DLBricks: Composable Benchmark Generation to Reduce Deep Learning Benchmarking Effort on CPUs (Extended)
The past few years have seen a surge of applying Deep Learning (DL) models for a wide array of tasks such as image classification, object detection, machine translation, etc. While DL models provide an opportunity to solve otherwise intractable tasks…
Authors: Cheng Li, Abdul Dakkak, Jinjun Xiong
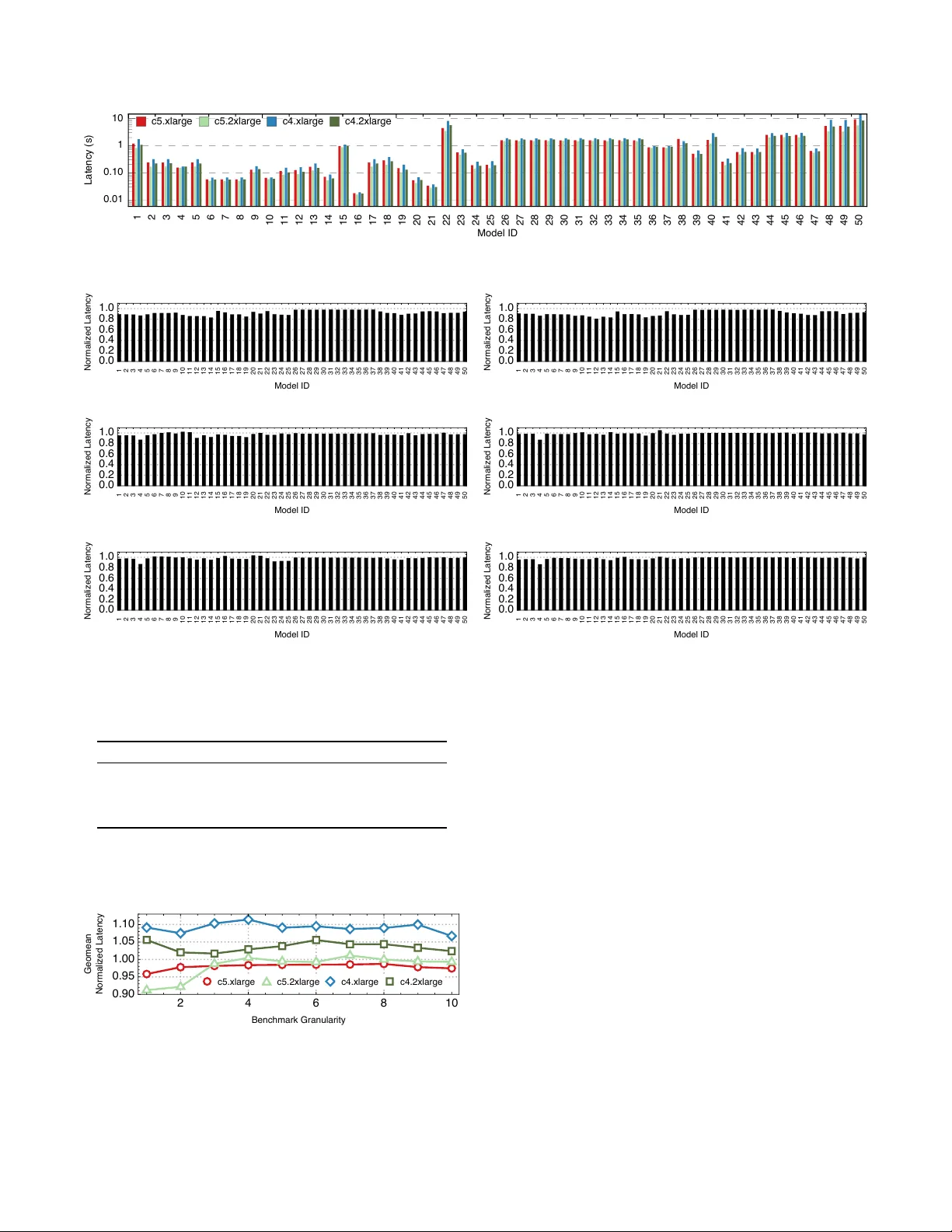
DLBricks: Composable Benchmark Generation to Reduce Deep Lear ning Benchmarking Eff ort on CPUs (Extended) Cheng Li Univ ersity of Illinois Urbana-Champaign Urbana, Illinois cli99@illinois.edu Abdul Dakkak Univ ersity of Illinois Urbana-Champaign Urbana, Illinois dakkak@illinois.edu Jinjun Xiong IBM T . J. W atson Research Center Y orktown Heights, Ne w Y ork jinjun@us.ibm.com W en-mei Hwu Univ ersity of Illinois Urbana-Champaign Urbana, Illinois w- hwu@illinois.edu Abstract The past fe w years ha ve seen a sur ge of applying Deep Learn- ing (DL) models for a wide array of tasks such as image classi- fication, object detection, machine translation, etc. While DL models provide an opportunity to solve otherwise intractable tasks, their adoption relies on them being optimized to meet latency and resource requirements. Benchmarking is a key step in this process but has been hampered in part due to the lack of representative and up-to-date benchmarking suites. This is exacerbated by the fast-e volving pace of DL models. This paper proposes DLBricks, a composable benchmark generation design that reduces the effort of dev eloping, main- taining, and running DL benchmarks on CPUs. DLBricks de- composes DL models into a set of unique runnable networks and constructs the original model’ s performance using the performance of the generated benchmarks. DLBricks le ver - ages two key observations: DL layers are the performance building blocks of DL models and layers are extensi vely re- peated within and across DL models. Since benchmarks are generated automatically and the benchmarking time is mini- mized, DLBricks can keep up-to-date with the latest proposed models, relieving the pressure of selecting representati v e DL models. Moreov er , DLBricks allo ws users to represent propri- etary models within benchmark suites. W e e v aluate DLBricks using 50 MXNet models spanning 5 DL tasks on 4 repre- sentativ e CPU systems. W e show that DLBricks provides an accurate performance estimate for the DL models and reduces the benchmarking time across systems (e.g. within 95% accu- racy and up to 4 . 4 × benchmarking time speedup on Amazon EC2 c5.xlarge ). 1 Introduction The recent impressiv e progress made by Deep Learning (DL) in a wide array of applications, such as autonomous vehicles, face recognition, object detection, machine translation, fraud detection, etc. has led to increased public usage of DL models. Benchmarking these trained DL models before deplo yment is critical for DL models to be usable and meet latency and resource constraints. Hence there ha ve been significant efforts to develop benchmark suites that ev aluate widely used DL models [ 2 , 8 , 16 , 27 , 28 ]. An example is MLPerf [ 16 ], which is formed as a collaboration between industry and academia and aims to provide reference implementations for DL model training and inference. Howe v er , the current benchmarking practice has a few limitations that are exacerbated by the fast-e volving pace of DL models. Dev eloping, maintaining, and running benchmarks takes a non-trivial amount of effort. Thus, ev en though there are many benchmark suites, the number of DL model benchmarks within them is small. F or each DL task of interest, benchmark suite authors select a small representative subset (or one) out of tens or ev en hundreds of candidate models. Deciding on a representativ e set of models is an arduous ef fort as it takes a long debating process to determine what models to add and what to exclude. For e xample, it took o ver a year of weekly discussion to determine and publish MLPerf v 0 . 5 inference models, and the number of models was reduced from the 10 models originally considered to 5 . Figure 1 shows the gap between the number of DL papers [ 19 ] and the number of models included in recent benchmarking ef forts. Gi ven that DL models are proposed or updated on a daily basis [ 9 , 12 ], it is very challenging for benchmark suites to be agile and representativ e of real-world DL model use. Moreov er , only public av ailable models are considered for inclusion in benchmark suites. Proprietary models are trade secret or restricted by cop yright and cannot be shared e xter- nally for benchmarking. Thus, proprietary models are not included or represented within benchmark suites. From the proprietary model owners’ point of view , since they cannot directly share their models, to benchmark the model using a vendor’ s system means inv esting time and money in purchas- ing vendor hardw are, setting it up, and ev aluating the model on the newly purchased system. This is a cumbersome pro- cess and places a large burden on proprietary model owners 1 Cheng Li, et al. # # Figure 1. The number of DL models included in the the recent pub- lished DL benchmark suites (Fathom [ 2 ], DawnBench [ 8 ], TBD [ 28 ], AI Matrix [ 27 ], and MLPerf [ 16 ]) compared to the number of DL papers published in the same year (using Scopus Previe w [ 19 ]) . ev aluating SW/HW stacks. Moreover , the research commu- nity cannot collaborate to propose potential optimizations for these proprietary models. T o address the above issues, we propose DLBricks — a composable benchmark generation design that reduces the ef fort to de v elop, maintain, and run DL benchmarks on CPUs. W e focus on latency-sensiti ve (batch size= 1 ) DL inference using CPUs since CPUs are a common and cost-ef fectiv e option for DL model deployment. Given a set of DL mod- els, DLBricks parses them into a set of atomic unique layer sequences based on the user-specified benchmark granular- ity ( G ). A layer sequence is a chain of layers and two layer sequences are considered non-unique if they are identical ignoring their weight v alues. DLBricks then generates unique (non-ov erlapping) runnable networks (or subgraphs of the model with at most G layers that can be executed by a frame- work) using the layer sequences’ information, and these net- works form the representati ve set of benchmarks for the input models. Users can run the generated benchmarks on a system of interest and DLBricks uses the benchmark results to con- struct an estimate of the input models’ performance on that system. DLBricks lev erages two key observations on DL infer- ence: 1 Layers are the performance building blocks of the model performance and a simple summation is ef fecti ve giv en the current DL software stack (no parallel e xecution of data- independent layers or ov erlapping of layer execution) on CPUs. 2 Layers (considering their layer type, shape, and parameters, but ignoring the weights) are extensi vely repeated within and across DL models. DLBricks uses both observ a- tions to generate a representativ e benchmark suite, minimize the time to benchmark, and estimate a model’ s performance from layer sequences. Since benchmarks are generated automatically by DL- Bricks, benchmark de velopment and maintenance ef fort are greatly reduced. DLBricks is defined by a set of simple consis- tent principles and can be used to benchmark and characterize a broad range of models. Moreover , since each generated benchmark represents only a subset of the input model, the input model’ s topology does not appear in the output bench- mark suite. This, along with the fact that “fake” or dummy models can be inserted into the set of input models, means that the generated benchmark suite can represent proprietary models without the concern of rev ealing proprietary models. In summary , this paper makes the following contrib utions: • W e perform a comprehensi ve performance analysis of 50 state-of-the-art DL models on CPUs and observe that layers are the performance building blocks of DL models, thus a model’ s performance can be estimated by the performance of its layers. • W e also perform an in-depth DL architecture analysis of the DL models and make the observ ation that DL layers with the same type, shape, and parameters are repeated extensi v ely within and across models. • W e propose DLBricks, a composable benchmark genera- tion design on CPUs that decomposes DL models into a set of unique runnable networks and constructs the original model’ s performance using the performance of the gener- ated benchmarks. DLBricks reduces the ef fort of dev eloping, maintaining, and running DL benchmarks, and relie ves the pressure of selecting representativ e DL models. • DLBricks allo ws representing proprietary models without model priv acy concerns as the input model’ s topology does not appear in the output benchmark suite, and “fake” or dummy models can be inserted into the set of input models. • W e e v aluate DLBricks using 50 MXNet models spanning 5 DL tasks on 4 representativ e CPU systems. W e sho w that DLBricks provides a tight performance estimate for DL models and reduces the benchmarking time across systems. E.g. The composed model latency is within 95% of the model actual performance while up to 4 . 4 × benchmarking speedup is achiev ed on the Amazon EC2 c5.xlarge system. This paper is structured as follo ws. First, in Section 5 we describe dif ferent benchmarking approaches pre viously per- formed. W e then (Section 2 ) detail two ke y observ ations 1 and 2 that enable our design. W e then propose DLBricks in Section 3 and describe ho w it provides a stream lined bench- mark generation workflo w which lowers the time to bench- mark. Section 4 ev aluates DLBricks using 50 models running on 4 systems. W e then describe future work in Section 6 before we conclude in Section 7 . 2 Motivation DLBricks is designed based on two key observations pre- sented in this section. T o demonstrate and support these ob- servations, we perform comprehensi ve performance and ar - chitecture analysis of state-of-the-art DL model. Evaluations in this section use 50 MXNet models of dif ferent DL tasks (listed in T able 1 ) and were run with MXNet (v 1 . 5 . 1 MKL release) on a Amazon c5.2xlarge instance (as listed in T able 2 ). W e focus on latency sensiti ve (batch size = 1 ) DL inference on CPUs. 2 DLBricks: Composable Benchmark Generation to Reduce Deep Lear ning Benchmarking Effor t on CPUs (Extended) ID Name T ask Num Layers 1 Ademxapp Model A T rained on ImageNet Competition Data Classification 142 2 Age Estimation VGG-16 T rained on IMDB-WIKI and Looking at People Data Classification 40 3 Age Estimation VGG-16 T rained on IMDB-WIKI Data Classification 40 4 CapsNet T rained on MNIST Data Classification 53 5 Gender Prediction VGG-16 T rained on IMDB-WIKI Data Classification 40 6 Inception V1 T rained on Extended Salient Object Subitizing Data Classification 147 7 Inception V1 T rained on ImageNet Competition Data Classification 147 8 Inception V1 T rained on Places365 Data Classification 147 9 Inception V3 T rained on ImageNet Competition Data Classification 311 10 MobileNet V2 T rained on ImageNet Competition Data Classification 153 11 ResNet-101 T rained on ImageNet Competition Data Classification 347 12 ResNet-101 T rained on YFCC100m Geotagged Data Classification 344 13 ResNet-152 T rained on ImageNet Competition Data Classification 517 14 ResNet-50 T rained on ImageNet Competition Data Classification 177 15 Squeeze-and-Excitation Net T rained on ImageNet Competition Data Classification 874 16 SqueezeNet V1.1 T rained on ImageNet Competition Data Classification 69 17 VGG-16 T rained on ImageNet Competition Data Classification 40 18 VGG-19 T rained on ImageNet Competition Data Classification 46 19 W ide ResNet-50-2 Trained on ImageNet Competition Data Classification 176 20 W olfram ImageIdentify Net V1 Classification 232 21 Y ahoo Open NSFW Model V1 Classification 177 22 AdaIN-Style T rained on MS-COCO and Painter by Numbers Data Image Processing 109 23 Colorful Image Colorization T rained on ImageNet Competition Data Image Processing 58 24 ColorNet Image Colorization T rained on ImageNet Competition Data Image Processing 62 25 ColorNet Image Colorization T rained on Places Data Image Processing 62 26 CycleGAN Apple-to-Orange T ranslation Trained on ImageNet Competition Data Image Processing 94 27 CycleGAN Horse-to-Zebra T ranslation Trained on ImageNet Competition Data Image Processing 94 28 CycleGAN Monet-to-Photo T ranslation Image Processing 94 29 CycleGAN Orange-to-Apple T ranslation Trained on ImageNet Competition Data Image Processing 94 30 CycleGAN Photo-to-Cezanne T ranslation Image Processing 96 31 CycleGAN Photo-to-Monet T ranslation Image Processing 94 32 CycleGAN Photo-to-V an Gogh T ranslation Image Processing 96 33 CycleGAN Summer-to-W inter T ranslation Image Processing 94 34 CycleGAN W inter-to-Summer T ranslation Image Processing 94 35 CycleGAN Zebra-to-Horse T ranslation Trained on ImageNet Competition Data Image Processing 94 36 Pix2pix Photo-to-Street-Map T ranslation Image Processing 56 37 Pix2pix Street-Map-to-Photo T ranslation Image Processing 56 38 V ery Deep Net for Super-Resolution Image Processing 40 39 SSD-VGG-300 T rained on P ASCAL V OC Data Object Detection 145 40 SSD-VGG-512 T rained on MS-COCO Data Object Detection 157 41 YOLO V2 T rained on MS-COCO Data Object Detection 106 42 2D Face Alignment Net T rained on 300W Large Pose Data Re gression 967 43 3D Face Alignment Net T rained on 300W Large Pose Data Re gression 967 44 Single-Image Depth Perception Net T rained on Depth in the Wild Data Regression 501 45 Single-Image Depth Perception Net T rained on NYU Depth V2 and Depth in the Wild Data Re gression 501 46 Single-Image Depth Perception Net T rained on NYU Depth V2 Data Regression 501 47 Unguided V olumetric Regression Net for 3D Face Reconstruction Re gression 1029 48 Ademxapp Model A1 T rained on ADE20K Data Semantic Segmentation 141 49 Ademxapp Model A1 T rained on P ASCAL VOC2012 and MS-COCO Data Semantic Segmentation 141 50 Multi-scale Context Aggreg ation Net Trained on CamV id Data Semantic Segmentation 53 T able 1. W e use 50 MXNet models from the publicly av ailable W olfram Neural Net Repository [ 17 ] for ev aluation. The models span across 5 DL tasks. All models are run using MXNet. The number of layers in a model is listed. 2.1 Layers as the Perf ormance Building Blocks A DL model is a directed acyclic graph (D A G) where each verte x within the D A G is a layer (or operator , such as conv o- lution, batchnormalization, pooling, element-wise, softmax) and an edge represents the transfer of data. F or a DL model, a layer sequence is defined as a simple path within the D A G containing one or more vertices. A subgraph , on the other hand, is defined as a D A G composed by one or more layers within the model (i.e. subgraph is a superset of layer sequence, and may or may not be a simple path). W e are only interested in network subgraphs that are runnable within framew orks and we call these runnable subgraphs runnable networks . DL models may contain layers that can be ex ecuted in- dependently in parallel. The runnable network determined by these data-independent layers is called a parallel module . For example, Figure 2a shows the VGG16 [ 21 ] (ID= 17 ) the model architecture. VGG16 contains no parallel modules and is a linear sequence of layers. Inception V3 [ 22 ] (ID= 9 ) (shown in Figure 2b ), on the other hand, contains a mix of layer sequences and parallel-modules. DL framew orks such as T ensorFlow [ 1 ], PyT orch [ 18 ], and MXNet [ 6 ] execute a DL model by running the layers within the model graph. W e explore the relation between layer performance and model performance by decomposing each 3 Cheng Li, et al. (a) VGG16 (ID= 17 ). … (b) Inception V3 (ID= 9 ). Figure 2. The model architecture of VGG16 (ID= 17 ) and Inception V3 (ID= 9 ). The critical path in each model is highlighted in red. Figure 3. The sequential and parallel total layer latency normalized to the model’ s end-to-end latenc y using batch size 1 on c5.2xlarge . DL model in T able 1 into layers. W e define a model’ s critical path to be a simple path from the start to the end layer with the highest latenc y . For a DL model, we add all its layers’ latency and refer to the sum as the sequential total layer latency , since this assumes all the layers are ex ecuted sequentially by the DL frame work. Theoretically , data-independent paths within the parallel module can be executed in parallel, thus we also calculate the parallel total layer latency by adding up the layer latencies along the critical path. The critical path of both VGG 16 (ID= 17 ) and Inception V3 (ID= 9 ) is highlighted in red in Figure 2 . For models that do not hav e parallel modules, the sequential total layer latency is equal to the parallel total layer latency . For each of the 50 models, we compare both sequential and parallel total layer latenc y to the model’ s end-to-end la- tency . Figure 3 sho ws the normalized latencies in both cases. For models with parallel modules, the parallel total layer la- tencies are much lo wer than the model’ s end-to-end latenc y . The difference between the sequential total layer latencies and the models’ end-to-end latencies are small. The normal- ized latencies are close to 1 with a geometric metric mean of 91 . 8% for the sequential case. This suggests the current software/hardware stack does not exploit parallel e xecution of data-independent layers or overlapping of layer e xecution, we verified this by inspecting the source code of popular framew orks such as MXNet, PyT orch, and T ensorFlo w . Based on the abov e analysis, we make the 1 observation: Observation 1: DL layers are the performance b uilding blocks of the model performance, therefore, a model’ s performance can be estimated by the performance of its layers. Moreov er , a simple summation is ef fectiv e gi ven the current DL software stack (no parallel execution of data-independent layers or ov erlapping of layer ex ecution) on CPUs. 2.2 Layer Repeatability From a model architecture point of vie w , DL layers are identi- fied by its type, shape, parameters. For example, a con v olution layer is identified by its input shape, output channels, k ernel size, stride, padding, dilation, etc. Layers with the same type, shape, parameters (i.e. only differ in weights) are expected to hav e the same performance. W e inspected the sources code of popular frame work and verified this, as they do not perform any special optimizations for weights. Thus in this paper we consider two layers to be the same if they hav e the same type, shape, parameters, ignoring weight v alues, and two layers are unique if they are not the same. DL models tend to ha ve repeated layers or modules (or subgraphs, e.g. Inception and ResNet modules). For e xample, Figure 4 shows the model architecture of ResNet-50 with the ResNet module detailed. Different ResNet modules ha ve layers in common and ResNet module 2 , 4 , 6 , 8 are entirely repeated within ResNet-50 . Moreov er , DL models are of- ten built on top of existing models (e.g. transfer learning [ 24 ] where model are retrained with different data), using common modules (e.g. T ensorFlow Hub [ 23 ]), or using layer bundles for Neural Architecture Search [ 11 , 25 , 26 ]. This results in ample repeated layers when looking at a corpus of models. W e quantitati vely e xplore the layer repeatability within and across models. Figure 5 shows the percentage of unique layers within each model in T able 1 . W e can see that layers are extensi vely re- peated within DL models. For example, in Unguided Vol- umetric Regression Net for 3D Face Recon- struction (ID= 47 ) which has 1029 layers, only 3 . 9% of 4 DLBricks: Composable Benchmark Generation to Reduce Deep Lear ning Benchmarking Effor t on CPUs (Extended) � BN P P P F S Module 1 Module 2 1 2 2 3 Module 3 Module 4 4 4 4 5 Module 5 Module 6 6 6 6 6 6 7 Module 7 Module 8 8 8 � � BN + BN � BN � BN 64 ⨯ 56 ⨯ 56 64 ⨯ 56 ⨯ 56 256 ⨯ 56 ⨯ 56 256 ⨯ 56 ⨯ 56 64 ⨯ 56 ⨯ 56 64 ⨯ 56 ⨯ 56 64 ⨯ 56 ⨯ 56 64 ⨯ 56 ⨯ 56 64 ⨯ 56 ⨯ 56 64 ⨯ 56 ⨯ 56 256 ⨯ 56 ⨯ 56 256 ⨯ 56 ⨯ 56 256 ⨯ 56 ⨯ 56 256 ⨯ 56 ⨯ 56 + � BN � BN � BN 256 ⨯ 56 ⨯ 56 256 ⨯ 56 ⨯ 56 64 ⨯ 56 ⨯ 56 64 ⨯ 56 ⨯ 56 64 ⨯ 56 ⨯ 56 64 ⨯ 56 ⨯ 56 64 ⨯ 56 ⨯ 56 64 ⨯ 56 ⨯ 56 256 ⨯ 56 ⨯ 56 256 ⨯ 56 ⨯ 56 256 ⨯ 56 ⨯ 56 256 ⨯ 56 ⨯ 56 � � BN + BN � BN � BN 256 ⨯ 56 ⨯ 56 256 ⨯ 56 ⨯ 56 512 ⨯ 28 ⨯ 28 512 ⨯ 28 ⨯ 28 128 ⨯ 28 ⨯ 28 128 ⨯ 28 ⨯ 28 128 ⨯ 28 ⨯ 28 128 ⨯ 28 ⨯ 28 128 ⨯ 28 ⨯ 28 128 ⨯ 28 ⨯ 28 512 ⨯ 28 ⨯ 28 512 ⨯ 28 ⨯ 28 512 ⨯ 28 ⨯ 28 512 ⨯ 28 ⨯ 28 + � BN � BN � BN 512 ⨯ 28 ⨯ 28 512 ⨯ 28 ⨯ 28 128 ⨯ 28 ⨯ 28 128 ⨯ 28 ⨯ 28 128 ⨯ 28 ⨯ 28 128 ⨯ 28 ⨯ 28 128 ⨯ 28 ⨯ 28 128 ⨯ 28 ⨯ 28 512 ⨯ 28 ⨯ 28 512 ⨯ 28 ⨯ 28 512 ⨯ 28 ⨯ 28 512 ⨯ 28 ⨯ 28 � � BN + BN � BN � BN 512 ⨯ 28 ⨯ 28 512 ⨯ 28 ⨯ 28 1024 ⨯ 14 ⨯ 14 1024 ⨯ 14 ⨯ 14 256 ⨯ 14 ⨯ 14 256 ⨯ 14 ⨯ 14 256 ⨯ 14 ⨯ 14 256 ⨯ 14 ⨯ 14 256 ⨯ 14 ⨯ 14 256 ⨯ 14 ⨯ 14 1024 ⨯ 14 ⨯ 14 1024 ⨯ 14 ⨯ 14 1024 ⨯ 14 ⨯ 14 1024 ⨯ 14 ⨯ 14 + � BN � BN � BN 1024 ⨯ 14 ⨯ 14 1024 ⨯ 14 ⨯ 14 256 ⨯ 14 ⨯ 14 256 ⨯ 14 ⨯ 14 256 ⨯ 14 ⨯ 14 256 ⨯ 14 ⨯ 14 256 ⨯ 14 ⨯ 14 256 ⨯ 14 ⨯ 14 1024 ⨯ 14 ⨯ 14 1024 ⨯ 14 ⨯ 14 1024 ⨯ 14 ⨯ 14 1024 ⨯ 14 ⨯ 14 � � BN + BN � BN � BN 1024 ⨯ 14 ⨯ 14 1024 ⨯ 14 ⨯ 14 2048 ⨯ 7 ⨯ 7 2048 ⨯ 7 ⨯ 7 512 ⨯ 7 ⨯ 7 512 ⨯ 7 ⨯ 7 512 ⨯ 7 ⨯ 7 512 ⨯ 7 ⨯ 7 512 ⨯ 7 ⨯ 7 512 ⨯ 7 ⨯ 7 2048 ⨯ 7 ⨯ 7 2048 ⨯ 7 ⨯ 7 2048 ⨯ 7 ⨯ 7 2048 ⨯ 7 ⨯ 7 + � BN � BN � BN 2048 ⨯ 7 ⨯ 7 2048 ⨯ 7 ⨯ 7 512 ⨯ 7 ⨯ 7 512 ⨯ 7 ⨯ 7 512 ⨯ 7 ⨯ 7 512 ⨯ 7 ⨯ 7 512 ⨯ 7 ⨯ 7 512 ⨯ 7 ⨯ 7 2048 ⨯ 7 ⨯ 7 2048 ⨯ 7 ⨯ 7 2048 ⨯ 7 ⨯ 7 2048 ⨯ 7 ⨯ 7 Figure 4. The ResNet-50 (ID= 14 ) architecture. The detailed ResNet modules 1 − 8 are listed above the model graph. % Figure 5. The percentage of unique layers in models in T able 1 , indicating that some layers are repeated within the model. % Figure 6. The type distribution of the repeated layers within each model. the total layers are unique. W e further look at the repeated layers within each model and Figure 6 shows their type distri- bution. As we can see Con volution, Elementwise, BatchNorm, and Norm are the most repeated layer types in terms of intra- model layer repeatability . If we consider all 50 models in T able 1 , the total number of layers is 10815 , but only 1529 are unique (i.e. 14% are unique). W e illustrate the layer repeatability across models by quan- tifying the similarity of any two models listed in T able 1 . W e use the Jaccard similarity coefficient; i.e. for any two models M 1 and M 2 the Jaccard similarity coefficient is defined by | L 1 ∩ L 2 | | L 1 ∪ L 2 | where L 1 and L 2 are the layers of M 1 and M 2 respec- tiv ely . The results are sho wn in Figure 7 . As sho wn, models that shared the same base architecture but are retrained using different data (e.g. CycleGAN * models with IDs 26 − 35 5 Cheng Li, et al. Figure 7. The Jaccard Similarity grid of the models in T able 1 . Each cell corresponds to the Jaccard similarity coefficient between the models at the row and column. Solid red indicates two models hav e identical layers, and black means there is no common layer . and Inception V1 * models with IDs 6 − 8 ) have many common layers. Layers are common across models within the same family (e.g. ResNet * ) since they are b uilt from the same set of modules (e.g. ResNet-50 is sho wn in Figure 4 ), or when solving the same task (e.g. image classification task category). Based on the abov e analysis, we make yet another 2 observ ation: Observation 2: Layers are repeated within and across DL models. This affords us to decrease the time to bench- mark since only a representati ve set of layers need to be ev aluated. The abov e two observ ations suggest that if we can decom- pose models into layers, and then take the union of them to produce a set of representativ e runnable networks, then benchmarking the representativ e runnable networks is suf- ficient to reconstruct the performance of the input models. Since we only look at the representative set, the total runtime is less than running all models directly , thus DLBricks can be used to reduce benchmarking time. Since layer decomposition elides the input model topology , models can be priv ate while their benchmarks can be public. The next section (Section 3 ) describes how we le verage these two observations to build a benchmark generator while ha ving a workflo w where one can reconstruct a model’ s performance based on the bench- marked layer performance. W e further explore the design { P M 1 , …, P M n } Pe rf o rma n ce C o n st ru ct o r 4 { P S 1 , …, P S k } 3 { M 1 , …, M n } { S 1 , …, S k } R u n n i n g Be n ch ma rks Be n ch ma rk G e n e ra t o r Be n ch ma rk G ra n u l a ri t y 1 1 2 6 5 §4.1 §4.2 Pe rf o rma n ce C o n st ru ct i o n W o rkf l o w Be n ch ma rk G e n e ra t i o n W o rkf l o w Legend: Figure 8. DLBricks design and workflow . space of benchmark granularity and its effect on performance construction accuracy . 3 DLBricks Design This section presents DLBricks, a composable benchmark generation design for DL models. The design is motiv ated by the two observations discussed in Section 2 . DLBricks explores not only layer le v el model composition b ut also se- quence le vel composition where a layer sequence is a chain of layers. The benchmark gr anularity ( G ) specifies the max- imum numbers of layers within any layer sequence in the output generated benchmarks. The design and workflo w of DLBricks is shown in Figure 8 . DLBricks consists of a benchmark generation workflo w and a performance construction workflo w . T o generate composable benchmarks, one uses the benchmark generator workflow where: 1 the user inputs a set of models ( M 1 , .. ., M n ) along with a target benchmark granularity . 2 The benchmark gener- ator parses the input models into a representativ e (unique) set of non-overlapping layer sequences and then generates a set of runnable networks ( S 1 , .. ., S k ) using these layer sequences’ in- formation. 3 The user ev aluates the set of runnable networks on a system of interest to get each benchmark’ s corresponding performance ( P S 1 , .. ., P S k ). The benchmark results are stored and 4 are used within the performance construction work- flow . 5 T o construct the performance of an input model, the performance constructor queries the stored benchmark results for the layer sequences within the model, and then 6 com- putes the model’ s estimated performance ( P M 1 , .. ., P M k ). This section describes both workflo ws in detail. 6 DLBricks: Composable Benchmark Generation to Reduce Deep Lear ning Benchmarking Effor t on CPUs (Extended) 3.1 Benchmark Generator The benchmark generator takes a list of models M 1 , . . . , M n and a benchmark granularity G . The benchmark gr anularity specifies the maximum sequence length of the layer sequences generated. This means that when G = 1 , each generated benchmark is a single-layer network, whereas when G = 2 each generated benchmark contains at most 2 layers. T o split a model with the specified benchmark granular- ity , we use the FindModelSubgraphs algorithm (Algo- rithm 1 ). The FindModelSubgraphs takes a model and a maximum sequence length and iteratively generates a set of non-ov erlapping layer sequences. First, the layers in the model are sorted topologically and then calls the Split- Model function (Algorithm 2 ) with the desired begin and end layer of fset. This SplitModel tries to create a runnable DL network using the range of layers desired, if it fails (i.e. a valid DL network cannot be constructed due to input/out- put layer shape mismatch 1 ), then SplitModel creates a network with the current layer and shifts the begin and end positions by one. The SplitModel returns a list of cre- ated runnable DL networks ( S i , . . . , S i + j ) along with the end position to FindModelSubgraphs . The FindMod- elSubgraphs terminates when no other subsequences can be created. The benchmark generator applies the FindModelSub- graphs for each of the input models. A set of representati ve (or unique ) runnable DL networks ( S 1 , . . . , S k ) is then com- puted. W e say two sequences S 1 and S 2 are the same if they hav e the same topology along with the same node parameters (i.e. they are the same DL network modulo the weights). The unique networks are exported to the frameworks’ network format and the user runs them with synthetic input data based on each network’ s input shape. The performance of each net- work is stored ( P S i . . . , P S k ) and used by the performance constructor workflo w . Algorithm 1 The FindModelSubgraphs algorithm. Input: M (Model), G (Benchmark Granularity) Output: M od el s 1: b e д in ← 0 , M o d el s ← { } 2: v er t s ← T opologicalOrder ( T oGraph ( M )) 3: while b e д in ≤ Length ( v s ) do 4: e n d ← Min ( b e д i n + G , Length ( v s )) 5: sm ← SplitModel ( v er t s , be д in , end ) 6: M od el s ← M o d el s + sm [ “models” ] 7: be д in ← sm [ “end” ] + 1 8: end while 9: return M o d el s 1 An example in v alid network is one which contains a Concat layer, but does not hav e all of the Concat layer’ s required input layers. Algorithm 2 The SplitModel algorithm. Input: v er t s , b e д in , e n d Output: ⟨ “models” , “end” ⟩ ▷ Hash table 1: v s ← v e r t s [ be д in : e n d ] 2: try 3: m ← CreateModel ( v s ) ▷ Creates a valid model 4: retur n ⟨ “models” → { m } , “end” → e n d ⟩ 5: catch ModelCreateException 6: m ← { CreateModel ( { v er t s [ be д in ]} ) } 7: n ← SplitModel ( v e r t s , b e д in + 1 , end + 1 ) 8: retur n ⟨ “models” → m + n [ “models” ] , “end” → n [ “end” ] ⟩ 9: end try 3.2 DL Model Perf ormance Construction DLBricks uses the performance of the layer sequences to construct an estimate to the end-to-end performance of the input model M . T o construct a performance estimate, the in- put model is parsed and goes through the same process 1 in Figure 8 . This creates a set of layer sequences. The perfor- mance of each layer sequence is queried from the benchmark results ( P S i . . . , P S k ). DLBricks supports both sequential and parallel performance construction. Sequential performance construction is performed by summing up all of the resulting queried results, whereas parallel performance construction sums up the results along the critical path of the model. Since current frameworks exhibit a sequential ex ecution strategy (from Section 2.1 ), sequential performance construction is used within DLBricks by default. Other performance con- struction can be easily added to DLBricks to accommodate different frame work execution strate gies. 4 Evaluation As the benchmark generation is automated and is based on a set of well-defined and consistent rules, DLBricks reduces the effort of de veloping and maintaining DL benchmarks. Thus relieving the pressure of selecting representati v e DL models. This section, therefore, focuses on demonstrating DLBricks is valid in terms of performance construction accuracy and benchmarking time speedup. W e explore the ef fect of bench- mark granularity on the constructed performance estimation as well as the benchmarking time. W e ev aluated DLBricks with 50 DL models (listed in T able 1 ) using MXNet (v 1 . 5 . 1 using MKL v 2019 . 3 ) on 4 different Amazon EC2 instances. These systems are recommended [ 3 ] by Amazon for DL in- ference and are listed in T able 2 . Each model or benchmark is run 100 times and the 20% trimmed mean is reported. 4.1 Perf ormance Construction Accuracy W e first ran the models on the 4 systems to understand their performance characteristics, as shown in Figure 9 . Then using DLBricks, we constructed the latency estimate of the models 7 Cheng Li, et al. ( ) Figure 9. The end-to-end latency of all models in log scale across systems. (a) Benchmark Granularity= 1 (b) Benchmark Granularity= 2 (c) Benchmark Granularity= 3 (d) Benchmark Granularity= 4 (e) Benchmark Granularity= 5 (f) Benchmark Granularity= 6 Figure 10. The constructed model latency normalized to the model’ s end-to-end latenc y for the 50 model in T able 1 on c5.2xlarge . The benchmark granularity varies from 1 to 6 . Sequence 1 means each benchmark has one layer (layer granularity). Instance CPUS Memory (GiB) $/hr c5.xlarge 4 Intel Platinum 8124M 8GB 0.17 c5.2xlarge 8 Intel Platinum 8124M 16GB 0.34 c4.xlarge 4 Intel Xeon E5-2666 v3 7.5GB 0.199 c4.2xlarge 8 Intel Xeon E5-2666 v3 15GB 0.398 T able 2. Evaluations are performed on the 4 Amazon EC2 systems listed. The c5. * operate at 3.0 GHz, while the c4. * systems operate at 2.9 GHz. The systems are ones recommended by Amazon for DL inference. Figure 11. The geometric mean of the normalized latency (con- structed vs end-to-end latency) of all the 50 models on the 4 systems with varying benchmark granularity from 1 to 10 . based on the performance of their layer sequence benchmarks. Figure 10 shows the constructed model latency normalized to the model’ s end-to-end latency for all the models with va rying benchmark granularity from 1 to 6 on c5.2xlarge . W e see that the constructed latenc y is a tight estimate of the model’ s actual performance across models and benchmark granularities. E.g., for benchmark granularity G = 1 , the normalized latency ranges between 82 . 9% and 98 . 1% with a geometric mean of 91 . 8% . Figure 11 shows the geometric mean of the normalized latency (constructed vs end-to-end latency) of all the 50 mod- els across systems and benchmark granularities. Overall, the estimated latency is within 5% (e.g. G = 3 , 5 , 9 , 10 ) to 11% ( G = 1 ) of the model end-to-end latency across systems. This demonstrates that DLBricks provides a tight estimate to input models’ actual performance. 4.2 Benchmarking Time Speedup DLBricks decreases the benchmarking time by only ev alu- ating the unique layer sequences within and across models. 8 DLBricks: Composable Benchmark Generation to Reduce Deep Lear ning Benchmarking Effor t on CPUs (Extended) Figure 12. The speedup of total benchmarking time for the all the models across systems and benchmark granularities. Recall from Section 2.2 that for all the 50 models, the to- tal number of layers is 10815 , but only 1529 are unique (i.e. 14% are unique). Figure 12 sho ws the speedup of the total benchmarking time across systems as benchmark granularity varies. The benchmarking time speedup is calculated as the sum of the end-to-end latency of all models di vided by the sum of the latency of all the generated benchmarks. Up to 4 . 4 × benchmarking time speedup is observed for G = 1 on the c5.xlarge system. The speedup decreases as the bench- mark granularity increases. This is because as the benchmark granularity increases, the chance of having repeated layer sequences within and across models decreases. Figure 10 and Figure 12 suggest a trade-off e xists between the performance construction accuracy and benchmarking time speedup and the trade-of f is system-dependent. F or ex- ample, while G = 1 (layer granularity model decomposition and construction) produces the maximum benchmarking time speedup, the constructed latenc y is slightly less accurate com- paring to other G values on the systems. Since this accuracy loss is small, overall, G = 1 is a good choice of benchmark granularity configuration for DLBricks gi ven the current DL software stack on CPUs. 5 Related W ork DL Benchmarking: T o characterize the performance of DL models, both industry and academia have in vested heavily in dev eloping benchmark suites that characterize models and systems. The benchmarking methods are either end-to-end benchmarks (performing user-observ able latency measure- ment on a set of representative DL models [ 8 , 16 , 27 ]) or are micro-benchmarks [ 4 , 7 , 27 ] (isolating common kernels or layers that are found in models of interest). The end-to- end benchmarks target end-users and measure the latenc y or throughput of a model under a specific workload scenario. The micro-benchmark approach, on the other hand, distills models to their basic atomic operations (such as dense ma- trix multiplies, con volutions, or communication routines) and measures their performance to guide hardware or software design improvements [ 10 , 15 ]. While both approaches are valid and have their use cases, their benchmarks are manu- ally selected and de veloped. Thus, curation and maintaining these benchmarks f acing requires significant ef fort and, in the case of lack of maintenance, becomes less representati v e of real-world models. DLBricks complements the DL benchmarking landscape as it introduces a novel benchmarking methodology which reduces the effort of developing, maintaining, and running DL benchmarks. DLBricks relieves the pressure of select- ing representati ve DL models and copes well with the fast- ev olving pace of DL models. DLBricks automatically de- composes DL models into runnable networks and generates micro-benchmark based on these netw orks. Users can specify the benchmark granularity . At the two extremes, when the granularity is 1 a layer-based micro-benchmark is generated, whereas when the granularity is equal to the number of layers within the model then an end-to-end network is generated. T o the best of our kno wledge, there has been no pre vious w ork solving the same problem and we are the first to propose such as design. Others: Previous work [ 11 , 26 ] has also decomposed DL models into layers to guide performance-aware neural archi- tecture search. DLBricks focuses on model performance and aims to reduce benchmarking effort. DLBricks shares a simi- lar spirit as synthetic benchmark generation. There is work about synthetic benchmark generation in other domains [ 14 ], howe ver , to the authors’ kno wledge, there has been no work on applying or specializing the synthetic benchmark genera- tion to the DL domain. 6 Discussion and Future W ork Generating Overlapping Benchmarks — The current de- sign only considers non-ov erlapping layer sequences during benchmark generation. This may inhibit some types of opti- mizations (such as layer fusion). A solution requires a small tweak to Algorithm 1 where we increment the be gin by 1 rather than the end index of the SplitModel algorithm (line 7 ). A small modification is also needed within the perfor- mance construction step to pick the layer sequence resulting in the smallest latency . Future work would explore the design space when generated benchmarks can ov erlap. Adapting to F ramework Evolution — The current DLBricks design is based on the observation that current DL frameworks do not ex ecute data-independent layers in parallel. Although DLBricks supports both sequential and parallel execution (Section 3.2 ), as DL frame works start to ha ve some support of parallel ex ecution of data-independent layers, the current design may be no longer suitable and needs to be adjusted. T o adapt DLBricks to this e volution of frame w orks, one can ad- just DLBricks to take user -specified parallel ex ecution rules. DLBricks can then use the parallel execution rules to make a more accurate model performance estimation. Future W ork — While this work focuses on CPUs, we expect the design to hold for GPUs as well. Future work would explore the design for GPUs. W e are also interested in 9 Cheng Li, et al. other use cases that are af forded by the DLBricks design — model/system comparison and advising for the cloud [ 5 , 13 , 20 ]. For example, it is common to ask questions such as, given a DL model which system should I use? or given a system and a task, which model should I use? These questions might come from a user who wants to pick the system that’ s ideal for the target model, a cloud provider who needs to schedule or migrate DL tasks, etc. Using DLBricks, the system pro vider can curate a continuously updated database of the generated benchmarks results across its system of ferings. The system provider can then perform a performance estimate of the user’ s DL model (without running it) and giv e suggestions as to which system to choose. 7 Conclusion The fast-ev olving landscape of DL posts considerable chal- lenges in the DL benchmarking practice. While benchmark suites are under pressure and are struggling to be agile, up- to-date, and representati ve, we take a dif ferent approach and propose a nov el benchmarking design aimed at relieving this pressure. Lev eraging the ke y observ ations that layers are the performance building block of DL models and the layer re- peatability within and across models, DLBricks automatically generates composable benchmarks that reduce the effort of de- veloping, maintaining, and running DL benchmarks. Through the e valuation of state-of-the-art models on representativ e systems, we demonstrated that DLBricks copes with the fast- ev olving pace of DL models. References [1] M. Abadi, A. Agarw al, P . Barham, E. Brevdo, Z. Chen, C. Citroand GS. Corrado, A. Davis, J. Dean, M. Devin, S. Ghemawat, I. Goodfellow , A. Harp, G. Irving, M. Isard, Y . Jia, R. Jozefowicz, L. Kaiser, M. Kudlur , J. Levenberg, D. Mane, R. Monga, S. Moore, D. Murray , C. Olah, M. Schuster, J. Shlens, B. Steiner, I. Sutskev er , K. T alw ar , P . T ucker , V . V anhoucke, V . V asudev an, F . V ieg as, O. V inyals, P . W arden, M. W attenber g, M. Wicke, Y . Y u, and X. Zheng. 2016. T ensorFlow: Lar ge-scale Machine Learning on Heter ogeneous Distributed Systems . Technical Report. Cornell Univ ersity . [2] Robert Adolf, Saketh Rama, Brandon Reagen, Gu-yeon W ei, and David Brooks. 2016. Fathom: Reference workloads for modern deep learn- ing methods. In 2016 IEEE International Symposium on W orkload Characterization (IISWC) . IEEE, IEEE, 1–10. [3] Amazon. 2019. Recommended CPU Instances. docs.aws.com/dlami/ latest/devguide/cpu.html . Accessed: 2019-10-17. [4] Baidu. 2019. DeepBench. github.com/baidu- research/DeepBench . [5] Denis Baylor, Levent Koc, Chiu Y uen Koo, Lukasz Lew , Clemens Mew ald, Akshay Naresh Modi, Neoklis Polyzotis, Sukriti Ramesh, Sudip Roy , Stev en Euijong Whang, Martin W icke, Eric Breck, Jarek W ilkiewicz, Xin Zhang, Martin Zinkevich, Heng-Tze Cheng, Noah Fiedel, Chuan Y u Foo, Zakaria Haque, Salem Haykal, Mustafa Ispir, and V ihan Jain. 2017. Tfx. In Proceedings of the 23r d A CM SIGKDD International Confer ence on Knowledge Discovery and Data Mining - KDD ’17 . A CM, A CM Press, 1387–1395. [6] T ianqi Chen, Mu Li, Y utian Li, Min Lin, Naiyan W ang, Minjie W ang, T ianjun Xiao, Bing Xu, Chiyuan Zhang, and Zheng Zhang. 2015. Mxnet: A flexible and efficient machine learning library for hetero- geneous distributed systems. arXiv pr eprint arXiv:1512.01274 (2015). [7] Soumith Chintala. 2019. Con vNet Benchmarks. github .com/soumith/ con vnet- benchmarks . [8] Cody Coleman, Matei Zaharia, Daniel Kang, Deepak Narayanan, Luigi Nardi, T ian Zhao, Jian Zhang, Peter Bailis, Kunle Olukotun, and Chris Ré. 2019. Analysis of DA WNBench, a Time-to-Accurac y Machine Learning Performance Benchmark. SIGOPS Oper . Syst. Rev . 53, 1 (July 2019), 14–25. [9] Jeff Dean, David Patterson, and Cliff Y oung. 2018. A New Golden Age in Computer Architecture: Empowering the Machine-Learning Rev olution. IEEE Micr o 38, 2 (March 2018), 21–29. [10] Shi Dong, Xiang Gong, Y ifan Sun, T rinayan Baruah, and Da vid Kaeli. 2018. Characterizing the Microarchitectural Implications of a Conv olu- tional Neural Network (CNN) Ex ecution on GPUs. In Pr oceedings of the 2018 A CM/SPEC International Confer ence on P erformance Engi- neering - ICPE ’18 . A CM, A CM Press, 96–106. [11] Thomas Elsken, Jan Hendrik Metzen, and Frank Hutter . 2019. Neural Architecture Search: A Survey . Journal of Machine Learning Resear ch 20, 55 (2019), 1–21. [12] Kim Hazelwood, Sarah Bird, David Brooks, Soumith Chintala, Utku Diril, Dmytro Dzhulgakov , Mohamed Fawzy , Bill Jia, Y angqing Jia, Aditya Kalro, James Law , Ke vin Lee, Jason Lu, Pieter Noordhuis, Misha Smelyanskiy , Liang Xiong, and Xiaodong W ang. 2018. Applied Machine Learning at Facebook: A Datacenter Infrastructure Perspec- tiv e. In 2018 IEEE International Symposium on High P erformance Computer Ar chitectur e (HPCA) . IEEE, IEEE, 620–629. [13] W aldemar Hummer, V inod Muthusamy , Thomas Rausch, Parijat Dube, Kaoutar El Maghraoui, Anupama Murthi, and Punleuk Oum. 2019. ModelOps: Cloud-based Lifecycle Management for Reliable and T rusted AI. In 2019 IEEE International Confer ence on Cloud Engineer- ing (IC2E) . IEEE, IEEE, 113–120. [14] M.D. Hutton, J.S. Rose, and D.G. Corneil. 2002. Automatic generation of synthetic sequential benchmark circuits. IEEE T rans. Comput.-Aided Des. Inte gr . Circuits Syst. 21, 8 (Aug. 2002), 928–940. [15] Matthew L. Merck, Ramyad Hadidi, Hyesoon Kim, Bingyao W ang, Lixing Liu, Chunjun Jia, Arthur Siqueira, Qiusen Huang, Abhijeet Saraha, Dongsuk Lim, and Jiashen Cao. 2019. Characterizing the Execution of Deep Neural Networks on Collaborativ e Robots and Edge Devices. In Proceedings of the Practice and Experience in Advanced Resear ch Computing on Rise of the Machines (learning) - PEARC ’19 (PEARC ’19) . A CM Press, New Y ork, NY , USA, Article 65, 6 pages. [16] mlperf 2019. MLPerf. github.com/mlperf . Accessed: 2019-10-17. [17] NeuralNetRepository 2019. W olfram NeuralNet Repository. https: //resources.wolframcloud.com/NeuralNetRepository/ . Accessed: 2019- 10-17. [18] Adam Paszke, Sam Gross, Soumith Chintala, and Gregory Chanan. 2017. Pytorch: T ensors and dynamic neural networks in p ython with strong gpu acceleration. 6 (2017). [19] Scopus Previe w . [n.d.]. Scopus Previe w . https://www .scopus.com/. Accessed: 2019-10-17. [20] Thomas Rausch, W aldemar Hummer , V inod Muthusamy , Alexander Rashed, and Schahram Dustdar . 2019. T owards a Serv erless Platform for Edge AI. In 2nd { USENIX } W orkshop on Hot T opics in Edge Computing (HotEdge 19) . [21] Karen Simonyan and Andrew Zisserman. 2014. V ery Deep Con- volutional Networks for Large-Scale Image Recognition. CoRR abs/1409.1556 (2014). arxiv .org/abs/1409.1556 [22] Christian Szegedy , V incent V anhoucke, Serge y Ioffe, Jon Shlens, and Zbigniew W ojna. 2016. Rethinking the Inception Architecture for Computer V ision. In 2016 IEEE Confer ence on Computer V ision and P attern Recognition (CVPR) . IEEE, 2818–2826. [23] T ensorFlow Hub [n.d.]. T ensorFlow Hub is a library for reusable machine learning modules . https://www .tensorflow .org/hub . Accessed: 2019-10-17. 10 DLBricks: Composable Benchmark Generation to Reduce Deep Lear ning Benchmarking Effor t on CPUs (Extended) [24] Karl W eiss, T aghi M. Khoshgoftaar, and DingDing W ang. 2016. A survey of transfer learning. J Big Data 3, 1 (May 2016), 9. [25] Bichen W u, Xiaoliang Dai, Peizhao Zhang, Y anghan W ang, Fei Sun, Y iming W u, Y uandong Tian, Peter V ajda, Y angqing Jia, and Kurt Keutzer . 2018. FBNet: Hardware-aware Efficient Con vNet Design via Differentiable Neural Architecture Search. CoRR abs/1812.03443 (2018). arxiv .org/abs/1812.03443 [26] Carole-Jean W u, Da vid Brooks, K evin Chen, Douglas Chen, Sy Choud- hury , Marat Dukhan, Kim Hazelwood, Eldad Isaac, Y angqing Jia, Bill Jia, T ommer Leyv and, Hao Lu, Y ang Lu, Lin Qiao, Brandon Reagen, Joe Spisak, Fei Sun, Andrew Tulloch, Peter V ajda, Xiaodong W ang, Y anghan W ang, Bram W asti, Yiming W u, Ran Xian, Sungjoo Y oo, and Peizhao Zhang. 2019. Machine Learning at Facebook: Understanding Inference at the Edge. In 2019 IEEE International Symposium on High P erformance Computer Arc hitectur e (HPCA) . IEEE, 11398–11407. [27] W ei Zhang, W ei W ei, Lingjie Xu, Lingling Jin, and Cheng Li. 2019. AI Matrix: A Deep Learning Benchmark for Alibaba Data Centers. arXiv pr eprint arXiv:1909.10562 (2019). [28] Hongyu Zhu, Mohamed Akrout, Bojian Zheng, Andrew Pelegris, Anand Jayarajan, Amar Phanishayee, Bianca Schroeder, and Gennady Pekhimenko. 2018. Benchmarking and Analyzing Deep Neural Net- work T raining. In 2018 IEEE International Symposium on W orkload Characterization (IISWC) . IEEE, IEEE, 88–100. 11
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment