모바일 SoC에서 신경망 추론 최적화와 성능 한계
본 논문은 최신 모바일 SoC에 탑재된 CPU, GPU, 전용 NPU 등 이기종 연산 유닛들의 추론 처리량과 에너지 효율을 정량적으로 평가하고, 기술 세대 간 성능·전력 변화를 분석한다. 또한 모든 유닛을 동시에 활용하는 병렬 추론 기법을 제안해 단일 유닛 사용 시 대비 최대 2배의 성능 향상을 입증한다.
저자: Siqi Wang, Anuj Pathania, Tulika Mitra
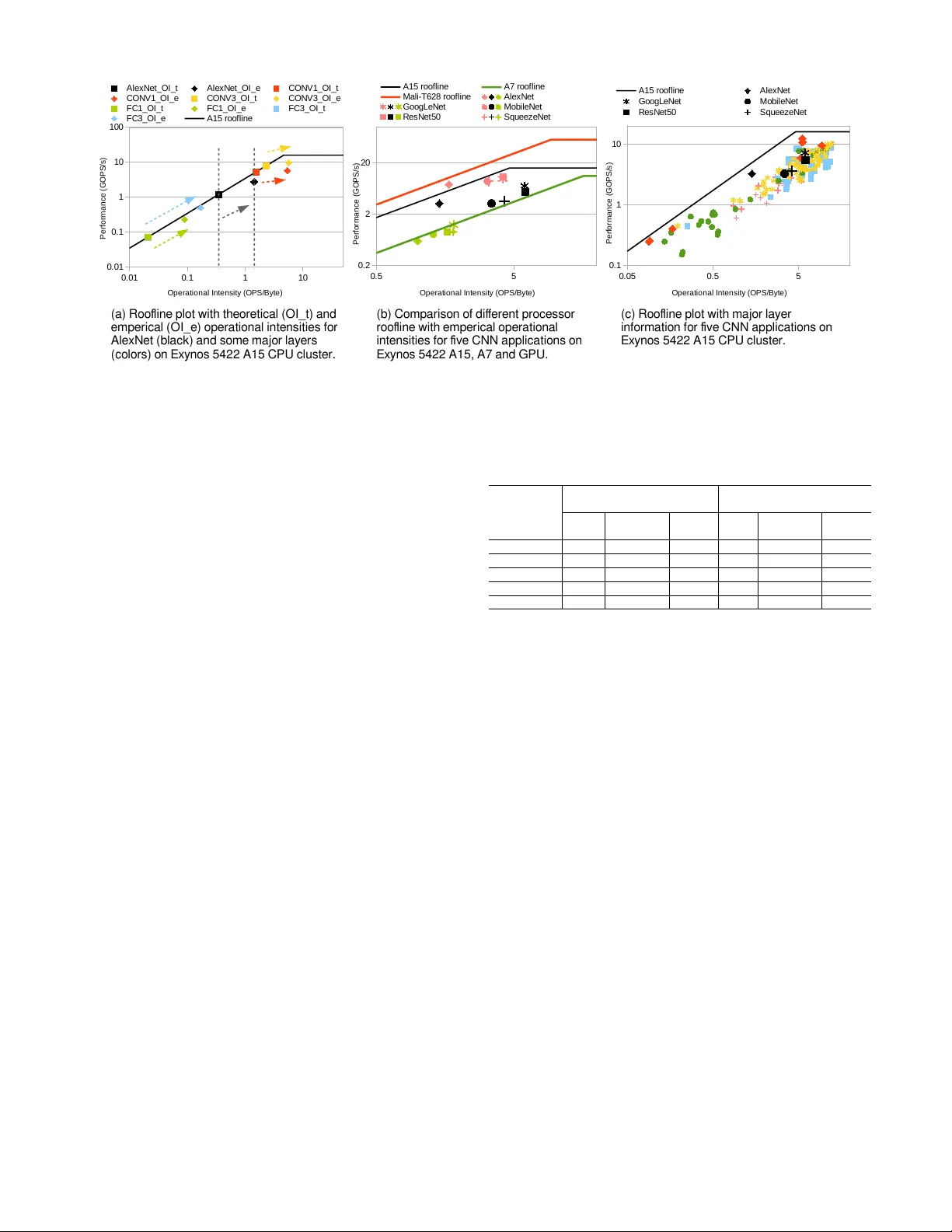
본 논문은 모바일 기기에 탑재된 이기종 연산 유닛(CPU, GPU, 전용 NPU)의 추론 성능과 전력 효율을 정량적으로 비교하고, 기술 세대 간 변화와 아키텍처 혁신이 미치는 영향을 심층 분석한다. 연구는 2014년 출시된 28 nm Exynos 5422와 2017년 출시된 10 nm Kirin 970 두 SoC를 대상으로 한다. 두 칩 모두 ARM big.LITTLE 구조를 채택하고 있으며, 각각 Cortex‑A15/A7, Cortex‑A73/A53 클러스터를 포함한다. GPU는 Mali T628 MP6과 Mali G72 MP12이며, Kirin 970에만 FP16 전용 1.92 TFLOPS 성능의 NPU가 존재한다.
실험에서는 AlexNet, GoogLeNet, MobileNet, ResNet‑50, SqueezeNet 등 5가지 대표 CNN을 선택해, 각 유닛별 이미지당 처리량(Img/s)과 평균 전력 소모를 측정하였다. 결과는 다음과 같다. 첫째, 최신 Kirin 970의 Big A73 클러스터는 Exynos 5422의 Big A15 대비 평균 4.4배, Small A53은 Small A7 대비 2.6배 높은 처리량을 보였다. GPU 역시 G72이 T628보다 4.2배 빠른 처리량을 기록했다. 둘째, 에너지 효율 측면에서는 NPU가 가장 우수했으며, 그 뒤를 GPU와 Small CPU 클러스터가 잇는다. NPU는 전용 FP16 연산과 최적화된 메모리 경로 덕분에 동일 작업당 전력 소모가 GPU 대비 2~3배 낮다. 셋째, 기술 스케일링(28 nm→10 nm)만으로는 클럭 주파수 상승이 1.2~1.3배에 불과했음에도, 실제 처리량 향상은 2.5~4.4배에 달했다. 이는 마이크로아키텍처 개선(분기 예측, 캐시 프리페치, 64‑bit NEON 확장)과 메모리 서브시스템 최적화가 주요 요인임을 의미한다. 넷째, Small CPU 클러스터는 전력 대비 성능 비율이 개선되지 않아, A53이 A7보다 전력은 두 배 가량 높지만 처리량은 2.6배에 머물렀다. 이는 복잡한 파이프라인과 큰 TLB가 전력 효율을 저해함을 보여준다.
Roofline 모델을 구축해 각 레이어의 운영 강도(OI)를 분석하였다. 이론적 OI(OIt)와 실제 DRAM 접근 기반 OI(OIe)를 구분했으며, 캐시 효과로 인해 OIe가 OIt보다 오른쪽(높은 강도)으로 이동함을 확인했다. 대부분의 CONV 레이어는 메모리 바운드에서 컴퓨트 바운드로 전이했으며, FC 레이어는 메모리 바운드 영역에 머물러 이론적 최대 성능에 근접했다. 이러한 분석은 CPU와 GPU가 메모리 대역폭에 크게 의존함을 보여주며, NPU는 전용 메모리 경로와 고정밀 FP16 연산 덕분에 메모리 병목을 최소화한다는 점을 강조한다.
마지막으로, 모든 연산 유닛을 동시에 스케줄링하는 병렬 추론 프레임워크를 구현하였다. 실험 결과, 단일 유닛 사용 시 대비 전체 처리량이 평균 1.8~2.0배 증가했으며, 전력 효율도 크게 악화되지 않았다. 이는 모바일 환경에서 고성능·저전력 추론을 달성하기 위한 실용적인 접근법으로 평가된다. 논문은 또한 NPU와 GPU의 포터블성·개발 난이도 차이, CPU 최적화 필요성, 그리고 향후 네트워크 구조 변화에 따른 가속기 호환성 문제 등을 논의하며, 모바일 AI 애플리케이션 설계 시 이기종 자원을 어떻게 조합할 것인가에 대한 전략적 인사이트를 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기