얼굴 랜드마크 기반 화자 독립형 오디오 비주얼 음성 향상
본 논문은 다중 화자가 동시에 말하는 혼합 음성에서 시각 정보가 제공되는 목표 화자의 음성을 향상시키는 방법을 제안한다. 얼굴 랜드마크 검출기를 이용해 얻은 움직임 특징을 LSTM 기반 모델에 입력하여 시간‑주파수 마스크를 예측하고, 이를 혼합 스펙트로그램에 적용한다. GRID와 TCD‑TIMIT 데이터셋에서 화자 독립적으로 학습·평가했으며, 시각‑음성 결합 마스크가 기존 방법보다 높은 SDR, PESQ, ViSQOL 점수를 기록한다.
저자: Giovanni Morrone, Luca Pasa, Vadim Tikhanoff
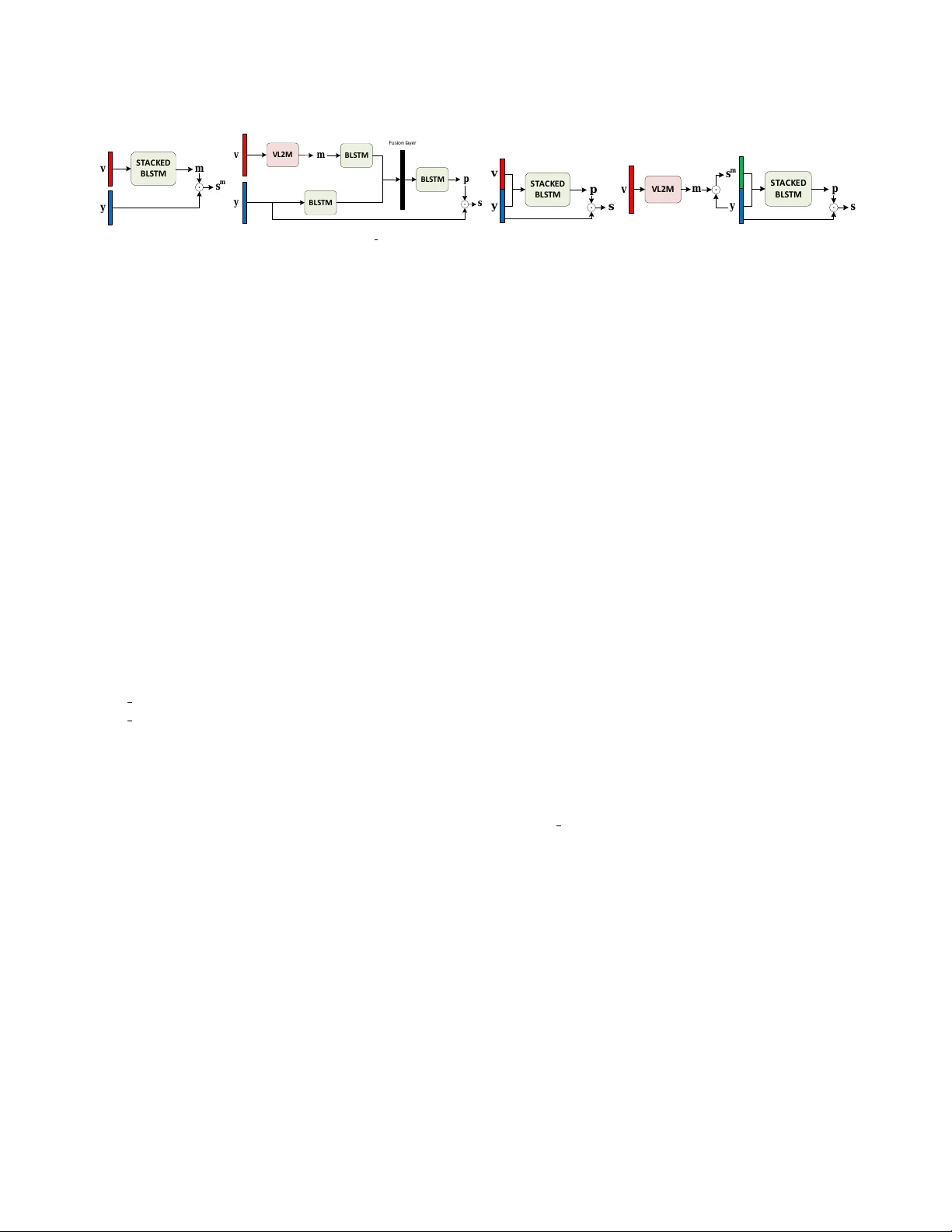
본 논문은 “칵테일 파티” 상황, 즉 여러 화자가 동시에 말하는 혼합 음성에서 목표 화자의 음성을 선택적으로 향상시키는 문제에 초점을 맞춘다. 기존 연구들은 주로 작은 오디오‑비주얼 데이터셋에서 직접 영상 프레임을 입력으로 사용해 시각 특징을 학습했지만, 데이터가 부족하면 과적합 위험이 크다. 이를 해결하고자 저자들은 사전에 대규모 이미지 데이터셋으로 학습된 얼굴 랜드마크 검출기(Dlib)를 이용해, 각 프레임에서 68개의 얼굴 포인트(총 136 차원)를 추출하고, 프레임 간 차분을 통해 움직임 벡터를 만든다. 이 움직임 벡터는 입술뿐 아니라 눈, 코, 턱 등 전체 얼굴의 미세 움직임을 포함하므로, 말소리와의 연관성을 풍부하게 제공한다.
시각 특징과 혼합 음성 스펙트로그램을 입력으로 하는 네 가지 모델을 설계하였다.
1. **VL2M (Video‑Landmark‑to‑Mask)**
- 입력: 순수 시각 움직임 벡터 v(t)
- 출력: 목표 이진 마스크(TBM) ˆm(t)
- 구조: 5층 스택된 양방향 LSTM (BLSTM) → 시그모이드 활성화
- 손실: 이진 교차 엔트로피 (TBM과 ˆm 간)
- TBM은 각 화자의 평균 스펙트럼과 표준편차를 이용해 임계값 τ
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기