- chine learning approaches, are more robust against challeng- ing scene conditions like lighting variations, occlusions, and repetitiv e patterns, in comparison with methods based on hand-crafted descriptors, such as SIFT [24], or SURF [25]. Howe ver , all these methods cannot perform localization in en vironments that have not been exploited in the training phase, therefore these regression models need to be retrained for ev ery new place. B. Camera and LiDAR-map appr oaches The second category of localization techniques lev erages existing maps, in order to solve the localization problem. In particular , two classes of approaches hav e been presented in the literature: geometry-based and projection-based methods. Caselitz et al. [3] proposed a geometry-based method that solves the visual localization problem by comparing a set of 3D points, the point cloud reconstructed from a sequence of images and the existing map. W olcott et al. [4], instead, dev eloped a projection-based method that uses meshes built from intensity data associated to the 3D points of the maps, projected into an image plane, to perform a comparison with the camera image using the Normalized Mutual Information (NMI) measure. Neubert et al. [5] proposed to use the sim- ilarity between depth images generated by synthetic views and the camera image as a score function for a particle filter , in order to localize the camera in indoor scenes. The main advantage of these techniques is that they can be used in any environment for which a 3D map is av ailable. In this way , they avoid one of the major drawbacks of machine learning approaches for localization, i.e., the necessity to train a new model for e very specific en vironment. Despite these remarkable properties, their localization capabilities are still not robust enough in the presence of occlusions, lighting variations, and repetitiv e scene structures. The work presented in this paper has been inspired by Schneider et al. [26], which used 3D scans from a LiD AR and RGB images as the input of a novel CNN, RegNet. Their goal was to provide a CNN-based method for calibrating the extrinsic parameters of a camera w .r .t. a LiD AR sensor . T aking inspiration from that work, in this paper we propose a nov el approach that has the advantages of both the categories described above. Differently from the aforementioned liter- ature contribution, which exploits the data gathered from a synchronized single activ ation of a 3D LiD AR and a camera image, the inputs of our approach are a complete 3D LiDAR map of the en vironment, together with a single image and a rough initial guess of the camera pose. Eventually , the output consists of an accurate 6-DoF camera pose localization. It is worth to notice that ha ving a single LiD AR scan taken at the same time as the image imply that the observed scene is exactly the same. In our case, instead, the 3D map usually depicts a different configuration, i.e., road users are not present, making the matching more challenging. Our approach combines the generalization capabilities of CNNs, with the ability to be used in any en vironment for which a LiDAR-map is av ailable, without the need to re- train the network. I I I . P R O P O S E D A P P RO AC H In this work, we aim at localizing a camera from a single image in a 3D LiD AR-map of an urban en vironment. W e exploit recent dev elopments in deep neural networks for both pose regression [11] and feature matching [27]. The pipeline of our approach is depicted in Fig. 1 and can be summarized as follows. First, we generate a synthesized depth image by projecting the map points into a virtual image plane, positioned at the initial guess of the camera pose. This is done using the intrinsic parameters of the camera. From now on, we will refer to this synthesized depth image as LiD AR-image. The LiD AR-image, together with the RGB image from the camera, are fed into the proposed CMRNet, which regresses the rigid body transformation H out between the tw o dif ferent points of vie w . From a technical perspecti ve, applying H out to the initial pose H init allows us to obtain the 6-DoF camera localization. In order to represent a rigid body transformation, we use a (4 , 4) homogeneous matrix: H = R ( 3 , 3 ) T ( 3 , 1 ) 0 ( 1 , 3 ) 1 ! ∈ SE ( 3 ) (1) Here, R is a (3 , 3) rotation matrix and T is a (3 , 1) trans- lation v ector , in cartesian coordinates. The rotation matrix is composed of nine elements, but, as it represents a rotation in the space, it only has three degrees of freedom. For this reason, the output of the network in terms of rotations is expressed using quaternions lying on the 3-sphere ( S 3 ) man- ifold. On the one hand, ev en though normalized quaternions hav e one redundant parameter , they have better properties than Euler angles, i.e., gimbal lock avoidance and unique rotational representation (e xcept that conjugate quaternions represent the same rotation). Moreov er , they are composed of fewer elements than a rotation matrix, thus being better suited for machine learning regression approaches. The outputs of the network are then a translation vector T ∈ R 3 and a rotation quaternion q ∈ S 3 . For simplicity , we will refer to the output of the network as H out , implying that we con vert T and q to the corresponding homogeneous transformation matrix, as necessary . A. LiD AR-Image Generation In order to generate the LiDAR-image for a given initial pose H init , we follow a two-step procedure. Map Pr ojection. First, we project all the 3D points in the map into a virtual image plane placed at H init , i.e., compute the image coordinates p of e very 3D point P . This mapping is shown in Equation (2), where K is the camera projection matrix. p i = K · H init · P i (2) The LiDAR-image is then computed using a z-buf fer ap- proach to determine the visibility of points along the same projection line. Since Equation (2) can be computationally expensi ve for large maps, we perform the projection only for a sub-region cropped around H init , ignoring also points that lay behind the virtual image plane. In Figure 2a is depicted an example of LiDAR-image. (a) W ithout Occlusion Filter (b) W ith Occlusion Filter Fig. 2. T op: a LiD AR-image with the associated RGB overlay . Please note how the points behind the building on the right, i.e., lighter points on the fence, are projected into the LiD AR-image. Bottom: an example of the occlusion filtering effect. Color codes distance from close (blue) to far point (red). Occlusion F iltering. The projection of a point cloud into an image plane can produce unrealistic depth images. F or in- stance, the projection of occluded points, e.g., laying behind a wall, is still possible due to the sparsity nature of point clouds. T o avoid this problem, we adopt the point clouds occlusion estimation filter presented in [28]; an example of the effect of this approach is depicted in Figure 2b. For ev ery point P i , we can build a cone, about the projection line tow ards the camera, that does not intersect any other point. If the cone has an aperture lar ger than a certain threshold Th , the point P i is marked as visible. From a technical perspectiv e, for each pixel with a non-zero depth p j in the LiD AR-image, we compute the normalized vector ~ v from the relativ e 3D point P j to the pin-hole. Then, for any 3D point P i whose projection lays in a neighborhood (of size KxK ) of p j , we compute the vector ~ c = P i − P j k P i − P j k and the angle between the two vectors ϑ = arccos( ~ v · ~ c ) . This angle is used to assess the visibility of P j . Occluded pixels are then set to zero in the LiD AR-image. More detail is av ailable in [28] B. Network Ar chitectur e PWC-Net [27] was used as baseline, and we then made some changes to its architecture. W e chose this network because PWC-Net has been designed to predict the optical flow between a pair of images, i.e., to find matches between them. Starting from a rough camera localization estimate, our insight is to exploit the correlation layer of PWC-Net and its ability to match features from different points of view to regress the correct 6-DoF camera pose. W e applied the following changes to the original architec- ture. • First, as our inputs are a depth and an RGB image (instead of two RGB images), we decoupled the feature pyramid extractors by removing the weights sharing. • Then, as we aim to perform pose regression, we re- mov ed the up-sampling layers, attaching the fully con- nected layers just after the first cost volume layer . Regarding the regression part, we added one fully connected layer with 512 neurons before the first optical flow estimation layer (conv6 4 in PWC-Net), follo wed by two branches for handling rotations and translations. Each branch is composed of two stacked fully connected layers, the first with 256 while the second with 3 or 4 neurons, for translation and rotation respectiv ely . Giv en an input pair composed of a RGB image I and a LiD AR-image D , we used the follo wing loss function in Equation (3), where L t ( I , D ) is the translation loss and L q ( I , D ) is the rotation loss. L ( I , D ) = L t ( I , D ) + L q ( I , D ) (3) For the translation we used a smooth L 1 loss [29]. Regarding the rotation loss, since the Euclidean distance does not provide a significant measure to describe the difference between two orientations, we used the angular distance between quaternions, as defined below: L q ( I , D ) = D a ( q ∗ inv ( ˜ q )) (4) D a ( m ) = atan 2( p b 2 m + c 2 m + d 2 m , | a m | ) (5) Here, q is the ground truth rotation, ˜ q represents the pre- dicted normalized rotation, inv is the in verse operation for quaternions, { a m , b m , c m , d m } are the components of the quaternion m and ∗ is the multiplicativ e operation of two quaternions. In order to use Equation (5) as a loss function, we need to ensure that it is differentiable for every possible output of the network. Recalling that atan 2( y , x ) is not differentiable for y = 0 ∧ x ≤ 0 , and the fact that m is a unit quaternion, we can easily verify that Equation (5) is differentiable in S 3 . C. Iterative refinement When the initial pose strongly de viates with respect to the camera frame, the map projection produces a LiD AR- image that shares just a fe w correspondences with the camera image. In this case, the camera pose prediction task is hard, because the CNN lacks the required information to compare the two points of view . It is therefore quite likely that the predicted camera pose is not accurate enough. T aking inspiration from [26], we propose an iterati ve refinement approach. In particular, we trained dif ferent CNNs by con- sidering descending error ranges for both the translation and rotation components of the initial pose. Once a LiD AR- image is obtained for a given camera pose, both the camera and the LiDAR-image are processed, starting from the CNN that has been trained with the largest error range. Then, a new projection of the map points is performed, and the process is repeated using a CNN trained with a reduced error range. Repeating this operation n times is possible to impro ve the accuracy of the final localization. The improvement is achiev ed thanks to the increasing overlap between the scene observed from the camera and the scene projected in the n th LiD AR-image. D. T raining details W e implemented CMRNet using the PyT orch library [30], and a slightly modified version of the official PWC-Net implementation. Regarding the acti vation function, we used a leaky RELU (REctified Linear Unit) with a negativ e slope of 0 . 1 as non-linearity . Finally , CMRNet was trained from scratch for 300 epochs using the ADAM optimizer with default parameters, a batch size of 24 and a learning rate of 1 e − 4 on a single NV idia GTX 1080ti. I V . E X P E R I M E N TA L R E S U L T S This section describes the e valuation procedure we adopted to validate CMRNet, including the used dataset, the assessed system components, the iterativ e refinements and finally the generalization capabilities. W e wish to emphasize that, in order to assess the perfor- mance of CMRNet itself, in all the performed experiments each input was processed independently , i.e., without any tracking or temporal integration strategy . A. Dataset W e tested the localization accuracy of our method on the KITTI odometry dataset. Specifically , we used the sequences from 03 to 09 for training (11697 frames) and the sequence 00 for validating (4541 frames). Note that the validation set is spatially separated from the train set, except for a very small sub-sequence (approx 200 frames), thus it is fair to say that the network is tested in scenes nev er seen during the training phase. Since the accuracy of the provided GPS- R TK ground truth is not suf ficient for our task (the resulting map is not aligned nearby loop closures), we used a LiDAR- based SLAM system to obtain consistent trajectories. The resulting poses are used to generate a down-sampled map with a resolution of 0.1m. This choice is the result of our expectations on the format of HD-maps that will be soon av ailable from map providers [10]. Since the images from the KITTI dataset have different sizes (varying from 1224x370 to 1242x376), we padded all images to 1280x384, in order to match the CNN architecture requirement, i.e., width and height multiple of 64. Note that we first projected the map points into the LiD AR-image and then we padded both RGB and LiD AR-image, in order not to modify the camera projection parameters. T o simulate a noisy initial pose estimate H init , we applied, independently for each input, a random translation, and rotation to the ground truth camera pose. In particular , for each component, we added a uniformly distributed noise in the range of [-2m, +2m] for the translation and [ − 10 ◦ , +10 ◦ ] for the rotation. Finally , we applied the following data augmentation scheme: first, we randomly changed the image brightness, contrast and saturation (all in the range [0.9, 1.1]). Then we randomly mirrored the image horizontally , and last we applied a random image rotation in the range [ − 5 ◦ , +5 ◦ ] along the optical axis. The 3D point cloud was transformed accordingly . Both data augmentation and the selection of H init take place at run-time, leading to different LiD AR-images for the same RGB image across epochs. B. System Components Evaluation W e ev aluated the performances of CMRNet by assessing the localization accuracy , varying different sub-components of the ov erall system. Among them, the most significativ e are shown in T able I, and derive from the following operational workflo w . First, we e valuated the best CNN to be used as backbone, comparing the performances of state-of-the-art approaches, namely PWC-Net, ResNet18 and RegNet [26], [27], [31]. According to the performed e xperiments, PWC-Net main- tained a remarkable superiority with respect to RegNet and ResNet18 and therefore was chosen as a starting point for further ev aluation. Thereafter , we estimated the effects in modifying both inputs, i.e., camera images and LiDAR-images. In particular, we added a random image mirroring and e xperimented dif fer- ent parameter values influencing the effect of the occlusion filtering presented in Section III-A, i.e., size K and threshold Th . At last, the effecti veness of the rotation loss proposed in Section III-B was ev aluated with respect to the commonly used L 1 loss. The proposed loss function achieved a relativ e decrease of rotation error of approx. 35%. The noise added to the poses in the v alidation set was kept fixed on all the experiments, allowing for a fair comparison of the performances. C. Iterative Refinement and Overall Assessment In order to improv e the localization accuracy of our sys- tem, we tested the iterati ve approach explained in Section III- C. In particular , we trained three instances of CMRNet varying the maximum error ranges of the initial camera poses. T o assess the robustness of CMRNet, we repeated the localization process for 10 times using dif ferent initial noises. T ABLE I P A R A ME T E R E ST I M A T I O N Occlusion Error Backbone K Th Mirroring Rot. Loss Transl. Rot. Regnet - - 7 D a 0.64m 1.67 ◦ ResNet18 - - 7 D a 0.60m 1.59 ◦ PWC-Net 11 3.9999 7 D a 0.52m 1.50 ◦ PWC-Net 13 3.9999 7 D a 0.51m 1.43 ◦ PWC-Net 5 3.0 7 D a 0.47m 1.45 ◦ PWC-Net 5 3.0 3 D a 0.46m 1.36 ◦ PWC-Net 5 3.0 3 L 1 0.46m 2.07 ◦ Median localization accuracy varying different sub-components of the overall system. K and Th correspond to the occlusion filter parameters as described in Section III-A. T ABLE II I T ER ATI V E P O SE R E FI N EM E N T Initial Error Range Localization Error T ransl. [m] Rot. [deg] T ransl. [m] Rot. [deg] Iteration 1 [-2, +2] [ − 10 , +10 ] 0.51 1 . 39 Iteration 2 [-1, +1] [ − 2 , +2 ] 0.31 1 . 09 Iteration 3 [-0.6, +0.6] [ − 2 , +2 ] 0.27 1.07 Median localization error at each step of the iterative refinement averaged over 10 runs. T ABLE III R U N T IM E P E R FO R M A NC E S Z-Buffer Occlusion Filter CMRNet T otal T ime [ms] 8.6 1.4 4.6 14.7 ( ∼ 68Hz) In the table, an analysis of the time performances of the system steps for a single ex ecution, i.e., 44.1ms for the 3-stages iterative refinement. All the code was developed in CUDA, achieving 68fps runtime performances on the KITTI dataset. CPU-GPU transfer time was not here considerated. The a veraged results are shown in T able II together with the correspondent ranges used for training each network. Moreov er , in order to compare the localization perfor- mances with the state-of-the-art monocular localization in LiD AR maps [3], we calculated mean and standard devia- tion for both rotation and translation components over 10 runs on the sequence 00 of the KITTI odometry dataset. Our approach shows comparable values for the translation component ( 0 . 33 ± 0 . 22 m w .r .t. 0 . 30 ± 0 . 11 m), with a lo wer rotation errors ( 1 . 07 ± 0 . 77 ◦ w .r .t. 1 . 65 ± 0 . 91 ◦ ). Ne vertheless, it is worth to note that our approach still does not take advantage of any pose tracking procedure nor multi-frame analysis. Some qualitati ve examples of the localization capabilities of CMRNet with the aforementioned iteration scheme are depicted in Figure 3. In Figure 4 we illustrate the probability density functions (PDF) of the error, decomposed into the six components of the pose, for the three iterations of the aforementioned refinement. It can be noted that the PDF of even the first network iteration approximates a Gaussian distribution and following iterations further decrease the variance of the distributions. An analysis of the runtime performances using this con- figuration is shown in T able III. Fig. 3. Four examples of the localization results. From left to right: Input LiD AR-image, CMRNet result after the third iteration, ground truth. All LiD AR-images are overlayed with the respecti ve RGB image for visualization purpose. (a) Longitudinal Errors (b) Lateral Errors (c) V ertical Errors (d) Roll Errors (e) Pitch Errors (f) Y a w Errors Fig. 4. Iterativ e refinement error distributions: a PDF has been fitted (using Gaussian kernel density estimation) on the network error outcome for each iteration step and each component. The dashed red lines are the theoretic PDFs of the initial H init errors. D. Generalization Capabilities In order to assess the generalization effecti veness of our approach, we e valuated its localization performance using a 3D LiD AR-map generated on a dif ferent day with respect to the camera images, yet still of the same en vironment. This al- lows us to hav e a completely different arrangement of parked cars and therefore to stress the localization capabilities. Unfortunately , there is only a short overlap between the sequences of the odometry dataset (approx. 200 frames), consisting of a small stretch of roads in common between sequences ”00” and ”07”. Ev en though we cannot completely rely on the results of this limited set of frames, CMRNet achiev ed 0.57m and 0.9 ◦ median localization accurac y on this test. Indeed, it is worth to notice that the network was trained with maps representing the same exact scene of the respectiv e images, i.e ., with cars parked in the same parking spots, and thus cannot learn to ignore cluttering scene elements. V . C O N C L U S I O N S In this work we ha ve described CMRNet, a CNN based approach for camera to LiD AR-Map registration, using the KITTI dataset for both learning and validation purposes. The performances of the proposed approach allow multiple specialized CMRNet to be stacked as to impro ve the final camera localization, yet preserving realtime requirements. The results have shown that our proposal is able to localize the camera with a median of less than 0 . 27 m and 1 . 07 ◦ . Preliminary and not reported experiments on other datasets suggests there is room for impro vement and the reason seems to be due to the limited vertical field-of-view av ailable for the point clouds.Since our method does not learn the map but learn ho w to perform the registration, it is suitable for being used with large-scale HD-Maps. V I . F U T U R E W O R K S Even though our approach does not embed any informa- tion of specific maps, a dependency on the intrinsic camera calibration parameters still holds. As part of the future works we plan to increase the generalization capabilities so to not directly depend from a specific camera calibration. Finally , since the error distributions reveal a similarity with respect to Gaussian distributions, we expect to be able to benefit from standard filtering techniques aimed to probabilistically tackle the uncertainties ov er time. A C K N O W L E D G M E N T S The authors would like to thank Tim Caselitz for his con- tribution related to the ground truth SLAM-based trajectories for the KITTI sequences and Pietro Colombo for the help in the editing of the associated video. R E F E R E N C E S [1] V . V aquero, I. del Pino, F . Moreno-Noguer, J. Sol ` a, A. Sanfeliu, and J. Andrade-Cetto, “Decon volutional networks for point-cloud vehicle detection and tracking in driving scenarios, ” in 2017 Eur opean Confer ence on Mobile Robots (ECMR) , 2017, pp. 1–7. [2] X. Chen, H. Ma, J. W an, B. Li, and T . Xia, “Multi-view 3d object detection network for autonomous driving, ” in The IEEE Conference on Computer V ision and P attern Recognition (CVPR) , July 2017. [3] T . Caselitz, B. Steder, M. Ruhnke, and W . Burgard, “Monocular camera localization in 3d lidar maps, ” in 2016 IEEE/RSJ International Confer ence on Intelligent Robots and Systems (IROS) , 2016, pp. 1926– 1931. [4] R. W . W olcott and R. M. Eustice, “V isual localization within lidar maps for automated urban driving, ” in 2014 IEEE/RSJ International Confer ence on Intelligent Robots and Systems , 2014, pp. 176–183. [5] P . Neubert, S. Schubert, and P . Protzel, “Sampling-based methods for visual navigation in 3d maps by synthesizing depth images, ” in 2017 IEEE/RSJ International Confer ence on Intelligent Robots and Systems (IR OS) , 2017, pp. 2492–2498. [6] I. P . Alonso, D. F . Llorca, M. Gavilan, S. A. Pardo, M. A. Garcia- Garrido, L. Vlacic, and M. A. Sotelo, “ Accurate global localization using visual odometry and digital maps on urban en vironments, ” IEEE T rans. Intell. T ransp. Syst. , Dec 2012. [7] G. Cao, F . Damerow , B. Flade, M. Helmling, and J. Eggert, “Camera to map alignment for accurate low-cost lane-level scene interpretation, ” Nov 2016. [8] M. Raaijmakers and M. E. Bouzouraa, “In-vehicle roundabout percep- tion supported by a priori map data, ” Sept 2015. [9] A. L. Ballardini, D. Cattaneo, and D. G. Sorrenti, “V isual localiza- tion at intersections with digital maps, ” in 2019 IEEE International Confer ence on Robotics and Automation (ICRA) , In press. [10] “The future of maps: technologies, processes and ecosystem, ” https: //www .here.com/file/7766/download?token=dwOqPUix, 12 2018, ac- cessed: 2019-04-13. [11] A. K endall, M. Grimes, and R. Cipolla, “Posenet: A con volutional network for real-time 6-dof camera relocalization, ” in The IEEE In- ternational Confer ence on Computer V ision (ICCV) , December 2015. [12] A. Geiger, P . Lenz, C. Stiller , and R. Urtasun, “V ision meets robotics: The kitti dataset, ” International J ournal of Robotics Resear ch (IJRR) , 2013. [13] A. R. Zamir and M. Shah, “ Accurate image localization based on google maps street view , ” in Computer V ision – ECCV 2010 , K. Dani- ilidis, P . Maragos, and N. Paragios, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2010, pp. 255–268. [14] T . Sattler, B. Leibe, and L. Kobbelt, “Improving image-based local- ization by active correspondence search, ” in Computer V ision – ECCV 2012 , A. Fitzgibbon, S. Lazebnik, P . Perona, Y . Sato, and C. Schmid, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2012, pp. 752– 765. [15] A. Kendall and R. Cipolla, “Geometric loss functions for camera pose regression with deep learning, ” in The IEEE Conference on Computer V ision and P attern Recognition (CVPR) , July 2017. [16] A. Kendall and R. Cipolla, “Modelling uncertainty in deep learning for camera relocalization, ” in 2016 IEEE International Conference on Robotics and Automation (ICRA) , 2016, pp. 4762–4769. [17] T . Naseer and W . Burgard, “Deep regression for monocular camera- based 6-dof global localization in outdoor en vironments, ” in 2017 IEEE/RSJ International Confer ence on Intelligent Robots and Systems (IR OS) , 2017, pp. 1525–1530. [18] S. Brahmbhatt, J. Gu, K. Kim, J. Hays, and J. Kautz, “Geometry-aw are learning of maps for camera localization, ” in The IEEE Conference on Computer V ision and P attern Recognition (CVPR) , June 2018. [19] N. Radwan, A. V alada, and W . Burgard, “Vlocnet++: Deep multitask learning for semantic visual localization and odometry , ” IEEE Robotics and Automation Letters , vol. 3, no. 4, pp. 4407–4414, 2018. [20] J. Shotton, B. Glocker , C. Zach, S. Izadi, A. Criminisi, and A. Fitzgib- bon, “Scene coordinate regression forests for camera relocalization in rgb-d images, ” in The IEEE Conference on Computer V ision and P attern Recognition (CVPR) , June 2013. [21] R. Clark, S. W ang, A. Markham, N. Trigoni, and H. W en, “V idloc: A deep spatio-temporal model for 6-dof video-clip relocalization, ” in The IEEE Conference on Computer V ision and P attern Recognition (CVPR) , July 2017. [22] E. Brachmann, A. Krull, S. Nowozin, J. Shotton, F . Michel, S. Gumhold, and C. Rother, “Dsac - differentiable ransac for camera localization, ” in The IEEE Confer ence on Computer V ision and P attern Recognition (CVPR) , July 2017. [23] E. Brachmann and C. Rother , “Learning less is more - 6d camera localization via 3d surface regression, ” in The IEEE Conference on Computer V ision and P attern Recognition (CVPR) , June 2018. [24] D. G. Lowe, “Distinctiv e image features from scale-inv ariant key- points, ” International Journal of Computer V ision , vol. 60, no. 2, pp. 91–110, Nov 2004. [25] H. Bay , A. Ess, T . Tuytelaars, and L. V . Gool, “Speeded-up robust features (surf), ” Computer V ision and Image Understanding , vol. 110, no. 3, pp. 346 – 359, 2008. [26] N. Schneider, F . Piewak, C. Stiller, and U. Franke, “Regnet: Multi- modal sensor re gistration using deep neural networks, ” in 2017 IEEE Intelligent V ehicles Symposium (IV) , 2017, pp. 1803–1810. [27] D. Sun, X. Y ang, M.-Y . Liu, and J. Kautz, “Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume, ” in The IEEE Confer ence on Computer V ision and P attern Recognition (CVPR) , June 2018. [28] R. Pintus, E. Gobbetti, and M. Agus, “Real-time rendering of mas- siv e unstructured raw point clouds using screen-space operators, ” in Pr oceedings of the 12th International conference on V irtual Reality , Ar chaeology and Cultural Heritage . Eurographics Association, 2011, pp. 105–112. [29] R. Girshick, “Fast r-cnn, ” in Proceedings of the IEEE international confer ence on computer vision , 2015, pp. 1440–1448. [30] A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Y ang, Z. DeV ito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer, “ Automatic differen- tiation in pytorch, ” in NIPS-W , 2017. [31] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition, ” in Pr oceedings of the IEEE conference on computer vision and pattern r ecognition , 2016, pp. 770–778.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment