End-to-End Optimized Speech Coding with Deep Neural Networks
Modern compression algorithms are often the result of laborious domain-specific research; industry standards such as MP3, JPEG, and AMR-WB took years to develop and were largely hand-designed. We present a deep neural network model which optimizes al…
Authors: Srihari Kankanahalli
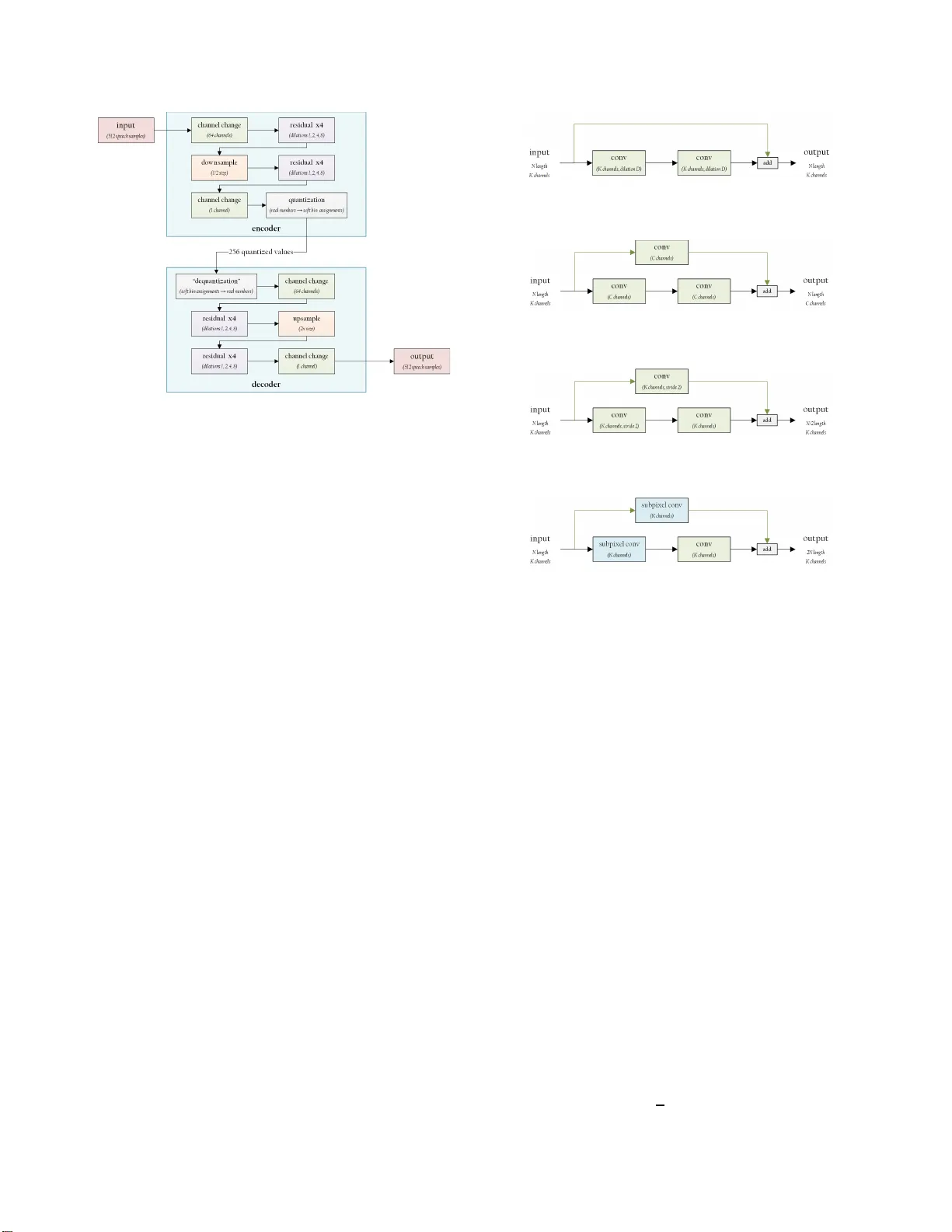
END-T O-END OPTIMIZED SPEECH COD ING WITH DEEP NEURAL NETWORKS Srihari Kankanahalli Zenovia Interactiv e sri@zenovia.io ABSTRA CT Modern compression algo rithms are often the r esult of la- boriou s domain-specific research; industry standard s such as MP3, JPEG, and AM R-WB took yea rs to develop and were largely hand-designed . W e present a dee p neural network model which optimizes all the steps of a wid eband spee ch coding pipeline (compression, quantization, entropy coding, and decomp r ession) end-to-end directly from raw speech data – no m a n ual feature en gineerin g n ecessary , and it trains in hours. In testing, ou r DNN-based cod e r perf orms o n par with the A M R-WB standard at a v ariety o f bitrates ( ∼ 9kbps up to ∼ 24kb ps). It also runs in realtime on a 3.8GhZ Intel CPU. Index T er ms — speech coding, dee p learning, n eural net- works, end-to-e nd tr aining, compr ession 1. INTR ODUCTION The e veryday app lica tions of data compression are ubiq ui- tous: streamin g live videos a n d mu sic in realtime acr o ss the planet, storin g thousand s of imag es and so ngs on a single tiny thumb dr ive, an d more. In a way , improved compre ssion was what made these innovations possible in the first plac e , and designing better an d more ef ficient methods o f compression could help expand them e ven further (to de veloping n ations with slower Internet speed s, for example) . Essentially all modern compression standards are hand- designed, including the mo st pr o minent wideband speech coder: AMR-WB [1]. It was crea ted by eight speech co ding researchers working at the V oiceAge Corpo ration ( in Mon - treal) and the No k ia Research Center ( in Finland ) over two years, and it pr ovides speech at a wide variety of bitrates ranging from 7kbps through 24kbps. (F or reference , u ncom- pressed wideban d speech has a bitrate of 2 56kb p s.) Recently , deep neural n etworks have shown a n incredible ability to lear n direc tly from data, circumventing traditio n al feature engineer ing to p roduc e state-of-th e-art results in a va- riety of areas [2]. Neural networks have seen si gnifican t his- torical interest fro m compre ssion research ers, but almost al- ways as a n in termediate p ipeline step, or as a way to optimize This pa per is based on independe nt research that the author conducted for his Master’ s Thesis at the Uni versity of Maryland, under Dr . Davi d Ja- cobs. the parameter s of an intermediate step [3]. For example, Kr - ishnamurth y et al. [4] used a n eural network to perfo rm vector quantization on speech featur es; W u et al. [5] u sed an ANN as part of a predictive speech coder; an d Cernak et al. [6] u sed a deep neural n etwork as a phonolog ical vocoder . Our pr o posal is different in natur e f r om all o f these: we reframe the entire co mpression pip eline, fr om start to fin ish, as a neural network optimization p roblem (along the lines of classical auto e ncoder s). A s far as we know , this is o nly the second p u blished work to lear n an aud io comp ression pip eline end-to- end – the previous being an ob scu re early attem pt by Morishima et al. in 19 90 [7] – and the first to comp ete with a co ntempo r ary standard. Cernak et al. [8] proposed a nearly end-to- end d e sign f or a very-low-bitrate low-quality speech coder in 201 6; howe ver , th eir pipeline still required extraction of acou stic features an d p itch (an d was also q uite comp lex, composin g se veral dif feren t dee p and spikin g n eural networks together) . All other related design s we know of employ ANNs as a m ere com ponen t of a larger han d-design ed system. In th e doma in of imag e c ompression , there has been some interest in training ANN- based systems since the 19 90s [9], but th is has not yield e d state-of-th e-art r esults until fairly recently either (starting August 2016, when T oderici et al. trained a neural network mod e l outperfo rming JPEG [10]). Thus, it seem s our work is on the c u tting edge of bo th deep learning resear ch and co mpression research. 2. NETWORK ARCHITECTURE AND TRAINING METHODOLOGY Our network arch itecture, shown in Figur e 1, is inspired by both residual n eural networks [1 1] an d autoencod ers. The model is comp osed of an encoder subnetwork and a deco der subnetwork; it takes in a vector of 512 speech samples (a 32ms speech win d ow) and outputs another vector of 512 speech samples (the reconstruc te d window after com pression and d e c ompression ). The ne twork is composed of 4 different types o f residua l b locks [ 11], shown in Figure 2. All conv olu- tions u se 1D filters of size 9 and PReLU acti vations [12]; the upsample block uses sub p ixel conv olution s [13]. (W e wer e unable to su ccessfully inc orpor ate batch n ormalizatio n .) Fig. 1 : Simplified ne twork ar chitecture. 2.1. Softmax Quantization Quantization – mapp ing the r eal-valued outpu t of a n e u ral net- work into discrete bin s – is an essential p art of ou r pipelin e. Howe ver , quantization is inherently no n-differentiable, and therefor e incompatible with the stan d ard gra dient-descen t- based method s u sed to train neural network s. In or der to circumvent th is, we u se a differentiable ap- proxim a tion first d iscussed by Agustsson et al. [14]. Specif- ically , we reframe scalar quantization as nearest-neighbor as- signment: given a list B of N bins, we quan tize a scalar x by assigning it to th e neare st qu a n tization bin. Th is operatio n still isn’t differentiable, but c a n be approximated as follows : D = [ | x − B 1 | , ..., | x − B N | ] ∈ R N (1) S = sof tmax ( − σ D ) (2) S is a soft assignment over the N quan tization bin s, which be- comes a hard assignment as σ → ∞ (and can later be rounded into one). On the deco d er side, we c an ”deq uantize” S back into a r eal v alue ˆ S by taking the dot product of S and B . Sinc e Agustsson et al. did not give this approximatio n a name, we hereby dub it softmax quantization . In practice, we noticed no problems trainin g with very high temper ature values f rom the start. For all experiments, we initialized with σ = 30 0 , making σ and B trainable pa - rameters of th e network. (W e also found th a t scalar quantiza- tion gave better-sounding results than the vector quan tization more pro minently discussed b y Ag ustsson et al.) 2.2. Objective Functio n The network’ s objective functio n is as f ollows: (a) residu al (b) ch annel chan g e (c) downsample (d) upsamp le Fig. 2 : Th e fo ur block types used in our n etwork architectu re. O ( x, y , c ) = λ mse ℓ 2 ( x, y ) + λ perceptual P ( x, y ) + λ quantiz ation Q ( c ) + λ entropy E ( c ) (3) where x is the o riginal signal, y is the reconstructed signa l, c is the enco der’ s output (the soft assign ments to qua n tization bins), ℓ 2 ( x, y ) is mean-sq uared erro r , and λ correspo nds to weights for each loss. P ( x, y ) , Q ( c ) , and E ( c ) are sup ple- mental losses, wh ich we now discuss in more depth. • P er ceptual loss. T raining a mode l solely to m in imize mean-squ ared error o f ten leads to blur ry reco n struc- tions lack ing in high-f r equency content [15] [16]. Therefo re, we augment our model with a percep tu al loss. W e compu te MFCCs [17] for both the origi- nal and reco nstructed signals, an d use the ℓ 2 distance between MFCC vectors as a prox y fo r percep tual dis- tance. T o allow for bo th co arse and fine d ifferentiation , we u se 4 MFCC fil terban ks of sizes 8, 1 6, 32, and 128: P ( x, y ) = 1 4 4 X i =1 ℓ 2 ( M i ( x ) , M i ( y )) (4) where M i is the MFC C f unction fo r filterbank i . • Quan tization penalty . Because softmax quantization is a co n tinuou s appro ximation, it is p ossible for the net- work to learn h ow to generate values outside the in - tended quantizatio n bins – and it almo st a lways will, if there is no additional penalty fo r d o ing so. T here- fore, we defin e a loss func tion fav oring soft assign- ments close to one-ho t vectors: Q ( c ) = 1 256 255 X i = 0 [ ( N − 1 X j = 0 √ c i,j ) − 1 . 0 ] (5) Q ( c ) is zero when all 256 e n coded symb ols are one-h ot vectors, and no nzero otherwise. • Entr opy contr ol. W e a p ply en tropy codin g to the q uan- tized sym bols, wh ich p rovides a simple way to spec- ify different b itrates without having to e ngineer entirely different network a rchitecture s for eac h o ne. Depend- ing on our d e sired bitrate, we can co nstrain the entro py of the enc o der’ s ou tput to be higher or lower (by mod i- fying the loss we ig ht λ entropy approp riately). T o estimate the en coder’ s entropy , we compu te a prob- ability distribution h specifying how often each qu a n- tized symb ol appears in the en coder’ s output, by av er- aging all of the soft assign ments the enco der g enerates over on e minib a tc h . Thus, o ur entropy estimate is : E ( c ) = X h = histogr am ( c ) − h i l og 2 ( h i ) (6) 2.3. T raining Process W e train the network on samples from the TIMI T speech corpuz s [18], which contains o ver 6,000 wideband rec o rd- ings of 63 0 American Eng lish speakers from 8 m ajor dialects. W e create smaller training /validation/test sets f rom the pre- existing tr ain/test split: o ur tra in ing set consists of 3 ,000 files from the orig inal train set, o ur validation set c o nsists of 20 0 files from the or iginal train set, an d ou r test set consists o f 500 files from the original test set. Each set co ntains an even dis- tribution over the 8 dialects, an d they do not sha r e any sp e ak- ers. Add itionally , we prep rocess each speech file by m axi- mizing its volume. W e extract raw speech windows of length 32ms (512 speech samples), with an overlap of 2ms ( 32 samples), using a Han n wind ow in the overlap region. This mean s that each speech window covers a total of 480 unique samples, or 3 0ms of speech. Our training p rocess takes place in two stages: 1. Qua ntization off . T he network is trained with o ut qu an- tization; in this stage, on ly the ℓ 2 and p e r ceptual losses are enabled. Af te r 5 ep ochs, the qu antization bin s are initialized using K-means clustering , λ entropy is set to an in itial value τ initial , and q uantization is tu rned on. W e f ound that this ”pre- training” pe riod im p roved the stability an d quality of th e network’ s o utput. 2. Quantizatio n o n . The network is tra in ed for 145 mor e epochs, targeting a specified bitrate. At the en d of each epoch, we evaluate the mo del’ s m ean PESQ over our validation set, and sav e the best-p erform ing one. W e also estimate the average bitrate o f the encoder : bitr ate = ( w indow s/sec ) ∗ ( sy mbol s/ wi ndow ) ∗ ( bits/sy mbol ) bps = 16000 512 − 32 ∗ 256 ∗ E ( c ) bps (7) If the estimated bitrate is above the target bitrate region, then λ entropy is incre a sed by a sm a ll value τ chang e ; if it is b elow th e target region , then λ entropy is decr eased by τ chang e . This removes the need to manu ally find the optim al λ entropy for each ta rget bitr a te . (The tar get region is de fin ed as o ur target bitrate ± 0 . 45kb p s.) During train ing, we also slo wly lo wer the n etwork’ s learn- ing rate from an initial value α initial to a final value α f inal , using cosine an nealing [19 ] [20]. W e repeat the training pro- cess fo r e a ch bitrate we want to target; for examp le, if we want to target 4 dif ferent b itrates, w e tra in 4 n etworks (u s- ing the same arch itecture, but end ing up with different sets of w e ights). The training p rocess takes abou t 20 hours p er network, on a GeF orce GTX 1080 Ti. 3. RESUL TS 3.1. Objective Qua lity Evaluation W e ev aluated th e average PESQ of our speech co d er versus the AMR-WB stand a rd ar ound 4 d ifferent target bitrates. The results are shown in Figure 3, and we reprodu ce them b elow: Dataset AMR-WB DNN Bitrate PESQ Bitrate PESQ T raining set 8.85 3.478 9.02 3.643 15.85 4.012 16.24 4.123 19.85 4.103 20.06 4.202 23.85 4.138 24.06 4.283 V alidation set 8.85 3.674 9.02 3.730 15.85 4.176 16.24 4.225 19.85 4.244 19.70 4.298 23.85 4.290 23.71 4.372 T est set 8.85 3.521 9.02 3.629 15.85 4.063 16.24 4.133 19.85 4.145 20.06 4.215 23.85 4.178 24.06 4.296 (a) trai ning set (b) v alidat ion set (c) test set Fig. 3 : Mean PESQ o f our encoder, compared with AMR-WB at different bitrates. Our spe e ch co der outp erform s AMR-WB at all b itr ates, espe- cially higher rates. The gap is bigger on the train ing set than on the validation or test sets, indicating po ssible overfitting (note that we did not use dropout or weig ht regularizatio n). 3.2. Subjective Quality Evaluation W e condu cted a simple prefer ence test using Amazon Me- chanical Turk. 20 spe ech files were rando mly selected from the test s et and processed with both AMR-WB and our method, at the same 4 target bitrates as be fore. Then, 20 listeners wer e p resented the o riginal speech sign al p lu s bo th processed versions (un labeled and ran domly switched). Each listener was asked to pick wh ich of the tw o he o r she p re- ferred. The subjects’ average preference s a r e record ed below: T arget Bitrat e DNN No Preference AMR-WB 9kbps 25.50 % 32.00 % 42.50 % 16kbp s 24.50 % 37.00 % 38.50 % 20kbp s 23.50 % 41.75 % 34.75 % 24kbp s 23.75 % 39.00 % 37.25 % Overall, the subjects slightly pre f erred AMR-WB to our DNN-based coder, with the gap narrowing a t higher bitrates. This ind icates tha t mo r e work need s to be done in or der to increase our model’ s subjective quality . 3.3. Computational Complexity W e e valuated the average time our model takes to encode and decode on e 30ms window , on an In tel i7 - 4970 K CPU (3.8Gh Z ) an d a GeForce GTX 1080 Ti GPU: Processor Encoder Decoder T ot al CPU 10.52 ms 1 0.90 m s 21.42 ms GPU 2.43m s 2.3 5ms 4.78ms Our speech coder run s in realtime (un d er 30ms f or co mbined encode and d ecode) without any optim iz a tions beyond those already provided by T ensor Flow and Keras. However , it’ s im - portant to note that real speech coders will need to run on processors muc h slower than the CPU we used. 4. CONCLUSION W e have shown a proof-o f-con cept applying d e e p neu ral net- works (DNNs) to speech co d ing, with v ery p r omising results. Our wideband speech code r is learn ed end-to -end f rom raw signal, with almost no audio-specific proce ssing aside from a relativ ely simple perce p tual loss; n evertheless, it man ages to compete with c urrent stand a r ds. The key to f urther increasing quality prob ably lies in our perceptu a l mo d el, which co uld be significa n tly more comp lex and nuanced. T h is is where psychoacoustic theo ry can c o me into the picture o nce again: to develop a differentiable percep - tual loss for this and o ther audio proc e ssing tasks. In additio n, expanding the train ing d ata to include music an d bac kgrou nd noise instead of solely clean speech may be fruitful. Finally , while our DNN-based coder alread y runs in real- time o n a mode rn desktop CPU, it’ s still a far cry from run- ning o n embedd ed systems or c e llp hones. Model co mpres- sion, transfer learning, an d cle ver arch itec ture designs are all interesting areas wh ich cou ld be explor ed h ere. 5. HYPERP ARAMETERS For pur poses of rep r oducib ility , we now make av ailable the list of parameters u sed for all experiments: σ initial 300 α initial 0.025 α f inal 0.01 λ perceptual 5.0 λ quantiz ation 10.0 λ mse 30.0 τ initial 0.5 τ chang e 0.025 N 32 Batch size 128 Optimizer Adam The param eters are listed in roug hly descending order by how mu ch manual tun ing they req uired. Sou r ce code will be made public after the revie wers’ decision. Speech samples are av ailable at: http: //srik.tk/s peech- coding 6. REFERENCES [1] Bruno Bessette, Redwan Salami, Roch Lefebvre, Mi- lan Jelinek, Jani Rotola - Pukkila, Jann e V ainio, Hann u Mikkola, and Kari Jarv inen, “The adaptiv e multirate wideband speec h c odec ( a m r-wb), ” I EEE transaction s on speec h and audio pr ocessing , vol. 10, n o. 8, pp. 620– 636, 20 02. [2] Y ann LeCun, Y oshua Bengio, an d Geoffrey Hinton, “Deep learn ing, ” Natur e , vol. 52 1, no . 7553, pp . 436– 444, 20 15. [3] Robert D Dony and Simon Haykin , “Ne u ral n etwork approa c h es to image compr e ssion, ” Pr oceed ings o f the IEEE , vol. 83 , no. 2 , pp. 2 88–30 3, 199 5. [4] Ashok K. Krishnamurth y , Stanley C. Ahalt, Douglas E. Melton, and Prakoon Chen, “Neural networks f o r vec- tor qua n tization of speech and imag es, ” IEEE jou rnal on selected ar eas in Communica tions , v ol. 8, no. 8 , pp. 1449– 1457 , 1990. [5] Lizho n g W u, Ma h esan Niranjan, and Frank Fallside, “Fully vecto r-quantized neur al network-b ased cod e- excited non lin ear predictive speech coding, ” IEEE transactions on speech and audio pr o cessing , vol. 2, no. 4, pp . 482 –489 , 1994 . [6] Milos Cernak , Blaise Potard, and Philip N Garner, “Phonolo gical vocodin g using artificial neur al net- works, ” in A coustics, Speech and Signal Pr ocess- ing (ICASSP), 201 5 IEEE Internation al Confer en ce on . IEEE, 2 015, pp. 4844–484 8 . [7] Shigeo Mo rishima, H Harashima, an d Y Katay ama, “Speech codin g b a sed on a multi-la y er n eural network, ” in Communicatio ns, 1990. ICC’90, In cluding S uper- comm T echnica l Session s. SUPERCOMM/ICC’90. Con - fer ence Record., IEEE Intern ational Conference on . IEEE, 1 990, pp. 429–433. [8] Milos Cern ak, Alexan d ros Lazaridis, Af saneh Asaei, and Philip N Garner, “Compo sition of deep and spik- ing ne u ral networks for very low bit ra te speech cod- ing, ” IEEE/ACM T ransactions o n Audio, Speech, an d Language Pr ocessing , vol. 24, no. 12, p p. 2301 –2312 , 2016. [9] J Jiang, “Image c o mpression with neur al networks–a survey , ” S ignal Pr ocessing : Image Comm unication , vol. 14, n o. 9, pp . 73 7 –760 , 1999 . [10] George T oderici, Dam ien V incent, Nick Jo hnston, Sung Jin Hwang, Da vid Minnen, Joel Sh or, and Michele Covell, “Full r esolution imag e com pres- sion with recur r ent neural networks, ” arXiv pr eprint arXiv:160 8.051 48 , 2016. [11] Kaimin g He, Xiang yu Zh ang, Sha oqing Ren, a n d Jian Sun, “Deep r e sid ual learning fo r image recog nition, ” in Pr o ceedings of the IE EE Conference on Computer V i- sion and P attern Recognition , 20 16, pp. 7 7 0–77 8. [12] Kaimin g He, Xiang yu Zh ang, Sha oqing Ren, a n d Jian Sun, “Delv ing de e p into rectifiers: Surpassing human - lev el perf ormanc e on im agenet classification, ” in Pr o- ceedings of th e IEEE intern ational conference on co m- puter vision , 2015 , pp. 1 026–1 034. [13] W enzhe Shi, Jose Caballero, Ferenc Husz ´ ar , Joha n nes T otz, And rew P Aitken, Rob Bishop, Daniel Rueckert, and Zehan W ang, “Real-time sing le imag e an d v ideo super-resolution using an efficient sub-pixel con volu- tional neural network, ” in Pr oceed ings o f the IEEE Con- fer ence on Co mputer V ision a nd P attern Recogn ition , 2016, pp. 1874–188 3. [14] Eirik ur Ag ustsson, Fabian Mentzer, Michael Tschan- nen, Lukas Cavigelli, Radu T imofte, Luca Benini, and Luc V an Goo l, “Soft-to- hard vector q uantization for end-to- end learned compression of images and neural networks, ” arXiv preprint arXiv: 1704 .0064 8 , 2017. [15] Micha el Mathieu, Camille Couprie, and Y ann LeCun, “Deep multi-scale v ideo pre d iction beyond mean squ are error, ” arXiv preprint arXiv:15 11.0 5440 , 2015 . [16] Alexey Do sovitskiy and Thomas Brox , “Ge n erating im - ages with perc eptual similarity metrics based o n deep networks, ” in Advances in Neural Information Pr oc ess- ing Systems , 201 6, p p. 6 5 8–66 6. [17] Lind asalwa Muda, Mumtaj Begam, and Irr aiv an Elam- vazuthi, “V oice reco gnition alg orithms using m e l frequen cy c e pstral coe fficient (mfcc) and d ynamic time warping (dtw) techn iques, ” arXiv p r eprint arXiv:100 3.408 3 , 2010. [18] John S Garofo lo, Lor i F Lam el, W illiam M Fisher, Jonathan G Fiscus, David S Pallett, Nancy L Dahlgren , and V ictor Zue, “Timit acou stic-phon etic continuo us speech c o rpus, ” Lin guistic data con sortium , vol. 10, no. 5, pp . 0, 199 3. [19] Ily a Loshchilov a n d Fra n k Hutter , “Sgdr: stochas- tic g radient d e scent with restarts, ” arXiv preprint arXiv:160 8.039 83 , 2016. [20] Xavier Gastaldi, “Shake-shake regularization , ” a rXiv pr eprint arXiv:1705. 07485 , 2 017.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment