Understanding Adversarial Attacks on Deep Learning Based Medical Image Analysis Systems
Deep neural networks (DNNs) have become popular for medical image analysis tasks like cancer diagnosis and lesion detection. However, a recent study demonstrates that medical deep learning systems can be compromised by carefully-engineered adversaria…
Authors: Xingjun Ma, Yuhao Niu, Lin Gu
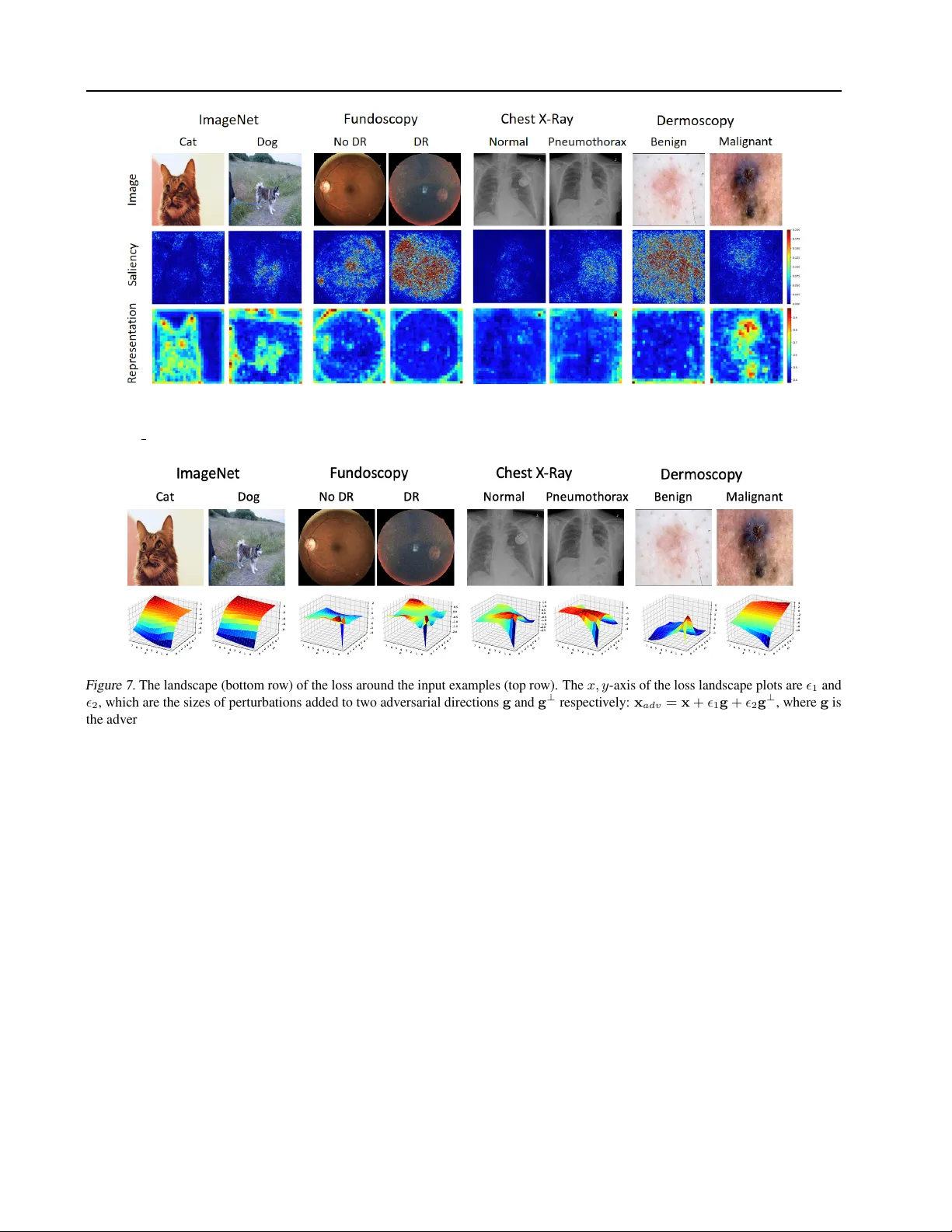
Understanding Adversarial Attacks on Deep Lear ning Based Medical Image Analysis Systems Xingjun Ma *, b Y uhao Niu *, a, c Lin Gu d Y isen W ang e Y itian Zhao f James Bailey b Feng Lu **, a, c a State Ke y Laboratory of VR T echnology and Systems, School of CSE, Beihang Univ ersity , Beijing, China. b School of Computing and Information Systems, The Univ ersity of Melbourne, Parkville, VIC 3010, Australia. c Beijing Advanced Inno vation Center for Big Data-Based Precision Medicine, Beihang Uni versity , Beijing, China. d National Institute of Informatics, T okyo 101-8430, Japan. e Department of Computer Science and Engineering, Shanghai Jiao T ong University , Shanghai, China. f Cixi Instuitue of Biomedical Engineering, Ningbo Institute of Industrial T echnology , Chinese Academy of Sciences, Ningbo, China. Abstract Deep neural networks (DNNs) ha ve become popular for medical image analysis tasks like cancer diagnosis and lesion detection. How- ev er , a recent study demonstrates that medical deep learning systems can be compromised by carefully-engineered adversarial e xamples/attacks with small imperceptible perturbations. This raises safety concerns about the deployment of these systems in clinical settings. In this paper , we provide a deeper understanding of adversarial e x- amples in the context of medical images. W e find that medical DNN models can be more vulnerable to adversarial attacks compared to models for nat- ural images, according to two dif ferent vie wpoints. Surprisingly , we also find that medical adversarial attacks can be easily detected, i.e., simple detec- tors can achiev e over 98% detection A UC against state-of-the-art attacks, due to fundamental fea- ture dif ferences compared to normal examples. W e belie ve these findings may be a useful basis to approach the design of more explainable and secure medical deep learning systems. 1. Introduction Deep neural networks (DNNs) are powerful models that hav e been widely used to achie ve near human-le vel perfor - mance on a variety of natural image analysis tasks such as image classification ( He et al. , 2016 ), object detection ( W ang et al. , 2019 ), image retrie v al ( Bai et al. , 2018 ) and 3D analysis ( Lu et al. , 2018 ). Dri ven by their current success on natural images (eg. images captured from natural scenes * Equal contribution . ** Correspondence to: Feng Lu < lufeng@b uaa.edu.cn > . T o appear in P attern Recognition . such as CIF AR-10 and ImageNet), DNNs ha ve become a popular tool for medical image processing tasks, such as cancer diagnosis ( Este va et al. , 2017 ), diabetic retinopathy detection ( Kaggle , 2015 ) and or gan/landmark localization ( Roth et al. , 2015 ). Despite their superior performance, recent studies ha ve found that state-of-the-art DNNs are vul- nerable to carefully crafted adversarial e xamples (or attacks), i.e. , slightly perturbed input instances can fool DNNs into making incorrect predictions with high confidence ( Sze gedy et al. , 2014 ; Goodfellow et al. , 2015 ). This has raised safety concerns about the deployment of deep learning models in safety-critical applications such as autonomous dri ving ( Eykholt et al. , 2018 ), action analysis ( Cheng et al. , 2018 ) and medical diagnosis ( Finlayson et al. , 2019 ). While existing works on adversarial machine learning re- search hav e mostly focused on natural images, a full under- standing of adversarial attacks in the medical image domain is still open. Medical images can have domain-specific characteristics that are quite dif ferent from natural images, for example, unique biological textures. A recent work has confirmed that medical deep learning systems can also be compromised by adversarial attacks ( Finlayson et al. , 2019 ). As sho wn in Figure 1 , across three medical image datasets Fundoscopy ( Kaggle , 2015 ), Chest X-Ray ( W ang et al. , 2017 ) and Dermoscopy ( ISIC , 2019 ), diagnosis results can be arbitrarily manipulated by adversarial attacks. Such a vulnerability has also been discussed in 3D volumetric medical image segmentation ( Li et al. , 2019 ). Consider- ing the v ast sums of money which underpin the healthcare economy , this ine vitably creates risks whereby potential attackers may seek to profit from manipulation against the healthcare system. For example, an attacker might manip- ulate their examination reports to commit insurance fraud or a false claim of medical reimbursement ( Paschali et al. , 2018 ). On the other hand, an attacker might seek to cause disruption by imperceptibly manipulating an image to cause a misdiagnosis of disease. This could have sev ere impact Understanding Adversarial Attacks on Deep Learning Based Medical Image Analysis Systems 2 Figure 1. Examples of adversarial attacks crafted by the Projected Gradient Descent (PGD) to fool DNNs trained on medical image datasets Fundoscopy ( Kaggle , 2015 ) (first ro w , DR=diabetic retinopathy), Chest X-Ray ( W ang et al. , 2017 ) (second row) and Dermoscopy ( ISIC , 2019 ) (third ro w). Left : normal images, Middle : adversarial perturbations, Right : adversarial images. The left bottom tag is the predicted class, and green/red indicates correct/wrong predictions. for the decisions made about a patient. T o make it worse, since the DNN works in a black-box way ( Niu et al. , 2019 ), this falsified decision could hardly be recognised. As deep learning models and medical imaging techniques become increasingly used in the process of medical diagnostics, de- cision support and pharmaceutical approv als ( Pien et al. , 2005 ), secure and robust medical deep learning systems be- come crucial ( Finlayson et al. , 2019 ; P aschali et al. , 2018 ). A first and important step is to develop a comprehensive understanding of adversarial attacks in this domain. In this paper , we provide a comprehensiv e understanding of medical image adversarial attacks from the perspecti ve of generating as well as detecting these attacks. T wo re- cent works ( Finlayson et al. , 2019 ; Paschali et al. , 2018 ) hav e in vestigated adv ersarial attacks on medical images and mainly focused on testing the robustness of deep models designed for medical image analysis. In particular , the work of ( Paschali et al. , 2018 ) tested whether existing medical deep learning models can be attacked by adversarial attacks. They sho wed that classification accuracy drops from abov e 87% on normal medical images to almost 0% on adv ersarial examples. W ork in ( Paschali et al. , 2018 ) utilized adver- sarial examples as a measure to ev aluate the robustness of medical imaging models in classification or segmentation tasks. Their study was restricted to small perturbations and they observed a marginal but variable performance drop across dif ferent models. Despite these studies, the following question has remained open “Can adversarial attacks on medical images be crafted as easily as attacks on natural images? If not, why?” . Furthermore, to the best of our knowledge, no pre vious work has in vestigated the detection of medical image adversarial examples. A natural question here is to ask “T o what de gr ee ar e adversarial attacks on medical images detectable?” . In this paper, we provide some answers to these questions by in vestigating both the crafting (generation) and detection of adversarial attacks on medical images. In summary , our main contributions are: 1. W e find that adversarial attacks on medical images can succeed more easily than those on natural images. That is, less perturbation is required to craft a successful attack. 2. W e sho w the higher vulnerability of medical image DNNs appears to be due to se veral reasons: 1) some medical images hav e complex biological te xtures, lead- ing to more high gradient re gions that are sensiti ve to small adversarial perturbations; and most importantly , and 2) state-of-the-art DNNs designed for lar ge-scale natural image processing can be overparameterized for medical imaging tasks, resulting in a sharp loss landscape and high vulnerability to adversarial attacks. 3. W e show that surprisingly , medical image adversarial attacks can also be easily detected. A simple detector trained on deep features alone can achie ve over 98% detection A UC against all tested attacks across our three datasets. T o the best of our kno wledge, this is the first work on the detection of adversarial attacks in the medical image domain. 4. W e show that the high detectability of medical image adversarial e xamples appears to be because adv ersarial Understanding Adversarial Attacks on Deep Learning Based Medical Image Analysis Systems 3 attacks result in perturbations to widespread regions outside the lesion area. This results in deep feature values for adversarial e xamples that are recognizably different from those of normal e xamples. Our findings of dif ferent degrees of adv ersarial vulnerabil- ities of DNNs on medical versus natural images can help dev elop a more comprehensi ve understanding on the relia- bility and robustness of deep learning models in different domains. The set of reasons we identified for such a dif- ference re veal more insights into the beha vior of DNNs in the presence of different types of adversarial examples. Our analysis of medical adv ersarial examples pro vides new in- terpretations of the learned representations and additional explanations for the decisions made by deep learning mod- els in the conte xt of medical images. This is a useful starting point tow ards building explainable and rob ust deep learning systems for medical diagnosis. The remainder of this paper is organized as follows. In section 2 , we briefly introduce deep learning based medical image analysis. In section 3 , we provide an introduction to adversarial attack and defense techniques. W e conduct sys- tematic experiments in sections 4 & 5 to inv estigate and un- derstand the beha viour of medical image adv ersarial attacks. Section 6 discusses se veral future work and summarizes our contributions. 2. Background of Medical Image Analysis Driv en by the current success of deep learning in tradi- tional computer vision, the field of medical imaging analysis (MIA) has also been influenced by DNN models. One of the first contributions of DNNs was in the area of medical image classification. This includes several highly successful appli- cations of DNNs in medical diagnosis, such as the se verity stage of diabetic retinopathy from retinal fundoscopy ( Kag- gle , 2015 ), lung diseases from chest X-ray ( W ang et al. , 2017 ) or skin cancer from dermoscopic photographs ( ISIC , 2019 ). Another important application of DNNs in medical image analysis is the segmentation of organs or lesions. Or- gan segmentation aims to quantitati vely measure the or gans, such as vessels( Gu & Cheng , 2015 ; Liu et al. , 2019b ) and kidneys ( W ang et al. , 2019b ), as a prelude to diagnosis or radiology therapy . Registration is another important task in medical imaging, where the objective is to spatially align medical images from different modalities or capture set- tings. For example, ( Cheng et al. , 2015 ) exploited the local similarity between CT and MRI images with two types of auto-encoders. Deep learning based medical image analysis may operate on a v ariety of input image sources, such as visible light images, hyperspectral light images, X-rays and nuclear mag- netic resonance images, across various anatomical areas such as the brain, chest, skin and retina. Brain images have been extensi vely studied to diagnose Alzheimers disease ( Liu et al. , 2014 ) and tumor segmentation ( Menze et al. , 2015 ). Ophthalmic imaging is another important applica- tion, which mainly focuses either on color fundus imaging (CFI) or Optical coherence tomography (OCT) for e ye dis- ease diagnosis or abnormalities segmentation. Among these applications, the deep learning based diabetic retinopathy diagnosis system was the first that was approved by the US Food and Drug Administration (FD A). ( Gulshan et al. , 2016a ) achiev ed comparable accuracy in detecting diabetic retinopathy to sev en certified ophthalmologists using an Inception network. There are systems that apply Con vo- lutional Neural Networks (CNNs) to extract deep features to detect and classify nodules ( W ang et al. , 2017 ) in the chest from radiography and computed tomography (CT). Digital pathology and microscopy is also a popular task due to the heavy burden on clinicians analyzing lar ge numbers of histopathology images of tissue specimens. Specifically , this task in volves segmenting high density cells and classify- ing the mitoses( Ciresan et al. , 2013 ). The abov e studies rely on the images captured by specialized cameras or devices. In contrast, in the context of skin cancer , it has been shown that standard cameras can deliv er excellent performance as input to DNN models ( Estev a et al. , 2017 ). Inspired by this success, the International Skin Imaging Collaboration ( ISIC , 2019 ) released a large dataset to support research on melanoma early detection. Most of these methods, especially diagnosis ones, adopt roughly the same pipeline, on a variety of images includ- ing ophthalmology ( Kaggle , 2015 ), radiology ( W ang et al. , 2017 ) and dermatology ( ISIC , 2019 ). The images are input into CNNs (typically the most adv anced ones existing at the time, such as ‘ AlexNet’, ‘V GG’, ‘Inception’ and ‘ResNet’ ( He et al. , 2016 )) to learn intermediate medical features before generating the final output. Whilst these pipelines hav e achiev ed excellent success, similar to those for stan- dard computer vision object recognition, they have been criticized for ha ving a lack of transparenc y . Though some preliminary attempt ( Niu et al. , 2019 ), has been proposed to use Koch postulates, the foundation of evidence based medicine, to explore the decision made by DNNs. People still find it dif ficult to verify the system’ s reasoning, which is essential for clinical applications which require high le v- els of trust. It is easy to see that such trust may be further eroded by the existence of adversarial examples, whereby an imperceptible modification may result in costly and some- times irreparable damage. W e next discuss methods for adversarial attack and detection. Understanding Adversarial Attacks on Deep Learning Based Medical Image Analysis Systems 4 3. Preliminaries In this paper , we focus on medical image classification tasks using DNNs. For a K -class ( K ≥ 2 ) classification problem, giv en a dataset { ( x i , y i ) } i =1 ,...,N with x i ∈ R d as a normal example and y i ∈ { 1 , . . . , K } as its associated label, a DNN classifier h with parameter θ predicts the class of an input example x i : h ( x i ) = arg max k =1 ,...,K p k ( x i , θ ) , (1) p k ( x i , θ ) = exp( z k ( x i , θ )) / K X k 0 =1 exp( z k 0 ( x i , θ )) , (2) where z k ( x i , θ ) is the logits output of the network with respect to class k , and p k ( x i , θ ) is the probability (softmax on logits) of x i belonging to class k . The model parame- ters θ are updated using back-propagation to minimize the classification loss such as the commonly used cross entropy loss ` ( h, x ) = 1 N P N i − y i log p y i ( x i , θ ) . 3.1. Adversarial Attacks. Giv en a pretrained DNN model h and a normal sample x with class label y , an attacking method is to maximize the classification error of the DNN model, whilst keeping x adv within a small -ball centered at the original sample x ( k x adv − x k p ≤ ), where k · k p is the L p -norm, with L ∞ being the most commonly used norm due to its con- sistency with respect to human perception ( Madry et al. , 2018 ). Adversarial attacks can be either targeted or untar- geted. A targeted attack is to find an adversarial example x adv that can be predicted by the DNN to a target class ( h ( x adv ) = y targ et ) which is different from the true class ( y targ et 6 = y ), while an untargeted attack is to find an adver- sarial example x adv that can be misclassified to an arbitrary class ( h ( x adv ) 6 = y ). Adversarial attacks can be generated either in a white-box setting using adversarial gradients ex- tracted directly from the target model, or a black-box setting by attacking a surrogate model or estimation of the adver- sarial gradients ( Jiang et al. , 2019 ; W u et al. , 2020 ). In this paper , we focus on untargeted attacks in the white-box setting under the L ∞ perturbation constraint. For white-box untar geted attacks, adversarial examples can be generated by solving the following constrained optimiza- tion problem: x adv = arg max k x 0 − x k ∞ ≤ ` ( h ( x 0 ) , y ) , (3) where ` ( · ) is the classification loss, and y is the ground truth class. A wide range of attacking methods have been proposed for the crafting of adversarial examples. Here, we introduce a selection of the most representativ e and state-of- the-art attacks. Fast Gradient Sign Method (FGSM). FGSM perturbs nor - mal examples x for one step by the amount of along the input gradient direction ( Goodfellow et al. , 2015 ): x adv = x + · sign ( ∇ x ` ( h ( x ) , y )) . (4) Basic Iterati ve Method (BIM). BIM ( K urakin et al. , 2017 ) is an iterati ve v ersion of FGSM. Dif ferent to FGSM, BIM iterativ ely perturbs the input with smaller step size, x t = x t − 1 + α · sign ( ∇ x ` ( h ( x t − 1 ) , y )) , (5) where α is the step size, and x t is the adversarial example at the t -th step ( x 0 = x ). The step size is usually set to /T ≤ α < for o verall T steps of perturbation. Projected Gradient Descent (PGD). PGD ( Madry et al. , 2018 ) perturbs a normal example x for a number of T steps with smaller step size. After each step of perturbation, PGD projects the adversarial e xample back onto the -ball of x , if it goes beyond: x t = Π x t − 1 + α · sign ( ∇ x ` ( h ( x t − 1 ) , y )) , (6) where α is the step size, Π( · ) is the projection function, and x t is the adversarial example at the t -th step ( x 0 = x ). Different from BIM, PGD uses random start for x 0 = x + U d ( − , ) , where U d ( − , ) is the uniform distribution between − and , and of the same d dimensions as x . PGD is normally regarded as the strongest first-order attack. Carlini and W agner (CW) Attack . The CW attack is a state-of-the-art optimization-based attack ( Carlini & W ag- ner , 2017 ). There are two versions of the CW attack: L 2 and L ∞ , here we focus on the L ∞ version. According to ( Madry et al. , 2018 ), the L ∞ version of tar geted CW attack can be solved by the PGD algorithm iterati vely as follo wing x t = Π x t − 1 − α · sign ( ∇ x ˆ f ( x t − 1 )) (7) ˆ f ( x t − 1 ) = max z y ( x t − 1 , θ ) − z y max 6 = y ( x t − 1 , θ ) , − κ , (8) where ˆ f ( · ) is the surrogate loss for the constrained opti- mization problem defined in Eqn. ( 3 ) , z y is the logits with respect to class y , z y max 6 = y is the maximum logits of other classes, and κ is a parameter controls the confidence of the attack. While there also e xists other attacking methods ( W u et al. , 2020 ), in this paper , we focus on the four state-of-the-art attacks mentioned abov e: FGSM, BIM, PGD and CW . 3.2. Adversarial Detection A number of defense models have been developed, input denoising ( Bai et al. , 2019 ), input gradients regularization Understanding Adversarial Attacks on Deep Learning Based Medical Image Analysis Systems 5 ( Ross & Doshi-V elez , 2018 ), and adversarial training ( Good- fellow et al. , 2015 ; Madry et al. , 2018 ). Howe ver , these defenses can generally be e vaded by the latest attacks, either wholly or partially ( Athalye et al. , 2018 ). Giv en the inherent challenges for adversarial defense, re- cent works hav e instead focused on detecting adversarial examples. These works attempt to discriminate adversarial examples (positi ve class) from normal clean examples (ne g- ati ve class), based on features extracted from dif ferent layers of a DNN. In machine learning, the subspace distance of the high dimension features has long been analysed ( Zhou et al. , 2020 ). Specifically , for the adversarial examples de- tection, detection subnetworks based on acti vations ( Metzen et al. , 2017 ), a logistic regression detector based on KD and Bayesian Uncertainty (BU) features ( Feinman et al. , 2017 ) and the Local Intrinsic Dimensionality (LID) of adversarial subspaces ( Ma et al. , 2018 ) are a few such w orks. Ker nel Density (KD): KD assumes that normal samples from the same class lie densely on the data manifold while adversarial samples lie in more sparse regions of f the data submanifold. Given a point x of class k , and a set of train- ing samples from the same class X k , the Gaussian K ernel Density of x can be estimated by: KD ( x ) = 1 | X k | X x 0 ∈ X k exp k z ( x , θ ) − z ( x 0 , θ ) k 2 2 σ 2 , (9) where σ is the bandwidth parameter controlling the smooth- ness of the Gaussian estimation, z is the logits of input x , and | X k | is the number of samples in X k . Local Intrinsic Dimensionality (LID): LID is a measure- ment to characterize the dimensional characteristics of ad- versarial subspaces in the vicinity of adversarial e xamples. Giv en an input sample x , the MLE estimator of LID makes use of its distances to the first n nearest neighbors: d LID ( x ) = − 1 n n X i =1 log r i ( x ) r n ( x ) ! − 1 , (10) where r i ( x ) is the Euclidean distance between x and its i -th nearest neighbor , i.e, r 1 ( x ) is the minimum distance while r n ( x ) is the maximum distance. LID is computed on each layer of the network producing a vector of LID scores for each sample. 3.3. Classification T asks, Datasets and DNN Models Here, we consider three highly successful applications of DNNs for medical image classification: 1) classifying di- abetic retinopathy (a type of eye disease) from retinal fun- doscopy ( Gulshan et al. , 2016b ); 2) classifying thorax dis- eases from Chest X-rays ( W ang et al. , 2017 ); and 3) classi- fying melanoma (a type of skin cancer) from dermoscopic photographs ( Estev a et al. , 2017 ). Here, we briefly intro- duce some general experimental settings with respect to the datasets and network architectures. Datasets. W e use publicly av ailable benchmark datasets for all three classification tasks. For our model training and attacking experiments, we need two subsets of data for each dataset: 1) subset T rain for pre-training the DNN model, and 2) subset T est for ev aluating the DNN models and crafting adversarial attacks. In the detection experiments, we further split the T est data into two parts: 1) AdvT rain for training adversarial detectors, and 2) AdvT est for e valuating the ad- versarial detectors. The number of classes and images we retriev ed from the public datasets can be found in T able 1 . T able 1. Number of classes and images in each subset of the fi ve datasets. Dataset Classes T rain T est AdvT rain AdvT est Fundoscopy 2 75,397 8,515 2,129 Chest X-Ray 2 53,219 6,706 1,677 Dermoscopy 2 18,438 426 107 Chest X-Ray-3 3 54769 9980 Chest X-Ray-4 4 57059 10396 W e follow the data collection process described in ( Fin- layson et al. , 2019 ). For the diabetic retinopathy (DR) clas- sification task, we use the Kaggle dataset Fundoscopy ( Kag- gle , 2015 ), which consists of over 80,000 high-resolution retina images taken under a v ariety of imaging conditions where each image was labeled to fi ve scales from ‘No DR’ to ‘mid/moderate/severe/proliferati ve DR’. In accordance with ( Gulshan et al. , 2016b ; Finlayson et al. , 2019 ), we aim to detect the refer able (grade moderate or worse) diabetic retinopathy from the rest (two classes in total). For the thorax disease classification task, we use a Chest X- Ray database ( W ang et al. , 2017 ), which comprises 112,120 frontal-view X-ray images of 14 common disease labels. Each image in this dataset can ha ve multiple labels, so we randomly sample images from those labeled only with ‘no finding’ or ‘pneumothorax’ to obtain our 2-class dataset. W e also sample two multi-class datasets from Chest X-Ray: 1) a 3-class dataset (e g. Chest X-Ray-3 in T able 1 ) includ- ing image labeled only with ‘no finding’, ‘pneumothorax’ or ‘mass’; 2) a 4-class dataset (eg. Chest X-Ray-4 in T a- ble 1 ) including ‘no finding’, ‘pneumothorax’, ‘mass’ and ‘nodule’. For the melanoma classification task, we retriev e melanoma related images of class ‘benign’ and class ‘malignant’ (two classes in total) from the International Skin Imaging Collab- oration database ( ISIC , 2019 ). Figure 2 shows two examples for each class of our three 2-class datasets. DNN Models. For all the fiv e datasets, we use the Ima- Understanding Adversarial Attacks on Deep Learning Based Medical Image Analysis Systems 6 Figure 2. Example images from each class of the three 2-class datasets. Figure 3. The pipeline of training DNNs (top) and generating ad- versarial attacks (bottom). geNet pretrained ResNet-50 ( He et al. , 2016 ) as the base network whose top layer is replaced by a new dense layer of 128 neurons, followed by a dropout layer of rate 0.2, and a K neuron dense layer for classification. The networks are trained for 300 epochs using a stochastic gradient descent (SGD) optimizer with initial learning rate 10 − 4 , momentum 0.9. All images are center-cropped to the size 224 × 224 × 3 and normalized to the range of [ − 1 , 1] . Simple data augmen- tations including random rotations, width/height shift and horizontal flip are used. When the training is completed, the networks are fixed in subsequent adv ersarial experiments. 4. Understanding Adversarial Attacks on Medical Image DNNs In this section, we in vestigate 4 different attacks against DNNs trained on fiv e medical image datasets. W e first describe the attack settings, then present the attack results with accompanying discussions and analyses. 4.1. Attack Settings The attacks we consider are: 1) the single step attack FGSM, 2) the iterativ e attack BIM, 3) the strongest first-order at- tack PGD, and 4) the strongest optimization-based attack CW ( L ∞ version). Note that all these attacks are bounded attacks according to a pre-defined maximum perturbation with respect to the L ∞ norm, i.e. , the maximum pertur- bation on each input pix el is no greater than . All 4 types of attacks are applied on both the AdvT rain and AdvT est subsets of images, follo wing the pipeline in Figure 3 . Giv en an image, the input gradient extractor feeds the image into the pre-trained DNN classifier to obtain the input gradients, based upon which the image is perturbed to maximize the network’ s loss to the correct class. The perturbation steps for BIM, PGD and CW are set to 40, 20 and 20 respec- tiv ely , while the step size are set to / 40 , / 10 and / 10 accordingly . W e focus on untargeted attacks in a white-box setting. 4.2. Attack Results W e focus on the difficulty of adversarial attack on medical images compared to that on natural images in ImageNet. The attack difficulty is measured by the least maximum perturbation required for most ( e.g . > 99% ) attacks to suc- ceed. Specifically , we vary the maximum perturbation size from 0.2/255 to 5/255, and visualize the drop in model ac- curacy on the adversarial e xamples in Figure 4 and Figure 5 for our 2-class and multi-class datasets respectiv ely , and the numeric results with respect to maximum perturbation = 1 . 0 / 255 can be found in T able 2 and T able 3 separately . Results on 2-class datasets. As expected, model accurac y drops drastically when adversarial perturbation increases, similar to that on natural images ( Goodfellow et al. , 2015 ; Carlini & W agner , 2017 ). Strong attacks including BIM, PGD and CW , only require a small maximum perturbation < 1 . 0 / 255 to generally succeed. This means attacking Understanding Adversarial Attacks on Deep Learning Based Medical Image Analysis Systems 7 0/255 1/255 2/255 3/255 4/255 5/255 P e r t u r b a t i o n s i z e e p s i l o n ( ) 0 20 40 60 80 100 Accuracy (%) FGSM BIM PGD CW (a) Fundoscopy 0/255 1/255 2/255 3/255 4/255 5/255 P e r t u r b a t i o n s i z e e p s i l o n ( ) 0 20 40 60 80 100 Accuracy (%) FGSM BIM PGD CW (b) Chest X-Ray 0/255 1/255 2/255 3/255 4/255 5/255 P e r t u r b a t i o n s i z e e p s i l o n ( ) 0 20 40 60 80 100 Accuracy (%) FGSM BIM PGD CW (c) Dermoscopy Figure 4. The classification accuracy of the three 2-class DNN classifiers on adversarial e xamples crafted by FGSM, BIM, PGD and CW with increasing perturbation size . Strong attacks including BIM, PGD and CW can succeed most of the time (model accuracy below 1% ) with very small perturbation < 1 . 0 / 255 . All attacks were generated in a white-box setting. Attack Fundoscopy Chest X-Ray Dermoscopy Accuracy A UC Accuracy A UC Accuracy A UC No attack 91.03 81.91 93.99 61.25 87.62 78.74 FGSM 1.15 3.71 1.90 0.96 29.98 20.58 BIM 0.00 0.00 0.00 0.00 0.21 0.13 PGD 0.00 0.00 0.00 0.00 0.43 0.74 CW 0.04 0.09 0.00 0.00 0.21 0.13 T able 2. The classification accuracies (%) and A UCs (%) of the three 2-class DNN classifiers on clean test images (denoted as “No attack”) and the 4 types of adversarial e xamples under L ∞ maximum perturbation 1 . 0 / 255 . 0.0/255 0.2/255 0.4/255 0.6/255 0.8/255 P e r t u r b a t i o n s i z e e p s i l o n ( ) 0 20 40 60 80 100 Accuracy (%) CXR-2 CXR-3 CXR-4 (a) FGSM 0.0/255 0.2/255 0.4/255 0.6/255 P e r t u r b a t i o n s i z e e p s i l o n ( ) 0 20 40 60 80 100 Accuracy (%) CXR-2 CXR-3 CXR-4 (b) BIM 0.0/255 0.2/255 0.4/255 0.6/255 P e r t u r b a t i o n s i z e e p s i l o n ( ) 0 20 40 60 80 100 Accuracy (%) CXR-2 CXR-3 CXR-4 (c) PGD 0.0/255 0.2/255 0.4/255 0.6/255 P e r t u r b a t i o n s i z e e p s i l o n ( ) 0 20 40 60 80 100 Accuracy (%) CXR-2 CXR-3 CXR-4 (d) CW Figure 5. Comparison of the attacks FGSM, BIM, PGD and CW on datasets Chest X-Ray (CXR-2), Chest X-Ray-3 (CXR-3) and Chest X-Ray-4 (CXR-4). For each attack, the classification accuracy after the attack (in a white-box setting) under different perturbation sizes is reported. Attack Accuracy when = 0 . 3 / 255 Accuracy when = 1 . 0 / 255 CXR-2 CXR-3 CXR-4 CXR-2 CXR-3 CXR-4 No attack 93.99 90.01 84.26 93.99 90.01 84.26 FGSM 16.26 10.07 3.01 1.90 2.14 0.74 BIM 1.60 0.72 0.19 0.00 0.00 0.00 PGD 0.56 0.30 0.08 0.00 0.00 0.00 CW 0.49 1.84 0.17 0.00 0.00 0.00 T able 3. White-box attacks on 2-class versus multi-class models on datasets Chest X-Ray (CXR-2), Chest X-Ray-3 (CXR-3) and Chest X-Ray-4 (CXR-4): the classification accuracies (%) of the three DNN classifiers on clean test images (denoted as “No attack”) and the 4 types of adversarial e xamples under L ∞ maximum perturbation = 0 . 3 / 255 and = 1 . 0 / 255 . Understanding Adversarial Attacks on Deep Learning Based Medical Image Analysis Systems 8 medical images is much easier than attacking natural im- ages like those from CIF AR-10 and ImageNet, which often require a maximum perturbation of > 8 . 0 / 255 for targeted attacks to generally succeed (see Figure 2 in ( Kurakin et al. , 2017 )). Results on multi-class datasets. Here, we further inv es- tigate the attack difficulty on 2-class datasets (eg. Chest X-Ray) versus that on multi-class datasets (eg. Chest X- Ray-3 and Chest X-Ray-4). As the A UC score is defined with respect to only 2 classes, here we only report the model accuracy on clean images (eg. “No attack”) and adversarial images crafted by FGSM, BIM, PGD, and CW . As shown in T able 3 , when there are more classes, the attacks hav e greater success rate. For example, under the same pertur- bation = 0 . 3 / 255 , model accuracy on crafted adversar - ial examples decreases as the number of classes increases. This indicates that medical image datasets that have mul- tiple classes are ev en more vulnerable than those 2-class datasets. Similar to the 2-class results above, the attacks BIM, PGD and CW can succeed more than 99% of the time with small perturbation = 1 . 0 / 255 . This is the case ev en with smaller perturbation = 0 . 3 / 255 , except for the CW attack on Chest X-Ray-3, which succeeds > 98% of the time. These findings are consistent with those found on natural images, that is, defending adversarial attacks on datasets with more classes (e g. CIF AR-100/ImageNet ver - sus MNIST/CIF AR-10) is generally more difficult ( Shafahi et al. , 2019 ). W e next consider further why attacking medical images is much easier than attacking ImageNet images. At first sight it is surprising, since medical images hav e the same size as ImageNet images. 4.3. Why ar e Medical Image DNN Models Easy to Attack? In this part, we provide explanations to the abov e phe- nomenon from the following 2 perspectiv es: 1) the char- acteristics of medical images; and 2) the characteristics of DNN models used for medical imaging. Medical Image V iewpoint. W e show the salienc y map for sev eral images from dif ferent classes, for both ImageNet and medical images in the middle row of Figure 6 . The saliency (or attention) map of an input image highlights the re gions that cause the most change in the model output, based on the gradients of the classification loss with respect to the input ( Simonyan et al. , 2013 ). W e can observe that some medical images hav e significantly lar ger high attention regions. This may indicate that the rich biological textures in medical im- ages sometimes distract the DNN model into paying extra attention to areas that are not necessarily related to the di- agnosis. Small perturbations in these high attention regions can lead to significant changes in the model output. In other words, this characteristic of medical images increases their vulnerability to adversarial attacks. Ho wev er , this argument only provides a partial answer to the question, as there is no doubt that some natural images can also have comple x textures. DNN Model V iewpoint. W e next show that the higher vul- nerability of medical DNN models is largely caused by the use of ov erparameterized deep networks for simple medi- cal image analysis tasks. The third row in Figure 6 illus- trates the representations learned at an intermediate layer of ResNet-50, i.e., the av eraged ‘res3a relu’ layer output over all channels. Surprisingly , we find that the deep representa- tions of medical images are rather simple, compared to the complex shapes learned from natural images. This indicates that, on medical images, the DNN model is learning simple patterns (possibly those are only related to the lesions) out of a large attention area. Howe ver , learning simple patterns does not require complex deep networks. This motiv ates us to in vestigate whether the high vulnerability is caused by the use of overparameterized networks, by e xploring the loss landscape around indi vidual input samples. Following previous works for natural adversarial images ( T ram ` er et al. , 2017 ), we construct two adversarial directions g and g ⊥ , where g and g ⊥ are the input gradients e xtracted from the DNN classifiers and a set of separately trained surrogate models respectiv ely . W e then craft adversarial examples following x adv = x + 1 g + 2 g ⊥ . More specifically , we gradually increase 1 and 2 from 0 to 8.0/255, and visual- ize the classification loss for each combination of 1 and 2 in Figure 7 . W e observed that the loss landscapes around medical images are extremely sharp, compared to the flat landscapes around natural images. A direct consequence of sharp loss is high vulnerability to adversarial attacks, because small perturbations of an input sample are likely to cause a drastic increase in loss. A sharp loss is usually caused by the use of an ov er complex netw ork on a simple classification task ( Madry et al. , 2018 ). In summary , we hav e found that medical DNN models can be more vulnerable to adv ersarial attacks compared to nat- ural image DNN models, and we ar gue this may be due to 2 reasons: 1) the complex biological textures of medical images may lead to more vulnerable re gions; and most im- portantly , and 2) state-of-the-art deep networks designed for large-scale natural image processing can be o verparameter - ized for medical imaging tasks and result in high vulnerabil- ity to adversarial attacks. 4.4. Discussion In deep learning based medical image analysis, it is a com- mon practice to use state-of-the-art DNNs that were origi- nally designed for complex large-scale natural image pro- cessing. Howe ver , these networks may be ov erparameter- Understanding Adversarial Attacks on Deep Learning Based Medical Image Analysis Systems 9 Figure 6. The normal images (top row), the salienc y maps of the images (middle row), and their representations (bottom ro w) learned at the ‘res3a relu’ layer (av eraged over channels) of the netw orks. 2 0 1 2 3 4 5 6 7 1 0 1 2 3 4 5 6 7 5 4 3 2 1 0 1 2 0 1 2 3 4 5 6 7 1 0 1 2 3 4 5 6 7 8 6 4 2 0 2 0 1 2 3 4 5 6 7 1 0 1 2 3 4 5 6 7 4 3 2 1 0 1 2 2 0 1 2 3 4 5 6 7 1 0 1 2 3 4 5 6 7 2.0 1.5 1.0 0.5 0.0 0.5 2 0 1 2 3 4 5 6 7 1 0 1 2 3 4 5 6 7 2.5 2.0 1.5 1.0 0.5 0.0 0.5 1.0 1.5 2 0 1 2 3 4 5 6 7 1 0 1 2 3 4 5 6 7 4 3 2 1 0 2 0 1 2 3 4 5 6 7 1 0 1 2 3 4 5 6 7 1 0 1 2 3 4 5 2 0 1 2 3 4 5 6 7 1 0 1 2 3 4 5 6 7 10 8 6 4 2 0 2 4 Figure 7. The landscape (bottom row) of the loss around the input e xamples (top row). The x, y -axis of the loss landscape plots are 1 and 2 , which are the sizes of perturbations added to two adversarial directions g and g ⊥ respectiv ely: x adv = x + 1 g + 2 g ⊥ , where g is the adversarial direction (sign of the input gradients) and g ⊥ is the adversarial direction found from the surrogate models. The z -axis of the loss landscape is the classification loss. The use of overparameterized deep netw orks on medical images causes the loss landscapes around medical images extremely sharp, compared to that of natural images. ized for many of the medical imaging tasks. W e would like to highlight to researchers in the field that, while these net- works bring better prediction performance, they are more vulnerable to adversarial attacks. In conjunction with these DNNs, regularizations or training strategies that can smooth out the loss around input samples may be necessary for robust defenses against such attacks. 5. Understanding the Detection of Medical Image Attacks In this section, we conduct v arious adversarial detection experiments using two state-of-the-art detection methods, i.e. , KD ( Feinman et al. , 2017 ) and LID ( Ma et al. , 2018 ). In addition, we also in vestigate the use of deep features (denoted by “DFeat”) or quantized deep features (denoted by “QFeat”) ( Lu et al. , 2017 ) for adversarial detection. The detection experiments are conducted on our three 2-class datasets. 5.1. Detection Settings The DNN models used here are the same as those used in the abov e attack experiments (see Section 4 ). The detection pipeline is illustrated in Figure 8 . Based on the pretrained DNN models, we apply the four attacking methods ( FGSM, BIM, PGD and CW ) to generate adversarial examples for the correctly classified images from both the AdvT rain and AdvT est subsets. W e then extract the features used for de- tection, which include the deep features at the second-last dense layer of the network (“DFeat”/“QFeat”), the KD (ker- nel density estimated from the second-last layer deep fea- tures) features, and the LID (local intrinsic dimensionality estimated from the output at each layer of the network) fea- Understanding Adversarial Attacks on Deep Learning Based Medical Image Analysis Systems 10 Figure 8. The pipeline of training an adversarial detector . tures. All the parameters for KD/LID estimation are set as per their original papers. All detection features are e xtracted in mini-batches of size 100. The detection features are then normalized to [0,1]. The detectors are trained on the de- tection features of the AdvT rain subset, and tested on the AdvT est subset. As suggested by ( Feinman et al. , 2017 ; Ma et al. , 2018 ), we use a logistic regression classifier as the detector for KD and LID, the random forests classifier as the detector for the deep features, and the SVM classifier for quantized deep features. A UC (Area Under Curve) score is adopted as the metric for detection performance. 5.2. Detection Results W e report the detection A UC scores of the 4 types of detec- tors against the 4 types of attacking methods (white-box) across the three datasets in T able 4 . State-of-the-art de- tectors demonstrate very robust performance against these attacks. Especially the KD-based detectors, which achieve an A UC of above 99% against all attacks across all three datasets. Howe ver , on natural images, these state-of-the-art detectors often achie ve less than 80% detection A UC against some of the tested attacks such as FGSM and BIM ( Ma et al. , 2018 ; Feinman et al. , 2017 ). This indicates that medical im- age adversarial e xamples are much easier to detect compared to natural image adversarial examples. Quite surprisingly , we find that the deep features ( e.g. ‘DFeat’) alone can de- liv er very rob ust detection performance against all attacks. In particular , deep feature based detectors achie ve an A UC score above 98% across all the testing scenarios. On the other hand, the detectors trained on quantized deep features ( e.g . ‘QFeat’) also achieve good detection performance. This indicates that the deep features of adversarial e xamples (adversarial features) may be fundamentally dif ferent from that of normal examples (normal features). 5.3. Detection T ransferability W e further test if the ‘QFeat’ detectors can still hav e good performance when trained on one attack (source), then ap- plied to detect the other 3 attacks (targets). In this trans- ferability test, we train detectors on ‘QFeat’ of adv ersarial examples crafted by the source attacks on both AdvT rain and AdvT est subsets, then apply the trained detectors to detect T able 4. Detecting white-box attacks: the A UC score (%) of var - ious detectors against the 4 types of attacks crafted on the three datasets. The best results are highlighted in bold . Dataset Detector FGSM BIM PGD CW Fundoscopy KD 100.00 100.00 100.00 100.00 LID 94.20 99.63 99.52 99.20 DFeat 99.97 100.00 100.00 99.99 QFeat 98.87 99.82 99.91 99.95 Chest X-Ray KD 99.29 100.00 100.00 100.00 LID 78.40 96.92 95.20 96.74 DFeat 99.97 100.00 100.00 100.00 QFeat 87.63 96.35 92.07 99.16 Dermoscopy KD 100.00 100.00 100.00 100.00 LID 64.83 95.37 92.72 95.90 DFeat 98.65 99.77 99.48 99.78 QFeat 86.53 89.27 95.45 93.92 T able 5. The detection transferability of the ‘DFeat’ detector: the A UC score (%) of the two detectors trained on source attacks FGSM and PGD then applied to detect other 3 attacks. The best results are highlighted in bold . Dataset Source FGSM BIM PGD CW Fundoscopy FGSM – 100.00 100.00 100.00 PGD 100.00 100.00 – 100.00 Chest X-Ray FGSM – 100.00 100.00 100.00 PGD 100.00 100.00 – 100.00 Dermoscopy FGSM – 100.00 100.00 100.00 PGD 100.00 100.00 – 100.00 adversarial e xamples crafted by other attacks also on both AdvT rain and AdvT est . As shown in T able 5 , the detectors trained on either weak attack FGSM or strong attack PGD all transfer perfectly against other attacks. This again con- firms that medical image adversarial examples can be easily detected. The 100% detection A UCs suggests that there are indeed some fundamental dif ferences between adversarial examples and normal e xamples. 5.4. Why ar e Adversarial Attacks on Medical Images Easy to Detect? T o better illustrate the difference between adversarial and normal features, we visualize the 2D embeddings of the deep features using t-SNE ( Maaten & Hinton , 2008 ). W e observe in Figure 9 that adversarial features are almost linearly sep- arable (after some non-linear transformations) from normal features. This is quite different from natural images, where deep features of adversarial examples are quite similar to that of normal e xamples, and deep feature based detectors can only provide limited robustness ( Feinman et al. , 2017 ; Ma et al. , 2018 ). Similar to Figure 6 , we visualize the deep representation Understanding Adversarial Attacks on Deep Learning Based Medical Image Analysis Systems 11 Fundoscopy Chest X-Ray Dermoscopy Clean vs FGSM Clean vs BIM Clean vs PGD Clean vs CW Figure 9. V isualization of t-SNE 2D embeddings of adversarial and normal features, extracted from the second last dense layer of the DNN models. Each row is a dataset, each column is an attack, and blue/orange indicates clean and adversarial examples respectiv ely . of normal and adversarial examples in Figure 10 . Here, we focus on features learned at a deeper layer (eg. the ‘res5b relu’ layer of ResNet-50), as we are more interested in the cumulati ve effect of adversarial perturbations. W e find that there are clear differences between adversarial and normal representations, especially for medical images. Compared to natural images, adversarial perturbations tend to cause more significant distortions on medical images in the deep feature space. Considering the dif ference in deep representations between natural images and medical images (Figure 6 ), this will lead to effects that are fundamentally different for natural versus medical images. As the deep representations of natural images activ ate a large area of the representation map, the adversarial representations that are slightly distorted by adversarial perturbations are not signifi- cant enough to be different from the normal representations. Howe ver , the deep representations of medical images are very simple and often cov er a small region of the repre- sentation map. W e believ e this makes small representation distortions stand out as outliers. T o further understand why tiny changes in deep features can make a fundamental dif ference, we show the attention maps of both normal and adv ersarial examples in Figure 11 . W e exploit the Gradient-weighted Class Activ ation Mapping (Grad-CAM) technique ( Selv araju et al. , 2017 ) to find the critical regions in the input image that mostly acti vate the the network output. Grad-CAM uses the gradients of a target class, flowing into the final con volutional layer to produce a coarse localization map highlighting the important regions in the image for predicting the class. As demonstrated in Figure 11 , the attentions of the DNN models are heavily disrupted by adversarial perturbations. On natural images, the attentions are only shifted to less important regions which are still related to the target class. For example, in the ‘cat’ example, the attention is shifted from the ear to the face of the cat. Howe ver , on medical images, the attentions are shifted from the lesion to regions that are completely irrelev ant to the diagnosis of the lesion. This explains why small perturbations in medical images can lead to deep features that are fundamentally different and easily separable from the normal features. 5.5. Discussion According to our above analysis, medical image adv ersar- ial examples generated using attacking methods de veloped from natural images are not really “adversarial” from the pathological sense. Careful consideration should be made if using these adversarial examples to ev aluate the perfor- mance of medical image DNN models. Our study also sheds some light on the future de velopment of more effecti ve at- tacks on medical images. Pathological image re gions might be exploited to craft attacks that produce more misleading adversarial features that are indistinguishable from normal features. Such attacks might have a higher chance to fool both the DNN models and the detectors. 6. Discussion and Conclusion 6.1. Discussion Although existing attacks can easily fool deep neural net- works (DNNs) used for medical image analysis, the per- turbations are small and imperceptible to human observers, thus posing very limited impact on the diagnosis results when medical experts are in volv ed. Whether physical world medical image examples can be crafted to fool both deep learning medical systems and medical experts is still not clear . While it has been demonstrated possible on natural images ( Kurakin et al. , 2017 ), traffic signs ( Eykholt et al. , 2018 ) or object detectors ( Liu et al. , 2019a ), the crafted adversarial stickers or patches are obviously malicious to humans. W e believ e more subtle and stealthy perturbations will be required for physical-world medical image adversar - ial examples. On the defense side, effecti ve defense techniques against medical image adversarial e xamples are imperativ e. While existing defense methods dev eloped on natural images such as adversarial training ( Madry et al. , 2018 ; W ang et al. , 2019a ; 2020 ; Y u et al. , 2019 ) and regularization methods ( Ross & Doshi-V elez , 2018 ; Zhang et al. , 2019 ) m ay also ap- ply for medical image adversarial examples, more ef fectiv e defenses might be dev eloped by also addressing the over - parameterization of DNNs used in deep learning medical systems. Understanding Adversarial Attacks on Deep Learning Based Medical Image Analysis Systems 12 Figure 10. The deep representations on normal images (first row) v ersus adversarial images (third row) learned by the ResNet-50 models at the ‘res5b relu’ layer (av eraged over channels). Figure 11. The attention maps of the network on normal images (first row) v ersus adversarial images (third ro w). The attention maps are computed by the Grad-CAM technique ( Selvaraju et al. , 2017 ). 6.2. Conclusion In this paper , we hav e in vestigated the problem of adversar - ial attacks on deep learning based medical image analysis. A series of experiments with 4 types of attack and detection methods were conducted on three benchmark medical im- age datasets. W e found that adversarial attacks on medical images are much easier to craft due to the specific charac- teristics of medical image data and DNN models. More surprisingly , we found that medical adversarial examples are also much easier to detect, and that simple deep fea- ture based detectors can achie ve o ver 98% detection A UC against all tested attacks across the three datasets and de- tectors trained on one attack transfer well to detect other unforeseen attacks. This is because adversarial attacks tend to attack a widespread area outside the pathological regions, which results in deep features that are fundamentally differ - ent and easily separable from normal features. Our findings in this paper can help understand why a deep learning medical system makes a wrong decision or diag- nosis in the presence of adversarial examples, and more importantly , the dif ficulties in generating and detecting such attacks on medical images compared to that on natural im- ages. This can further moti ve more practical and ef fective defense approaches to improve the adversarial robustness of medical systems. W e also believ e these findings may be a useful basis to approach the design of more explainable Understanding Adversarial Attacks on Deep Learning Based Medical Image Analysis Systems 13 and secure medical deep learning systems. Acknowledgement This w ork was supported by National Natural Science Foundation of China (NSFC) under Grant 61972012 and JST , ACT -X Grant Number JPMJ AX190D, Japan and Zhejiang Provincial Natural Science F oundation of China (LZ19F010001). References Athalye, A., Carlini, N., and W agner , D. A. Obfuscated gradients gi ve a f alse sense of security: Circumventing de- fenses to adversarial examples. International Confer ence on Machine Learning , pp. 274–283, 2018. Bai, X., Y an, C., Y ang, H., Bai, L., Zhou, J., and Hancock, E. R. Adaptiv e hash retrie val with kernel based similarity . P attern Recognition , 75:136 – 148, 2018. Bai, Y ., Feng, Y ., W ang, Y ., Dai, T ., Xia, S.-T ., and Jiang, Y . Hilbert-based generativ e defense for adversarial ex- amples. In IEEE International Conference on Computer V ision , pp. 4784–4793, 2019. Carlini, N. and W agner , D. T ow ards ev aluating the robust- ness of neural networks. In 2017 IEEE Symposium on Security and Privacy , pp. 39–57. IEEE, 2017. Cheng, X., Zhang, L., and Zhang, L. Deep similarity learn- ing for multimodal medical images. Computer Methods in Biomechanics and Biomedical Engineering , 2015. Cheng, Y ., Lu, F ., and Zhang, X. Appearance-based gaze estimation via ev aluation-guided asymmetric regression. In Eur opean Confer ence on Computer V ision (ECCV) , pp. 105–121, 2018. Ciresan, D. C., Giusti, A., Gambardella, L. M., and Schmid- huber , J. Mitosis detection in breast cancer histology images with deep neural networks. In International Con- fer ence on Medical Image Computing and Computer As- sisted Intervention , volume 8150, pp. 411–418. Springer , 2013. Estev a, A., Kuprel, B., Novoa, R. A., K o, J., Swetter, S. M., Blau, H. M., and Thrun, S. Dermatologist-lev el classifi- cation of skin cancer with deep neural networks. Natur e , 542(7639):115, 2017. Eykholt, K., Evtimov , I., Fernandes, E., Li, B., Rahmati, A., Xiao, C., Prakash, A., Kohno, T ., and Song, D. Rob ust physical-world attacks on deep learning visual classifi- cation. In IEEE Conference on Computer V ision and P attern Recognition , pp. 1625–1634, 2018. Feinman, R., Curtin, R. R., Shintre, S., and Gardner , A. B. Detecting adversarial samples from artifacts. Interna- tional Confer ence on Learning Repr esentations , 2017. Finlayson, S. G., Bowers, J. D., Ito, J., Zittrain, J. L., Beam, A. L., and K ohane, I. S. Adversarial attacks on medical machine learning. Science , 363(6433):1287–1289, 2019. Goodfellow , I. J., Shlens, J., and Szegedy , C. Explaining and harnessing adversarial e xamples. International Con- fer ence on Learning Repr esentations , 2015. Gu, L. and Cheng, L. Learning to boost filamentary structure segmentation. In International Confer ence on Computer V ision , December 2015. Gulshan, V ., Peng, L., Coram, M., Stumpe, M. C., W u, D., Narayanaswamy , A., V enugopalan, S., and et al. Dev el- opment and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus pho- tographs. Journal of the American Medical Association , 2016a. Gulshan, V ., Peng, L., Coram, M., Stumpe, M. C., W u, D., Narayanaswamy , A., V enugopalan, S., Widner , K., Madams, T ., Cuadros, J., et al. Development and valida- tion of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. J ama , 316(22): 2402–2410, 2016b. He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In IEEE Confer ence on Computer V ision and P attern Recognition , pp. 770–778, 2016. ISIC. The international skin imaging collaboration. https://www .isic-archiv e.com/, 2019. Jiang, L., Ma, X., Chen, S., Baile y , J., and Jiang, Y .-G. Black-box adversarial attacks on video recognition mod- els. In ACM International Confer ence on Multimedia , pp. 864–872, 2019. Kaggle. Kaggle diabetic retinopathy detection chal- lenge. https://www .kaggle.com/c/diabetic-retinopathy- detection, 2015. Kurakin, A., Goodfello w , I. J., and Bengio, S. Adversarial examples in the physical world. International Confer ence on Learning Repr esentations , 2017. Li, Y ., Zhu, Z., Zhou, Y ., Xia, Y ., Shen, W ., Fishman, E. K., and Y uille, A. L. V olumetric medical image segmentation: A 3d deep coarse-to-fine framework and its adversarial examples. In Deep Learning and Con volutional Neural Networks for Medical Imaging and Clinical Informatics , pp. 69–91. Springer , 2019. Understanding Adversarial Attacks on Deep Learning Based Medical Image Analysis Systems 14 Liu, A., Liu, X., Fan, J., Ma, Y ., Zhang, A., Xie, H., and T ao, D. Perceptual-sensitive gan for generating adversarial patches. In AAAI Conference on Artificial Intelligence , volume 33, pp. 1028–1035, 2019a. Liu, B., Gu, L., and Lu, F . Unsupervised ensemble strategy for retinal vessel se gmentation. In Medical Imag e Com- puting and Computer Assisted Intervention – MICCAI 2019 , pp. 111–119, 2019b. Liu, S., Liu, S., Cai, W ., Pujol, S., Kikinis, R., and Feng, D. Early/ diagnosis of alzheimer’ s disease with deep learning. In IEEE International Symposium on Biomedical Imaging (ISBI) , pp. 1015–1018, April 2014. Lu, F ., Chen, X., Sato, I., and Sato, Y . Symps: BRDF symmetry guided photometric stereo for shape and light source estimation. IEEE T ransactions on P attern Analysis and Machine Intelligence (TP AMI) , 40(1):221–234, 2018. Lu, J., Issaranon, T ., and Forsyth, D. A. Safetynet: Detecting and rejecting adversarial examples rob ustly . International Confer ence on Computer V ision , pp. 446–454, 2017. Ma, X., Li, B., W ang, Y ., Erfani, S. M., Wije wickrema, S. N. R., Schoenebeck, G., Houle, M. E., Song, D., and Bailey , J. Characterizing adversarial subspaces using local intrinsic dimensionality . International Confer ence on Learning Repr esentations , 2018. Maaten, L. v . d. and Hinton, G. V isualizing data using t-sne. Journal of Machine Learning Resear ch , 9(Nov): 2579–2605, 2008. Madry , A., Makelov , A., Schmidt, L., Tsipras, D., and Vladu, A. T owards deep learning models resistant to adversarial attacks. International Conference on Learn- ing Repr esentations , 2018. Menze, B. H., Jakab, A., Bauer, S., and et al. The mul- timodal brain tumor image segmentation benchmark (brats). IEEE T ransactions on Medical Imaging , 34(10): 1993–2024, Oct 2015. Metzen, J. H., Genewein, T ., Fischer, V ., and Bischoff, B. On detecting adversarial perturbations. International Confer ence on Learning Repr esentations , 2017. Niu, Y ., Gu, L., Lu, F ., Lv , F ., W ang, Z., Sato, I., Zhang, Z., Xiao, Y ., Dai, X., and Cheng, T . Pathological e vidence exploration in deep retinal image diagnosis. In AAAI confer ence on artificial intelligence , v olume 33, pp. 1093– 1101, 2019. Paschali, M., Conjeti, S., Nav arro, F ., and Navab, N. Gener- alizability vs. robustness: Inv estigating medical imaging networks using adversarial examples. In Medical Im- age Computing and Computer Assisted Intervention , pp. 493–501, 2018. Pien, H. H., Fischman, A. J., Thrall, J. H., and Sorensen, A. G. Using imaging biomarkers to accelerate drug de- velopment and clinical trials. Drug discovery today , 10 (4):259–266, 2005. Ross, A. S. and Doshi-V elez, F . Improving the adv ersarial robustness and interpretability of deep neural networks by regularizing their input gradients. In Thirty-second AAAI confer ence on artificial intelligence , 2018. Roth, H. R., Lu, L., Farag, A., Shin, H.-C., Liu, J., Turkbe y , E. B., and Summers, R. M. Deeporgan: Multi-level deep con volutional netw orks for automated pancreas segmen- tation. In International Conference on Medical Image Computing and Computer Assisted Intervention , pp. 556– 564. Springer , 2015. Selvaraju, R. R., Cogswell, M., Das, A., V edantam, R., Parikh, D., and Batra, D. Grad-cam: V isual explanations from deep networks via gradient-based localization. In International Confer ence on Computer V ision , pp. 618– 626, 2017. Shafahi, A., Najibi, M., Ghiasi, M. A., Xu, Z., Dickerson, J., Studer , C., Davis, L. S., T aylor, G., and Goldstein, T . Adversarial training for free! In Advances in Neural Information Pr ocessing Systems , pp. 3353–3364, 2019. Simonyan, K., V edaldi, A., and Zisserman, A. Deep inside con volutional netw orks: V isualising image classification models and saliency maps. arXiv , 2013. Szegedy , C., Zaremba, W ., Sutskev er , I., Bruna, J., Erhan, D., Goodfellow , I., and Fergus, R. Intriguing properties of neural networks. International Conference on Learning Repr esentations , 2014. T ram ` er , F ., Papernot, N., Goodfello w , I., Boneh, D., and Mc- Daniel, P . The space of transferable adv ersarial examples. arXiv , 2017. W ang, C., Bai, X., W ang, S., Zhou, J., and Ren, P . Multi- scale visual attention networks for object detection in vhr remote sensing images. IEEE Geoscience and Remote Sensing Letters , 16(2):310–314, Feb 2019. W ang, X., Peng, Y ., Lu, L., Lu, Z., Bagheri, M., and Sum- mers, R. Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In IEEE Con- fer ence on Computer V ision and P attern Recognition , pp. 3462–3471, 2017. W ang, Y ., Ma, X., Bailey , J., Y i, J., Zhou, B., and Gu, Q. On the con ver gence and robustness of adversarial training. In International Confer ence on Machine Learning , pp. 6586–6595, 2019a. Understanding Adversarial Attacks on Deep Learning Based Medical Image Analysis Systems 15 W ang, Y ., Zhou, Y ., Shen, W ., Park, S., Fishman, E. K., and Y uille, A. L. Abdominal multi-organ segmentation with organ-attention netw orks and statistical fusion. Medical Image Analysis , 2019b. W ang, Y ., Zou, D., Y i, J., Bailey , J., Ma, X., and Gu, Q. Im- proving adversarial robustness requires re visiting misclas- sified examples. In International Confer ence on Learning Repr esentations , 2020. W u, D., W ang, Y ., Xia, S.-T ., Bailey , J., and Ma, X. Skip connections matter: On the transferability of adversar - ial examples generated with resnets. In International Confer ence on Learning Repr esentations , 2020. Y u, H., Liu, A., Liu, X., Y ang, J., and Zhang, C. T o wards noise-robust neural netw orks via progressiv e adversarial training. arXiv pr eprint arXiv:1909.04839 , 2019. Zhang, C., Liu, A., Liu, X., Xu, Y ., Y u, H., Ma, Y ., and Li, T . Interpreting and improving adversarial rob ustness with neuron sensitivity . arXiv pr eprint arXiv:1909.06978 , 2019. Zhou, L., Bai, X., Liu, X., Zhou, J., and Hancock, E. R. Learning binary code for fast nearest subspace search. P attern Recognition , 98:107040, 2020.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment