Face Landmark-based Speaker-Independent Audio-Visual Speech Enhancement in Multi-Talker Environments
In this paper, we address the problem of enhancing the speech of a speaker of interest in a cocktail party scenario when visual information of the speaker of interest is available. Contrary to most previous studies, we do not learn visual features on…
Authors: Giovanni Morrone, Luca Pasa, Vadim Tikhanoff
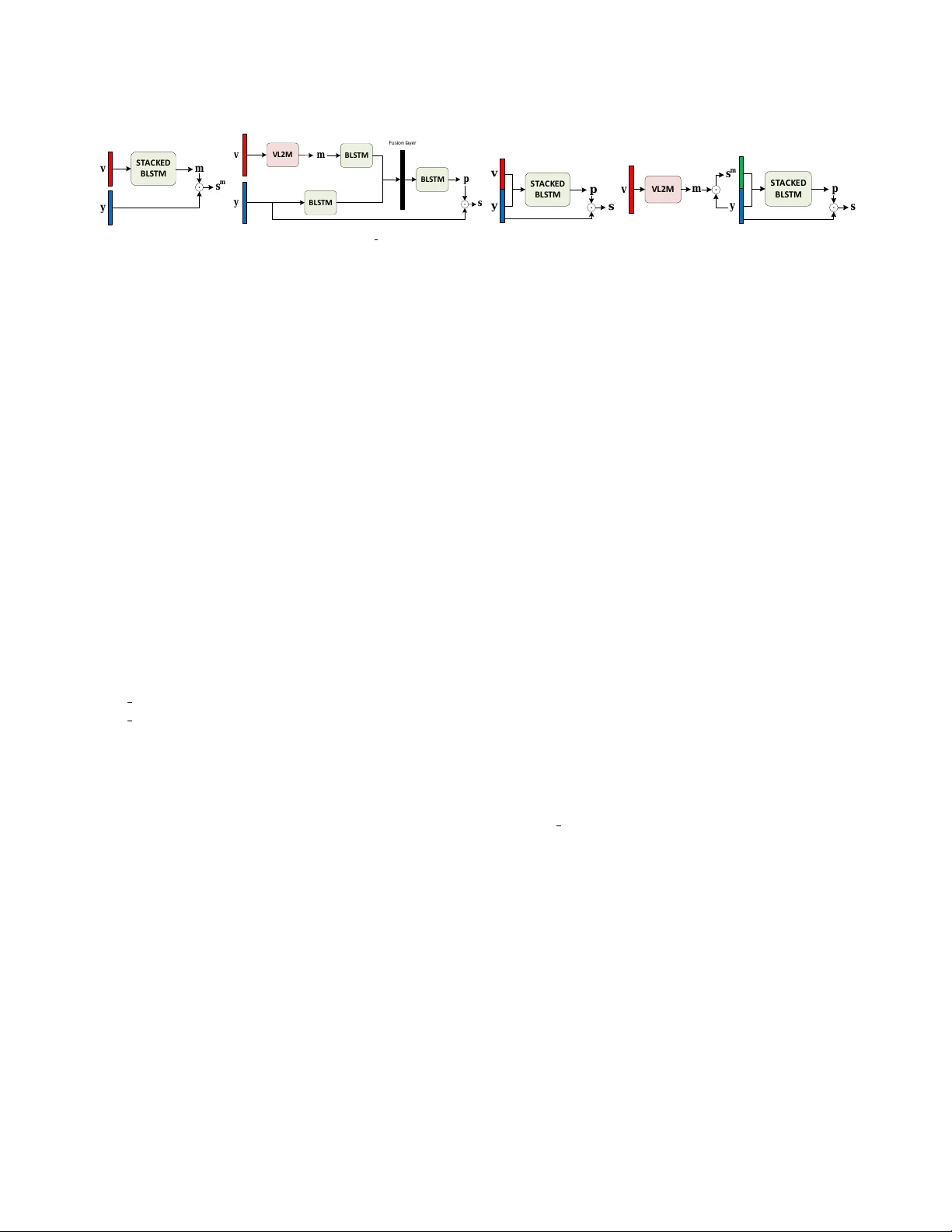
F A CE LANDMARK-B ASED SPEAKER-INDEPENDENT A UDIO-VISU AL SPEECH ENHANCEMENT IN MUL TI-T ALKER ENVIR ONMENTS Giovanni Morr one ? Luca P asa † V adim T ikhanoff † Sonia Ber gamaschi ? Luciano F adiga † Leonar do Badino † ? Department of Engineering ”Enzo Ferrari”, Uni versity of Modena and Re ggio Emilia, Modena, Italy † Istituto Italiano di T ecnologia, Ferrara, Italy ABSTRA CT In this paper , we address the problem of enhancing the speech of a speaker of interest in a cocktail party scenario when vi- sual information of the speaker of interest is a vailable. Contrary to most previous studies, we do not learn visual features on the typically small audio-visual datasets, b ut use an already a vailable face landmark detector (trained on a sep- arate image dataset). The landmarks are used by LSTM-based models to gen- erate time-frequency masks which are applied to the acoustic mixed-speech spectrogram. Results show that: (i) land- mark motion features are very ef fectiv e features for this task, (ii) similarly to pre vious work, reconstruction of the target speaker’ s spectrogram mediated by masking is significantly more accurate than direct spectrogram reconstruction, and (iii) the best masks depend on both motion landmark features and the input mixed-speech spectrogram. T o the best of our knowledge, our proposed models are the first models trained and ev aluated on the limited size GRID and TCD-TIMIT datasets, that achiev e speaker-independent speech enhancement in a multi-talker setting. Index T erms — audio-visual speech enhancement, cock- tail party problem, time-frequency mask, LSTM, face land- marks 1. INTR ODUCTION In the context of speech perception, the cocktail party effect [1, 2] is the ability of the brain to recognize speech in complex and adverse listening conditions where the attended speech is mixed with competing sounds/speech. Speech perception studies have shown that watching speaker’ s face movements could dramatically improve our ability at recognizing the speech of a target speaker in a multi-talker en vironment [3, 4]. This work aims at extracting the speech of a target speaker from single channel audio of sev eral people talking simulta- neously . This is an ill-posed problem in that many differ - ent hypotheses about what the target speaker says are con- sistent with the mixture signal. Y et, it can be solved by ex- ploiting some additional information associated to the speaker of interest and/or by lev eraging some prior knowledge about speech signal properties (e.g., [5]). In this work we use face mov ements of the target speaker as additional information. This paper (i) proposes the use of face landmark’ s move- ments, extracted using Dlib [6, 7] and (ii) compares dif fer- ent w ays of mapping such visual features into time-frequency (T -F) masks, then applied to clean the acoustic mixed-speech spectrogram. By using Dlib extracted landmarks we reliev e our mod- els from the task of learning useful visual features from raw pixels. That aspect is particularly relev ant when the training audio-visual datasets are small. The analysis of landmark-dependent masking strategies is motiv ated by the fact that speech enhancement mediated by an explicit masking is often more ef fectiv e than mask-free enhancement [8]. All our models were trained and ev aluated on the GRID [9] and TCD-TIMIT [10] datasets in a speaker-independent setting. 1.1. Related work Speech enhancement aims at extracting the v oice of a tar- get speaker , while speech separation refers to the problem of separating each sound source in a mixture. Recently pro- posed audio-only single-channel methods hav e achie ved v ery promising results [11, 12, 13]. Ho wev er the task still remains challenging. Additionally , audio-only systems need separate models in order to associate the estimated separated audio sources to each speaker , while vision easily allo w that in a unified model. Regarding audio-visual speech enhancement and separa- tion methods an extensi ve revie w is provided in [14]. Here we focus on the deep-learning methods that are most related to the present work. Our first architecture (Section 2.1) is inspired by [15], where a pre-trained con volutional neural network (CNN) is used to generate a clean spectrogram from silent video [16]. Rather than directly computing a time-frequency (T -F) mask, the mask is computed by thresholding the estimated clean spectrogram. This approach is not very effecti ve since the pre-trained CNN is designed for a different task (video-to- speech synthesis). In [17] a CNN is trained to directly esti- mate clean speech from noisy audio and input video. A sim- ilar model is used in [18], where the model jointly generates clean speech and input video in a denoising-autoender archi- tecture. [19] shows that using information about lip positions can help to improve speech enhancement. The video feature vec- tor is obtained computing pair-wise distances between any mouth landmarks. Similarly to our approach their visual fea- tures are not learned on the audio-visual dataset but are pro- vided by a system trained on different dataset. Contrary to our approach, [19] uses position-based features while we use motion features (of the whole face) that in our experiments turned out to be much more ef fecti ve than positional features. Although the aforementioned audio-visual methods work well, they have only been ev aluated in a speaker-dependent setting. Only the av ailability of ne w large and heterogeneous audio-visual datasets has allowed the training of deep neu- ral network-based speaker-independent speech enhancement models [20, 21, 22]. The present work shows that huge audio-visual datasets are not a necessary requirement for speaker-independent audio-visual speech enhancement. Although we have only considered datasets with simple visual scenarios (i.e., the target speaker is always facing the camera), we expect our methods to perform well in more complex scenarios thanks to the robust landmark e xtraction. 2. MODEL ARCHITECTURES W e e xperimented with the four models shown in Fig. 1. All models receive in input the target speaker’ s landmark mo- tion vectors and the power -law compressed spectrogram of the single-channel mixed-speech signal. All of them perform some kind of masking operation. 2.1. VL2M model At each time frame, the video-landmark to mask (VL2M) model (Fig. 1a) estimates a T -F mask from visual features only (of the target speaker). F ormally , gi ven a video sequence v = [ v 1 , . . . , v T ] , v t ∈ R n and a target mask sequence m = [ m 1 , . . . , m T ] , m t ∈ R d , VL2M perform a function F v l 2 m ( v ) = ˆ m , where ˆ m is the estimated mask. The training objecti ve for VL2M is a T arget Binary Mask (TBM) [23, 24], computed using the spectrogram of the tar- get speak er only . This is moti v ated by our goal of e xtracting the speech of a target speaker as much as possible indepen- dently of the concurrent speakers, so that, e.g., we do not need to estimate their number . An additional motiv ations is that the model takes as only input the visual features of the target speaker , and a target TBM that only depends on the target speaker allows VL2M to learn a function (rather than approximating an ill-posed one-to-many mapping). Giv en a clean speech spectrogram of a speaker s = [ s 1 , . . . , s T ] , s t ∈ R d , the TBM is defined by comparing, at each frequency bin f ∈ [1 , . . . , d ] , the target speaker value s t [ f ] vs. a reference threshold τ [ f ] . As in [15], we use a function of long-term av erage speech spectrum (L T ASS) as reference threshold. This threshold indicates if a T -F unit is generated by the speaker or refers to silence or noise. The process to compute the speaker’ s TBM is as follows: 1. The mean π [ f ] and the standard deviation σ [ f ] are computed for all frequency bins of all seen spectro- grams in speaker’ s data. 2. The threshold τ [ f ] is defined as τ [ f ] = π [ f ] + 0 . 6 · σ [ f ] where 0 . 6 is a value selected by manual inspection of sev eral spectrogram-TBM pairs. 3. The threshold is applied to ev ery speaker’ s speech spec- trogram s . m t [ f ] = 1 , if s t [ f ] ≥ τ [ f ] , 0 , otherwise. The mapping F v l 2 m ( · ) is carried out by a stacked bi- directional Long Short-T erm Memory (BLSTM) network [25]. The BLSTM outputs are then forced to lay within the [0 , 1] range. Finally the computed TBM ˆ m and the noisy spectrogram y are element-wise multiplied to ob- tain the estimated clean spectrogram ˆ s m = ˆ m ◦ y , where y = [ y 1 , . . . y T ] , y t ∈ R d . The model parameters are estimated to minimize the loss: J v l 2 m = P T t =1 P d f =1 − m t [ f ] · log ( ˆ m t [ f ]) − (1 − m t [ f ]) · log (1 − ˆ m t [ f ]) 2.2. VL2M ref model VL2M generates T -F masks that are independent of the acous- tic conte xt. W e may w ant to refine the masking by including such context. This is what the novel VL2M ref does (Fig. 1b). The computed TBM ˆ m and the input spectrogram y are the input to a function that outputs an Ideal Amplitude Mask (IAM) p (known as FFT -MASK in [8]). Giv en the target clean spectrogram s and the noisy spectrogram y , the IAM is defined as: p t [ f ] = s t [ f ] y t [ f ] Note that although IAM generation requires the mixed-speech spectrogram, separate spectrograms for each concurrent speakers are not required. The target speaker’ s spectrogram s is reconstructed by multiplying the input spectrogram with the estimated IAM. V alues greater than 10 in the IAM are clipped to 10 in order to obtain better numerical stability as suggested in [8]. v : video input y : noisy spectrogram s m : clean spectrogram TBM s : clean spectrogram IAM m : TBM p : IAM S T A C K E D BL S T M m s m v y (a) VL2M v V L 2 M m y BL S T M B L S T M F u s i o n l a ye r BL S T M p s (b) VL2M ref v y p S T A C K E D BL S T M s (c) Audio-V isual concat s m y p S T A C K E D BL S T M s v V L 2 M m (d) Audio-V isual concat-ref Fig. 1 . Model architectures. The model performs a function F mr ( v , y ) = ˆ p that con- sists of a VL2M component plus three different BLSTMs G m , G y and H . G m ( F v l 2 m ( v )) = r m receiv es the VL2M mask ˆ m as in- put, and G y ( y ) = r y is fed with the noisy spectrogram. Their output r m , r y ∈ R z are fused in a joint audio-visual represen- tation h = [ h 1 , . . . , h T ] , where h t is a linear combination of r m t and r y t : h t = W hm · r m t + W hy · r y t + b h . h is the input of the third BLSTM H ( h ) = ˆ p , where ˆ p lays in the [0,10] range. The loss function is: J mr = T X t =1 d X f =1 ( ˆ p t [ f ] · y t [ f ] − s t [ f ]) 2 2.3. A udio-Visual concat model The third model (Fig. 1c) performs early fusion of audio- visual features. This model consists of a single stacked BLSTM that computes the IAM mask ˆ p from the concate- nated [ v , y ] . The training loss is the same J mr used to train VL2M ref. This model can be regarded as a simplification of VL2M ref, where the VL2M operation is not performed. 2.4. A udio-Visual concat-ref model The fourth model (Fig. 1d) is an impro ved version of the model described in section 2.3. The only difference is the input of the stacked BLSTM that is replaced by [ ˆ s m , y ] where ˆ s m is the denoised spectrogram returned by VL2M operation. 3. EXPERIMENT AL SETUP 3.1. Dataset All experiments were carried out using the GRID [9] and TCD-TIMIT [10] audio-visual datasets. For each of them, we created a mixed-speech v ersion. Regarding the GRID corpus, for each of the 33 speakers (one had to be discarded) we first randomly selected 200 ut- terances (out of 1000 ). Then, for each utterance, we created 3 dif ferent audio-mixed samples. Each audio-mixed sample was created by mixing the chosen utterance with one utter- ance from a different speak er . That resulted in 600 audio-mixed samples per speaker . The resulting dataset was split into disjoint sets of 25 / 4 / 4 speakers for training/v alidation/testing respectiv ely . The TCD-TIMIT corpus consists of 59 speakers (we ex- cluded 3 professionally-trained lipspeakers) and 98 utterances per speaker . The mix ed-speech v ersion was created following the same procedure as for GRID, with one difference. Con- trary to GRID, TCD-TIMIT utterances hav e different dura- tion. Thus 2 utterances were mixed only if their duration dif- ference did not exceed 2 seconds. F or each utterance pair , we forced the non-target speaker’ s utterance to match the du- ration of the target speaker utterance. If it was longer , the utterance was cut at its end, whereas if it w as shorter, silence samples were equally added at its start and end. The resulting dataset was split into disjoint sets of 51 / 4 / 4 speakers for training/v alidation/testing respectiv ely . 3.2. LSTM training In all experiments, the models were trained using the Adam optimizer [26]. Early stopping was applied when the error on the v alidation set did not decrease o ver 5 consecutive epochs. VL2M, A V concat and A V concat-ref had 5 , 3 and 3 stacked BLSTM layers respecti vely . All BLSTMs had 250 units. Hyper-parameters selection was performed by using random search with a limited number of samples, therefore all the reported results may improve through a deeper hyper - parameters validation phase. VL2M ref and A V concat-ref training was performed in 2 steps. W e first pre-trained the models using the oracle TBM m . Then we substituted the oracle masks with the VL2M component and retrained the models while freezing the pa- rameters of the VL2M component. 3.3. A udio pre- and post-processing The original wa veforms were resampled to 16 kHz. Short- T ime F ourier T ransform (STFT) x was computed using FFT size of 512, Hann window of length 25 ms (400 samples), and hop length of 10 ms (160 samples). The input spectro- gram was obtained taking the STFT magnitude and perform- ing power-la w compression | x | p with p = 0 . 3 . Finally we applied per-speak er 0-mean 1-std normalization. In the post-processing stage, the enhanced wa veform gen- erated by the speech enhancement models was reconstructed SDR PESQ V iSQOL Noisy − 1 . 06 1 . 81 2 . 11 VL2M 3 . 17 1 . 51 1 . 16 VL2M ref 6 . 50 2 . 58 2 . 99 A V concat 6 . 31 2 . 49 2 . 83 A V c-ref 6 . 17 2 . 58 2 . 96 T able 1 . GRID results - speak er-dependent. The “Noisy” ro w refers to the metric values of the input mix ed-speech signal. 2 Speakers 3 Speakers SDR PESQ V iSQOL SDR PESQ V iSQOL Noisy 0 . 21 1 . 94 2 . 58 − 5 . 34 1 . 43 1 . 62 VL2M 3 . 02 1 . 81 1 . 70 − 2 . 03 1 . 43 1 . 25 VL2M ref 6 . 52 2 . 53 3 . 02 2 . 83 2 . 19 2 . 53 A V concat 7 . 37 2 . 65 3 . 03 3 . 02 2 . 24 2 . 49 A V c-ref 8 . 05 2 . 70 3 . 07 4 . 02 2 . 33 2 . 64 T able 2 . GRID results - speaker -independent. by applying the in verse STFT to the estimated clean spectro- gram and using the phase of the noisy input signal. 3.4. V ideo pre-pr ocessing Face landmarks were extracted from video using the Dlib [7] implementation of the face landmark estimator described in [6]. It returns 68 x-y points, for an overall 136 values. W e upsampled from 25/29.97 fps (GRID/TCD-TIMIT) to 100 fps to match the frame rate of the audio spectrogram. Upsampling was carried out through linear interpolation ov er time. The final video feature vector v was obtained by com- puting the per-speak er normalized motion vector of the face landmarks by simply subtracting e very frame with the pre vi- ous one. The motion vector of the first frame was set to zero. 4. RESUL TS In order to compare our models to previous works in both speech enhancement and separation, we e valuated the perfor - mance of the proposed models using both speech separation 2 Speakers 3 Speakers SDR PESQ V iSQOL SDR PESQ V iSQOL Noisy 0 . 21 2 . 22 2 . 74 − 3 . 42 1 . 92 2 . 04 VL2M 2 . 88 2 . 25 2 . 62 − 0 . 51 1 . 99 1 . 98 VL2M ref 9 . 24 2 . 81 3 . 09 5 . 27 2 . 44 2 . 54 A V concat 9 . 56 2 . 80 3 . 09 5 . 15 2 . 41 2 . 52 A V c-ref 10 . 55 3 . 03 3 . 21 5 . 37 2 . 45 2 . 58 T able 3 . TCD-TIMIT results - speaker -independent. and enhancement metrics. Specifically , we measured the ca- pability of separating the tar get utterance from the concurrent utterance with the source-to-distortion ratio (SDR) [27, 28]. While the quality of estimated target speech was measured with the perceptual PESQ [29] and V iSQOL [30] metrics. For PESQ we used the narro w band mode while for V iSQOL we used the wide band mode. As a very first experiment we compared landmark posi- tion vs. landmark motion v ectors. It turned out that landmark positions performed poorly , thus all results reported here refer to landmark motion vectors only . W e then carried out some speaker -dependent experiments to compare our models with previous studies as, to the best of our knowledge, there are no reported results of speaker- independent systems trained and tested on GRID and TCD- TIMIT to compare with. T able 1 reports the test-set ev alua- tion of speaker-dependent models on the GRID corpus with landmark motion v ectors. Results are comparable with pre vi- ous state-of-the-art studies in an almost identical setting [15, 17]. T able 2 and 3 show speaker-independent test-set results on the GRID and TCD-TIMIT datasets respectively . V2ML performs significantly worse than the other three models in- dicating that a successful mask generation has to depend on the acoustic conte xt. The performance of the three models in the speaker-independent setting is comparable to that in the speaker -dependent setting. A V concat-ref outperforms V2ML ref and A V concat for both datasets. This supports the utility of a refinement strat- egy and suggests that the refinement is more effecti ve when it directly refines the estimated clean spectrogram, rather than refining the estimated mask. Finally , we ev aluated the systems in a more challenging testing condition where the target utterance was mixed with 2 utterances from 2 competing speakers. Despite the model was trained with mixtures of two speakers, the decrease of performance was not dramatic. Code and some testing examples of our models are av ail- able at https://goo.gl/3h1NgE . 5. CONCLUSION This paper proposes the use of face landmark motion vec- tors for audio-visual speech enhancement in a single-channel multi-talker scenario. Different models are tested where land- mark motion vectors are used to generate time-frequency (T - F) masks that extract the target speaker’ s spectrogram from the acoustic mixed-speech spectrogram. T o the best of our kno wledge, some of the proposed mod- els are the first models trained and ev aluated on the limited size GRID and TCD-TIMIT datasets that accomplish speaker- independent speech enhancement in the multi-talker setting, with a quality of enhancement comparable to that achie ved in a speaker -dependent setting. 6. REFERENCES [1] E. Colin Cherry , “Some experiments on the recognition of speech, with one and with two ears, ” The Journal of the Acoustical Society of America , vol. 25, no. 5, pp. 975–979, 1953. [2] Josh H McDermott, “The cocktail party problem, ” Curr ent Biology , vol. 19, no. 22, pp. R1024–R1027, 2009. [3] Elana Zion Golumbic, Gre gory B. Cogan, Charles E. Schroeder , and David Poeppel, “V isual input enhances selectiv e speech envelope tracking in auditory cortex at a “cocktail party”, ” J ournal of Neu- r oscience , vol. 33, no. 4, pp. 1417–1426, 2013. [4] W ei Ji Ma, Xiang Zhou, Lars A. Ross, John J. F oxe, and Lucas C. Parra, “Lip-reading aids word recognition most in moderate noise: A bayesian explanation using high-dimensional feature space, ” PLOS ONE , vol. 4, no. 3, pp. 1–14, 03 2009. [5] Albert S Bregman, Auditory scene analysis: The perceptual organi- zation of sound , MIT press, 1994. [6] V ahid Kazemi and Josephine Sullivan, “One millisecond face align- ment with an ensemble of regression trees, ” in The IEEE Conference on Computer V ision and P attern Recognition (CVPR) , June 2014. [7] Davis E. King, “Dlib-ml: A machine learning toolkit, ” J ournal of Machine Learning Resear ch , vol. 10, pp. 1755–1758, 2009. [8] Y uxuan W ang, Arun Narayanan, and DeLiang W ang, “On T raining T argets for Supervised Speech Separation, ” IEEE/ACM T ransactions on Audio, Speech, and Language Processing , vol. 22, no. 12, pp. 1849–1858, Dec. 2014. [9] Martin Cooke, Jon Barker , Stuart Cunningham, and Xu Shao, “ An audio-visual corpus for speech perception and automatic speech recognition, ” The Journal of the Acoustical Society of America , vol. 120, no. 5, pp. 2421–2424, Nov . 2006. [10] Naomi Harte and Eoin Gillen, “TCD-TIMIT: An Audio-V isual Cor- pus of Continuous Speech, ” IEEE T ransactions on Multimedia , vol. 17, no. 5, pp. 603–615, May 2015. [11] Z. Chen, Y . Luo, and N. Mesgarani, “Deep attractor network for single-microphone speaker separation, ” in 2017 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , March 2017, pp. 246–250. [12] Y usuf Isik, Jonathan Le Roux, Zhuo Chen, Shinji W atanabe, and John R. Hershey , “Single-channel multi-speaker separation using deep clustering, ” in Interspeech , 2016. [13] Morten Kolbaek, Dong Y u, Zheng-Hua T an, Jesper Jensen, Morten K olbaek, Dong Y u, Zheng-Hua T an, and Jesper Jensen, “Multitalker speech separation with utterance-level permutation inv ariant training of deep recurrent neural networks, ” IEEE/ACM T rans. Audio, Speech and Lang. Pr oc. , vol. 25, no. 10, pp. 1901–1913, Oct. 2017. [14] Bertrand Rivet, W enwu W ang, Syed Mohsen Naqvi, and Jonathon Chambers, “ Audiovisual Speech Source Separation: An overvie w of key methodologies, ” IEEE Signal Pr ocessing Magazine , vol. 31, no. 3, pp. 125–134, May 2014. [15] A viv Gabbay , Ariel Ephrat, T avi Halperin, and Shmuel Peleg, “Seeing through noise: V isually driven speaker separation and enhancement, ” in ICASSP . 2018, pp. 3051–3055, IEEE. [16] Ariel Ephrat, T avi Halperin, and Shmuel Peleg, “Improved speech reconstruction from silent video, ” ICCV 2017 W orkshop on Computer V ision for Audio-V isual Media , 2017. [17] A viv Gabbay , Asaph Shamir, and Shmuel Peleg, “V isual speech en- hancement, ” in Interspeech . 2018, pp. 1170–1174, ISCA. [18] Jen-Cheng Hou, Syu-Siang W ang, Ying-Hui Lai, Y u Tsao, Hsiu-W en Chang, and Hsin-Min W ang, “ Audio-V isual Speech Enhancement Us- ing Multimodal Deep Conv olutional Neural Networks, ” IEEE T rans- actions on Emer ging T opics in Computational Intelligence , vol. 2, no. 2, pp. 117–128, Apr . 2018. [19] Jen-Cheng Hou, Syu-Siang W ang, Y ing-Hui Lai, Jen-Chun Lin, Y u Tsao, Hsiu-W en Chang, and Hsin-Min W ang, “ Audio-visual speech enhancement using deep neural networks, ” in 2016 Asia- P acific Signal and Information Processing Association Annual Sum- mit and Confer ence (APSIP A) , Jeju, South K orea, Dec. 2016, pp. 1–6, IEEE. [20] Ariel Ephrat, Inbar Mosseri, Oran Lang, T ali Dekel, Ke vin W ilson, A vinatan Hassidim, W illiam T . Freeman, and Michael Rubinstein, “Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-V isual Model for Speech Separation, ” ACM T ransactions on Graphics , v ol. 37, no. 4, pp. 1–11, July 2018, arXiv: 1804.03619. [21] T . Afouras, J. S. Chung, and A. Zisserman, “The conv ersation: Deep audio-visual speech enhancement, ” in Interspeech , 2018. [22] Andrew Owens and Alexei A Efros, “ Audio-visual scene analysis with self-supervised multisensory features, ” Eur opean Conference on Computer V ision (ECCV) , 2018. [23] Michael C. Anzalone, Lauren Calandruccio, Karen A. Doherty , and Laurel H. Carney , “Determination of the potential benefit of time- frequency gain manipulation, ” Ear Hear , vol. 27, no. 5, pp. 480–492, Oct 2006, 16957499[pmid]. [24] Ulrik Kjems, Jesper B. Boldt, Michael S. Pedersen, Thomas Lunner , and DeLiang W ang, “Role of mask pattern in intelligibility of ideal binary-masked noisy speech, ” The Journal of the Acoustical Society of America , vol. 126, no. 3, pp. 1415–1426, 2009. [25] A. Gra ves, A. Mohamed, and G. Hinton, “Speech recognition with deep recurrent neural networks, ” in 2013 IEEE International Con- fer ence on Acoustics, Speech and Signal Pr ocessing , May 2013, pp. 6645–6649. [26] Diederik P Kingma and Jimmy Ba, “ Adam: A method for stochastic optimization, ” arXiv pr eprint arXiv:1412.6980 , 2014. [27] E. V incent, R. Gribonv al, and C. Fevotte, “Performance measure- ment in blind audio source separation, ” IEEE T ransactions on Audio, Speech and Languag e Pr ocessing , vol. 14, no. 4, pp. 1462–1469, July 2006. [28] Colin Raffel, Brian McFee, Eric J Humphrey , Justin Salamon, Oriol Nieto, Dawen Liang, Daniel PW Ellis, and C Colin Raf fel, “mir e val: A transparent implementation of common mir metrics, ” in In Pr oceed- ings of the 15th International Society for Music Information Retrie val Confer ence, ISMIR . Citeseer , 2014. [29] A.W . Rix, J.G. Beerends, M.P . Hollier , and A.P . Hekstra, “Perceptual ev aluation of speech quality (PESQ)-a new method for speech qual- ity assessment of telephone networks and codecs, ” in 2001 IEEE In- ternational Conference on Acoustics, Speech, and Signal Processing . Pr oceedings (Cat. No.01CH37221) , Salt Lake City , UT , USA, 2001, vol. 2, pp. 749–752, IEEE. [30] A. Hines, J. Sk oglund, A. K okaram, and N. Harte, “V iSQOL: The V irtual Speech Quality Objectiv e Listener, ” in IW AENC 2012; Inter- national W orkshop on Acoustic Signal Enhancement , Sept. 2012, pp. 1–4.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment