엔드투엔드 딥러닝 기반 광대역 음성 코딩
본 논문은 원시 음성 파형을 입력으로 하는 완전 엔드투엔드 딥 뉴럴 네트워크를 설계해, 압축·양자화·엔트로피 코딩·복원을 모두 학습한다. 9 kbps~24 kbps 구간에서 기존 AMR‑WB 표준과 동등하거나 약간 우수한 PESQ 점수를 달성했으며, 3.8 GHz CPU에서도 실시간 인코·디코가 가능하다.
저자: Srihari Kankanahalli
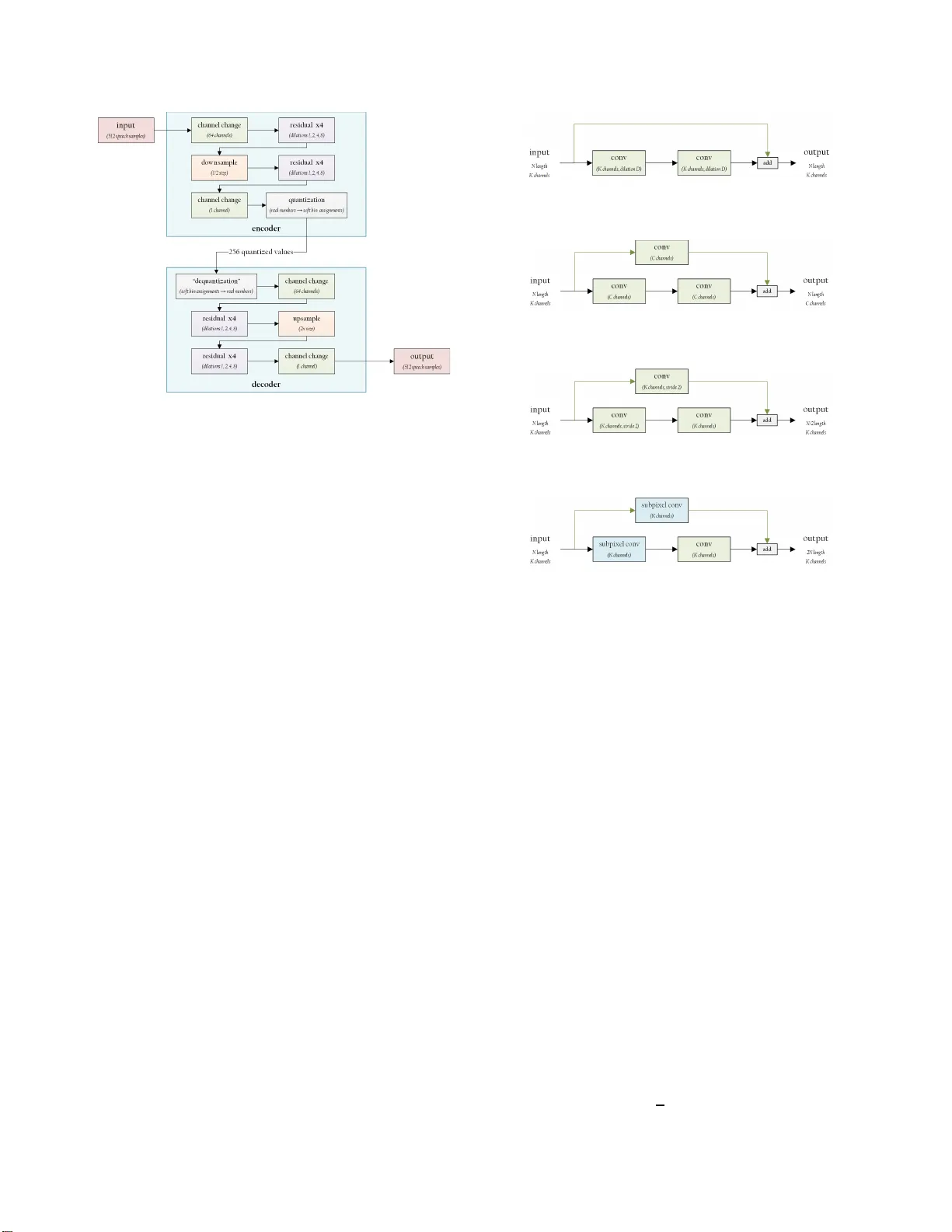
본 논문은 광대역 음성 코딩을 위한 완전 엔드투엔드 딥 뉴럴 네트워크(Deep Neural Network, DNN) 모델을 제안한다. 기존의 AMR‑WB와 같은 표준 코덱은 수년간의 도메인‑특화 연구와 손수 설계된 파이프라인(프레임 분할, LPC, 코드북, 비트스트림 포맷 등)으로 구성되어 있다. 저자는 이러한 복잡한 설계 과정을 모두 신경망 하나로 대체하고, 원시 파형을 직접 입력·출력하도록 설계하였다.
네트워크 구조는 인코더와 디코더로 이루어진 대칭형 auto‑encoder 형태이며, 1‑D 컨볼루션 residual 블록을 네 종류(standard residual, down‑sample, up‑sample, channel‑change)로 조합한다. 모든 컨볼루션은 필터 길이 9, PReLU 활성화 함수를 사용하고, up‑sampling은 sub‑pixel convolution을 적용한다. 배치 정규화는 실험적으로 적용되지 않았다. 입력은 32 ms(512 샘플) 길이의 음성 윈도우이며, 출력 역시 동일한 길이의 재구성 파형이다.
양자화는 기존의 비미분 가능한 하드 양자화 대신, “softmax quantization”이라 부르는 연속적인 소프트 어사인먼트 방식을 채택한다. 스칼라 값 x와 미리 정의된 N개의 양자화 구간 B₁…B_N 사이의 거리 D를 구하고, D에 대해 온도 σ를 곱한 뒤 softmax을 적용해 확률 벡터 S를 만든다. 학습 초기에 σ를 크게(300) 설정해 부드러운 분포를 유지하고, 학습이 진행됨에 따라 σ를 증가시켜 하드 양자화에 가까워지게 한다. 디코더는 S와 구간 B의 내적을 통해 복원된 실수 값을 얻는다.
손실 함수는 네 가지 항목을 가중합한다. (1) ℓ₂ 손실은 재구성 파형과 원본 파형 사이의 평균 제곱 오차를 최소화한다. (2) 퍼셉추얼 손실은 MFCC 기반으로 정의되며, 4개의 서로 다른 필터뱅크(8, 16, 32, 128)에서 추출한 MFCC 벡터 간 ℓ₂ 거리를 평균한다. 이는 인간 청각 특성을 일부 반영해 고주파 디테일을 보존한다. (3) 양자화 패널티 Q(c)는 소프트 어사인먼트가 원‑핫 형태에 가깝도록 유도한다. (4) 엔트로피 손실 E(c)는 출력 심볼의 확률 분포 엔트로피를 추정해 목표 비트레이트를 조절한다. 엔트로피는 히스토그램 기반으로 계산되며, λ_entropy 파라미터를 동적으로 조정해 비트레이트 목표값(±0.45 kbps) 안에 유지한다.
학습은 두 단계로 진행된다. 첫 단계(Pre‑training)에서는 양자화를 비활성화하고 ℓ₂·퍼셉추얼 손실만으로 5 epoch를 학습한다. 이후 K‑means로 양자화 구간을 초기화하고 양자화를 켠다. 두 번째 단계에서는 전체 손실을 사용해 145 epoch를 학습한다. 매 epoch마다 검증 셋의 PESQ를 측정하고 최고 성능 모델을 저장한다. 학습 데이터는 TIMIT 코퍼스에서 3,000개의 훈련 파일, 200개의 검증 파일, 500개의 테스트 파일을 추출했으며, 각 파일은 32 ms 윈도우와 2 ms 오버랩(한 윈도우당 480개의 고유 샘플)으로 전처리했다.
실험 결과, 9 kbps, 16 kbps, 20 kbps, 24 kbps 네 비트레이트에서 DNN 코덱은 AMR‑WB 대비 평균 PESQ가 0.05~0.2 정도 향상되었다. 특히 높은 비트레이트(≥20 kbps)에서 차이가 크게 나타났으며, 훈련 셋에서 약간의 오버피팅이 관찰되었다(검증·테스트 셋에서는 차이가 감소). 주관적 청취 테스트(Amazon Mechanical Turk)에서는 20명 이상의 청취자가 원본·두 코덱의 출력 중 선호도를 선택했으며, 전반적으로 AMR‑WB가 약간 더 선호되었지만 비트레이트가 높아질수록 차이가 줄어들었다. 이는 현재 퍼셉추얼 손실이 인간 청취 특성을 완전히 포착하지 못함을 의미한다.
연산 측면에서 인코더는 10.5 ms, 디코더는 10.9 ms(총 21.4 ms)를 소요했으며, 3.8 GHz 인텔 i7‑4970K CPU에서도 실시간(30 ms 윈도우) 처리가 가능했다. GPU에서는 2.4 ms(인코딩)·2.3 ms(디코딩)으로 더 빠르게 동작한다. 그러나 실제 모바일·임베디드 환경에서는 추가적인 모델 압축·양자화·하드웨어 최적화가 필요하다.
결론적으로, 저자는 (1) 전통적인 음성 코덱 파이프라인을 완전 자동화된 엔드투엔드 학습으로 대체, (2) 차별화된 softmax 양자화와 엔트로피 기반 비트레이트 제어, (3) MFCC 기반 퍼셉추얼 손실을 도입해 고품질 재구성을 달성, (4) 비교적 짧은 학습 시간과 실시간 인코·디코 구현이라는 네 가지 주요 기여를 제시한다. 향후 연구 과제로는 더 정교한 청각 기반 퍼셉추얼 손실, 잡음·음악 포함 데이터셋 확대, 모델 경량화 및 하드웨어 친화적 압축 기법이 제시된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기