의료 영상 딥러닝 시스템의 적대적 공격 이해와 방어 전략
본 논문은 의료 영상 분석에 사용되는 딥러닝 모델이 자연 이미지보다 적대적 공격에 더 취약함을 실험적으로 입증하고, 간단한 특징 기반 탐지기로 98% 이상의 검출 AUC를 달성할 수 있음을 보여준다. 이를 통해 의료 AI의 신뢰성 확보를 위한 새로운 설계 방향을 제시한다.
저자: Xingjun Ma, Yuhao Niu, Lin Gu
본 논문은 의료 영상 분석에 딥러닝이 널리 활용되는 현 상황에서, 적대적 공격이 의료 AI 시스템에 미치는 위험성을 정량·정성적으로 파악하고, 효과적인 탐지 방안을 제시한다. 서론에서는 자연 이미지에서 입증된 적대적 취약성이 의료 분야에도 동일하게 적용될 수 있음을 강조하며, 보험 사기·오진 등 실질적 위협 시나리오를 제시한다.
2절에서는 의료 영상 분석 파이프라인을 개괄한다. Fundoscopy(당뇨망막증), Chest X‑Ray(폐질환), Dermoscopy(피부암) 등 다양한 모달리티와 해부학적 부위를 다루는 데이터셋을 소개하고, 기존 연구에서 사용된 Inception, ResNet, VGG 등 자연 이미지용 CNN이 그대로 적용되는 현황을 설명한다. 또한 의료 영상 특유의 고해상도 텍스처와 제한된 라벨링 데이터가 모델 설계에 미치는 영향을 논의한다.
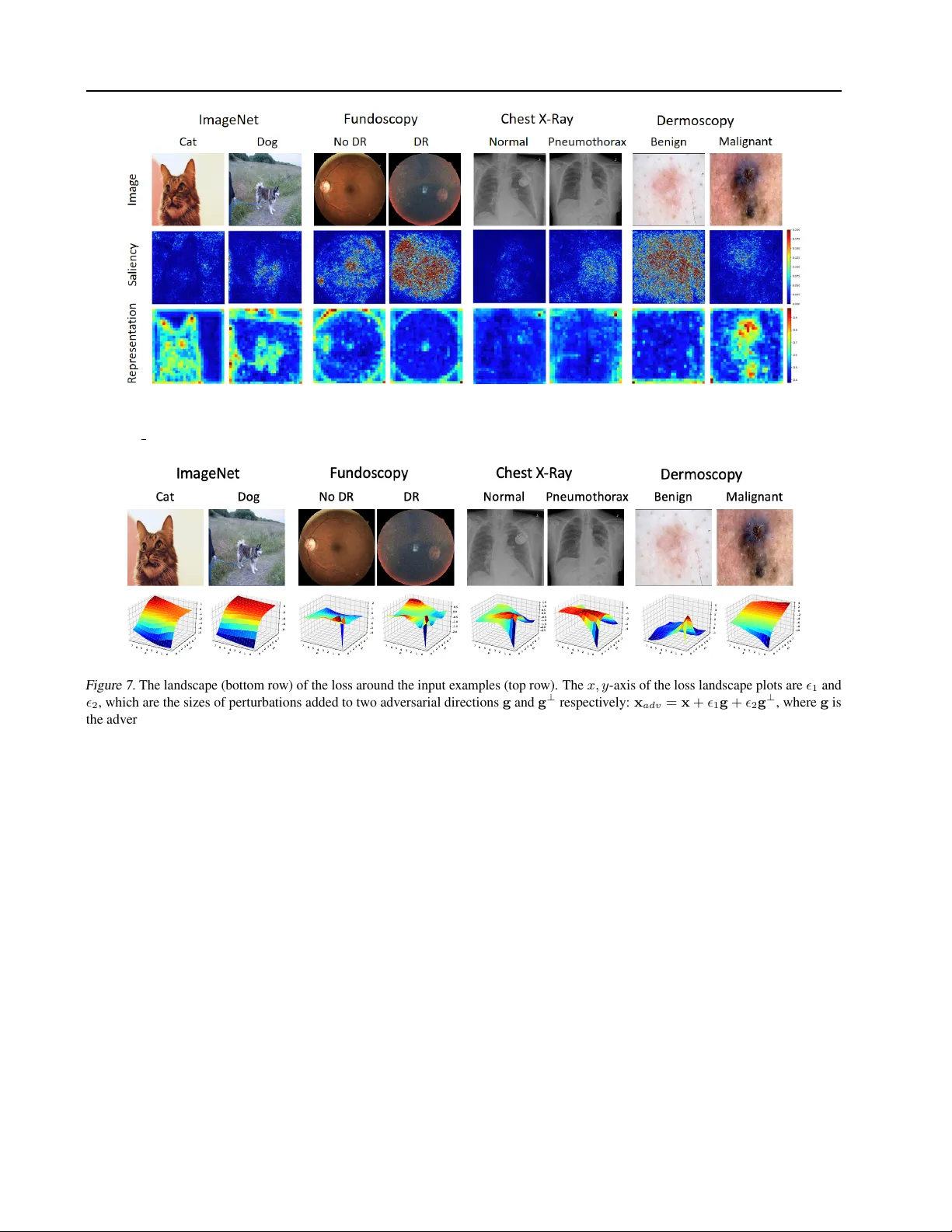
3절에서는 적대적 공격 이론을 정리한다. L∞ 제약 하의 화이트박스 공격을 중심으로 FGSM, BIM, PGD, CW 네 가지 대표 알고리즘을 수식과 함께 소개한다. 특히 PGD와 CW가 최적화 기반으로 가장 강력하다는 점을 강조한다.
4절과 5절에서 핵심 실험이 진행된다. 세 가지 의료 데이터셋에 대해 동일한 네트워크 아키텍처와 하이퍼파라미터를 적용하고, 자연 이미지(CIFAR‑10, ImageNet)와 비교한다. 결과는 의료 모델이 동일 ε값에서 훨씬 높은 성공률을 보이며, 특히 FGSM조차 ε≈1/255에서 정확도를 거의 0%로 만든다. 이는 의료 이미지가 복잡한 생물학적 텍스처를 포함해 기울기 폭이 크고, 자연 이미지용 대규모 모델이 과잉 파라미터화돼 손실 지형이 급격히 변하기 때문이다.
그 다음, 적대적 샘플의 탐지 가능성을 조사한다. 중간 레이어에서 추출한 deep feature를 입력으로 하는 간단한 2‑layer MLP 탐지기를 학습시켰으며, 모든 공격·데이터셋 조합에서 98% 이상의 AUC를 기록한다. 탐지기가 높은 성능을 보이는 이유는 적대적 변형이 병변 영역을 넘어 이미지 전역에 퍼져, 전체 통계적 특성이 정상 샘플과 현저히 달라지기 때문이다.
논의 섹션에서는 두 가지 주요 함의를 제시한다. 첫째, 의료 AI 모델 설계 시 과잉 파라미터화를 피하고, 의료 특화 경량 모델을 도입해 손실 지형을 완만하게 만드는 것이 공격 저항성을 높인다. 둘째, 탐지 기반 방어를 시스템에 기본적으로 탑재함으로써, 사전‑학습된 특징 추출기와 경량 탐지기만으로도 실시간 적대적 입력 차단이 가능하다.
마지막으로 한계와 향후 과제를 언급한다. 현재 연구는 주로 화이트박스 공격에 초점을 맞추었으며, 실제 임상 환경에서 발생할 수 있는 물리적·전이 공격에 대한 검증이 부족하다. 또한 탐지기의 일반화 능력을 높이기 위해 다양한 데이터셋·모델에 대한 메타‑학습 접근이 필요하다. 향후 연구는 블랙박스 공격에 강인한 탐지기 설계, 의료 규제기관과 연계한 인증 프레임워크 구축, 그리고 설명가능성(Explainability)과 보안성을 동시에 만족하는 모델 아키텍처 개발을 목표로 해야 한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기