DLBricks: CPU 딥러닝 벤치마크 자동 생성으로 비용·시간 절감
DLBricks는 딥러닝 모델을 레이어 단위로 분해해 중복되지 않는 실행 가능한 서브네트워크를 자동 생성하고, 이 서브네트워크들의 실행 시간을 합산해 원본 모델의 추론 지연을 예측한다. 레이어가 성능의 기본 블록이며 동일한 타입·형태·파라미터를 가진 레이어는 재사용 가능하다는 두 가지 관찰을 기반으로, 벤치마크 개발·유지 비용을 크게 낮추고 최신 모델까지 빠르게 반영한다. 50개의 MXNet 모델을 4대의 CPU에서 평가한 결과, 95 % 이상…
저자: Cheng Li, Abdul Dakkak, Jinjun Xiong
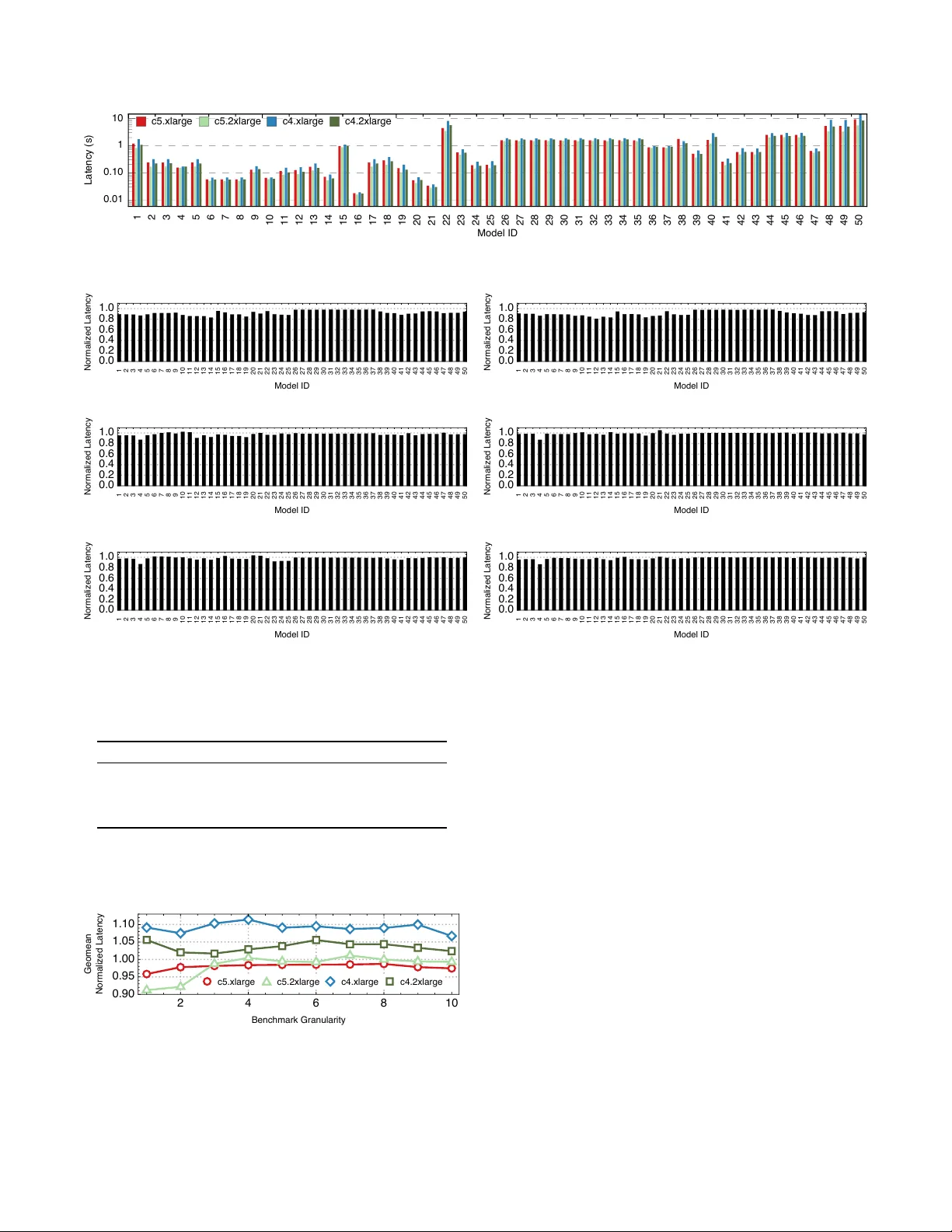
본 논문은 CPU 환경에서 딥러닝 모델의 추론 성능을 효율적으로 벤치마크하고 예측하기 위한 새로운 프레임워크인 DLBricks를 제안한다. 딥러닝 모델은 수백에서 수천 개의 레이어로 구성된 DAG(Directed Acyclic Graph)이며, 현재 주요 딥러닝 프레임워크는 레이어를 순차적으로 실행한다. 저자들은 50개의 MXNet 모델을 대상으로 레이어별 지연을 측정하고, 순차 합산값과 실제 엔드‑투‑엔드 지연이 8 % 이내 차이 나는 것을 확인함으로써 “레이어는 모델 성능의 기본 블록이다”는 첫 번째 관찰을 도출한다.
두 번째 관찰은 동일한 타입·형태·파라미터를 가진 레이어는 가중치가 달라도 실행 시간이 동일하다는 점이다. 이를 검증하기 위해 ResNet‑50, Inception‑V3 등 복잡한 모델을 분석했으며, 전체 레이어 중 90 % 이상이 다른 모델 혹은 동일 모델 내에서 이미 존재하는 레이어와 중복됨을 확인했다. 이러한 높은 레이어 재사용성은 벤치마크 대상 레이어를 최소화할 수 있는 근거가 된다.
DLBricks는 사용자가 지정한 최대 레이어 수 G(benchmark granularity)를 기준으로 모델을 레이어 시퀀스로 분할한다. 중복되지 않는 시퀀스를 식별하고, 각 시퀀스를 실행 가능한 서브그래프(런어블 네트워크)로 변환한다. 변환된 서브네트워크는 기존 프레임워크에서 바로 실행 가능하며, 각 서브네트워크의 지연을 측정한다. 이후 원본 모델의 지연은 해당 모델을 구성하는 레이어 시퀀스들의 측정값을 단순 합산해 추정한다.
실험 설정은 다음과 같다. 5가지 딥러닝 작업(이미지 분류, 객체 탐지, 이미지 변환, 회귀, 세그멘테이션)에서 50개의 MXNet 모델을 선정하고, 4대의 대표적인 CPU(예: Amazon EC2 c5.xlarge, c5.2xlarge, Intel Xeon 등)에서 벤치마크를 수행했다. 결과는 두 가지 주요 지표에서 우수하였다. 첫째, 모델 지연 추정 정확도는 대부분 95 % 이상이며, 최악의 경우에도 90 % 수준을 유지했다. 이는 레이어 단위 측정만으로도 전체 모델 성능을 충분히 예측할 수 있음을 입증한다. 둘째, 전체 모델을 직접 실행하는 전통적 벤치마크에 비해 측정 시간은 평균 2.1배, 최고 4.4배까지 단축되었다. 특히 새로운 모델이 추가될 때마다 전체 벤치마크를 재실행할 필요 없이 레이어 시퀀스만 재사용하면 되므로, 최신 모델을 빠르게 반영할 수 있다.
DLBricks는 모델 프라이버시 보호 측면에서도 장점을 제공한다. 입력 모델의 토폴로지는 서브네트워크 생성 과정에서 추상화되며, 가중치 자체는 전혀 사용되지 않는다. 따라서 기업이 자체 모델을 외부에 노출하지 않고도 벤치마크에 포함시킬 수 있다. “가짜” 모델을 삽입해 레이어 풀을 풍부하게 만들 수도 있어, 프라이버시와 벤치마크 다양성을 동시에 확보한다.
한계점으로는 현재 CPU 전용 추론에 초점을 맞추었으며, GPU·TPU와 같은 가속기에서는 레이어 병렬 실행 및 오버랩이 활발히 이루어지므로 단순 합산 방식이 부정확할 수 있다. 또한, 프레임워크가 향후 레이어 수준 최적화(예: 가중치 기반 캐싱)를 도입하면 레이어 재사용 가정이 깨질 가능성이 있다. 이러한 점을 보완하기 위해 향후 연구에서는 가속기 지원, 동적 스케줄링 모델, 그리고 레이어 간 의존성을 고려한 복합 추정 모델을 탐색할 계획이다.
결론적으로, DLBricks는 레이어 수준의 중복성을 활용해 벤치마크 생성·실행 비용을 크게 낮추고, 최신 모델까지 빠르게 반영할 수 있는 실용적인 솔루션을 제공한다. 이는 딥러닝 모델 최적화, 하드웨어 선택, 그리고 기업 내부 모델 평가 등에 있어 중요한 도구가 될 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기